sodaß die Daten in die ausführbare Datei einkompiliert werden, was auch
Ziel der Sache ist, da ich nicht auf externe Daten zugreifen kann und
will.
Mache ich das Ganze allerdings mit ein paar Daten mehr (so 10000
structure-Einträge) schießt die Kompilierzeit (hier mit dem MS
VC-Compiler) ins unermeßliche (die .h-Datei ist so ca. 2MB groß und er
kompiliert jetzt seit gut 40 Minuten).
Kennt jemand eine effiziente Möglichkeit, diese konstanten Structures
mit Werten zu befüllen, daß am Ende trotzdem alles in einer ausführbaren
Datei bleibt?
Viele Grüße
Nicolas
lagere doch die Daten in eine Datei aus und laden sie zur laufzeit. Es
ist doch sinnlos jedesmal eine neue Programm zu bauen, nur weil sich
daten ändern.
Peter II schrieb:> lagere doch die Daten in eine Datei aus und laden sie zur laufzeit. Es> ist doch sinnlos jedesmal eine neue Programm zu bauen, nur weil sich> daten ändern.
Das ist genau das Gegenteil von dem, was ich will. Ich habe keinen
Dateilademechanismus zur Verfügung (kein Dateisystem). Auch kein EEPROM
oder sonstwie addressierbaren externen Speicher. Dafür bleiben die Daten
dauerhaft konstant. Die Structures sind nur ein Vehikel, weil das
Auslesen dann sehr komfortabel und übersichtlich geht.
Nicolas S. schrieb:> Das ist genau das Gegenteil von dem, was ich will. Ich habe keinen> Dateilademechanismus zur Verfügung (kein Dateisystem).
du bist hier aber in bereich "PC-Programmierung" und dort gibes
Dateisystem und ladefunktionen.
Man könnte als es obj-Datei direkt in den linker vorgang übernehmen,
dann musst aber es aber selber noch in die Structur überführen.
Bei 10'000 Codezeilen sollte die Compilierzeit auf einer halbwegs
modernen Maschine längst nicht so gross sein. Deine Variante ist also
schon ok. Ich vermute mal, dass der Präprozessor oder der Compiler sich
aus irgend einem Grund verrennt. Mehr kann ich dir aber beim besten
Willen nicht helfen.
Peter II schrieb:> lagere doch die Daten in eine Datei aus und laden sie zur laufzeit. Es> ist doch sinnlos jedesmal eine neue Programm zu bauen, nur weil sich> daten ändern.
Man kann auch umgekehrt argumentieren. Warum eine Laderoutine bauen,
wenn sich die Daten sowieso nur selten ändern.
um auszuschließen, daß der Compiler sich an einer fehlerhafen Zeile
verrennt. Außerdem besteht mein Testcode nur noch aus dem Deklarieren
und Instanzieren dieses Structures, um Nebeneffekte auszuschließen.
Bei ca. 500 Zeilen geht das Ganze auch noch recht zügig vonstatten, bei
mehr als 10000 Zeilen (Headerdatei über 1,2 MB) ist die Kompilierzeit
immer noch bei mehr als 20 Minuten (danach abgebrochen). Der Rechner ist
"schnell genug mit ausreichend Hauptspeicher (TM)". Also scheint die
Methode nicht so toll geeignet zu sein.
Viele Grüße
Nicolas
P.S.: Im "Orignal" steht natürlich
Nicolas S. schrieb:> Das ist genau das Gegenteil von dem, was ich will. Ich habe keinen> Dateilademechanismus zur Verfügung (kein Dateisystem). Auch kein EEPROM> oder sonstwie addressierbaren externen Speicher.
Ähm blöde Frage, aber was ist das für ein seltenes Zielsystem das genug
Speicher hat für Deine Aktion, für das mit MS VC compiliert wird, aber
das keinerlei Zugang zu einem Dateisystem haben soll? Nicht mal zu ner
SD-Card? Das kann doch jeder poplige 4-Bit-Mikrocontroller, wenn man ihm
eine dranlötet ;-)
Das sieht so aus, als ob sich der Compiler beim Optimieren einen
abbricht. Vielleicht versucht er, konstante Werte direkt in den
Assemblercode zu übernehmen, wenn er beim Compilen schon weiss, welches
struct-Element benutzt wird.
Falls dem so ist, lagere die Variablendefinition in eine eigene Datei
aus, die als separate Objektdatei gelinkt wird:
getier.h
Wozu erst mal ein 2GB Makro anlegen, das kein Mensch braucht?
#include ist #include: Der Inhalt des Files wird an der Stelle
reingezogen, an der der #include steht. Und erst dieses Endergebnis muss
gültigen C Code ergeben. Kein Mensch schreibt vor, was in einem
#includiertem File stehen muss.
Man kann auch so programmieren
1
#include"int.inc"
2
#include"main.inc"
3
#include"LeftParen.inc"
4
#include"RightParen.inc"
5
#include"LeftBrace.inc"
6
#include"RightBrace.inc"
und zusammen mit den entsprechenden zu includierenden Files
int.inc
Der GCC braucht bei mir auf einem schon etwas betagteren Laptop für die
10000 Einträge 0,6 s. Die Headerdatei nach deinem Muster ist aber nicht
2 MB, sondern nur 580 kB groß. Trotzdem ist das ein riesiges Makro, was
dem MS-Compiler (bzw.Präprozessor) durchaus Schwierigkeiten machen
könnte. Deswegen würde ich auch den Weg von Karl Heinz vorschlagen.
Hallo zusammen,
am Präprozessor liegt es wahrscheinlich nicht, da die Kompilierdauer für
ein direktes Einsetzen im C-Quelltext ziemlich gleich ist.
Ich habe jetzt auf folgenden (lauffähigen) Quelltext gekürzt:
1
// MEX_loadgetier.c
2
/* Test fuer das Kompilieren grosser Structures: Liegt hier der Flaschenhals? */
3
4
#include "mex.h"
5
#include "string.h"
6
#include "getier.h"
7
8
typedef char boolean;
9
typedef enum {reich,
10
stamm,
11
klasse,
12
ordnung,
13
familie,
14
gattung,
15
art } viecher_t;
16
17
typedef struct {
18
const char* name;
19
const char* zeugs;
20
boolean tot;
21
unsigned int beine;
22
viecher_t viech;
23
double masse;
24
} Getier_t;
25
26
27
/* ********************* main ****************************** */
28
void mexFunction(int nlhs, mxArray *plhs[],
29
int nrhs, const mxArray *prhs[]) {
30
31
const Getier_t Getier[] = GETIER;
32
return;
33
}
die Includedatei "getier." wird automatisch erstellt und sieht so aus:
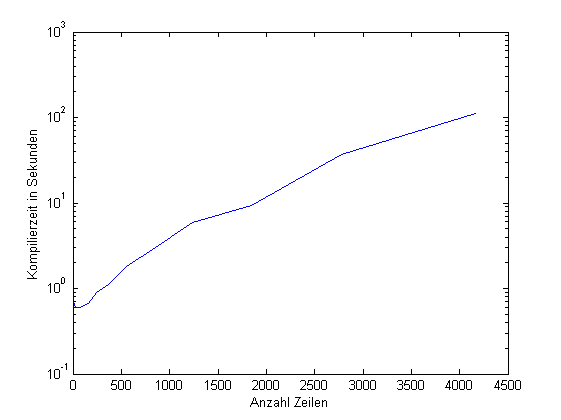
und das Ergebnis ist die Kompilierzeit im Verhältnis zur Anzahl der
Zeilen im includefile (siehe Bild).
Ich schaue mal, ob der Verlauf mit dem GCC reproduzierbar ist.
Viele Grüße
Nicolas
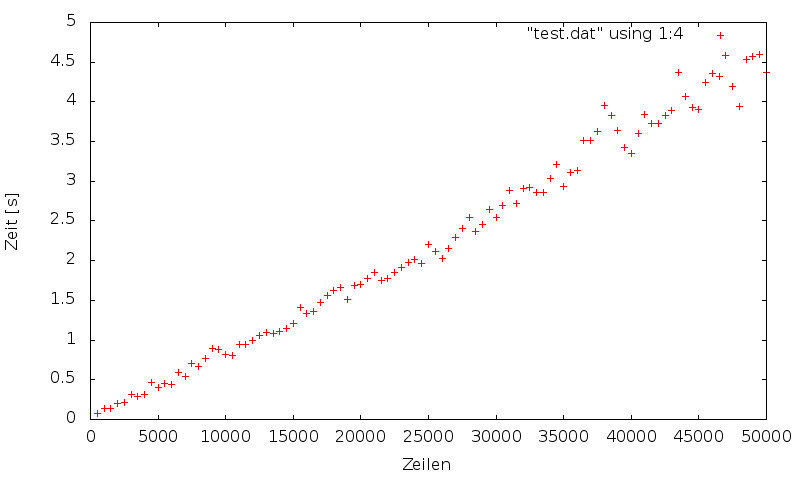
Hi
hier mal ein Test unter Linux/x64 bis zu 50k Zeilen und gcc 4.6.3. Man
beachte die unterschiedliche Skalierung der Y-Achse.
Lösung für das Ursprungsproblem:
Verwende den GCC :-)
Matthias
Warum wird das Objekt lokal angelgt? Sinnvoller wäre doch entweder
global oder zumindest mal lokal, aber static. Sonst muß ja der gesamte
Datenblock bei jedem Aufruf der Funktion erstmal auf den Stack kopiert
werden.
Hallo zusammen.
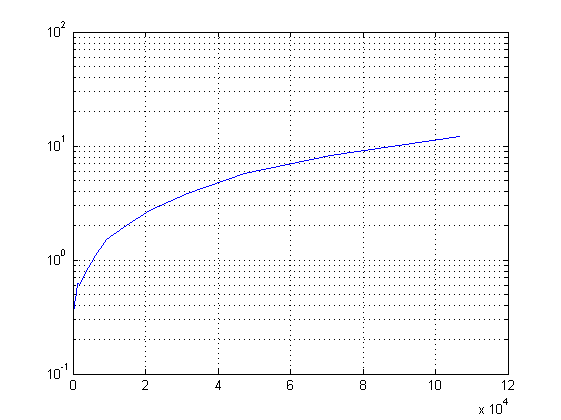
Tatsache: Der GCC (hier Version 4.6.2) verschluckt sich nicht so leicht
an größeren Headerdateien (siehe auch angehängtes Diagramm). Die
entstandene DLL ist auch etwas kleiner als der ursprüngliche Datensatz.
Jetzt bleibt natürlich die Frage offen, wie dem MSVC Vernunft
beizubringen ist - die Option, die Konstanten in einer fremdkompilierten
DLL unterzubringen will ich erst gar nicht in Erwägung ziehen - auch
genau aus dem Grund, den Rolf Magnus erwähnt: Die Konstanten werden nur
von main() des Hauptprogramms und nur beim Start benötigt, deswegen soll
das wenn möglich erst gar nicht im Speicher angelegt werden.
Vielen Dank für die interessante Diskussion
Nicolas
Nicolas S. schrieb:> deswegen soll> das wenn möglich erst gar nicht im Speicher angelegt werden.
da main immer aktiv ist, wird es sowieso in den speicher geladen. Da ist
kein unterschied zu einer globalen variable.
Nicolas S. schrieb:> Jetzt bleibt natürlich die Frage offen, wie dem MSVC Vernunft> beizubringen ist
Gibt es denn vernünftige Gründe dafür, gerade den MSVC zu verwenden,
wenn man in C programmieren will?
Nimm doch einen Compiler, der auch C99 unterstützt.
Mark Brandis schrieb:>> Gibt es denn vernünftige Gründe dafür, gerade den MSVC zu verwenden,> wenn man in C programmieren will?>
Wichtigster Grund ist für mich die Matlab-Unterstützung, der
zweitwichtigste, daß ich mit dem Debugger so langsam klarkomme.
Welcher Code wird denn da für g1, g2, g3 erzeugt — vorausgesetzt, wie
werden nicht wegoptimiert?
Für g1 gibt's 2 Möglichkeiten der Initialisierung:
1) Die Daten werden aus einem Literal ins RAM kopiert, z.B. im
Standard CRT-Code.
2) Der Compiler erzeugt einen "künstlichen" Constructor, der zur
init-Zeit aufgerufen wird, d.h. vor main. Der Code in einem solchen
Konstruktor funktioniert dann gemäß 4) oder 5)
Ditto für g2. Zusätzlich gibt's dafür noch die Möglichkeit
3) Ein Literal wird zur Load-Zeit vom Loader des OS' geladen,
ebenso wie der Programmcode auch. Ein Kopieren zur Init-Zeit
ist nicht nötig.
Für g3 gibt's folgende Möglichkeiten:
4) Der Kompiler erzeugt ein implizites Literal im read-only Bereich
und kopiert diese Daten, indem er in Implizites memcpy erzeugt.
5) Der Compiler erzeugt einzelne Instruktionen; jede Instruktion
initialisiert zB ein 8-, 16-, 32- oder 64-Bit Happen von g3.
Falls 5) verwendet wird, ist das natürlich sehr teuer, sowohl zur
Compilerzeit als auch zu Laufzeit, denn der Compiler muss zig
Instruktionen verwalten, compilieren, optimieren, ausgeben; evtl.
Constant-Pools anlegen und verwalten, in den Pools suchen, etc.
Ausserdem steigt die Codegröße linear mit der Größe des Objekts an.
GCC verwendet auch Mischformen zB 4) mit memset(0) und danach 5)
Bei GCC kann man all diese Strategiern beobachten; 5) allerdings nur
dann, wenn das zu initialisierende Objekt klein ist. Für Objekte, die
größer als ein paar Worte sind, nimmt er dann 4)
Weiterer Grund für die Langsamkeit kann wie gesagt PCH sein.
GCC kennt den Schalter -Q, der Auskunft über den Resourcenverbrauch auf
dem Host macht, ausgabe siehe unten.
Vielleicht gibt's sowas ja auch für den MSCV so daß man besser versteht,
wo die Zeit draufgeht.
Nicolas S. schrieb:> Wichtigster Grund ist für mich die Matlab-Unterstützung, der> zweitwichtigste, daß ich mit dem Debugger so langsam klarkomme.
Mach nen Call beim Hersteller auf, ist ja schließlich kein
Opensourcefrickel.
So nun wollte ich es auch selber mal wissen.
Ich kann es bei mir nachvollziehen das es langsam ist. Aber wenn man die
Variable globale macht, dann geht das ganze bei 100.000 einträgen in
2sekunden.
Das ganze lokal und damit auf dem Stack zu machen, ist für diese menge
an daten sowieso unpassend.
Hallo zusammen,
A. K. schrieb:> Was soll eigentlich der Spuk mit diesem Monster-Define? Warum nicht ein> ganz normales statisches Array mit Initialisierung?
ist es das nicht? Sobald das define ausgeführt ist steht doch nichts
anderes da ein statisches structure array. Die Auslagerung in ein define
ist nur eine Komfortfunktion, da es etwas kompfortabler ist, eine
.h-Datei zu erstellen mit define als in einem Quelltext nach einer
Textstelle zu suchen und ersetzen. Das Ganze struct ist nur eine
Komfortfunktion, um den Quelltext besser lesen zu können.
Peter II schrieb:> Ich kann es bei mir nachvollziehen das es langsam ist. Aber wenn man die> Variable globale macht, dann geht das ganze bei 100.000 einträgen in> 2sekunden.
Danke für den Tipp, muß ich mal ausprobieren, sobald ich meinen Kaffee
getrunken habe.
troll42 schrieb:> Darf man fragen was das werden soll? Klingt irgendwie spannend, so nach> universeller Tierchendatenbank...
Nein, das ist einfach ein hastig zusammengestricktes lauffähiges
Minimalbeispiel, um die Problemstellung möglichst anschaulich darstellen
zu können, sich nicht in Nebenschauplätzen des tatsächen Codes zu
verlieren und "nebenbei" sicherzustellen, daß das Problem überhaupt an
der Stelle ist, wo man es vermutet.
Viele Grüße
Nicolas
Nicolas S. schrieb:> A. K. schrieb:>> Was soll eigentlich der Spuk mit diesem Monster-Define? Warum nicht ein>> ganz normales statisches Array mit Initialisierung?>> ist es das nicht? Sobald das define ausgeführt ist steht doch nichts> anderes da ein statisches structure array. Die Auslagerung in ein define> ist nur eine Komfortfunktion, da es etwas kompfortabler ist, eine> .h-Datei zu erstellen mit define als in einem Quelltext nach einer> Textstelle zu suchen und ersetzen. Das Ganze struct ist nur eine> Komfortfunktion, um den Quelltext besser lesen zu können.
Du hast Karl-Heinz' Beitrag
Beitrag "Re: C - halbwegs große, konstante Structures" gelesen (und
verstanden)?
Nach dem Lesen Deines ersten Postings war auch dies mein erster Gedanke:
Solch riesige Textersetzungen macht "man" eigentlich nicht mit define's
(bzw. ist es gut vorstellbar, dass hier der Hase im Pfeffer liegt, da
die Textersetzung eigentlich nicht für derart große Strings ausgelegt
ist).
Ist zumindest viel wahrscheinlicher, als die Schuld beim Compiler suchen
zu wollen.
Hallo Patrick,
ich habe den Beitrag gelesen, verstanden und ausprobiert. Und keinerlei
meßbaren Unterschied in der Kompilierzeit in den Varianten mit und ohne
Defines festgestellt. Siehe hier:
Nicolas S. schrieb:> am Präprozessor liegt es wahrscheinlich nicht, da die Kompilierdauer für> ein direktes Einsetzen im C-Quelltext ziemlich gleich ist.
Wenn bei einer derartigen Reihe kein Unterschied feststellbar ist, gehe
ich davon aus, daß die diese Hypothese erst einmal verworfen werden
sollte.
Viele Grüße
Nicolas
Auch wenn es nicht Hilft, solltest du das ohne Define machen, das
verkompliziert doch die Sache nur... Hattest du meinen Link dir mal
angeschaut? Wenn die Daten wirklich konstant sind könnte man da ja auch
einmal ein OBJ draus kompilieren (dann dauerts halt ne Stunde...) und es
später einfach nur dazulinken (lassen).
Läubi .. schrieb:> Auch wenn es nicht Hilft, solltest du das ohne Define machen,
Es geht doch nur um einen Testfall um das Problem nachzuvollziehen —
das offenbar nix mit dem Define selbst zu tun hat.
Den Testfall aufzuhübschen macht den MSVC auch net schneller ;-)
Warum nicht einfach Resource-Dateien benutzen?
Die werden einfach vom Linker mit in die EXE kopiert. Die kannst du dann
ganz einfach auslesen, genau für sowas sind die doch da.