Guten Tag,
ich bin gerade dabei verschiedene Pseudozufallsgeneratoren für mein
Industrieprojekt zu entwickeln. Der lineare Kongruenzgenerator und das
LFSR funktionieren schon. Der Blum Blum Shub Generator erzeugt mir
allerdings nicht die Folge, die in MATLAB erzeugt wird. Wäre nett, wenn
jemand von euch mal über den Code schaut. Vielleicht habe ich da
irgendwas falsch gemacht. Danke im voraus
1
libraryieee;
2
useieee.numeric_std.all;
3
useieee.std_logic_1164.all;
4
useieee.std_logic_arith.all;
5
6
entityshifter3is
7
8
generic
9
(
10
p:integerrange1to2100:=47;
11
q:integerrange1to2100:=23
12
);
13
14
port
15
(
16
prbsclk:instd_logic;
17
aus_x:outinteger
18
);
19
20
21
endentity;
22
23
architecturertlofshifter3is
24
25
constantm:integer:=1081;
26
signalx:integer:=1764;
27
signalx_neu:integer;
28
begin
29
30
31
process(prbsclk)
32
begin
33
34
ifrising_edge(prbsclk)then
35
36
x_neu<=(x**2)modm;
37
aus_x<=x_neu;
38
x<=x_neu;
39
endif;
40
41
endprocess;
42
43
endrtl;
eigentlich sollte folgende Folge ausgegeben werden (nur die ersten
Glieder laut MATLAB)
47079 33124 66490 39821 283513 165467 39811 168219
320635 139804
Chris L. schrieb:> also der lineare kongruenzgenerator funktioniert ja auch schon (auch in> hardware)... der arbeitet auch mit mod nach folgender formel (ax+c) mod> n
da ist aber n normalerweise eine 2er Potenz, selbst bei
Softwareimplementationen.
meinst du, dass das deswegen nicht funktioniert? also, weil m keine
zweierpotenz ist? die simulation gibt meist ein, manchmal 2 folgeglieder
korrekt zurück bevor sie sich "verrechnet"
Chris L. schrieb:> die simulation gibt meist ein, manchmal 2 folgeglieder> korrekt zurück bevor sie sich "verrechnet"
Es geht nicht um die Simulation. die Simulation kann jede Art von
Division und Modulo. Im echten Leben auf einem FPGA ist das ungleich
komplizierter...
> meinst du, dass das deswegen nicht funktioniert?
Nein. Du hast noch einen anderen Fehler...
> also, weil m keine zweierpotenz ist?
Aus diesem Grund wirst du das auf einem FPGA entweder
1. gar nicht
oder
2. mit sehr hohem Hardwareaufwand
realisiert bekommen.
Chris L. schrieb:> constant m : integer :=1081;Chris L. schrieb:> mist... sorry hier is noch ein falscher Wert für m drin. m=p*q = 340513
Warum schreibst dann nicht gleich so:
constant m : integer := p*q;
Das stimmt doch auch nicht:
> p : integer range 1 to 2100:=47;> q : integer range 1 to 2100:=23> m=p*q = 340513
47*23 gibt bei mir 1161... :-/
Chris L. schrieb:> eigentlich sollte folgende Folge ausgegeben werden
Und was kommt stattdessen heraus?
Chris L. schrieb:> meinst du, dass das deswegen nicht funktioniert? also, weil m keine> zweierpotenz ist? die simulation gibt meist ein, manchmal 2 folgeglieder> korrekt zurück bevor sie sich "verrechnet"
Meine Antwort bezog auf die Hardwareimplmentation.
Zu deinem Problem hier ein kleiner Schuss ins Blaue:
x_neu ist nicht initialisert, davon abgesehen auch überflüssig.
Bei getakteter Logik steht das Ergebniss immer erst im nächsten Tag zur
Verfügung. Also x_neu <= ... gefolgt von x <= x_neu macht nicht das
gleiche wie eine Softwarelösung.
sorry, ich bin da wohl mit meinen verschiedenen parametern durcheinander
gekommen.
also für p=167 q=2039 m=340513
für p=47 q=23 m=1081 (nicht 1161!!!)
ich hab das m direkt reingeschrieben, weil ich alle möglichen
fehlerursachen ausschließen wollte...
also für p=23 q=47 und x0 = x*x = 1764 sollte folgende folge
herauskommen...
578 55 863 1041 519 (nur die ersten glieder nach matlab)
das ergebnis der simulation häng ich mal an...
@lattice user...
wäre nett, wenn du mir dann verrätst wie ich das richtig mache. Ich bin
ein geübter C-Progger aber VHDL hatte ich letztes Semester nur mal kurz
das mit dem überlauf is ne gute idee, die ich auch hatte. deshalb jetzt
das "kleinere" Beispiel, welches eigentlich nicht aus dem 32Bit Bereich
laufen sollte
Lattice User schrieb:> 47079 * 47079 geht nicht mehr in 32bit signed Integer
Warum schreibst dann nicht gleich so:
constant m : integer := p*q;
Sollte auch nie auftauchen, denn modulo 1081 ergibt 1080 als höchste
Zahl. Wenn aber tatsächlich die erwähnten 340513 drin sind, dann muß es
schief gehen, denn m darf maximal 32768 groß sein!
Chris L. schrieb:> m=1081 (nicht 1161!!!)
Richtig. War wohl ein Tippfehler am Rechner... :-/
Aber umso mehr ein Grund, das den Synthesizer rechnen zu lassen:
constant m : integer := p*q;
gut mach ich dann so... aber woran könnte das dann denn noch liegen. bei
p=23 und q=47 dürfte die Größe der zahlen nich das Problem werden. Gibt
es für die größeren Variante, die mir natürlich auch eine brauchbarere
Periode für meine PN-Folge liefert eine Lösung? Zum Beispiel nen
Datentyp, der damit umgehen kann?
Chris L. schrieb:> wäre nett, wenn du mir dann verrätst wie ich das richtig mache. Ich bin> ein geübter C-Progger aber VHDL hatte ich letztes Semester nur mal kurz
Da ich selbst Verilog benutze lasse ich lieber die Finger davon VHDL
Beispiele hinzuschreiben, das können andere besser.
Das was die Simulation da anzeigt finde ich aber extrem seltsam, warum
zappelt aus_x z zwischen den Takten, wieso ändert sich der Zustand nicht
auf den Taktflanken?
Noch ein kleiner Ratschlag als jemand der auch von C/C++ kommt:
VHDL/Verilog sind KEINE Programiersprachen, sondern
Hardwarebeschreibungssprachen. Man sollte immer die Hardwaresicht von
Registern, Clocks und Leitungen im Blick haben, sonst geht es schief.
Stell dir es so vor als ob dein C Programm von vielen Prozessoren
abgeabrbeitet wird, für jede Programzeile ein eigener.
gut, dass nicht so sequentiell gearbeitet wird, wie in C ist mir schon
klar... blos, wo liegt jetzt der Fehler im Code.. Für mich sollte der
genau das machen , was ich "will" aber irgendwie scheint es einflüsse zu
geben, an die ich nicht denke (aus unerfahrenheit)... deswegen erhoffe
ich mir ja von den "erfahrenen" einen anstoss... ich will keine fertige
Lösung, sondern nur einen Anstoß in die richtige Richtung, damit ich das
Thema dann auch verstehe!
Chris L. schrieb:> blos, wo liegt jetzt der Fehler im Code.
Du hast keinen Fehler im Code. Du hast ein Problem mit dem Wertebereich
von Integern...
Chris L. schrieb:> das ergebnis der simulation häng ich mal an...
Der Brüller... :-o
Machst du da eine Timingsimulation? Ist dir arg langweilig?
Ich habe schon seit Eeeeeeewigkeiten keine Timigsimulation mehr gemacht.
Die sagt so gut wie nichts aus wenn nicht die Testbench dazu ziemlich
ausgefuchst ist.
Man macht eine Verhaltenssimulation, und fordert dann mit
Timing-Constraints eine bestimmte Geschwindigkeit. Und wenn die nicht
erreicht wird, hilft die Statische Timinganalyse bei der Suche nach dem
kritischen Pfad.
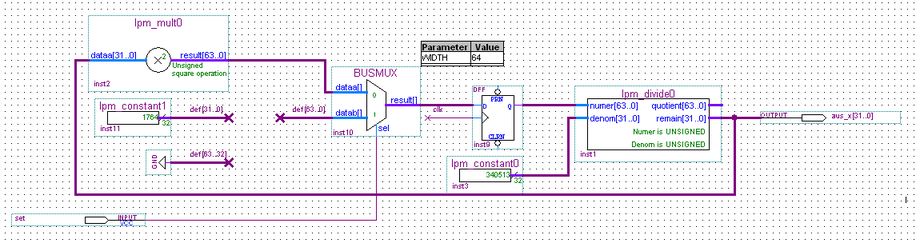
Ich habe das jetzt mal bereinigt, die unnötigen Signale rausgeschmissen,
und das Ganze leserlicher gemacht. Passt das jetzt?
Und was sagt die Simulation?
Mach mal einen Screenshot mit allen relevanten Signalen, und nicht nur
aus_x und einer clk die scheinbar nix mit der internen prbsclk zu tun
hat.
Lattice User schrieb:> und einer clk die scheinbar nix mit der internen prbsclk zu tun hat.
Wie gesagt, mein Verdacht: Timing-Simulation. Denn immer nach einer
steigenden Flanke ändert sich was...
War abgelenkt, Lothar war schneller und volltändiger :-)
Das mit der Timingsimulation ist mir nicht aufgefallen, ich habe selbst
noch nie eine gemacht. Beim FPGA meistens auch überflüssig.
danke Lothar!
dank dir! ich will nicht nerven, aber wo liegt nun genau der
unterschied? warum hast du mein ausgabe x in einen std_logic_vektor
umgewandelt?
was bietet den vorteil / nachteil einer timing analyse?
Chris L. schrieb:> warum hast du mein ausgabe x in einen std_logic_vektor umgewandelt?
Weil es sonst der Xilinx ISIM nicht richtig darstellen kann... :-(
Du kannst das auch als Integer zurückgeben.
> was bietet den vorteil / nachteil einer timing analyse?
Vorteil: mir nicht bekannt.
Nachteil: unnötiger Aufwand, Signale werden evtl. umbenannt und
verschwinden, mehr Rechenzeit nötig, unschönes "Gewusel" in der
Waveform...
@Chris L. und Lothar Miller
Hoppla, da gibts es, so glaube ich eine Begriffsverwirrung
zwischen Timing Analyse und Timing Simulation und hier
war evtl. die Timingsimulation gemeint:
> was bietet den vorteil / nachteil einer timing analyse?
Denn die "Timing Analyse" nach dem Place&Route ist hochaktuell,
denn dort sehe ich dann meine maximal möglichen Taktfrequenzen
(bei ASICs auch noch die hold-Zeiten).
Die Timing-Simulation hingegen, also Simulation mit den Gattern und
allen ihren laufzeiten nach dem Place&Route, macht kaum mehr Sinn.
bko schrieb:>> was bietet den vorteil / nachteil einer timing analyse?> Hoppla, da gibts es, so glaube ich eine Begriffsverwirrung
Autsch, richtig: ich hatte Timig-Simulation gelesen.
bko schrieb:> Denn die "Timing Analyse" nach dem Place&Route ist hochaktuell,
Korrekt, das ist ja auch meine Aussage...
Bei der Statischen Timinanalyse sieht man wie gesagt sofort den
langsamsten (=kritischen) Pfad (der die maximale Taktfrequenz begrenzt)
und wie er zustandekommt. Dann kann man leicht abwägen, ob das Routing
ungünstig ist oder zuviele Logikebenen hintereinandergelegt wurden.
Bei einer combinatorischen Loop kann die statische Timinganalyze
versagen, sollte aber zumindestens ein Warning ausgeben.
@Chris
Ich halte es durchaus für möglich dass du dir mit dem Modulo Operator
eine combinatorische Loop eingefangen hast. Und deine Timingsimulation
sagt dir dass deren Hardwareumsetzung nicht funktioniert.
Lattice User schrieb:> Bei einer combinatorischen Loop kann die statische Timinganalyze> versagen, sollte aber zumindestens ein Warning ausgeben.
Sowas wird normalerweise schon vom Synthesewerkzeug erkannt und
gemeldet. Allerdings können gegatete kombinatorische Schleifen durchaus
auch "nur" als Latch erkannt werden...
Hier mal für Xilinx XST:
http://www.lothar-miller.de/s9y/categories/36-Kombinatorische-Schleife
Basierend auf die beiden Beispiele dort hat auch auch Synopsys (Lattice)
eine ähnliche Meinung zum Thema:
1
@W: CL180 :"C:\...\CombinatorialLoop.vhd":18:12:18:21|Found combinational loop at toggle
2
@W: CL179 :"C:\...\CombinatorialLoop.vhd":15:16:15:24|Found combinational loop at un2_counter[3]
3
@W: CL179 :"C:\...\CombinatorialLoop.vhd":15:16:15:24|Found combinational loop at un2_counter[2]
Und die gegatete Version:
1
@W: CL179 :"C:\...\CombLoop.vhd":51:34:51:42|Found combinational loop at un2_counter[3]
2
@W: CL179 :"C:\...\CombLoop.vhd":47:6:47:9|Found combinational loop at counter[2]
3
@W: CL179 :"C:\...\CombLoop.vhd":47:6:47:9|Found combinational loop at counter[1]
4
@W: CL179 :"C:\...\CombLoop.vhd":47:6:47:9|Found combinational loop at counter[0]
> Ich halte es durchaus für möglich dass du dir mit dem Modulo Operator> eine combinatorische Loop eingefangen hast.
Nein. Das ist nicht das Problem, denn das ganze Design ist getaktet. Es
hat nur mit dem Wertebereich von Integern zu tun...
Lothar Miller schrieb:> Nein. Das ist nicht das Problem, denn das ganze Design ist getaktet. Es> hat nur mit dem Wertebereich von Integern zu tun...
Die Version von der Chris seinen Simulationsscreenshot gepostet hat,
sollte eigentlich keinen Überlauf haben, hat es bei deiner Version ja
auch nicht.
Kann man überhaupt eine allgemeine Division (ausser durch Lookuptable)
ohne irgendeine Art von Iteration (loop) implementieren? Ich dachte das
geht nicht aber lasse mich gerne eines besseren belehren.

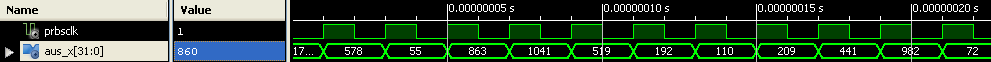{kind=link}