Ngii Rayan schrieb:> Ich habe den Grund herausgefunden.
Schön.
Aber viel schöner wäre es, wenn du auch noch schreiben würdest, WAS es
war. Immerhin könnte dein Wissen jemand Anderem später mal
weiterhelfen...
Hallo,
Das Problem lag an Wishbone Arbiter.Also einfach UART als Slave 0 wird
es gelöst:
// UART Slave
.s0_dat_i(uart_dat_o),
.s0_dat_o(uart_dat_i),
.s0_adr_o(uart_adr),
.s0_sel_o(uart_sel),
.s0_we_o (uart_we),
.s0_cyc_o(uart_cyc),
.s0_cti_o(uart_cti),
.s0_stb_o(uart_stb),
.s0_ack_i(uart_ack),
.s0_err_i(1'b0),
.s0_rty_i(1'b0),
Ngii Rayan schrieb:> Das Problem lag an Wishbone Arbiter.Also einfach UART als Slave 0 wird> es gelöst:
Falsche Lösung, denn das Problem wird wieder auftauchen.
Ich habe mit den Arbiter angeschaut, die Slave Addressen müssen in
aufsteigender Reihenfolge sein.
z.B:
.S0_BASE (32'h0000), //GPIO
.S1_BASE (32'h0800), // UART
.S2_BASE (32'h1000), //EBR
.S3_BASE (32'h5000)
Ich gebe dir Recht!
Stimmt tauscht das Problem wieder bei mehrere Komponente. Nur wollte ich
in meinem Fall nur UART Komponent testen.
Aber gilt deine Lösung allgemein für mehrere Komponente.
Genau das meinte ich !
Nun zum UART Test unter Linux: Hat jemand eine Idee warum ich meine GPIO
Problemlos schreiben/lesen kann aber nicht meine UART Komponent?
1
[root@localhostpci_sample_2]#./regrwECP3_SFIF_1
2
UserSpaceLatticePCIedevicedriverusingmmap
3
BoardECP3_SFIF_1
4
Openingaccesstolscpcie/ECP3_SFIF_1
5
fd=2
6
pmem=0xb77eb000
7
*p0=b77eb000
8
9
RegisterRead/WriteAccess
10
r-reada32bitregister
11
w-writea32bitvalueintoaregister
12
addressesareon4byteboundaries
13
q,x-exit
14
r|w<addr>[data]:w00080000ffff// ON LEDs
15
r|w<addr>[data]:r00080000ffff
16
00000008:0xffff
17
r|w<addr>[data]:w000800000000// OFF LEDs
Aber das gleiche Verfahren kalppt nicht zum UART Zugriff:
Also
1
r|w<addr>[data]:w10100000ffff// UART Write to IER Register
Ich muss nochmal fragen, wo hast du wbs_uart her? Selbstgemacht?
Im Versakit, von dem du den toplevel wohl her hast, ist es jedenfalls
nicht enthalten.
Ja !
wbs_uart.v entpricht einfach uart_top.v von Opencore was ich mit Lattice
Mico32 erfolgsreich getestet habe.
Also habe ich nur die toplevel Dateiename umbennant zur klarheit für das
gesamte Projekt.
Ngii Rayan schrieb:> wbs_uart.v entpricht einfach uart_top.v von Opencore was ich mit Lattice> Mico32 erfolgsreich getestet habe.
Und welcher der vielen UARTS, die es dort gibt? Setze doch einfach mal
einen Link.
Du hast natürlich die Unterschiede in der Addressierung und
Datenbusbreite beachtet?
Das geht so nicht.
Dein WB Datenbus ist 16bit breit (im Gegensatz zum Mico32).
Vom PC werden bei PCIe immer 32bit Zugriffe durchgeführt, dabei sind die
Addressbits 0 und 1 immer auf 0 und zu ignorieren. Byteauswahl erfolgt
durch Byte enables.
Der wb_tlc (PCIe -> Wishbone) Module übersetzt JEDEN PCIe Zugriff in
ZWEI Wishbone cycles, wobei die Adresse um 2 incrementiert wird. Dieses
Verhalten muss in deinem Slave berücksichtigt werden.
Sowas schaut man sich natürlich am besten in einer Simulation an. Da
aber das Aufsetzen und schreiben einer PCIe testbench nicht einfach ist,
bietet sich als Alternative auch Reveal an.
Ich habe einen ersten Experiment mit Reveal gemacht und sie sehr
nutzlich aus.
Was mir noch unklar ist folgende:
Der wb_tlc (PCIe -> Wishbone) Module übersetzt JEDEN PCIe Zugriff in
ZWEI Wishbone cycles für wishbone Slaves.
Meine Meinung: Stimmt aber nur wenn es um einen 32 bit Daten
Übertragung.
Das ist beispielweise der Fall beim Zugriff auf 32 bit GPIO Register
(Versa) und Byteauswahl erfolgt durch wb_sel_i[0/1], wobei die Adresse
um 2 incrementiert wird.
Nun meine Frage wie wäre falls PCIe TLP nur 8 bits schreiben/lesen soll?
(8/16 Slave Devices). Der wb_tlc (PCIe -> Wishbone) Module in diesem
Fall nur wb_sel_i[0] braucht um es zu machen. Folglich keine Adresse
incrementierung .
Das ist der Fall für Opencore UART/CAN die 8 Bit Daten sind .Was
bedeutet jeder Register vom Host über TLP Packet mit 8 Bits
lesbar/schreibar ist .
Ngii Rayan schrieb:> Meine Meinung: Stimmt aber nur wenn es um einen 32 bit Daten> Übertragung.
Meinungen zählen hier nicht. Im Versa Kit ist der wb_tlc in source form
enthalten. Schau ihn dir an.
(die WB Schreibzyklen werden in wb_tlc/wb_intf.v Zeile 179-218
generiert.)
Nochmal, es gibt KEINE 8bit TLPs. TLPs sind IMMER vielfache von 4 Bytes,
auch
wenn die PC einen 8 bit Zugriff macht. Dafür gibt es die wb_sel Signale.
Das gleiche Problem hast du übrigens wenn du ein 8 bit Slave (OpenCan)
an einen 32bit Master anschliesst (Mico32).
OK !
Da bedeutet in Lattice Fall: TLP Daten max = 1 DW (allgemein PCIe bis
1024 DW möglich)
also
Length = 0x001
und um die benotige Byte zu wissen werden First DW Byte Enables und Last
DW Byte Enables gebraucht also
bei 32 bits Datentransfer :Last BE = 0x0 und First BE = 0xf(1111)
bei 16 bits Datentransfer :Last BE = 0x0 und First BE = 0x3 (0011)
bei 8 bits Datentransfer :Last BE = 0x0 und First BE = 0x1 (0001)
Nun zu 8 bit Slave (OpenCan) an einen 32bit Master anschliesst (Mico32):
bei 8 bit Opencore UART (beinhaltet ein sel_i Signal )also wurde kein
Problem fesgestellt.
aber mit 8 bit Opencore CAN(beinhaltet kein sel_i Signal ):lässt sich
Read/Write Operationen mit Mico32 ausführen .
Dies Problem lässt sich mit ALTERA mit dem 8 Bit Befehl IOWR_8DIRECT
lösen auch wenn NIOS 32 bit ist.
Wie wird es nun ohne sel_i Signal von Opencore CAN gelöst oder gibt es
eine Opencore CAN Variante mit sel_i Signale?
Ngii Rayan schrieb:> Da bedeutet in Lattice Fall: TLP Daten max = 1 DW (allgemein PCIe bis> 1024 DW möglich)> also> Length = 0x001
Wenn ich es richtig sehe unterstützt wb_tlc auch längere TLP, es werden
dann halt auch entsprechend viele WB Zyklen erzeugt.
Allerdings erzeugt die CPU in einem PC bei Memorymapped IO nur TLPs mit
max 4 Bytes Payload, eventuell verteilt auf 2 DW. (Siehe Bild 1).
Ein memcopy mit 16 bytes wird auf viele TLPs verteilt (Siehe Bild 2).
>> und um die benotige Byte zu wissen werden First DW Byte Enables und Last> DW Byte Enables gebraucht also>> bei 32 bits Datentransfer :Last BE = 0x0 und First BE = 0xf(1111)>> bei 16 bits Datentransfer :Last BE = 0x0 und First BE = 0x3 (0011)>> bei 8 bits Datentransfer :Last BE = 0x0 und First BE = 0x1 (0001)
Das gilt nur wenn die Addresse auf PC Seite ein vielfaches von 4 ist.
Siehe die angehängten Beispiele
>>> Nun zu 8 bit Slave (OpenCan) an einen 32bit Master anschliesst (Mico32):>> bei 8 bit Opencore UART (beinhaltet ein sel_i Signal )also wurde kein> Problem fesgestellt.>> aber mit 8 bit Opencore CAN(beinhaltet kein sel_i Signal ):lässt sich> Read/Write Operationen mit Mico32 ausführen .>> Dies Problem lässt sich mit ALTERA mit dem 8 Bit Befehl IOWR_8DIRECT> lösen auch wenn NIOS 32 bit ist.
Das sieht aus wie ein Macro, das die passenden Addressumrechnungen
macht.
>> Wie wird es nun ohne sel_i Signal von Opencore CAN gelöst oder gibt es> eine Opencore CAN Variante mit sel_i Signale?
Mach dir eine. Ist ja schliesslich Opensource.
Beim Mico32 ist das Problem vermutlich einfach zu lösen indem du doe
Registeroffsets mit 4 multiplizierst.
Danke für Klarheit durch ein echtes Beispiel. ich werde davon lernen um
weiter zu implementieren.
Das Buch PCIe Architechture habe ich aber
so dargestellt wie dieses Beipiel lernt man mehr auf einmal.
Danke nochmals
Mit dem Offset *4 für Opencore CAN blokiert ab
OPENCORECAN_REGISTER(OPENCORECAN2_BASE_ADDRESS, CAN_ACCEPTANCE_MASK)=
bMASK; Zeile.
Ursprungliche ALTERA Code sieh so aus:(Sieh Anhang für OWR_8DIRECT
Beschreibung)
Hallo
Mit Reveal Analyser bin ich dabei die DatenZugriff (8/32 Bits) über
Lattice Wishbone Interface (wb_tlc/wb_intf.v) zu analysieren:
Dafür habe ich 2 Slaves über PCIe gebunden(32 Bit und 8 Bit)
sind folgende Betrachtungen für die Analyse richtig ?
SLAVE 32 Bit wird folgende erwartet:
-------------------------------------
32 Bit Zugriff auf Slave = 2 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=11 also 16 Bit werden übertragen
Cycle two = wb_sel_i[1:0]=11 also 16 Bit werden Bit werden übertragen
16 Bit Zugriff auf Slave = 1 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=11 also 16 Bit
Cycle two = wb_sel_i[1:0]=00 kein Zugriff auf Slave da nur 16 Bit
8 Bit Zugriff auf Slave = 1 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=01 also 8 Bit
Cycle two = wb_sel_i[1:0]=00 kein Zugriff auf Slave da nur 8 Bits
BEI SLAVE 8 Bits wird folgende erwartet:
------------------------------------------
32 Bit Zugriff auf Slave = 4 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=01 also 8 Bit werden übertragen
Cycle two = wb_sel_i[1:0]=01 also 8 Bit werden Bit werden übertragen
Cycle three = wb_sel_i[1:0]=01 also 8 Bit werden übertragen
Cycle four = wb_sel_i[1:0]=01 also 8 Bit werden Bit werden übertragen
16 Bit Zugriff auf Slave = 2 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=01 also 8 Bit werden übertragen
Cycle two = wb_sel_i[1:0]=01 also 8 Bit werden Bit werden übertragen
8 Bit Zugriff auf Slave = 1 Wishbone Cycles
Cycle one = wb_sel_i[1:0]=01 also 8 Bit werden übertragen
Ngii Rayan schrieb:> sind folgende Betrachtungen für die Analyse richtig ?
Nein.
Du gehst immer noch davon auss, dass es bei WB einen Busbreitenkonverter
gibt. Gibt es in dem Beispiel nicht, und hat sich vermutlich auch noch
niemand die Mühe gemsaht einen zu schreiben.
Schau dir in Reveal einfach nur die WB Signale in deinem Toplevel an.
OK hast du Recht gibt es nicht in meinem Besipiel.(Versa)
Nur möchte ich einen Opencore UART 8 Bit Breite dazu binden und Zugriff
ermöglichen.
Wenn man aus folgenden GPIO 32 Bit Zugriff Beispiel geht. Wie soll den
Zugriff auf UART 8 Bit implementiert werden mit Bezug wb_intf.v Module?
(Ich habe einiges erfolglos probiert.)
So dass die 2 Wishbone Cycles Verhalten in UART Slave berücksichtigt
wird.
Der wb_tlc (PCIe -> Wishbone) Module übersetzt JEDEN PCIe Zugriff in
ZWEI Wishbone cycles, wobei die Adresse um 2 incrementiert wird. Dieses
Verhalten muss in deinem Slave berücksichtigt werden.
Ngii Rayan schrieb:> Der wb_tlc (PCIe -> Wishbone) Module übersetzt JEDEN PCIe Zugriff in> ZWEI Wishbone cycles, wobei die Adresse um 2 incrementiert wird. Dieses> Verhalten muss in deinem Slave berücksichtigt werden.
Wie wäre es, wenn Du die überflüssigen Bits einfach ignorierst?
Das macht so ziemlich jeder Busteilnehmer, wenn die zu übertragende
Bitbreite kleiner ist als die native Bitbreite des Bussystems.
Und es zwingt Dich auch niemand in Deinem IP-Core auf jede Adresse zu
reagieren, oder?
Duke
Ouahh !
Ich bin mit dem Thema einen Schritt weiter. Ich habe ein GPIO Register 8
Bit implementiert und konnte lesen/schreiben mit 8 Bit.
Nun werde ich einfach die gleiche Vorgehenweise für Opencore UART 8 Bits
und damit sollte es gehen....
Hallo zusammen,
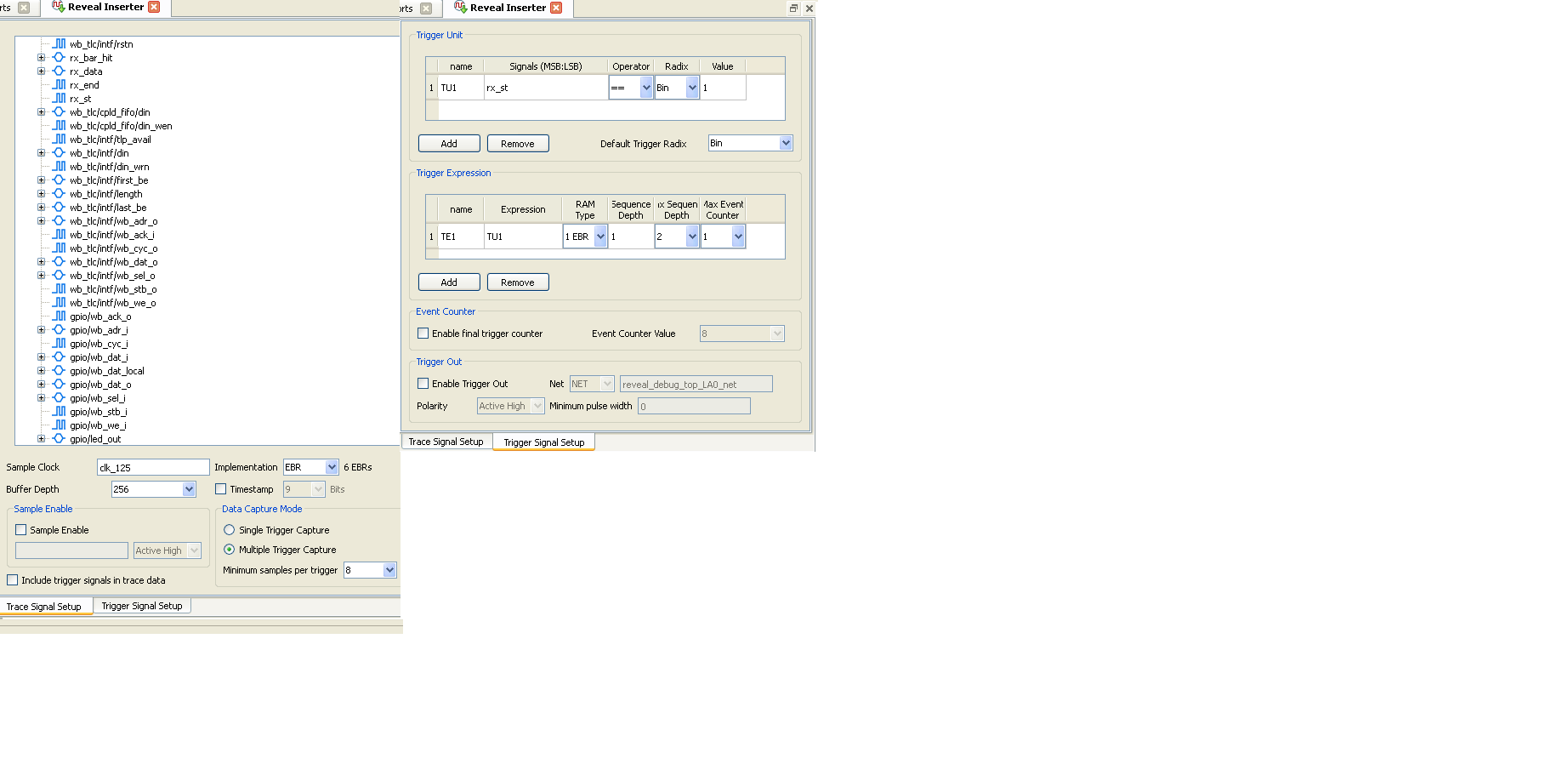
Wie kann ich ein Trigger mit Reveal Analyser einstellen so dass ich ab
rx_st Signal 20 Samples clock nacher warte.
Amders formuliert das Ziel ist es ein gesamte Wishbone Zyklus anschauen
zu können bis ack_o Signal von GPIO Slave auf 1 wird ?
Ich habe einiges erfolglos probiert....
Ist jetzt schon eine Weile her, dass ich mich damit beschäftigt habe.
Momentan schaffe ich es, meine Bugs mit Simulation ond Nachdenken
auszumerzen.
Du schreibts nicht, was genau du schon probiert hast.
Also erst mal ins blaue.
Du musst im Reavel Inserter erst mal Triggerunits anlegen, ist etwas
komplex da man auch Sequenzen definieren kann. Im Analyzer kann man dann
einzelne Triggerunits auswählen.
Am besten Screenshots(*) bei weiteren Fragen.
(*) Im PNG Format!, sonst gibtes Haue von allen möglichen Leuten denen
langweilig ist.
Ich gebe dir voll Recht. Also beigefügt entsprechende Reveal
Inserter/Analyser und Linux Befehle:
Schritt 1: Unter Linux habe ich Memory Write Paket gesendet mit folgende
Befehle:
q,x - exit
(1)- r|w <addr> [data]: w 0004 FF // 0004
isGPIO:LEDs
(2)- r|w <addr> [data]: w 0004 AA
(3)- r|w <addr> [data]: w 0004 CC
ERKLÄRUNG: Write an ADRESSE xxxx DATEN xx (hexadecimal)
Mein Trigger wird immer ausgelöst wenn es ein TLP (MWr)also start of
paket =1
Waveform_Memory_Write_0xAA.PNG für (2)
Waveform_Memory_Write_0xCC.PNG für (3)
Nun meine Fragen:
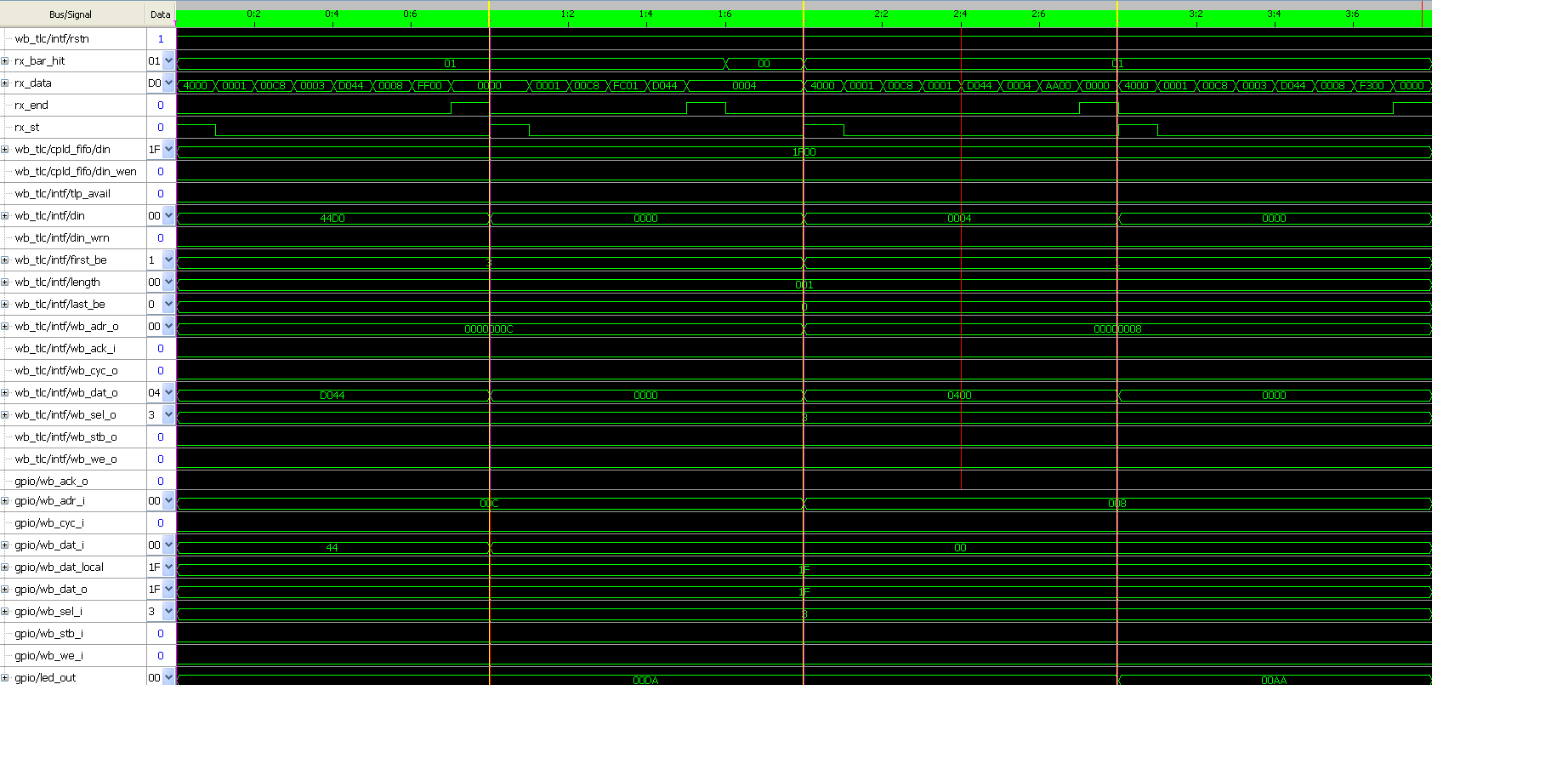
Frage 1: Warum gpio/wb_adr_i also Endpoint nicht die Adresse 0x0004
bekommt ?
Frage 2: Warum erhalt man immer die Daten an naschte Waveform (Beispiel:
AA sieht man nur nach Linux Operation 3) FIFO oder?
Habe ich versucht über Reset leer zu machen um entprenche Daten für jede
Operation zu empfangen aber nichts gebracht.
Frage 3: Wie is Reveal Inserter einzustellen um nnach dem gesendeten TLP
Paket(MWr) die gesamte Wishbone Zyklus von gpio/wb_cyc_i bis
gpio/wb_ack_o
anzuschauen?
Ngii Rayan schrieb:> Nun meine Fragen:>> Frage 1: Warum gpio/wb_adr_i also Endpoint nicht die Adresse 0x0004> bekommt ?
Siehe PCI/PCIe Spec. Jedes Device bekommt vom BIOS mindestens eine
Adresse zugewiesen.
>> Frage 2: Warum erhalt man immer die Daten an naschte Waveform (Beispiel:> AA sieht man nur nach Linux Operation 3) FIFO oder?> Habe ich versucht über Reset leer zu machen um entprenche Daten für jede> Operation zu empfangen aber nichts gebracht.
Du hast als MaxSequence 2 angegeben, beim Analyzer vielleicht
eingestellt dass er 2 Triggerevents braucht?
>> Frage 3: Wie is Reveal Inserter einzustellen um nnach dem gesendeten TLP> Paket(MWr) die gesamte Wishbone Zyklus von gpio/wb_cyc_i bis> gpio/wb_ack_o> anzuschauen?
Grössere Buffertiefe, oder einfach mehr als nur 16 im Analyzer
anschauen.
Buffertiefe 512 statt 256 geht ohne dass mehr EBRs gebraucht werden.
(Ob es reicht weiss ich nicht)
rx_st als einzige Triggerbedingung ist u.U. etwas knapp, bei einem Intel
basierendem Motherboard kann es sein, dass du mit Vendorspecific
Messages zugemüllt wirst.
Vielleicht besser auf wb_cyc triggern.
Hallo zusammen,
Es ist mir gelungen ein 8 Bit Module über Lattice Wishbone Interface
wb_intf.v anzuschliessen mit Lesen/Schreiben Möglichkeit.
[vhdl]
module wbs_gpio(wb_clk_i, wb_rst_i,
wb_dat_i, wb_adr_i, wb_cti_i, wb_cyc_i, wb_lock_i, wb_sel_i,
wb_stb_i, wb_we_i,
wb_dat_o, wb_ack_o, wb_err_o, wb_rty_o,
switch_in, led_out
);
input wb_clk_i;
input wb_rst_i;
input [7:0] wb_dat_i;
input [8:0] wb_adr_i;
input [2:0] wb_cti_i;
input wb_cyc_i;
input wb_lock_i;
input [1:0] wb_sel_i;
input wb_stb_i;
input wb_we_i;
output [7:0] wb_dat_o;
output wb_ack_o;
output wb_err_o;
output wb_rty_o;
input [7:0] switch_in;
output [13:0] led_out; //output [7:0] led_out;
//reg [31:0] scratch_pad;
reg [13:0] led_out;
reg [7:0] wb_dat_local;
//reg [15:0] temp_data;
reg wb_ack_o;
reg wr_delayed; //For VERSA
assign rd = ~wb_we_i && wb_cyc_i && wb_stb_i;
assign wr = wb_we_i && wb_cyc_i && wb_stb_i;
assign wr_use = (!wr_delayed) && wr; //for VERSA
// Need to pipeline the write side to allow the read side time to read
data
always @(posedge wb_rst_i or posedge wb_clk_i)
begin
if (wb_rst_i)
begin
//scratch_pad <= 32'd0;
led_out <= 14'd0;
wb_dat_local <= 32'd0;
//temp_data <= 0;
wr_delayed <= 0;//for VERSA
end
else
begin
wr_delayed<=wr;
if (wb_cyc_i)
begin
case (wb_adr_i)
9'h000: begin
if (rd) wb_dat_local <= 8'h30;
end
9'h002: begin
if (rd) wb_dat_local <= 8'h12;
end
9'h003: begin
if (rd) wb_dat_local <= {led_out[13:8],2'b11};
else if (wr) begin
led_out[13:8] <= wb_sel_i[0] ? wb_dat_i[5:0] : led_out[13:8];
//led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] : led_out[7:0];
end
end
`ifdef VERSA
9'h004: begin
if (rd) wb_dat_local <=
{led_out[5:4],led_out[3],led_out[3],led_out[2:1],led_out[0],led_out[0]};
else if (wr_use) begin
if (led_out[0]&led_out[3]) begin
led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] : led_out[7:0];
end
else if (led_out[0]&(!led_out[3])) begin
led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] : led_out[7:0];
end
else if ((!led_out[0])&led_out[3]) begin
led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] : led_out[7:0];
end
else if ((!led_out[0])&(!led_out[3])) begin
led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] : led_out[7:0];
end
end
end // case: 9'h004
`else
9'h004: begin
if (rd) wb_dat_local <= led_out;
else if (wr) begin
//led_out[15:8] <= wb_sel_i[0] ? wb_dat_i[15:8] :
led_out[15:8];
led_out[7:0] <= wb_sel_i[1] ? wb_dat_i[7:0] :
led_out[7:0];
end
end
`endif
9'h006: begin
if (rd) wb_dat_local <= {switch_in};
end
endcase
end // cyc
end //clk
end
assign wb_dat_o = wb_dat_local;
assign wb_err_o = 1'b0;
assign wb_rty_o = 1'b0;
always @(posedge wb_rst_i or posedge wb_clk_i)
if (wb_rst_i) begin
wb_ack_o <= 0;
end
else begin
wb_ack_o <= wb_cyc_i & wb_stb_i & (~ wb_ack_o);
end
endmodule
/vhdl]
Aus diese Vorgehenweeise möchte ich auch Opencore UART 8 Bit Zugriff
über
Lattice Wishbone Interface wb_intf.v ermöglicen.
ABER diese hat nicht die gleiche Architekture um direkt Zugriff auf
Register um mein Adressdekoder wie mit GPIO Module zu schreiben.
Hat vielleicht jemand eine Idee wie ich vorgehen sollte ?
Ich habe eine Idee!
ich glaube es wird über das Module uart_wb.v also uart interface.
Sobald ich damit fertig bin dann melde ich mich
Aber ich würde mich auf weitere Idee freuen.
Hallo Leute,
Kann man mir vielleicht erklären warum unter the Lattice Wishbone
Interface Module wb_intf.v wird das Signal wb_sel_o immer wieder gleich
Werte also auf 1 gesetzt.
Ich habe unterschedliche TLP Datenlänge probiert(length = 1 DW,
2DW,3DW,4DW) und immer wieder gleich Werte also wb_sel_o <= 2'b11;
Gibt es Fälle wo first_be[3:0] andere Werte aufnehmen als 1111?
Ich würde mich auf Klarheit hier freuen...
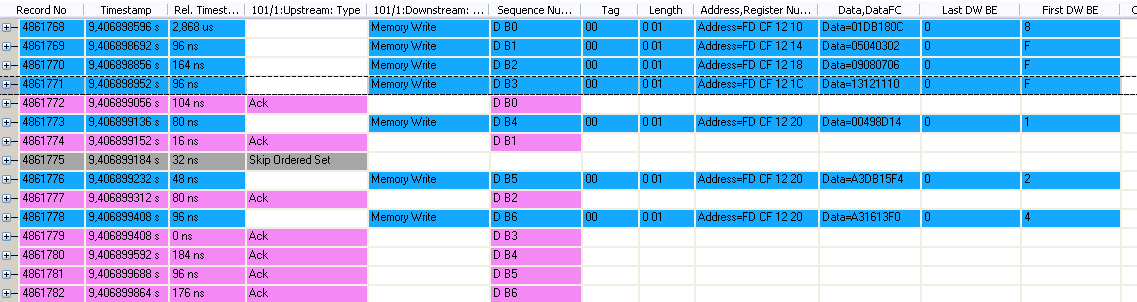
Ngii Rayan schrieb:> Gibt es Fälle wo first_be[3:0] andere Werte aufnehmen als 1111?
Ja natürlich,
Schau dir meine PCIe Traces von oben mal genau an.
Für die meisten hier wären deine Fragen leichter nachzuvollziehen, wenn
du auch Screenshots von einer Simulation, bzw von Reveal anhängen
würdest. So muss man immer erst den Quellcode studieren (obendrein
Verilog, die überwiegende Mehrheit hier nutzt VHDL). Ausserdem aus einem
einzelenen Schnipsel den gesamten Zusammenhang zu erkennen ist oft nicht
möglich.
OK
Ich habe dein Beispiel nochmals angeschaut und die erste Zeile
beinhaltet folgende:
Length =001 Last BE = 0 First BE = 8
Was dies Datenmäßig bedeutet ? also wieviel Datenmenge werden da
übertragen ?
1 Byte oder ?
beigefügt meine PCIe Traces (gesendet habe ich nur 1 Byte = 0xFF)also
sollte ich First BE = 1 oder ? aber bekomme ich First BE=0xF
Mein Hauptziel ist erkennen zu können aus einem TLP Paket welche
Datenmenge für Read/Write gebraucht wird (Endpoint)?
Ngii Rayan schrieb:> beigefügt meine PCIe Traces (gesendet habe ich nur 1 Byte = 0xFF)also>
Nein, hast du nicht.
Deine Software/Treiber auf dem PC macht immer 32 bit Zugriffe. Wenn du
Byte Zugriffe sehen möchtest muss man Treiber buw SW entsrechend
abändern.
Versuch mal eine ungerade Addresse einzugeben, vielleicht lässt die
SW/Treiber das ja zu.
ich habe nochmal nachgeschaut, bei der Windowsvesrion der Lattice SW
schreibts du einzele Bytes mit
1
wb 0004 AA
Dürfte bei der Linuxversion das gleiche sein.
Aber eine Einschränkung: Ich verwende diese Software nicht, kann mich
also irren.
Noch eine Ergänzung
Ngii Rayan schrieb:> Length =001 Last BE = 0 First BE = 8>> Was dies Datenmäßig bedeutet ? also wieviel Datenmenge werden da> übertragen ?> 1 Byte oder ?
Übertragen werden 4 Bytes, sieht man auch im Trace, aber nur 1 Byte ist
gültig.
Hallo,
Nun habe ich herausgefunden warum ich immer wieder nicht die gesendete
Daten bisher gesehen habe (oder First BE Signal nicht genau wie erwartet
passt)
Schauen Sie einfach auf mein TRACE . Da ist festzustellen dass ich mit
Vendorspecific Messages zugemüllt werde. Mein TLP Paket kommt erst an
der dritte Stelle.
gesendet wurde: 1 Byte 0xAA
Jetzt simmt es mit First BE = 1 überein.
Nun eine Frage : Wie kann ich Zugriff für ungerade Adresse steuern.
Mein erste Gedanken ist bei UART beispielsweise jede Adresse zu
vershieben also Mal 2.
Aber unbenutzte Speichebereiche (bei UART 0 bis 6 Offset wird 0 bis 12)
Hinweis: Endpoint mit 8/16 Slaves Devices alle über Wb_intf.v Module.
Auf Hinweise würde ich mich freuen...
Ngii Rayan schrieb:> Schauen Sie einfach auf mein TRACE . Da ist festzustellen dass ich mit> Vendorspecific Messages zugemüllt werde. Mein TLP Paket kommt erst an> der dritte Stelle.
Auf dieses Problem habe ich schon hier hingewiesen:
Beitrag "Re: Lattice Diamond: UART Receiver Siganl Wegoptimiert"
(Letzer Abschnitt)
Ngii Rayan schrieb:> Nun eine Frage : Wie kann ich Zugriff für ungerade Adresse steuern.> Mein erste Gedanken ist bei UART beispielsweise jede Adresse zu> vershieben also Mal 2.
Das ist das einfachste.
Aber auf die Enable achten, bei deinem Slave kommen immer 2 Zugriffe an.
Der 2. mit wb_sel = 00!
(Wobei ich mal 4 nehmen würde)
Ngii Rayan schrieb:> Schauen Sie einfach auf mein TRACE . Da ist festzustellen dass ich mit> Vendorspecific Messages zugemüllt werde. Mein TLP Paket kommt erst an> der dritte Stelle.
Habe es noch einmal angeschaut:
In dem Trace ist KEINE Vendorspecific Message.
(Die würden mit 03xx oder 07xx anfangen)
1. TLP, Schreiben auf Addresse 8 und BE = 3,
2. TLP. Lesen von Addresse 4 und BE = 1
3. TLP, Schreiben auf Addresse 4 und BE = 1
Du hast ganz nebenbei auch noch ein Softwareproblem.
Mal 2 habe ich vor weil ein 8 Bit UART/CAN nur bitemäßig vom Host
gelesen wird.
Bei wordweise dann hätte ich sofort an Mal 4 gedacht. Aber bitte dies
nur Gedanken die geprüft werden sollte.Nicht als Contra (x4) ansehen
sondern Überlegung.
Ich simuliere erstmals dann melde ich mich mit dem Ergebnis....
Zum Testzweck habe ich vor 1 Monat ein Paar Read/Write Befehle in meinem
Treiber eingefügt.(und vergessen!)
Also jetzt endlich ein perfekter TLP Pakete:
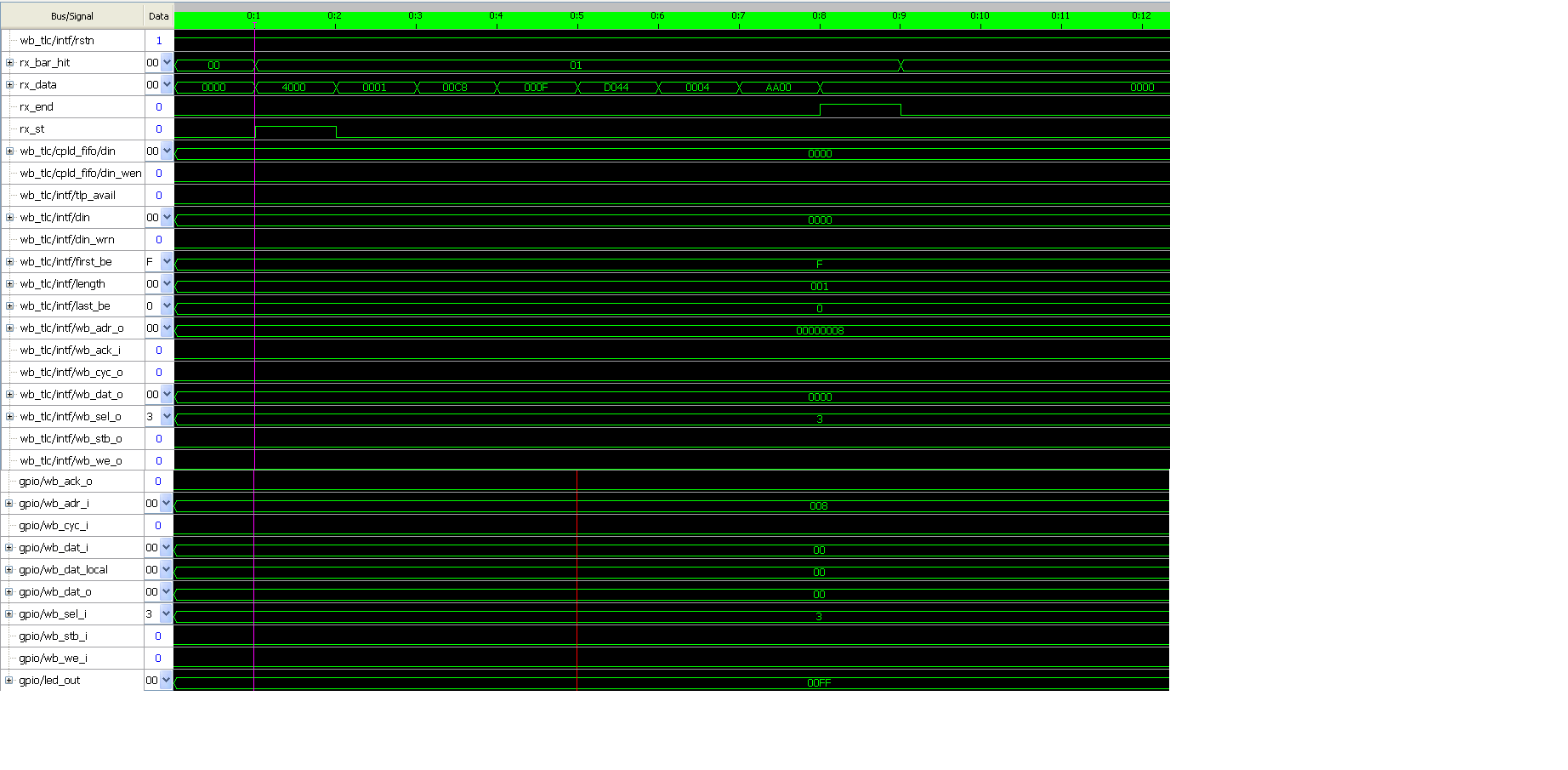
Gesendet wurde: 0xAA an Adresse 0x0004
Aus folgende Zeile wurde die wishbone Adresse im Wishbone Interface
Module berechnet.
Ngii Rayan schrieb:> Also wb_adr_o = 0008
Der Wishbonecyclus ist im Trace nicht sichtbar, das was da auf wb_adr
sichtbar ist stammt von einem vorherigen Zugriff, und hat mit deinem Mal
2 nichts zu tun.
Du musst auf wb_cyc triggern, oder weit mehr Samples im Reveal anzeigen.
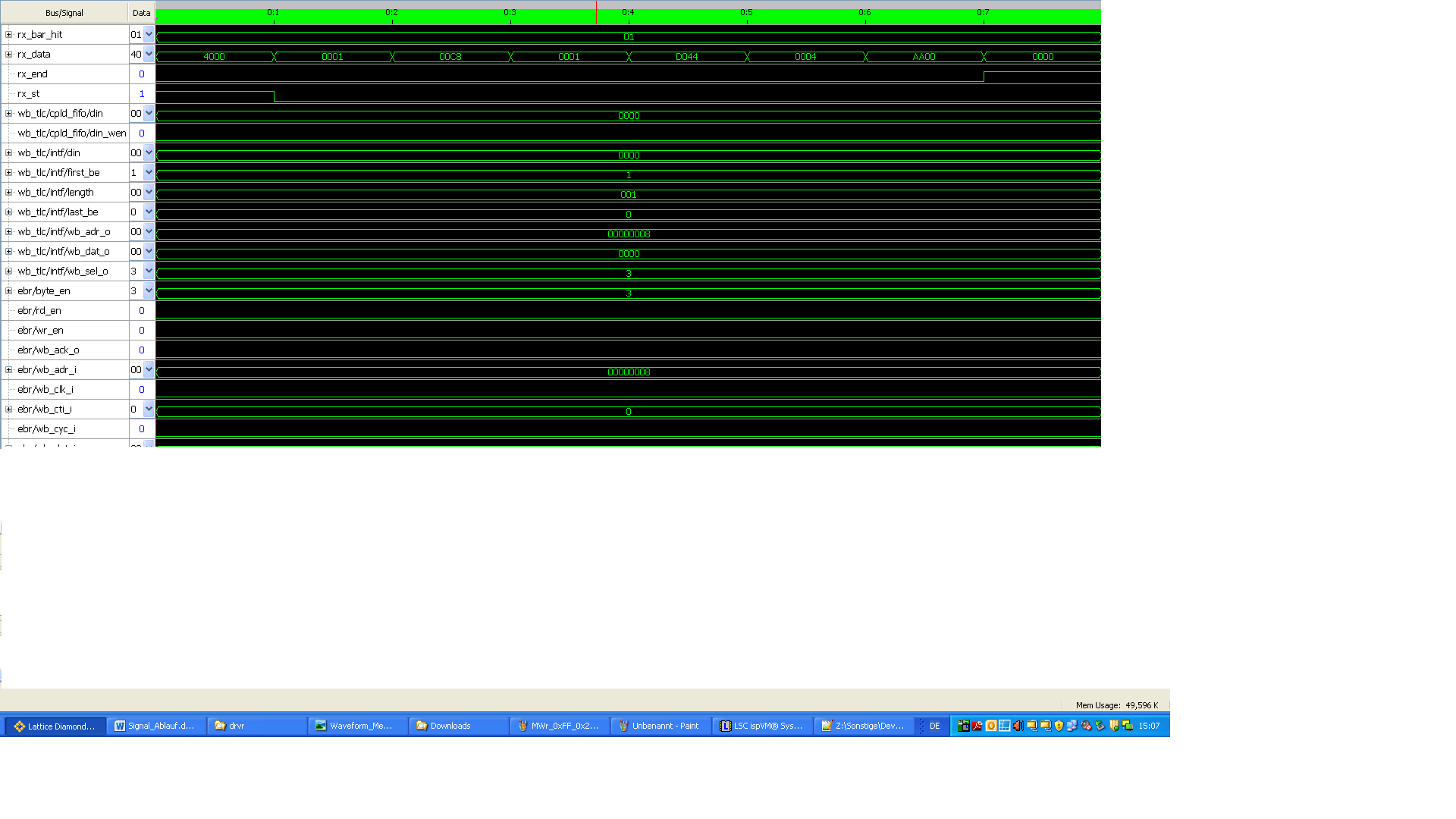
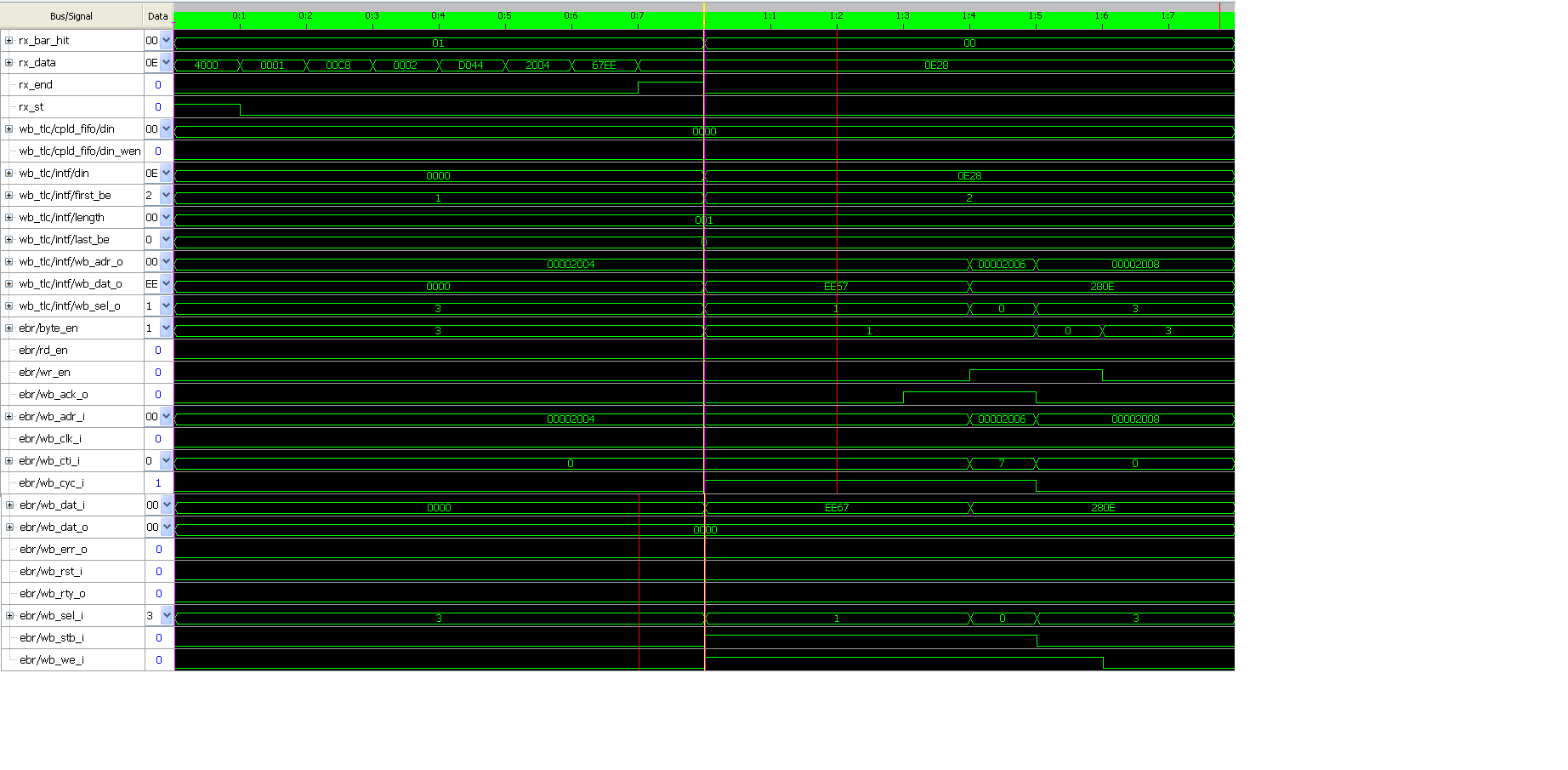
OK habe ich folgende gemacht
Damit ich TLP Pakete und Wishbone Cycle anschauen kann, habe ich
folgende Trigger genutzt: rx_st oder ebr_cyc .
Dadurch lassen sich Abläufe von MWr TLP bis Wishbone Zyklus(ebr)
darstellen.
Gesendet wurde: 0xEE an Adresse 0x2004
passt jetzt oder ?
Hier mein TRACE für 8 Bit Slave Zugriff (hier : led_out[7:0])
Ich glaube es gut aussieht mit gpio/wb_sel_i= 0 beim zweiten Zugriff
oder verpasse was da ?
Auf Anmerkungen würde ich mich freuen...
Gesendet wurde: 0xFF an Adresse 0x0000 (8 Bit led)
Ngii Rayan schrieb:> Ich glaube es gut aussieht mit gpio/wb_sel_i= 0 beim zweiten Zugriff> oder verpasse was da ?
Genau darum geht es.
Damit kommen die typischen 8bit WB slaves nicht zurande.
Hallo zusammen
Nachdem ich erfolgsreich 8 Bit GPIO Slave Module implementiert habe,
habe ich das Ziel Opencore Uart 32 Bit hinten Lattice Wishbone interface
anzuhängen (wb_intf.v)
Auf diesem Grund habe ich alle UART Adresse verschoben um 4 wie
folgende:
Ngii Rayan schrieb:> Aber Schauen Sie bitte mein Track ! Das Output entpricht nicht was> erwartet wird.>
Doch,
z.B. Addresse 0x1004 kommt als Addresse 0x0004 bei der UART an.
Aber:
1
//`define DATA_BUS_WIDTH_8
heisst die UART ist als 32 bit Slave konfiguriert. Und wenn ich richtig
verstanden habe, enthählt sie einen Layer der dann 32bit Zugriffe nach
8 bit übersetzt. Und damit geht alles daneben!
So ein Layer ist keineswegs WB Standard, und schränkt IMO die
Verwendbarkeit des Cores ein.
Im 8bit Mode wird aber wb_sel nicht ausgwertet, und das wiederum macht
hier Probleme, da Zugriffe mit wb_sel = 0 erfolgen.
Hast du völlig Recht !
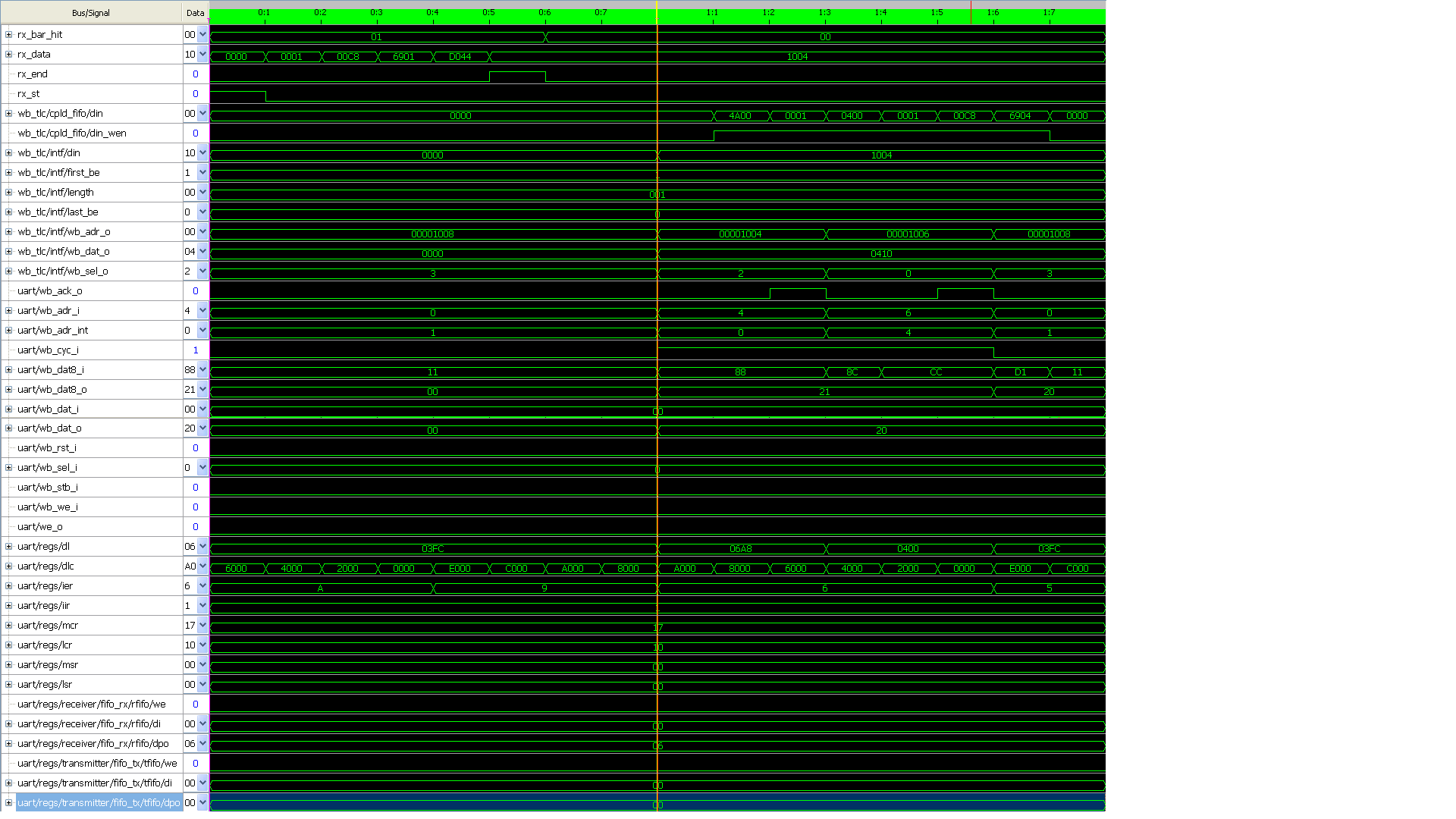
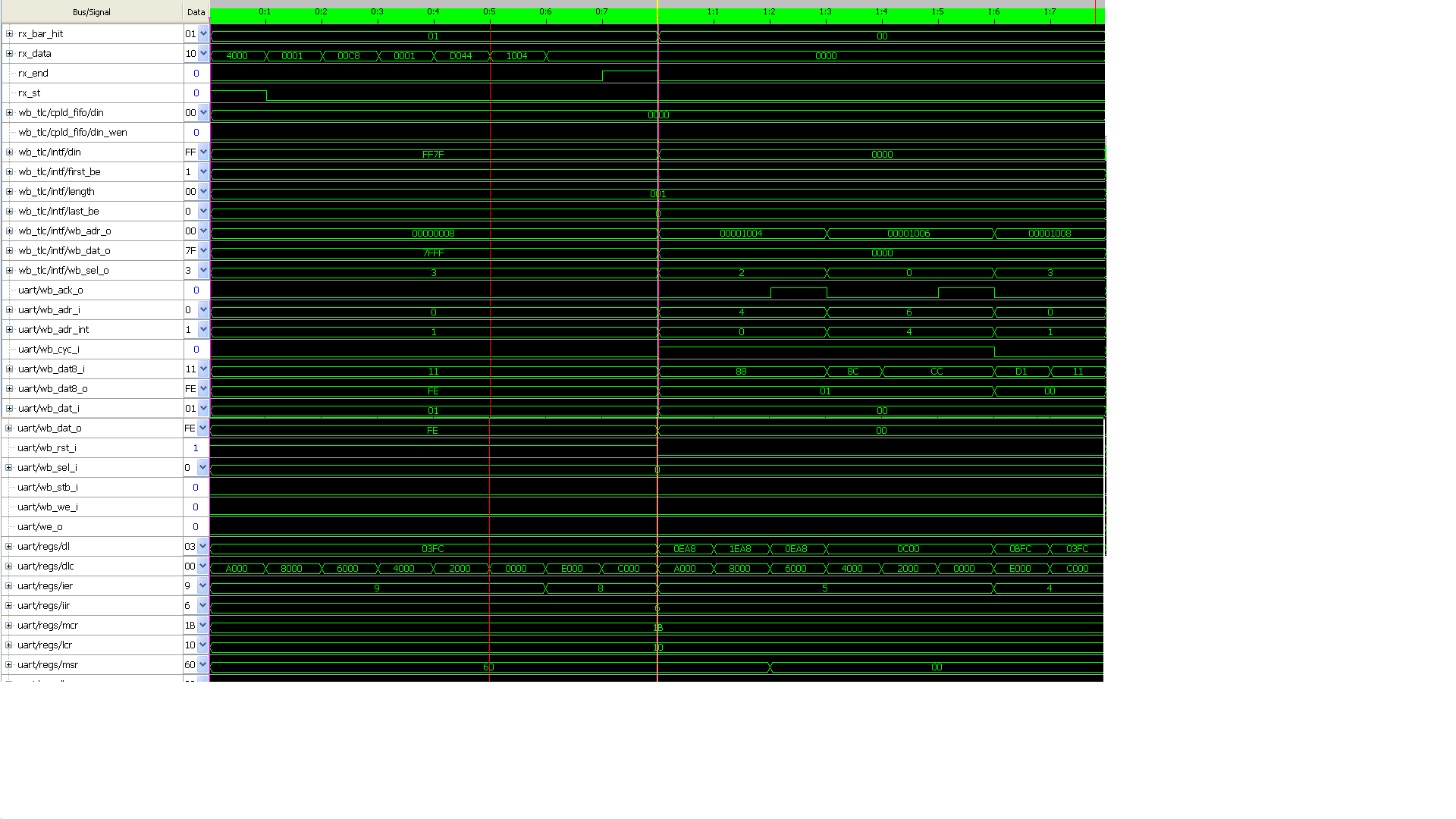
genauso sieht folgende Trace im 8 Bit Mode aus (Sieh Anhang)
2 Transaktionen habe ich gamacht:
1) Write Daten 0x03 Adresse: 0x1004 (MWr_8Bit_uart_0x03_0x1004.PNG)
2) Read Adresse: 0x1004 (MRd_8Bit_uart_0x1004.PNG )
Dann würde ich gern das UART Interface Module(uart_wb.v sih voheriges
Anhang) so ändern mit select Signal für 8 Bit Mode:
`ifdef DATA_BUS_WIDTH_8 // 8-bit data bus
always @(posedge clk or posedge wb_rst_i)
if (wb_rst_i)
wb_dat_o <= #1 0;
else
wb_dat_o <= #1 wb_dat8_o;
always @(wb_dat_is)
//wb_dat8_i = wb_dat_is;
---- > wb_dat8_i <= wb_sel_i[1] ? wb_dat_is : wb_dat8_i; < ---
`else // 32-bit bus
// put output to the correct byte in 32 bits using select line
Und Mal schauen oder bringt diese allein NICHT!
Ngii Rayan schrieb:> Dann würde ich gern das UART Interface Module(uart_wb.v sih voheriges> Anhang) so ändern mit select Signal für 8 Bit Mode:
Ja genau.
Ob die Änderungen ausreichen wird man sehen.
Der gezeigte Ausschnitt (Es ist ein kombinatorischer Prozess) hat gleich
2 Probleme.
1. Die Sensitivitylist ist unvollständig.
2. Es ist ein Latch beschrieben, sollte man bei einem FPGA vermeiden.
Zu 1: In Verilog 2001 (default bei Lattice) kann man faul sein und
einfach @(*) schreiben. (Nur für kombinatorische Prozesse)
Im Trace fehlt wb_dat_is.
Übrigens auch ein kleines Lob.
Du hast erkannt, dass man bei komplexen Designs auch Ausschnitte
simulieren kann, im Gegensatz zu manchen mit angeblichen 10 Jahren
Aerospace erfahrung, die meinen weil das Gesamtdesign zu komplex ist man
auf die Simulation verzichten muss.
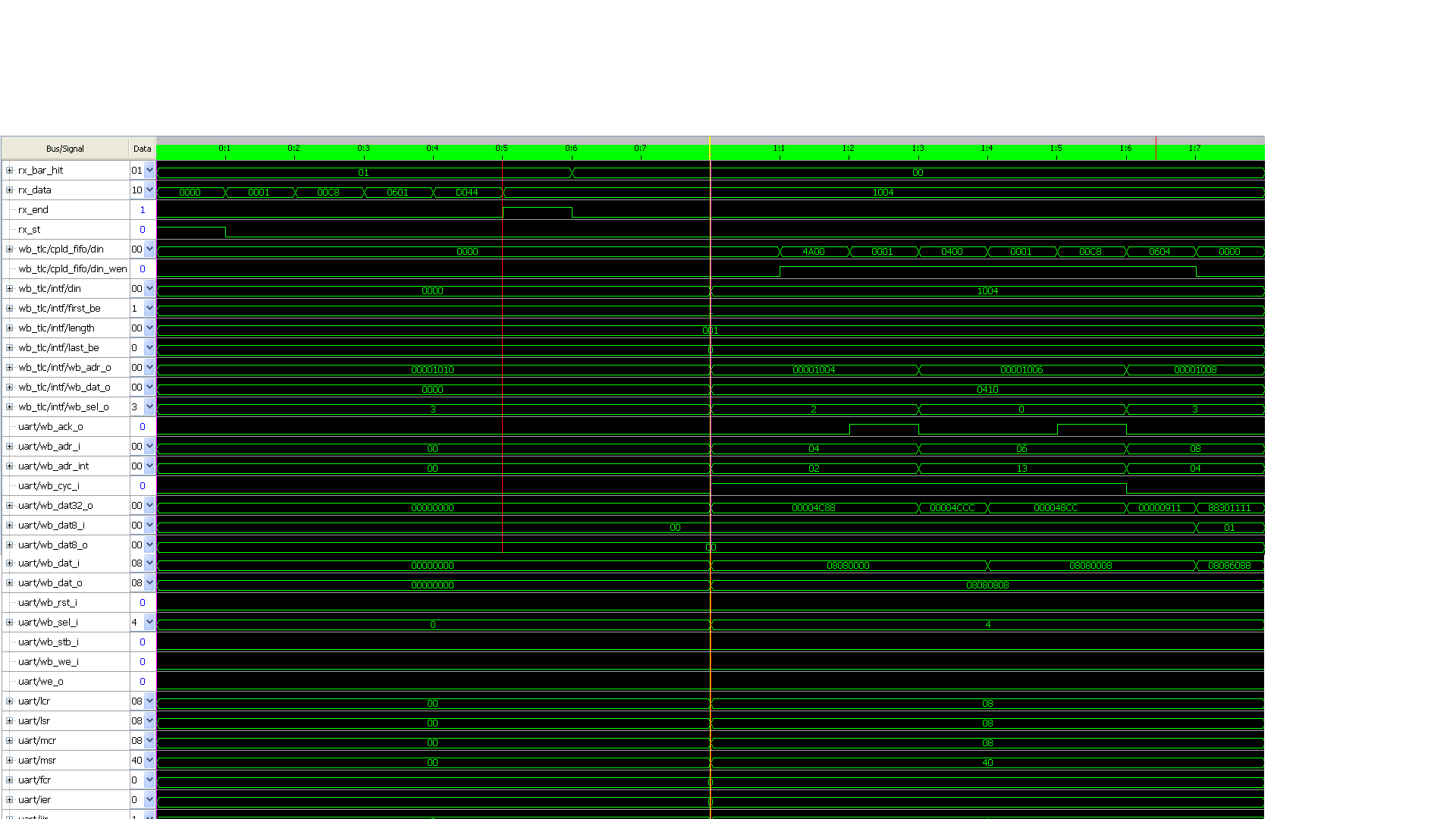
Hallo,
Danke für das Lob! Durch die Simulation versteht man einfach besser was
drin lauft! Also würde ich empfehlen...
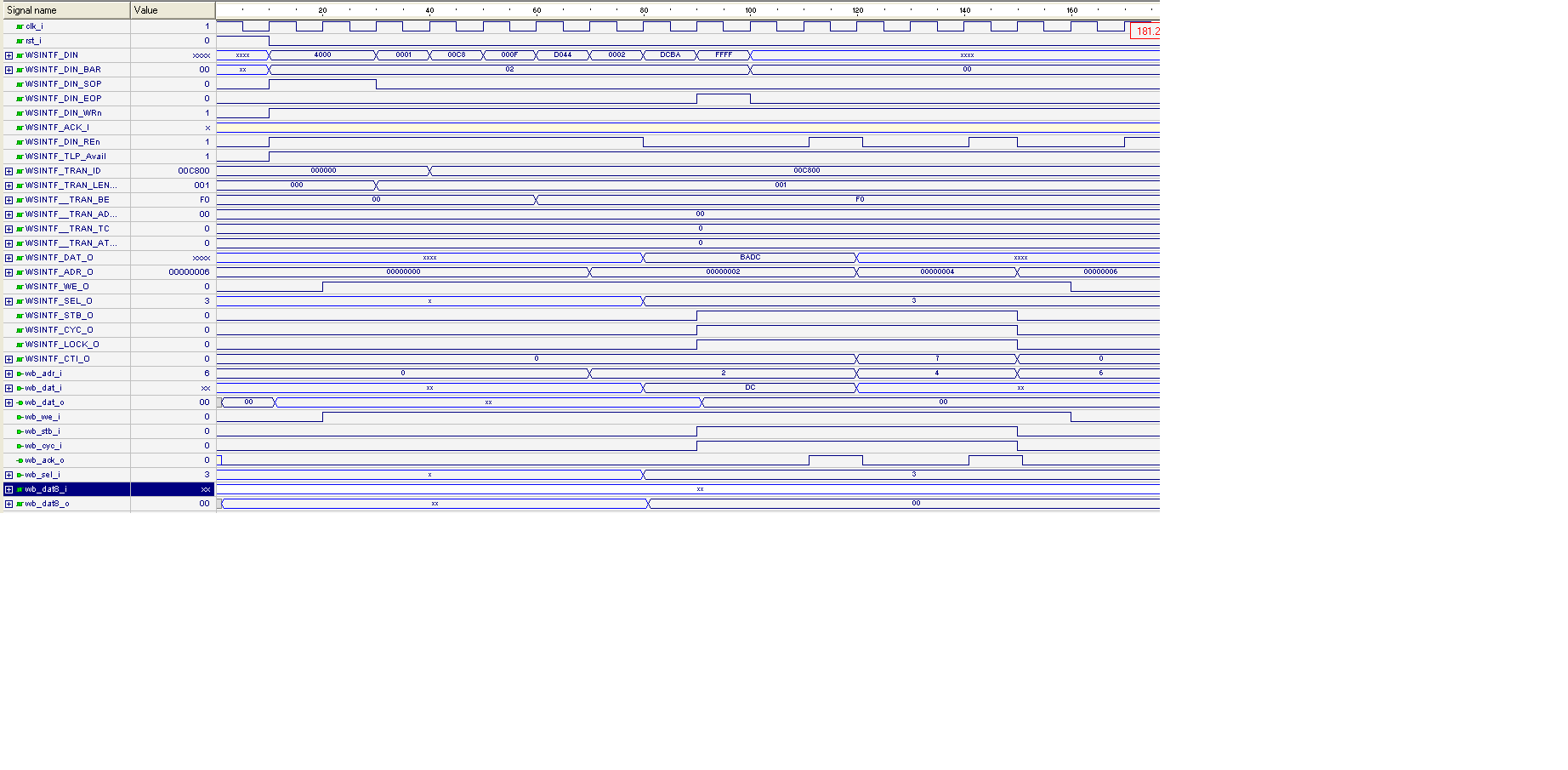
jetzt sieht meine Simulation gut aus!
Gesendet wurde
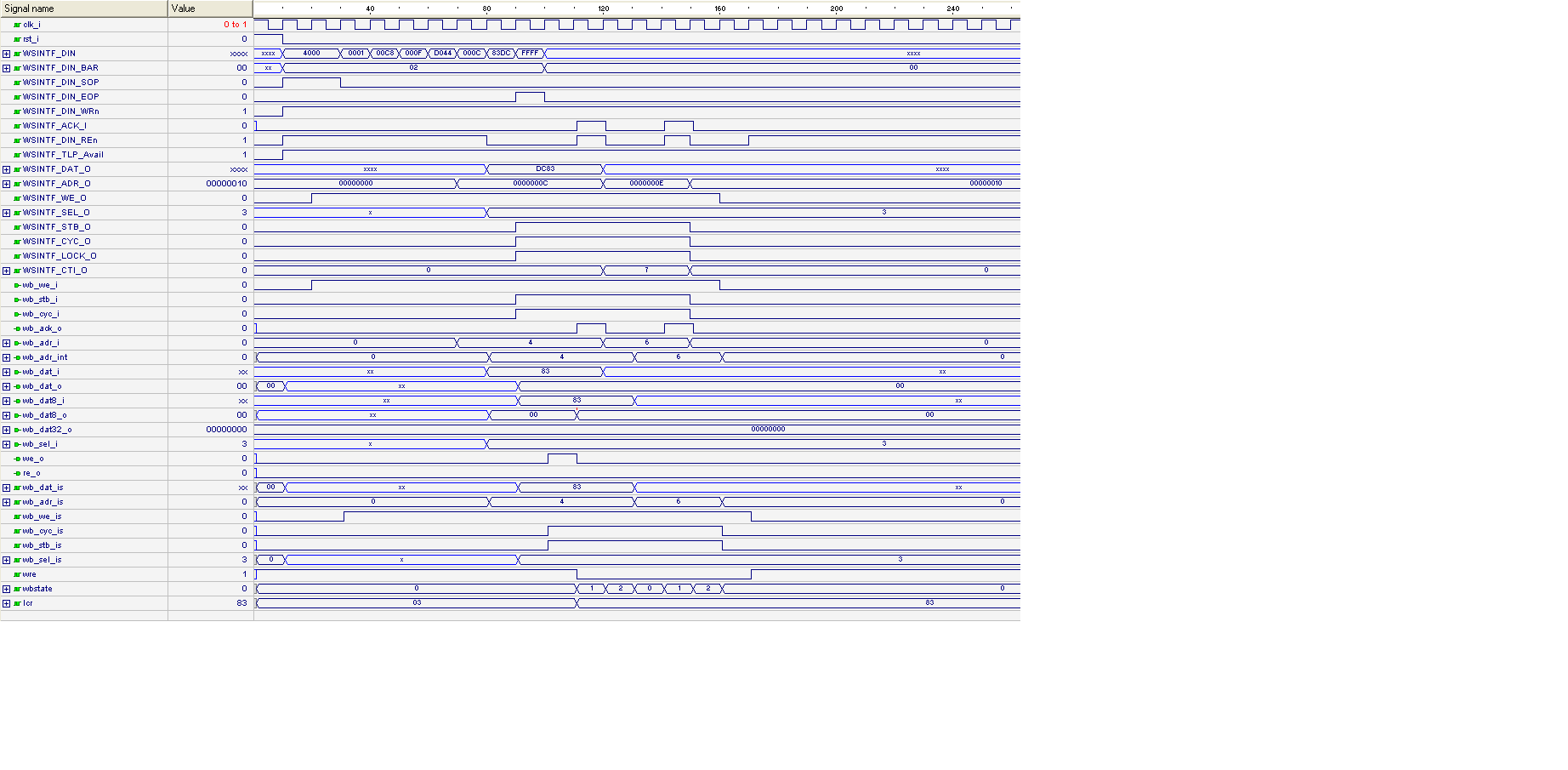
0x08 an Adresse 0x04 (also ier = Interrupt Enable Register)
Sieh Simulation_MWr_0x08_IER.PNG
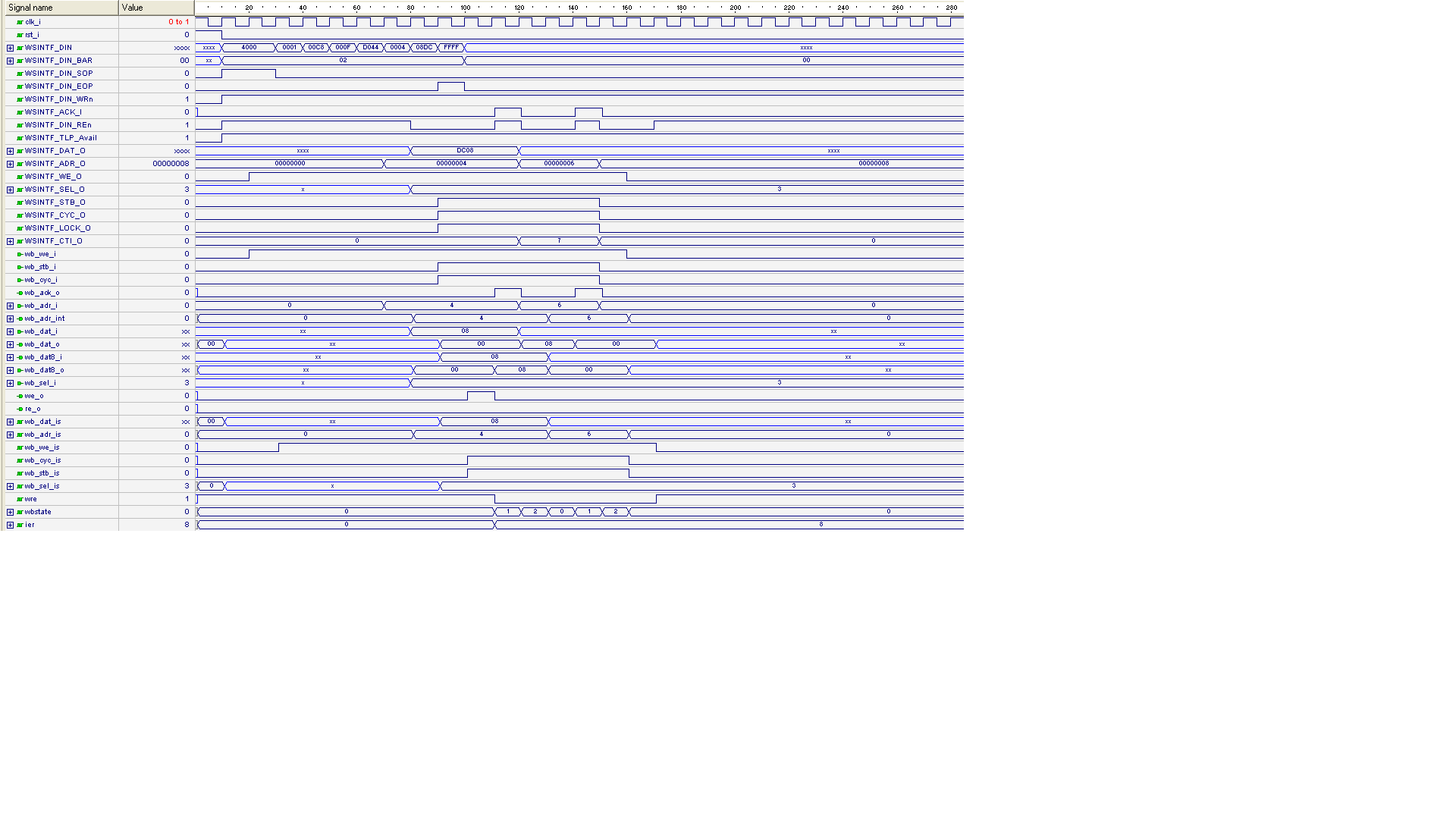
und
0x83 an Adresse 0x0C (also lcr = Line Control Register)
Sieh Simulation_MWr_0x83_LCR.PNG
Die Inhalte dieser Registern sind ganz unten zu sehen (Simulation)
Nochmals zur Errinerung wurde die Offset Register wegen Wishbone
Interface Module um 4 verschoben.
Also ier = offset:1 nun 4
lcr = offset:3 nun C
Auf Hinweise würde ich mich freuen ...
Hier eine Verbesserung !
Bei
0x83 an Adresse 0x0C (also lcr = Line Control Register)
Stimmen die Adresse nicht anstatt 0x04 sollte man eher 0x0C
Nun korrigiert
Sieh Simulation_MWr_0x83_LCR.PNG
Hallo zusammen,
Ich habe erfolgreich mein OpencoreCAN Controller über Wishbone interface
(wsb.v)simuliert.
Siehe Anhang...
alle Adresse wurden Mal 4 also :
Control Register = 0x00
Command Register = 0x04
Status Register = 0x08
Interrupt Register = 0x0C
Acceptance Code Register = 0x10
.....
Nur habe ich Probleme nach dem *.bit Download auf dem Board.
Nach dem Schreiben kann ich nicht das Gleiche Lesen...
Hat es vielleicht mit Timing zu tun da ich 125 MHz für wb_clk_i und
clk_i benutzt habe? Siehe unten
Ngii Rayan schrieb:> Hat es vielleicht mit Timing zu tun da ich 125 MHz für wb_clk_i und> clk_i benutzt habe? Siehe unten
Geht es denn in der Simulation?
Wenn die Constraints stimmen, und die Timinganalyse keine Fehler findet,
sollte es von dieser Seite in Ordnung sein.
Hallo,
Es hat mit dem CAN Bus geklappt es war einen kleinen Fehler von mir.
Also der Adresse Bus war in der Luft .
Mit 125 MHz für wishbone und CAN_clock hat problemlos funktioniert.
Also gleicher Takt für PCIe - CAN
Nun meine Frage:
PCI Express ist mit125 MHZ getaktet.
Welche Vorteil oder Risiken gibt es wenn ich Enpoint Devices mit andere
Clock takte.
Beispiel
1)- 50 MHz On Board für Asynchrone SRAM zum Waitstate Generierung.
2)- 25 MHz PLL für CAN wishbone(wb_clk_i) + CAN Clock(clk_i).
Gibt es zpezielle Anforderungen für Transport von Daten zwischen
unterschiedliche
Taktdomänen (125MHZ-PCIe und 50MHZ-CAN) oder (125MHZ-PCIe und 25
MHZ-CAN)?
Was wäre die sichere Lösungsansatzt ?
Was spricht dagegen den CAN Controller mit 125 MHz zu betreiben?
Zu klären ist allerdings folgendes:
Die 125 MHz des PCI Express Designs leiten sich von der Rerefenzclock
des PC's ab. Und diese ist mit SCC (Spread Spectrum Clocking) verseucht.
Kann man bei manchen MBs abschalten. Ansonsten wie sind die
Anforderungen von CAN an die Clockgenauigkeit und Stabilität?
Ngii Rayan schrieb:> Gibt es zpezielle Anforderungen für Transport von Daten zwischen> unterschiedliche> Taktdomänen (125MHZ-PCIe und 50MHZ-CAN) oder (125MHZ-PCIe und 25> MHZ-CAN)?
Ja, die gibt es. Lothar schreibt dass es nichts für den Anfänger ist,
wenn man da etwas falsch macht gibt es sporadische scheinbar
unerklärliche Fehler und in der Folge viele graue oder ausgerissene
Haare.
Anforderungen von CAN:
Bis jetzt wurde 25MHz Ozillator für 12.5 MHz(CAN Controller) und 500
kbps genutzt. Die Kompatibilität sollte gewährleistet werden .
Soll ich da Waitstates implementieren ?
Wenn Ja wie kann ich es am einfachstens mit Lattice implementieren?
Ngii Rayan schrieb:> Soll ich da Waitstates implementieren ?
Das reicht nicht.
Wishbone ist ein synchroner Bus, d.h. man muss alle Teilnehmer (Master
und Slaves) mit der gleichen Clock versorgen.
Es ist sicher möglich eine WB -> WB Bridge zu implementieren um
Clockdomaingrenzen zu überwinden, das ist aber nicht ganz trivial.
Übrigens hat das mit dem ursprünglichen Thema nichts mehr zu tun, es
wäre vielleicht sinnvoll einen neuen Thread speziell zum Wishbone Thema
aufzumachen, um wieder ein breiteres Publikum anzusprechen.
Wäre es möglich, einen Stand deiner Implementierung zu bekommen
(z.B. dein Beispiel mit einem UART würde schon reichen),
so dass man dies als Grundlage für eigene Versuche benutzen kann?
Oder sind deine Entwicklungen closed source
und damit leider nicht verfügbar?
Das wäre eine Lösung !
Von Lattice umsetzbar über IP Express Tool
FIFO_DC
A dual-clock FIFO using EBR (Embedded Block RAM). The FIFO_DC module
provides a variety of FIFO memory organizations. This FIFO has two
clocks. The generated netlist has gray counters to handle clock domain
transfer. Ports, properties, and functionality are described in detail
in the “See Also” section below.
Ich werde es umsetzen!
Zur Martin Maurer (capiman) Nachfrage!
Ich kann leider nur wegen Datenschtutz
dir nur Hinweise über deine Probleme geben.
Mehr darf ich leider nicht.
Überdies lernst du auch viel by learning by doing.
Ngii Rayan schrieb:> Es hat problemlos funktioniert.> Grund dafür ist : PCIe 125 MHz zur gleiche clock domäne mit mein 25 MHz> PLL can_clk.
Nein, das ist nicht der Grund.
Der Grund ist, dass die Entwickler des Opencore CANs es vorgesehen haben
(aber nirgends dokumentiert, daher taugt der Core nicht wirklich für
Anfänger).
Hier ein kleiner Auszug (für den Rückweg):
1
always @ (posedge wb_clk_i)
2
begin
3
cs_ack1 <=#Tp cs_sync3;
4
cs_ack2 <=#Tp cs_ack1;
5
cs_ack3 <=#Tp cs_ack2;
6
end
7
8
// Generating acknowledge signal
9
always @ (posedge wb_clk_i)
10
begin
11
wb_ack_o <=#Tp (cs_ack2 & (~cs_ack3));
12
end
Da ist noch viel mehr.
Wenn du verstanden hast um was es hier geht wirst du sehen dass es auch
mit einer asynchronen CAN Clock gehen sollte.
Ngii Rayan schrieb:> Zur Martin Maurer (capiman) Nachfrage!>> Ich kann leider nur wegen Datenschtutz> dir nur Hinweise über deine Probleme geben.> Mehr darf ich leider nicht.> Überdies lernst du auch viel by learning by doing.
Dir ist klar dass sowohl der CAN Core, als auch der UART Core von
Opencores unter der LGPL Lizenz stehen?
Spätesten deinen eigenen Kunden wirst du alle deinen Modifikationen
offenlegen müssen. Obendrein musst du ihnen die Möglichkeit geben selbst
Änderungen an den LPGL Cores zu machen, was im Prinzip darauf
hinausläuft, dass du deinen gesamten Source überreichen musst.
Also was soll die Geheimniskrämerei.
Bin ich einverstanden!
Nur darf ich nicht das gesamte Design senden.(Vielleicht am Ende )
Hinweis was zur Opencore geändert werden soll ok!
Ich möchte auch dass er viel verstehe. Von dir habe ich Hinweis immer
bekommen dann habe ich versuche by doing herauszufinden.
Wenn du alles zu mir gesendet hättest. Glaub mir hätte ich keine
Simulation gemacht was meinn Vertandnis verstärkt hat.
Also ich bin bereit zu helfen. Ich schreibe eine Private Mail zu ihm so
können wir Kontakt halten.
Übrigens in welchem Opencore Can Controller Module ist dein kleiner
Auszug (für den Rückweg):
1
always@(posedgewb_clk_i)
2
begin
3
cs_ack1<=#Tpcs_sync3;
4
cs_ack2<=#Tpcs_ack1;
5
cs_ack3<=#Tpcs_ack2;
6
end
7
8
//Generatingacknowledgesignal
9
always@(posedgewb_clk_i)
10
begin
11
wb_ack_o<=#Tp(cs_ack2&(~cs_ack3));
12
end
Das finde ich nicht hast du vielleicht ein anderer Opencore ?
Ngii Rayan schrieb:> Das finde ich nicht hast du vielleicht ein anderer Opencore ?
Ich habe keinen, nur online geschaut. (http://opencores.org/project,can)
Da ich auf Opencores nur einen CAN Controller für WB in Verilog gefunden
habe, nahm ich an, dass es der ist den du auch benutzt. Ausserdem gibt
es dort die 2 getrennten Clocks wb_clk_i und clk_i, wie in deinen
Auszügen.
Die Stelle ist im module can_top, ziemlich weit unten.
Kleiner Hinweis:
Das #Tp im Opencan Core ist überflüssig und wirkt nur auf die
Simulation, manche brauchen es halt um sich Sand in die Augen zu
streuen.
Damit hat der kleine Versatz zwischen der roten Linie und den Clocks
nichts zu sagen. (Wie gesagt nur Sand im Auge des Betrachters)
(An die VHDLer, das ist das Gleiche wie ein after in VHDL)
Um zu sehen was da wirklich passiert, solltes du die Simulation mal mit
einer asynchronen Clock machen, mit einer möglichst krummen bezogen auf
die 125 MHz.
OK!
so sieht es aus: sieh Anhang: besser habe ich verstanden und bin
gespannt was mit dem UART für 25 MHz passieren wird ?
Nun eine Frage:
Aus meinem bisherigen Verstandnis dachte ich dass, Prefetchable Memory
BAR immer 64 Bit sein sollte.Kann man auch mit 32 Bit oder ?
Mein Ziel ist Asynchrone SRAM 1 MB als Endpoint Device was Prefetchable
bedeutet.
Nun darf man 32 Bit (1 BAR) oder muss man 64 Bits(also 2 BARs) ?
Tut mir Leid Hier die Simulation !
Nun eine Frage:
Aus meinem bisherigen Verstandnis dachte ich dass, Prefetchable Memory
BAR immer 64 Bit sein sollte.Kann man auch mit 32 Bit oder ?
Mein Ziel ist Asynchrone SRAM 1 MB als Endpoint Device was Prefetchable
bedeutet.
Nun darf man 32 Bit (1 BAR) oder muss man 64 Bits(also 2 BARs) ?
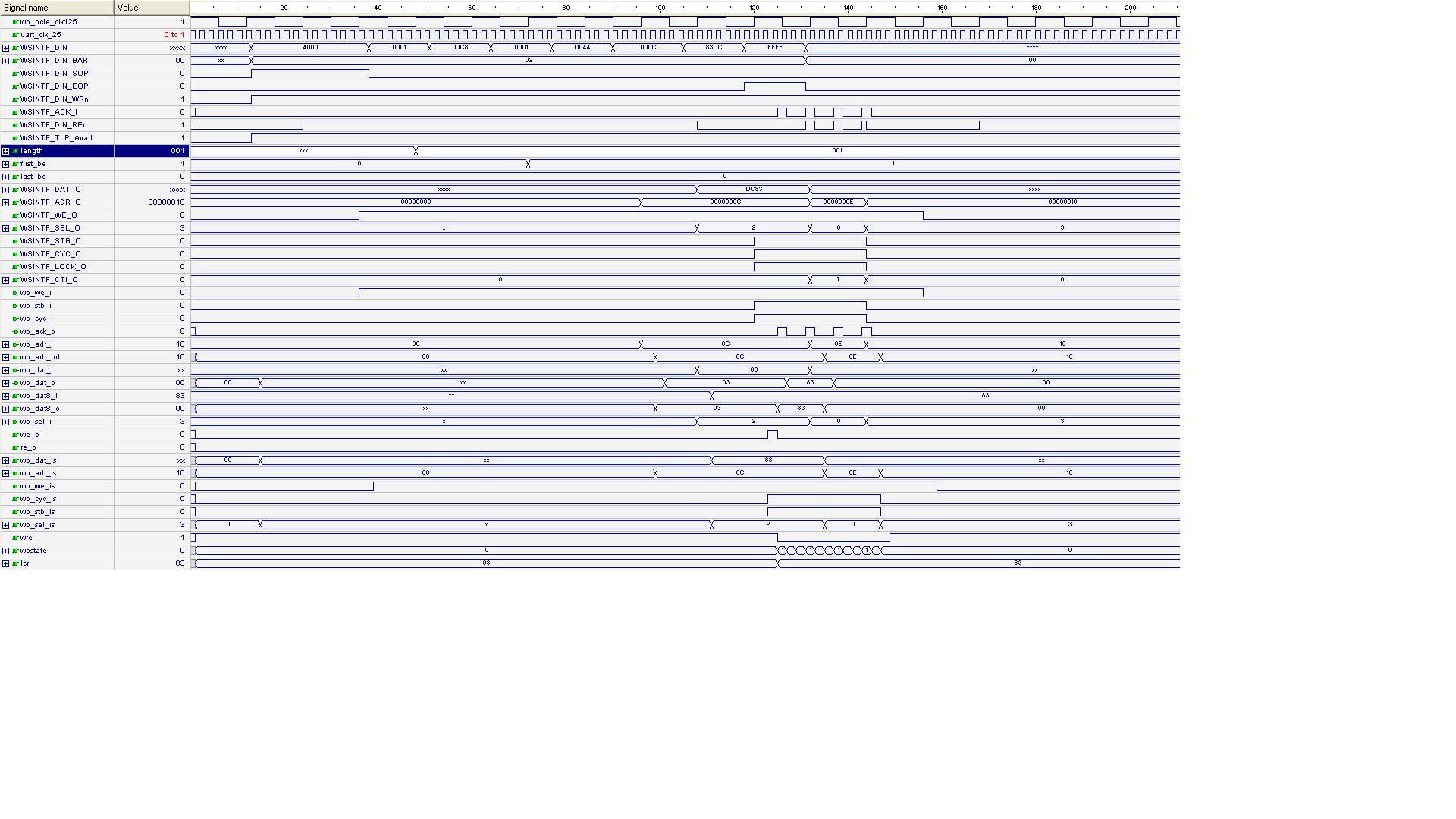
Hat als auch mit dem UART Opencore (25 MHz) zumindest mit der Simulation
geklappt.
Wishbone Inerface= 125 MHz
UART = 25 MHz
Auch wenn Ack Signal 4 Mal gesendet wird
nur der erster berücksichtigt ist (we_0=1 sonst we_0=0)
Ngii Rayan schrieb:> Aus meinem bisherigen Verstandnis dachte ich dass, Prefetchable Memory> BAR immer 64 Bit sein sollte.Kann man auch mit 32 Bit oder ?>
Ja sollte gehen.
Bei PCI Express ist das übrigens egal, du kannst sowohl 32 als 64 Bit
BARS beliebig kennzeichnen.
Die Unterscheidung stammt aus der PCI Bridge Spezification und hat damit
zu tun dass es beim PCI Protokol keine Burstlänge gibt, sondern der
Burst beendet ist wenn die CPU keine Lust mehr hat. Damit es schnell
geht muss eine PCI Bridge also auf der Deviceseite vorrauslesen
(prefetch) und zuvielgelesene Daten wegschmeissen.
Damit die PCI Bridge unterscheiden kann ob prefetch erlaubt its, hat sie
zwei Addressfenster, je eines für nonprefetch und prefetch. Das für
nonprefetch kann nur 32bit Addressen umsetzen.
Eine PCIe Bridge hat wegen der Rückwärtskompatibiltät auch diese 2
Fenster, braucht aber die Zugriffe nicht unterschiedlich behandeln da
das PCIe Protokoll eine Längenangabe enthält.
Allerdings dürften die meisten BIOSe und Betriebsysteme immer noch so
tun als ob es wichtig wäre.
Wenn das BIOS/OS auf eine 64bit Bar ohne prefetch stösst, wird halt
immer noch eine 32bit Addresse zugewiesen und verschwendet wertvollen
Addressraum im < 4GByte Bereich. Übrigens für jedes Device gleich 1
MByte, egal wie klein deine BARs sind.
> Mein Ziel ist Asynchrone SRAM 1 MB als Endpoint Device was Prefetchable> bedeutet.> Nun darf man 32 Bit (1 BAR) oder muss man 64 Bits(also 2 BARs) ?
Die ist klar was Prefetchable auch cachable aus der Sicht der CPU
bedeutet und du extra Aufwand im Treiber hast?
Ngii Rayan schrieb:> Hat als auch mit dem UART Opencore (25 MHz) zumindest mit der Simulation> geklappt.>> Wishbone Inerface= 125 MHz> UART = 25 MHz>
Wofür wird die UART Clock verwendet? Nur für den Baudrategenerator, oder
auch für den Registerzugriff?
Wenn ersteres, hat das Uartmodule intern korrekte Clockdomaincrossings?
Hallo zusammen,
eine Woche lang war ich krank !
Erstens vien Dank für die 32/64 Bit BARs Erklärung. Ich werde weiterhin
mit 64 Bits für SRAM machen.
Nun zu deiner Fragen:
1) Wofür wird die UART Clock verwendet? Nur für den Baudrategenerator,
oder auch für den Registerzugriff?
2) Wenn ersteres, hat das Uartmodule intern korrekte
Clockdomaincrossings?
Antworte: auch für den Registerzugriff
Nach dem Test funktioniert es aber ich werde den Test mehrmal
durchführen um eine Sicherheit zu haben.
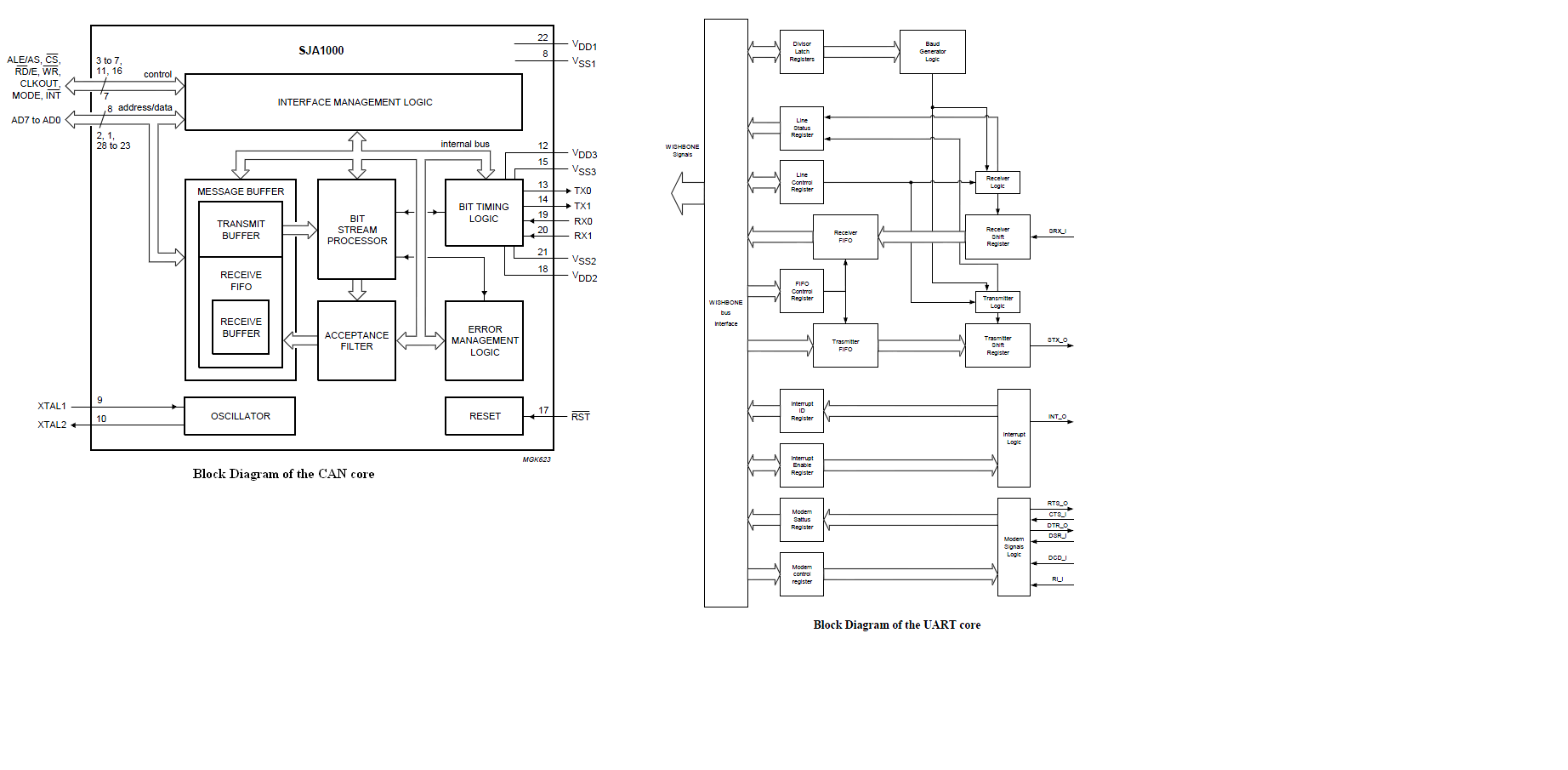
Nun meine Fragen:
Es is nirgendwo geschrieben ob Opencore CAN/UART Interrupt Hight oder
Low aktive sind.
Aber wenn man der Blockdiagram anschaut(Sieh Anhang),
scheint UART16550 aktive High aktive und CAN aktive Low zu sein. Ist es
So oder bin ich falsch?
Ich benutze MSI (rising Edge Interrupt). Nur wollte ich mir klar machen
welche Typ von Interrupts von Slave Device generiert werden.
Hallo alle Lattice user,
Hier ein Beispiel zur Lattice Wishbone Interface <-->8Bit UART Slave
Kommunikation als Basis für einen Einstieg.
Bei Fragen stehe ich gern zur Verfügung.
Hallo zusammen,
ich arbeite auch mit Lattice IP Core und habe Problem mit der
Adressierung:
Ursprunglich wird der Zugrrif auf Devices wie folgende:
1
wb_arb#(.c_DATA_WIDTH(16),
2
.S0_BASE(32'h0000),
3
.S1_BASE(32'h4000),
4
.S2_BASE(32'h1000),
5
.S3_BASE(32'h5000)
6
)wb_arb(
7
.clk(clk_125),
8
.rstn(core_rst_n),
9
10
//PCIeMaster
11
.m0_dat_i(pcie_dat_o),
12
.m0_dat_o(pcie_dat_i),
13
.m0_adr_i(pcie_adr),
14
.m0_sel_i(pcie_sel),
15
.m0_we_i(pcie_we),
16
.m0_cyc_i(pcie_cyc),
17
.m0_cti_i(pcie_cti),
18
.m0_stb_i(pcie_stb),
19
.m0_ack_o(pcie_ack),
20
.m0_err_o(),
21
.m0_rty_o(),
22
23
//DMAMaster
24
.m1_dat_i(16'd0),
25
.m1_dat_o(),
26
.m1_adr_i(32'd0),
27
.m1_sel_i(2'd0),
28
.m1_we_i(1'b0),
29
.m1_cyc_i(1'b0),
30
.m1_cti_i(3'd0),
31
.m1_stb_i(1'b0),
32
.m1_ack_o(),
33
.m1_err_o(),
34
.m1_rty_o(),
35
36
//GPIO32-bit
37
.s0_dat_i(gpio_dat_o),
38
.s0_dat_o(gpio_dat_i),
39
.s0_adr_o(gpio_adr),
40
.s0_sel_o(gpio_sel),
41
.s0_we_o(gpio_we),
42
.s0_cyc_o(gpio_cyc),
43
.s0_cti_o(gpio_cti),
44
.s0_stb_o(gpio_stb),
45
.s0_ack_i(gpio_ack),
46
.s0_err_i(gpio_err),
47
.s0_rty_i(gpio_rty),
48
49
//DMASlave
50
.s1_dat_i(16'd0),
51
.s1_dat_o(),
52
.s1_adr_o(),
53
.s1_sel_o(),
54
.s1_we_o(),
55
.s1_cyc_o(),
56
.s1_cti_o(),
57
.s1_stb_o(),
58
.s1_ack_i(1'b0),
59
.s1_rty_i(1'b0),
60
.s1_err_i(1'b0),
61
62
//EBR
63
.s2_dat_i(ebr_dat_o),
64
.s2_dat_o(ebr_dat_i),
65
.s2_adr_o(ebr_adr),
66
.s2_sel_o(ebr_sel),
67
.s2_we_o(ebr_we),
68
.s2_cyc_o(ebr_cyc),
69
.s2_cti_o(ebr_cti),
70
.s2_stb_o(ebr_stb),
71
.s2_ack_i(ebr_ack),
72
.s2_err_i(ebr_err),
73
.s2_rty_i(ebr_rty),
74
75
//Notused
76
.s3_dat_i(16'd0),
77
.s3_dat_o(),
78
.s3_adr_o(),
79
.s3_sel_o(),
80
.s3_we_o(),
81
.s3_cyc_o(),
82
.s3_cti_o(),
83
.s3_stb_o(),
84
.s3_ack_i(1'b0),
85
.s3_rty_i(1'b0),
86
.s3_err_i(1'b0)
87
);
Nur möchte ich eher sowas:
wb_arb #(.c_DATA_WIDTH(16),
.S0_BASE (32'h4000),
.S1_BASE (32'h4008),
.S2_BASE (32'h4010),
.S3_BASE (32'h4018)
) wb_arb (
erlauben dann habe der Wishbone Arbiter so angepasst:
Leider kann ich damit nur Devices 4000 und 4010 zugreifen aber nicht
4008 und 4018
Bitte was soll ich noch da machen um mein Ziel zu erreichen ?
Beigefügt ist der Arbiter zu finden..














{kind=link}