N'abend, ich sitz grad am AVR Studio 5, und würde gerne einen popeligen String auf einem Display ausgeben, das den ANSI-Zeichensatz und nicht UTF-8 besitzt. Nun geht das auch reibungslos, bis eben auf alles >127, das konvertiert VS nämlich in Uni-Code / UTF-8 und damit krieg ich kein "ü". Hab versucht, einen externen editor zu nehmen, ging nicht, VS konvertiert die Datei direkt beim Öffnen wieder nach UTF-8 (und falsch auch noch, btw). Hat das schon mal jemand gelöst? Danke, Christoph
Christoph Söllner schrieb: > auf einem Display HD44780-kompatibles Display? Dann füll doch in die acht benutzerdefinierbaren Zeichen ein ü, ö, ä, Ü, Ö, Ä und ß ein und gib die stattdessen aus. mfg mf
Und die Formatierung der Quellcodedatei spielt keine Rolle, da beim
Kompilieren bzw. Assemblieren dein String sicher ohnehin umgewandelt
wird. Höchstwahrscheinlich in ASCII. UTF-8 auf einem Mikrocontroller ist
eher unüblich. Also einfach im Datenblatt des Displaycontrollers bzw. in
einer Zeichentabelle schauen, welchen Code die Umlaute haben und diesen
dann anstelle des Zeichens in den String einfügen. Falls es dir wichtig
ist, die Strings im richtigen Format sind kannst du die Zeichen auch in
deiner Ausgabefunktion ummappen. Also wenn Zeichen = Code('ü') dann
Zeichen = DisplayCodr('ü') usw.
Die meisten LCDs können von Hause aus leider keine deutschen Umlaute...
g, danke für die Antworten, das Display kann das, ist ein GLCD, und als Softfont verwende ich Arial mit allen Zeichen. Es geht nur um das VS-Problem, dass im Quelltext der C-Code
1 | sprintf(myBuffer, "Kühler:"); |
2 | lcd_puts(myBuffer, 10, 15); //StringBuffer, X, Y |
Tatsächlich diesen Text (wirklich auf dem LCD) ausspuckt: "Kühler:" Und das ist ein Visual-Studio-Problem, ich will, dass im Quelltext einfach nur das einbytige (0d0129, 0x81) Zeichen steht, damit der Compiler nicht die UTF-8Bytes verwendet. @nyan: Ich habs mit \u81 versucht --> Incomplete Charater Code ist der Fehler. Sonst noch Ideen? Danke, Christoph
Christoph Söllner schrieb: > @nyan: Ich habs mit \u81 versucht --> Incomplete Charater Code ist der > Fehler. \u kennt VS wohl nicht. Probier doch mal \xhh wobei hh der ascii code in hex ist. Siehe auch: http://msdn.microsoft.com/en-us/library/h21280bw.aspx
Christoph Söllner schrieb: > N'abend, ich sitz grad am AVR Studio 5, und würde gerne einen popeligen > String auf einem Display ausgeben, das den ANSI-Zeichensatz und nicht > UTF-8 besitzt. Um die Glaskugelraterei ein bisschen einzugrenzen: Woran liegt es denn? Findest du das "ü" nicht Zeichensatz von deinem Display (welches auch immer?), kannst du es in AVR Studio 5 nicht eintippen oder weißt du nicht, wie du deinem Compiler beibringen sollst, dass er den richtigen Code zum Display schickt.
Die beste Variante ist wirklich, du akzeptierst UTF-8 als Zeichensatz fuer den Sourcecode und wandelst in deiner Ausgaberoutine auf die Zielhardware um. Damit ist eine klare, nachvollziehbare Schnittstelle und hast in der Zukunft weniger Aerger mit wechselnden Editoren/Hardware/etc.
Angehängte Dateien:
-

AVR-Studio-_.png
12 KB
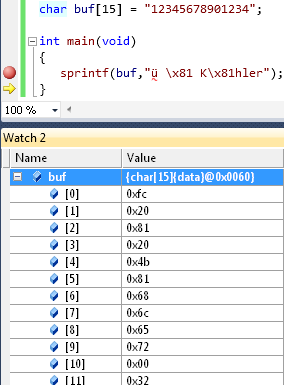
Christoph Söllner schrieb: > Und das ist ein Visual-Studio-Problem, ich will, dass im Quelltext > einfach nur das einbytige (0d0129, 0x81) Zeichen steht Blöd, dass der ASCII-Code für ein 'ü' eben genausogut ein 0xfc sein kann (ISO-8859-1), und das vom AVR-Studio korrekt umgesetzt wird (Screenshot)... Da gibts auch was zum Thema: http://www.torsten-horn.de/techdocs/ascii.htm http://www.c-plusplus.de/forum/260997
Visual Studio (das hier wohl als IDE verwendet wird) bietet sehr wohl
die Möglichkeit, die Art der Zeichencodierung zu beeinflussen. Dazu muss
in der Projektverwaltung ("Solution Explorer") anstatt die
Quelltextdatei mit einem Doppelklick zu öffnen mal ein Rechtsklick und
"Open With" aufgerufen werden.
Da werden dann verschiedene Editoren angeboten, hier ist die
Defaultvariante wohl eine, die "with encoding" heißt. Nimm die andere,
und das Problem dürfte soweit Geschichte sein, als daß danach Deine
Quelltexte nach Codepage 1252 bzw. nach 8859-1 codiert werden.
Da wird 'ü' korrekt als 0xFC codiert.
Wenn Dein Display aber 0x81 erwartet, dann ist es nicht ANSI-Codiert,
sondern nutzt den sogenannten "DOS-Zeichensatz" nach Codepage 437 bzw.
850, der auch im Windows-Befehlszeilenfenster (oft fälschlich "DOS-Box"
genannt) standardmäßig verwendet wird.
Grüße, in Kürze: es tut jetzt. @0xFC: Korrekt, das hatte ich noch falsch. @Solution Explorer: Ah, stimmt, ich probier's heute abend mal aus, wenn ich Zugriff auf die Hardware habe. Jetzt hab ich nur noch ein Problem, wenn ich "°C" darstellen möchte: Schreibe ich "\xB0C", kommt nix, schreibe ich "\xB0\x43", paßt es. Gibt's dafür auch eine elegante Lösung? Danke, Christoph
> Schreibe ich "\xB0C", kommt nix, Doch, es kommt ein Byte mit dem Wert 0x0C... > wenn ich "°C" darstellen möchte: Probiers mal so:
1 | sprintf(buf,"\xb0\Celsius"); |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.