Hi,
ich versuche mich gerade daran eine Programmiersprache zu der ich eine
Sprachbeschreibung in grafischer Form voliegen habe,
in eine EBNF-Form zu bringen.
Mit Coco/R möchte ich mir daraus später einen Parser generieren lassen.
Jetzt ergeben sich aus den Diagrammen aber ein paar Mehrdeutigkeiten,
bei denen ich keine Idee habe wie man diese lösen kann.
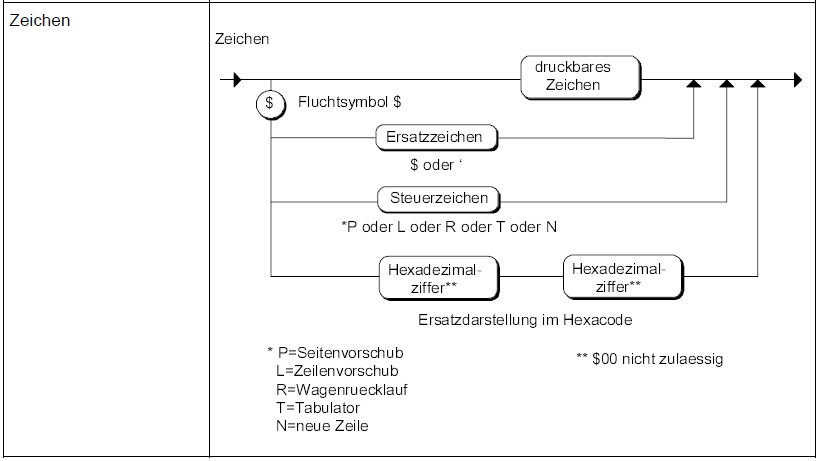
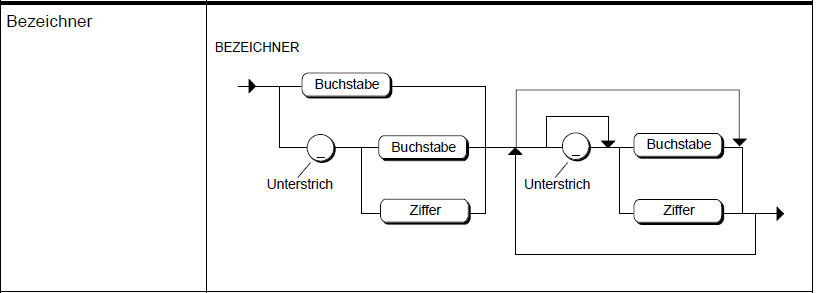
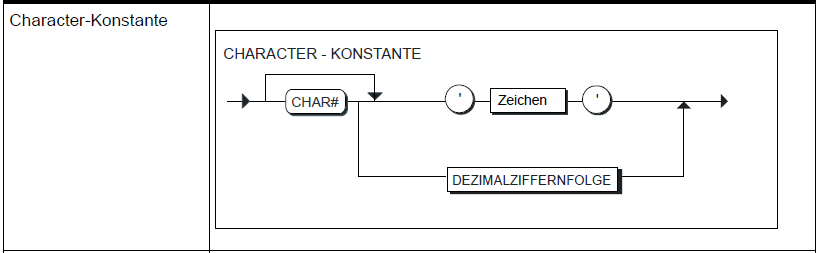
Als Beispiel habe ich mal drei Diagramme angehängt.
Folgende Zeichengruppen habe ich definiert:
1
CHARACTERS
2
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz".
Bei diesen beiden Token besteht aber das Problem dass diese nicht
eindeutig voneinander unterscheidbar sind.
'bezeichner' und 'zeichen' kommen in diversen anderen Symbolen vor, z.B.
'zeichen' in 'char-konstante' (siehe im Diagramm im Anhang).
Die einzige Möglichkeit das Problem aufzulösen die ich momentan sehe,
wäre an allen Stellen wo auf 'zeichen' verwiesen wird immer die
komplette Beschreibung einzusetzen. Denn erst durch zusätzliche Symbole
wird 'zeichen' dann von 'bezeichner' unterscheidbar.
Kann man das irgendwie anders lösen?
Denn so ein Problem taucht in der Art noch an anderen Stellen auf.
Beispielsweise ist an manchen Stellen in Zahlwerten ein Unterstrich als
Trennstrich erlaubt, an manchen nicht (z.B. 1_23 für 123 an manchen
Stellen erlaubt, an anderen nicht)
Thomas W. schrieb:> Bei diesen beiden Token besteht aber das Problem dass diese nicht> eindeutig voneinander unterscheidbar sind.> 'bezeichner' und 'zeichen' kommen in diversen anderen Symbolen vor, z.B.> 'zeichen' in 'char-konstante' (siehe im Diagramm im Anhang).
Schon. Aber in char-konstante kommt kein Bezeichner vor. Das heißt, das
Problem, dass die beiden terminalen Anfänge von bezeichner und zeichen
sich überschneiden, stellt sich hier gar nicht. In char-konstante KANN
es sich nur um ein 'zeichen' handeln (wenn überhaupt). In der EBNF von
char-konstante forderst du, dass da eines stehen muss. Die Frage ob da
nicht auch ein bezeichner passen würde stellt sich gar nicht.
2 Regeln dürfen ruhig dieselben terminalen Anfänge haben. Solange es
nicht zur Situation kommt, dass beide Regeln *an der verwendenden
Stelle* zum Einsatz kommen könnten, ist das ja kein Problem.
Übrigens:
Wenn du dann soweit bist, die Semantik zu ergänzen, wirst du
draufkommen, dass du die Dinge sowieso noch mehr in Regeln aufschlüsseln
willst um nicht die Übersicht zu verlieren. Also kannst du das auch
gleich jetzt tun.
Und mach dir Namen, die vernünftig aussehen. Namen mit 10 Zeichen und
alles in Kleinbuchstaben ist nicht sehr schlau. hexziffer und hexZiffer
unterscheiden sich zwar nur in der Schreibweise vom Z, der Gewinn im
Lesefluss ist jedoch nicht zu verachten.
Und du wirst auch drauf kommen (spätestens dann, wenn du die Semantik
ergänzt), dass es nicht so schlau ist, dein Regelwerk quer über den
ganzen Bildschirm in eine einzige Zeile zu quetschen. Spätestens dann,
wenn du mit den Klammerungen nicht mehr durchblickst, wird dein Umdenken
einsetzen :-) So wie es dir bei deiner Regel für Zeichen passiert ist.
Dein Regelwerk stimmt nicht mit dem Diagramm überein.
Hallo Karl Heinz,
danke für deine Tips.
Wenn ich Coco/R aufrufe überprüft das Programm wohl jeden Token separat
auf Eindeutigkeit. Ist das nicht der Fall gibt es eine Fehlermeldung
wie:
"Tokens bezeichner and zeichen cannot be distinguished"
Auch wenn die aus den mehrdeutigen Token abgeleiteten Produktionen
später eindeutig sind, wird kein Scanner/Parser generiert.
Ich stelle gleich mal ein vereinfachtes atg für Coco mit den Beispielen
aus den Diagrammen zusammen.
Karl Heinz, kennst du dich mit dem Coco/R etwas aus?
Ich kann nämlich nicht wie in deinem Beispiel die Steuerzeichen zu einem
Token (oder Token-Klasse) zusammenfassen, und dieses dann in einem
anderen Token verwenden.
Ich könnte die beispielsweise als Zeichengruppe unter CHARACTER
einsortieren, aber das ist auch unübersichtlich.
Wie folgt hätte ich es mir gedacht, aber das scheint grundlegend falsch:
1
COMPILER Test
2
CHARACTERS
3
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz".
wieso TOKENS?
Was du da hast sind PRODUCTIONS und keine Tokens. Du beschreibst hier
schon EBNF Regel, und nicht mehr wie der lexikographische Scanner aus
dem Input Stream Einheiten rausfischen soll
Karl Heinz Buchegger schrieb:> wieso TOKENS?> Was du da hast sind PRODUCTIONS und keine Tokens. Du beschreibst hier> schon EBNF Regel, und nicht mehr wie der lexikographische Scanner aus> dem Input Stream Einheiten rausfischen soll
Mit dem einsortieren tue ich mich auch etwas schwer.
Wenn man aber eine Real-Zahl als Token annimmt, habe ich gedacht dass es
sinnvoll ist wenn man eine Zeichenkonstante wie 'X' ebenfalls als Token
betrachten kann.
In der Sprach-Beschreibung von CSharp (http://ssw.jku.at/Coco/) sind
charCon und stringCon auch Tokens und keine Produktionen.
Das würde bei mir prinzipiell ja auch gehen, wenn ich die gesamten
Escape-Zeichen direkt in die Beschreibung mit hineinnehme. Aber wie du
oben schon schriebst gibt es sicher Probleme wenn es dann an die
Semantik geht.
Aber um mein Beispiel von oben erstmal zu Ende zu bringen:
Ich habe die Teile dementsprechend als Produktionen definiert (laut Doku
sollte man Produktionen mit einem Großbuchstaben beginnen):
1
COMPILER Test
2
CHARACTERS
3
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz".
Thomas W. schrieb:> Tokens dezimalZiffernFolge and hexZeichen cannot be distinguished> Tokens hexZeichen and bezeichner cannot be distinguished> Tokens dezimalZiffernFolge and hexZeichen cannot be distinguished
Das dreht sich auch wieder um Tokens.
Token MUESSEN eindeutig sein. Der Scanner darf keine 'Umgebung'
benötigen um zu entscheiden, wie er einen Textausschnit
einkategorisieren soll.
Bei Tokens geht es darum, dass der erste Teil des SCanners den Text in
Einheiten zerlegt. Jede dieser Einheiten wird eine Kategorie zugeordnet.
Da gibt es zb SChlüsselwörter (die sich COCO aus dem Regelteil holt)
oder auch Kategorien, wie "das ist ein Name", oder "jetzt kommt eine
Zahl". Wenn das so nicht eindeutig möglich ist, dann musst du die
Sachlage mit Regeln abbilden, so dass du aus der Umgebung heraus, wo
dieses 'Ding' vorkommt, entscheiden kannst worum es sich handelt.
> charCon und stringCon auch Tokens und keine Produktionen.
die kannst du aber leicht unterschieden.
Ein charCon fängt IMMER mit einem ' an
ein stringCon fängt IMMER mit einem " an
Deine Tokens SIND nicht eindeutig. Was ist
AAA
ist das der Name eine bezeichner oder ist das eine hexZeichen?
Was ist
777
dezimalZiffernfolge oder hexZeichen?
Das lässt sich bei dir nicht klären solange du nicht von vorne herein
weißt, ob du es an dieser Stelle in der Grammatik nur mit einem
bezeichner zu tun haben kannst (oder mit einem hexZeichen). Wenn deine
Grammtik als nächstes Eingabe-Token einen bezeichner verlangt und der
lex-Scanner liefert eine hex Zahl, dann ist das logischerweise ein
Fehler.
Wenn du dir die C Sharp Grammatik ansiehst, dann kann man intCon und
realCon zb so aufs Notwendigste zusammenschrumpfen
1
intCon = digit {digit} .
2
realCon = digit {digit} "." digit {digit} .
da steht eindeutig: eine real Konstante ist etwas mit einem "." mitten
drinn. Bei einer intCon kann aber kein Punkt vorkommen (denn in digit
ist kein Punkt enthalten). Ergo: die beiden sind eindeutig
unterscheidbar. Und daher ist das auch nicht fehlerhaft.
Ich bin jetzt ersteinmal dabei für eine vereinfachte Sprache alle
Schritte bis zur Codegenerierung umzusetzen, bin aber momentan bei einem
kleinen Problem.
Aufgrund meiner Zielarchitektur brauche ich bei der Codegenerierung
einen etwas anderen Ansatz.
Und zwar habe ich keinen Stack zur Verfügung, sondern alle
arithmetischen Operationen werden zwischen zwei Akkumulatoren
durchgeführt (ähnlich der 8051 Architektur mit den A/B Akkus für
Mul/Div).
Ich hatte als erstes eine eigene Lösung entwickelt bei der ich als
Zwischencode einen Quadrupelcode (Operation, Argument 1, Argument 2,
Ergebnis) erzeugt habe.
Das hat bei arithmetischen Operationen ganz gut funktioniert, bei
anderen Dingen wird das aber irgendwann unpraktisch.
Nun habe ich mich etwas eingelesen, und bin momentan bei einer Lösung
bei der ich einen abstrakten Syntaxbaum generiere (AST). Dazu gibt es
auf der Coco/R-Webseite auch ein Beispiel an das ich mich größtenteils
mit meiner Lösung angelehnt habe.
Dabei wird für jeden Knoten des Syntaxbaums (BinExpr, Assignement,
Ident, ...) ein eigenes Objekt erzeugt, die alle von einer gemeinsamen
Basisklasse (Node) abgeleitet wurden.
Um die Knoten für die Codegenerierung (oder dumpen des Baums)
durchzugehen, scheint mir das Visitor-Pattern ganz gut geignet.
Zumindest für einen dump des Syntaxbaums funktioniert es ganz gut.
Bei der Codegenerierung weiß ich jedoch momentan nicht wie man das am
geschicktesten lösen kann.
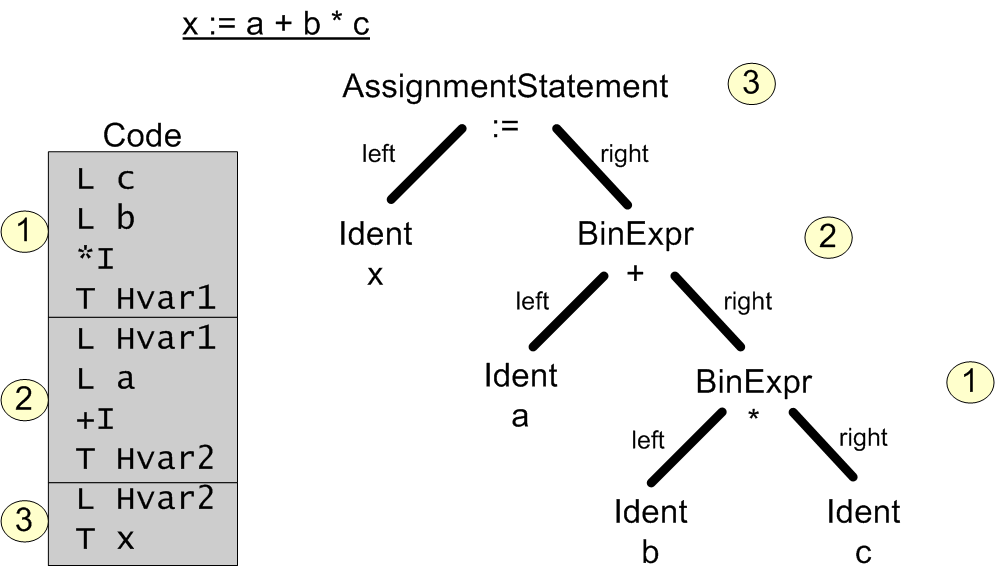
Angehängt habe ich die Darstellung eines Syntaxbaum für einen einfachen
arithmetische Ausdruck, und wie der generierte Code aussehen müsste.
Die Codegenerierung müsste demnach immer am äußersten Blatt des Baums
beginnen und dann nach innen arbeiten. An den entsprechenden Stellen
müssten Zwischenvariablen eingesetzt werden (die später ggf.
wegoptimiert werden).
Zu den äußersten Blättern gelange ich über den visitor recht einfach,
indem ich den Typ des Objektes in left/right prüfe. Ist dieses kein
Endknoten (Ident oder Konstante) dann wird das Objekt "besucht" um dort
das gleiche zu tun.
Am untersten Blatt (1) angelangt könnte an dieser Stelle der
entsprechende Code erzeugt werden.
Dann müsste jedoch bei (2) das Blatt am rechten Ast (right) von einem
BinExpr-Objekt in ein Ident-Objekt mit Namen der entsprechenden
Hilfsvariable geändert werden.
Dazu müsste sich das Objekt aber entweder selber von einem Typ in einen
anderen umwandeln, oder sein Eltern-Objekt modifizieren. Ersteres
scheidet generell aus (oder?), und Zweites weil das Objekt sein
Eltern-Objekt - bisher zumindest noch nicht - kennt.
Die Eltern kennen nur ihre Kinder, und nicht umgekehrt.
Gibt es da einen geschickten Ansatz wie man das objektorientiert lösen
kann? Oder komme ich da mit dem Visitor (welcher keine Werte zurückgibt)
nicht weiter?
Die meisten Beispiele in denen aus einem AST Code generiert wird sind
für Maschinen die einen Stack besitzen, und da kann man einfach von oben
nach unten abarbeiten und alles auf den Stack schieben.
Danke schonmal.
Thomas W. schrieb:> Gibt es da einen geschickten Ansatz wie man das objektorientiert lösen> kann? Oder komme ich da mit dem Visitor (welcher keine Werte zurückgibt)> nicht weiter?
Visitor ist da der falsche Ansatz. Ok, nicht unbedingt falsch, aber
umständlich.
Das ganze ist eine ganz normale Post-Order Baumtraversierung.
So ungefähr:
1
RsultNode::EvaluateTree(...)
2
{
3
if(leftTree!=NULL)
4
LeftVariableName=leftTree->EvaluateTree();
5
6
if(rightTree!=NULL)
7
RightVariableName=rightTree->EvaluteTree();
8
9
if(Operation==Identifier)
10
returnIdentifierName
11
12
elseif(Operation==Addition){
13
Emit(LoadInstruct,LeftVariableName);
14
Emit(LoadInstruct,RightVariableName);
15
Emit(AdditionInstruction);
16
TempVarName=GenerateTemporaryVariable();
17
Emit(StoreInstruction,TempVarName);
18
returnTempVarName;
19
}
20
21
elseif(Operation==....
22
....
23
}
Den Baum eben Post-Order abarbeiten.
Erst in die Rekursionen links/rechts einsteigen und dann erst die
Operation für den Knoten selber machen.
Pre-Order
* erst den Knoten und erst dann den links/rechts rekursiv runter
* -> Der Baum wird von der Wurzel zu den Blättern hin aufgerollt
Post-Order
* erst links/rechts rekursiv rein und erst dann den Knoten
* -> Der Baum wird von den Blättern her zur Wurzel hin aufgerollt
In-Order
* erst links, dann den Knoten, dann rechts
* -> Der Baum wird von dern Blättern her von links nach rechts
aufgerollt
Hm, das passt besser.
Ich gehe davon aus dass du meinst, dass ich eine EvaluteTree(...)
Funktion für jeden Knotentyp erstellen muss. So wie ich es jetzt auch
beim Visitor gemacht habe. Also:
1
EvaluteTree(BinExpr expr){
2
3
EvaluteTree(AssignStatement assign){
usw.
Vom Prinzip her stimmt das mit der Rekursion meines Visitors überein,
nur müsste ich bei diesem dann einen anderen Rückgabetyp angeben.
Momentan sieht dort der Visitor z.B. so aus:
1
public override void Visit(BinExpr binExpr)
2
{
3
if (!(binExpr.left is Ident))
4
{
5
binExpr.left.Accept(this);
6
}
7
...
Und in die Struktur bekomme ich meine temporären Variablen nicht rein.
Thomas W. schrieb:> Hm, das passt besser.> Ich gehe davon aus dass du meinst, dass ich eine EvaluteTree(...)> Funktion für jeden Knotentyp erstellen muss.
Moment.
Du hast für jeden Operationstyp einen eigenen Knotentyp?
Ja, dann machst du dir in die Basisklasse eine virtuelle Evaluate
Funktion rein und in jedem Knoten dann eben nur den Teil der Auswertung,
die du im jeweiligen Knoten brauchst
Ich würd die Idee mit dem Vsitor aufgeben. Bringt nix. Vor allen Dingen
bringst du keine Informationen durch die Baumtraversierung durch.
Visitor kannst du dann nehmen, wenn mit den Knoten unabhängig von allen
anderen Knoten etwas passieren muss.
Hast du den Fall nicht (und du hast den hier nicht: ein Knoten muss an
seinen Aufrufer den Namen der Variablen zurückgeben können, die er
temporär erzeugt hat), dann ist Visitor Overkill und verkompliziert die
Sache nur.
Die Einzelfunktionen bei den Klassen sind hingegen trivial:
Gibt es einen Linken Sohn, dann lass den auswerten und du kriegst den
Namen einer Variablen zurück. Gibt es einen rechten Sohn, dann lass den
auswerten und du kriegst von der Auswertung den Namen einer Variablen
geliefert. (*)
Bei einem Ident-Knoten brauchst du überhaupt nicht links/rechts
auswerten. Ganz im Gegenteil, die dürfen keinen linken/rechten Teilbaum
haben, sonst ist da was faul. Ein ident Node gibt einfach nur, den in
ihm gespeicherten Variablennamen zurück zur geschätzten Kentnisnahme des
Aufrufers, der etwas mit dieser Variablen machen wird.
(*)
D.h. ob es einen linken bzw. rechten Sohn gibt, weißt du ja auch, weil
du weisst in welcher Klasse du gerade operierst. Eine Addition muss
IMMER einen linken und einen rechten Teilbaum haben. Eine
Sinus-Berechnung wird nur EINEN Teilbaum haben (links oder rechts,
kannst du dir bei der Baumerzeugung aussuchen)
Karl Heinz Buchegger schrieb:> Moment.> Du hast für jeden Operationstyp einen eigenen Knotentyp?
Für jeden Operationstyp nicht.
So ist meine Struktur des AST (momentan ist alles public weil ich
vorhatte dass der visitor sich selbst modifizieren können sollte):
Basisklasse für alle Knoten:
1
public abstract class Node
2
{
3
public abstract void Accept(Visitor visitor);
4
}
Für arithmetische Ausdrücke diese Klasse, Op ist die Operation (+-/*):
1
public abstract class Expr : Node { }
2
3
public class BinExpr : Expr
4
{
5
public Op op;
6
public Expr left, right;
7
public BinExpr(Expr e1, Op o, Expr e2)
8
{
9
op = o;
10
left = e1;
11
right = e2;
12
}
13
14
public override void Accept(Visitor visitor)
15
{
16
visitor.Visit(this);
17
}
18
}
Oder meine Zuweisung
1
public class Assignment : Stat
2
{
3
public Obj left;
4
public Expr right;
5
public Assignment(Obj o, Expr e)
6
{
7
left = o;
8
right = e;
9
}
10
11
public override void Accept(Visitor visitor)
12
{
13
visitor.Visit(this);
14
}
15
}
Identifier:
1
public class Ident : Expr
2
{
3
public Obj obj;
4
public Ident(Obj o)
5
{
6
obj = o;
7
}
8
9
public override void Accept(Visitor visitor)
10
{
11
visitor.Visit(this);
12
}
13
}
Das ganze Modell könnte ich ja um weitere Methode EvaluateTree()
ergänzen.
Das schöne am Visitor ist finde ich, dass ist ich damit den Syntax-Baum
und die Codegenerierung voneinander trennen kann.
Ich werde einfach mal ausprobieren, momentan ist das alles noch
überschaubar sodass ein Weg in die falsche Richtung nicht weiter
tragisch ist.
Hallo Karl Heinz,
also vom Prinzip her funktioniert es mit dem Visitor wenn ich der Visit
Methode einfach einen string als Rückgabewert gebe.
Den Rest programmiere ich so wie du es in deinem Beispiel angegeben
hast.
Dann brauche ich auch nichts mehr mit "is" zu überprüfen, weil über die
Überladung der Methode immer die richtige zum Objekt des Astes
aufgerufen wird.
Meine Visitor-Ableitung zur Code-Generierung sieht dann beispielhaft so
aus:
1
public override string Visit(Ident ident)
2
{
3
return "#" + ident.obj.name;
4
}
5
6
public override string Visit(IntCon intCon)
7
{
8
return intCon.val.ToString();
9
}
10
11
public override string Visit(BinExpr binExpr)
12
{
13
string leftVar, rightVar, retVar;
14
leftVar = binExpr.left.Accept(this);
15
rightVar = binExpr.right.Accept(this);
16
17
Emit(Instruction.L, leftVar);
18
Emit(Instruction.L, rightVar);
19
switch (binExpr.op)
20
{
21
case Op.ADD:
22
Emit(Instruction.ADD_I);
23
break;
24
case Op.SUB:
25
Emit(Instruction.SUB_I);
26
break;
27
case Op.MUL:
28
Emit(Instruction.MUL_I);
29
break;
30
case Op.DIV:
31
Emit(Instruction.DIV_I);
32
break;
33
}
34
retVar = GenerateTemporaryVariable();
35
Emit(Instruction.T, retVar);
36
37
return retVar;
38
}
Wenn z.B. binExpr.left ein Ident Objekt ist, wird Visit() für Ident
aufgerufen usw.
Sieht doch erstmal schon nicht verkehrt aus, oder?
Danke nochmal für deine nützlichen Tips.
Sorry,
aber in alter Zeit gab es Lex und Yacc. Habe auch schon vor langer Zeit
die Äquivalente in Java gesehen. Die Grammatik beschreiben, durch die
Generatoren jagen und dann kommen Klassen raus. Ich würde nicht auf die
Idee kommen, das ganze händisch in prozeduralen Sprachen oder in
Objektorientierung zu realisieren.
Es geht doch nichg um Lex und Yecc oder irgeneinen anderen
Compilergenerator. Es geht jetzt darum Instruktionen für eine Maschine
zu erzeugen, die, wenn sie die Instruktionen abarbeitet eben genau das
ursprüngliche Programm abarbeitet.
Der Syntax Teil ist schon lange erledigt. Jetzt wird Code erzeugt!
Und wenn man dann irgendwann mal die ersten Optimizer implementieren
will, dann braucht man dann eben für arithmetische Ausdrücke erst mal
eine Baumdarstellung. Optimierungen sind dann "einfach" nur
Baumtransformationen.
Momentan ist meine Sprache noch ohne Datentypen (bzw. ist alles Integer)
und hat ungefähr den Umfang von PL/0.
Die Quellsprache ist diese hier:
http://de.wikipedia.org/wiki/Strukturierter_Text
und hat natürlich alles mögliche an Datentypen.
Ich weiß auch noch nicht an welcher Stelle ich die Datentypen ins Spiel
bringe. Da in der Sprache viel mit expliziter Typkonvertierung
gearbeitet werden muss könnte man das meiste schon im Parser
unterbringen. Das hätte auch beim Erzeugen der eventuellen
Fehlermeldungen Vorteile, denn wenn ich die Datentypen erst bei der
Codegenerierung aus dem Syntaxbaum prüfe, müsste ich in diesen die
Zeilen-/Spaltennummern mit hineinnehmen damit es nachvollziehbare
Fehlermeldungen gibt.
Außerdem reicht dann meine bisherige Vorgehensweise mit dem string als
Rückgabewert meines Visitors nicht mehr aus. Da müsste ich den Datentyp
noch mit integrieren.
P.S.
Ursprünglich war mein Vorhaben, mir ein kleines Tool zur
Quellcode-Dokumentation wie Doxygen oder Javadoc für die o.g. Sprache zu
schreiben. Hab dann aber gemerkt dass es nicht viel bringt da ganz ohne
Ahnung vom Thema Compilerbau ranzugehen. Darum erstmal einen Schritt
zurück und bei den Grundlagen anfangen ;)
Außerdem ist es ein interessantes Thema, und durch die viele Rekursion
eine andere Programmierung als die man (ich) sonst so benutze.
Thomas W. schrieb:> Ich weiß auch noch nicht an welcher Stelle ich die Datentypen ins Spiel> bringe. Da in der Sprache viel mit expliziter Typkonvertierung> gearbeitet werden muss könnte man das meiste schon im Parser> unterbringen. Das hätte auch beim Erzeugen der eventuellen> Fehlermeldungen Vorteile, denn wenn ich die Datentypen erst bei der> Codegenerierung aus dem Syntaxbaum prüfe, müsste ich in diesen die> Zeilen-/Spaltennummern mit hineinnehmen damit es nachvollziehbare> Fehlermeldungen gibt.
Genau so wirds auch gemacht.
Im Baum sind die Konvertierungen ganz einfach weitere Knoten, werden
also wie arithmetische Operatoren aufgefasst.
> Außerdem reicht dann meine bisherige Vorgehensweise mit dem string als> Rückgabewert meines Visitors nicht mehr aus. Da müsste ich den Datentyp> noch mit integrieren.
Nicht nur das.
Du brauchst eine generelle Beschreibung (Klasse) für einen Wert. Ein
'Value' hat dann nicht nur einen Zahlenwert (im Falle einer Konstanten)
sondern auch einen Datentyp.
D.h. dort, wo du jetzt mehr oder weniger einfach nur einen String hast,
brauchst du dann ein Objekt dieser Value Klasse, welches dir alle
Eigenschaften eines Ergebnisses beschreibt.
Auch deine Operatoren werden dann erweitert werden müssen. An einen
Operator sind dann nicht nur die Operanden (in Form von Verzeigerungen)
geknüpft sowie die eigentliche Operation, sondern der Operator hat dann
selber wieder einen Ergebnisdatentyp (der vom Knoten über ihm
ausgewertet werden muss)
Stell dir einfach vor, du müsstest im Baum an jedem Knoten den
jeweiligen Datentyp des Ergebnisses dazuschreiben. Dann folgt alles
weitere daraus.
int i;
int x = 3.5 * i;
wie siehst der Baum für diesen Ausdruck aus?
Assign
|
+-------+-------+
| |
Ident Op *
x |
+------+------+
Const Ident
3.5 i
Jetzt werden die Knoten des Expression Trees erweitert um Datentypen.
Erst mal die, die unmittelbar bekannt sind (ergibt sich sowieso aus der
rekursiven Abarbeitung. Die bekannten Datentypen sitzen immer an den
Blättern und durch die Rekursion geht dort die Abarbeitung los)
Assign
|
+-------+-------+
| |
Ident Op *
x
int |
+------+------+
Const Ident
3.5 i
double int
Baum durcharbeiten. In einem Aufwasch kann jetzt erledigt werden:
Wo müssen Konvertierungen rein, bzw. welches sind die Datentypen der
Operatoren?
In der Rekursion stösst man irgendwann auf das "Op *". Der linke
Teilbaum hat Datentyp double, der rechte hat Datentyp int. Das passt
nicht. Also muss der rechte Teilbaum auf double gebracht werden. Diese
Konvertierung fasst du als ganz normalen Operator auf. So wie es auch
der Op * war. Dieser Operator führt die Konvertierung durch. Er wandelt
einen int in einen double. Sein Eingangs-teilbaum muss also vom Typ int
sein, der Operator-Knoten selbst hat dann den Eregbnisdatentyp double:
Assign
|
+-------+-------+
| |
Ident Op *
x
int |
+------+------+
Const |
3.5 Op int->double
double double
|
Ident
i
int
Jetzt sind beide Teilbäume vom Op * vom gleichen Datentyp und damit
steht auch der Ergebnisdatentyp des Op * fest: der ist double
Assign
|
+-------+-------+
| |
Ident Op *
x double
int |
+------+------+
Const |
3.5 Op int->double
double double
|
Ident
i
int
In der Rekursion gehts weiter nach oben und man landet beim Assign.
Wieder die Fragestellung: Datentyp links? Datentyp rechts? Sind die
identisch?
Nein, sind sie nicht: links ist ein int, rechts ein double. Also muss da
was passieren. Der double muss in einen int umgeformt werden.
Und wieder kommt ein Konvertieroperator zum Einsatz.
Assign
int
|
+-------+-------+
| |
Ident Op double->int
x int
int |
Op *
double
|
+------+------+
Const |
3.5 Op int->double
double double
|
Ident
i
int
Jetzt passt es. Jetzt hast du den vollständigen Baum, der die komplette
Operation
x = 3.5 * i;
in all ihren Details beschreibt. Die Codegenerierung muss ihn nur noch
durchackern und die entsprechenden Instruktionen erzeugen. (Beachte
auch: Der Baum sagt der Codegenerierung zb auch, dass der Op * als eine
double Multiplikation durchzuführen ist, oder dass beim Assign ein int
zugewiesen werden muss. Die Codegenerierung muss also keine eigene Logik
mehr dafür haben. Alles was sie braucht, findet sie im Baum schon fix
fertig zur Verwendung ausgewertet)
(Die Konvertierknoten kannst du natürlich auch schon während der
Syntaxanalyse einfügen, sofern sie bekannt sind.)
Thomas W. schrieb:> Hab dann aber gemerkt dass es nicht viel bringt da ganz ohne> Ahnung vom Thema Compilerbau ranzugehen. Darum erstmal einen Schritt> zurück und bei den Grundlagen anfangen ;)
Ich geb zu: Ich bin befangen.
Drumm sag ich: gute Entscheidung!
Zudem ist es lohnend.
Dinge wie Protokollanalyse bzw. Command Line Interfaces können wunderbar
mit den Techniken im Compilerbau erschlagen werden.
Dinge wie Expression Tree und wie man mit ihm arbeitet schulen ungemein
beim Umgang mit Bäumen bzw. (was zangsläufig damit zusammenhängt) dem
Umgang mit rekursiven Funktionen.
Ob dein Klassenaufbau, Ableitungen sinnvoll sind oder nicht, lässt sich
relativ leicht sagen: Fallen die Einzelteile deines Compilers wie
Puzzleteile ineinander, sind die Funktionen kurz, dann passt der Aufbau
meistens.
Ausserdem schult es das Verständnis für Fehlermeldungen deines richtigen
Compilers, wenn man ein wenig Ahnung hat, wie so eine Übersetzung läuft.
Weiter Baumoperationen sind zb. Constant-Folding.
Ein Teilbaum der Form
Op +
int
|
+--------------+
Const Const
3 4
int int
kann durch einen anderen Teilbaum
Const
7
int
ersetzt werden, indem der Compiler selbst die Addition ausrechnet. Auch
das ist wieder nichts anderes als ein Post-Order Baumtraversierung
(damit die Optimierung von den Blättern zur Wurzel läuft) bei der unter
Umständen in einem Knoten Teilbäume gelöscht werden und der Knoten gegen
einen anderen Knoten ausgetauscht wird.
In einem Op + wird der linke Teilbaum untersucht: ist es eine Konstante?
es wird der rechte Teilbaum untersucht: ist es eine Konstante?
Wenn beide male die Antwort ja lautet (und zb das ganze eine
int-Addition ist), dann wird der Op + gegen einen Const Knoten
ausgetauscht.
Eh voila: Schon ist in deiner Programmiersprache ein
int SekundenProMinute = 60 * 60;
kein Thema mehr. Der Compiler ersetzt das durch
int SekundenProMinute = 3600;
Eine Operation
Op double->int
int
|
Const
7.5
double
kann ebenfalls schon vom Compiler durchgeführt werden. Und, und, und. Da
fallen dir sicherlich noch viele andere Operationen ein, die vom
Compiler auf dem Baum durchgeführt werden können und die gemeinhin unter
das Stichwort 'Optimierung' fallen. Und wenn nicht: einfach ein wenig im
erzeugten Code schmökern. Da fallen einem dann noch zig Möglichkeiten
auf.
Karl Heinz,
deine Diagramme mit den zusätzlichen Datentypen sind wirklich sehr
hilfreich gewesen, vielen Dank nochmal.
So habe ich es jetzt programmiert, und es macht alles einen schlüssigen
Eindruck. Eine Typkonvertierung gibt es als eigenes Objekt und wird
direkt beim Parsen passend in den Syntaxbaum eingebaut. Alle Klassen die
von Expression abgeleitet sind haben einen Datentyp für den
Rückgabewert.
Für Statements ist das ja nicht notwendig, da kein Wert zurückgegeben
wird.
Mit der Codeoptimierung weiß ich aber noch nicht weiter. Momentan mache
ich das soweit es geht im generierten Ziel-Code, das ist dort aber nicht
ganz so einfach.
Zur Optimierung im Syntax-Baum müsste ich wohl doch mein Visitor-Konzept
über Bord werfen (hattest du ja schon prohezeit), auch wenns mir bis
hier hin gut dafür gepasst hat.
Thomas W. schrieb:> Zur Optimierung im Syntax-Baum müsste ich wohl doch mein Visitor-Konzept> über Bord werfen (hattest du ja schon prohezeit), auch wenns mir bis> hier hin gut dafür gepasst hat.
Siehs mal so:
Ein Optimierer auf dieser Ebene ist auch nichts anderes als ein Visitor,
der im Baum nach 'Mustern' sucht und diese Muster durch andere ersetzt.
Das einzige was jetzt ein wenig anders ist: So ein Muster kann auch aus
mehreren Knoten bestehen.