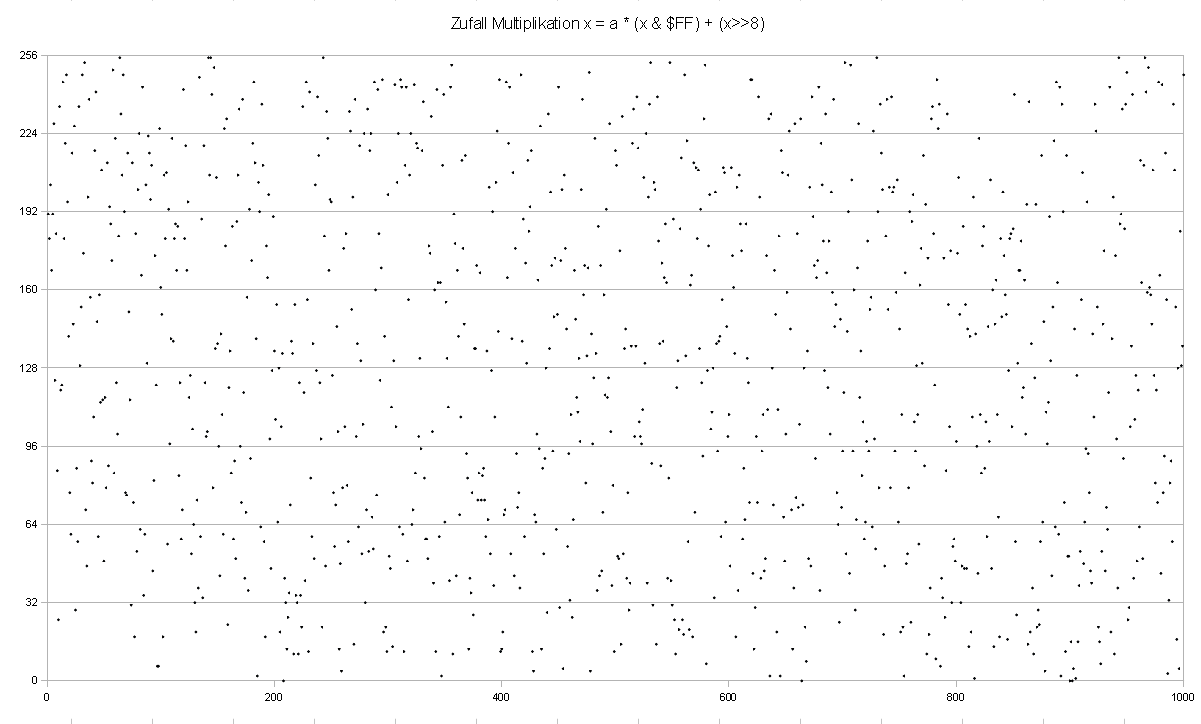
Ich habe ein bißchen mit Zufallszahlengeneratoren simuliert. Die
rückgekoppelten Schieberegister werden zwar oft implementiert, bringen
bei meinen Tests (32 bit, mehrere Rückkopplungsvarianten) aber oft
Folgen am unteren und oberen Rand wie 1 - 2 - 4 - 8 oder 5 - 10 - 20 -
40, bis die Folge dann wieder unregelmäßig wird.
Daher habe ich folgenden Generator getestet:
Beitrag "Re: Zufallszahlen mit Atmega8"
Hier wird die Funktion x = a * low(x) + high(x) verwendet. Mit den
vorgegebenen Startwerten für a bekommt man schöne Zufallsverteilungen,
die auch im Histogramm relativ gut gleichverteilt sind und keine
sichtbaren Oszillationen zeigen.
Dann habe ich die Funktion auf 8 bit vereinfacht:
x = a * (x & $FF) + (x >> 8)
erg = x % 256
Funktioniert auch ganz gut, aber: Bei manchen Werten für a gibt es
Zufallszahlen, bei anderen a oszilliert x nur zwischen wenigen Werten.
Jetzt würde mich natürlich interessieren, wie man brauchbare Werte von a
ermittelt. Sprich woher die Anfangswerte in der Tabelle des verlinkten
Beitrags stammen. Ich habe aber keinen Zusammenhang erkennen können,
ausser dass a > 1/4 xmax ist.
Hier noch der ASM-Code für den AVR, die Tests mache ich aber in einer
Basic-Simu auf dem PC:
Vereinfacht habe ich den Generator auf 4 bit (x = a * (x & $F) + (x >>
4)) und einem Histogramm gefüttert, und a von 1 bis 15 durchprobiert.
Bei 1000 Durchläufen ergibt sich für die verschiedenen a folgende
Verteilung der Zufallszahlen i (0..15).
1
i / a 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2
0 0 0 88 333 77 111 0 0 134 153 0 20 61 135 25
3
1 0 200 87 333 77 111 0 0 0 0 0 42 92 108 42
4
2 0 0 131 0 78 0 0 143 134 0 0 55 30 162 60
5
3 0 200 43 0 78 0 0 0 134 0 0 64 31 27 60
6
4 0 0 87 334 101 111 0 143 66 0 0 51 121 135 51
7
5 0 0 87 0 52 0 0 286 0 77 0 64 61 27 68
8
6 0 200 44 0 51 111 0 0 132 77 0 54 60 0 51
9
7 0 0 44 0 51 111 0 0 0 77 0 83 60 54 88
10
8 0 200 86 0 76 111 0 0 0 0 0 42 0 108 42
11
9 0 0 86 0 77 111 0 143 132 231 1000 72 122 81 73
12
10 2 0 44 0 77 112 1000 285 67 77 0 63 91 0 60
13
11 0 0 43 0 26 0 0 0 67 77 0 70 60 27 75
14
12 998 200 86 0 51 111 0 0 67 77 0 64 31 54 65
15
13 0 0 0 0 52 0 0 0 67 77 0 75 30 0 66
16
14 0 0 44 0 51 0 0 0 0 77 0 86 90 55 82
17
15 0 0 0 0 25 0 0 0 0 0 0 95 60 27 92
Man sieht, dass bei einigen a (5, 12, 15) alle i erreicht werden, bei
einigen a die Werte zwischen ein paar i springen und bei einigen a auf
einem Wert festsitzen.
Bei 8 bit wird die Verteilung deutlich besser, aber das Prinzip (einige
a gehen, andere nicht) bleibt. Brauchbare Werte für a sind z.B. 80, 83,
84, 87, 90, 98, 105, 108, 129.
Nun könnte ich das einfach hinnehmen, aber ich würde schon gern wissen,
warum das so ist.
Btw: x kann nie Null werden, denn dann bleibt der Generator auf Null
hängen. Da aber nur ein Byte von x verwendet wird, tritt Null trotzdem
mit gleicher Wahrscheinlichkeit (bei 8 bit) wie die anderen Zahlen auf.
Zufallszahlen sind eine schwierige Sache. Ganze Bücher sind schon
darüber geschrieben worden. Sowas schüttelt man nicht einfach aus dem
Ärmel.
Soll heißen: Google danach. Es ist unwahrscheinlich, daß du ausgerechnet
hier im Forum einen Spezialisten zum Thema "Generatoren - wer, wie, was,
warum" findest.
Timm Thaler schrieb:> aber oft> Folgen am unteren und oberen Rand wie 1 - 2 - 4 - 8 oder 5 - 10 - 20 -> 40, bis die Folge dann wieder unregelmäßig wird.
Was erwartest du?
Du hast in jedem Fall eine Bildungsvorschrift. Das ist deine
Regelmäßigkeit. Ob die nun durch ein LFSR oder die Multiplikation
hervorgerufen wird ändert daran nichts.
Ich würde behaupten bei deinem Multiplikationsversuch findest du solche
Reihen durch den gesamten Werteraum.
Ein wenig besser wird das ganze, wenn du nicht-lineare Funktionen
verwendest. Dann ist das Muster als lesender Mensch schwerer zu erahnen.
Wenn genau das dein Ziel ist, dann schau dich unter den Cryptoverfahren
um. Die erzeugen auch ein möglichst Zufällig aussehende Folge, können
jedoch nur sehr schwer auf die Bildungsregel zurückgeführt werden (was
eben genau Ziel dieser Verfahren ist))
max schrieb:> Ich würde behaupten bei deinem Multiplikationsversuch findest du solche> Reihen durch den gesamten Werteraum.
Nicht so offensichtlich, beim Shift-Generator tritt eine merkliche
Häufung von Fliegendreck am Rand auf, wobei die Werte im Histogramm
gleichverteilt sind. Siehe die Bilder der Zufallsfolgen.
max schrieb:> Ein wenig besser wird das ganze, wenn du nicht-lineare Funktionen> verwendest.
Es war nicht die Frage, einen besseren Generator zu finden. Ich will
keine Krypo machen, ich brauche das für einen RGB-Farbwechsler. Da würde
es auch reichen, wenn ich eine ausreichende Anzahl Zufallszahlen im
Flash ablege und die zyklisch durchlaufe.
Mir geht es um das prinzipielle Verständnis, warum genau dieser
Multiplikator-Generator so reagiert, also:
Warum gibt es für einige Multiplikatoren a brauchbare Zufallsreihen, für
einige nicht?
Wie bestimme ich mathematisch brauchbare Multiplikatoren, ausser durch
trial and error?
Leider bin ich nicht so ein Mathegenie, mir die Theorie selbst
herzuleiten.
Timm Thaler schrieb:> Die> rückgekoppelten Schieberegister werden zwar oft implementiert
Weil sie gut funktionieren.
Timm Thaler schrieb:> bringen> bei meinen Tests (32 bit, mehrere Rückkopplungsvarianten) aber oft> Folgen am unteren und oberen Rand
Dann hast Du was falsch gemacht.
Warum nimmst Du nicht eine fertige Lib?
Ich hab mir mal die vom Keil C51 angesehen. Ist schon einige Jahre her,
daher ohne Gewähr:
Es wird ein 32Bit Register so rückgeführt, daß alle Zustände 2^32-1
durchlaufen werden.
Das wird für jede Abfrage 31 mal gerechnet, damit aufeinander folgende
Werte nicht ähnlich sind. Und davon werden dann 15Bit als Zufallswert
geliefert, den man dann auf den gewünschten Wertebereich skalieren muß.
Natürlich bleibt der interne 32Bit Wert für den nächsten Aufruf
erhalten.
http://www.keil.com/support/man/docs/c51/c51_rand.htm
Peter
Peter Dannegger schrieb:> Das wird für jede Abfrage 31 mal gerechnet, damit aufeinander folgende> Werte nicht ähnlich sind.
Klar kann man Werte überspringen und den Generator mehrfach durchlaufen,
das braucht dann aber deutlich mehr Rechenzeit, als eine Multiplikation
und bißchen Addieren. Ich bin da halt pingelig, sonst würde ich ja nicht
ASM programmieren. ;-)
Ich hab jetzt was gefunden, man muss nur die richtigen Begriffe haben:
http://de.wikipedia.org/wiki/Kongruenzgenerator
Da ist y = (a * y + b) % m
Nur dass dort b konstant ist, bei mir wird es aus dem high-Byte des
vorigen Wertes gebildet. Damit lassen sich dummerweise die
Bildungsregeln für a nicht wie dort angegeben verwenden.
Timm Thaler schrieb:> Klar kann man Werte überspringen und den Generator mehrfach durchlaufen,> das braucht dann aber deutlich mehr Rechenzeit
Hä ???
Du willst LEDs ändern, da brauchts überhaupt keine Rechenzeit.
Das Auge ist über 1000-mal träger, als Du neue Zufallswerte erzeugen
kannst.
Peter
Timm Thaler schrieb:> Ich hab jetzt was gefunden
Na dann mußt Du es ja nur noch überprüfen.
Ich nehme lieber ne bewährte fertige Lib, auch wenn die vielleicht 0,1%
CPU-Zeit belegt anstatt 0,01%.
Peter
Timm Thaler schrieb:> Dann habe ich die Funktion auf 8 bit vereinfacht:>> x = a * (x & $FF) + (x >> 8)> erg = x % 256
M. E. liegt hier dein Fehler. Ich schlage vor, intern immer mit den 16
bit zu rechnen und erst am Schluss dir davon ein Byte rauszusuchen, wenn
dir 8 bit reichen. Die Begrenzung auf 8-bit von vorneherein schränkt den
Wertebereich unnötig ein.
Hier eine nette 19-bit Zufallsroutine in AVR Assembler. Braucht ein paar
Register, is aber schnell. Seed in StateA bis StateC einfüllen: