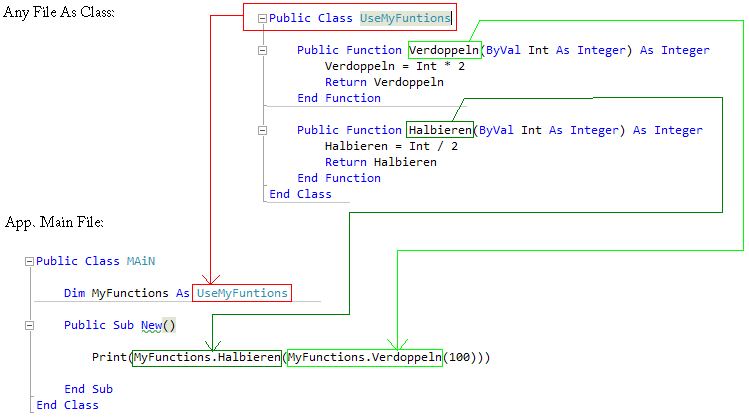
Hallo, ich beschäftige mich nun schon eine ganze Weile mit der großen Welt der µCs insbesondere Pic und Atmel, - darunter habe ich verschiedene Compiler und IDEs angeschaud, natürlich hunderte "hello worlds" mit den einzelnen Funktionen der µCs durchgetestet, etc... Bissher leider eher nur Basic / Bascom ähnliche Sachen, um einfache mini-Projecte / oder kleine Tools und Gadgets zu basteln. Nun bleib ich entschlossen beim AVR / AtmelStudio und bei GCC C, hab auch dazu einige HelloWorld´s durch, und viele Tutorials gelesen. Was C++ allgemein angeht, steh ich noch seeehr weit am Anfang, komm aber recht gut vorwärts... Hab nun ein paar allgemeine Fragen, zum OOP. Hab gelesen es gibt große Einschränkungen, inbesondere beim "Instanziieren" von Objekten zur Laufzeit. Also ich weiß, dass man aufpassen muss, wegen Ressourcen - man darf nicht zu viel verlangen... Zum teil wurde geschrieben, dass es überhaupt nicht möglich sei, z.B. eine Klasse innerhalb eines Namespaces zu schreiben, und dann darin (ganz normal) seine Funktionen reinzupacken, und diese Class bzw. das "Object" über die "Main" (ggf. auch mehrmals) zu instanziieren mit Constructer & Co für die Laufzeit, um anschließend deren Funktionen aufrufen zu können. Ich hoffe es ist klar was ich meine, also ich wollte mich von diesen "statischen Code-zusammen-klatschen" fernhalten, und eben nun auch auf dem µC etwas "weiter gehen"... Zu dem Bild, der Dateiname sagt es schon, also Des_Is_Des_Was_Ich_Meine_Aber_In_VB - wie wird das in GCC gelöst ? Habe dazu leider noch kein vernünfiges Tutorial gefunden, was OOP Klassen Objekte Abstrakte Datentypen Instance / Constructor / Destructor, etc.. enthält, und deren Handhabung und Syntax etc.. beschreibt. Durch die vielen verschiedenen Aussagen der vielen verschiedenen Artikel die ich gelesen habe, bin ich nun etwas ratlos. Ich hätte mir gerne diverse "Standard-Sachen" in paar Klassen gepackt. Habe schon einige dieser "Standard-Sachen" (uart, lcd, keys, etc) angeschaut, aber keine Klasse die ich bisher gesehen hatte wurde auf die beschriebene Art und Weise "instanziiert" sondern einfach nur "include´t", wenn ihr wisst was ich mein.. Desshalb wollte ich "ma eben" nachfragen, ob mir jemand einen Beispiel-Code geben kann, oder jemand ein (verständliches, kurzes und knappes) Tutorial kennt oder hat, was den OOP-Part mit AVR-GCC etwas erläutert? Im wesentlichen geht´s mir einfach um das im Bild beschriebene Beispiel. Gruß
Angehängte Dateien:
Tim S. schrieb: > Zum teil wurde geschrieben, dass es überhaupt nicht möglich sei, ... > (ganz normal) ... > OOP Klassen Objekte Abstrakte Datentypen Instance / Constructor > / Destructor, etc.. ... > aufrufen zu können. Tim S. schrieb: > Ich hoffe es ist klar was ich meine ... > kein vernünfiges Tutorial gefunden ... > "Standard-Sachen" ... > Desshalb wollte ich "ma eben" nachfragen, ob es überhaupt Sinn macht, weiterhin danach zu suchen, bzw. ob es überhaupt möglich und machbar ist, eigene "Objekte" zu instanziieren. Das muss doch in paar Zeilen Code erklärbar sein, bevor ich unzählige Tut´s nach einem Punkt absuche, der eventuell gar nicht zu finden ist... Gruß
Sie sollten auf jeden fall zuerst C und erst danach ++ lernen, ansonsten ist die chance zeugs zu verwechseln zu gross (malloc/free vs new/delete, references vs address-of operator etc). Wegen dem OO Da ist ein paper in dem das jemand komplett durchgebruetet hat: http://www.planetpdf.com/codecuts/pdfs/ooc.pdf Offensichtlich ist das meiste davon overkill aufm Mikrocontroller. Meist reicht es wenn man sein Zeugs einigermaßen sauber in structures verpackt und funktionen schreibt die damit was machen, aber prinzipiell spricht nichts dagegen, wenn man die structure mit function pointers vollpflastert, und so die methoden aufruft. Mit dem this pointer wird's vielleicht problematisch. Dyn Speicher Allokierung ist meist problematisch, also wird auf dem stack oder statisch/global instanziert.
asdf schrieb: > Sie sollten auf jeden fall zuerst C und erst danach ++ lernen, ansonsten > ist die chance zeugs zu verwechseln zu gross (malloc/free vs new/delete, > references vs address-of operator etc). Blödsinn! C++ und C sind verschiedene Sprachen, die man einwandfrei unabhängig voneinander lernen kann. Und wer malloc/free nie gelernt hat (weil er gleich ordentliches C++ lernt), der verwechselt da auch nix.
Mikrocontroller Programme sind in der Regel klein genug, um auch ohne C++ Objekte übersichtlich zu bleiben. C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM Speicher nicht gut zusammen passt. Es ist nicht schwer, Strukturen und Funktionen auch ohne OOP ausreichend eindeutige Namen zu geben. Und wenn dann doch mal ein Konflikt auftritt, benennst Du sie eben einfach um. SO macht man das normalerweise.
Stefan Frings schrieb: > C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM > Speicher nicht gut zusammen passt. Immer wieder behauptet, und trotzdem falsch. Identische Funktionalität per C oder C++ (objektorientiert) implementiert, ergibt am Ende so gut wie gleich großen Code. avr-gcc kommt halt ohne C++-Standardbibliothek, damit fehlen da alle Bibliotheksfunktionen und -operatoren, und über sowas wie std::vector sollte man auf einem AVR eh erst gar nicht nachdenken. new/delete fehlen zwar auch, lässt sich einfach selber implementieren, wenn man sie den unbedingt benötigt (was nicht sein muß), und dann geht eigentlich fast alles, was C++ erlaubt. Oliver
Mein Vorschlag lern erstmal C. Damit kommste beim Mikrocontroller programmieren deutlich weiter als mit C++. Solltest dir irgendwann C nicht mehr ausreichen ist es von C nach C++ auch nicht mehr weit. In C++ sind halt im groben die ganzen OOP Konzepte verpackt worden, strenggenommen könntest du selbst in C objektorientiert programmieren, aber das ist ja hier nicht die Frage. Falls es doch unbedingt C++ sein muss, benutz google und du findest tausende gute Tuts. Gruß Timo
Oliver schrieb: > Stefan Frings schrieb: >> C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM >> Speicher nicht gut zusammen passt. > > Immer wieder behauptet, und trotzdem falsch. Identische Funktionalität > per C oder C++ (objektorientiert) implementiert, ergibt am Ende so gut > wie gleich großen Code. Du meinst also, wenn eine Funktionalität wie "LED Blinkern" oder was auch immer implementiert wird, dann ergibt sich mit C und C++ immer die gleiche Codegüte, unabhängig davon jeweiligen Softwaredesign? Wohl kaum.
Johann L. schrieb: > Du meinst also, wenn eine Funktionalität wie "LED Blinkern" oder was > auch immer implementiert wird, dann ergibt sich mit C und C++ immer die > gleiche Codegüte, unabhängig davon jeweiligen Softwaredesign? Nein und das hat er auch nie behauptet. Der Unterschied kommt dann aber vom Design, nicht von der verwendeten Sprache. Die schlechtere Sprache zu waehlen, obwohl man in der besseren Alles machen kann, was auch in der schlechteren geht, weil man Angst hat, man koennte sich zu einem Design verleiten lassen, was ein wenig mehr Speicher oder Rechenzeit verbraucht, ist einfach nur peinlich. Der einzige Haken an C++ fuer Mikrocontroller ist, dass die Standardliteratur ein Bild von C++ vermittelt, das so auf Mikrocontrollern praktisch nicht anwendbar ist. Dafuer kann aber die Sprache auch wieder nichts.
Tim S. schrieb: > Das muss doch in paar Zeilen Code erklärbar sein, bevor ich unzählige > Tut´s nach einem Punkt absuche, der eventuell gar nicht zu finden ist... Wenn dir so schwer faellt, die Frage zu formulieren, bist du einfach nicht erfahren genug. Da bringt dir eine scheinbar einfache Antwort auch nichts. Sammle also erst mal etwas Erfahrung mit C++ und mit Mikrocontrollern, dann wirst du schnell merken, dass die Verwendung von C++ auf Mikrocontrollern ganz einfach ist - und du wirst auch selbst merken, weswegen sich viele Konzepte vom Desktop nicht auf den Mikrocontroller uebertragen lassen.
Johann L. schrieb: > Oliver schrieb: >> Stefan Frings schrieb: >>> C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM >>> Speicher nicht gut zusammen passt. >> >> Immer wieder behauptet, und trotzdem falsch. Identische Funktionalität >> per C oder C++ (objektorientiert) implementiert, ergibt am Ende so gut >> wie gleich großen Code. > > Du meinst also, wenn eine Funktionalität wie "LED Blinkern" oder was > auch immer implementiert wird, dann ergibt sich mit C und C++ immer die > gleiche Codegüte, unabhängig davon jeweiligen Softwaredesign? Ich denke was Oliver meint ist, dass es bei 'C versus C++' Vergleichen oft so ist, dass nicht identische Funktionalität verglichen wird. Ein C++ welches mit std::string arbeitet hat nun mal als EXE eine meistens größere Signatur, als ein C Programm, welches die STringverarbeitung mit der heißen Nadel zusammenstrickt. Ergänzt man im C Programm die Features, die man durch std::string automatisch bekommt, dann sind beide wieder gleich auf. Oft sind die C++ Programme sogar kleiner. Selbiges mit std::vector und selbstgeschriebenen dynamischen Array-Klassen, respektive den anderen Containerklassen. Benötige ich Polymorphismus, dann kostet mir das in C++ nun mal ein bischen was. Aber es kostet mir auch in C etwas, wenn man Polymorphismus nachbildet, und sei es nur durch Typeflags und switch-case Orgien. In Summe schenkt sich das kaum was, nur ist die C++ Lösung eleganter und besser erweiterbar. Und so hält sich dann eben hartnäckig das Gerücht, dass C++ einen 'gewaltigen Overhead' mit sich bringt. Übersehen wird dabei, dass oft Äpfel mit Birnen verglichen werden. Die Frage ist eher: was bringt mir OOP auf einem µC der Güteklasse eines kleinen Mega. UNzweifelthaft kann man ein paar Dinge einsetzen und alleine dadurch, dass C++ Compiler einige Dinge strikter handhaben, bringt das einen Vorteil. Aber die Sache ist auch die, dass OOP in dieser Leistungsklasse seine Vorzüge nicht wirklich ausspielen kann. Dazu sind die Programme einfach zu klein und noch zu überschaubar bzw. finden sich auch in OOP keine Lösungen zu den 'interessanteren' Problemen.
Karl Heinz Buchegger schrieb: > Johann L. schrieb: >> Oliver schrieb: >>> Stefan Frings schrieb: >>>> C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM >>>> Speicher nicht gut zusammen passt. >>> >>> Immer wieder behauptet, und trotzdem falsch. Identische Funktionalität >>> per C oder C++ (objektorientiert) implementiert, ergibt am Ende so gut >>> wie gleich großen Code. >> >> Du meinst also, wenn eine Funktionalität wie "LED Blinkern" oder was >> auch immer implementiert wird, dann ergibt sich mit C und C++ immer die >> gleiche Codegüte, unabhängig davon jeweiligen Softwaredesign? > > Ich denke was Oliver meint ist, dass es bei 'C versus C++' Vergleichen > oft so ist, dass nicht identische Funktionalität verglichen wird. Ein > C++ welches mit std::string arbeitet hat nun mal als EXE eine meistens > größere Signatur, als ein C Programm, welches die STringverarbeitung mit > der heißen Nadel zusammenstrickt. Ergänzt man im C Programm die > Features, die man durch std::string automatisch bekommt, dann sind beide > wieder gleich auf. Wenn man in der einen Sprache nur ein Feature/Konstrukt verwenden darf, das in der anderen zu vergleichbarem Binärcode führt, ist die Behauptung natürlich trivialerweise erfüllt. Unterschiedliche Sprachen legen unterschiedliche Designpattern nahe und kommen mit unterschiedlichen Standard-Funktionalitäten daher. Schreibt man in der Sprache, wird ein erfahrener Programmierer darauf zurückgreifen (wollen) und nicht "C in C++" programmieren wollen. Callback-Implementieung, Stringverarbeitung, Konstruktoren und Destruktoren, Referenzen vs. Zeiger, etc. Wenn man jetzt sagt "Konstruktor/Destruktor per malloc/free in C nachzubilden ist auch teuer" dann stimmt das natürlich, aber der geneigte µC-C-Programmierer wird gerne einen Bogen drum machen. Gleiches Thema: Referenzen. Als ich mal wegen Effizienz-Problemen wegen einer Fixed-Point Implementierung in einem Forum nachfragte, kam reflexartig der Kommentar: "Nimm Referenzen statt Pointer, das ist effizienter!" Nur leider waren die Datentypen nur 1-2 Bytes groß, und wenn nicht sichergestellt ist, daß alles geinlinet wird, dann wird das sehr teuer. Die Probleme mit der Fixed-Point Implementierung hab ich übrigens nicht lösen können; Operator-Overloading wäre ganz nett gewesen, aber nach den ersten versuchen bin ich wieder nach C. > Und so hält sich dann eben hartnäckig das Gerücht, dass C++ einen > 'gewaltigen Overhead' mit sich bringt. Übersehen wird dabei, dass oft > Äpfel mit Birnen verglichen werden. C++ auf einem µC wie AVR mit den "erheblichen Resource-Einschränkungen" ist m.E. ohne Performance-Einbußen nur machbar, wenn man "Casual inspection of the generated code is highly recommended" beherzigt — was freilich auch in entschärfter Form für C gilt. Auch mit C kann man schnell den Code aufblasen, etwa mit lokale Arrays, printf, float-Operationen oder Adressen von Auto/Parametern zu nehmen.
Johann L. schrieb: >> Ich denke was Oliver meint ist, dass es bei 'C versus C++' Vergleichen >> oft so ist, dass nicht identische Funktionalität verglichen wird. Ein >> C++ welches mit std::string arbeitet hat nun mal als EXE eine meistens >> größere Signatur, als ein C Programm, welches die STringverarbeitung mit >> der heißen Nadel zusammenstrickt. Ergänzt man im C Programm die >> Features, die man durch std::string automatisch bekommt, dann sind beide >> wieder gleich auf. > > Wenn man in der einen Sprache nur ein Feature/Konstrukt verwenden darf, > das in der anderen zu vergleichbarem Binärcode führt, ist die Behauptung > natürlich trivialerweise erfüllt. Das hat nichts mit 'verwenden dürfen' zu tun. Will man in C eine Stringverarbeitung bauen, die einen ähnlichen Sicherheitslevel bietet wie std::string, dann braucht man dazu Aufwand. Man kann aber nicht diesen Aufwand einfach weglassen und so tun, als ob Buffer Overflows einfach mit dazugehören und dann mit dem Finger auf C++ zeigen, bei dem diese Overflows von den darunterliegenden Klassen schon aufgefangen und behandelt werden. Das derartige Vergleiche immer hinken werden, darüber brauchen wir doch nicht wirklich diskutieren. Genau das wird aber oft (auf Desktop-Programmier-Ebene) getan, wenn die Aussage mit dem 'gewaltigen Overhead' kommt. Der Overhead ist auch nicht größer, als wie wenn man das C Programm erst mal auf den gleichen Stand bringt, den man mit C++ und seinen Klassen von Haus aus bekommt. Ein std::vector<int> a(5); a.push_back( 8 ); ist nun mal was anderes als ein int a[5]; int i = 0; a[i++] = 8; Brauch ich das dynamische Wachstum, dann muss ich auch in C entsprechenden Aufwand treiben. Brauch ich es nicht, dann erhebt sich die Frage, warum ein std::vector benutzt wird. Bringt man beide Schnipsel auf gleiche Funktionalität, dann verschwindet der vermeintliche Overhead, der nur deswegen sichtbar war, weil Äpfel mit Birnen verglichen wurden.
Oliver schrieb: > Stefan Frings schrieb: >> C++ bringt einen gewaltigen Overhead mit sich, der mit dem kleinen RAM >> Speicher nicht gut zusammen passt. > > Immer wieder behauptet, und trotzdem falsch. Identische Funktionalität > per C oder C++ (objektorientiert) implementiert, ergibt am Ende so gut > wie gleich großen Code. Das kann ich nur unterstreichen. Ich habe mir mal die Mühe gemacht, ein C-Programm mit structs und Funktionen nach C++ mit class und Methoden umzuschreiben: Es entsteht exakt der gleiche Code, im Falle von C++ aber bedeutend weniger Tipparbeit, public/private und polymorphe Funktionen. Es gibt kein Argument gegen C++ auf µC - verwende ich sogar auf bei den µCs mit 2kb Flash (attiny2313/msp430g22x1). > Mikrocontroller Programme sind in der Regel klein genug, um auch ohne > C++ Objekte übersichtlich zu bleiben. Und wenn es dann doch - so ab 32kb - plötzlich groß wird? Wechselt man zu C++? Das macht dann keiner, also besser gleich. > Es ist nicht schwer, Strukturen und Funktionen auch ohne OOP ausreichend > eindeutige Namen zu geben. Das Problem hatte ich ständig. Die guten Namen gehen irgendwann aus. Alleine der "kleine" name space durch die Klasse ist vorteilhaft. asdf schrieb: > Wegen dem OO > Da ist ein paper in dem das jemand komplett durchgebruetet hat: > http://www.planetpdf.com/codecuts/pdfs/ooc.pdf Das ist von 1993, und das Wort µC taucht darin nicht auf. > Offensichtlich ist das meiste davon overkill aufm Mikrocontroller. Meist > reicht es wenn man sein Zeugs einigermaßen sauber in structures verpackt Mit der Einschränkung "meist" und "einigermaßen". Es spricht überhaupt gar nichts dagegen, dies "sauber" in eine class zu verpacken, und private/public nebst getter und setter einzusetzen: Es entsteht der exakt gleiche Code. Johann L. schrieb: > Du meinst also, wenn eine Funktionalität wie "LED Blinkern" oder was > auch immer implementiert wird, dann ergibt sich mit C und C++ immer die > gleiche Codegüte, unabhängig davon jeweiligen Softwaredesign? Die gleiche Codegüte beim gleichen SW-Design wie oben beschrieben. Was soll sonst der Vergleich? Den Vergleich mit Funktionszeigern vs. virtuelle Funktionen habe ich noch nicht durchgeführt. Karl Heinz Buchegger schrieb: > Die Frage ist eher: was bringt mir OOP auf einem µC der Güteklasse eines > kleinen Mega. Bis auf den letzten Abschnitt stimme ich Dir zu :-) M. A. ist die Frage eher "Warum nicht gleich auf einen Ansatz setzen, der keine Nachteile mit sich bringt, damit man auch für den großen Mega gerüstet ist: Im Sinne der Erfahrung, der Tools, der erstellten Bibliotheken usw.
asdf schrieb: > Wegen dem OO > Da ist ein paper in dem das jemand komplett durchgebruetet hat: > http://www.planetpdf.com/codecuts/pdfs/ooc.pdf Erstmal danke für die vielen umfangreichen Antworten... Timo Reuters schrieb: > Mein Vorschlag lern erstmal C. > Damit kommste beim Mikrocontroller programmieren deutlich weiter als mit > C++. > Solltest dir irgendwann C nicht mehr ausreichen ist es von C nach C++ > auch nicht mehr weit. Karl Heinz Buchegger schrieb: > In Summe schenkt sich das kaum was, nur ist die C++ Lösung eleganter und besser erweiterbar. Was würdet ihr mir nun raten?? (Bitte nicht wieder einen Kampf starten wegen dem einen Byte was C evtl sparsamer [oder whatever] gegenüber C++ ist...) Bin für´s erste mit "unoptimierten" - also direkt erzeugten Code zufrieden. Johann L. schrieb: > C++ auf einem µC wie AVR mit den "erheblichen Resource-Einschränkungen" > ist m.E. ohne Performance-Einbußen nur machbar, wenn man > > "Casual inspection of the generated code is highly recommended" > > beherzigt — was freilich auch in entschärfter Form für C gilt. Das gilt für mich / bei mir noch gar nicht ^^... So derart Aufwändig werden meine Sachen wahrscheinlich auch wieder nicht. Ich versuch mal dem Compiler zu vertrauen. Marwin schrieb: > Tim S. schrieb: >> Das muss doch in paar Zeilen Code erklärbar sein, bevor ich unzählige >> Tut´s nach einem Punkt absuche, der eventuell gar nicht zu finden ist... > > Wenn dir so schwer faellt, die Frage zu formulieren, bist du einfach > nicht erfahren genug. Da bringt dir eine scheinbar einfache Antwort auch > nichts. Sammle also erst mal etwas Erfahrung mit C++ und mit > Mikrocontrollern, dann wirst du schnell merken, dass die Verwendung von > C++ auf Mikrocontrollern ganz einfach ist - - wird langsam... > und du wirst auch selbst merken, weswegen sich viele Konzepte vom Desktop > nicht auf den Mikrocontroller uebertragen lassen. Ja schon klar, begrenzter Speicher, ganz andere Architektur usw. Ist ja auch kein ARM. Vorläufig werde ich bei C++ bleiben, außer jemand kann mich wirklich überzeugen, dass es längerfristig gesehen mehr sinn macht, auf C zu setzen. Insbesondere auch wegen (irgendwann mal ganz) anderen µCs, oder eben auch Desktop-Sachen. Dass ich eben bei einer einzigen relativ gut portierbaren Sprache bleiben könnte. Werde mir jedenfalls constructor/destructor selber bauen müssen, und mir die benötigten (erwähnten) Funktionen und Eigenschaften von C++, mit Pointern, Callback, Referenzen und Zeiger etc. genauer auf der Zunge zergehen lassen. Gruß.
Tim S. schrieb: > Werde mir jedenfalls constructor/destructor selber bauen müssen, und mir Mit Konstruktoren und Destruktoren gibt es kein Problem. Nur mit Allem, was dynamischen Speicher braucht. Also erst Mal Finger weg von new und delete (genauso wie man mit C die Finger von malloc und free laesst). Vor der Verwendung von virtuellen Methoden dreimal nachdenken, das macht die Klassen fett. Und die std-C++-Library vergessen wir gleich mal, halte dich an das nackige C++.
Ok, dann in medias res. Aus den unterschiedlich Gründen hab ich bisherimmer einen großen Bogen um C++ gemacht. Dementsprechend wenig Ahnung hab ich von dem Moloch, lerne aber gerne dazu. Für den Anfang hab ich ein kleines Beispiel getippst, das den Ansatz einer accum-Implementierung analog zu accum aus stdfix.h von ISO/IEC TR 18037 darstellen soll:
1 | class accum |
2 | {
|
3 | // s7.8 wie accum aus stdfix.h
|
4 | |
5 | public:
|
6 | int x; |
7 | |
8 | accum operator + (accum b) const |
9 | {
|
10 | accum sum; |
11 | sum.x = x + b.x; |
12 | return sum; |
13 | };
|
14 | |
15 | inline accum (void) : x (0) {}; |
16 | inline accum (double val) : x (val * 0x100) {}; |
17 | };
|
18 | |
19 | |
20 | #include <math.h> |
21 | #include <stdlib.h> |
22 | #include <avr/pgmspace.h> |
23 | |
24 | const PROGMEM accum lookup[] = |
25 | {
|
26 | accum (M_PI), |
27 | accum (M_E) |
28 | };
|
29 | |
30 | const accum v PROGMEM = 0; |
31 | |
32 | unsigned volatile index; |
33 | |
34 | int main (void) |
35 | {
|
36 | if (pgm_read_word (&v)) |
37 | abort(); |
38 | |
39 | return (lookup[index] + accum (0.5) + v).x; |
40 | }
|
Vermutlich hab ich da schon x Klopper drinne. Als erstes: Wie schafft man es, daß das Programm nicht auf abort läuft? Ich hab's zwar nicht laufen lassen, aber daß es auf abort kommt ist offensichtlich. Zweitens: C++ ist keine Obermenge von C, schon garnicht vom o.g. ISO/IEC TR 18037, was etwa die "Named Address Space" (AS) spezifiziert, die avr-gcc 4.7 implementiert (__flash, __flash1, ..., __memx). Wie macht man das sauber in C++, ohne das PROGMEM und pgm_read-Geraffel? Drittens: Ist es möglich, C-Erweiterungen in C++ zu verwenden? Ein Beispiel ist der o.g. accum-Typ, ein s7.8 Q-Format. Gerade auf kleiner Hardware ist Fixed-Point ganz nett. Es ist wesentlich effizienter als float und schöner, als ständig von Hand Werte hin- und her und wieder hin zu skalieren und zu shiften. Ausserdem bekommt ein Compiler, der diese Typen kennt, z.T. besseren Code hin als (inline-)Assembler Das kann in C++ zwar nett in Klassen verpackt werden, aber die libgcc bring schon mehr als 3000 Support-Funktionen für Fixed-Point mit: Konvertierung, +, -, *, /, <<, >>, ABS, NEG, Saturierung (!), Vergleiche, unterschiedliche Formate wie 0.8, s.7, 8.8, s7.8, 0.16, s.15, 16.16, etc. Weiterer Vorteil sind neue Typ-Suffixe, die man in C++ auch nicht hat.
Johann L. schrieb: > accum operator + (accum b) const Das erste was du dir (tatsächlich) angewöhnen musst: Wenn geht, dann benutze const Referenzen. Es gibt hier keinen Grund b als Wert zu übergeben, in der Funktion wird b nicht verändert. Also const Referenz Das muss nicht bedeuten, dass es damit automatisch effizienter ist. Aber du ermöglichst dem Compiler sein Bestes zu tun. accum operator + (const accum& b) const > { > accum sum; > sum.x = x + b.x; Bevorzuge Initialisierung, wo es geht. Es hat keinen Sinn, wenn der Konstruktor erst mal das sum Objekt in einen gültigen Zustand bringt, nur damit du es nachher gleich wieder änderst. Schreibe dir Konstruktoren, mit denen du gleich das Objekt so initialisieren kannst, dass das Ergebnis der Operation als Argument für einen Konstruktor gebrauchen kannst (wenn du sie noch nicht hast). std::string result; result = "hello world"; ist eine Operation zu viel std::string result = "hello world"; ergibt danach denselben Inhalt, wird aber schneller ausgeführt. > const PROGMEM accum lookup[] = > { > accum (M_PI), > accum (M_E) > }; > > const accum v PROGMEM = 0; > > unsigned volatile index; > > int main (void) > { > if (pgm_read_word (&v)) > abort(); > > return (lookup[index] + accum (0.5) + v).x; > }[/c] > > Vermutlich hab ich da schon x Klopper drinne. Sieht nicht so schlecht aus. Inwiefern da jetzt PROGMEM den gcc beeinflusst kann ich nicht sagen, aber der Rest sieht gut aus. > > Als erstes: Wie schafft man es, daß das Programm nicht auf abort läuft? > Ich hab's zwar nicht laufen lassen, aber daß es auf abort kommt ist > offensichtlich. Wieso soll das offensichtlich sein? Du hast hier eine implizite Annahme: dass sizeof(accum) gleich einem word ist. Das würde ich mal in Frage stellen. > Zweitens: C++ ist keine Obermenge von C, schon garnicht vom o.g. ISO/IEC > TR 18037, was etwa die "Named Address Space" (AS) spezifiziert, die > avr-gcc 4.7 implementiert (__flash, __flash1, ..., __memx). Wie macht > man das sauber in C++, ohne das PROGMEM und pgm_read-Geraffel? 'namespace' Keyword. Aber im Regelfall reicht es aus, wenn man die Dinge einfach in Klassen kapselt. Dann fungiert der Klassenname wie eine Art Namespace. > Drittens: Ist es möglich, C-Erweiterungen in C++ zu verwenden? Ein > Beispiel ist der o.g. accum-Typ, ein s7.8 Q-Format. Kann ich dir nicht sagen. Dazu müsste man die Compilerdoku studieren, oder einfach ausprobieren. Ich würde aber davon ausgehen, dass das meiste was ein C Compiler experimentell implementiert hat, auch in C++ gehen wird. Gerade der gcc ist sowas wie das "Arbeitspferd" der Leute, die versuchen eine Spracherweiterung durch die Normierungsgremien zu bekommen. Eine beispielhafte Implementierung ist zu diesem Behufe nützlich (um zu demonstrieren dass es prinzipiell geht und das keine negativen Auswirkungen auf den Rest zu erwarten sind), und oft genug muss dazu der gcc her halten.
Karl Heinz Buchegger schrieb: >> accum operator + (accum b) const > > Das erste was du dir (tatsächlich) angewöhnen musst: > Wenn geht, dann benutze const Referenzen. > Es gibt hier keinen Grund b als Wert zu übergeben, in der Funktion wird > b nicht verändert. Also const Referenz > > Das muss nicht bedeuten, dass es damit automatisch effizienter ist. Aber > du ermöglichst dem Compiler sein Bestes zu tun. > > accum operator + (const accum& b) const Um das auch gleich auszuräumen. Eine Referenz ist nicht einfach nur ein POinter in einem anderen Gewand. Eine Referenz ist ein anderer Name für ein ansonsten existierendes Objekt. D.h. in accum x, y; x + y; wir y an die Referenz gebunden. b ist nicht einfach nur eine neue Variable, sondern mit der Referenz hast du dem COmpiler gesagt: das ist dieselbe Variable, die sind austauschbar Wird die inline Ersetzung gemacht x.operator+( y ) ... const accum& b = y; accum sum; sum.x = x.x + b.x; dann kann der Compiler quer durch die ganze Ersetzung b durch y ersetzen! accum sum sum.x = x.x + y.x; d.h. b taucht im (soweit) endgültigen Code überhaupt nicht mehr auf. Eines ist unbestritten: C++ lebt sehr stark davon, dass der Compiler optimiert. Bei abgeschaltetem Optimizer ist der erzeugte Code grauenhaft. Darf der Compiler aber optimieren, dann würde es mich nicht wundern, wenn bei deinem Code mehr oder weniger dasselbe wie bei
1 | int values[2] = { M_PI * 100, M_E * 100 } |
2 | int v; |
3 | |
4 | int main() |
5 | {
|
6 | int tmp = pgm_read_word( &v ); |
7 | return values[index] + 0.05 * 100 + tmp; |
8 | }
|
rauskommt. (Auch das retournierte Objekt im op+ darf der Compiler ohne Rücksicht auf Verluste wegoptimieren. Das ist die Named Return Value Optimization. http://en.wikipedia.org/wiki/Return_value_optimization
Karl Heinz Buchegger schrieb: > Johann L. schrieb: > >> accum operator + (accum b) const > > Das erste was du dir (tatsächlich) angewöhnen musst: > Wenn geht, dann benutze const Referenzen. > Es gibt hier keinen Grund b als Wert zu übergeben, in der Funktion wird > b nicht verändert. Also const Referenz Für + seh ich das ein, weil die Funktion geinlint werden soll. Aber was, wenn nicht, etwa wenn die Operation teuer ist wie bei Division oder einer saturierten Addition. In dem Falle würde doch die Adresse von b genommen, bzw. dem entsprechenen Parameter. Die Adresse einer auto zu nehmen ist auf einem x86-Host ken großes Ding, aber mach das mal auf AVR. > Das muss nicht bedeuten, dass es damit automatisch effizienter ist. Aber > du ermöglichst dem Compiler sein Bestes zu tun. > > accum operator + (const accum& b) const > >> { >> accum sum; >> sum.x = x + b.x; > > Bevorzuge Initialisierung, wo es geht. Es hat keinen Sinn, wenn der > Konstruktor erst mal das sum Objekt in einen gültigen Zustand bringt, > nur damit du es nachher gleich wieder änderst. Schreibe dir > Konstruktoren, mit denen du gleich das Objekt so initialisieren kannst, > dass das Ergebnis der Operation als Argument für einen Konstruktor > gebrauchen kannst (wenn du sie noch nicht hast). Has Problem ist, daß der Constructore einen double bekommen muss. Nimmt man einen Contructor mit int um die Komponente .x direkt zu initialisieren, dann hat man später eine Mehrdeutigkeit, weil man nicht den Contruktoe mit 1 aufrufen kann um die Zahl mit 1 zu initialisieren (der Wert wäre dann 1/256). Ich hatte schon einen Constructor mit int und den wieder rausgeworfen, weil zB in einem Initializer der falsche Constructor für einen double wie 3.14 genommen wurde -> falscher Wert. >> const PROGMEM accum lookup[] = >> { >> accum (M_PI), >> accum (M_E) >> }; >> >> const accum v PROGMEM = 0; >> >> unsigned volatile index; >> >> int main (void) >> { >> if (pgm_read_word (&v)) >> abort(); >> >> return (lookup[index] + accum (0.5) + v).x; >> }[/c] >> >> Vermutlich hab ich da schon x Klopper drinne. > > Sieht nicht so schlecht aus. Inwiefern da jetzt PROGMEM den gcc > beeinflusst kann ich nicht sagen, aber der Rest sieht gut aus. Es wird ein impliziter Constructor für v und lookup angelegt. Zum einen ist das teuer wegen des zusätzlichen Codes, zum anderen können die Variablen nicht mehr im Flash sein. Entweder sie sind im Flash und der implizite Constructor schreibt willkürlich RAM-Adressen (diejenigen, die den Objekten im Flash entsprechen), oder das Zeug ist entgegen der Vereinbarung nicht im Flash. Hier ist letzteres der Fall. >> Als erstes: Wie schafft man es, daß das Programm nicht auf abort läuft? >> Ich hab's zwar nicht laufen lassen, aber daß es auf abort kommt ist >> offensichtlich. > > Wieso soll das offensichtlich sein? Die Daten liegen nicht im Flash! Daher das abort — es sei denn, an der entsprechenden Flash-Adresse stehz zufällig eine 0x0000. > Du hast hier eine implizite Annahme: dass sizeof(accum) gleich einem > word ist. Das würde ich mal in Frage stellen. sizeof accum ist 2. Wenn man davon nicht ausgehen kann, dann braucht's memcpy_P o.ä. um Objekte aus dem Flash zu lesen. Oder man muss die Daten serialisieren/deserialisieren, was insbesondere Kopfzerbrechen bereitet, wenn die Daten schon zur Compilezeit serialisiert werden sollen, z.B in ein Char- oder unsigned Array. Und selbst wenn das geht: schön ist anders... Im Endeffekt heisst das: Es ist nicht möglich, Objekte aus dem Flash zu lesen und zB const-Objekte zu haben, die im Flash leben. >> Zweitens: C++ ist keine Obermenge von C, schon garnicht vom o.g. ISO/IEC >> TR 18037, was etwa die "Named Address Space" (AS) spezifiziert, die >> avr-gcc 4.7 implementiert (__flash, __flash1, ..., __memx). Wie macht >> man das sauber in C++, ohne das PROGMEM und pgm_read-Geraffel? > > 'namespace' Keyword. > Aber im Regelfall reicht es aus, wenn man die Dinge einfach in Klassen > kapselt. Dann fungiert der Klassenname wie eine Art Namespace. Ich versteh nicht, wie man durch den Namespace erreicht, daß der Compiler nicht mehr per LD/LDS auf die Objekte zugreift, sondern wie bei des Address-Spaces per LPM. Wo und wie kommen denn die LPM-Instruktionen ins Spiel? Karl Heinz Buchegger schrieb: > Eines ist unbestritten: C++ lebt sehr stark davon, dass der Compiler > optimiert. Bei abgeschaltetem Optimizer ist der erzeugte Code > grauenhaft. > > int values[2] = { M_PI * 100, M_E * 100 } Aber genau das will man doch vermeiden in C++! Das "* 100" ist die interne Darstellung des accum, keiner ausser die Innereien von accum hat das zu interessieren! Das oll doch alles in accum gekapselt sein, oder nicht? > Darf der Compiler aber optimieren, dann würde es mich nicht > wundern, wenn bei deinem Code mehr oder weniger dasselbe wie bei > > return values[index] + 0.05 * 100 + tmp; Nicht nur das Ergebnis spielt eine Rolle, sondern auch der Weg dahin. 1) "* 100" gehört in die Klasse accum. Wenn das nicht geht hat C++ versagt — behaupt ich jetzt mal frech ;-) 2) Es geht hier darum, float-Operationen komplett zu vermeiden und die entsprechenden Fixed-Operationen in eine eine Klasse zu packen. Wenn float auf AVR keine Effizient-Probleme hätte, dann bräuchte man die ganze Terz ja nicht und würde direkt float/double hernehmen.
Johann L. schrieb: > Für + seh ich das ein, weil die Funktion geinlint werden soll. Aber was, > wenn nicht, etwa wenn die Operation teuer ist wie bei Division oder > einer saturierten Addition. In dem Falle würde doch die Adresse von b > genommen, bzw. dem entsprechenen Parameter. Die Adresse einer auto zu > nehmen ist auf einem x86-Host ken großes Ding, aber mach das mal auf > AVR. OK. Ist natürlich ein Argument. Bei Objekten dieser Größe (die im wesentlichen nur ein int sind) ist eine Kopie kein Thema. Aber das ist ja nicht der Normalfall. > Has Problem ist, daß der Constructore einen double bekommen muss. Nimmt > man einen Contructor mit int um die Komponente .x direkt zu > initialisieren, dann hat man später eine Mehrdeutigkeit, weil man nicht > den Contruktoe mit 1 aufrufen kann um die Zahl mit 1 zu initialisieren > (der Wert wäre dann 1/256). Man kann Konstruktoren als 'explizit' markieren. Damit verbietet man ihm, einen Konstruktor von sich aus zu benutzen. Eine Verwendung dieses Konstruktors muss damit explizit angefordert werden. > Im Endeffekt heisst das: Es ist nicht möglich, Objekte aus dem Flash zu > lesen und zB const-Objekte zu haben, die im Flash leben. Da hat sich ja nichts geändert. const hat ja ursäcjlich nichts mit dem Flash zu tun (zumindest nicht beim gcc) > >>> Zweitens: C++ ist keine Obermenge von C, schon garnicht vom o.g. ISO/IEC >>> TR 18037, was etwa die "Named Address Space" (AS) spezifiziert, die >>> avr-gcc 4.7 implementiert (__flash, __flash1, ..., __memx). Wie macht >>> man das sauber in C++, ohne das PROGMEM und pgm_read-Geraffel? >> >> 'namespace' Keyword. >> Aber im Regelfall reicht es aus, wenn man die Dinge einfach in Klassen >> kapselt. Dann fungiert der Klassenname wie eine Art Namespace. > > Ich versteh nicht, wie man durch den Namespace erreicht, Mein Fehler. namespaces haben damit nichts zu tun. Ich war so sehr auf Standard-C++ fixiert, dass ich gar nicht mitbekommen habe, dass du von was ganz anderem sprichst. > daß der > Compiler nicht mehr per LD/LDS auf die Objekte zugreift, sondern wie bei > des Address-Spaces per LPM. Wo und wie kommen denn die > LPM-Instruktionen ins Spiel? Da würde ich mein Heil in einer 'Flash' Klasse suchen, die im Prinzip wie ein Pointer funktioniert und die Dereferenzierungsoperation überschreibt (monadischen operator *). Ein klassischer Smart-Pointer. > > Karl Heinz Buchegger schrieb: > >> Eines ist unbestritten: C++ lebt sehr stark davon, dass der Compiler >> optimiert. Bei abgeschaltetem Optimizer ist der erzeugte Code >> grauenhaft. >> >> int values[2] = { M_PI * 100, M_E * 100 } > > Aber genau das will man doch vermeiden in C++! Das "* 100" ist die > interne Darstellung des accum, keiner ausser die Innereien von accum > hat das zu interessieren! Das was ja ein Beispiel, wie man das in C schreiben würde! Natürlich will man das in C++ in der Klasse verstecken. > Nicht nur das Ergebnis spielt eine Rolle, sondern auch der Weg dahin. Auch der Weg dorthin, wird vom Compiler nicht viel anders organsisiert werden. > > 1) "* 100" gehört in die Klasse accum. Wenn das nicht geht hat C++ > versagt — behaupt ich jetzt mal frech ;-) > > 2) Es geht hier darum, float-Operationen komplett zu vermeiden und > die entsprechenden Fixed-Operationen in eine eine Klasse zu packen. > Wenn float auf AVR keine Effizient-Probleme hätte, dann bräuchte > man die ganze Terz ja nicht und würde direkt float/double hernehmen. Oh Mann. Ich wollte doch nur dein C++ Beispiel in ein C Beispiel überführen, von dem ich erwarten würde, dass der C Compiler in etwa denselben Code erzeugt wie ein C++ COmpiler, der sich das aus den Klassen zusammenoptimiert. Das war die Intention.
Karl Heinz Buchegger schrieb: > Johann L. schrieb: > >> Drittens: Ist es möglich, C-Erweiterungen in C++ zu verwenden? Ein >> Beispiel ist der o.g. accum-Typ, ein s7.8 Q-Format. > > Kann ich dir nicht sagen. Dazu müsste man die Compilerdoku studieren, > oder einfach ausprobieren. -std=gnu++0x tut's jedenfalls nicht. Address-Space Support funktioniert definitiv nicht in C++. > Ich würde aber davon ausgehen, dass das > meiste was ein C Compiler experimentell implementiert hat, auch in C++ > gehen wird. Gerade der gcc ist sowas wie das "Arbeitspferd" der Leute, > die versuchen eine Spracherweiterung durch die Normierungsgremien zu > bekommen. Das war einmal. Mittlerweile ist's andersrum. Die GCC-Entwickler sind überhaupt nicht mehr begeistert von "Language Extentions" Address-Space Qualifier wie __flash werden mit ziemlicher Sicherheit nicht in C++ aufgenommen, zumindest wenn ich Gaby [1] glauben darf; er ist Mitglied der WG21, die den C++ Standard hütet: >> In general, there is an aversion towards more qualifiers. >> I suspect this is mostly because of the committee being >> burned by "volatile" and also because qualifiers tend to >> lead to combinatorial explosion when it comes to implicit >> conversions and overload resolution. >> >> The trend has been to use classes (sometimes with compiler >> support) to render abstractions such as these. See for >> example how C++11 handles atomics (std::atomic<T>) compared >> to C11 (_Atomic). > Eine beispielhafte Implementierung ist zu diesem Behufe > nützlich (um zu demonstrieren dass es prinzipiell geht und das keine > negativen Auswirkungen auf den Rest zu erwarten sind), und oft genug > muss dazu der gcc her halten. Wenn ich [1] recht verstehe würde das über Templates(?) gehen wie std::flash<T>. Wie würde so ein Template denn aussehen? Und auch da wieder die Frage: Wo kommen die LPMs her? Und was macht man, denn man den Code zu einer anderen Architektur portiert? Mit den Address-Spaces geht das unfein, aber kurz und schmerzlos über #define __flash Oder sogar ganz ohne den Code anzufassen per -D__flash= -- [1] http://lists.gnu.org/archive/html/avr-gcc-list/2012-05/msg00044.html
Karl Heinz Buchegger schrieb: > Johann L. schrieb: > >> Für + seh ich das ein, weil die Funktion geinlint werden soll. Aber was, >> wenn nicht, etwa wenn die Operation teuer ist wie bei Division oder >> einer saturierten Addition. In dem Falle würde doch die Adresse von b >> genommen, bzw. dem entsprechenen Parameter. Die Adresse einer auto zu >> nehmen ist auf einem x86-Host ken großes Ding, aber mach das mal auf >> AVR. > > OK. > Ist natürlich ein Argument. Bei Objekten dieser Größe (die im > wesentlichen nur ein int sind) ist eine Kopie kein Thema. Es geht nicht nur um die Kopie, sondern auch um das Erzeugen der Referenz. Wird geinlint dann kostet weder Referenz noch Kopie weil der gleiche Code entsteht. Wird nicht geinlint, ist abzuwägen zwischen Kopie und Referenzerzeugung (d.h. evtl. Anlegen eines Frames!) und den in der Methode entstehenden höheren Registerlast. AVRs sind nicht gerade üppig mit Zeiger-Registern ausgestattet. > Aber das ist ja nicht der Normalfall. Es war der Beweggrund für meinen letzten Umstiegsversuch nach C++: Eine hübsche Fixed-Point Implementierung, die nicht zur C-üblichen Verunstaltung des Codes führt. Allerdings hab ich den Versuch bald aufgegeben. Ich dachte aber, daß er hier als naheliegendes Beispiel für die Fähigkeiten von C++ taugen würde. >> Das Problem ist, daß der Constructor einen double bekommen muss. Nimmt >> man einen Contructor mit int um die Komponente .x direkt zu >> initialisieren, dann hat man später eine Mehrdeutigkeit, weil man nicht >> den Contruktoe mit 1 aufrufen kann um die Zahl mit 1 zu initialisieren >> (der Wert wäre dann 1/256). > > Man kann Konstruktoren als 'explizit' markieren. Damit verbietet man > ihm, einen Konstruktor von sich aus zu benutzen. Eine Verwendung dieses > Konstruktors muss damit explizit angefordert werden. Ok, ok. Wenn dann aber der Standard-Construktor einen double bekommt (was gebraucht wird, um ohne Verrenkung Konstanten wie 3.14 einzufüttern), wie wird dann die float-Arithmetik vermieden wenn der Constructor keine zur Compilezeit bekannte Konstante bekommt? Bracht's dann doch wieder nichtportierbare GCC-Hässlichkeiten wie __builtin_choose_expr oder __builtin_const oder wie auch immer? >> Im Endeffekt heisst das: Es ist nicht möglich, Objekte aus dem Flash zu >> lesen und zB const-Objekte zu haben, die im Flash leben. > > Da hat sich ja nichts geändert. > const hat ja ursäcjlich nichts mit dem Flash zu tun (zumindest nicht > beim gcc) Nicht bei AVR. Bei linearem Speicher spricht absolut nicht dagegen, const Objekte ins Flash zu legen, d.h. .rodata liegt im Flash. Bei avr-gcc muss .rodata jedoch im RAM liegen! > Ich war so sehr auf Standard-C++ fixiert, dass ich gar nicht > mitbekommen habe, dass du von was ganz anderem sprichst. Ah, ok. >> daß der Compiler nicht mehr per LD/LDS auf die Objekte zugreift, >> sondern wie bei des Address-Spaces per LPM. Wo und wie kommen >> denn die LPM-Instruktionen ins Spiel? > > Da würde ich mein Heil in einer 'Flash' Klasse suchen, die im Prinzip > wie ein Pointer funktioniert und die Dereferenzierungsoperation > überschreibt (monadischen operator *). Ein klassischer Smart-Pointer. AFAIK ist es in C++ nicht erlaubt, Zeiger zu überladen? Und Basis-Typen auch nicht. Wie würde so ein Code denn aussehen? Hier mal ein kleiner C-Code:
1 | typedef short _Fract T; |
2 | |
3 | // Default calibration values in flash.
|
4 | // Will be adjusted by calibration as needed
|
5 | static __flash const volatile T cal[] = |
6 | {
|
7 | 0.214hr, 0.1191hr |
8 | };
|
9 | |
10 | T calc (T x) |
11 | {
|
12 | return (x + 0.5hr) * cal[1] + cal[0]; |
13 | }
|
avr-gcc 4.8 erzeugt:
1 | calc: |
2 | ldi r30,lo8(cal+1) |
3 | ldi r31,hi8(cal+1) |
4 | lpm r18,Z |
5 | ldi r30,lo8(cal) |
6 | ldi r31,hi8(cal) |
7 | lpm r25,Z |
8 | subi r24,lo8(-(0x40)) |
9 | mov r19, r24 |
10 | fmuls r18,r19 |
11 | mov r24,r1 |
12 | clr __zero_reg__ |
13 | add r24,r25 |
14 | ret |
Natürlich ist klar wie das als "normaler" C-Code aussieht, aber... >> Karl Heinz Buchegger schrieb: > Oh Mann. > Ich wollte doch nur dein C++ Beispiel in ein C Beispiel überführen, von > dem ich erwarten würde, dass der C Compiler in etwa denselben Code > erzeugt wie ein C++ Compiler, der sich das aus den Klassen > zusammenoptimiert. Das war die Intention. ...interessant ist doch die andere Richtung: Wie geht das in C++, ohne einfach "C per C++" zu programmieren sondern richtig mit Kapselung und Objektorientierung und so? Und zudem ohne Performance-Einbuße — und natütlich auch übertragbar auf ausgewachseneren Code. Hier würden doch (mindestens) 2 Klassen gebraucht: 1) Eine für T, die die Arithmetik implementiert 2) Eine die das __flash abbildet Wie sieht denn so ein Smart-Zeiger aus, ich hab echt keinen Plan. 2) ist vielleicht auch ein Template, aber auch da hab ich keine Idee wie es aussehen könnte. Gerade den obigen Code sollte doch gut geeignet sein um die Möglichkeiten von C++ zu erklären? Denn hier kann man nicht einfach alles in "extern C" reinkloppen, sondern muss wirklich C++-Magie verwenden, um die fehlenden Features zu modellieren. In Objective-C könnte man den obigen Code einfach übersetzen, denn im Gegensatz zu C++ ist Objective-C eine echte Obermenge von C. Was spricht denn eigentlich gegen Objective-C? Dazu reicht doch schon ein -c objective-c als Compilerschalter und ein Umschreiben des C-Codes erübrigt sich. Man kann dann anfangen, den Code Stück für Stück nach OOP zu bringen. Der TO sprach ja nut von OOP, aber das ist hier wohl synonym mit C++?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.