Xilinx liefert im advisor, dass die performance des multipliers
blahblahblah improved werden kann, wenn man nur noch ein register level
addieren würde. Zunächst hatte er 2 Register vorgeschlagen, die ich auch
implementiert habe. Nun will er immer wieder noch ein weiteres, obwohl
ich inzwischen schon 3 FF stages dahin geklebt habe.
Ist das nun nur noch eine Phantonmeldung oder mache ich was falsch?
Der ominöse multiplier ist Teil eines Konstrukts in einer pipeline:
Jaromir schrieb:> Ist das nun nur noch eine Phantonmeldung oder mache ich was falsch?
Das liegt daran, das in den DSP-Slices diese Register schon vergraben
sind. Durch die weiteren Register (die ja eigentlich schon da sind) läßt
sich (in Abhängigkeit vom restlichen Design) die Taktfrequenz erhöhen.
Allerdings muß das Design auch mit der zusätzlichen Latenz klarkommen.
Wenn mein Design langsam ist (Größenordnung: 50 MHz), dann lass ich die
Registerstufen weg. Wenn es schnell sein muß (ab 100 MHz), dann versuche
ich die Pipelineregistern zu verwenden.
Duke
Jaromir schrieb:> Bekommt er das wegen der Subtraktion nicht gebacken?
Probiers doch einfach mal aus: lass die Multiplikation getaktet auf ein
Zwischenregister los. Viel Aufwand ist das ja nicht:
Natürlich müssen jetzt die Datentypen für die Pipeline (zumindest
teilweise) als unsigned agelegt werden...
Und/Oder such mal nach "Register-Balancing"....
Jaromir schrieb:> Bekommt er das wegen der Subtraktion nicht gebacken?
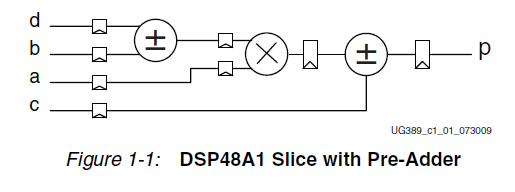
Das ist möglich. Im UG389 findet sich die angehängte Grafik.
Da könnte er für die Subtraktion den Pre-Adder verwenden.
Wenn Du maximale Performance brauchst, kannst Du den DSP48-Slice auch
von Hand instanziieren. Ansonsten würde ich es bei einer lesbaren,
architekturunabhängigen Schreibweise belassen.
Duke
Aber genau wegen des adders im DSP-slice sollte es ihm doch möglich
sein, die SUB auszuführen und danach die MUL. Hinter der MUL ist nichts
formuliert, daher gibt es da nichts, woran er sich stören kann.
Register balancing habe ich drin. Aber das ist ja ein aufwändiger
Process.
Jaromir schrieb:> Aber genau wegen des adders im DSP-slice sollte es ihm doch möglich> sein, die SUB auszuführen und danach die MUL. Hinter der MUL ist nichts> formuliert, daher gibt es da nichts, woran er sich stören kann.
Wenn's ein DSP48 werden soll, muß man sich an die Vorgaben halten. Die
stehen z.B. im UG687 (v13.3) auf Seite 201: Pre-Adder Description With
Explicit Data Extensions Coding Example
Hier scheint die Breite des Adders (resize) und der Datentyp (signed)
relevant zu sein.
Mit diesem Code:
1
libraryieee;
2
useieee.std_logic_1164.all;
3
useieee.numeric_std.all;
4
5
6
entityinfer_dsp48is
7
port(
8
clk:instd_logic;
9
point_s2:instd_logic_vector(6downto0);
10
maxi:instd_logic_vector(5downto0);
11
value_s6:outstd_logic_vector(15downto0)
12
);
13
endentityinfer_dsp48;
14
15
architecturertlofinfer_dsp48is
16
17
signala:signed(7downto0);
18
signalb:signed(17downto0);
19
signalc:signed(15downto0):=(others=>'0');
20
signald:signed(17downto0);
21
22
signalpre:signed(17downto0);
23
signalm:signed(25downto0);
24
signalp:signed(25downto0);
25
26
begin
27
28
a<=signed(point_s2&'0');
29
b<=resize(signed(point_s2&'1'),18);
30
d<=resize(signed(maxi&"10"),18);
31
32
process
33
begin
34
waituntilrising_edge(clk);
35
pre<=d-b;
36
m<=pre*a;
37
p<=m+c;
38
endprocess;
39
40
value_s6<=std_logic_vector(resize(p,16));
41
42
endarchitecturertl;
packt er - wie gewünscht - alles in DSP-Slice.
Ich hoffe ich habe Deine Signalnamen nicht verwechselt.
Duke
Jaromir schrieb:> Register balancing habe ich drin. Aber das ist ja ein aufwändiger> Process.
Genau weil die direkte Verwendung der Macros aufwendig ist, lasse ich
mir immer entsprechende Funktionen mit dem Core-Generator erzeugen. Da
kann man angeben was man haben will, Frequenz, Funktion, Breite der
Operanden usw.
Tom
D,h, man muss beim Xilinx die DSP slices manuell instanziieren, wenn man
sicherstellen möchte, dass er es optimal baut?
Das ist aber tödlich, wenn man den Code portieren will. Ich kenne den
Unsinn ja vom System Generator her, mit dem man immer genau
Xilinx-Primtiven instanziert bekommt und sonst nichts. Die Katastrophe
dabei ist, dass das System nicht mehr skaliert werden kann.
Bei meinen Designs möchte ich mal ein Bit hinzufügen und über die
generics automatisch berechnen lassen. Das wird total verunmöglicht,
wenn es durch die Grafiken oder die exzessive Nutzung der Primitiven
eingefroren wird.
Ich habe den Thread nochmals durchgeblättert: Der TE hat doch nur eine
Subtraktion vor der Multiplikation stehen. Ich verstehe noch nicht,
warum das nicht einfach so wie in der ersten Zeichung von Duke
angeschlossen wird. Das wäre es doch schon.
Hm, die Frage ist, ist es denn in dem Fall überhaupt nötig, den DSP48
optimal auszureizen? Solange das Timing erreicht wird, besteht doch da
eigentlich keine Veranlassung, und der Code kann generisch
hingeschrieben werden. Ich bekomm diese Meldung auch immer.
Na, wenn einem die slices so langsam ausgehen, wird das schon
interessant. Wenigstens die Adder sollte man schon nutzen können und das
mit full speed.
Andererseits ist dies nicht der einzig Fall, wo eine Xilinx Synthese
einen Chip nicht optimal nutzt. In einem parallelen thread wird ja davon
bereichtet, dass andere tools schneller lauffähigen code generieren
können sollen. Ich habe leider keinen Zugriff auf Synplify o.ä. dass ich
das mal austesten könnte. Wäre mal interessant, zu wissen, wie so ein
Tool mit den standard HDL-Konstrukten wie oben umgeht und ob er die
slices besser ausnutzt.
Frager schrieb:> Der TE hat doch nur eine> Subtraktion vor der Multiplikation stehen. Ich verstehe noch nicht,> warum das nicht einfach so wie in der ersten Zeichung von Duke> angeschlossen wird. Das wäre es doch schon.
Naja, da hat der Synthesizer eben noch Potential für Optimierungen.
Wie gesagt, wenn man mit resize auf die richtige Bitbreite geht und
signed verwendet, macht er ja auch das richtige draus. Und der Code
sieht immernoch einigermaßen generisch aus. Ich finde es zumindest
besser lesbar, als wenn man das DPS-Primitiv direkt instanziieren würde.
Christian R. schrieb:> Hm, die Frage ist, ist es denn in dem Fall überhaupt nötig, den DSP48> optimal auszureizen? Solange das Timing erreicht wird, besteht doch da> eigentlich keine Veranlassung, und der Code kann generisch> hingeschrieben werden. Ich bekomm diese Meldung auch immer.
So sehe ich das eigentlich auch. Es ist ein ziemlicher Aufwand den Code
passend zu optimieren. Wenn dann die nächste Chip-Generation oder ein
Herstellerwechsel kommt, fängt man wieder damit an :-/
Also, wenn's Timing (oder die Ressourcen) nicht drückt, dann einfach so
lassen.
Duke
Jaromir schrieb:> aber das sollte ja nichts machen.
Bei mir ging es mit unsigned nicht. Und mit der falschen Bitbreite
ging es auch nicht. Ich habe es nicht umsonst hingeschrieben.
Duke