Moin,
ich habe hier ein relativ komplex gewachsenes Design (VHDL), was für den
Spartan6 optimiert wurde. Fast alle Module sind plattformunabhängig.
Jetzt will die Chose auf dem Lattice ECP3 nudeln lassen, was auch schon
geht, aber leider nur bei deutlich reduziertem Clock.
Der HDL-Analyst von Synplify Pro sagt mir netterweise auch warum: Das
kritische Timing ("Slack") liegt fast immer an den Pfaden vom BRAM
(FIFO) zur Verarbeitungslogik. Wenn ich den Synthesizer zu "Distributed
RAM" zwinge, schafft er das Timing jeweils, aber frisst mir natürlich
sinnlos LUT-Resourcen weg. Bevor ich hier noch lange suche/pröble: Kann
mir ev. jemand einen architektonisch wertvollen Hinweis geben?
Ansich will ich vermeiden, Cores explizit zu generieren. Auch weitere
Abtaktungen sind bei den BRAM-basierten Ausgabe-FIFOs eher knifflig,
aber vielleicht komme ich ja doch nicht drumrum..
Grüsse,
- Strubi
Verwende Boxen, um die Logik beisammen zu halten. Verwende zusätzliche Register für die Fifo-Lesedaten. Dr. Schnaggels
Um welche Taktfrequenzen geht es? Hast du bei den Timingconstraints den PAR_ADJ Parameter angegeben? Wenn das Projekt mit einer älteren Version als Diamond 2.1 angelegt wurde, die Routingmethode auf NBR umstellen. Brute Force: d.h. mehrere P&R Iterationen, (lassen sich parallelisieren mit Windows auf mehrere Cores, mit Linux sogar auf mehrere Rechner) Schau dir das Eregbnis im Timinganalysator von Diamond an, da kannst du dir den Pfad im Floorplan anzeigen lassen. (Vorsicht: das kann negative Auswirkungen auf den Blutdruck haben)
Lattice User schrieb: > Um welche Taktfrequenzen geht es? Rund 160 MHz. FPGA: LFE3-17EA -7 > > Hast du bei den Timingconstraints den PAR_ADJ Parameter angegeben? > In einer vorherigen Version des Designs ja. Das läuft aber mit sehr relaxtem Timing. > Wenn das Projekt mit einer älteren Version als Diamond 2.1 angelegt > wurde, die Routingmethode auf NBR umstellen. > Ich bin noch bei 2.0. Sollte ich da eher upgraden? (Würde ich gerne vermeiden) > Brute Force: d.h. mehrere P&R Iterationen, (lassen sich parallelisieren > mit Windows auf mehrere Cores, mit Linux sogar auf mehrere Rechner) > Mache ich dann in der nächsten Phase. So weit bin ich noch nicht mit der Optimierung. > Schau dir das Eregbnis im Timinganalysator von Diamond an, da kannst du > dir den Pfad im Floorplan anzeigen lassen. (Vorsicht: das kann negative > Auswirkungen auf den Blutdruck haben) Ansich habe ich erst mal auf Synplify-Ebene angefangen zu optimieren, um generelle 'Schwachpunkte' (ok, it's a feature) gegenüber der Spartan6-Synthese herauszukristallieren. Die zusätzlichen Register sind, wo es geht, schon drin. Leider geht das an einigen FIFO-Schnittstellen wegen zusätzlicher Latenzen nur bedingt gut Das Blutdruckproblem bzgl. Floorplanner kenne ich schon :-) Um das zu umgehen, bräuchte ich wohl eine neue Kiste. Momentan no go.. Ansonsten ist das Timing nicht so extrem kritisch, die wichtigsten Komponenten laufen ansich alle mit massig 'Headroom', nur diese Lattice-seitig offensichtlich eher kritischen Memory-Pfade machen mich noch etwas narrisch. Muss dazu aber sagen, dass ich in die Details der Lattice-Primitiven nicht vorgedrungen bin. Im schlimmsten Fall muss ich wohl noch weitere mini-Distributed-RAM-FIFOs dazwischenhängen, oder halt doch IPX-Cores wrappen. Andere Idee? Grüsse & danke schon mal für die Hinweise, - Strubi
Martin S. schrieb: >> >> Hast du bei den Timingconstraints den PAR_ADJ Parameter angegeben? >> > > In einer vorherigen Version des Designs ja. Das läuft aber mit sehr > relaxtem Timing. Auf jedem Falle hinzufügen, bei 160 MHz, etwa 20-25. Dadurch rechnet er beim Plazieren mit einer höheren Taktfrequenz und packt alles etwas enger zusammen. > > Ich bin noch bei 2.0. Sollte ich da eher upgraden? (Würde ich gerne > vermeiden) Habe es gerade noch mal nachgeprüft. Auch bei der 2.0 ist NBR schon default für neue Projekte. Vorher war es optional. Da es problemlos möglich ist mehrere Diamond Version parallel installiert zu haben, grade ich relativ schnell up. Bei einem Projekt in der kritischen Phase kann man die alte weiterverwenden. > >> Brute Force: d.h. mehrere P&R Iterationen, (lassen sich parallelisieren >> mit Windows auf mehrere Cores, mit Linux sogar auf mehrere Rechner) >> > > Mache ich dann in der nächsten Phase. So weit bin ich noch nicht mit der > Optimierung. bei 160 MHz > >> Schau dir das Eregbnis im Timinganalysator von Diamond an, da kannst du >> dir den Pfad im Floorplan anzeigen lassen. (Vorsicht: das kann negative >> Auswirkungen auf den Blutdruck haben) > > Ansich habe ich erst mal auf Synplify-Ebene angefangen zu optimieren, um > generelle 'Schwachpunkte' (ok, it's a feature) gegenüber der > Spartan6-Synthese herauszukristallieren. Die zusätzlichen Register sind, > wo es geht, schon drin. Leider geht das an einigen FIFO-Schnittstellen > wegen zusätzlicher Latenzen nur bedingt gut > Das Blutdruckproblem bzgl. Floorplanner kenne ich schon :-) Um das zu > umgehen, bräuchte ich wohl eine neue Kiste. Momentan no go.. Ich bezog mich darauf zu sehen welche Pfade ihm wirklich Schwierigkeiten machen und warum. Floorplanning hatte ich erst bei einem Projekt eingesetzt, das lief aber mit 250 MHz. (Auf Speedgrade 8) Da waren auch einige Blockrams mit 250 MHz getaktet. > Im schlimmsten Fall muss ich wohl noch weitere > mini-Distributed-RAM-FIFOs dazwischenhängen, oder halt doch IPX-Cores > wrappen. Andere Idee? Path-based Placement (hat bei dem 250 MHz Projekt auch geholfen) Der Dualclock Lattice IPX Fifo verwendet Graycounter. Das entspannt.
Da habe ich wohl einen angefangenen Satz übersehen. Martin S. schrieb: >> Brute Force: d.h. mehrere P&R Iterationen, (lassen sich parallelisieren >> mit Windows auf mehrere Cores, mit Linux sogar auf mehrere Rechner) >> > > Mache ich dann in der nächsten Phase. So weit bin ich noch nicht mit der > Optimierung. > Bei 160 MHz kann das schon hilfreich sein, fürs erste einfach mal einen anderen Iterations Startpunkt eintragen. PAR_ADJ varieren ist auch eine Option.
Martin S. schrieb: > Kann > mir ev. jemand einen architektonisch wertvollen Hinweis geben? Ich kann dir nur empfehlen bei der Geschwindigkeit output-Flipflops zu verwenden. Ohne liegt die Zeit bis nach einem Takt Daten am Ausgang anliegen bei 2.8ns, mit bei unter 0.5ns. Bei 6ns pro Takt ist das verdammt viel! Nach meiner Erfahrung ist genau das das Problem bei 95% aller timing-Probleme mit Fifos. PAR_ADJ wird nichts helfen, wenn er schon ohne das timing nicht schafft, wie soll er das dann mit noch strengeren constraints machen?
Jan M. schrieb: > > PAR_ADJ wird nichts helfen, wenn er schon ohne das timing nicht schafft, > wie soll er das dann mit noch strengeren constraints machen? PAR_ADJ ist kein strengeres Constraint, d.h. es geht in die finale Timinganalyse nicht ein. Einzig und allein die Platzierung wird dadurch beeinflusst, sozudagen ein Hint dass er sich mehr Mühe geben soll.
Du hast natürlich recht, mit "constraint" meine ich die timing-Vorgabe für den par-Lauf und die ist strenger. Natürlich erreicht man mit PAR_ADJ in der Regel höhere maximale Taktraten. Allerdings habe ich noch keinen Fall gesehen, bei denen sie wirklich den Ausschlag gegeben hätten, ein nie erreichtes timing dann am Ende doch zu erreichen. Es könnte helfen, wenn man PAR_ADJ auf die entsprechenden Signale anwendet und so den placer überzeugt, Elemente dichter beisammen zu legen. Im Allgemeinen habe ich aber mit placement constraints bessere Ergebnisse erzielt. Wobei ich aus der Beschreibung von Martin heraus nicht glaube, dass er es mit schlechtem placement zu tun hat. Ohne output-FF wird man bei dieser Taktrate nicht glücklich werden - dafür sind die BRAM mit ihrer clock-to-out-Zeit einfach nicht schnell genug. Falls man dann noch das read-Signal abhängig von den erhaltenen Daten steuern sollte, dann ist man vom timing leider schon fast hoffnungslos verloren.
@Jan Ich gehe eigentlich davon aus, dass Martin Output-FFs hat. Könnte natürlich sein, dass bei seinem generisch codierten Fifo Synplify Pro das nicht erkennt und diese nicht in die EBR FFs verschiebt. Ich habe gerade mal bei mir geschaut, ca die Hälfte meiner Fifos haben auch kein OutputFF enabled und machen mir keinen Stress (125 MHz). Sind mit IPExpress generierte Singleclock Fifos. Ok, bei 125 MHz hat man 2ns mehr Luft. Eine Frage an an Martin, sind das asynchrone Dualclock Fifos?
Angehängte Dateien:
-

view.png
60 KB
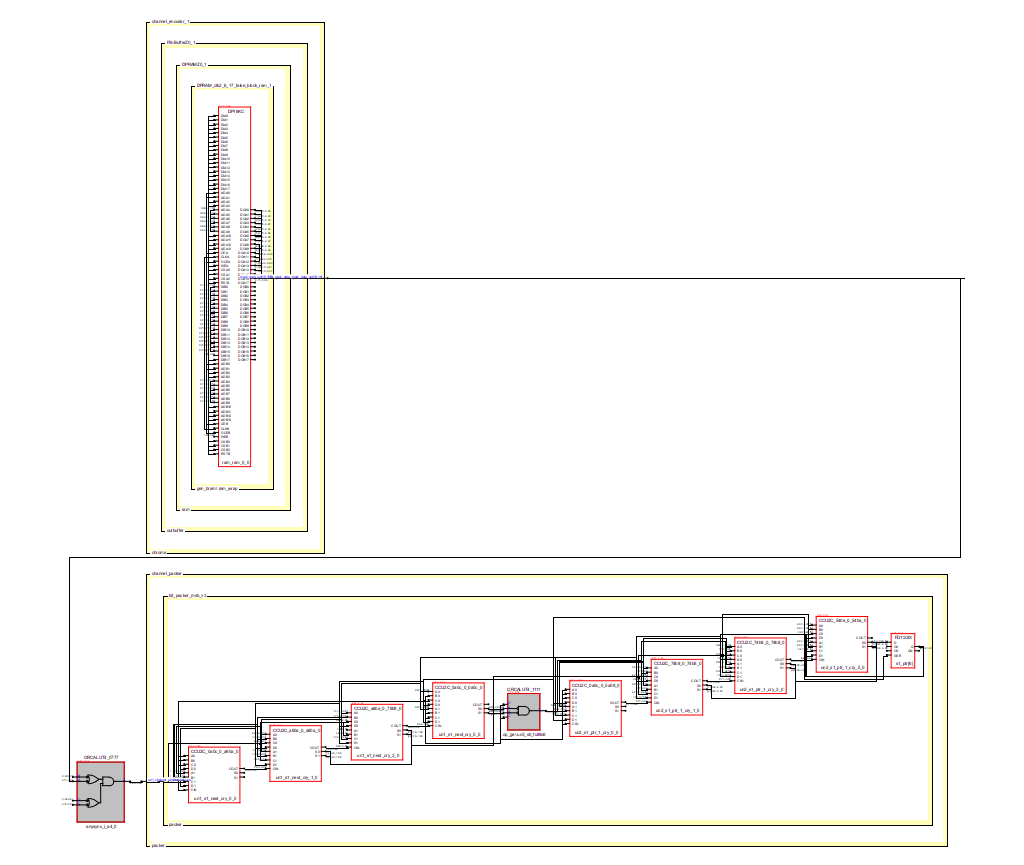
Morgen allerseits, > @Jan > Ich gehe eigentlich davon aus, dass Martin Output-FFs hat. Könnte > natürlich sein, dass bei seinem generisch codierten Fifo Synplify Pro > das nicht erkennt und diese nicht in die EBR FFs verschiebt. > Im RAM habe ich bei den kritischen FIFO-Elementen kein Output-Register drin, d.h. Daten liegen eine Clock-Periode nach entsprechender Adresse an. Ich habe mal einen Snapshot des kritischen Pfades ohne FF angehängt. Oben links die DP16KC-Primitive, unten eine Carry-Chain. Der minimale Slack kommt vom RAM, rund -3ns. Das deckt sich schon mal mit Jans Zeitangaben. Wenn ich probeweise noch ein FF dazwischenhaue, steht schon 50Mhz mehr auf dem Tacho :-) Muss das nur wieder mit einem weiteren 'readahead'-Buffer ausgleichen, damit ich die Latenz auf einen Cycle kriege. Wie Jan schon quasi erraten hat, muss die Logik an einer Stelle auf die Daten unmittelbar 1 cyc später reagieren. > Ich habe gerade mal bei mir geschaut, ca die Hälfte meiner Fifos haben > auch kein OutputFF enabled und machen mir keinen Stress (125 MHz). Sind > mit IPExpress generierte Singleclock Fifos. > Ok, bei 125 MHz hat man 2ns mehr Luft. > > > Eine Frage an an Martin, sind das asynchrone Dualclock Fifos? Nein, nur single-Clock. Mit händisch codierten DC-Async-FIFOs (Gray-coded) habe ich auf dem ECP3 blindlings losgelegt und mir gleich eine blutige Nase geholt. Irgendwas funktioniert bei den Lattice-RAM-Primitiven anders als bei Xilinx (da läuft es tadellos), ich habe nur nicht mehr weiter experimentiert und schlussendlich den IPX bemüht. Vermutlich irgend ein Problem mit der Wr/Rd-Priorisierung. Aber Dein Hinweis mit den Gray-Codes ist gut, ich probiere ev. mal die DC-FIFO-Variante mit einem Systemclock. Schon am "almost empty|full"-Komparator könnte sich das ev. auszahlen. Danke euch schon mal herzlich für die Tips, hilft mir schon mal, nicht in die falsche Richtung zu rennen. Beste Grüsse, - Strubi P.S. Ich vergass: schlechte PAR-Ergebnisse können wir, denke ich, nach den letzten Erkenntnissen, erst mal aussen vor lassen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.