Hallo,
habe mal wieder eine Frage. Stecke aktuell in einem Projekt drin, wo ich
Bilddaten (Pixeldaten) komprimieren will. Warum und wieso lass ich jetzt
mal weg, hat schon einen bestimmten Grund (Vllt. nur kurz zu erwähnen,
um bestimmte Datenraten einhalten zu können).
So nun zu meinem aktuellen Stand. Habe mittels FFT die Bilddaten
eingelesen und mir die Real und Imaginärwerte angesehen. Ist in
Vergleich zu den Matlab-Referenzwerten in Ordnung. Nun habe ich eine
Huffman-Tabelle, wo ich die FFT Output Daten skaliert einlese, um daraus
ein Bitstrom zu generieren. Den Bitstrom habe ich unter Delphi schon
einen Kollegen generieren lassen, sodass ich als Ergebnis einen
Kompressionsfaktor von ca. 2 sah, was mich zum Ziel führt.
Meine Frage beruht sich nun darauf, wie ich diesen Bitstrom bilden soll.
Aktuell habe ich folgendermaßen programmiert:
Die Skalierten FFT daten werden als Addresse für einen BRAM (Huffman
Tabelle) benutzt, wo dann ebend die Bitstrom-Daten + die gült. Bitanzahl
hinterlegt sind.
Z.B. habe ich eine Zahl 1 aus der FFT dann wird im BRAM die Addresse 1
ausgelesen und gibt mir folgendes als Ergebnis: "0001010101010101" &
"0000000000001110". Das Ergebnis sagt mir nun, dass auf den Bitstrom 14
Bits gelegt werden müssen (von rechts aus gesehen, also
"01010101010101").
Jetzt lege ich diese Bits in eine Zwischenvariable bis neue Daten
kommen. Und hier liegt mein Problem, ich muss die Daten nun
verschieben/shiften/platz machen, um neue Daten aufzunehmen bis eine
bestimmte Menge gefüllt ist, sodass es wieder entleert werden kann.
Vllt. ein bisschen durcheinander, aber die Frage halte ich ein bisschen
Allgemein, wie sollte man nach der Huffman-Tabelle vorgehen, wie sollte
der Bitstrom erzeugt werden?
Quellcode zu posten habe ich erstmal sein lassen, wollte das jetzt
keinem antun, ist schon zuvieles drin, bis man sich reinfindet dauerts.
Würde mich über jede Hilfestellung sehr freuen.
mfg Cihan
Cihan Kalayci schrieb:> bis eine bestimmte Menge gefüllt ist
Wie groß ist diese "bestimmte" Menge?
Denn so, wie due es da jetzt gerade beschrieben hast, ist das erst mal
ein Monstermultiplexer...
Cihan Kalayci schrieb:> "0001010101010101" & "0000000000001110".> Das Ergebnis sagt mir nun, dass auf den Bitstrom 14 Bits gelegt werden> müssen
D.h. die zweite Zahl wird nicht größer als 16?
Kannst du da mal ein längeres Beispiel geben?
Lothar Miller schrieb:> Cihan Kalayci schrieb:>> bis eine bestimmte Menge gefüllt ist> Wie groß ist diese "bestimmte" Menge?> Denn so, wie due es da jetzt gerade beschrieben hast, ist das erst mal> ein Monstermultiplexer...
mit bestimmte Menge meine ich eigentlich nur 64 Bits, die dann in einen
Fifo reingeschrieben werden. Die Zwischenvariable ist 128 Bits groß.
D.H. sobald mehr als 63 Bits in der zwischenvariable drin ist, raus
damit, in den Fifo damit, den Rest mit neu ankommenden Daten
umsortieren.
> Cihan Kalayci schrieb:>> "0001010101010101" & "0000000000001110".>> Das Ergebnis sagt mir nun, dass auf den Bitstrom 14 Bits gelegt werden>> müssen> D.h. die zweite Zahl wird nicht größer als 16?> Kannst du da mal ein längeres Beispiel geben?
Die Zahlen bzw. Bits können höchstens 15 werden, wobei es auch
Sonderzeichen gibt. Im groben können in einem neuen Takt von mind. 4 -
62 bits in die Zwischenvariable (in den Bitstrom kommen).
Ich versuch mal ein längeres Beispiel darzustellen.
Nehmen wir an wir haben folgende Huffman Tabelle:
Bram-Addresse Bits Anz.gült.Bits
0 11 2
1 1000 4
2 00001 5
3 10111 5
...
252 011000111110101 15
253 010100001110011 15
254 010101001110001 15
255 010101001110111 15
Nun kommt aus der FFT folgende Real und Imaginärzahlen raus (daten sind
skaliert):
Real: 18000, 299, 0, 3, 255, ...
Imag: 0, 2, 252, 1500, 5000, ...
Als erstes wird die Huffman Tabelle in den Addressen 18000 und 0
abgefragt. Hierbei muss ich erwähnen, dass es zwei Huffman Tabellen
sind, jeweils real und imaginärteil. Dabei sind beide Huffman-Tabellen
mit 1024x32 Bits implimentiert.
Nun wird geguckt: 18000 außerhalb des Bram Addressbereiches also
sonderzeichen, d.h. eine bestimmte bitfolge("01010101001011") + die
18000 landen im Bitstrom. Weiterhin wird für den imag. Teil die Addr. 0
gelesen, also kommen die Bits "11" auf den Bitstrom.
(Sonderzeichen) (18000) (Imag-Teil)
Aktueller Bitstrom: 01010101001011 00100011001010000 11
Bitstrom-Größe: 33
Im nächsten Beispiel müssen nun die 299 und 2 genommen werden, auch hier
hat der Real Teil ein Sonderzeichen, der Imag bekommt die Bits "00001"
(siehe ob. Tabelle), also ergibt sich der nächste Bitstrom:
(vorherige Daten)
Aktueller Bitstrom: 010101010010110010001100101000011
01010101001011 00000000100101011 00001
(Sonderzeichen) (299) (Imag-Teil)
Bitstrom-Größe: 33 + 36 = 69
Jetzt müssen die ersten 64 Bits in ein Fifo. D.h. im nächsten Takt, raus
aus dem akt. Bitstrom, rein in ein fifo. Der rest des Bitstroms muss nun
mit den neu ankommenden Daten weiter verknüpft werden.
Und das geht so weiter bis die FFT ihre Arbeit fertig geleistet hat.
hoffe das Beispiel ist verständlich genug. Wäre echt dankbar wenn ihr
mir dabei Tipps geben könntet.
Achso, vllt. noch erwähnenswert.
Ich versuche schon seit letzter Woche die Implimentierung für den
Bitstrom hinzubekommen. Habe dabei immer das Problem, dass die Synthese
ewigkeiten dauert und dabei im Arbeitsspeicher auch eine sehr große
Auslagerungsdatei abgelegt wird ( > 3GB). Die Simulation mit ISIM unter
Xilinx läuft, der Bitstrom wird erzeugt, aber wenn ich es synthesieren
will, hat XST bzw. ISE echt probleme.
Wie sollte man bei sowas denn am besten vorgehen?
Cihan
Cihan Kalayci schrieb:> Habe dabei immer das Problem, dass die Synthese ewigkeiten dauert> und dabei im Arbeitsspeicher auch eine sehr große Auslagerungsdatei> abgelegt wird ( > 3GB).
Hört sich nach "Kombinatorikmonster" an...
> Die Simulation mit ISIM unter Xilinx läuft, der Bitstrom wird erzeugt,> aber wenn ich es synthesieren will, hat XST bzw. ISE echt probleme.
Das ist absolut kein Problem, sowas hinzubekommen. Ich behaupte, das
schafft man mit einem kleinen Dreizeiler, wenn eine Schleife beteiligt
ist.
Cihan Kalayci schrieb:> Jetzt müssen die ersten 64 Bits in ein Fifo. D.h. im nächsten Takt, raus> aus dem akt. Bitstrom, rein in ein fifo. Der rest des Bitstroms muss nun> mit den neu ankommenden Daten weiter verknüpft werden.>> Und das geht so weiter bis die FFT ihre Arbeit fertig geleistet hat.
Das ist ein riesiger Multiplexer, kein Wunder, dass die Synthese da so
lange braucht. Lass doch mal das Zusammensetzen des Bitstroms sehen.
Ich poste mal einen Ausschnitt aus meinem aktuellen Code (siehe Anhang,
code.vhd).
Aktuell habe ich versucht mit dem operator shift_left zu arbeiten. Was
erstmal geklappt hat. die Synthese dauert aber immer noch sehr sehr
lange, wobei er jetzt nur so ungefähr < 1GB Auslagerungsdatei erstellt
hat.
@Lothar:
Würde mich interessieren, ob die Programmierung sinnvoll ist bzw. ob man
sowas mit einem shift_left machen könnte.
Cihan
Wahrscheinlich ist der Code ein bisschen unübersichtlich.
Nochmal ein update:
Ich hab diesen Code im FPGA implimentiert, der funktioniert auch. Nur
ich bekomme bei Place&Route Timing-Fehler, die vorher nicht da waren.
Wahrscheinlich kommen sie durch die shift_left-Operationen zustande?
Da kommt mir die Frage dann, ob man die Vektorverschiebungen mit dem
shift_left-Operator machen sollte oder gibt es eine bessere Lösung?
Cihan
Kleiner Hinweis von mir: Ich würde die konstanten Operationen der
konstanten Ausdrücke derart zusammenfassen, dass es lesbar wird. Diese
kommen an mehreren Stellen vor.
z.B.
'Sonstwas_SIZE '
statt
'VALID_BIT_SIZE_im + SZ_BIT_SIZE'
Die Integer-Werte "VALID_BIT_SIZE_im" und "VALID_BIT_SIZE_re" ändern
sich im jeden Takt. Meinst du dass ich die zu einer Variablen
zusammenfassen soll und die so im code verwenden soll?
Cihan
i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO (BIT_SIZE - 64));
ist fehler anfällig,
z.B. bit_size=8
DATA_STREAM((7 DOWNTO -56);
Bleibt 64 bit breit. Ich weiss auch nicht ob downto bis in den
Minusbereich geht.
schreibe besser: wird gleich übersichtlicher.
i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO 0);
Die Frage: Wievile Zeit hast du muss in einem Takt alles passieren?
René D. schrieb:> i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO (BIT_SIZE - 64));>> ist fehler anfällig,>> z.B. bit_size=8> DATA_STREAM((7 DOWNTO -56);>> Bleibt 64 bit breit. Ich weiss auch nicht ob downto bis in den> Minusbereich geht.>>> schreibe besser: wird gleich übersichtlicher.>> i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO 0);>>> Die Frage: Wievile Zeit hast du muss in einem Takt alles passieren?
Zeitmäßig habe ich nur 10ns, ich takte ja mit 100 MHz.
Und die Zeile:
i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO (BIT_SIZE - 64));
wird nur dann aufgerufen wenn BIT_SIZE > 64 ist, d.h. das Fifo wird
immer mit 64 gült. Bits geladen. Der Minusbereich den du meinst tritt
nicht auf.
Als Beispiel nehmen wir mal an dass BIT_SIZE 70 ist (>64), also sieht
die Zeile dann so aus:
i_USER_FIFO_DIN <= DATA_STREAM((70 - 1) DOWNTO (70 - 64));
i_USER_FIFO_DIN <= DATA_STREAM(69 DOWNTO 6);-- 64 Bits
Cihan
>> Zeitmäßig habe ich nur 10ns, ich takte ja mit 100 MHz.>
kannst du das Schieben und in den Fifo legen in unterschiedlichen Takten
durchführen?
Könnte dein Problen entspannen.
Muss Bit_size nicht eine Konstante sein?
Ist dein Fifo 64 bit breit?
Selbst wenn du eine 64bit breiten Fifo hast, bekommst du die Daten mit
64bit Breite aus dem FPGA. Mach einen max. 32bit breiten Fifo. Da musst
du nicht so viel schieben. Das würde sehr viel FPGA Resourcen sparen. Es
kann aber passieren du muss zwei Werte in den Fifo legen. Und wenn der
FiFo in der Annahme überlastet ist und keine neuen Werte gerade
entgegennehmen kannm muss ein busy Signal an den eigentlichen
Huffmandecoder gehen.
Für mach mal eine Pause.
René D. schrieb:> Muss Bit_size nicht eine Konstante sein?
Bit_Size wird in jedem Takt aktualisiert, er gibt ja an wie viele Bits
gerade in der Ziwschenvariable Data_Stream gültig sind.
René D. schrieb:> Ist dein Fifo 64 bit breit?
Mein Fifo ist 64 Bit breit, ja und zwar aus folgendem Grund: Data_Stream
kann in einem Takt 4 Bits - 62 Bits aufnehmen. D.h. z.B. wenn Bit_Size
aktuell 33 ist und es werden nun weitere Bits in Data_Stream
geschrieben, dann wird Bit_Size ebend zu 33+62= 95. Nun lese ich die
oberen 64 Bits von Data_Stream in den Fifo ein und die restlichen Bits
müssen nun wieder mit neu ankommenden Bits in Data_Stream. Und hier ist
die Schwierigkeit. Wenn ich es so mache wie im obigen code (code.vhd,
siehe weiter oben), dann dauert die Synthese sehr lange und er hat auch
noch Timing-Fehler.
René D. schrieb:> Selbst wenn du eine 64bit breiten Fifo hast, bekommst du die Daten mit> 64bit Breite aus dem FPGA. Mach einen max. 32bit breiten Fifo. Da musst> du nicht so viel schieben. Das würde sehr viel FPGA Resourcen sparen. Es> kann aber passieren du muss zwei Werte in den Fifo legen. Und wenn der> FiFo in der Annahme überlastet ist und keine neuen Werte gerade> entgegennehmen kannm muss ein busy Signal an den eigentlichen> Huffmandecoder gehen.> Für mach mal eine Pause.
32Bit wird wahrscheinlich zu wenig sein, da ich in jedem Takt bis zu 62
Bits neue Daten bekommen könnte. Um es so wie du beschrieben hast machen
zu können müsste ich den FFT Output entweder nochmal zwischenspeichern
(was ich vermeiden will) oder den Output stoppen können.
Cihan
Moin,
weiss nicht, ob's hilft, aber ansich musst Du nur untenstehenden C-Code
in VHDL giessen, allerdings mit einer grösseren Bitbreite für Deinen
Fall (hier nur 32).
Das geht mit 2 oder 3 Zyklen Latenz, je nach Durchsatzanforderungen.
Der Code ist aus einer JPEG-Implementation. Die VHDL-Version kann ich
leider nicht posten. Aber Huffman-Coder sollten sich diverse in
verschiedenen JPEG-Encodern finden lassen. Würde den mal als separate
Entity synthetisieren um das Problem zu isolieren.
Ahja: data und numbits sind daten resp. Anzahl bits, bitindex beginnt
bei null. Fürs "flushen" der letzten feststeckenden Bits musst Du Dir
noch 'n Signal reinbauen.
Strubi schrieb:> Moin,>> weiss nicht, ob's hilft, aber ansich musst Du nur untenstehenden C-Code> in VHDL giessen, allerdings mit einer grösseren Bitbreite für Deinen> Fall (hier nur 32).> Das geht mit 2 oder 3 Zyklen Latenz, je nach Durchsatzanforderungen.>> Der Code ist aus einer JPEG-Implementation. Die VHDL-Version kann ich> leider nicht posten. Aber Huffman-Coder sollten sich diverse in> verschiedenen JPEG-Encodern finden lassen. Würde den mal als separate> Entity synthetisieren um das Problem zu isolieren.>> Ahja: data und numbits sind daten resp. Anzahl bits, bitindex beginnt> bei null. Fürs "flushen" der letzten feststeckenden Bits musst Du Dir> noch 'n Signal reinbauen.>>
>> Viel Erfolg,>> - Strubi
Ich habs auch in Delphi umgesetzt. Da geht es ja dann nicht um Timing
(grob gesehen), wo ich hier in VHDL probleme bekomme.
Eigentlich habe ich versucht genau nach diesen Schema zu programmieren,
Bits auffüllen, dementsprechend Platz machen, wenn eine bestimmte Menge
gefüllt wurde, abladen, wieder umfüllen + auffüllen, wieder Platz machen
für die Bits, usw.
Eigentlich geht es mir in diesen Thread wirklich nur darum, wie man so
etwas in VHDL am besten umsetzen sollte. Ich hab sachen wie shifter
probiert (shift_left), doch leider mit Timing Fehlern. Oder auch ganz
einfache Schieberegister, allerdings mit einer Breite von 128 Bits,
welches wieder in der Synthese einfach zu lange Zeit braucht. Im groben
noch nichts brauchbares.
Mit welcher Technik, mit welchen Verfahren sollte man denn am besten
Bitstroms erzeugen. Ich bin langsam am verzweifeln.
Zu Not muss ich alle Daten zwischenspeichern, gemühsam alles durchführen
und den Bitstrom erzeugen. Mein Problem dabei ist aber, dass ich
zyklisch Daten bekomme (Bilddaten von einer Kamera alle 1,6 ms) und ich
dabei nicht alle Zeit der Welt habe.
Cihan
Cihan Kalayci schrieb:> René D. schrieb:>> Muss Bit_size nicht eine Konstante sein?>> Bit_Size wird in jedem Takt aktualisiert, er gibt ja an wie viele Bits> gerade in der Ziwschenvariable Data_Stream gültig sind.
i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO (BIT_SIZE - 64));
ist dein Code überhaupft fitbar?
Ich bin mir sehr sicher, dass BIT_SIZE eine Konstante sein muss. Da
dieser Ausdruck nicht durcn den Fitter geht.
DATA_STREAM((BIT_SIZE - 1)
Sowas hatte ich auch bereis aus probiert und das ging nicht.
Welchen Fitter benutzt du?
Das ist mal eine Frage an den Lothar, wie hier der Stand der VHDL ist?
Ist interessant, man kann auch was dazu lernen.
Ich habe mich mit decodieren mal beschäfftigt.
An der Stelle hatte ich es wie folgt gelöst.
Das Schiebe register war doppelt so breit wie der Fifo.
Fifo
------<--------
deocoder
Ein Pointer hat auf das forderste gültige bit gezeigt.
Und wenn das gülte bit die Fifo Breite überschritten hat wurden die
Daten aus dem Schieberegister entnommen. Die Position der Entnahme gibt
der Pointer an.
René D. schrieb:> Sowas hatte ich auch bereis aus probiert und das ging nicht.> Welchen Fitter benutzt du?
Was meinst du denn mit Fitter?
René D. schrieb:> Ich habe mich mit decodieren mal beschäfftigt.>> An der Stelle hatte ich es wie folgt gelöst.> Das Schiebe register war doppelt so breit wie der Fifo.>>>> Fifo> ------<--------> deocoder>> Ein Pointer hat auf das forderste gültige bit gezeigt.> Und wenn das gülte bit die Fifo Breite überschritten hat wurden die> Daten aus dem Schieberegister entnommen. Die Position der Entnahme gibt> der Pointer an.
Eigentlich habe ich es genauso gemacht wie du es geschrieben hast. Was
hast du den mit den übrigen Bits gemacht? und wie hast du die Bits
nacheinander in den doppelt so breiten register geschrieben?
Ich versuch mal noch einmal ein Beispiel darzustellen, wie es bei mir
aktuell aussieht.
Cihan
doch leider mit Timing Fehlern. Oder auch ganz
einfache Schieberegister, allerdings mit einer Breite von 128 Bits,
welches wieder in der Synthese einfach zu lange Zeit braucht.
Es ist ja in Grunde auch kein reines Schieberegister mehr es wirdnach
links weggespeichert und das Schieberegister kann zwischen 0 und 64 bit
weit hüpfen.
Da kommen eine Menge Leitungen zusammen. vor jedem Reigster muss ein
64bit breiter Multiplexer realisiert werden.
Was für eine Kamera hast du, die 64bit erzeugt?
Typisch sind 12bit Farbtiefe pro Pixel.
12bit und 64bit das sind Entfernungen dazwischen
Huffman hat ein Problem man, kann icht vorhersagen wie weit die
Schiebung sein wird, sonst könnte man parallelisieren.
So hier das Beispiel:
FiFo Input DIN ist 64 Bit groß.
Data Stream Schiebe Register (meine Zwischenvariable) ist 128 Bit groß
Nun kommen Daten an:
Bsp.: 33 Bits
Die 33 Bits werden in Data_Stream geschrieben
die nächsten Daten kommen: 44 Bits
Nun werden die ersten 33 Bits um 44 Stellen verschoben mit shift left,
um für die nächsten 44 Bits Platz zu machen. Anschließend werden die 44
Bits in Data Stream geschrieben. Nun habe ich 77 Bits in Data_Stream.
Richtig! jetzt muss ich die oberen 64 Bits in den Fifo schieben:
D.H. bit 76(77-1) bis 13(77-64) müssen in den Fifo rein, darum folgende
Zeile:
i_USER_FIFO_DIN <= DATA_STREAM((BIT_SIZE - 1) DOWNTO (BIT_SIZE - 64));
Und mein Bit_Size ist ebend in diesem Fall Bit_Size, welches in jedem
Takt verändert wird.
Bin aber noch noch fertig, nachdem die oberen 64 bits nun im Fifo sind
müssen die letzen 13 Bits wieder geshiftet werden, da neue daten kommen
und platz gemacht werden muss. z.B. kommen jetzt 24 neue Bits.
Also müssen die unteren 13 Bits um 24 Stellen nach links verschoben
werden und die 24 neuen Bits kommen in Data_Stream rein.
Nun habe ich als Bit_size - WErt 37 Bits.
so geht es nun weiter bis ebend keine Daten mehr kommen.
Das was Rene D. mit pointer meinte ist bei mir Bit_Size.
Mein eigentliches Problem liegt aber darin, dass meine shift-Operationen
Timing Fehler verursachen. Deswegen die Frage an dich Rene D., wie hast
du den die Bits geshiftet umsortiert sortiert usw.?
Cihan
René D. schrieb:> Was für eine Kamera hast du, die 64bit erzeugt?> Typisch sind 12bit Farbtiefe pro Pixel.> 12bit und 64bit das sind Entfernungen dazwischen
Ich habe eine Line Cam, die mir 12 Bit x 8192 Zeilen in 4 Sprekten
liefert. Allerdings geht in die FFT nur 1 Sprektrum mit 12Bit x 8192
Zeilen rein. Der Output der FFT wird nun skaliert und mit der
Huffman-Tabelle verglichen. Die 64 Bit werden dann hier
zusammengestückelt, es sind also keine Kameradaten, die 64 Bit meine
ich.
René D. schrieb:> Huffman hat ein Problem man, kann icht vorhersagen wie weit die> Schiebung sein wird, sonst könnte man parallelisieren
genau das ist ja mein Problem :-(
muss doch aber irgendwie elegant zu lösen sein.?!?
Cihan
Cihan Kalayci schrieb:> Und mein Bit_Size ist ebend in diesem Fall Bit_Size, welches in jedem> Takt verändert wird.
Der Satz musste lauten:
Und mein Bit_Size ist ebend in diesem Fall 77, welches in jedem
Takt verändert wird.
sorry
Cihan
Hi Cihan,
du musst u.U. einen 'Barrel shifter' von Hand implementieren, und zwar
je einen mit "left shift" und einen "right shift", die gleichzeitig
arbeiten.
Damit sollte zumindest der Syntheseschluckauf weggehen...
Die Probleme mit den Timings kamen bei mir auch, als ich als erstes mal
ganz 'naiv' die Geschichte mit 1 clock-Delay implementiert hatte. Mit
entsprechendem Pipelining solltest Du die 100 MHz hinkriegen (könnte
allenfalls auf einem Spartan3 etwas knifflig werden).
Grüsse,
- Strubi
> Timing Fehler verursachen. Deswegen die Frage an dich Rene D., wie hast> du den die Bits geshiftet umsortiert sortiert usw.?>> Cihan
Gute Frage
Ich habe gerade nachgeschaut.
Ich habe kein Schieberegister sonderen ein Ringspeicher. So werden die
einzelnen Bits nicht verschoben sondern dem Schreiben ein Offset
gegeben.
Der Code stamte von einem Decoder. Der Fifo schreibt in den
Ringspeicher.
Meiner Meinung nach sollte es keine Unterschiede geben. Bei dem ersten
Ausschnitt stimmt das Ergebnis, aber bekomme Timing-Fehler und die
Synthese dauert ziemlich lange.
Bei dem zweiten Ausschitt ist das Ergebnis zwar falsch, aber wenigstens
keine Timing-Fehler und die Synthese läuft normal durch.
Die Bits von Data_Stream habe ich mir in Chipscope angeguckt, woraufhin
ich die Unterschiede sah.
Cihan
René D. schrieb:> case write_rot_pointer is> when "00"=> rot_buffer(7 downto 0)<= input_reg(15 downto 8);> when "01"=> rot_buffer(15 downto 8) <=input_reg (15 downto 8);> when "10"=> rot_buffer(23 downto 16) <=input_reg(15 downto 8);> when "11"=> rot_buffer(31 downto 24) <=input_reg(15 downto 8);> when others=> null;> end case;
So weit ich sehe, hast du immer 8 Bit weise geschrieben?!?
Und anschließnd je nach pointer Position entsprechen die Bits
weitergegeben.
Richtig?
Cihan Kalayci schrieb:> Ausschnitt 1:DATA_STREAM((VALID_BIT_SIZE_im - 1) DOWNTO 0) <=> VALID_DATA_im((VALID_BIT_SIZE_im - 1) DOWNTO 0);> DATA_STREAM((SZ_BIT_SIZE + VALID_BIT_SIZE_im - 1) DOWNTO VALID_BIT_SIZE_im) <=> SZ_re(16 DOWNTO 0);> DATA_STREAM((VALID_BIT_SIZE_re + SZ_BIT_SIZE + VALID_BIT_SIZE_im - 1) DOWNTO
(SZ_BIT_SIZE + VALID_BIT_SIZE_im)) <=
> VALID_DATA_re((VALID_BIT_SIZE_re - 1) DOWNTO 0);>> Ausschnitt 2:DATA_STREAM((VALID_BIT_SIZE_re + SZ_BIT_SIZE + VALID_BIT_SIZE_im -
1) DOWNTO 0) <=
> VALID_DATA_re((VALID_BIT_SIZE_re - 1) DOWNTO 0) &> SZ_re(16 DOWNTO 0) &> VALID_DATA_im((VALID_BIT_SIZE_im - 1) DOWNTO 0);
Ich habe nochmal über Nacht überlegt, was der Unerschied sein kann.
Mit einem Beispiel lässt sich das wahrscheinlich besser erklären.
Nehmen wir an das "VALID_BIT_SIZE_re" und "VALID_BIT_SIZE_im" für beide
Codeausschnitte die selben Werte haben, dann sollten die Ergebnisse auch
gleich sein. Das Problem beim ersten Ausschnitt ist wahrscheinlich, dass
ISE in der Synthese für die Variablen alle Möglichkeiten berücksichtigen
muss. Im zweiten Ausschnitt gehen die Variablen ja gegen 0 ("...downto
0"). Hier geht er ja von der rechten Seite aus gesehen bei Data_Stream
von einem festen Wert aus (0). Im Ausschnitt 1 variieren die Index Nr.
von Data_Stream.
Was ich aber nicht verstehe, warum ich unter dem Code von Ausschnitt 2
falsche Ergebnisse habe. Als Bsp. mal kurz:
Nehmen wir an dass
VALID_DATA_re(15 DOWNTO 0) <= X"154B" und VALID_BIT_SIZE_re <= 14 bzw.
VALID_DATA_im(15 DOWNTO 0) <= X"0003" und VALID_BIT_SIZE_im <= 2 bzw.
SZ_re(16 DOWNTO 0) <= X"0480A" und SZ_BIT_SIZE <= 17 (einzige Konstante)
ist.
Dann sollte das Ergebnis ja folgendes für Data Stream sein:
1
Data_Stream((14+17+2-1)DOWTNO0))<="01010101001011"&"00100100000001010"&"11";-- in Binär
2
Data_Stream<=X"0AA59202B";-- in Hex
Doch ich bekomme folgendes zusammengestückelt:
1
Data_Stream((14+17+2-1)DOWTNO0))<="000010101010010110000000000000011";-- in Binär
2
Data_Stream<=X"0154b0003";-- in Hex
das kann ich mir überhaupt garnicht erklären, wie er auf dieses Ergebnis
kommt. Ich hab mir alle Signale in Chipscope angeguckt und auch diese,
die ich ebend benannt habe, doch das Ergebnis ist ebend falsch.
habe ich einen Fehler drin, den ich nicht sehe?
Cihan
SuperWilly schrieb:> Kannst du den in Echtzeit beobachteten Fehler simulieren?
Der Fehler tritt in der Simulation nicht auf.
Simulation ist genauso wie ich es auch eigentlich erwarte.
Dort wird der Vektor auch richtig zusammengestückelt.
Der Fehler taucht nur in der Hardware auf (in Chipsope).
Cihan
Hast Du in Echtzeit Fifo-Überläufe oder Unterläufe? Dock mal die
entsprechenden Fifo-Flags an Chipscope ...
Hast du verschiedene Taktdomänen, deren Übergänge du nicht richtig
behandelst?
Taktdomäne habe ich nicht, alles läuft unter 100MHz.
Der Teil mit dem Fehler den ich meine, hat mit dem Fifo noch nichts zu
tun. Es wird einfach nur aus einem Bram Daten eingelesen (auch unter
100MHz) und anschließend je nach Inhalt wird ein 128 Bit Register
beschrieben. Und das beschreiben hier ist schon Fehlerhaft.
Die Fifo Flags sind auch in Chipscope drin, werden aber wie gesagt zu
dem Zeitpunkt wo der Fehler auftritt noch nicht verwendet.
Cihan
SuperWilly schrieb:> Du simulierst exakt die gleichen BRAM-Schreib- und Lesezugriffe?
Ja. Ich simiuliere in ISIM.
Alle Flags die in der Programmierung gesetzt werden, alle Register die
beschrieben werden sind von Timing her genau gleich. Nur der Inhalt der
Register (Data_Stream 128 Bit Zwischenspeicher) ist unterschiedlich.
Ich mache mal gleich Screenshots und versuche mal darzustellen was ich
meine.
Cihan
Ich habe in meinem Projekt einen großen ROM für die FFT initialisiert,
8192x12 Bit und zwei weitere RAMS (BRAM) für die Huffman-Tabelle,
jeweils 1024x32Bit. Allein diese ROM und RAMS haben eine Zeilenanzahl
von ca. 1000 Zeilen, da ich sie ja initialisiert habe. Kann sowas ISE /
XST durcheinander bringen? Manchmal trifft er die Zeilennummer nicht,
wenn er mich auf meine Fehler hinweist. Würde ihn so etwas stören?
Meiner Meinung nach sollte das ja kein Problem darstellen.
Cihan
Cihan Kalayci schrieb:> Manchmal trifft er die Zeilennummer nicht,> wenn er mich auf meine Fehler hinweist. Würde ihn so etwas stören?
Tritt der hier beschriebene Fehler dann auf, wenn die Zeilennummer
geteilt wird und zum Teil auf der nächsten Zeile steht?
Wenn ja, dann ist das wahrscheinlich nicht die Ursache Deines
eigentlichen Problems.
Duke
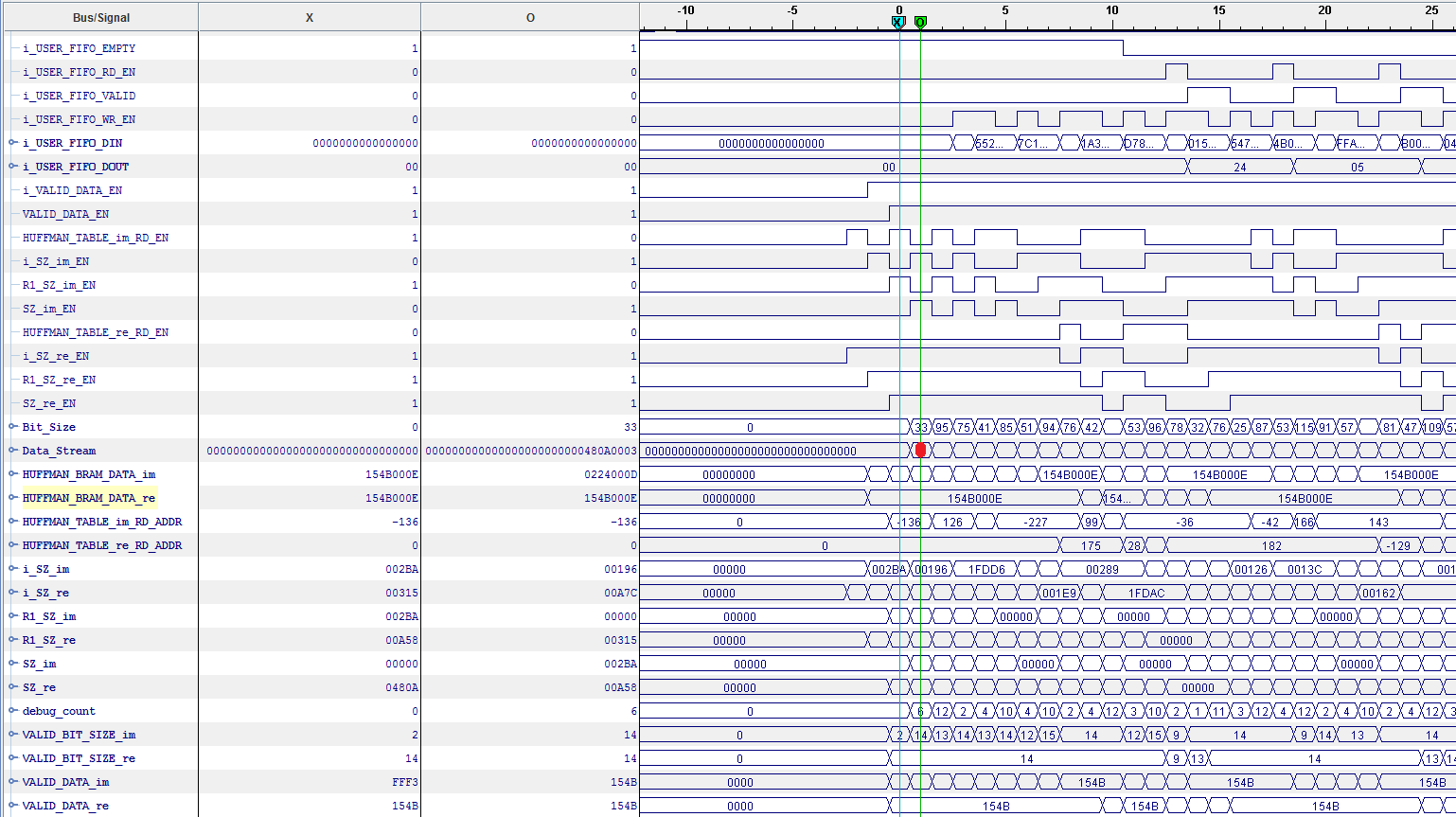
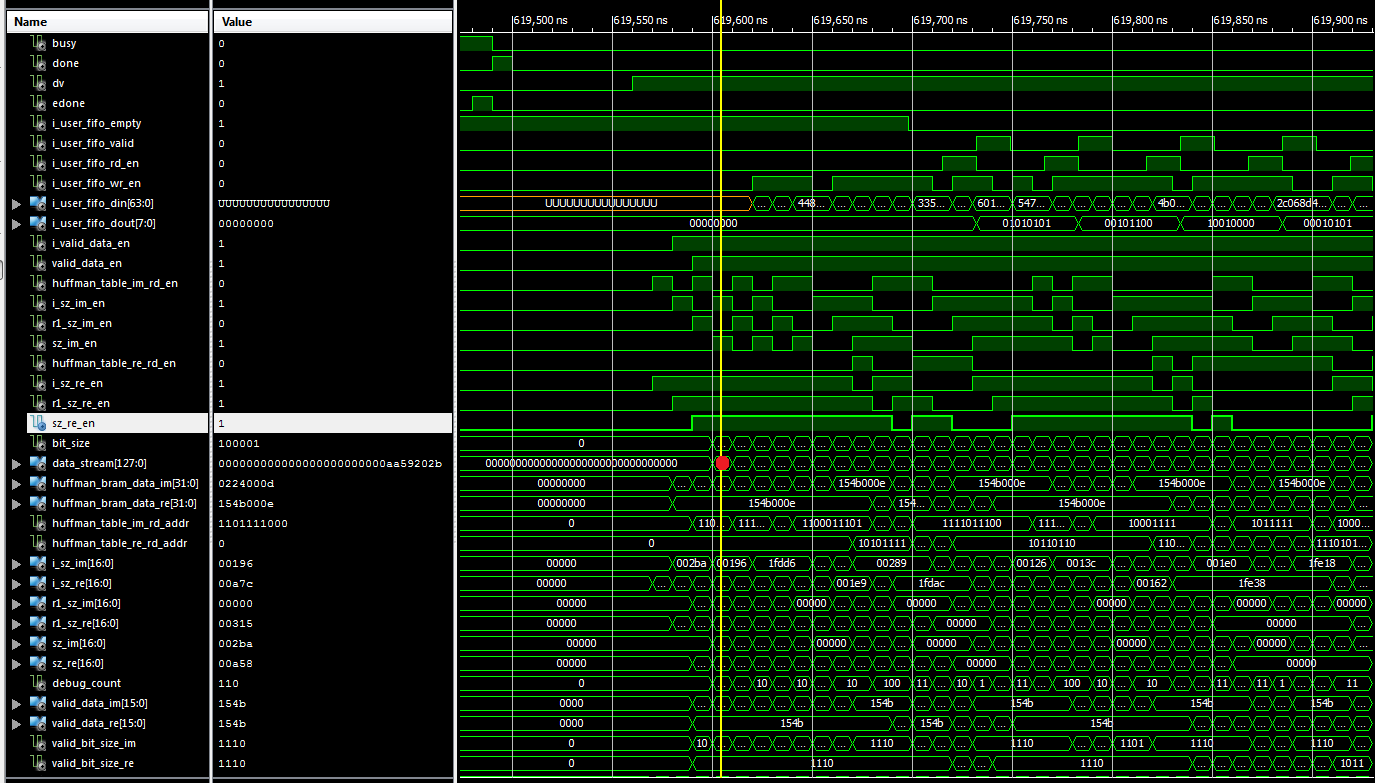
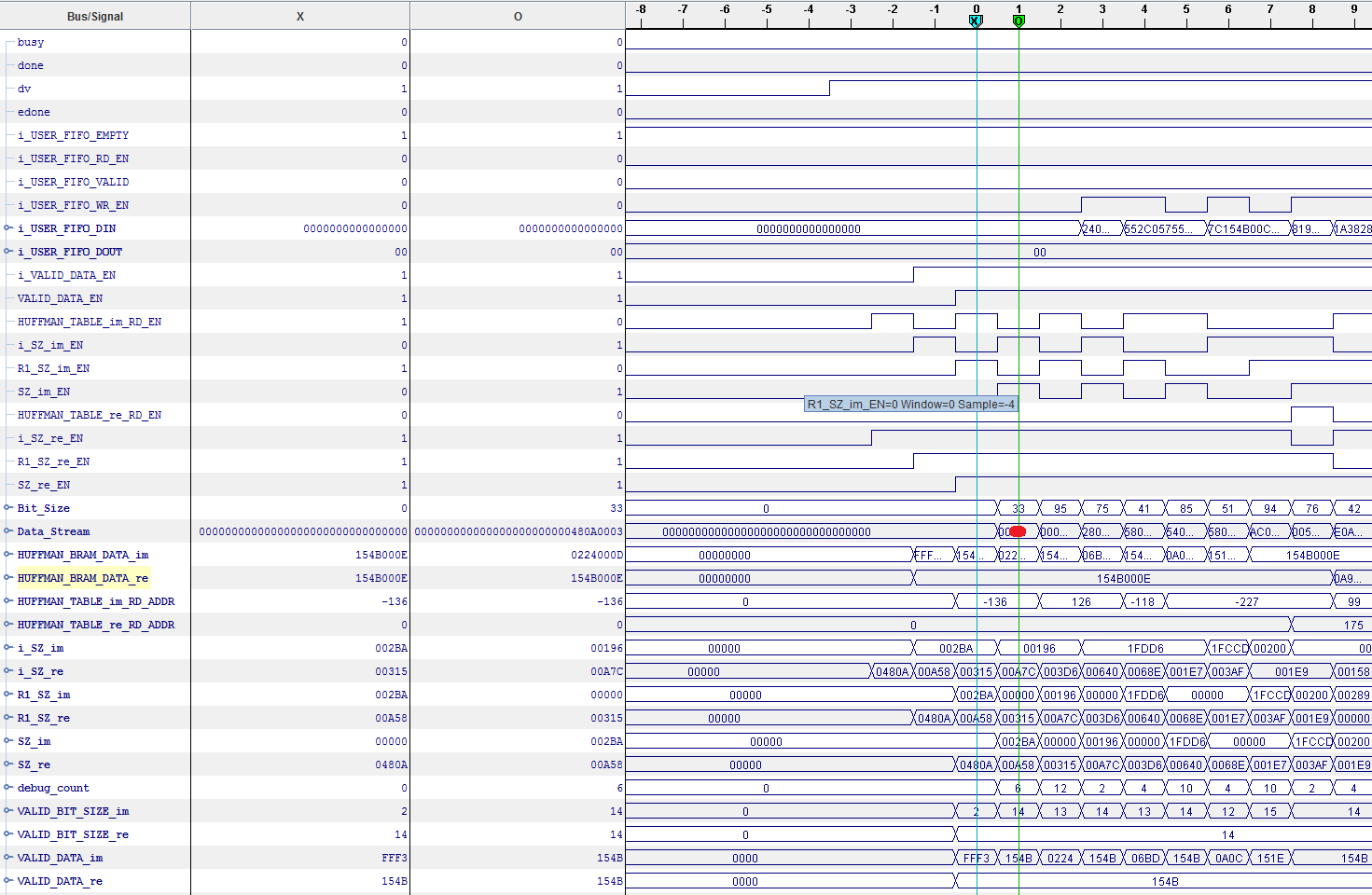
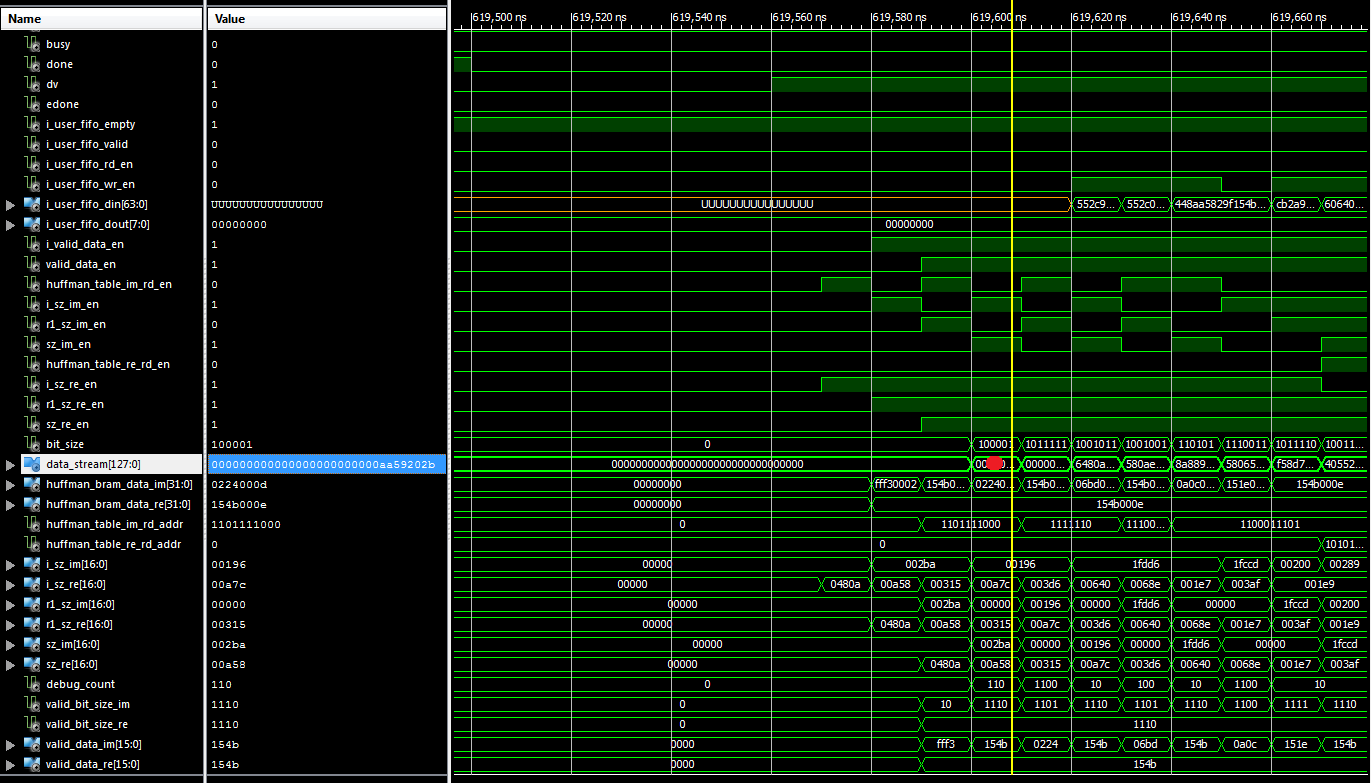
Hier die Screenshots die ich versprochen habe.
Habe einen weiten und nahen Screenshot von der Simulation in ISIM und
der Hardwareimplimentierung mit Chipscope gemacht.
Habe auf allen Bilder einen roten Punkt gemacht. Der deutet auf den
Fehler hin den ich meine. In dem Punkt wird der Inhalt anders. In den
nahen Bildern kann man sehen, dass alle anderen Register vor dem
beschreiben von Data_Stream sowohl unter ISIM als auch unter Chipscope
die gleichen Inhalte in den Registern haben.
Cihan
Nimm doch einfach mal eine einfache BRAM-Ansteuerung mit entsprechenden
Schreib- und Lesezugriffen und mach dir deutlich, ob Chipscope das
anzeigt, was du in der Simulation siehst. Nicht dass du falsche Annahmen
bezüglich des BRAM-Timings hast ....
Ich speichere die Daten Stück für Stück in einem FIFO, der wiederum
durch eine RS422 Routine ausgelesen wird und mir die gleichen Daten in
Hterm ausgibt wie in CS. D.h. wenn ich in CS Fehlerhafte Daten habe,
tauchen diese auch in Hterm auf.
Cihan
Nach längerer Zeit möchte ich mich mal mit meinem Ergebnis melden.
Am Anfang hatte ich ja versucht eine (sehr sehr große) Kombinatorik zu
beschreiben, die auf einer 128 Bit Variable basiert. Leider hatte ich da
viele Probleme in Hinsicht der Resourcenverwendung und des
Timingverhaltens.
Habe im Anschluss das Design auf eine 64 Bit Variante umgebaut, was viel
weniger Resourcen gebraucht hat und vor allem hatte ich keine
Timingprobleme. Der Bitstrom wird nun über die Huffman-Tabelle korrekt
erzeugt. Ich muss auch noch dazu sagen, dass ich viele IF ELSE Abfragen
optimiert habe (anders beschrieben) sodass ich dadurch auch bisschen
Resourcen sparen konnte. Letztendlich habe ich nun ein Design, dass
30-40% des FPGA (VIRTEX 5) füllt.
Wollte den Thread nicht in der Luft hängen lassen.
Danke nochmals an alle Beteiligten für ihre hilfreichen Beiträge.
lg Cihan
Ja die Kompression ist gelungen. Komme auf Kompressionsfaktoren bis ca.
1,5 - 3. Die Kompressionsrate hängt natürlich von meinem Scale_Factor
und der Huffman-Tabelle ab.
Cihan