Hallo Leute,
mein Verständnis von VHDL-Prozessen wird gerade hart in Frage gestellt.
Folgende Situation:
Ich habe einen Quad-Port-Speicher mit 2 Schreib- und 2 Leseports.
Nun habe ich 4 Eingangsports für Daten, die aber nicht immer Daten
liefern, es gibt eine Maske in der verzeichnet ist, welche der 4 Ports
gerade Daten schreiben wollen und auch wohin. 2 Ports sind "Master",
also wenn sie schreiben wollen, dann dürfen sie auch, die anderen 2 sind
Slave und werden reingequetscht, wenn der Master nur einen Port
blockiert oder gar keinen.
Im Prinzip ein 4 auf 2 Mux mit 2 priorisierten Kanälen, wobei die
Reihenfolge keine Rolle spielt.
Also Beispiel:
Maske: (master1 master2 slave1 slave2): "1010"
führt zu: master1 schreibt auf port1; slave 1 schreibt auf den freien
port2 + zustand "slave2 muss noch geschrieben werden".
Nun war der Prozess-code so ähnlich wie folgender:
1
process
2
-- eine menge variablen zum bookkeping der schreib-zuordnungen
Ich weiß eigentlich gar nicht so genau wie das überhaupt funktionieren
konnte, dass man "im gleichen Takt" das Ergebnis aus einer Berechnung
mit Operanden aus einer Lese-Operation vom Register direkt wieder
reinschreiben kann (beziehungsweise wie VHDL das semantisch sieht, was
ich da geschrieben habe), auf jeden Fall war das Ergebnis zur nächsten
Taktflanke im Register und kann direkt weiterverwendet werden (ich denke
mal, dass der Speicher irgendwie den Schreib-Port zum Leseport
durchschleift, falls man im gleichen Takt auf dieselbe Addresse schreibt
und von ihr liest, und das ergebnis eigentlich erst zur nächsten
Taktflanke geschrieben wird, obwohl die Schreib-werte schon zwischen den
Taktflanken bereitstehen).
Auf jeden Fall jetzt das Problem: Die Logik für die Zuordnung von
Berechnungsresultaten, Konstanten und Slave-Werten auf die Schreibports
war dermaßen kompliziert, dass ich keine "geschlossene" Funktion angeben
konnte, sondern Variablen mehrfach überschreiben musste etc. Also diese
Logik hat den kompletten Prozess-Code einfach nur unleserlich gemacht.
Nun habe ich mir einen Kombinatorischen Block gemacht, der diese
Zuordnung übernehmen soll:
In dem Block ist eine Weiche zum Umleiten der Slave Ports und dahinter 2
2x1 Muxe, die jeweil Slave oder Master-Port auswählen. Dazu noch ein
Zustandsprozess, um Slave-Operationen auf mehrere Takte verteilen zu
können und eine große Funktion, die anhand der Eingangswerte und dem
aktuellen Zustand berechnet, wie die Weiche und die Muxe geschaltet
werden müssen (ich könnte auch einmal ein Blockschaltbild davon malen,
wenn das hilft).
Okay, so weit so gut. Das Problem ist, dass ich jetzt gerne hätte, dass
dieser kombinatorische Mux-Kontroll-Block genauso benutzt wird, wie es
der Prozess "damals" intern auch gemacht hat.
Wenn ich jetzt folgendes schreibe (zusammengestaucht um auf den Punkt zu
kommen):
1
signalmaster1...;
2
signalmaster2...;
3
signalslave1...;
4
signalslave2...;
5
signalwrite1...;
6
signalwrite2...;
7
8
begin
9
mux_ctrl:entitywork.write_controller_4x2
10
portmap(
11
master1=>master1,
12
master2=>master2,
13
slave1=>slave1,
14
slave2=>slave2,
15
out1=>write1,
16
out2=>write2
17
);
18
19
processbegin
20
waituntilrising_edge(clock);
21
22
master1<=registers(4);-- schreibt in einen puffer-register :(
23
master2<=registers(6);-- das auch :(
24
25
registers(2)<=out1;
26
registers(3)<=out2;
27
endprocess;
... dann werden jetzt für master1 und master2 Register eingefügt und das
Ergebnis ist somit erst 2 Takte später in den Registern.
Ich hätte nun aber gerne, dass der Parser irgendwie erkennt, dass
master1 und out1 kombinatorisch miteinander verbunden sein sollen und
keine Register eingefügt werden, genauso wie es war, als die Logik, die
ich in write_controller_4x2 ausgelagert habe, noch in dem
Prozess-Quelltext stand (und dort ja auch kombinatorisch umgesetzt
werden musste, um semantisch das richtige zu berwerkstelligen, zwischen
zwei Taktflanken).
Das einzige das mir jetzt noch einfiele, wäre es, diese Kontrollogik
nicht als kombinatorischen Block umzusetzen, sondern als Funktion, die
ich ja direkt im Kontext des Prozesses aufrufen kann, sodass der
VHDL-Parser weiß, was ich zu erreichen versuche.
Es würde mich freuen, wenn mir jemand von euch aufklären könnte, ob man
kombinatorische Entities irgendwie "in den Kontext eines Prozesses"
ziehen kann oder ob Funktionen die einzige Lösung sind (oder ob
Funktionen auch keine Lösung sind und ich überhaupt mal gar keine Ahnung
habe, nach Hause gehen sollte um an Sudokus zu trainieren O.O)!
Puh, viel Text - tut mir Leid :( Wenn ich zur Illustrationen
Blockschaltbilder bereitstellen soll, weil meine Erklärungen dürftig
sind, bitte Bescheid geben!
Viele Grüße,
Deci
Michael S. schrieb:> Das einzige das mir jetzt noch einfiele, wäre es, diese Kontrollogik> nicht als kombinatorischen Block umzusetzen, sondern als Funktion, die> ich ja direkt im Kontext des Prozesses aufrufen kann, sodass der> VHDL-Parser weiß, was ich zu erreichen versuche.
Vorneweg: ich kapiere nicht so ohne weiteres, was dein Problem ist, aber
ich habe den Eindruck, dass du da irgendwas "programmieren" willst, so
wie du einen uC "programmieren" würdest.
Tritt mal einen Schritt zurück und überleg dir, wie du das mit
Hardwarekomponenten (RAM, MUX, Kombinatorik) aufbauen würdest. Und das
beschreibst du dann. Dafür ist VHDL da...
> Wenn ich zur Illustrationen Blockschaltbilder bereitstellen soll
Es wird dir und uns helfen, einen Überblick über das zu bekommen, was du
da machen willst.
> oder ob Funktionen die einzige Lösung sind
Funktionen sind toll für die Simulation. Aber bei der Synthese sollte
sich die Komplexität der Funktion in engen Grenzen halten (so in etwa
auf dem Niveau rising_edge() oder to_integer()), denn der Synthesizer
wird dir gnadenlos Hardware aus jeder einzelnen "aufgerufenen" Funktion
basteln.
Ich rate immer zu Folgendem:
Konzept
Blockdiagramm
Zeitablauf
dann, frühestens dann die Schaltung machen.
Das gilt auch fürs Darstellen,
So kann sich keiner ein Bild machen was Du überhaupt möchtest.
Hallo!
Jau, also ich hab schon Zeichnungen gemacht, aber die waren in keiner
Form, dass man sie hier hätte zeigen können.
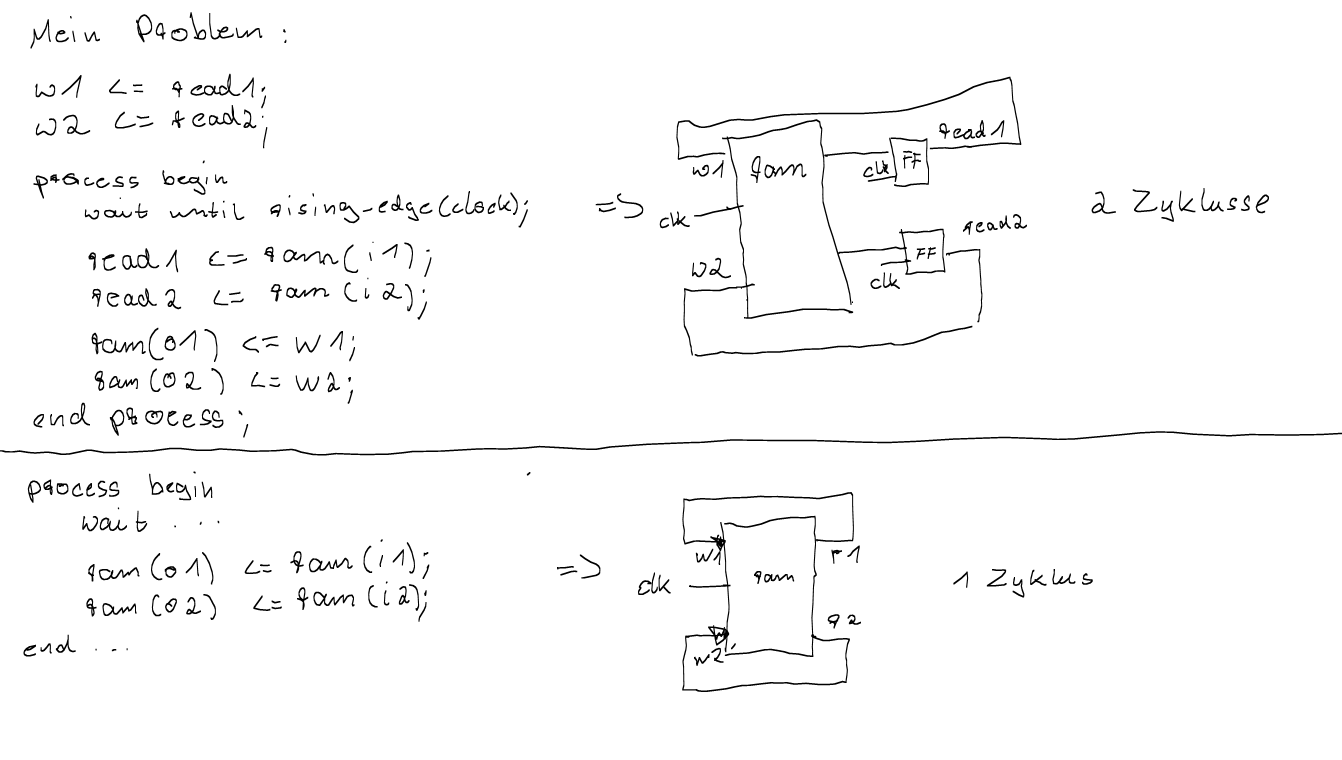
bild1 zeigt den Aufbau, den ich erreichen möchte.
bild2 zeigt das grundlegende Problem, das ich hier habe. Wie man im
unteren Teil sehen kann, lässt sich mit einem monolithischen Prozess der
getaktete Speicher inklusive berechneter Rückführung realisieren, alles
in einem Takt (statt direkt die Signale zuzuweisen, könnte man auch über
variablen mit ihnen rumrechnen (=> Kombinatorik auf dem Signalpfad)).
Wenn man nun aber den monolithischen Prozess auseinanderdröseln möchte
(aber trotzdem noch Prozess, um den synchronen RAM zu beschreiben), dann
fügt er einem vor dem "äußeren" "ausgelagerten" "modularisierten"
kombinatorischen Schluss ein Flipflop (was normalerweise ja auch
gewünscht ist). Aber ich möchte vor der Kombinatorik (zwischen read1 und
w1 in der Zeichnung) keinen Flipflop. Der Synthetisierer soll sich
denken, dass alles was zwischen read1 und w1 kommt eigentlich eine
kombinatorische Berechnung ist, die man auch gleich in den Prozess hätte
schreiben können.
Ich habe von dem monolithischen Prozess wie im unteren Teil zu dem
modularisierten Modell wie im oberen Teil umgebaut, habe jetzt aber
"Latenz" von 2 Takten, eben wegen des Flipflops, das mit "Ausgängen" von
synchronen Prozessen einhergeht. Ich könnte damit leben, weil jetzt der
ganze Quelltext wesentlich besser zu lesen ist, aber ich weiß ja, dass
der monolithische Prozess das in einem Takt schafft, warum sollte es
also nicht auch gehen, wenn man den Projektaufbau etwas angenehmer
gestaltet.
PS: Entschuldigt bitte die Zeichnungsqualiät, das ist das beste, was ich
aus dem Grafiktablett rausholen konnte :D
Wen du in einem (oder durch einen) Prozess keine Flipflops erzeugen
willst, dann darfst du ihn nicht takten. Oder andersrum: jede
Signalzuweisung in einem getakteten Prozess ergibt Flipflops...
Danke Lothar!
Also ich habe jetzt mal das Schreiben im getakteten Prozess und das
lesen kombinatorisch außerhalb des Prozessen umgesetzt (so etwas hatte
ich nicht gewagt zu versuchen, obwohl Xilinx ja so den Distributed Ram
beschreibt, den ich hier ja offenbar benötige). Und im Simulator
funktioniert's!
Jetzt frage ich mich aber: wird das auch synthetisiert funktionieren?
Ich beschreibe hier ja quad-port distributed ram mit 2x write und 2x
read. In den Xilinx-Unterlagen kann ich so eine Konfiguration gar nicht
finden, trotzdem sagt mir Xst, es hätte quad-port distributed ram
synthetisiert.
Und eine weitere Frage: Xst hat auch einen Maximaltakt bestimmen können
der genau dem entspricht, was ich mit dem monolithischen Prozess hatte
und mir ist nicht direkt klar, wie? Ich habe ja jetzt einen äußeren
kombinatorischen Kreisschluss definiert, ohne da bestimmte Zeiten
vorzugeben.
Muss Xst die Sache so behandeln, dass synchrone Prozesse immer einen
stabilen Eingang zu Taktflanken haben, sodass sich aus diesem Umstand
ergibt, dass Lesen+Berechnen innerhalb eines Zyklusses vonstatten gehen
muss, weil das Ergebnis Eingang eines getakteten Prozesses ist?
Viele Grüße,
Deci
Okay, weiter unten beim Routing kommen folgende Warnmeldungen:
----------------------
WARNING:Par:288 - The signal reg/Mram_registers2_RAMB_DPO has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers2_RAMD_O has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers1_RAMB_DPO has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers1_RAMD_O has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers14_RAMB_DPO has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers14_RAMD_O has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers11_RAMB_DPO has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers11_RAMD_O has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers13_RAMB_DPO has no load.
PAR will not attempt to route this signal.
WARNING:Par:288 - The signal reg/Mram_registers13_RAMD_O has no load.
PAR will not attempt to route this signal.
----------------------
Da hier A und C als Indizes fehlen, interpretiere ich das jetzt so, dass
er für meine 2 read 2 write Register einen Speicher aus zwei "2 read 1
write" zusammenbaut (also insgesamt "4 read 2 write", wobei ich nur 2
reads angeschlossen habe (die er auf A und C legt) und somit 2 read
ports brachliegen (B und D)?
Oder ist das ein Anzeichen dafür, dass das, was ich wollte, einfach
nicht richtig synthetisiert wurde?
Wenn die brachliegen, könnte ich auf der rechten Seite ja ohne große
weitere kosten (außer halt all den Leitungen) einfach direkt 4 Kanäle
rausführen, hrmmmm. Aber ist dann halt sehr speziell auf die Architektur
ausgelegt.
Grundsätzlich gilt, wie Lothar ja auch schon sagte, dass alles, was in
einem getakteten Prozess zugewiesen wird, zu einem Register führt.
Alles, was in einem Prozess außerhalb der Abfrage der Taktflanke steht,
wird rein Kombinatorisch umgesetzt. Genauso, wie wenn du es ganz
außerhalb eines Prozesses beschreiben würdest.
Ob du innerhalb eines Prozesses Q<=A and B schreibst, oder außerhalb,
ist egal.
Es wird eine kombinatorische Und-Verknüpfung daraus.
Schreibst du das aber innerhalb einer Abfrage auf die Taktflanke (was
nur innerhalb eines Prozesses möglich ist), dann wird ein Register
daraus, an dessen Eingang ein UND vorgeschaltet ist.
Ich glaube, nun sollte mir ein Großteil klar sein, bezüglich der
Prozesse. Ich hatte komplett vergessen, dass man Prozesse auch rein
kombinatorisch verwenden kann.
Wobei ich bei nicht-getakteten Prozessen auf die Sensitivity-Liste
aufpassen muss, leider. Dabei finde ich die Syntax in Prozess-Blöcken
sehr viel schöner als die außerhalb, aber immer auch die
Sensitivity-Liste mit-aktualisieren für den kombinatorischen Prozess
wird auf Dauer wohl nerven. Mir stellt sich sowieso die Frage, warum man
da in VHDL Syntax-mäßig zweigleisig fährt.
Schade auch, dass ich keine Chipscope-Lizenz besitze, im Moment kann ich
das Design (vor allem im Bezug auf die fragliche Speicherumsetzung)
nicht im FPGA austesten, weil es einfach noch keine vernünftige Ausgabe
ermöglicht. Also weiterbasteln und simulieren und hoffen :D
Sei's drum, vielen Dank für eure Erklärungen!
Viele Grüße,
Deci
PS: Schlumpf: die im anderen Thread noch offene Frage, wegen der
kombinatorischen Busy-Rückführung werde ich leider nicht mehr austesten
können, weil sich währenddessen an dieser Baustelle hier so viel getan
hat, dass da nix vergleichbares mehr ist, zumal ich bislang zu bequem
war, ein repo für das Projekt einzurichten -.- Möchte deshalb nicht den
Thread pushen, drum hier die Erwähnung.
Hallo Michael,
das mit der Sensitivity-List ist halt leider so in VHDL, auch wenn´s
nervt.
Der XEmacs Editor kann die aber automatisch vervollständigen. Ein
mächtiger Editor, aber die Bedienung ist eher Geschmackssache.
Was die Synthese aus deinem Code macht, kannst du auch im RTL-View
anschauen. Dort bekommst du die Info, wie dein Code in Logik umgesetzt
wird. Der Technology-View zeigt dir dann, wie diese Logik auf den FPGA
abgebildet wird. Nach der Synthese kannst du dir auch noch die komplette
Netzliste des Designs als VHDL-Code erzeugen lassen und wieder in deinen
Simulator schieben. Dann siehst du, ob das, was du beschrieben hast,
auch wirklich so funktioniert (inklusive aller Timinginformationen).
Stichwort hierzu: "Backannotation".
Oder sind diese Funktionen bei Xilinx kostenpflichtig?
Zu dem anderen Thread: Kein Problem :-)
Schlumpf schrieb:> inklusive aller Timinginformationen
Das macht aber nur dann Sinn, wenn auch das Simulationsmodell
Timinginformationen enthält. Normalerweise sinnvoll gesetzte
Timing-Constraints (wenigstens die Taktperiode), denn die muss man
sowieso machen. Man kann sich nicht drauf verlassen, dass jedesmal schon
was Passendes rauskommen wird...
Hallo!
Die 100MHz für das Nexys3-Board sind schon in der Begleit-UCF
eingetragen, sowei ich das beurteilen kann.
Aber ich glaube, sobald ich die Kombinatorik aus einem Prozess ausbaue,
muss ich per Hand sagen, welche kombinatorischen Pfade welche Zeit
brauchen dürfen, oder nicht? Der Synthetisierer kann ja nicht wissen, ob
ich der Kombinatorik vielleicht 2 Takte zum auswerten gönnen möchte,
oder?
Hingegen, wenn ich das alles in einem getakteten Prozess mache, dann
weiß der Synthetisierer ja implizit, was Sache ist?
Bin da noch etwas planlos, aber bin glaube ich auf dem besten Weg, mir
vorstellen zu können, was ich da so in etwa angeben muss. Nur wie gibt
man zeitliche constraints für offene Netzwerke an, das geht ja
wahrscheinlich am einfachsten, wenn man das Netzwerk in eine Komponente
auslagert und irgendwie angibt, dass die Ausgangs-Ports nach einer
maximalen Zeit stabil sein sollen, nachdem man eine beliebige
Kombination der Eingangsports verändert hat. Da wird sich ja bestimmt
einen Pfad berechnen lassen, der irgendwie alle dominiert, den man als
"repräsentativ" für diesen Kombinatorik-Block bezeichnen könnte
(Zusammensetzung aus Gatter-Anzahl und aufsummierter Leitungslänge
irgendwie).
Viele Grüße,
Deci
Michael S. schrieb:> Der Synthetisierer kann ja nicht wissen, ob> ich der Kombinatorik vielleicht 2 Takte zum auswerten gönnen möchte,> oder?
Das Signal erst nach zwei Taktzyklen lesen wäre die offensichtliche
Möglichkeit, das sollte die Synthese auch merken. Alles andere hat
sowieso das Potential, Glitches zu erzeugen, oder?
greg schrieb:> Michael S. schrieb:>> Der Synthetisierer kann ja nicht wissen, ob>> ich der Kombinatorik vielleicht 2 Takte zum auswerten gönnen möchte,>> oder?>> Das Signal erst nach zwei Taktzyklen lesen wäre die offensichtliche> Möglichkeit, das sollte die Synthese auch merken. Alles andere hat> sowieso das Potential, Glitches zu erzeugen, oder?
Hatte auch gehofft, das mein Synthesizer (Symplify Pro) merkt, dass um
den kombinatorischen Block herum ein Enable-Signal Signal mit 2-Takten
verzögerung läuft.
Leider nicht, es sind für die Pfade durch den kombinatorischen Block
zusätzliche Constraints nötige, damit der Syntesizer das korrekte Timing
kennt (eine MultiCylcle Constraint).