zachso schrieb:
> nun frage ich mich natuerlich ob das nicht um einiges eleganter geht
> irgendwie? das muss doch anders moeglich sein.
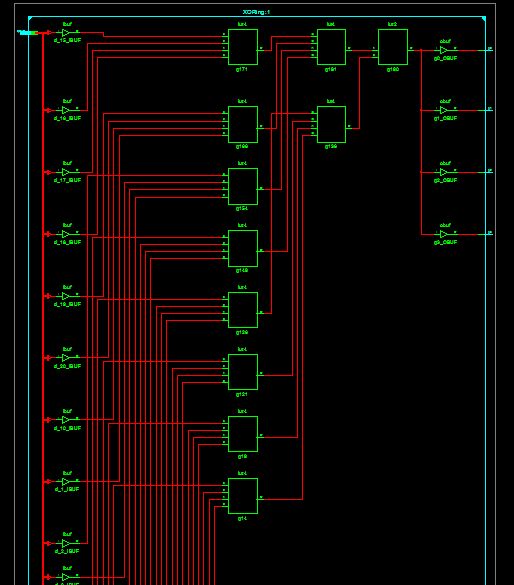
Sieh dir mal an, was der Synhtesizer draus macht. Ich würde sagen, dass
da bei einer 4er LUT immer 4 Eingänge zsammengefasst werden, und dann
immer 4 der Zwischenergebnisse wieder mit einer LUT. Schlussendlich
bleiben also 3 ziemlich direkt verdrahtete Logikebenen.
Mit der 6er LUT vom Virtex6/Spartan6 sind es sogar nur 2 Logikebenen...
Das parcbe passt sogar in 1 4er-LUT und kann effizienter gar nicht
dargestellt werden...
> par <= pardat xor parcbe;
Dafür wäre es allerdings u.U. besser, gleich alle beteiligten Signale in
einem Term zu verknüpfen...
Also so:
1 | par <= d(0) xor d(1) xor d(2) xor d(3) xor d(4) xor d(5) xor d(6)
|
2 | xor d(7) xor d(8) xor d(9) xor d(10) xor d(11) xor d(12) xor d(13)
|
3 | xor d(14) xor d(15) xor d(16) xor d(17) xor d(18) xor d(19)
|
4 | xor d(20) xor d(21) xor d(22) xor d(23) xor d(24) xor d(25)
|
5 | xor d(26) xor d(27) xor d(28) xor d(29) xor d(30) xor d(31)
|
6 | xor cbe_i(0) xor cbe_i(1) xor cbe_i(2) xor cbe_i(3);
|
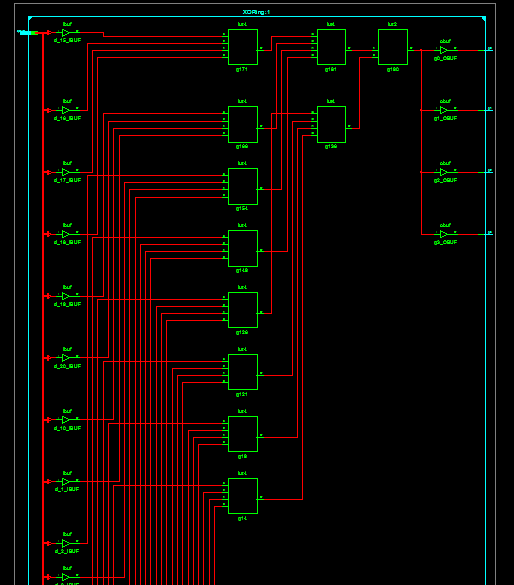
Aber es kann auch gut sein, dass der Synthesizer das selber merkt und ie
zusätzliche Logikebene rauslässt...
{kind=link}