Eine kleine Verständnisfrage: Braucht das dargestellte FIR-Filter auf einem FPGA (mit genügend Multiplizierern) zur Berechnung eines Ausgangswertes: a) einen Taktzyklus (?die Multiplikationen finden bei steigender Flanke, das Aufaddieren der Teilprodukte bei fallender Flanke statt?) b) zwei Taktzyklen (?einen für die Multiplikationen, einen für die Akkumulierung der Teilprodukte?) c) weder noch ? Da bin ich mal gespannt ;)
Angehängte Dateien:
-

FIR_parallel_copy.jpg
55 KB

sorry, hab ne .psd Datei angehangen.. hier nochmal als JPEG.
nur zur Absicherung: die Copy-Rights für das Bild hat Xilinx ;)
Weder noch: Das kommt auf die Implementierung an, wie viele zusaetzliche Register du einbaust. Das Addieren von 256 Zahlen ist keine triviale Sache, die innerhalb von wenigen Nanosekunden erledigt waere. Wenn dein Takt langsam genug ist (schaetzungweise <10MHz im Spartan 3), dann kann man das sicher auch in nur einem Taktzyklus abarbeiten, sonst muss man dort mit Pipelining arbeiten und zusaetzliche Zwischenergebnisse berechnen.
> ...zur Berechnung eines Ausgangswertes...
Also, genügend (und genügend schnelle) Kombinatorik (Multiplizierer und
LUTs) vorausgesetzt, braucht diese Schaltung einen Takt nur zum
Weiterschieben der Eingangsdaten.
Weder die Multiplikation noch die Addition ist eine getaktete Operation.
Also Lösung c, weil zur Berechnung kein Takt nötig ist.
@ Jan .M: Pipeline-Register würden zwar den Durchsatz erhöhen, aber die Berechnung eines Ausgangswertes würde doch durch die zusätzlichen Verzögerungen durch die Pipeline-Register mehr Zeit in Anspruch nehmen, oder? @ Lothar Miller: was genau ist damit gemeint, dass keine Berechnung notwendig ist? Es muss doch jeweils ein Eingangswert mit einem Filterkoeffizienten multipliziert werden und das Ergebnis zum vorherigen Ergebnis hinzuaddiert werden oder nicht?
Ohne die Verschiebeoperation asynchron zu machen und die Operationen explizit aufzubauen, benötigt man n-1 Register und kann es in n Takten machen. Die Addition schachtelt man rekursiv rein. Das macht aber kein Mensch so, sondern baut pLatzoptimiert.
>> was genau ist damit gemeint, dass keine Berechnung nötig ist... Nein, meine Aussage war, dass > zur Berechnung kein Takt nötig ist. Die Rechnungen, die in dem Filter vorkommen sind prinzipiell nur kombinatorisch und benötigen daher keinen Takt. Ich kann z.B. eine Addition in VHDL einfach so beschreiben:
1 | r <= b + c; |
--> kein Takt nötig. Dasselbe geht mit einer Multiplikation:
1 | w <= e * f; |
--> wiederum: kein Takt nötig Beide Grund-Rechenoperationen können daher taktlos synthetisiert werden. Und mit den von dir angegebenen Rahmenbedingungen: 1) mit genügend Multiplizierern 2) keine Architektur 3) keine Angabe zur gewünschten Arbeitsgeschwindigkeit kann ich daher sagen: Zur Berechnung des Ausgangswertes ist kein Takt notwendig. Allein zum Eintakten der Daten in das Filter brauche ich getaktete Register (deshalb heißen die Dinger oben im Bild ja auch Reg). In der Praxis hat man Vorgaben zu den Ressourcen (nicht beliebig viele Addierer und Multiplizierer) und auch Vorgaben zur Geschwindigkeit. Da muss man dann das ganze Design oder Teile davon sequentiell abarbeiten.
Bekommt man da in der Praxis keine Probleme mit den racing conditions? weil 256 Filtertaps sind ja (gefühlt) schon eine ganze menge wenn man das ohne Takt (asynchron) machen will. Gruß
Angehängte Dateien:
-

DSP.jpg
240 KB

@Lothar Miller: Sorry, hatte Dich erst falsch verstanden.. aber auch bei kombinatorischer Logik kann ich doch die Teilergebnisse erst aufaddieren, nach dem die Multiplikationen stattgefunden haben. Beispielsweise beim Code:
1 | c <= a * b; |
1 | d <= d + c; |
so wird für Zeile 2 doch im selben Takt noch nicht das Ergebnis von a * b für c, sondern der vorherige Wert von c (was immer der sein mag) verwendet. Also irgendwo spielt doch in Hardware ein Takt, oder zummindest ein zeitliche Komponente eine Rolle (die Signale, die durch die synthetisierte kombinatorische Logik geführt werden, brauchen doch eine gewisse Zeit, die Operationen finden wohl kaum mit delta_t=0 statt). Um ein wenig Klarheit in den Kontext meiner Frage zu bringen, habe ich die beiden Folien der XUP Präsentration in den Anhang gepackt. Es geht dabei um das Aufzeigen der Vorteile von FPGAs im Vergleich zu DSPs.

Angehängte Dateien:
-

muladd1.gif
16 KB
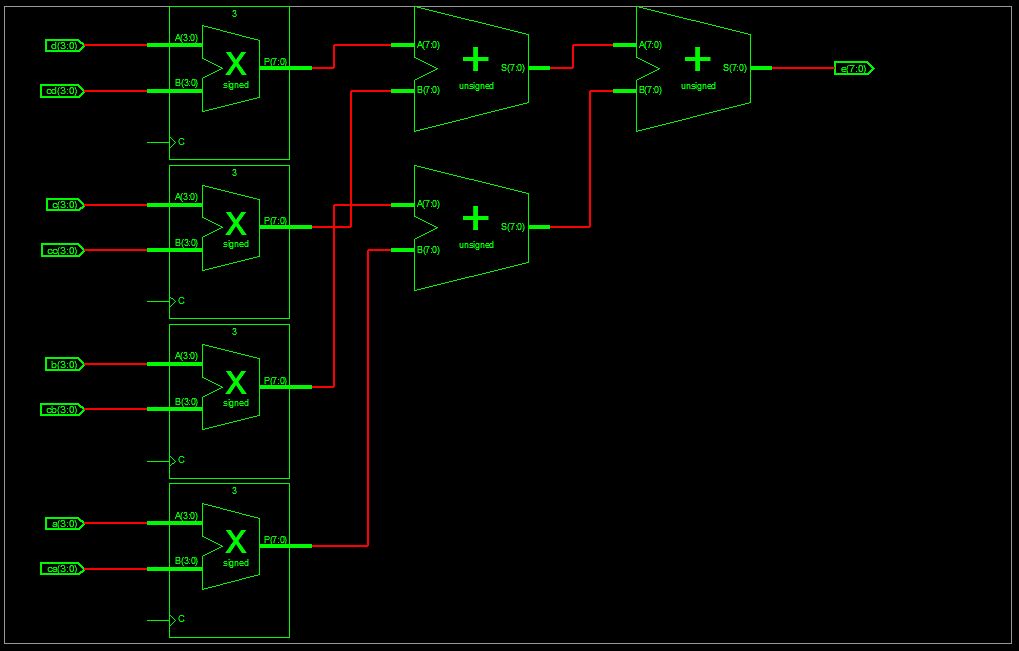
> so wird für Zeile 2 doch im selben Takt noch nicht das > Ergebnis von a * b für c, sondern der vorherige Wert von c verwendet. Oh nein. Wenn ich das taktlos und concurrent beschreibe, wird das wirklich parallel aufgebaut. Hier z.B. eine kleine Beschreibung mit 4 Registerwerten multipliziert mit 4 Koeffizienten und anschliessender Summation. Im ganzen Design weit und breit kein Takt. Der Takt ist nur für das Filter nötig, um neue Registerwerte (für a,b,c und d) zu laden, aber das passiert nicht hier in dieser Beschreibung.
1 | library IEEE; |
2 | use IEEE.STD_LOGIC_1164.ALL; |
3 | use IEEE.NUMERIC_STD.ALL; |
4 | |
5 | entity muladd is |
6 | Port ( a : in SIGNED (3 downto 0); -- Eingangswerte v. Registern |
7 | b : in SIGNED (3 downto 0); |
8 | c : in SIGNED (3 downto 0); |
9 | d : in SIGNED (3 downto 0); |
10 | ca : in SIGNED (3 downto 0); -- Koeffizienten |
11 | cb : in SIGNED (3 downto 0); |
12 | cc : in SIGNED (3 downto 0); |
13 | cd : in SIGNED (3 downto 0); |
14 | e : out SIGNED (9 downto 0)); |
15 | end muladd; |
16 | |
17 | architecture Behavioral of muladd is |
18 | signal ma : SIGNED (7 downto 0); -- Multiplikationsergebinsse |
19 | signal mb : SIGNED (7 downto 0); |
20 | signal mc : SIGNED (7 downto 0); |
21 | signal md : SIGNED (7 downto 0); |
22 | begin
|
23 | ma <= a * ca; |
24 | mb <= b * cb; |
25 | mc <= c * cc; |
26 | md <= d * cd; |
27 | e <= ma + mb + mc + md; |
28 | end Behavioral; |
Im Bild dazu die RTL Schematics. Auch hier klar zu sehen: die clk-Pins sind nicht angeschlossen, weil asynchrone Multiplizierer verwendet werden. > aber auch bei kombinatorischer Logik kann ich doch die Teilergebnisse > erst aufaddieren, nach dem die Multiplikationen stattgefunden haben. Richtig, rein kombinatorisch aufgebaut wird das Design ziemlich groß und zäh. Denn die Multiplikationen laufen zwar (wirklich) parallel, das daraus berechnete Additionsergenbnis wird aber geraume Zeit vor sich hin glitchen. > Es geht dabei um ... Vorteile von FPGAs im Vergleich zu DSPs. Auf dem Bild von Xilinx sieht man dann auch: For Academic Use Only In der Praxis wird kaum einer einen so großen Filter tatsächlich komplett Kombinatorisch aufbauen, dazu sind die Ressourcen zu wertvoll ;-)
Zunächst einmal vielen Dank für die Mühe.. Gerade die Stelle
1 | das |
2 | daraus berechnete Additionsergenbnis wird aber geraume Zeit vor sich hin |
3 | glitchen |
wirft bei mir ja die Frage auf, wie lang das Aufaddieren dauert.. je nach Takt könnte diese Dauer doch (vor allem bei sovielen Teilprodukten) länger dauern als ein Taktzyklus, oder?
Kommt drauf an, wie schnell die Logikgatter sind und wieviele Logik-Ebenen hintereinander sind. Auch schnelle FPGAs haben endliche Schaltzeiten.
> wie lang das Aufaddieren dauert.... > je nach Takt könnte diese länger dauern als ein Taktzyklus, oder? Ja. Dein Takt, der die Daten einschiebt und/oder weiterverarbeitet muß natürlich langsam genug sein. Ob es reicht sagt dir die Statische Timinganalyse, wenn du es mal implementiert hast.
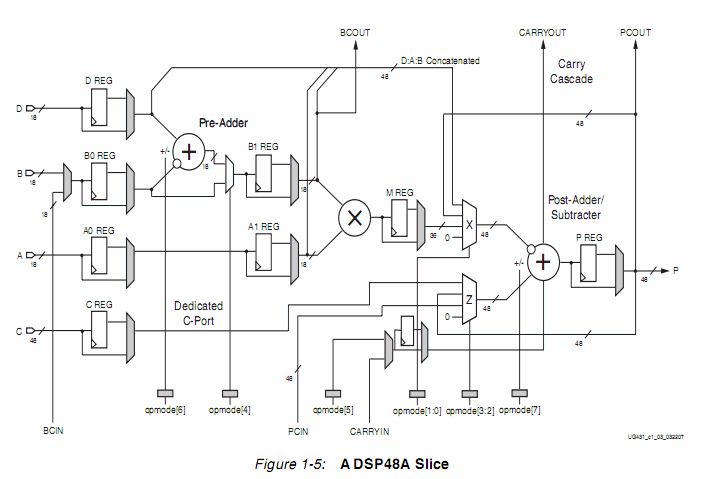
Hallo! kennt sich desbezüglich jemand mit einem DSP48A Slice aus? JEDES dieser Slices kann ja eine Vor-Addition, eine Multiplikation und eine Nach-Addition durchführen. Da ein solches Slice keinen Takteingang hat, heißt das doch, das die Logik kombinatorisch ist und dass das Ergebnis immer bei einer Signaländerung am Eingang sofort (bzw. nur mit einer minimalen Schaltzeitverzögerung) am Ausgang bereit steht, richtig? Und da im Datenblatt steht, dass der Slice maximal mit einem Takt von 250 MHz läuft, kann man davon ausgehen, dass diese Schaltzeit 1/250MHz beträgt oder sehe ich das ganze falsch? Wieso steht da überhaupt was vom maximal verwendbaren Takt, wenn das Teil gar nicht getaktet werden kann?
> Wieso steht da überhaupt was vom maximal verwendbaren Takt, > wenn das Teil gar nicht getaktet werden kann? Weil davor und danach wieder alles getaktet und hübsch synchron sein sollte und sein wird. Und dann ist natuürlich interessant, wie schnell dieser Takt sein darf. Im Xilinx User-Guide 431 steht >>> Full-speed operation is 250 MHz when using the pipeline registers. Und Pipeline Register waren schon immer das Mittel, wenn es darum ging, die Taktfrequenz auf Kosten der Latency hochzuschrauben. Siehe dazu den Beitrag "Re: failed paths im Timing analyzer"
Danke erstmal... echt nett, wie Du allen hier auf die Sprünge hilfst ;) Und umso netter wäre es, wenn du dich auch noch kurz zu meinen anderen Aussagen äußern würderst: "Da ein solches Slice keinen Takteingang hat, heißt das doch, das die Logik kombinatorisch ist und dass das Ergebnis immer bei einer Signaländerung am Eingang sofort (bzw. nur mit einer minimalen Schaltzeitverzögerung) am Ausgang bereit steht, richtig? Und da im Datenblatt steht, dass der Slice maximal mit einem Takt von 250 MHz läuft, kann man davon ausgehen, dass diese Schaltzeit (bei maximalem Pipelining) 1/250MHz beträgt oder?" Pipelining macht aber doch nur Sinn, wenn ich hohe Datenanforderungen habe.. wenn ich z.B. ein FIR Filter habe, dass als Eingang alle 1/48kHz neue Audiodaten erhält, dann macht der Einsatz von Pipelineregistern ja keinen Sinn, weil diese dann nur zu einer zusätzlichen Latenz führen würden, oder? Weil, es ist doch so: Alle 1/48kHz = 20833ns liegt ein Eingangswert am Eingang an, wird Blitzschnell (nur mit einer Schaltzeit) und parallel abgearbeitet, und das FIR-Filter wartet den Rest des Taktes auf einen neuen Eingangswert. Sehe ich das falsch?
@Gerd (Gast), du kannst die DSP-Komponenten bei entsprechend gesetzten Generic-Werten auch ohne Register verwenden. In diesem Fall hast du eine kombinatorische Schaltung. Aus der in der Tabelle abzulesenden max. Taktrate ergibt sich dann die Gatterlaufzeit (die eben umgekehrt die Frequenz bestimmt). Bei 250MHz ergibt sich so eine Gatterlaufzeit von 4 ns. Wenn du vor oder nach der Multiplikation noch weitere komb. Logik verwendest, dann kannst du die Pipeline-Register im Eingang bzw. im Ausgang auch weglassen (eben auf Kosten der Gatterlaufzeit, bei 48KHz wohl kein Problem). Gruss jörg
Angehängte Dateien:
-

DSP48A-Slice.gif
25 KB
{kind=link}
{kind=link}
> Da ein solches Slice keinen Takteingang hat... Doch, ein DSP48A-Slice hat durchaus einen Takteingang. Dieser geht auf die vielen Register, die nach jeder kombinatorischen Elementaroperation in dem Slice eingebaut sind. > wenn ich z.B. ein FIR Filter habe, dass als Eingang alle 1/48kHz > neue Audiodaten erhält, dann macht der Einsatz von Pipelineregistern ja > keinen Sinn, weil diese dann nur zu einer zusätzlichen Latenz führen > würden, oder? Prinzipiell ist keine Signalverarbeitung ohne Latenz möglich, für ein Filter brauche ich mehrere Eingangsdaten, damit ich ein Ergebnis berechnen kann. Die Pipelineregister innerhalb des Slices sind so angeordnet, dass dazwischen nie mehr als 4ns-(ts+th) vergehen, so kommt Xilinx auf eine maximale_Taktfrequenz von 250MHz. Ein Wert muss aber u.U. bis zu 5 solcher Stufen hintereinder durchlaufen, bis das Ergebnis am Ausgang erscheint. Fazit: komplette Rechenzeit vom Eingang bis zum Ausgang 20ns = 50MHz maximale_Rechengeschwindigkeit.
Ist denn die Verwendung von Pipelineregistern (bei Erstellung eines parallelen FIR-Filters mit Hilfe von DSP48A-Slices) bei einer geringen Datenrate von nur 48kHz nun a) kontraproduktiv (führt also zu schlechteren Ergebnissen), b) produktiv (auch bei 48kHz sind die Pipelinregister sinnvoll, da insgesamt auch da der Durchsatz erhöht wird) oder c) das Ergebnis ist in diesem Fall das Gleiche, nur dass das Ergebnis mit einer höheren Latenz erscheint (also kein Nutzen durch Pipelineregister, aber gleiches Ergebnis mit höherer Latenz als ohne Verwendung von jeglichen Pipelineregistern). Gruß Gerd
@Gerd
a)nein
b)nein
c)ja
aber bei 48kHz sollte man sich ernsthaft überlegen,
das parallele FIR-Filter in ein serielles zu überführen,
und mit einem N-fachen Arbeitstakt zu arbeiten, da man
bei 'richtigem Aufbau' eine Menge Ressourcen einsparen kann.
Speziell: N Multiplizierer -> 1 Multiplizierer
'richtiger Aufbau' meint hier, daß man versuchen sollte,
die Eingangsmultiplexer (für den einen Multiplizierer) zu
vermeiden, indem Memory (SRL16, distributed RAM oder BlockRAM)
diese Funktionalität übernimmt
http://www.xilinx.com/publications/xcellonline/xcell_52/xc_pdf/xc_s3dsp52.pdf
/Jochen
Als Anregung auch folgender Link: http://janick.bergeron.com/ -> Earlier Work, Top-Down Design Using VHDL Duke
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.