Hallo zusammen!
Ich hätte da mal eine Frage zu einem Problem, das mich schon länger
beschäftigt.
ich habe eine Divisions-Einheit, die zwei Integer-Operanden a und b mit
je 32 Bit einliest und das Ergebnis ebenfalls als 32 Bit Integer
ausgibt. Intern arbeitetet diese Einheit aber mit einer
Fließpunkt-Divisions-Einheit.
Der Datenfluss sieht also wie folgt aus:
fixed_to_float(a) -->
float_divider --> float_to_fixed
fixed_to_float(b) -->
Die drei Komponenten sind mit dem Core-Generator xon Xilinx erstellt
worden.
Nun stellt sich mir die Frage, wie ich das in einer Pipeline so
umsetzten kann, dass ich den maximalen Takt herauszuhole ( bzw. was
schreiben die "Coding Styles" o.ä. in diesem Falle vor?):
1. Direkt verdrahten (so wie oben abgebildet)
2. Vor und hinter float_divider ein Register (also insgesamt drei)
3. So wie 2., aber auch die Ein- und Ausgänge der Pipeline mit Registern
entkoppeln (also insgesamt sechs)
Wie würdet ihr das machen? Bringen denn die Vorschläge 2 und 3 überhaupt
einen Performance-Gewinn gegenüber Vorschlag 1 oder verschenke ich da
bloß wertvolle Flip-Flops?
Gruß,
dito
PS: Der obige Ansatz verbraucht tatsächlich weniger Ressourcen als die
direkte Division mit Integerzahlen (zumindest für den Fall, dass ich mit
jedem Takt ein Ergbnis erhalte (Latenz dafür 40 Takte))
Sind die Einheiten schon getaktet oder sind das kombinatorische Sachen? Wenn die getaktet sind hast du eh schon die Register an den Eingängen und es bringt nix, ansosnten kann es helfen ein Register vor und nach Float divider einzubauen (am Anfang und ende bringts nicht so viel bzw sizt da eh meist noch ein Register wenn du es mit anderer getakteter Logik verwindest).
Alle Komponenten sind getaktet. Der Float-Divider wird daher wohl auch Register am Eingang haben. Ich habe irgendwo mal gelesen, dass man "an bestimmten Stellen" (ich glaube an Anfang und Ende eines Moduls) Register plazieren sollte, um die Synthesewerkzeuge bei der Ermittlung des maximalen Taktes zu unterstützen. Weiß nur leider nicht mehr was da genau stand... :-(
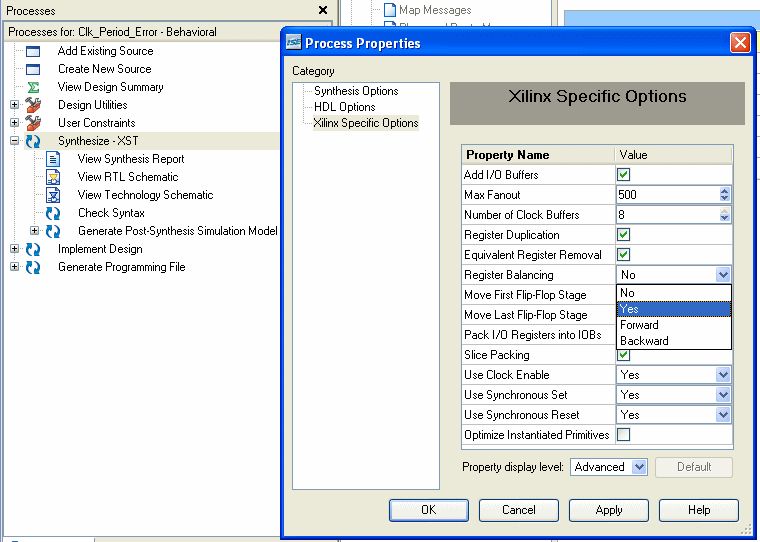
Das ist das Registerbalancing... Das muss nicht nur ein FF sein, es können auch mehrere Stufen sein und die Synthese versucht, die möglichst gleichmässig zwischen die Kombinatorik zu verteilen. Man kann die FFs vor die Logik setzen oder auch dahinter. BTW: Das kann auch zu Registerverdopplungen führen, die Funktion wird aber nicht geändert (wenn die Synthese keinen Mist baut...). Beim xst schaltet man das mit "-register_balancing YES" an. Hau einfach mal ein paar Register vor deine Eingänge und schau, ob die Taktperiode kleiner wird. Wenn der kritische Pfad aber zB. schon in dem FP_DIV war, wird die Balazierung wohl direkt nichts mehr bringen. Allerdings relaxed sie das gesamte Timing, das kann sich psoitiv auf die Routingzeiten auswirken. > Weiß nur leider nicht mehr was da genau stand... :-( XST User Guide S. 325 http://www.xilinx.com/support/documentation/sw_manuals/xilinx11/xst.pdf
Angehängte Dateien:
{kind=link}
> Beim xst schaltet man das mit "-register_balancing YES" an.
Oder über das GUI (Synthese-Optionen, Screenshot).
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.