Wird die zum Beitrag 'RFM12 Protokoll Stack' (Wettbewerb) angekündigte Referenzimplementierung noch erscheinen?
Eine Implementierung gibt's doch. Was es nicht gibt, ist ein fertig compilierbares Beispiel.
Bin grad dabei Diplomarbeit zu schreiben, deswegen läuft das etwas zögerlich. Außerdem hab ich kein konkretes Projekt bei dem ich den Stack einsetzen will. Auf der anderen Seite hab ich jetzt dank dem Wettbewerb zwei USBprog und werde mir noch ein paar RFM12 kaufen. Dann kann ich etwas effizienter testen. Das Projekt ist also definitiv nicht gestorben. (Bei konkretem Interesse ist auch ne Mail besser, als ein Eintrag hier im Forum, den bekomme ich ja nicht zwingen mit)
Ich würde demnächst am Stack weitermachen, hätte aber vorher Feedback ob das Design so für die meisten taugt, oder ob ich lieber was ändern soll. Wer hätte denn überhaupt Interesse den Stack zu benutzen?
Das hört sich doch schon mal gut an. Könnt ihr vielleicht den Verwendungszweck etwas genauer beschreiben? Welche Hardware (µC) wollt ihr einsetzen? Wie viele Teilnehmer soll ein Netz haben? Braucht ihr eher hohe Datenrate oder hohe Datensicherheit?
Parametrisierbar :) Erstmal hätte ich ganz gerne Doku. Das ist ja alles nett, aber noch nicht ganz ausgereift, oder? Wenn ich nach dem Schichtenmodell gehe, dann muss ich doch auch Daten auf dem PHY Layer durch einen einfachen Aufruf versenden können. Wenn ich davon ausgehe, dass deine Konvention RFM12_PHY_xxx bedeutet, dass dies die Zugriffsfunktionen für den Layer1 sind, dann fehlt mir aber eine Funktion "rfm12_phy_send_data(void* data)". Hier klingelt der Phy-Layer den Mac-Layer durch einen Callback an, um Daten abzusenden? Das Schöne an einem Schichtenmodell ist doch grade, dass die Schichten gegeneinander gekapselt sind. Warum muss der Mac-Layer bei einem Sendevorgang wieder aufgerufen werden? Hast du denn schon mal eine Anwendung dafür gebaut? Wenn man definitiv weiß, dass die Funktionen zum Einstellen der Hardware (mit den teilweise unergründbaren Konfigurationen) funktioniert, dann ist das doch schon mal richtig cool. Es scheint aber bisher keiner einzusetzen? Hat jeder sein selbst erfundenes Rad am Laufen?
Doku wird's hoffentlich noch geben, der Wiki-Artikel soll ja erst mal ein Entwurf sein über den man diskutieren kann. Zum Schichtenmodell: Wenn man das auf einem PC implementiert geb ich dir vollkommen recht, da schieben die Layer einfach Daten nach unten durch. So einfach ist es auf einem µC leider nicht, wenn man RAM und Rechenzeit sparen will. 1. Wenn die Daten im Layer 3 vorliegen und zum Layer 2 übergeben werden, müsste dieser z.B. für die FEC ein neues Array mit doppelter Größe anlegen, und dann für die Berechnung über das ganze Array laufen und dieses kopieren. Ist natürlich nicht sehr effizient, da die Daten gar nicht gleichzeitig vorliegen müssen. 2. Häufig liegen die Daten (z.B. Header) gar nicht als Array vor, sondern werden "on-the-fly" generiert, auch hier ist es geschickter, wenn der untere Layer die Daten erst bei Bedarf vom oberen Layer anfragt. Hier haben wir jetzt also den Konflikt, dass man den oberen Layer zwar nicht kennen möchte, diesen aber aufrufen muss. In meiner Implementierung hab ich das so gelöst, dass der untere Layer zumindest die Deklaration der Funktion des oberen Layer kennt. Noch schöner wäre natürlich gar kein Funktionsaufruf, sondern inline Code. TinyOS löst das sehr schön mit einem eigenen Präprozessor, der aus generischen Vorlagen C-Code erzeugt. Vollständige Kapselung ist bei einem µC auch nicht nötig, da die Layer ja zur Compile-Zeit bekannt sind (im Gegensatz z.B. zu einem PC Betriebssystem). MAC und PHY hab ich so schon für einfache (nur 2 Teilnehmer) Projekte eingesetzt. Die optimalen Einstellungen für Bandbreite, Baudrate und Kanalabstand müssen aber dringend noch diskutiert werden!
Okay, seh ich ein. Aber gerade für so etwas braucht es ein paar Zeilen Doku^^ Und wenn du die FUnktionen als inline deklarierst, hast du auch keinen Function Call, dafür aber eine (wie ich finde) schöne Schnittstelle. Das inline könnte man sogar noch hinzu-#definen, je nachdem, ob man die Layer3-Schnittstelle nutzen möchte und somit Layer2 und 1 kapseln will. Kann man den µC eigentlich in den Sleepmode schicken, sodass er wieder durch einen INT bei Empfang geweckt wird, oder macht er dann Merkwürdigkeiten mit seinen Pins, die dem RFM stören? Wie genau funktioniert deine Collision Detection (oder Avoidance)? Listen-before-Talking ist ja cool, aber rein theoretisch kann es trotzdem knallen. Kriegt man das mit (außer man definiert sich dann ein Handshake)? Stell doch einfach mal dein 2-Teilnehmer-Beispiel bereit, vielleicht wird dann einiges klarer :) MfG Mr.Green
Das mit inline ist leider nicht so einfach mit dem avr-gcc, der ignoriert das gern mal. Vor allem wenn die Funktion in einer anderen *.c Datei aufgerufen wird. Sleep-Modus sollte grundsätzlich möglich sein. Vom RFM her spricht nix dagegen. Collision Detection sollte ähnlich wie bei WLAN und Zigbee funktionieren, also Random Backoff bei Sendewunsch dagegen aber sofortiges ACK, wenn gewünscht. Einfach mal die Wiki-Artikel zu beiden oben genannten durchlesen. Beispiel kann ich mal vorbereiten, sobald der USB-HID Stack für den USBprog zuverlässig geht.
Manuel Stahl wrote: > Das mit inline ist leider nicht so einfach mit dem avr-gcc, der > ignoriert das gern mal. Vor allem wenn die Funktion in einer anderen *.c > Datei aufgerufen wird. Der ignoriert da gar nichts. Das Inlinen erledigt der Compiler und der arbeitet halt nur mit einer *.c Datei zur gleichen Zeit. Es kann also gar nicht funktionieren. Meine Lösungen dafür: Entweder Alle Inline Funktionen in eine *.c Datei, oder in unterschiedliche *.c Dateien und diese per #include inkludieren oder den Code in *.h Dateien schreiben und diese inkludieren.
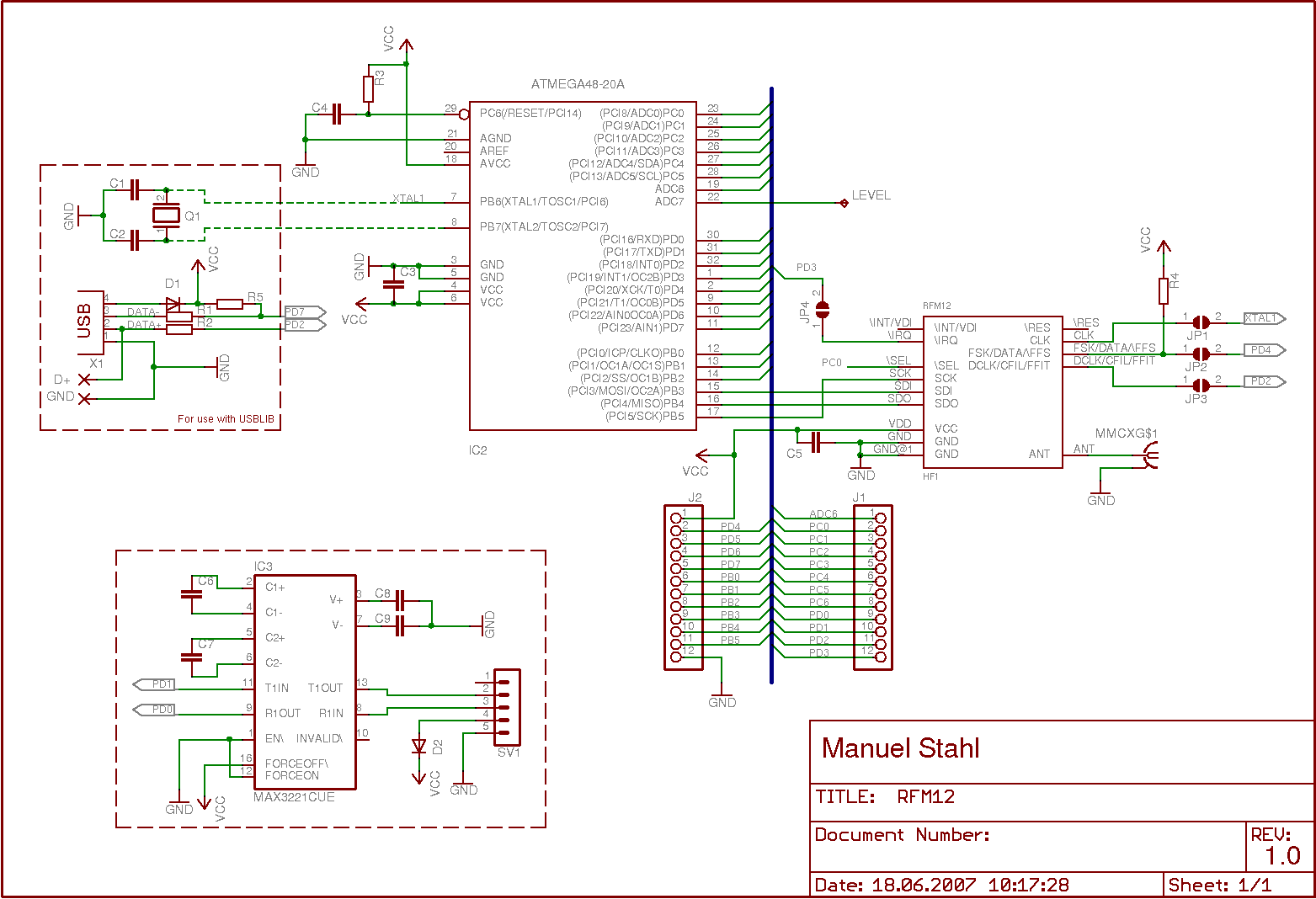
Und was mir grad noch einfällt: Welche Schaltung liegt dem denn nun zu Grunde? Exakt die hier? http://www.mikrocontroller.net/wikifiles/5/51/AVR_RFM12_Schematic.png Gruß Mr.Green
{kind=link}
So, melde mich auch mal mit Interesse. Würde auch gerne ein Netz mit etwa 10 Teilnehmner (in der Art: 1xMaster und 9x Slave) aufbauen. Datenrate wäre da nicht so wichtig, aber Datensicherheit (nicht, dass die Daten verschlüsselt sind, sondern dass sie korrekt gesendet werden). Würde mich über eine weiterentwicklung freuen :) Auch eine Doku und ein gut dokumentiertes Beispiel wären nicht schlecht.
Chris R. wrote: > Und was mir grad noch einfällt: Welche Schaltung liegt dem denn nun zu > Grunde? > Exakt die hier? > http://www.mikrocontroller.net/wikifiles/5/51/AVR_RFM12_Schematic.png Das ganze ist völlig unabhängig von der Schaltung. In der Referenzimplementierung ist nur wichtig, dass der RFM12 per SPI am Atmel hängt. Zum Experimentieren hab ich den RFM12 direkt (ohne weitere Bauteile) am USBprog ;)
Eine Frage, im Artikel ist die maximal Laenge des L2 Pakets mit 517 bytes angegeben. Spaeter jedoch, wird von 973 bytes Paketgroesse ausgegangen. Was stimmt ?
512 nicht 517. Das wäre mal so n Vorschlag. Zigbee erlaubt z.B. nur 128 byte. Wo das Optimum liegt, hängt stark von der zu erwartenden Fehlerrate ab. Wo genau ließt du 973?
Unter Frames, MACLLCL3 Beachte: Durch die Hamming-Codierung sind alle Bytes innerhalb des MAC-Layer doppelt so lang wie angegeben! also(layer2): preamble 2 bytes 0xAA sync 2 bytes suffix 1 byte 0xAA Nutzdaten (layer3): header 4 bytes src,dst,flags,crc data 0-480 bytes Nutzdaten x2, wegen des Hamming, also 968 bytes + 3 byte layer 5 macht 973 bytes, bei 4800bps ca 2sek uebertragungszeit. Ich weiss, dass das Modul schneller sein kann, aber bei weiten Entfernungen muss die Geschwindigkeit gedrosselt werden.
Jetzt bin ich glatt selber durcheinander gekommen. 512 Bit, nicht Byte, macht 64 Byte. Minus 4 Byte bleiben nocht 60 Byte, aber nicht Nutzdaten sonder mit FEC. Wären dann nur 30 Byte Nutzdaten für Layer 3. Ist möglicherweise etwas wenig. Wie gesagt, hier kann man noch Experimentieren.
Meine Erfahrung mit dem RFM12, Paketgröße, Baudrate usw.: Zu kleine Pakete bremsen aus, das ist klar (RX-TX Umschaltung usw.). Je größer das Paket dagegen ist, desto höher ist die Wahrscheinlichkeit, dass es durch einen Übertragungsfehler beschädigt wird (ich verwende keine Fehlerkorrektur, sondern fordere das komplette Paket neu an). Ein, meiner Meinung nach häufige Fehler ist, dass ein Bit verschluckt wird. Dann nützt auch Hamming nichts. Ich hatte Hamming anfangs auch verwendet, aber am Ende verworfen, da es letzendlich schneller ging die Daten ab und zu nochmal komplett neu zu übertragen, als immer die doppelte Datenmenge rumschleppen zu müssen. Keine Ahnung ob es realisierbar ist, aber ich würde zu einer effizienteren Fehlerkorrektur tendieren (leider ist das nicht wirklich mein Fachgebiet). Um die Probleme mit aus dem Takt kommen des Empfängers zu vermeiden, füge ich nach einem 0x00 oder 0xFF ein 0xAA ein. So sind worst case 8 Bits ohne eine Flanke. Weiterhin kommt dazu, dass große Pakete auch viel RAM brauchen, vor allem wenn mehrere in kurzer Zeit empfangen werden, und der µC noch andere Sachen zu tun hat. Bei mir haben sich daher 64 oder 128Byte Pakete durchgesetzt (64Byte für Netzwerke mit vielen Teilnehmern, 128Byte für Punkt zu Punkt Verbindungen). Als Baudrate verwende ich meist 10-20kBaud. Auch hier hat man wieder den Kompromiss: Hohe Baudraten sind störanfälliger, bei niedrigen Baudraten dauert die Übertragung länger, und die Warscheinlichkeit dass irgendein anderer Sender dazwischenfunkt wird höher. Bei höheren Baudraten nimmt meiner Erfahrung nach die Fehlerrate schnell zu.
Danke Benedikt, dass sind schon mal brauchbare Anhaltspunkte. > Meine Erfahrung mit dem RFM12, Paketgröße, Baudrate usw.: > Zu kleine Pakete bremsen aus, das ist klar (RX-TX Umschaltung usw.). > Je größer das Paket dagegen ist, desto höher ist die Wahrscheinlichkeit, > dass es durch einen Übertragungsfehler beschädigt wird (ich verwende > keine Fehlerkorrektur, sondern fordere das komplette Paket neu an). So wie immer halt. Welche Paketlänge (in Millisekunden) empfiehlst du denn? > Ein, > meiner Meinung nach häufige Fehler ist, dass ein Bit verschluckt wird. > Dann nützt auch Hamming nichts. Ich hatte Hamming anfangs auch > verwendet, aber am Ende verworfen, da es letzendlich schneller ging die > Daten ab und zu nochmal komplett neu zu übertragen, als immer die > doppelte Datenmenge rumschleppen zu müssen. Das Problem hatte ich auch schon, aber Schuld war nicht das RFM12 sondern ein zu langsames SPI am Sender. Nur mit Hardware SPI auf 2Mbit und Interupts konnte ich sicherstellen, dass ich rechtzeitig Daten nachschieb. Könntest du mal prüfen, ob das nicht auch bei dir das Problem ist? > Keine Ahnung ob es > realisierbar ist, aber ich würde zu einer effizienteren Fehlerkorrektur > tendieren (leider ist das nicht wirklich mein Fachgebiet). Die Tabelle geht halt schön schnell. Polynome berechnen ginge auch noch, braucht aber wesentlich mehr Takte. Das Hauptproblem sind ja auch Büschelfehler, daher müsste die Redundanz über das gesamte Paket verteilt werden, was natürlich wieder ein Puffern des Gesamtpakets nötig macht. > Um die > Probleme mit aus dem Takt kommen des Empfängers zu vermeiden, füge ich > nach einem 0x00 oder 0xFF ein 0xAA ein. So sind worst case 8 Bits ohne > eine Flanke. Das wäre auch ne Möglichkeit, aber 0xAA ist bei mir z.B. auch Paketende. Dann müssen auch wieder Escapezeichen mit rein, das wollte ich eigentlich vermeiden. > Weiterhin kommt dazu, dass große Pakete auch viel RAM brauchen, vor > allem wenn mehrere in kurzer Zeit empfangen werden, und der µC noch > andere Sachen zu tun hat. Bei mir haben sich daher 64 oder 128Byte > Pakete durchgesetzt (64Byte für Netzwerke mit vielen Teilnehmern, > 128Byte für Punkt zu Punkt Verbindungen). Hört sich vernünfig an, wobei der Stack auch "on-the-fly" Verarbeitung und Generierung der Daten erlaubt. > Als Baudrate verwende ich meist 10-20kBaud. Auch hier hat man wieder den > Kompromiss: Hohe Baudraten sind störanfälliger, bei niedrigen Baudraten > dauert die Übertragung länger, und die Warscheinlichkeit dass irgendein > anderer Sender dazwischenfunkt wird höher. Bei höheren Baudraten nimmt > meiner Erfahrung nach die Fehlerrate schnell zu. Hälst du es für realistisch, dass man die Baudrate variabel macht? Also erst ein kurzes Sync mit Aushandlung der Baudrate und dann erst die Daten. Oder man legt für verschiedene Kanäle Baudraten fest. Dann hätte man einen Kanal für Signalisierung und einen für Burst-Transfers.
Manuel Stahl wrote: > So wie immer halt. Welche Paketlänge (in Millisekunden) empfiehlst du > denn? Ich würde bis etwa 100ms gehen. Das ergibt 256Bytes bei 20kBaud. > Das Problem hatte ich auch schon, aber Schuld war nicht das RFM12 > sondern ein zu langsames SPI am Sender. Nur mit Hardware SPI auf 2Mbit > und Interupts konnte ich sicherstellen, dass ich rechtzeitig Daten > nachschieb. Könntest du mal prüfen, ob das nicht auch bei dir das > Problem ist? Ich lasse das SPI Interface mit 2.5MHz laufen (das maximale was der RF12 kann). Bei einem 1 Byte im FIFO und 20kBaud hat der AVR 400µs Zeit um ein Byte zu liefern. Da sehe ich eigentlich keine Probleme, das kann ich bei mir auch ausschließen, da meine Senderoutine blockierend ist, der AVR wartet also nichtstuend darauf, das nächste Byte senden zu können. Ganz 100%ig kann ich es nicht ausschließen, da ich aber seit dem Einfügen des 0xAA nach 0x00 und 0xFF eine sehr viel geringere Fehlerrate habe, dürfte es daran gelegen haben. > Das wäre auch ne Möglichkeit, aber 0xAA ist bei mir z.B. auch Paketende. Ich übertrage gleich als erstes die Länge des Pakets. Das hat auch vor und Nachteile (was ist wenn die Länge falsch übertragen wurde? -> Plausibilitätsprüfung anhand der maximal zulässigen Paketgröße) > Dann müssen auch wieder Escapezeichen mit rein, das wollte ich > eigentlich vermeiden. Bei mir sind 0x00 und 0xFF quasi die Escapezeichen selbst: Sobald die empfangen wurden, wird das nächste Byte komplett ignoriert. Der Hamming Code sollte aber eigentlich vermeiden, dass 0x00 und 0xFF an Daten entstehen, so dass dieses Problem garnicht erst entsteht. > Hälst du es für realistisch, dass man die Baudrate variabel macht? Also > erst ein kurzes Sync mit Aushandlung der Baudrate und dann erst die > Daten. Oder man legt für verschiedene Kanäle Baudraten fest. Dann hätte > man einen Kanal für Signalisierung und einen für Burst-Transfers. Sowas hatte ich anfangs vor, habe es dann aber verworfen, da mir der Aufwand zu hoch war: Der Empfänger beurteilt die Qualität des empfangenen Signals und passt dynamisch die Parameter wie Baudrate, Sendeleistung usw. an. Bei einer Punkt zu Punkt Verbindung ist das noch leicht zu lösen, aber spätestens bei mehreren Teilnehmern dürfte das sehr kompliziert werden, vor allem wenn alle Teilnehmer gleichberechtigt sind, und es keinen Master gibt, der mit fester Baudrate arbeitet und an den sich alle anderen anmelden und der so die Parameter aller anderen kennt. Dann müsste jeder neue Teilnehmer durch ausprobieren die Baudrate der anderen ermitteln, man müsste also einen Befehl einbauen, der an alle gesendet wird, und auf den diese mit einer Liste der aktuellen Parameter antworten. Ein Problem wäre dann noch, wie man einen Baudratenwechsel sauber unter allen Teilnehmern koordiniert. Wie stellt man sicher, dass alle Teilnehmer die neue Baudrate mitbekommen haben? Eine mögliche Lösung wäre regelmäßig einen Ping auszusenden, und wenn der eine bestimmte Zeit lang nicht beantwortet wurde, springt das entsprechende Modul in den Suchmodus in dem es mit allen Baudraten versucht jemanden zu erreichen.
Oder eben fixe Baudraten für verschiedene Kanäle. Wenn man schneller übertragen möchte, wechselt man (nach Absprache) den Kanal.
Ich überlege gerade Broadcast Gruppen einzuführen. Individuelle IDs und Gruppen IDs wären nur 7-bit groß. Ist das MSB gesetzt, ist die Gruppe gemeint. 0xff ist Broadcast an alle. Ein mögliches Anwendungsgebiet wären z.B. Lichtschalter, die mehrere Lichter gleichzeitig Schalten wollen. Oder man könnte alle Steckdosen ausschalten, ohne das Licht auszuschalten. Die Konfiguration der Gruppen müsste dann über das Layer 3 Protokoll mit der TypeID 0 gehen.
Hallo Manuel, könntest du bitte ins Programm eine Abfrage reinmachen, dass nur die Kanäle 4-7 verwendet werden können? Ausserdem wäre ein Hinweis nicht schlecht, dass beim Verwenden von Kanälen ausserhalb dieses Bereiches andere Funkdienste gestört werden und dieser Betrieb in der EU nicht erlaubt ist. Im Störungsfall können Messeinsätze der BNetzA nicht unerhebliche Kosten sowie Bussgelder verursachen, da diese Sender kein CE-Kennzeichen besitzen. Servus, Helmut
Helmut -dc3yc wrote: > Im Störungsfall können Messeinsätze der BNetzA nicht > unerhebliche Kosten sowie Bussgelder verursachen, da diese Sender kein > CE-Kennzeichen besitzen. Keine Ahnung wie das genau ist, da der Sender ja an sich nicht komplett ist ohne Ansteuerung, aber für die RFM12 gibt es hier eine CE Konformitätserklärung: http://www.pollin.de/shop/static/konformitaet/D810049K.PDF
@Helmut: geb mir mal noch n Link auf ne Seite wo die entspr. Richtlinie steht. Dann bau ich das ein. Das Wiki kannst du übrigens selbst ändern.
Hallo, also der Link der Allgemeinverfügung der BNetzA ist hier: http://www.bundesnetzagentur.de/media/archive/298.pdf Ui, die CE-Erklärung hab ich mir mal ausgedruckt! Da werde ich morgen gleich den Herrn Dipl. Ing. (FH) Werner Pollin anrufen und ihn fragen, wie er dafür CE erteilt. Ok, dann werde ich das mal wieder rückändern, hatte das Wiki schon ergänzt. Aber da muss ich nachfragen, wie man dafür CE erteilen kann. Werde mich da wieder melden, was herausgekommen ist. Servus, Helmut.
Manuel Stahl wrote: > Ich würde demnächst am Stack weitermachen, hätte aber vorher Feedback ob > das Design so für die meisten taugt, oder ob ich lieber was ändern soll. > Wer hätte denn überhaupt Interesse den Stack zu benutzen? Also ich habe den Stack für mein Projekt lauffähig gemacht. Allerdings bin ich jetzt etwas stutzig geworden. Das Problem ist, wie der CRC Check von der LLC Schicht gemacht werden soll ohne die empfangenen Daten in der LLC Schicht zu puffern und ohne die CRC Checksumme als letztes Byte der L3 Schicht zu übergeben. Die sollte ja vom CRC Check nichts mitbekommen. Die einzige Lösung aus meiner Sicht wäre, das LLC Frameformat um eine Längenangabe zu erweitern. Viele Grüße, Jens
Wenn man die CRC checken will, müsste eigentlich sowieso das ganze Paket gepuffert werden und erst nach erfolgreichem Check an den L3 gehen. Um nachträglich zu prüfen reicht jedoch schon 1 Byte Puffer, so dass der L3 den Datenstrom um 1 Byte versetzt bekommt. Die LLC bekommt ja mit, wenn das Paket zu Ende ist und kann dann das Byte im Puffer als CRC verwenden.
Hallo Manuel, > Wenn man die CRC checken will, müsste eigentlich sowieso das ganze Paket > gepuffert werden und erst nach erfolgreichem Check an den L3 gehen. Die in der Referenzimplementierung verwendete _crc_ibutton_update()-Funktion benutze ich byteweise (direkt beim Empfangen eines Bytes), dann speichere ich jeweils die temporäre CRC zwischen und am Ende wird die Funkton mit der gesendeten CRC aufgerufen - als Ergebnis muss Null herauskommen. So kann man sich das Zwischenspeichern des gesamten Frames sparen. Die eigentliche Frage ist, wie man die Daten an die L3 Schicht übergeben soll. Ich bin bis jetzt von der Beispiel L3-Implementierung aus der Diskussion zum Stack ausgegangen. Hier werden die Daten byteweise übergeben. Das hat aus meiner Sicht den Nachteil, dass die L3-Schicht erst am Ende der Übertragung weiss ob die Daten korrekt sind (die sie aber schon empfangen hat). Die Fehlersicherung findet doch aber in der LLC-Schicht statt und sollte die L3-Schicht nicht kümmern. Es wäre natürlich auch möglich die Fehlersicherung für Bytestreams ganz wegzulassen. Alternativ kann man, wie Du schon vorgeschlagen hast, das ganze Paket in der LLC-Schicht zwischenspeichern, dann den CRC-Check machen und anschließend als ganzes Paket an die L3-Schicht übergeben. Hiermit könnte man auch streamen indem man ein Byte pro Paket verschickt - allerdings mit großem Overhead. Also Byte oder Paket an die L3 übergeben, das ist die Frage ;-) Viele Grüße, Jens
Meiner Meinung nach beides, über zwei getrennte APIs für die L3, weil nur diese entscheiden kann, ob sie streaming- oder packet-basiert arbeiten will.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.