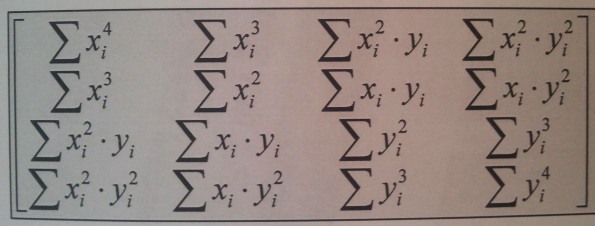
Hallo, Ich bin ein Anfänger in VHDL und bin gerade dabei die elemente einer (4*4)Matrix auszurechen. Ich hab zwei Arrays x und y jeweils aus 32 elemente, und muss z.B. Summe(x^2 * y), Summe(x^4), ... (die Elemente könnt ihr im Anhang sehen) für N = 1..32 ausrechnen. Mein Ansatz: Array: type MessSignal is array (0 to 2) of std_logic_vector(3 downto 0); Element ausrechnen: Sumx2y:= (y(0)*y(0)+x(0))+(y(1)*y(1)+x(1))+(y(2)*y(2)+x(2));(Nur für N = 3) Sumx2:= x(0)*x(0); . . . Meine frage: Kann ich das noch sowie C mit einer for schleife verallgemeinern ?
Angehängte Dateien:
-

2012-12-25_13.59.23.jpg
42 KB
ja natürlich
einfach folgendes schreiben
gen_label: for i in 0 to 2 generate
MessSignal(i) <= hier die rechnung hinschreiben;
end generate
Vielen Dank für die Antwort,
Ich hab das folgendermassen geschreiben
type MessSignal is array (0 to 31) of std_logic_vector(3 downto 0);
variable Cos : MessSignal;
variable Sin : MessSignal;
for n in 1 to 32 loop
SumSin(n) := sin(n); -- sum(y)
SumCos(n) := Cos(n); -- sum(x)
SumSinCos(n) := cos(n)*sin(0); --
sum(xy)
SumSin2(n) := sin(n)*sin(n); --
sum(y^2)
SumCos2(n):= cos(n)*cos(n); -- sum(x^2)
end loop;
d.h Die Summe von alle Sin is SumSin(31) aber im Synthesis bekomme ich
den Fehler das SumSin und SumCos2 unterschiedliche längen haben !
wie kann ich den Fehler vermieden ?
In VHDL rechnet man für Matritzen am Besten mit der Sarrusschen Regel, wenn man es sequenziell rechnen oder es in dieser Weise formulieren will. Das Umbrechen der Indizes geht einfach über Restklasse/Modulo.
J. S. schrieb: > In VHDL rechnet man für Matritzen am Besten mit der Sarrusschen Regel Die Regel von Sarrus gilt aber nur für 3x3 Matrizen. http://de.wikipedia.org/wiki/Sarrussche_Regel Es handelt sich um einen Spezialfall der Leibniz-Formel. Jihad Alayan schrieb: > Ich bin ein Anfänger in VHDL und bin gerade dabei die elemente einer > > (4*4)Matrix auszurechen.
Grössere Matritzen rechnet man meist nicht mehr elementar durch. Das kann man rekursiv schachteln, weil bei der Zahl der ADDs/MULs in VHDL langsam an die Resourcen geht und man idealerweise soviel in einen Schritt packt, wie zeittechnisch in einen Takt geht. Eine 3x3 ist von einem schnellen FPGA noch in 1-2 Takten zu machen.
Angehängte Dateien:
-

LinearGleichung.png
6,4 KB
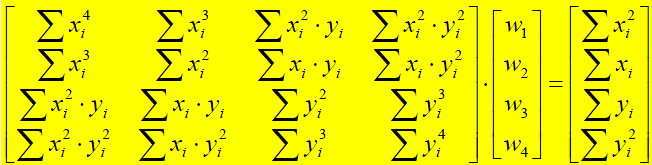
Hallo wie Würdet ihr denn das lösen ? Ich habe das mit dem Cramersche Regel, leider klappt es nicht weil es auch viele Resourcen braucht !.
Moin, ich habe mal einen Matrizen-Beschleuniger gehackt, gibt da mehrere Tricks, siehe angehängte Bilder (sorry wegen Skalierung) - Matrizengrösse ist eine Potenz von zwei -> Divide et impera. (fscalpr.pdf) - Matrizengrösse beliebig: 'interleaved'-Berechnung der Elemente und Akkumulieren mit Delay (ilpu.pdf). - Komplette Multiplikation in 1 Takt erforderlich: Dann gehts so wie oben beschrieben, für 2D-Faltungen braucht man allerdings noch etwas Schiebe/Buffer-Logik. Wenn so ein Ding etwas komplexere Berechnungen (bei niedrig gehaltendem Resourcenverbrauch) machen soll, kommt man nicht umhin, die Pipeline von Hand zu codieren und sie auch immer voll zu halten. Grüsse, - Strubi
Angehängte Dateien:
-

matrix.png
23 KB
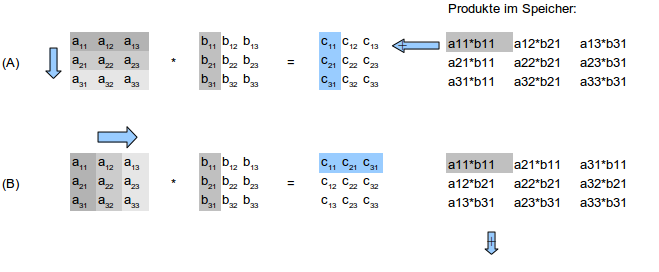
Hi Jad, den Code dazu kann ich leider nicht hergeben, ist Teil einer spezifischen DSP-Engine. Ist aber keine riesige Hexerei, Du musst Dir nur die Dimensionierung des Delays genau überlegen. Zur Veranschaulichung noch das Matrizen-Multiplikationsschema angehängt. (A) würdest du es vermutlich klassisch auf dem Papier machen, (B) die alternative Variante bei der das transponierte Ergebnis herauskommt. Massgeblich dabei ist die Anordnung der Produkte im Speicher oder in der Pipeline. Bei (B) lässt sich per Delay die Latenz des Akkumulators so nutzen, dass jeweils alle Produkte modulo N (hier: N = 3) summiert werden (siehe auch blauer Pfeil für die Additions-Richtung). Bei voller Pipe kriegst Du dann eine Operation pro Clock, die Total-Latenz (bis ein Ergebnis am Ausgang anliegt) ist halt etwas grösser. Die Sache lässt sich relativ beliebig parallelisieren, man dreht jeweils nur am Delay bzw. muss die Ausgänge korrekt multiplexen oder umsortieren. Dasselbe übrigens auch am Dateneingang, da sind ev. auch Delays/FIFOs nötig um die Daten "interleaved" an die Engine zu schicken. Sorry für das Fachchinesisch :-) Und viel Erfolg!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.