
Hallo :) Wie im Titel schon angekündigt möchte ich ein Stimmgerät mit einem AVR (vermutlich ein ATTiny) bauen. Das Problem ist nur die erkennung der Grundwelle, also ein mathematisches Problem. Das Signal was der AVR reinbekommt, sieht in z.b. so aus wie im Anhang. Die roten Markierungen sind genau eine Periode (ca 12mS, 82Hz). Die Frage ist jetzt, wie kann ich so ein Signal erkennen? Das Gerät soll nachher nur "zu hoch" oder "zu tief" ausgeben, allerdings von selber erkennen welche saite den gemeint war. Dazu müsste ich die Frequenz der Grundwelle kennen, aber eine FFT ist mit den begrenzen Ressourcen vermutlich nicht drin. MfG Akkubohrer
Angehängte Dateien:
-

signalform.png
7,3 KB
Der Königsweg dazu ist per linearer Prädiktion. Die gibt Dir dann die Grundfrequenz als Prädiktionsfehler aus. Da gibts einen Algorithmus, der die Parameter itterativ bestimmt, der könnte hier auch funktionieren.
Ach ja, falls Du nur ein Stimmgerät bauen willst, kannst Du auch einfach das Signal heruntermischen. Für jedes Sample x machst Du dann: a=x*sin(2*pi*f*t) b=x*cos(2*pi*f*t) Und tiefpasst dann die Signale a und b. f ist die Frequenz die Du suchst. A und b kannst Du als Drehzeiger ansehen. Hat das Eingangssignal eine Komponente bei f, so ändert sich sein Winkel nicht. Gibt es einen Unterschied, so dreht sich der Zeiger in eine Richtung die vom Vorzeichen des Unterschiedes abhängig ist. Wenn Du also den Winkel grob bestimmst, kannst Du sehen ob er größer oder kleiner wird, oder gleich bleibt. Damit bestimmst Du aber nicht die Grundfrequenz, sondern nur einen Anteil bei einer bestimmten Frequenz.
Hui das hört sich beides schonmal sehr interessant an, ich werde dieses WE mal in diese Richtung recherchieren :) Zur misch-methode: Kann man nicht einfach die Frequenz f solange anpassen bis der Zeiger nicht mehr wandert und hat damit die gesuchte Frequenz?
eine DFT wäre viel zu aufwändig, zumal ich die Frequenz ja damit nicht ausbekomme sondern nur wie stark die jeweilige Frequenz drin vertreten ist.
Es gibt schon Ansätze für FFT auf dem AVR (gidf), das sollte niocht das Problem sein. Und zur Frage der Grundfrequenz: Sind Harmonische nicht einfach vielfache der Grundfrequenz? -> Grundfrequenz = niedrigste freq. in dem mischmasch...
Der Vorschlag mit dem mischen ist an sich nur ein herausfiltern einer Frequenz. Dabei ist nicht sicher das man auch wirklich die Grundfrequenz findet, und nicht eine Oberwelle. Auch muss man damit immer noch probieren, und an sich ist das auch nicht mehr als die DFT für je eine Frequenz. So einfach ist das suchen der Grundfrequenz nicht. Die DFT ist da schon ein guter Ansatz und auch mit einem µC noch zu machen, braucht aber schon leicht etwas mehr RAM als ein Tiny.. bietet. Wegen des eher begrenzten Speichers und damit geringen Sampelzahl ist aber die Auflösung eher schlecht. Das reicht also nur um damit grob die Frequenzen zu finden und dann die Grundfrequenz als kleinsten gemeinsamen Teiler zu finden. Die Grundfrequenz selber muss im Extremfall nicht einmal vorhanden sein. Für die genaue Bestimmung der Frequenz braucht es dann aber noch eine andere Methode: mit einem groben Schätzwert als Ausgangspunkt kann man dazu z.B. die Korrelationsfunktion direkt berechnen, für 2 Blöcke (z.B. je 50 Punkte) mit etwas mehr Abstand (z.B. ca. 100 ms).
Der Markt der Stimmgeräte wird praktisch nur von einer einzigen Firma beherrscht. Schau dir ihre Patente an, öffne eines ihrer Geräte. Viel ist da nicht drin bei dem Preis.
Hallo Akkuboherer, kannst Du sagen, in welchem Frequenzbereich die Grundtöne liegen? fmin? fmax?
chris schrieb: > die Grundtöne Es ist erstmal nur ein Grundton. Laut Kommentar im Audacity-Screenshot liegt die Periodenzeit bei 12ms, also ist die Grundfrequenz 83,3Hz. Das ist in etwa der Ton E in der zweiten Oktave unterm Kammerton A mit 440Hz. mfg mf
Dann würde ich folgendes Verfahren vorschlagen: 1. Signal Tiefpassfiltern ( Beitrag "Grenzfrequenz digitaler Tiefpass" ) lässt sich sehr effizient mit Shift Operationen berechnen, gut für Attiny 2. Nulldurchgänge des resultierenden Signals zur Bestimmung der Periodendauer verwenden. Das ist vielleicht nicht der übliche Weg in der Signalverarbeitung, dürfte aber für den Attiny mit seinem kleinen Speicher und dem fehlenden Multiplizierer am geeignetsten sein.
P.s. könntest Du ein kurzes WAV-File des Signals posten?
Hallo :) Erstmal vielen Dank an die zahlreichen Helfer hier, super! Die Frequenzen der gestimmten Gitarre werden > 82,41 Hz > 110,0 Hz > 146,8 Hz > 196,0 Hz > 246,9 Hz > 329,6 Hz sein. Ein einfacher Tiefpassfilter hilft da nicht, da z.b. die 3te Oberwelle von 82,41 Hz genau 329,6Hz ist. Wenn ich jetzt die Frequenz 329,6Hz herausfiltere hilft das noch nicht wirklich weiter. Ein Tiefpassfilter der alles über 400Hz abschneidet wäre zwar hilfreich ein sauberes Signal zu bekommen, allerdings ist er alleine noch nicht die Lösung. Aber der Filter ist ja ziemlich sparsam was Rechenoperationen angeht, bei 20Mhz sollte das kein Problem sein. WAV-File kann ich am Montag hochladen, im Augenblick befinde ich mich ca 100km von meinem Hauptrechner entfernt. Könnte man nicht das Signal auf 1 Bit reduzieren um es paltzsparend zu speichern und dann mittels Autokorrelation die Frequenz suchen? Oder geht bei der Reduktion zuviel Information verloren? MfG Akkubohrer
Hier gibts Lesestoff ... https://instruct1.cit.cornell.edu/courses/ee476/FinalProjects/s2004/ddb25/complete2.htm
Ich wundere mich immer wieder, wie es Leute schaffen, sich für ein Problem die ungünstigste Lösung zu suchen, obwohl deutlich bessere, aber nicht wesentlich teurere Alternativen existieren. In diesem Fall: dsPIC33EP64GP502: 28 Pins, gibts auch in DIL, kostet etwa 4-5 Euro in Einzelstückzahlen, läuft mit 70 MHz Instruktions-Takt, hat spezielle DSP-Erweiterungen, zwei 40-Bit Akkus, Bit-reverse und Module-Adressierungsarten für FFT und ähnliches, flexiblere Peripherie, 12 Bit ADC. Warum sich mit was schlechterem herumschlagen? Die 44-Pin-Version von den Teil gibts für 4.95€ bei Reíchelt. fchk
Frank K. schrieb: > Ich wundere mich immer wieder, wie es Leute schaffen, sich für ein > Problem die ungünstigste Lösung zu suchen, obwohl deutlich bessere, aber > nicht wesentlich teurere Alternativen existieren. Ja, wobei man das natürlich genauso gut mit einem AVR machen kann, wenn man bei diesem bleiben will. Für einen größeren AVR ist eine FFT genauso wenig ein Problem wie für deinen dsPIC, Beispiele dafür gibt's genügend. Warum man sich (sofern man nicht gerade 100000 Stück davon verkaufen will) dann unbedingt den allerkleinsten Controller antun muss, ist mir auch nicht klar.
Das ganze auf einem Attiny13 ist aber eine schönere Herausforderung. Da muss man richtig nachdenken. Hallo Akkubohrer, hast Du das Wav-File?
chris schrieb: > Das ganze auf einem Attiny13 ist aber eine schönere Herausforderung. Ließe sich allerdings noch übertreffen, indem man versucht, es auf einem ATtiny5 zu implementieren. =:-)
Jörg Wunsch schrieb: > Ließe sich allerdings noch übertreffen, indem man versucht, es auf > einem ATtiny5 zu implementieren. =:-) [ironie] Ja mit den üppigen 32 Byte RAM lässt sich das mit Sicherheit implementieren. [/ironie] :) Gruß Oliver
Hallo und tschuldigung für die Verspätung ;) Hier das versprochene file. es muss ja kein ATTiny13 sein, das wäre schon arg klein. Eher ein ATTiny85, das macht schon unglaubliche 512 Byte :)
Akkubohrer, ist Dir klar, dass ein atMega einen 8x8Bit = 16Bit HW Multiplizierer hat? Das ist ein sehr gutes Argument für einen atMega.
Akkubohrer schrieb: > e-a-d-g-b-e.mp3 Super. Dir ist klar, dass es zig verschiedene MP3-Decoder da draußen gibt und jeder davon eine andere Waveform generiert? MP3 ist _kein verlustloses_ Kompressionsverfahren. Stell dir vor, du lädst jeden, der hier mitschreibt, zu dir ein, er soll ein Foto von deinem Auto machen. Naja, ist doch dasselbe Auto wirst du sagen... Kommt also ungefähr dasselbe bei raus. Grund ist, dass vielleicht noch die Frequenzen des Signals richtig abgebildet werden können. Aber die Phasenlage macht auch noch ihriges. Wir wollen ein unkomprimiertes oder ein verlustfrei komprimiertes Signal! mfg mf
>Super. Dir ist klar, dass es zig verschiedene MP3-Decoder da draußen >gibt und jeder davon eine andere Waveform generiert? MP3 ist _kein >verlustloses_ Kompressionsverfahren. Eigentlich hätte ich gerne ein Wav-File gehabt. Aber Spektrum der MP3 Aufnahme dürfte nich so unterschiedlich sein.
Angehängte Dateien:
-

Bildschirmfoto.png
24 KB
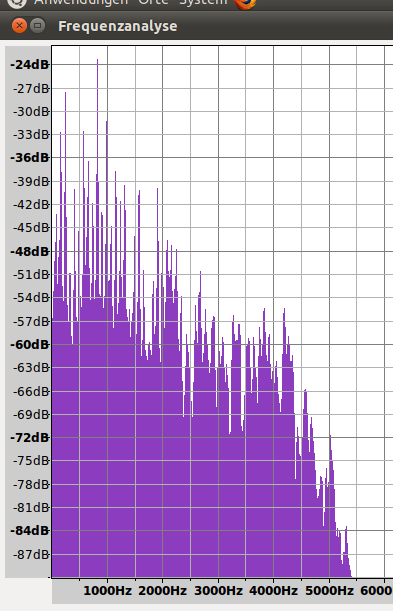
Hier das Spektrum des TON-e mit Audacity gemacht. Die Amplitude der harmonischen scheinen weit über der Grundfrequenz zu liegen.
Hier die .WAV Version. Es ist etwas groß und ich wollte nicht von Falk einen auf den Deckel wegen der Dateigröße bekommen.
Akkubohrer schrieb: > Es ist etwas groß und ich wollte nicht von Falk > einen auf den Deckel wegen der Dateigröße bekommen. Nee, es sind ja nützliche Quelldaten zur Analyse. Vielleicht gibt es ja ein Wavelet zum drüber falten, das das Ganze einfacher macht. mfg mf
Ich werde mal dieses Wwochenende die ganzen Tipps versuchen umzusetzen (erstmal in einem C-Demoprogramm, zwecks besserem Debugging), am meisten Hoffnung habe ich noch für die Autokorrelation. Ich melde mich sobald es Ergebnisse gibt :) Bis hierhin schonmal vielen Dank an alle die mir bisher geholfen haben. Klasse!
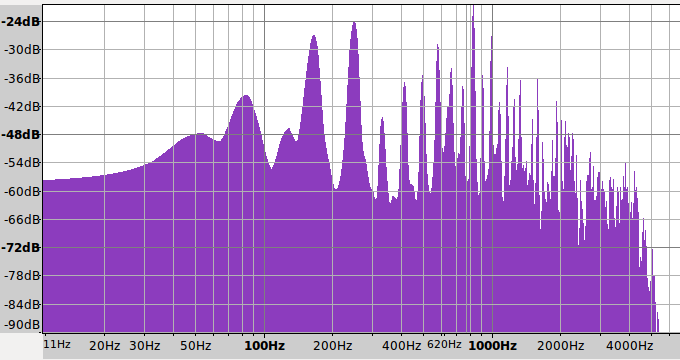
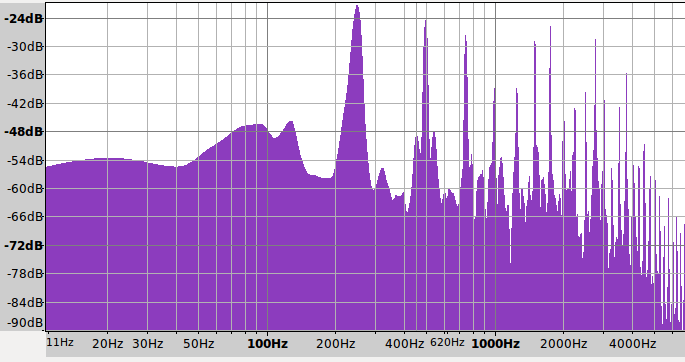
>Ich werde mal dieses Wwochenende die ganzen Tipps versuchen umzusetzen >(erstmal in einem C-Demoprogramm, zwecks besserem Debugging) Du hast Recht, zuerst sollte man den Algorithmus offline entwickeln. Allerdings wären meiner Meinung nach Matlab ( oder als Open Source "Octave") besser geeignet. In den Spektren der Signal fällt mir folgendes auf: Beim niedrigen TonE ist ist die Grundfrequenz ( 82Hz ) um 20dB schwächer als die Frequenz der ersten harmonischen ( 164 Hz ) und der noch höheren Frequenzen. 20dB bedeutet, dass die Amplitude der gesuchten Grundfrequenz um den Faktor 10 schwächer ist. Das Verhältnis wird beim TonB deutlich besser. Die Schwäche beim TonE könnte vielleicht aus dem Frequenzgang deines Aufnahmegerätes resultieren. Die Frage wäre, ob man für den TonE auch die erste harmische zum "Stimmen" verwenden könnte.
Bei der Gitarre liegen die Obertöne etwas neben der mathematischen Harmonischen. Ist bei Quarzen ja genauso.
Nach einigem Nachdenken sind mir noch ein paar Ideen zum Algorithmus gekommen. 1. eine FFT ist nicht notwendig Für die Maximumsbestimmung eines Peaks werden nur 3 Frequenzpunkte benötigt: Ein Punkt genau auf der gesuchten Frequenz sowie jeweils ein Punkt links und rechts daneben. Mit diesen 3 Punkten sollte sich durch Interpolation das Maximum bestimmen lassen und damit auch die Frequenzverschiebung. 2. Die drei Frequenzpunkte können mit dem Görtzel Algorithmus bestimmt werden bzw. mit dem Verfahren welches weiter obeben beschrieben wurde ( das Heruntermischen ). Also: Multiplikation jedes Abtastwertes mit Sinus und Cosinuns und daran angehängter Tiefpassfilterung und danach geometrische Betragsbildung aus den beiden Werten. 3. Wie man im Spektrum sieht, wäre vor der AD-Wandlung ein guter Tiefpassfilter vorteilhaft. Damit lassen sich die hochfrequenten Harmonischen unterdrücken. Dann kann man mit der Abtastfreuqenz herunter gehen und hat mehr Rechenzeit für die Signalverarbeitung.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.