Ich kämpfe mich schon seit geraumer Zeit mit diesem Problem ab (keine Hausaufgabe ;) privates Vergnügen) http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=24&page=show_problem&problem=2157 (Unter Umständen mit einem anderen Browser als Firefox öffnen, die Seite suckt ein wenig) Alle meine bisherigen Versuche endeten entweder mit "Time Limit Exceeded" (3 Sekunden) oder "Memory Limit Exceeded" (64MB) Meine bisher schnellste Lösung braucht für ein 30*30 Testfeld mit 200 Quellen (also der maximale Fall) ca. 4 Stunden Meine bisherigen Ansätze: - Erst Felder bewäsern die nur garantiert von einer Quelle versorgt werden können und das iterativ solange bis es keine solchen Felder mehr gibt - In den Ecken anfangen (da nur 2 Möglichkeiten) und mich nach innen vorarbeiten - Erst Felder bewässern die sehr nahe an einer Quelle liegen Vielleicht hat jemand von euch einen entscheidenden Hinweis wie man den Backtrackbaum sinnvoll prunen könnte oder eine Metrik mit der man zügig zu einer Lösung kommt. (Yalu for the rescue ;) )
kann man nicht so vorgehen, dass man die ergiebigsten quellen an das obere Ende packt und nur nach unten wässern lässt? dann versucht man die verbleibenden Felder in den Spalten mit den weniger ergiebigen so zu füllen, dass möglichst die Spalten voll werden. sollte es nicht passen, dann von unten zeilenweise füllen, das sich die Spaltenlänge veringert. wo gibts denn da die Inputfiles? das Problem sieht interessant aus. Ich glaub, das probier ich zuhause auch mal
Vlad Tepesch schrieb: > wo gibts denn da die Inputfiles? das is ne gute frage ;-) sieht in der tat interresant aus
Vlad Tepesch schrieb: > kann man nicht so vorgehen, dass man die ergiebigsten quellen an das > obere Ende packt und nur nach unten wässern lässt? die sind fest vorgegeben die position der quellen. > > dann versucht man die verbleibenden Felder in den Spalten mit den > weniger ergiebigen so zu füllen, dass möglichst die Spalten voll werden. > sollte es nicht passen, dann von unten zeilenweise füllen, das sich die > Spaltenlänge veringert. Geht eben nicht > > wo gibts denn da die Inputfiles? unten im Tab "Sample Input" findest du 2 Beispielfälle und 2 mögliche Ausgaben für den jeweiligen input. Die anderen Testfälle sind geheim. Aber ich habe dafür schonmal einen Testcasegenerator geschrieben, den kann ich mal rauskramen. Input / Output sind genau spezifiziert (Ein/Ausgabe erfolgt über stdin/stdout) und constrained. Bei dem Problem ist garantiert dass es zu jedem Testcase mindestens eine gültige Lösung gibt (steht in der Aufgabenstellung) und es reicht eine gültige zu finden. In einem File sind maximal 50 TCs, d.h. das schlimsmte was passieren kann ist: 50 Testcases * 30*30 Feldgröße * 200 Quellen, das muss dein Programm in 3 Sekunden können Wenn du dich auf der Seite anmeldest kannst du einen Lösungsvorschlag abgeben und bekommst als Antwort: Accepted (korrekt), Wrong Answer (falsche Antwort), Time Limit Exceeded (Programm zu langsam), Memory Limit Exceeded (Zuviel Speicher), oder Runtime Error (segfault, stack overflow oder sontige abstürze zur laufzeit) oder auch Compiler Error mit der entsprechenden compiler fehler meldung. Achte darauf falls du ein Programm abgibst dass es sich mit exit(0) beendet. Falls dus mit Java löst muss die Klasse "Main" heißen also
1 | public class Main {}
|
> das Problem sieht interessant aus. > Ich glaub, das probier ich zuhause auch mal Viel Glück bzw Erfolg, ich hadere schon einige Zeit, im Moment die einzige Aufgabe in meiner Liste mit "tried but not solved"
D. I. schrieb: > Meine bisherigen Ansätze: > > - Erst Felder bewäsern die nur garantiert von einer Quelle versorgt > werden können und das iterativ solange bis es keine solchen Felder mehr > gibt > > - In den Ecken anfangen (da nur 2 Möglichkeiten) und mich nach innen > vorarbeiten Das lässt sich noch verallgemeinern, indem du in jedem "Zug" immer das Feld betrachtest, das von den wenigsten Quellen erreichbar ist und für dieses Feld dann alle möglichen Quellen durchspielst. Dadurch verzweigt sich der Suchbaum nicht so stark. Ob das allerdings schon reicht, um die Rechenzeit von 4h auf 3s zu reduzieren, weiß ich nicht :) D. I. schrieb: > In einem File sind maximal 50 TCs, d.h. das schlimsmte was passieren > kann ist: 50 Testcases * 30*30 Feldgröße * 200 Quellen, das muss dein > Programm in 3 Sekunden können Weiß man, ob die Testfälle für jeden User bzw. Versuch neugeneriert werden, oder sind sie immer gleich? Hoffentlich doch letzteres. Und sehe ich das richtig: Wenn dein Programm das Zeitlimit überschrei- tet, hast du keinerlei Information darüber, wie knapp du die Latte gerissen hast, weil du ja die Testfälle nicht kennst und somit diese nicht auf deinem eigenen PC laufen lassen kannst. In deinem Beispiel von oben könnte es also passieren, dass dein Programm 50·4h = 200h benötigt. Du müsstest es also um den Faktor 2.4E5 beschleu- nigen, was u.U. ein völlig anderes Lösungskonzept erfordert. Es könnte aber auch sein, dass die Testfälle so leicht sind, dass dir nur ein paar Millisekunden zum Erfolg fehlen. In diesem Fall würden schon ein paar lokale Optimierungen zum Ziel führen. Ich habe übers Wochenende leider wenig Zeit, um selbst einen Versuch zu starten, es sei denn, mir fällt eine 20-Zeilenlösung ein. Aber auf der Webseite habe ich mich schon einmal angemeldet ;-) PS: Danke für deine PM.
D. I. schrieb: > Vlad Tepesch schrieb: >> kann man nicht so vorgehen, dass man die ergiebigsten quellen an das >> obere Ende packt und nur nach unten wässern lässt? > > die sind fest vorgegeben die position der quellen. oh, stimmt. sonst wärs ja zu einfach ;) D. I. schrieb: > Bei dem Problem ist garantiert dass es zu > jedem Testcase mindestens eine gültige Lösung gibt (steht in der > Aufgabenstellung) und es reicht eine gültige zu finden. das kann ich nirgends rauslesen. Es steht lediglich da, dass die Kapazität der Wasserquellen ausreicht um alle Felder zu bewässern. Ob das heißt, dass es auch eine gültige Lösung gibt, wäre zu beweisen. Poste mal den Generator. wie lange brauch der denn zur Generierung einer Aufgabe? Er muss doch auch testen, ob sie lösbar ist. d.h. der Generator kann nur maximal so gut sein, wie dein bisheriger Lösungsansatz.
Project Euler ist auch sowas in der Art
Vlad Tepesch schrieb: > das kann ich nirgends rauslesen. > Es steht lediglich da, dass die Kapazität der Wasserquellen ausreicht um > alle Felder zu bewässern. > Ob das heißt, dass es auch eine gültige Lösung gibt, wäre zu beweisen. in der output specification steht das Yalu X. schrieb: > Weiß man, ob die Testfälle für jeden User bzw. Versuch neugeneriert > werden, oder sind sie immer gleich? Hoffentlich doch letzteres. immer dieselben cases Yalu X. schrieb: > Und sehe ich das richtig: Wenn dein Programm das Zeitlimit überschrei- > tet, hast du keinerlei Information darüber, wie knapp du die Latte > gerissen hast, weil du ja die Testfälle nicht kennst und somit diese > nicht auf deinem eigenen PC laufen lassen kannst. richtig, es kann sich um ein paar millisekunden handeln oder aber auch um Stunden (sonst könnte der judge bei endlosschleifen ja ewig laufen, ...) Yalu X. schrieb: > In deinem Beispiel von oben könnte es also passieren, dass dein Programm > 50·4h = 200h benötigt. Du müsstest es also um den Faktor 2.4E5 beschleu- > nigen, was u.U. ein völlig anderes Lösungskonzept erfordert. so ist es, aber da es schon ein paar leute sehr schnell gelöst haben muss eine relativ gute Strategie existieren Yalu X. schrieb: > Das lässt sich noch verallgemeinern, indem du in jedem "Zug" immer das > Feld betrachtest, das von den wenigsten Quellen erreichbar ist und für > dieses Feld dann alle möglichen Quellen durchspielst. Dadurch verzweigt > sich der Suchbaum nicht so stark. Ob das allerdings schon reicht, um die > Rechenzeit von 4h auf 3s zu reduzieren, weiß ich nicht :) reicht nicht ;) genau das mache ich schon Yalu X. schrieb: > Es könnte aber auch sein, dass die Testfälle so leicht sind, dass dir > nur ein paar Millisekunden zum Erfolg fehlen. In diesem Fall würden > schon ein paar lokale Optimierungen zum Ziel führen. Aus Erfahrung mit ICPC weiß ich, dass die Testcases meist sehr gut gestaltet und breit gefächert sind, so dass solche Lücken meist sehr unwahrscheinlich sind. Dazu kommt noch nur weil man ein TLE hat heißt das noch lang nicht dass das Programm trotzdem richtig geantwortet hätte ;) TLE überwiegt WA Vlad Tepesch schrieb: > Poste mal den Generator. > wie lange brauch der denn zur Generierung einer Aufgabe? Er muss doch > auch testen, ob sie lösbar ist. d.h. der Generator kann nur maximal so > gut sein, wie dein bisheriger Lösungsansatz. Sobald ich ihn wieder gefunden habe, gerne. Nein einen funktionierenden Testcase zu bauen ist nicht schwer, den ersten 30*30 habe ich sogar per Hand gebaut
Vlad Tepesch schrieb: > Project Euler ist auch sowas in der Art jo, aber da sind mir die Probleme zu leicht mit relativ trivialen Ansätzen lösbar
Vlad Tepesch schrieb: > Es steht lediglich da, dass die Kapazität der Wasserquellen ausreicht um > alle Felder zu bewässern. > Ob das heißt, dass es auch eine gültige Lösung gibt, wäre zu beweisen. hier nochmal: It is guaranteed that at least one solution exists. Print a blank line after each test case. Das heißt die TCs sind so gestaltet dass das erfüllt wird
D. I. schrieb: > hier nochmal: > > It is guaranteed that at least one solution exists. Print a blank line > after each test case. > > Das heißt die TCs sind so gestaltet dass das erfüllt wird ja, nach deinem ersten Hinweis hab ichs gesehen. hatte mir Output nicht so genau durchgelesen. so eine Aussagen hätte ich auch eher unter Input erwartet ;) D. I. schrieb: > Vlad Tepesch schrieb: >> Project Euler ist auch sowas in der Art > > jo, aber da sind mir die Probleme zu leicht mit relativ trivialen > Ansätzen lösbar Angeber ;) da finde ich besser, dass man die Lösung direkt postet. dH, man ist frei in der Wahl der Mittel und kann das nehmen, was einem Gerade am einfachsten vorkommt. Octave, perl, zettel, c,... und man muss sich nicht mit dem Parsen des Inputs abquälen. Hab ich das richtig verstanden, dass du allen anderen Probleme da gelöst hast? wie viel sind das? 10000? wie lange machst du das schon?
D. I. schrieb: > Vlad Tepesch schrieb: >> Project Euler ist auch sowas in der Art > > jo, aber da sind mir die Probleme zu leicht mit relativ trivialen > Ansätzen lösbar Schön wärs... Ich hab gerade mal 49 Stück geschafft und ziemlich oft Brute-Force. :-(
Zum prunen solltest Du noch schauen ob es Felder gibt, die garnicht bewässert werden können (weil der Weg abgeschnitten ist). Ich würde mir im ersten Anlauf merken welches für jedes Feld potentielle Bewässerungsquellen sind. Das mit den Ecken ist zu eng gedacht, wie Yalu schon schrieb. Fang mit den Feldern an die am wenigsten potentielle bewässerungsfelder haben, das ändert sich evtl. nach jeder Entscheidung. Eine Information die Du noch garnicht benutztst ist das das wasser gerade aufgeht, was auch bedeutet, daß jede quelle genau ihre kapazität auschöpft. Wenn du also eine Quelle so verbaust, daß sie ihre Kapazität nicht ausschöpfen kann, kannst du die lösung wegwerfen. Zuletzt solltest du noch darüber nachdenken, daß Dein Backtracking-Baum wahrscheinlich ganze teilbäume mehrmals bearbeitet, weil es mehrere Wege zu einer Teillösung gibt. Viel Erfolg
D. I. schrieb: > Sobald ich ihn wieder gefunden habe, gerne. Nein einen funktionierenden > Testcase zu bauen ist nicht schwer, den ersten 30*30 habe ich sogar per > Hand gebaut Vielleicht kannst du ja mal einen nichttrivialen "Referenz"-Testcase posten, bspw. den, der bisher die 4h benötigt hat. Das Beispiel in der Aufgabenstellung ist viel zu leicht, weil man mit deiner oben beschriebenen Vorgehensweise ganz ohne Backtracking zum Ziel kommt. Ich befürchte aber, dass wenn ich mir irgendwie selber ein 30×30-Beispiel zusammenbastle, dass dieses ebenfalls zu leicht wird.
Ich möchte noch die Möglichkeit vorschlagen, das ganze als Maximum Matching in einem bipartiten Graphen zu formulieren, in etwa so: Menge A sind alle Felder, die keine Quellen sind. Menge B enthält alle Quellen, jeweils so oft, wie diese andere Felder bewässern können. Kanten: Von jedem Feld in A aus zu jedem Vertreter der Quellen in B, von der aus das Feld bewässert werden könnte (also gleiche Zeile, Spalte, genügende Reichweite). Die Eigenschaft der Testcases, dass es eine genau passende Lösung gibt garantiert dann, dass es ein perfektes Matching gibt. Das ganze hätte den Vorteil, dass sich Matchings effizient berechnen lassen. Allerdings wäre nicht garantiert, dass dabei keine "abgeschnittenen" Felder erzeugt werden. Ich bin nicht sicher, ob oder wie das entsprechend modifiziert werden könnte, möchte das aber mal als Ansatz vorstellen.
Vlad Tepesch schrieb: > Angeber ;) > da finde ich besser, dass man die Lösung direkt postet. > dH, man ist frei in der Wahl der Mittel und kann das nehmen, was einem > Gerade am einfachsten vorkommt. Octave, perl, zettel, c,... > und man muss sich nicht mit dem Parsen des Inputs abquälen. Das ist in der Tat ein Vorteil, aber auch das parsen von kack input trainiert die eigenen Programmierfähigkeiten ;) > > Hab ich das richtig verstanden, dass du allen anderen Probleme da gelöst > hast? wie viel sind das? 10000? wie lange machst du das schon? Nein da hast du mich missverstanden. Das ist bisher das einzige Problem welches "tried but not solved" ist. Ich habe auf der Plattform bisher ca. 150 Probleme gelöst (jenachdem wie ich Zeit und Lust habe), aber das ist das einzige was ich noch nicht lösen konnte. Die anderen 1800 Probleme habe ich noch garnicht erst angesehen oder versucht ;) xpler schrieb: > Schön wärs... Ich hab gerade mal 49 Stück geschafft und ziemlich oft > Brute-Force. :-( Genau das meinte ich, ca 80% der Probleme die ich dort bisher gelöst habe, gingen mit Brute-Force und das hat mich dann gelangweilt, weil ich wiederrum nicht den sprtlichen Ehrgeiz besitze ein gelöstes Problem eleganter zu lösen auch wenn der Lerneffekt wohl gegeben wäre.
Hans Mayer schrieb: > Zum prunen solltest Du noch schauen ob es Felder gibt, die garnicht > bewässert werden können (weil der Weg abgeschnitten ist). > > > Ich würde mir im ersten Anlauf merken welches für jedes Feld potentielle > Bewässerungsquellen sind. Das mache ich schon Hans Mayer schrieb: > Eine Information die Du noch garnicht benutztst ist das das wasser > gerade aufgeht, was auch bedeutet, daß jede quelle genau ihre kapazität > auschöpft. Wenn du also eine Quelle so verbaust, daß sie ihre Kapazität > nicht ausschöpfen kann, kannst du die lösung wegwerfen. Daran habe ich allerdings noch nicht gedacht! Thorsten schrieb: > Die Eigenschaft der Testcases, dass es eine genau passende Lösung gibt > garantiert dann, dass es ein perfektes Matching gibt. Es gibt mindestens eine Lösung > > Das ganze hätte den Vorteil, dass sich Matchings effizient berechnen > lassen. > Allerdings wäre nicht garantiert, dass dabei keine "abgeschnittenen" > Felder erzeugt werden. Die Idee hatte ich auch schonmal, bin aber daran gescheitert zu formulieren wie man sicher geht, dass sich die Wasseradern nicht überkreuzen Yalu X. schrieb: > Vielleicht kannst du ja mal einen nichttrivialen "Referenz"-Testcase > posten, bspw. den, der bisher die 4h benötigt hat. Das Beispiel in der > Aufgabenstellung ist viel zu leicht, weil man mit deiner oben > beschriebenen Vorgehensweise ganz ohne Backtracking zum Ziel kommt. Ich > befürchte aber, dass wenn ich mir irgendwie selber ein 30×30-Beispiel > zusammenbastle, dass dieses ebenfalls zu leicht wird. Ich reimplementiere gerade meinen Testcasegenerator mit dem ich so ein Beispiel gezimmert habe und stelle ihn dann heut im Laufe des Abends noch online.
Hier ein erster sehr einfacher Quick&Dirty Testcase Generator. Später oder morgen stelle ich noch einen ausgefeilteren online
ich will erst mal ein einfacheres Problem probieren. was mir allerdings nciht klar ist: woher weiß ich, wann ich aufhören muss, die Eingabe zu lesen? zB beim ersten Problem (http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=3&page=show_problem&problem=36) - ja ich weiß, das ist nur eine Fingerübung: da steht nur, man bekommt eine Reihe von Paaren. da steht nicht wie viel, oder was eine Abbruchbedingung ist. Gibts irgendwo genauere Infos zu den Anforderungen an die Programme? Ich hab nix gefunden.
Vlad Tepesch schrieb: > ich will erst mal ein einfacheres Problem probieren. Freut mich, dass du gefallen gefunden hast :) Unser Topteam ist aktuell auf den World Finals die am Montag stattfinden in Florida: http://cm.baylor.edu/welcome.icpc Das ist übrigens das Problemset aus dem letzten Jahr World Finals: http://cm.baylor.edu/ICPCWiki/attach/Problem%20Resources/2010WorldFinalProblemSet.pdf wer sich dran versuchen will: http://livearchive.onlinejudge.org/ > > was mir allerdings nciht klar ist: > woher weiß ich, wann ich aufhören muss, die Eingabe zu lesen? da helfe ich dir gerne weiter: Wenn nichts weiter spezifiziert ist liest du genau soviel ein wie du für einen Testcase brauchst. Zum Beispiel:
1 | int i,j; |
2 | while (cin >> i >> j) |
3 | {
|
4 | //gebe lösung aus |
5 | } |
6 | exit(0); |
oder in java
1 | Scanner s = new Scanner(System.in); |
2 | while (s.hasNextInt()) |
3 | {
|
4 | int i = s.nextInt(), j = s.nextInt(); |
5 | } |
> > zB beim ersten Problem > (http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=3&page=show_problem&problem=36) > - ja ich weiß, das ist nur eine Fingerübung: Vertu dich da mal nicht :) Glaubt man und man bekommt als erstes eine WA reingedrückt. Ich gebe dir den Tipp: lies die Aufgabenstellung 100% genau ;) bzgl. ein und ausgabe. Hin und wieder sind da mal ein paar Spitzen versteckt. > da steht nur, man bekommt eine Reihe von Paaren. da steht nicht wie > viel, oder was eine Abbruchbedingung ist. > > Gibts irgendwo genauere Infos zu den Anforderungen an die Programme? Ich > hab nix gefunden. Die Zeitanforderung steht beim Problem dabei. Speicher standardmäßig 64MB Hier ist das offizielle Forum dazu: http://online-judge.uva.es/board/ dort ist auch eine Abteilung HOWTO http://online-judge.uva.es/board/viewforum.php?f=31&sid=38dc4a84a5000ea41f28e00d539169f8 Hier habe ich auch mal eine kurze Einführung verfasst: https://fsi.informatik.uni-erlangen.de/forum/thread/5823-HowTo-ICPC-Vorbereitung und das sollte man auch nicht missen: http://www.uvatoolkit.com/ http://www.acmsolver.org/
D. I. schrieb: > da helfe ich dir gerne weiter: Wenn nichts weiter spezifiziert ist liest > du genau soviel ein wie du für einen Testcase brauchst. Zum Beispiel: danke. Ich schreib so selten interaktive Kommandozeilenprogramme. mir war bisher nicht klar, wie das mit der Eingabe und der Umlenkung funktioniert, dass man auch das Ende mitbekommt. das Problem selbst ist ja nicht so schwer. der 2. submit hat auch gleich funktioniert. der 1. hatte ein Problem mit der Eingabe. Nur die Zeit war nicht so prickelnd, da ich die einfachste rekursive Implementierung abgeliefert hatte. Was heißt denn das SE in der Statistik? die anderen sind ja in dem How-To erklärt
Vlad Tepesch schrieb: > Was heißt denn das SE in der Statistik? die anderen sind ja in dem > How-To erklärt SE, als Abkürzung für einen Error-Code wie WA oder TLE? Keine Ahnung ist mir bisher noch nie untergekommen und habe ich davor auch noch nicht gehört. Ah gerade entdeckt: Submission Error - das bedeutet dass man versucht eine Lösung zu einem Problem zu schicken ohne das man angemeldet ist oder zu einer invaliden Problem ID http://online-judge.uva.es/board/viewtopic.php?t=7430
Heute finden übrigens die ACM ICPC World Finals statt. Das ganze Spektakel lässt sich live ab 15 Uhr hier abgreifen: http://cm.baylor.edu/digital/digital.html
Deutschland - vertreten durch unsere Uni - hat sich auf einen soliden 7. Platz gecoded und damit eine Silbermedaille verdient. Hier das final Scoreboard: http://www.icpclive.com/?page=live333 Die diesjährigen Probleme werden wohl die nächsten Tage online kommen.
Die aufgaben sind sogar schon online: http://livearchive.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=45
beeindruckend. wie kann man denn in 27min die Aufgabe C lösen? selbst 1,5h sind beeindruckend. darf man da zusätzliche Bibliotheken nutzen? die Objekte sind schließlich noch scaliert, rotiert oder gar verformt Die Objekte zu segmentieren ist ja noch einfach. Aber schon das Finden von rotations- und salierungs-invarianten Merkmalen ... Gab es denn da die Trainingsbilder wenigstens schon als Bitmap? oder wenigstens ein kompletter Testcase? oder interpretiere ich da was mit den Zeiten falsch? 2:27 bedeutet doch 2 Versuche und 27min, oder? Die gesamtzeit wirkt auch unplausibel. zB 1462min des 2.plazierten. sind das mehrere Tage gewesen, oder wurde da tatsächlich ein kompletter Tag durchgemacht. Arbeitet man da zusammen oder schnappt sich jeder ein Problem
http://icpc.baylor.edu/icpc/finals/about.htm 3er teams The total time is the sum of the time consumed for each problem solved. The time consumed for a solved problem is the time elapsed from the beginning of the contest to the submittal of the first accepted run plus 20 penalty minutes for every previously rejected run for that problem. There is no time consumed for a problem that is not solved. The World Finals programming language tools include Java, and C/C++. See the Programming Environment Web Site, for detailed configuration information. Prior to the World Finals, the judges will have solved all problems in Java and C/C++. Each team will be provided with a single computer and a calculator. All teams will have equivalent computing equipment. Contestants may not bring any printed materials or machine-readable versions of software or data to the Contest Area. Contestants may not bring their own computers, computer terminals, calculators, or other electronic devices to the Contest Area. Each team member may bring an unannotated natural language dictionary. On-line reference materials will be made available as described at the Reference Materials Web Site. Each team will be permitted to provide a PDF file of up to 25 pages of notes within the limits described at the Team Certification Web Site. Details are provided at On-Site Registration Instructions.
Vlad Tepesch schrieb: > beeindruckend. > > wie kann man denn in 27min die Aufgabe C lösen? > selbst 1,5h sind beeindruckend. > darf man da zusätzliche Bibliotheken nutzen? nein, nur das was c++/java von haus aus mitbringt und natürlich das 25seitige DINA4 Notebook was sich jedes Team ausgedruckt mitnehmen darf, auf dem dann üblicherweise Snippets für Standardalgorithmen stehen. Ich finde 11 Minuten für Aufgabe K (die da wohl der NoBrainer war) schon sportlich, aber 27 Minuten für die C ist schon Hammer. Aber "so schwer" im Vergleich zu den anderen kann sie nicht sein, da die neben der K die meistgelöste war. Aber ich werde mal meinen Kumpel fragen wie die geht :D > > die Objekte sind schließlich noch scaliert, rotiert oder gar verformt > > Die Objekte zu segmentieren ist ja noch einfach. > Aber schon das Finden von rotations- und salierungs-invarianten > Merkmalen ... > > Gab es denn da die Trainingsbilder wenigstens schon als Bitmap? > oder wenigstens ein kompletter Testcase? Ich denke die kompletten Testcases kommen, wenn die Statements nicht nur in PDF Form vorliegen sondern dann auch regulär ins System gespeist wurden, was immer ca. 1-2 Wochen dauert. > > oder interpretiere ich da was mit den Zeiten falsch? > 2:27 bedeutet doch 2 Versuche und 27min, oder? Das ist richtig interpretiert. Das bedeutet dass der 2. Versuch zu Minute 27 korrekt angenommen wurde. > Die gesamtzeit wirkt auch unplausibel. zB 1462min des 2.plazierten. > sind das mehrere Tage gewesen, oder wurde da tatsächlich ein kompletter > Tag durchgemacht. Der Kollege hat ja schon erklärt wie das mit den Zeiten funktioniert. Für jedes gelöste Problem wird der Zeitpunkt des Accepted auf das Zeitkonto addiert, +20 Minuten für jede Fehlabgabe. Die Contestzeit betrug übrigens 5 Stunden für 11 Probleme > > Arbeitet man da zusammen oder schnappt sich jeder ein Problem Üblicherweise teilt man die Probleme je nach Stärken und Schwächen in den einzelnen Bereichen auf
Vlad Tepesch schrieb: > Gab es denn da die Trainingsbilder wenigstens schon als Bitmap? > oder wenigstens ein kompletter Testcase? Ach jetzt habe ich die Frage richtig verstanden. Vor Ort im Contest hat man die Sample Input/Outouts die auf den Ausdrucken stehen auch als Textdatei vorliegen, damit man das nicht mühsam aptippen muss, was bei Aufgabe C sicherlich keinen Spaß gemacht hätte :D .
D. I. schrieb: > Für jedes gelöste Problem wird der Zeitpunkt des Accepted auf das > Zeitkonto addiert, +20 Minuten für jede Fehlabgabe. Das kann so nicht sein. Bei der Friedrich-Alexander-Universität steht: time 1088 [Minuten] Addiert man die Aufgaben kommt man auf 1228 [Minuten] (1+1+1+3+1+6+1)*20 + (210+94+57+119+288+159+21) = 1228
Alexander Schmidt schrieb: > D. I. schrieb: >> Für jedes gelöste Problem wird der Zeitpunkt des Accepted auf das >> Zeitkonto addiert, +20 Minuten für jede Fehlabgabe. > > Das kann so nicht sein. > Bei der Friedrich-Alexander-Universität steht: time 1088 [Minuten] > Addiert man die Aufgaben kommt man auf 1228 [Minuten] > (1+1+1+3+1+6+1)*20 + (210+94+57+119+288+159+21) = 1228 Du weißt das 1 bedeutet auf dem ersten Versuch gelöst, also keine Fehlabgabe? Ziehe also mal von jedem 1 ab, was bei 7 Stück 140 Minuten entsprecht, so kommt man von deinen 1228-140 auf die 1088 angegebenen ;)
Vlad Tepesch schrieb: > wie kann man denn in 27min die Aufgabe C lösen? Jetzt fällt es mir wie Schuppen von den Augen: - Alle Figuren besitzen eine unterschiedliche Anzahl an inneren weißen Flächen (0 - 5) - Außenbereich mit FloodFill mit einer anderen Farbe als Schwarz füllen - Innerhalb der schwarzen Umrandungen die übriggebliebenen weißen Flächen zählen Fertig ist die Laube, jetzt muss mans nur noch programmieren, was ich definitiv nicht in 27 Min gekonnt hätte :D
>FloodFill
FloodFill ist schon ein Backtracking. Wer keinen Backtracking hinkriegt
ist fehl am Platz.
Sept Oschi schrieb: >>FloodFill > > FloodFill ist schon ein Backtracking. Wer keinen Backtracking hinkriegt > ist fehl am Platz. Blödsinn, Floodfill ist eine einfache Breitensuche, niemals wird ein Schritt zurückgenommen.
Floodfill sucht ein zusammenhaengendes Gebiet. Das macht man mit einem Backtracking, womit denn sonst ?
Floodfill sucht nicht sondern füllt einfach ale adjazenten Felder der gleichen Farbe. Das kann man iterativ oder rekursiv machen, aber kein zurücknehmen von Schritten -> kein Backtracking, wer das nicht versteht ist fehl am Platz. :-P
Was man am betreffenden Punkt macht ist nicht wirklich wichtig. Ob man
nur ein Ziel sucht, den schnellsten Weg zum Ziel, oder nur alles
abklappern will ist Einerlei. Der Standardansatz ist :
MachDenPunkt(x,y)
{
ist das Ziel ereicht, resp geht's weiter ?
Falls ja :
falls moeglich() MachDenPunkt(x+1,y);
falls moeglich() MachDenPunkt(x-1,y);
falls moeglich() MachDenPunkt(x,y+1);
falls moeglich() MachDenPunkt(x,y-1);
}
Den Rest muss man sich jeweils ueberlegen und anpassen. Auch ob wie der
Rueckgabewert auschaut. Und was man damit macht.
Das ist der Standardansatz für Rekursion, Backtracking geht so:
Funktion FindeLoesung (Stufe, Vektor)
1. wiederhole, solange es noch neue Teil-Lösungsschritte gibt:
a) wähle einen neuen Teil-Lösungsschritt;
b) falls Wahl gültig ist:
I) erweitere Vektor um Wahl;
II) falls Vektor vollständig ist, return true; // Lösung
gefunden!
sonst:
falls (FindeLoesung(Stufe+1, Vektor)) return
true; // Lösung!
sonst mache Wahl rückgängig; // Sackgasse
(Backtracking)!
2. Da es keinen neuen Teil-Lösungsschritt gibt: return false // Keine
Lösung!
aus
http://de.wikipedia.org/wiki/Backtracking
Nachdem ihr ja euch perfekt mit Backtracking auszukennen scheint, habt ihr sicher auch schon das Eingangsproblem gelöst? :D
Nee, hab leider grad zuviel andere Projekte, aber was machen Deine Versuche? Konntest du herausfinden warum manche Eingaben so schwer zu lösen sind?
Hans Mayer schrieb: > Nee, hab leider grad zuviel andere Projekte, aber was machen Deine > Versuche? > Konntest du herausfinden warum manche Eingaben so schwer zu lösen sind? Es geht nun etwas fixer, nur noch nicht fix genug ;) der Baum ist einfach noch zu groß. Ich denke zur Zeit über den Max-Matching Ansatz nach, wie man den Graph entsprechend zur Laufzeit ändern könnte
Ich denke nicht daß das max matching Dir hilft, es ist ja nur eine andere Formulierung des gleichen Problems, in der die Pruning-bedingungen unklarer sind. Der Hopcroft–Karp algorithm arbeitet mit augmenting paths und ich vermute(habs nicht richtig überprüft), daß da letztlich eine Unabhängikeitsannahme drinsteckt (also daß ein Teilmatching den Rest des Matchingproblems nicht ändert). Das ist bei dir aber gerade nicht erfüllt. Wenn du die Standardalgorithmen also nicht nutzen kannst wirst Du am Ende doch wieder Backtracking machen, nur auf einer komplizierteren Formulierung. Auf der anderen Seite gibt es bei dem Problem aber sicher unabhängig Lösbare Teilaufgaben, für die man sich etwas schlaues überlegen könnte. Mein Verdacht geht aber dahin daß Du die Fälle bei denen das ginge sowieso schnell lösen kannst und das schwierige die Fälle sind, bei denen alles von allem abhängt.
Hans Mayer schrieb: > Ich denke nicht daß das max matching Dir hilft, > es ist ja nur eine andere Formulierung des gleichen Problems, in der die > Pruning-bedingungen unklarer sind. > > Der Hopcroft–Karp algorithm arbeitet mit augmenting paths und ich > vermute(habs nicht richtig überprüft), daß da letztlich eine > Unabhängikeitsannahme drinsteckt (also daß ein Teilmatching den Rest des > Matchingproblems nicht ändert). Das ist bei dir aber gerade nicht > erfüllt. Nun es gibt ja noch mehr Algorithmen. Richtig das ist das initiale Problem, dass die Bedingungen den Graphen zur Laufzeit ändern. Ich bin gerade dabei auszuprobieren wie das performed: > > Wenn du die Standardalgorithmen also nicht nutzen kannst wirst Du am > Ende doch wieder Backtracking machen, nur auf einer komplizierteren > Formulierung. Richtig, es geht eben darum schnell zu bewerten ob die aktuelle Situation noch lösbar ist. Das ginge mit Matching, in dem ich mir angucke ob überhaupt noch ein maximales Matching erreichbar wäre in der aktuellen Konfiguration. > > Auf der anderen Seite gibt es bei dem Problem aber sicher unabhängig > Lösbare Teilaufgaben, für die man sich etwas schlaues überlegen könnte. > Mein Verdacht geht aber dahin daß Du die Fälle bei denen das ginge > sowieso schnell lösen kannst und das schwierige die Fälle sind, bei > denen alles von allem abhängt. Jo mal sehen wie ich weiter komme :) Leider noch soviel andere Sachen zu tun :(
Ich habe heute mal was in Python hingerotzt. Der Code ist aufgebläht und überhaupt nicht schön anzuschauen, aber er liefert Lösungen, zumindest für die Testfälle, mit denen ich ihn bisher gefüttert habe :) Ein 30×30-Problem braucht durchschnittlich 3s. Wenn der Geschwindig- keitsfaktor zwischen C und Python größer ist als die Anzahl der im Online-Judge zu lösenden Einzel-Probleme, und wenn meine Testfälle halbwegs repräsentativ sind, sollte es möglich sein, in die Wertung zu kommen. Ich werde das Programm morgen in C oder C++ umschreiben und submitten. Falls es angenommen wird, werde ich die dahintersteckenden Ideen hier verraten.
Yalu X. schrieb: > Ich habe heute mal was in Python hingerotzt. Der Code ist aufgebläht und > überhaupt nicht schön anzuschauen, aber er liefert Lösungen, zumindest > für die Testfälle, mit denen ich ihn bisher gefüttert habe :) > > Ein 30×30-Problem braucht durchschnittlich 3s. Wenn der Geschwindig- > keitsfaktor zwischen C und Python größer ist als die Anzahl der im > Online-Judge zu lösenden Einzel-Probleme, und wenn meine Testfälle > halbwegs repräsentativ sind, sollte es möglich sein, in die Wertung > zu kommen. > > Ich werde das Programm morgen in C oder C++ umschreiben und submitten. > Falls es angenommen wird, werde ich die dahintersteckenden Ideen hier > verraten. Ich bin gespannt, ich hab noch nichts nennenswertes
D. I. schrieb: > Ich bin gespannt, ich hab noch nichts nennenswertes Du hast dir doch nicht die Nacht bis heute Morgen um 04:03 vergeblich um die Ohren geschlagen? ;-) Ich habe heute um die Mittagszeit mein C-Programm in den Online Judge eingestellt. Seither hat es (zusammen mit Hunderten, wenn nicht Tausenden anderer Submissions) den Status "In judge queue". Da wird jetzt am Wochenende wohl nichts mehr repariert werden. Und nächste Woche wird es wohl erst einmal einen Tag dauern, bis alle aufgestauten Jobs abgearbeitet sind :-/ Ich habe in das Programm noch eine kleine Optimierung mit recht großer Wirkung eingebaut. Das Python-Programm ist damit etwa um den Faktor 7 schneller als vorher, so dass ein 30×30-Problem jetzt nur noch 0,4s dauert. Mit dem C-Programm sind es 5ms (3ms reine CPU-Zeit ohne I/O). Wenn man wollte, könnte man das Programm ohne grundlegende Änderungen im Algorithmus sicher noch um den Faktor 3 bis 10 schneller machen, da im Moment noch vieles umständlich und teilweise mehrfach berechnet wird. Erst einmal muss aber das jetzige Programm vom Judge akzeptiert werden. Nicht dass am Ende alles hinfällig ist, weil ich vielleicht die Aufgabe falsch verstanden habe ... ;-) Edit: Der Judge scheint wieder aufgewacht zu sein :) Gerade habe ich ein "Wrong answer" bekommen :( Jetzt muss ich erst einmal nachschauen, ob vielleicht nur das Ausgabeformat fehlerhaft ist oder doch noch mehr fehlt.
Yalu X. schrieb: > Edit: > Der Judge scheint wieder aufgewacht zu sein :) > Gerade habe ich ein "Wrong answer" bekommen :( Na das ist immerhin mehr, als ich bisher hatte :D Nein ich habe nicht bis 4:03 programmiert, da ging unser Gesellschaftsspieleabend gerade zu Ende :)
gratz yalu, gerade gesehen dass dus raus hast :) Dann kannste gleich mit dem Nachbarproblem "Jewel Magnetizer" oder "Airplane Scheduling" weitermachen :D Oder du machst dich ans World Finals Set ;)
Angehängte Dateien:
-

irrigation.png
14 KB
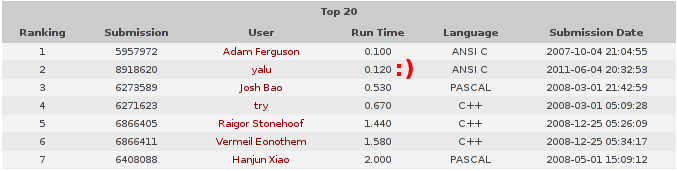
D. I. schrieb: > gratz yalu, gerade gesehen dass dus raus hast :) Danke! Da waren noch zwei hässliche Bugs im Programm, aber ich hatte gleich doppelt Glück, sonst hätte ich wahrscheinlich ewig danach gesucht: Nachdem das Programm Tausende von Testfällen fehlerfrei gelöst hat, gelang es mir durch Zufall, einen Testfall zu generieren, bei dem es versagte, so konnte ich den Fehler reproduzieren. Glücklicherweise waren die Bugs nur im C- nicht aber im Python-Programm. So konnte ich die Programme mit kilometerlangen Debugausgaben spicken und die Ausgaben mit Diff vergleichen, um den Fehler einzugrenzen. Mittlerweile hat auch der Judge seine Queue abgearbeitet, so dass die Prüfung jetzt wieder ohnen nennenswerte Zeitverzögerung möglich ist. Leider hat es nicht ganz für den ersten Platz gereicht ;-) Nun aber zum Backtracking: Jede Quelle Q_i hat sozusagen 4 Arme, über die sie ihr Wasser auf die umliegenden Felder verteilt. Die Summe der Längen dieser Arme ist durch die Kapazität c_i der Quelle gegeben. Der Algorithmus speichert zu jedem Arm einen Minimal- und einen Maximalwert. Anfangs sind die Minimalwerte alle 0 und die Maximalwerte c_i. Durch verschiedene Fakten und Ereignisse werden im Verlauf der Lösungs- suche die Minimalwerte vergößert und die Maximalwerte verkleinert. Wenn irgendwann für alle Arme die beiden Werte zusammenfallen, ist die Aufga- be gelöst. Der Algorithmus läuft folgendermaßen ab:
1 | 1. Initialisiere alle Minimal- und Maximalwerte |
2 | |
3 | 2. Korrigiere sie gemäß der Regeln A bis E (s.u.) |
4 | |
5 | 3. Erstelle eine Matrix, die für jedes Feld alle (0 bis 4) Quellen |
6 | enthält, die das Feld erreichen können. |
7 | |
8 | 4. Suche in der Matrix alle Felder, die von genau einer Quelle erreicht |
9 | werden können und halte sie als Teil der Lösung fest |
10 | |
11 | wenn es keine solchen Felder gibt fahre mit Schritt 7 fort |
12 | |
13 | 5. Aktualisiere alle Minimal- und Maximalwerte gemäß der Regeln B bis E |
14 | |
15 | 6. Fahre mit Schritt 3 fort |
16 | |
17 | 7. Gibt es nur mehrdeutige Felder, wähle ein Feld mit der minimalen |
18 | Anzahl von Möglichkeiten (2 bis 4) aus |
19 | |
20 | 8. Speichere die aktuellen Minimal- und Maximalwerte aller Quellen auf |
21 | dem Stack |
22 | |
23 | 7. Rufe den Algorithmus für jede dieser Möglichkeiten rekursiv bei |
24 | Schritt 3 auf, bis eine Lösung gefunden wurde, und lese nach jedem |
25 | erfolglosen Versuch die Minimal- und Maximalwert vom Stack zurück |
Die Minimal- und Maximalwerte werden nach folgenden Regeln modifiziert: Aktualisierung der Maximalwerte: A) Ein Arm kann maximal bis zur nächsten Quelle oder bis zum Rand des Landstücks reichen. Dieser Test wird nur einmal bei der Initialisierung durchgeführt. B) Ein Arm kann maximal bis zu einem Feld reichen, das bereits von einer anderen Quelle gespeist wird. C) Ein Arm kann höchstens die Länge c_i abzüglich der Summe der Minimal- werte der anderen drei Arme haben. Aktualisierung der Minimalwerte: D) Wird ein Feld einer bestimmten Quelle zugeordnet, wird der Minimal- wert des entsprechenden Arms so gesetzt, dass er bis zu diesem Feld reicht. Alle Felder zwischen der Quelle und diesem Feld gehören damit implizit ebenfalls zur Quelle. E) Ein Arm muss mindestens die Länge c_i abzüglich der Summe der Maxi- malwerte der anderen drei Arme haben. Durch die Aktualisierung der Minimalwerte entstehen implizit neue Beleg- ungen von Feldern, die weitere Aktualisierungen andere Werte nach sich ziehen. In Schritt 5 wird die Aktualisierung deswegen so lange fortge- führt, bis sich keine Änderungen mehr ergeben. Interessanterweise ist der Suchbaum, der durch diesen Algorithmus ent- steht, ist in den meisten Fällen nur ein dürrer Halm :) Eine Zeit lang dachte ich, man könnte vielleicht komplett auf das Back- tracking verzichten. Selbst wenn die Belegung des nächsten Felds in Schritt 7 mehrdeutig ist, führt in den allermeisten Fällen jede der Alternativen zum Ziel. Ich musste über 100 große (30×30) Testfälle generieren, bis einer dabei war, bei dem backgetrackt werden musste. In diesem Fall hatte der Baum aber nur eine einzige Verzweigung. Mittler- weile (nach Tausenden von Testfällen) habe ich auch welche mit zwei Verzweigungen gefunden, mehr aber nicht. Auch die Rekursionstiefe ist i.Allg. nicht sehr groß, da in der Schleife von Schritt 3 bis Schritt 6 innerhalb einer einzigen Rekursionsebene sehr viele, oft sogar alle Felder belegt werden. Eine der Schwierigkeiten bei der Lösung der Aufgabe lag deswegen darin, dass es nur mit viel Mühe gelang, halbwegs schwierige Testfälle zu generieren, mit denen das selten erforderliche Backtracking getestet werden konnte. Der letzte Fehler, der sich im C-Code versteckte, war genau so einer: Er trat erst in der zweiten Backtrackingebene auf, und dort auch nicht immer. > Dann kannste gleich mit dem Nachbarproblem "Jewel Magnetizer" oder > "Airplane Scheduling" weitermachen :D > > Oder du machst dich ans World Finals Set ;) Hmm, mal sehen. Aber sicher nicht mehr dieses Wochenende. Hab eigentlich noch ein paar andere Sachen vor ;-)
Angehängte Dateien:
-

irrigation.png
14 KB
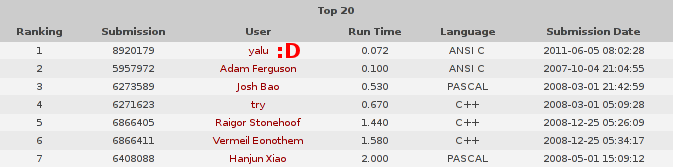
Mir ist gerade noch eingefallen, dass man an zwei Stellen im Code mit einer einfachen Abfrage in vielen Fällen eine Serie von komplizierteren Abfragen überspringen kann. Damit wäre die 100ms-Marke geknackt :)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.