Digitaltechnik
Bit
Abkürzung für Binary digit
Ein Bit ist die kleinste digitale Einheit und kann die Werte 0 und 1 annehmen.
Siehe auch
Nibble
Nibble ist eine weniger gebräuchliche Bezeichnung für ein halbes Byte (4 Bit). In diesem Zusammenhang spricht man häufig von HIGH- und LOW-Nibble. Ein Nibble entspricht auch jeweils einem Zeichen der hexadezimalen Darstellung.
Byte
Abkürzung für Binary Term.
Ein Byte besteht aus 8 Bits und kann damit 2^8 = 256 verschiedene Werte annehmen.
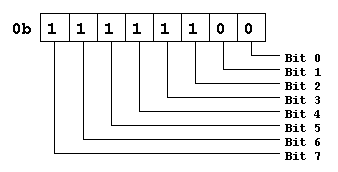
In der üblichen Schreibweise (INTEL) werden die einzelnen Bits von rechts nach links abgezählt. "MSB" nennt man das höchstwertige Bit (ganz links, Bit 7), "LSB" das niederwertigste (ganz rechts, Bit 0).
Auf dem PowerPC ist es umgekehrt, dort ist Bit #0 das MSB (links) und Bit 7/15/31/63 ganz rechts das LSB.
Word
Ein Word besteht aus zwei oder mehr (2^N) aufeinanderfolgenden Bytes. Im Falle von zwei Bytes kann es somit 256*256 = 65536 Werte annehmen.
Prozessoren mit mehr als 16 Bits "natürlicher" Breite bezeichnen oft ihre natürliche Breite als Word (also ein 32-bit-Prozessor 4 aufeinanderfolgende Bytes, ein 64-bit-Prozessor 8 aufeinanderfolgende Bytes). Allerdings wird dies nicht mehr durchweg einheitlich gehandhabt. Auf einer X86-Architektur ist es oft unter MS Windows aufgrund seiner Abstammung von einem 16-Bit-Betriebssystem üblich, zwei Bytes als Word zu bezeichnen. Wird der gleiche Prozessor unter Unix betrieben, bezeichnet ein Word dagegen 4 aufeinanderfolgende Bytes, da das Betriebssystem als 32-Bit System auf diesen Prozessor portiert worden ist (zu Zeiten, da die X86-Architektur bereits eine natürliche Wortbreite von 32 Bit hatte, also i386 und höher).
Endianness
In Verbindung mit einem 16, 32 oder 64 Bit Prozessor ist das Problem interessant, in welcher Reihenfolge die Bytes im Speicher angeordnet sind, also das höherwertige Byte an vorderer oder hinterer Stelle. Die unterschiedliche Art der Darstellung z. B. zwischen den x86- und PowerPC Prozessoren nennt man "Little Endian" und "Big Endian". Diese kuriose Bezeichnung lehnt an das Problem an, von welchem Ende man ein Ei aufschlagen sollte.
Beispiel:
Little Endian Hex Dump:
00000000 20 8F 04 08 23 00 00 00 12 00 00 00 1E 00 00 00 | ...#...........| 00000010 94 8D 04 08 00 00 00 00 12 00 08 00 E6 01 00 00 |................|
Der markierte Bereich auf Adresse 0x1C zeigt das 16-bit Word mit dem Wert
0xE6 + (256 * 0x01) = 0x01E6 = 486
Die jeweils größeren Adressen enthalten dabei die höherwertigen Bytes des Word.
Auf einer Big-Endian Maschine würde der Hexdump so aussehen:
00000000 8F 20 08 04 00 23 00 00 00 12 00 00 00 1E 00 00 |. ...#..........| 00000010 8D 94 08 04 00 00 00 00 00 12 00 08 01 E6 00 00 |................|
Die höheren Adressen enthalten hier die niederwertigen Bytes. Das erscheint auf den ersten Blick unlogisch, hat aber andererseits den Vorteil, daß man die Zahl (0x01E6) "auf den ersten Blick" im Hexdump erkennen kann.
Mikroprozessoren wurden von Intel zunächst in Little-Endian Byteorder eingeführt, worauf Motorola mit Big-Endian Byteorder reagierte. Viele RISC-Prozessoren kann man theoretisch per Hardwarebit in ihrer Byteorder umschalten, wobei dies praktisch so früh erfolgen muß, daß die gesamte Maschine (einschließlich BIOS etc.) darauf eingerichtet sein muß.
Big-Endian ist auch die sogenannte Network Byte Order, d.h. insbesondere im IP-Bereich werden alle Daten "auf dem Draht" in dieser Anordnung übertragen. Entsprechend müssen Little-endian Maschinen in ihren Netzwerkprotokollen sehr viel zwischen beiden Anordnungen übersetzen, so daß es z. B. beim Intel Pentium einen eigenen Prozessorbefehl für diese Operation gibt.
- Typische Vertreter für Little-Endian sind:
Mit der Endianess in Verbindung steht die Frage der Bitnummerierung. Wenn man bei Big-Endian die Bits von rechts nach links nummeriert, bekommt man spätestens bei Bitfeldern Probleme. 68020 nummeriert deshalb Einzelbits von rechts nach links, die später hinzugekommenden Bitfelder von links nach rechts. Weshalb solche Prozessoren die Bits manchmal konsequent von links nach rechts nummerieren (z. B. PowerPC), was jene irritiert, die in der Bitnummer auch die Wertigkeit des Bits sehen.
Alignment auf größeren Prozessoren
Damit wird die Ausrichtung (engl. Alignment) von Daten mit mehr als ein Byte Länge beschrieben. Manche Prozessoren benötigen bei Zugriffen auf ein Word eine Adresse, die mit der Wortgröße ausgerichtet ist, besonders RISC-Prozessoren. Soll beispielsweise auf ein 32-Bit Word zugegriffen werden, so muß die Adresse dann ebenfalls durch 4 teilbar sein (32 Bit = 4 Byte). Dies wird erforderlich, da der gesamte Prozessor- und Speicherbus in dieser Wortgröße organisiert ist, so daß ein unaligned access (Zugriff auf nicht teilbare Adresse) mehr als einen Buszyklus verursachen würde. Ein solcher Zugriff generiert auf diesen Prozessoren dann einen Trap. Andere Prozessoren (z. B. X86) können diesen unaligned access zwar ausführen, indem sie die Ergebnisse von zwei Speicherzyklen zum gewünschten Word kombinieren, jedoch ist dieser Mehrfachzugriff uneffektiv, so daß Compiler sich trotzdem gern an die Ausrichtung auf ganze Wortgrenzen halten, beispielsweise beim Ausrichten von struct Elementen durch Einfügen von Füllbytes (padding bytes), oder durch Einfügen von NOPs vor Beginn einer neuen Funktion.
Siehe auch
- Forumsbeitrag: Wie nennt man diese Darstellung von Digitalsignalen? (viele Links auf Programme zur Darstellung von Impulsdiagrammen