Nachdem sich zig AVR-Basics hier tummeln, hab ich jetzt ubasic auf einem
uralt-8051 Board zum Laufen zu bekommen., Compiler ist sdcc.
Jetzt hab ich ein 16k grosses char array im externen RAM liegen, welches
das Basic Programm hält.
Nun möchte ich mir das Programm anhand der Zeilennummern sortieren
lassen. Freien Speicher im RAM hab ich noch ca. 1,5k.
Bisher hab ich einfach zwei 8k Arrays genommen, das erste durchforstet,
wenn die Zeilennummer gepasst, hat ins zweite geschrieben, ...
Eine Basic-Zeile sieht so aus:
10 PRINT "HELLO WORLD"
Das rausfischen einzelner Zeilen und das aufsplitten in Zeilennummer und
Befehl funktioniert einwandfrei.
Pseudocode:
Nun ist das ja nicht gerade schnell und vorallem verschwende ich extrem
RAM.
Gibts da eine Möglichkeit das mit den verbleibenden 1,5k RAM irgendwie
zu lösen? Ich überlege schon eine ganze Weile, aber komme auf nichts...
Quicksort ist wohl kaum geeignet, da die Rekursion ganz schön viel Platz
auf dem Stack frisst.
Bubblesort z.B. vergleicht immer nur 2 nebeneinander liegende Elemente
und vertauscht sie gegebenenfalls. Die Laufzeit ist aber im schlimmsten
Fall quadratisch.
Ja, es ist immer ein Tradeoff zwischen Laufzeit und Speicher. Das ist
wie Strom und Spannung ;-)
Bubblesort wäre jetzt auch mein Vorschlag gewesen. Ist auch leicht zu
implementieren.
Sortierer schrieb:> Bubblesort z.B. vergleicht immer nur 2 nebeneinander liegende Elemente> und vertauscht sie gegebenenfalls. Die Laufzeit ist aber im schlimmsten> Fall quadratisch.>
genau, wollte ich auch gerade bemerken...
Aber warum musst du eigentlich Zeilennummern sortieren?
Grüße Uwe
Jenachdem wie die Zeilennummern genau aussehen kannst du dir die
Eigenschaft des Schluessels zunutze machen um schneller zu sortiern -
zB. mit Bucketsort.
LG Stefan
Ich würde Direct-Insert verwenden, den kann man noch sehr einfach
Implementieren, und benötigt wenn man es sauber drauf anlegt nur 2-3
Indexe zusätzlich zu dem Array mit den Rohdaten
Simon K. schrieb:> Wenn ich das richtig sehe braucht Bucketsort von den genannten> Möglichkeiten hier den meisten Speicher ;-)>
korrekt --> im Gegensatz zu Bubblesort, dort wird genau nur einmal die
Größe eines Elementes (zum Swap) benötigt --> weniger geht nicht!
Aber nochmal die Frage, warum Basic-Zeilen sortieren...?
Grüße Uwe
> Aber warum musst du eigentlich Zeilennummern sortieren?
Für einen Zeilenorientierten Editor, fürs übergeben an den Interpreter
und zum Ausdrucken, soll alles standalone auf dem Controller laufen.
Ein Programm wird vom Interpreter Zeile für Zeile abgearbeitet, egal
welche Nummer sie hat.
Bubblesort sieht für mich am besten aus, da am wenigsten Aufwendig. Ich
lasse mir sämtliche Zeilennummern in ein Array schreiben (16bit, 1000
Mögliche Zeilen, Knapp 2k RAM). Dann ein char Array von einer maximalen
Zeilenlänge (256Byte) zum auslagern einer zu beschreibenden Zeile und
dann nach dem sortierten Array die Zeilen zusammensetzen.
Noch was anderes, was mir gerade kam...
Das Board hat 32k RAM drauf. 64k sind beim 8051 möglich. Ich habe noch
einen 32k RAM Chip hier. A15 vom Controller ist frei.
Kann ich den zweiten RAM Chip huckepack auf den ersten löten und A15
dann für den Chip-Enable verwenden?
Klappt das?
Das erste RAM liegt von 0x8000 bis 0xffff. Wenn ich das zweite jetzt
draufmache, wird da dann nicht beim Zugriff auf das Zweite das selbe ins
erste geschrieben bzw aus beiden gleichzeitig gelesen, wenn A15 als Chip
Enable dient?.
Wie wird sowas angeschlossen, wenn man statt einen 64k RAM zwei 32er
hat?
Hallo,
ich arbeite in einem solchem Fall in der Regel mit doppelverketten
Listen, braucht geringfügig mehr Speicher, ist aber extrem schnell. Da
ich in der Liste nur rückwärts laufen muss bis ich das Element gefunden
habe, dass den Vorgänger zu meinem aktuellen darstellt. Anschliessend
nur die Zeiger umhängen und an der Stelle weitermachen von wo ich das
Element geholt habe.
Rekursion oder wiederholtes Durchlaufen wie bei Bubblesort ist damit
nicht nötig.
Gruß
Frank
Ich würde, um Speicher zu sparen, die Zeilen selbst gar nicht sortieren,
sondern nur Pointer auf die Zeilen. So hast Du die Zeilen selbst nur
einmal im RAM.
Nachdem Du die Pointer auf die Zeilen sortiert hast (z.B. geht sowas
easy mit quicksort), kannst Du sie dann über Deine sortierte
Pointerliste auch sortiert ausgeben, interpretieren... oder was auch
immer.
Warum erst sortieren, wenn schon alle Zeilen durcheinander im Speicher
liegen? Warum nicht gleich an der richtigen Position einfügen, wenn Du
den Code in Deinem zeilenorientierten Editor eingibst oder editierst?
Murkser
Nils S. schrieb:> Das erste RAM liegt von 0x8000 bis 0xffff. Wenn ich das zweite jetzt> draufmache, wird da dann nicht beim Zugriff auf das Zweite das selbe ins> erste geschrieben bzw aus beiden gleichzeitig gelesen, wenn A15 als Chip> Enable dient?.> Wie wird sowas angeschlossen, wenn man statt einen 64k RAM zwei 32er> hat?
Wenn dann mußt Du A15 an das Chipenable beider Ramchips legen.
Invertiert an den originalen, nicht invertiert an den Huckepack.
Das mit Pointern hört sich auch gut an, allerdings will der Interpreter,
ein grosses in dem Format:
char bla[16384] = "10 PRINT 1+1\n 20 PRINT ...\n...\n";
aber den Interpreter könnte ich auch noch ein wenig umbiegen.
... schrieb:> Invertiert an den originalen, nicht invertiert an den Huckepack.
Bzw. umgekehrt. Spielt aber eigentlich keine Rolle, Hauptsache einmal
invertiert und einmal nicht.
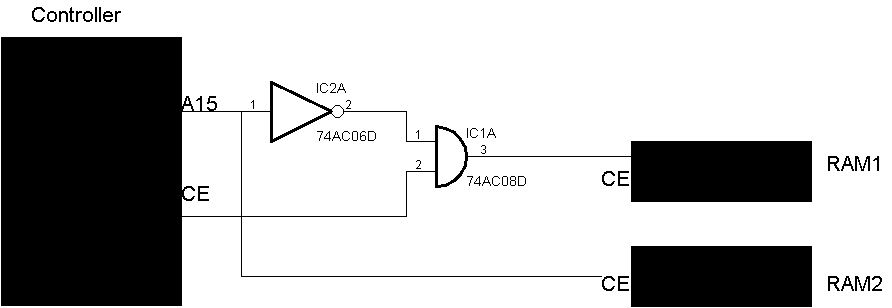
Also so wie im Anhang dann?
Das AND weil ich den originalen CHIP Enable ja mitbenutzen muss, oder
lass ich den und das AND dann weg? Oder muss ich den Originalen Chip
Enable für beide zusammen nehmen?
Nils S. schrieb:> Wie wird sowas angeschlossen, wenn man statt einen 64k RAM zwei 32er> hat?>Kann ich den zweiten RAM Chip huckepack auf den ersten löten und A15>dann für den Chip-Enable verwenden?
Nein.
A15 einmal direkt, einmal invertiert und dann jeweils mit dem normalen
/CE auf ein ODER-Gatter und von da auf die /CE vom RAM.
Sonst ist einer der beiden Chips immer Enabled und blockiert den
Adress/Datenbus.
mfg.
>/CE auf ein ODER-Gatter und von da auf die /CE vom RAM.
Aber wieso oder? Ich hab doch nur ein /CE auf dem Board. So müsste ich
dann einfach beide /CE zusammenlöten?
Komm grad nicht ganz mit...
Nils S. schrieb:> Das mit Pointern hört sich auch gut an, allerdings will der Interpreter,> ein grosses in dem Format:> char bla[16384] = "10 PRINT 1+1\n 20 PRINT ...\n...\n";> aber den Interpreter könnte ich auch noch ein wenig umbiegen.
Hm, das hört sich nicht sehr performant an, wenn es um "goto xyz" geht.
Bei einer Pointerliste, die eventuell die Zeilennummern in einem
gesonderten Array hält, dürfte die Suche nach der Zeile xy dann auch
wesentlich schneller gehen.
Aber das wäre dann eine weitere Optimierungsstufe...
Nils S. schrieb:> Aber wieso oder?
Von unserer menschlichen Logik her UND.
Da Chip Enable aber Low-Aktiv ist ODER.
/CE A15 /CE1 /CE2
1 0 1 1
1 1 1 1
0 0 0 1
0 1 1 0
So muss das aussehen.
mfg.
MoinMoin,
Frank M. schrieb:>> Das mit Pointern hört sich auch gut an, allerdings will der Interpreter,>> ein grosses in dem Format:>> char bla[16384] = "10 PRINT 1+1\n 20 PRINT ...\n...\n";>> aber den Interpreter könnte ich auch noch ein wenig umbiegen.>> Hm, das hört sich nicht sehr performant an, wenn es um "goto xyz" geht.> Bei einer Pointerliste, die eventuell die Zeilennummern in einem> gesonderten Array hält, dürfte die Suche nach der Zeile xy dann auch> wesentlich schneller gehen.>> Aber das wäre dann eine weitere Optimierungsstufe...
Handelt es sich um diesen BASIC-Interpreter
http://www.mikrocontroller.net/articles/AVR_BASIC?
Da sind einige Optimierungen, gerade für GOTO/GOSUB eingebaut. Einmal
angesprunge Zeilennummern/Label werden mit ihrer Textstelle gepuffert.
Aber nochmal zum Ursprungsproblem. Ich würde da eher an dem Editor
ansetzen. Also ihn dazu befähigen Zeilen an der richtigen Stelle
einfügen zu können. Dann kann man sich die Sortiererei sparen und könnte
auch die bequeme Interpreter-Eigenschaft "Programmzeilen ohne
Zeilennummern" verwenden.
Ich plane eigentlich auch einen Editor für diesen Interpreter, bin aber
bisher nicht so richtig dazu gekommen...
Grüße Uwe
Hallo,
das C64 Basic hatte als Kopf der Zeile in Byte 1 und 2 die binär
gespeicherte Zeilennummer und in Byte 3 und 4 die Startadresse der
nächsten Zeile. Zum Einfügen oder Löschen war so jeweils nur etwas Block
kopieren nötig.
Gruß aus Berlin
Michael
Uwe Berger schrieb:> Ich würde da eher an dem Editor> ansetzen. Also ihn dazu befähigen Zeilen an der richtigen Stelle> einfügen zu können.
Ich hatte in meinen Anfängen mal ein Telefonbuch auf nem 8051
programmiert.
Nach dem Drücken von Enter wurde die Zeile mit allen Einträgen
verglichen, bis die Einfügestelle gefunden war, dann alle Einträge
darüber um die Zeilenlänge verschoben und die Zeile eingefügt.
Geht bei so kleinen Datenmengen schneller, als man Enter wieder
losgelassen hat.
Eine extra Tabelle mit Pointer und Zeilennummer ist auch eine gute Idee,
wird sogar die Ausführung von Sprüngen und Calls deutlich beschleunigen.
Man kann ja beides machen.
Peter
MoinMoin,
immer vorausgesetzt Nils verwendet oben von mir angesprochenen
BASIC-Interpreter:
Peter Dannegger schrieb:> Ich hatte in meinen Anfängen mal ein Telefonbuch auf nem 8051> programmiert.> Nach dem Drücken von Enter wurde die Zeile mit allen Einträgen> verglichen, bis die Einfügestelle gefunden war, dann alle Einträge> darüber um die Zeilenlänge verschoben und die Zeile eingefügt.> Geht bei so kleinen Datenmengen schneller, als man Enter wieder> losgelassen hat.>
Das funktioniert nur solange, wie Zeilennummern in den BASIC-Programmen
verwendet werden. Mein BASIC-Interpreter kann auch ohne Zeilennummern,
da würde dies dann nicht mehr funktionieren...
Peter Dannegger schrieb:> Eine extra Tabelle mit Pointer und Zeilennummer ist auch eine gute Idee,> wird sogar die Ausführung von Sprüngen und Calls deutlich beschleunigen.>
das passt nicht ganz in den derzeit implementierten Algorithmus des
Parsers zum Lesen des Programmtextes. Es gibt aber eine Schnittstelle
(tokenizer_access.c) mit der man soetwas realisieren könnte. Ob dadurch
aber eine deutliche Beschleunigung erreicht wird bezweifle ich erst mal,
da ja seeks, je nach Programmspeichermedium auch Zeit kosten (ich denke
dabei vorallem an Zugriffe auf ein Filesystem). Für
GOTO/GOSUB-Sprungziele gibt es intern im Interpreter bereits
entsprechende Sprungtabellen.
Grüße Uwe
den Interpreter, den ich benutze ist ubasic, im ersten Post schon
geschrieben :)
Der braucht gerade mal 5kb Flash (mal abgesehen von printf an jeder
Ecke.... was aber auch praktisch ist.)
ich habs jetzt erstmal so gelöst, wie ich geschrieben hab. ging
eiknfacher als ich dachte...
>Bubblesort sieht für mich am besten aus, da am wenigsten Aufwendig. Ich>lasse mir sämtliche Zeilennummern in ein Array schreiben (16bit, 1000>Mögliche Zeilen, Knapp 2k RAM). Dann ein char Array von einer maximalen>Zeilenlänge (256Byte) zum auslagern einer zu beschreibenden Zeile und>dann nach dem sortierten Array die Zeilen zusammensetzen.
jetzt werd ich parallel zum bestehenden Interpreter den soweit ändern,
dass ich mit einer Tabelle aus Pointern zurecktkomme.
Nils S. schrieb:> den Interpreter, den ich benutze ist ubasic, im ersten Post schon> geschrieben :)> Der braucht gerade mal 5kb Flash (mal abgesehen von printf an jeder> Ecke.... was aber auch praktisch ist.)>
von mir erwähnter Interpreter basiert im Grundgerüst auf ubasic, kann
aber mittlerweile einiges mehr und ist weitestgehend
plattformunabhängig, kannst du dir ja mal anschauen....
Grüße Uwe
Aus (http://de.wikipedia.org/wiki/Quicksort): "Quicksort kann auch
nicht-rekursiv mit Hilfe eines kleinen Stack oder Array implementiert
werden. Hier eine einfache Variante mit zufälliger Auswahl des
Pivotelements:"
@Nils S.
wenn dein jetziger RAM von 0x8000 bis 0xFFFF liegt, muss ja schon eine
Verknüpfung von A15 und /CE vorhanden sein, sonst währe der Speicher ja
ab 0x0000 ansprechbar. Wo ist eigentlich der der Basicinterpreter
abgelegt?
Was für RAM-Chips verwendest du? Bei einigen Typen gibts mehrere /CE's
die sich für sowas verwenden lassen.
Sascha
>wenn dein jetziger RAM von 0x8000 bis 0xFFFF liegt, muss ja schon eine>Verknüpfung von A15 und /CE vorhanden sein, sonst währe der Speicher ja>ab 0x0000 ansprechbar. Wo ist eigentlich der der Basicinterpreter>abgelegt?
Interpreter liegt im Flash. Das Board hat ein GAL drauf um ausm RAM
ausführen zu lassen, allerdings muss ich da jedesmal die Locations beim
Compiler ändern, wenn ich wieder in den Flash will. Und so hab ich nur
32k Speicher gesamt, Flash bringt mir in dem Fall nix.
Im Flash abgelegt hab ich 512k Flash in 64k Bänke aufgeteilt und 32k
RAM. Das Huckepack RAM werd ich heute Abend mal draufbasteln.
In der Anleitung zum Board steht:
>...> "User" (freier Bereich) zwischen 0 und 7fff>...>FM1 bietet einen 32kB großen freien Speicherblock für externe>Erweiterungen an. Sämtliche benötigten Signale sind auf einer Seite des>FM1 herausgeführt. Das Signal "A15" kann als "Enable"-Signal verwendet>werden.>...
ftp://www.wickenhaeuser.de/anleitungen/flash_m1.pdf
>Was für RAM-Chips verwendest du? Bei einigen Typen gibts mehrere /CE's>die sich für sowas verwenden lassen.
62256 bzw 62ct081 (beim zweiten bin ich mir nicht 100%ig sicher, 081
hinten raus stimmt, bin gerade nicht @home...)
Eine bessere auswahl der Sortieralgorithmen als im oberen Link gibts
hier:
http://de.wikipedia.org/wiki/Sortierverfahren
Da sind dann direkt auch die Komplexitäten gegeben und ob der
Algorithmus rekursiv ist.
Hast du mal deinen Bubblesort über alle 16k Elemente laufen lassen?
Dürfte ziemlich langsam werden.
Bei mir läuft Heapsort (http://de.wikipedia.org/wiki/Heapsort) auch bei
größeren Datenmengen sehr zufriedenstellend. Ist aber natürlich etwas
schwerer zu implementieren als Bubblesort ;)
Viele Grüße,
Sebastian
Sebastian ... schrieb:> Eine bessere auswahl der Sortieralgorithmen als im oberen Link gibts> hier:> http://de.wikipedia.org/wiki/Sortierverfahren> Da sind dann direkt auch die Komplexitäten gegeben und ob der> Algorithmus rekursiv ist.>> Hast du mal deinen Bubblesort über alle 16k Elemente laufen lassen?> Dürfte ziemlich langsam werden.
Kommt auf die Variante an, die er benutzt.
Wenn er die Variante nimmt, die in deinem Link auf dem weiterführenden
Link zu finden ist, dann könnte die in seinem Fall gar nicht so schlecht
sein. Denn es gibt einen Sonderfall, in dem diese Variante nicht zu
schlagen ist: Wenn das Array bereits sortiert oder nahzu sortiert ist.
Und das dürfte hier in der Mehrzahl der Fälle tatsächlich der Fall sein.
1
sorted = false
2
3
while not sorted {
4
sorted = true
5
for i = 0 to arraysize - 1 {
6
if element[i] > element[i+1] {
7
swap element[i], element[i+1]
8
sorted = false
9
}
10
}
11
}
dieser Bubblesort degeneriert in diesem speziellen Fall dann zu einer
'Überprüfung ob das Array sortiert ist und kleineren Korrekturen bis es
sortiert ist'. Perfekt um einen bereits sortierten Bestand schnell
durchzuschleusen.
>Wenn das Array bereits sortiert oder nahzu sortiert ist.> Und das dürfte hier in der Mehrzahl der Fälle tatsächlich der Fall sein.>>
1
> sorted = false
2
>
3
> while not sorted {
4
> sorted = true
5
> for i = 0 to arraysize - 1 {
6
> if element[i] > element[i+1] {
7
> swap element[i], element[i+1]
8
> sorted = false
9
> }
10
> }
11
> }
12
>
>> dieser Bubblesort degeneriert in diesem speziellen Fall dann zu einer> 'Überprüfung ob das Array sortiert ist und kleineren Korrekturen bis es> sortiert ist'. Perfekt um einen bereits sortierten Bestand schnell> durchzuschleusen.
Als ich mir das vorhin mal auf Papier aufgemalt hab und erstmal richtig
verstanden habe, kam ich auch darauf, dass mein Array ja schon relativ
sortiert ist. Neue Zeilen kommen am Ende dazu, bei jedem
Speichern/Ausführen wird sortiert, also kein Hexenwerk.
So in der Art wie du das jetzt in Pseudocode geschrieben hast, hab ich
das gerade vor.
Ich bin nur gerade dabei, Funktionen mit Pointern und einem Index zu
schreiben, sodass ich nicht das komplette Array durchwühlen muss sondern
einfach nur "index_ptr_ziel[i]" aufrufen muss. Sortiert wird der Index.
Kostet mich pro 1000 Zeilen etwa 1,95k*2 RAM bei 16bit
Adresspointern(16bit Pointer, 16bit Zeilennummer). Das ist zu
verschmerzen. Mit dem zusätzlichen RAM hab ich dann etwa 40k für
BASIC-Code, nochmal 10k für für den Index einrechnen und ich bin weit
besser dran als auf einem C64 :D