


Hallo! Habe da ein Problem mit einer SD-Karte. Bei Schreiben(WRITE_SINGLE_BLOCK) mit konstanter daten-rate (und auf konsekutive blöcke) von meinem ATMega168 gibt es Phasen, wenn die SD Card auf ein mal viel viel länger zum Schreiben eines Blocks benötigt (0.130s statt 0.005s). Das erste Bild (IMG1) zeigt das typische Pattern - lange zeit kann ich mit konstanter Geschwindigkeit schreiben, aber in regelmäßigen Abständen kommt es zu "Aussetzern". Das zweite Bild (IMG2) zeigt einen Zoom wo man das Verhalten schon etwas besser sieht. In diesem Fall sieht man zumindestens 64 Blöcke die in annähernd gleicher Zeit geschrieben sind (siehe Insbes. Clock1 und das dortige Muster) Man sieht auch, daß ich alle 32 Blöcke mehr Clocks brauche (Dickerer Balken) um die nächsten 32 Pages vorab zu löschen. Und dann am Schluß sieht man den Fall, wo der Block write 0.13s benötigt. (und dieser Block ist nicht an einer typischen "block-grenze") Und im letzten Bild sieht man dann den zoom in auf so eine "lange" Pause. Typischer weise sind das dann 3 Blöcke in Serie, wovon 2 extrem lang und einer kürzer ist. In diesem Fall ist der letzte (kürzere) Block von einem "erase pages" gefolgt (was man an der kurzen "spitze" und der weiter laufenden Clock erkennt). Daher handelt es sich um block 29,30,31 aus meiner Sequenz. Man erkennt auch daß die meiste Zeit nicht mit dem eigentlichen schreiben der Daten verschwendet wird, sonder mit dem auf die SD-Karte warten. Dies ist natürlich kein optimales Verhalten für meinen CAN Bus logger, den ich ja primär schreibe um einen "unfall" zu protokollieren (ala. Blackbox). Und da ich annehme, daß es im Fehler-Fall viele Nachrichten übertragen werden, sollte die Blackbox auch beim Schreiben mit-halten können... Die momentanen Tests laufen bei 500KBit CAN bus und ca. 50% Bus-Auslastung. Das einzige, was mir einfällt, ist einen ATMega mit mehr SRAM zu nehmen (8 oder 16k) um solche "delays" abzufangen (=buffern). Aber mehr Buffer bedeutet auch, daß die letzten Daten nicht rechtzeitig geschrieben werden können, wennn dann im Falle eines Unfalles der Strom auch noch ausgeht... (in meinem Fall: Wasser Einbruch ins Uboot mit darauf-folgendem Strom-ausfall) - momentan habe ich 16 CAN messages buffer... Aber vielleicht hat jemand eine Idee, wie ich diese "Aussetzer" umgehen kann ohne unbeding mehr buffern zu müssen? Danke, Martin
Die SD-Karte mit ihrem internen Wear-Level und Bad-Block Management ist für Dich eine Black Box. Für Echtzeitaufgaben ist sie nicht gedacht. Die von Dir beobachteten Pausen passieren, ohne dass Du hier eingreifen kannst. Wenn das für Dich nicht akzeptabel ist, wirst Du eben ein anderes Speichermedium nehmen müssen, bei dem Du selber den Speichercontroller implementierst. NAND-Flash wäre da eine Alternative. Hier wirst Du Dich um Bad Blocks und Wear Leveling selber kümmern müssen, aber dafür ist das NAND-Flash deterministisch(er). fchk
> die SD Card auf ein mal viel viel länger zum Schreiben eines Blocks > benötigt (0.130s statt 0.005s). Das gilt noch als schnell, wir hatten schon Karten die gelegentlich mehr als 0.3 Sekunden brauchen. Da helfen nur große Puffer - wir benutzen den LPC1768 mit insgesamt 64 KB SRAM, da ist genügend Platz. > Blackbox Du musst dann Deine Stromversorgung so auslegen, dass die Blackbox noch die Daten nach dem Unfall wegschreiben kann. Übrigens kennen SD-Karten auch einen "Write multiple Sectors" Befehl. Dort kann es aber auch zu Wartezeiten kommen, insbesondere wenn man über die Grenze einer Page schreibt - gängige Karten haben IIRC 2 MB pro Page. Vorsicht bei Versogung aus einer Batterie: Der Stromverbrauch könnte deutlich höher sein als beim Scheiben von einzelnen Sektoren. Allerdings kann man der Karte vorher sagen, wieviele Blöcke geschrieben werden sollen (ACMD23, SET_WR_BLK_ERASE_COUNT) - ganz verhindert das die Wartezeiten aber nicht.
Nimm lieber einen anderen Controller. STM32F3 oder F4 haben ein 4Bit SD-Karten Interface dabei und minestens 64kB Ram. Damit sollte es locker gehen. Grüsse
Zu den internas von SD-Karten und mit welchen blocksizes+alignment man am besten arbeitet findet man hier: https://wiki.linaro.org/WorkingGroups/Kernel/Projects/FlashCardSurvey und https://lwn.net/Articles/428584/
Das ist mir (leider) schon bewußt... Ich hoffe immer noch, daß es vielleicht eine Möglichkeit gibt die Situation zu verbessern - in dem man Z.b: mehr Blöcke vorab löscht oder ähnliches... Es muß ja irgendwie schneller gehen, denn wie bekommt man sonst am PC die Daten schneller auf die Karte? Der echte Daten-transfer mach ja nur 1/3tel der Zeit für das gesamte Schreiben eines Blockes aus, den rest der Zeit wartet man bis MISO auf high geht)... Und das wear-leveling sollte sich eigentlich auch nicht verbessern, wenn ich echtes "SD" sprechen würde und nicht nur "SD-SPI". Der einzige Vorteil am "PC" ist, daß der einen große Write-cache hat und das so "verstecken" kann... Und im "Falle eines Unfalles" ist nacher dann die SD-Card herausnehmen und in den Card-reader zu stecken einfacher als bei einem NAND... Was mir einfällt sind: * MultiBlock-Write - braucht leider auch mehr Buffer... * Erase von mehr (größeren Blöcken) * immer "genügend" Blöcke gelöscht lassen * andere Karte verwenden (>2GB, mit höherer Geschwindigkeit,...?) Ich hoffe daß ich nicht der Erste bin, der eine derartige Erfahrung gemacht hat, und daß es einen Lösungsansatz dafür gibt (beziehungsweise die Tests gemacht hat)... Martin
>Und im "Falle eines Unfalles" ist nacher dann die SD-Card herausnehmen >und in den Card-reader zu stecken einfacher als bei einem NAND... File System läuft auch noch? Der arme Atmega. Ich weiss zwar nicht was du alles protokollierst und sonst noch machst,aber ich gehe im worst case von ca. 50kByte/s aus. Nicht gerade wenig im SPI Modus. Zu den SD Karten: bei mir haben sich die Sandisk Karten immer als die schnellsten dargestellt. Könntest du vlt. probieren. Grüsse
Martin Sperl schrieb: > Ich hoffe immer noch, daß es vielleicht eine Möglichkeit gibt die > Situation zu verbessern - in dem man Z.b: mehr Blöcke vorab löscht oder > ähnliches... Nein. Gibt es nicht. > Es muß ja irgendwie schneller gehen, denn wie bekommt man sonst am PC > die Daten schneller auf die Karte? Der PC überträgt 4 Bit pro Takt im MCI-Modus, aber die gelegentlichen Pausen hast Du auch dort. Das fällt da aber nicht weiter auf. > Und das wear-leveling sollte sich eigentlich auch nicht verbessern, wenn > ich echtes "SD" sprechen würde und nicht nur "SD-SPI". Das Übertragungsprotokoll beeinflusst die Operation des SD-internen Memorycontrollers nicht. > Und im "Falle eines Unfalles" ist nacher dann die SD-Card herausnehmen > und in den Card-reader zu stecken einfacher als bei einem NAND... ... das Du im Ernstfall auch irgendwie steckbar machen kannst. Früher gab es die flachen SmartMedia-Karten und die XD Karten. Beides sind dumme Flashkarten ohne eigene Intelligenz - der Controller steckt hier im Kartenleser. So ein System wäre für Dich geeigneter. Oder Du baust Dir Deine eigene PCMCIA-Karte mit NAND-Flash innendrin. Steckplätze und Leergehäuse gibts bei Digikey. Das ist das einzige, was WIRKLICH deterministisch funktioniert. Du darfst natürlich auch gerne fertige PCMCIA-Flash-Karten verwenden, aber nur Linear Flash Cards (*)(die nur NOR-Flashes enthalten) und keine ATA-Flash-Cards mit eingebautem IDE-Controller (und deswegen auch keine CF Cards). Nochmal zum mitmeißeln: Der Flash-Controller im einer SD-Karte ist für Dich eine nichtdeterministische Blackbox. Du wirst niemals zuverlässig vorhersagen können, wann er seine Pausen einlegt und wie lange die dauern werden. > Ich hoffe daß ich nicht der Erste bin, der eine derartige Erfahrung > gemacht hat nein, und Du wirst auch nicht der letzte sein, der feststellen wird, dass er ein für seine Zwecke ungeeignetes Medium verwendet. >, und daß es einen Lösungsansatz dafür gibt (beziehungsweise > die Tests gemacht hat)... Mööööp. fchk (*) http://www.tecsys.de/de/speicherkarten/pcmcia-linear-flash.html
Danke für den Tip: ich werde es mit einer SAN-Disk Karten probieren... Vielleicht geht die "besser" zum Thema Filesystem: * "nackt" - entweder gar kein Filesystem: SD karte wird linear geschrieben und dann einfach via
1 | dd if=/dev/sdX of=daten bs=1M |
gelesen * "fake" FAT16/32, mit einer großen Datei. Das FS ist so "getuned" (beim "formatieren"), daß die Blöcke der Datei durchgehend in Sequenz sind, dann brauche ich mir nur ersten und letzten Block der Datei merken und schreibe dazwischen die Daten mit Rollover - die daten-records bekommen so wie so einen Timestamp, sodaß man den Rollover erkennen kann... (ist eigentlich nichts anderes wie oben, nur daß es noch einfacher ist, die daten zu lesen). Momentan fahre ich meine Tests mit der Option "nackt" - der Aufwand für den Daten-logger sollte sich auch in Grenzen halten und ich hoffe nicht, daß ich das Uboot so oft nach einem fatalen Fehler analysieren muß... So ganz nebenbei: Mein geplanter Hauptprozessor für die Orchestrierung der module dess Uboots - ein Raspberry Pi - mit einem mcp2515 unter Linux verschluckt sich and der hier beschriebenen Daten-rate nach einiger Zeit... Der ATMega verkraftet das einwandfrei - halt bis auf das SD-Karten-problem und dem damit verbundenen Datenverlust... Der momentane Zwischenstand aller Kommentare zeigt: Ich werde mir halt einen Mega mit mehr Speicher (als Buffer) für den Fall der Unfälle nehmen mussen und muß im schlimmsten Fall die letzten Daten ins AVR-eeprom sichern... Danke, Martin
Also ich habe mich noch etwas herumgespielt und habe dabei einen für mich "überraschenden" Umstand beobachtet: Nachdem ich den Karten block an die Karte geschickt habe muß ich dann ja die Karte wegen ihres "Status" pollen, bis sie mit dem Schreiben fertig ist. Wenn ich an dieser Stelle zum Beispiel 1ms delay einfüge, so verlängert sich die "Wartezeit" direkt um 1ms. Meine These ist jetzt, daß der Controller auf der SD Karte die Clock cycles von SPI braucht um intern zu laufen... Demnach müsste die Clock-rate am SPI Bus so hoch wie möglich sein um möglichst rasch zu sein - und nicht nur <50% der Zeit (code vom gcc nach vorgaben aus dem AVR manual). Ich werde versuchen diesen code-teil einmal via assembler so zu optimieren um auf fast 100% duty cycle auf SCK zu kommen. Dann werden wir sehen wie sich das ganze verhält... Wenn die These sich bestätigt, so wäre der "delay dann nur mehr 0.065s", was doch schon um einiges besser ist als der Status quo... (aber ohne größerem Buffer werde ich wohl trotzdem nicht auskommen) Ich halte Euch über das Ergebnis dieser Tests auf dem Laufenden... Ciao, Martin
Martin Sperl schrieb: > Ich werde versuchen diesen code-teil einmal via assembler so zu > optimieren um auf fast 100% duty cycle auf SCK zu kommen. Dann werden > wir sehen wie sich das ganze verhält... Da laberst du aber grade Mist =P Bei 100% Duty Cicle kannste gleich 3,3V auf CLK legen, lol ... mehr als CLK/2 als SPI takt geht beim AVR nicht, selbst mit Port toggeln kommste nich schneller. Da hilfts nur nen AVR zu nehmen, der bei 3,3V mehr Takt kann oder ihn auf 5V laufen lassen mit Pegelwandlern. Wobei die Idee an sich schon komisch klingt o0
OK - war vieleicht nicht ganz "korrekt" ausgedrückt - die Frage ist was man als ON/OFF zählt! Ich habe bei den Rechnungen das Maß "Clock läuft, clock läuft nicht" genommen. Momentan läuft SCK für einige Zeit (8 SPI-Clock-ticks) und dann ist für cirka die selbe Zeit "Ruhe" auf SCK (low). Also wenn man "SCK" läuft/läuft nicht nimmt, so ist es 50% Duty cycle und diesen kann man dann im Ideal-fall bis auf 100% bringen. Nach der Rechnung der einzelnen Clocks Ticks wäre das dann 25% Duty cycle, was man dann im Ideal-fall auf 50% treiben kann.
Dann guck mal hier: http://www.matuschek.net/atmega-spi/ Schneller als das geht dann nicht, weil der AVR ja noch das Register füttern muss.
Danke! Wie ich das "schätze" produziert dein Code 2 SCK-clock ticks idle und damit 40% duty cycle wenn man die SCK-clock ticks zählt... Aber wenn man ASM-Clocks zählt (wie du es auch in Deinem Kommentar schreibst), so geht das ganze (zumindestens beim "echten" SPI) noch schneller! Dort schaffe ich es die "Pause" auf einen SCK-clock tick zu reduzieren... - sprich 44%(=8/(2*9)*100%) Duty cycle beim Zählen der SCK-ticks und das ist dann schon sehr nahe an den 50% des Idealfalls (erreichbar mit CPUs mit DMA engines oder größeren FIFO buffern...) Das geht natürlich nur, wenn man wirklich mit dem clock divider von 2 arbeitet - sonst ist der Aufwand "sinnlos". Ab einem Divider von 8 ist eine normale "Schleife aus dem AVR-handbuch" schnell genug... Ich muß zugeben, daß ich mir auch nicht sicher bin, ob das ganze in allen "Situationen" korrekt funktionert - aber dann wäre die SPI-implementation des AVR auch nicht deterministisch... Ich werde es einfach einmal lange zeit laufen lassen und dann schauen, ob es zu "Fehlern" kommt... Sieht dann circa so aus (in diesem Fall ist der code unrolled):
1 | ... |
2 | ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; |
3 | ;; the data3 byte arrives |
4 | in tmp, rSPDR |
5 | ;; push out next byte request over SPI |
6 | out rSPDR,SPIFILL |
7 | ;; now we have 18 cycles for calculations |
8 | ;; store the byte now |
9 | st Z+,tmp |
10 | ;; we are at 2 cycles here, so we have some time to spare (14 exactly) |
11 | nop |
12 | nop |
13 | nop |
14 | nop |
15 | nop |
16 | nop |
17 | nop |
18 | nop |
19 | nop |
20 | nop |
21 | nop |
22 | nop |
23 | nop |
24 | nop |
25 | ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; |
26 | ;; the data4 byte arrives |
27 | in tmp, rSPDR |
28 | ;; push out next byte request over SPI |
29 | out rSPDR,SPIFILL |
30 | ;; now we have 18 cycles for calculations |
31 | ;; store the byte now |
32 | st Z+,tmp |
33 | ;; we are at 2 cycles here, so we have some time to spare (14 exactly) |
34 | nop |
35 | nop |
36 | nop |
37 | nop |
38 | nop |
39 | nop |
40 | nop |
41 | nop |
42 | nop |
43 | nop |
44 | nop |
45 | nop |
46 | nop |
47 | nop |
48 | ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; |
49 | ;; the data5 byte arrives |
50 | ... |
Das unrolling macht bei 14 Transfers in einem IRQ handler Sinn, wenn man statt den NOP Befehlen andere Berechnungen durchführen möchte um die Zeit im IRQ möglichst kurz halten möchte. (Außerhalb des Interrupts geht es dann nur um die Kommunikation mit der SD-Karte...) Das geht dann leider etwas zu Lasten der Leserlichkeit, halbiert aber in meinem Fall fast die Zeit, die im IRQ vertrödelt wird... Martin
Angehängte Dateien:
Hallo! Also ich habe den Code soweit optimiert habe, das ich jetzt den SPI bus extrem effizient betreibe (keine Clock verschwendet - siehe auch angehängtes Bild vom Logic-analyzer). Damit kann ich 512 Byte in 0.000512s (sprich 1 Byte in 0.0000001s) bei 8MHz SPI Takt übertragen! Leider muss ich feststellen, daß sich diese Optimierung sich nicht auf die "Latenzen" der SD-Karte auswirkt. Daher der SD-card-controller doch nicht von der Bus-clock getrieben wird, sondern doch eine eigene clock haben dürfte. Also ist es keine Möglichkeit zur Beschleunigung der SD-Karte... - Vielleicht ginge es eine Class10 Karte zu verwenden, aber das würde das Problem auch nicht 100% aus der Welt schaffen... Jetzt werde ich wohl FRAM als Buffer und einen AVR mit 1x SPI und 2 USART nutzen müssen um dieses Problem zu lösen... Danke allen für ihre Mithilfe... Martin
> Leider muss ich feststellen, daß sich diese Optimierung sich nicht auf > die "Latenzen" der SD-Karte auswirkt. Das war laut Spezifikation auf sdcard.org nicht anders zu erwarten. > Class10 Karte Kartenklassen wirken sich nicht auf den SPI Modus aus, sondern sind nur im SD Modus interessant. Es könnte aber durchaus ein schnellerer Controller oder schnelleres Flash verbaut sein - aber eventuell ist auch die AU Size größer, d.h. die Flash Blöcke sind größer. IIRC gilt die Speed Class nur beim Schreiben von ganzen AUs, was auch bei Class 10 Latenzen von mehr als 200 ms ermöglicht.
Angehängte Dateien:
{kind=link}
Nachtrag zur Dokumentation (falls andere einmal ähnliche "Probleme"
haben sollten):
Bei der von mir verwendeten Karte zeigt sich das Verhalten, daß diese
Mindestens 3.5ms Zeit benötigt bis ein einzelner Block als geschrieben
gilt (typischer Weise bis 7.5ms).
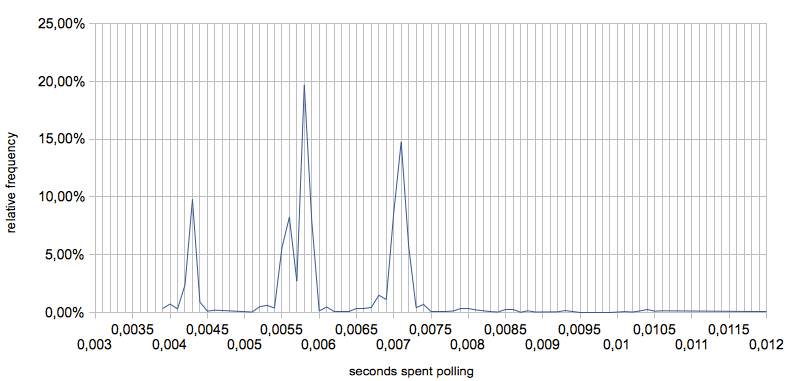
Wenn man ein Histogramm aus 5503 Messungen der Zeiten, die für Polling
aufgewendet werden müssen, zeichnet, so ergibt sich eine signifikante
Häufung bei 4.3, 5.8 und 7.1ms - siehe Bild.
Das genaue Verhalten kann für andere Karten anders sein, soll aber ein
Beispiel für ein mögliches zu erwartendes Verhalten sein.
Wenn man nach dem Senden der Daten an die SD-Karte für einige Zeit
überhaupt keine Clock vorgibt - daher wenn man nach dem korrektem
Empfang der Daten (sprich nach dem Senden der 2 bytes dummy Checksum und
dem folgendem Status byte, wo die niedrigsten 5 bit den Wert 5 haben
sollten) 3.0 ms wartet und dann erst beginnt den Status zu pollen (ob
MISO high ist), dann verzögert sich die Zeit bis die Daten geschrieben
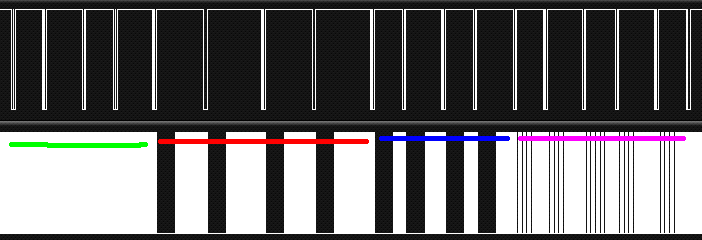
werden um die gewarteten 3.0 ms - siehe Bild (Zeigt MOSI und CLOCK) der
"rote" Teil.
Wenn man stattdessen entweder:
* die ganze Zeit polled ( grün - 50% duty cycle auf clock)
* oder ein mal polled und dann 3ms wartet und dann bis zum Ende polled
(blau)
* oder wenn man 30 mal im Abstand von 100us polled und dann bis zum ende
polled (purpur)
So ergibt sich zwischen diesen letzten 3 Szenarien keine großen
Unterschiede in der Laufzeit...
Nur sofortiges Warten (ohne einmaligem pollen am Anfang) bedeutet eine
direkte Verzögerung um die Wartezeit.
Daher kann man nach dem der Block an die Karte geschickt wurde und man
mindestens ein mal gepolled hat, sich einige Zeit lassen (z.b: zum Strom
sparen schlafen legen und durch einen Timer wecken lassen) und man muß
dann erst pollen...
Auf jeden Fall scheint hoch-optimiertes pollen nicht nötig zu sein um
höchste Geschwindigkeit beim Schreiben zu erreichen -sie muß nur
angestoßen werden ihre Arbeit zu tun...
Ich werde dieses Wissen nutzen um einen "Sekundärbuffer" in FRAM zu
implementieren...
Vielleicht hilft ja diese Beobachtung in Zukunft jemandem einmal ;)
Ciao,
Martin
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.