Hallo allerseits,
ich stecke gerade bei einem Projekt in einer Sackgasse was einen
Algorithmus angeht. Ich habe folgendes Scenario:
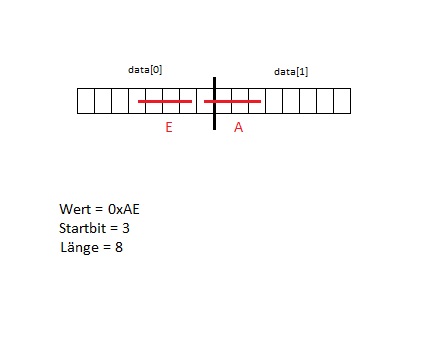
Byte-Array: __u8 data[8]
Ich betrachte das Array als 64Bit und möchte beispielsweise ab Bit 35
den wert 0x39D mit der Länge 10 Bit schreiben.
Dabei sollen alle anderen Werte (vor Bit 35 und nach Bit 45)
unangetastet bleiben.
Vielleicht liefert mir ja jemand einen Denkansatz dafür, denn ich komme
absolut nicht weiter. Ich habe viel mit links und rechtshift und masken
die ich über das ganze lege ruprobiert, aber leider kam ich bisher nicht
zum Ziel
Danke!
das einfachste ist doch einfach jedes Bit einzeln zu setzen.
Schreibe ein funktion
SetBit(pos, wert).
diese sollte recht einfach umsetzbar sein.
Dann gehst du einfach den wert bit für bit durch.
Herbert D. schrieb:> Setzen eines Bits ist gar kein Problem. Die eigentliche Schwierigkeit> ist, in welchem Schema SetBit aufgerufen werden muss.
wo ist da das Problem?
int StartPos = 32;
for( int i = 0; i < 8; ++ i ) {
SetBit( StartPos + 32, ( wert >> i) & 1 )
}
Hi Herbert, das ist schonmal ein toller Ansatz, aber was genau meinst du
mit
"wert" in dem Prototyp SetBit(pos, wert) ?
So wie ich das verstehe berücksichtigt die Variante auch (noch) nicht
das Intel (little endian) Problem berücksichtigt.
Danke und Grüße
Herbert D. schrieb:> "wert" in dem Prototyp SetBit(pos, wert) ?>> So wie ich das verstehe berücksichtigt die Variante auch (noch) nicht> das Intel (little endian) Problem berücksichtigt.
wert ist der wert den das bit annhemen soll, also 0 oder 1. Und es
berücksichtig das Endian problem. Du hast nur nicht definiert in welcher
reihenfolge der Bits drin stehen sollen. Aber es liefert auf alles
systemen das gleicher ergebniss.
Hi Peter. Danke für die Mühe.
So wie ich das sehe, schiebt dieser Ausdruck
1
( wert >> i) & 1
einfach beginnend beim LSB bis hoch zum MSB alle Bits von Wert einzeln
in die setBit-Funktion. Bei der Intel Methode wird aber nicht die
Ordnung der Bits, sondern die der Bytes gedreht.
Herbert D. schrieb:> Byte-Array: __u8 data[8]
Da gibt es keine "intel-Zählweise". Das sind 8 einzelne Bytes mit
jeweils 8 einzelnen Bits.
Endianness kommt erst dann ins Spiel, wenn Datentypen verwendet werden,
die mehrere Bytes groß sind - also 16-Bit-, 32-Bit- oder 64-Bit-Werte.
Da Du aber auf Byteebene operierst, kann Dir das egal sein.
Deine Bitsetzoperation besteht aus drei Schritten:
a) bestimme das zu verändernde Byte
Bitnummer durch 8 teilen
b) bestimme die Nummer des zu verändernden Bits in diesem Byte
Bitnummer modulo 8
c) Setze/Lösche dieses Bit.
Fertig.
Herbert D. schrieb:> einfach beginnend beim LSB bis hoch zum MSB alle Bits von Wert einzeln> in die setBit-Funktion. Bei der Intel Methode wird aber nicht die> Ordnung der Bits, sondern die der Bytes gedreht.
der compiler kümmert sich darum. Es ist definiert was bei bei >>
rauskommen. Dabei ist es egal wie die byte angeordnet sind.
aus dem Grund ist auch das auf jeden System gültig
int i = x1<<8 | x1
also 2byte zu einem 16bit verbinden
Rufus Τ. Firefly schrieb:> Herbert D. schrieb:>> Byte-Array: __u8 data[8]>> Da gibt es keine "intel-Zählweise". Das sind 8 einzelne Bytes mit> jeweils 8 einzelnen Bits.>> Endianness kommt erst dann ins Spiel, wenn Datentypen verwendet werden,> die mehrere Bytes groß sind - also 16-Bit-, 32-Bit- oder 64-Bit-Werte.
Hallo Rufus. Im Prinzip arbeite ich mit datentypen die mehrere Byte groß
sind, ich zerteile sie nur in 8-Bit Pakete. Die Anwendung dahinter ist
folgende: Ich habe einen CAN-Frame mit 8 Datenbytes. Jetzt möchte ich
ein Signal darin codieren (Beispielsweise eine Spannungsmessung) die 10
Bit lang ist. Ich möchte auf diese Weise den CAN-Frame maximal ausnutzen
und alle Bits verwenden.
So kann es sein, dass mein 10-Bit Wert in der Mitte des zweiten Bytes
beginnt und im dritten Byte endet. Der 10 Bit Wert ist allerdings
Little-endian dargestellt und muss deshalb auch so in meine Datenfelder
gelegt werden.
Herbert D. schrieb:> So kann es sein, dass mein 10-Bit Wert in der Mitte des zweiten Bytes> beginnt und im dritten Byte endet. Der 10 Bit Wert ist allerdings> Little-endian dargestellt und muss deshalb auch so in meine Datenfelder> gelegt werden.
Nö.
Das deine 10 Bit Werte Little-Endian sind, interessiert erst den
Empfänger wieder, der sich die 10 Bit Werte aus dem CAN-Frame wieder
rausholt.
Hier bist du schon auf Transportebene. Hier gibt es nur noch Bytes. Der
Sender verpackt die Bits und der Empfänger entpackt die Bits. Was sie
bedeuten interessiert auf dieser Ebene nicht mehr. Du machst dir selber
das Leben schwer, in dem du dich an dieser Stelle um Details kümmerst,
die dich nicht kümmern müssen.
Das einzige was uns kümmern muss ist, dass die Reihenfolge der zu
codierenden Bits von Sender und Empfänger gleich angesehen werden. Kommt
das MSB zuerst, oder kommt das LSB zuerst.
1
// MSB zuerst
2
voidEncode10Bit(__u8StartBitPosition,__u16Wert)
3
{
4
__u8i;
5
6
for(i=0;i<10;i++)
7
{
8
SetBit(StartBitPosition,Wert&0x0200);
9
StartBitPosition++;
10
Wert<<=1;
11
}
12
}
13
14
__u16Decode10Bit(__u8StartBitPosition)
15
{
16
__u16Wert=0;
17
18
for(i=0;i<10;i++)
19
{
20
if(GetBit(StartBitPosition))
21
Wert|=1;
22
23
Wert<<=1;
24
}
25
26
returnWert;
27
}
Wie hingegen die Bytes in einem Int angeordnet sind, interessiert dich
weder beim Sender, noch beim Empfänger. Denn das macht der Compiler,
wenn er die Schiebeoperationen umsetzt.
Verzeihung wenn ich etwas dumm dabei klinge, aber ich kapier die
Argumentation noch nicht.
Mein Empfänger erwartet die Daten im can-Frame im Little Endian Format,
daran kann ich nix ändern. Lege ich die Daten einfach so in den
can-Frame ab kommen an der anderen Seite beim Empfänger falsche Werte
raus.
Wo kümmert sich jetzt wer um dieses Problem?
Dein Problem ist etwas schwer zu verstehen.
Warum legst Du die Daten nicht so ab, wie sie der Empfänger erwartet?
Und was spielt auf Bit-Ebene ein little oder big Endian Format für eine
Rolle?
kümmert sich der Compiler darum, dass die logische Anordnung der Bits,
so wie du sie festgelegt hast (also Most Signifikant Bit zuerst) wieder
in die notwendige Endianess übersetzt wird.
Wendet man einen Schiebebefehl an, der sich notgedrungenermassen über
mehrere Bytes hinzieht, dann berücksichtigt der Compiler die Endianess,
so dass die Bits sich in der logisch richtigen Art und Weise durch die
Bytes schieben. Unabhängig von ihrer physikalischen Anordnung.
Alles andere wäre auch gehirntot und würde Schiebe-, aber auch alle
Bitoperationen auf mehrbytigen Datentypen vollkommen unbrauchbar machen.
Bei
1
inti=5;
2
3
if(i&0x00FF)
4
...
brauch ich mich nicht um die Endianess zu kümmern! Genausowenig, wie ich
es bei
1
intj=i<<6;
tun muss. Logisch gesehen wandern die Bits um 6 Stellen nach links. WIe
sich das IM SPEICHER auswirkt, wenn der 16 Bit Wert mit der vorgegebenen
Endianess abgelegt wird, ist etwas was mich an dieser Stelle nicht zu
kümmern braucht.
spontan schrieb:> Dein Problem ist etwas schwer zu verstehen.> Warum legst Du die Daten nicht so ab, wie sie der Empfänger erwartet?
Genau das versuche ich und dabei benötige ich die Hilfe von euch.
spontan schrieb:> Und was spielt auf Bit-Ebene ein little oder big Endian Format für eine> Rolle?
Es spielt insofern ne Rolle, da ich die Daten aufbereiten muss, sodass
sie mein Empfänger versteht.
spontan schrieb:> Dein Problem ist etwas schwer zu verstehen.
Ich versuche es nochmal zu erklären: Ich muss über den CAN Bus Daten an
senden. Die allgemeine Verabredung auf dem Bus ist, dass die Daten in
den Telegrammen little-endian formatiert sind. Wenn ich jetzt meine
Daten stur in den canframe lege - wie oben als unproblematisch erklärt -
interpretiert sie mein Emfänger falsch.
Zahlenbeispiel:
value = 2748(dez) = 0xABC(hex)
Mein Empfänger möchte die Daten wie folgt im CAN frame sehen:
00 00 00 BC 0A 00 00 00
Lege ich die Daten stur rein, sieht es ja folgendermaßen aus
00 00 00 AB C0 00 00 00
Der Empfänger interpretiert nun die Zahl falsch.
Nach obiger Methode (Peter II) wird sogar noch MSB und LSB vertauscht
und es steht
00 00 00 3D 50 00 00 00
im Frame. Empfänger interpretiert ebenfalls falsch.
Herbert D. schrieb:> Ich versuche es nochmal zu erklären: Ich muss über den CAN Bus Daten an> senden. Die allgemeine Verabredung auf dem Bus ist, dass die Daten in> den Telegrammen little-endian formatiert sind.
SObald du eine derartige Kompression machst, in der du mehrere 10-Bit
Werte in Bytes quetscht, so dass kein Bit unbenutzt bleibt, ist das
Konzept der 'Endianess' hinfällig geworden. Denn dann hast du im
CAN-Frame keine Endianess mehr. Du hast eine private Interpretation
erzeugt, wie die Bits im Frame liegen. Die Bytestrukturierung eines
Frames hat sich damit selbst überholt.
Das Konzept des 'Least Signifiakant Bit' zuerst oder eines 'Most
Signifikant Bit' zuerst, macht noch Sinn und ist auch wichtig um die
Daten wieder korrekt zu rekonstruieren. Aber Endianess auf Byteebene ist
hier auf Frameebene hinfällig geworden, weil deine Bytes sowieso nur
noch notwendiges Übel sind. Tatsächlich jedoch ist diese künstliche
Einteilung sinnlos geworden und man sieht einen derartigen Frame als
eine Abfolge von Bits an. Und nicht mehr.
> Daten stur in den canframe lege - wie oben als unproblematisch erklärt -> interpretiert sie mein Emfänger falsch.
Dann stimmen dein Sendecode und dein Empfangscode nicht überein.
Herbert D. schrieb:> Aber der Empfänger verlangt doch nach dieser Datenabfolge, nicht ich :-)
Was genau sagt die Doku zu deinem Empfänger?
Bitte wortwörtlich zitieren.
Bis jetzt ist das ja noch gar nicht aufgetaucht, dass dir der
Empfangscode aufs Auge gedrückt wurde.
Karl Heinz Buchegger schrieb:> Herbert D. schrieb:>> Aber der Empfänger verlangt doch nach dieser Datenabfolge, nicht ich :-)>> Was genau sagt die Doku zu deinem Empfänger?> Bitte wortwörtlich zitieren.>> Bis jetzt ist das ja noch gar nicht aufgetaucht, dass dir der> Empfangscode aufs Auge gedrückt wurde.
Hallo Karl-Heinz, vorwerg schonmal danke für die vielen ausführlichen
Erklärungen.
Einen schriftliche Doku dazu habe ich leider nicht. Was ich habe ist
eine CAN-Spec vom Empfänger, die folgendes definiert:
Botschaft ID: 0x3AC
Signal 1: Temperatur - Startbyte: 4 - Startbit: 0 - Länge: 12Bit
Signal 2: Timestamp - Startbyte: 5 - Startbit: 4 Länge: 10Bit
...
Meine Applikation liefer jetzt die Werte für Timestamp und Temperatur
als Integer. Diese muss ich jetzt in den CAN-Frame nach obiger vorgabe
verstricken, sodass mir der Empfänger am Display diese richtigen Daten
anzeigt. Ich habe mir den CAN-Trace angesehen und mit Tests
herausgefunden, was der Empfänger gerne sehen möchte. Die Doku des
Empfängers sagt mir nur, dass es die Daten im Intel-Format sehen möchte.
Für obiges beispiel Temperatur erwartet der Emfänger bei einem Wert von
temp=0xABC folgendes Datenpaket:
00 00 00 BC 0A 00 00 00
Verstehe ich dich richtig, dass du sagst, dass das NICHT echtes
little-endian ist, sondern eine proprietäre Verdrehung der Daten?
Herbert D. schrieb:> Für obiges beispiel Temperatur erwartet der Emfänger bei einem Wert von> temp=0xABC folgendes Datenpaket:>> 00 00 00 BC 0A 00 00 00
Ja, ok.
Da beginnt jetzt allerdings der Wert an einer tatsächlichen Bytegrenze.
Ich könnte schwören, ich hab hier irgendwo im Thread gelesen, dass da 10
Bit Werte knirsch an knirsch in den Bytes abgelegt werden sollen. Ich
finde allerdings die Stelle nicht mehr.
Ah, hier ist es
> Jetzt möchte ich ein Signal darin codieren (Beispielsweise eine> Spannungsmessung) die 10 Bit lang ist. Ich möchte auf diese Weise> den CAN-Frame maximal ausnutzen und alle Bits verwenden.> So kann es sein, dass mein 10-Bit Wert in der Mitte des zweiten> Bytes beginnt und im dritten Byte endet.
Äh. Moment. Das kannst du nicht tun. Davon muss auch der Empfänger
wissen!
(Und das dürfte auch der Grund für das Missverständnis sein. Denn damit
man sowas machen kann, muss man auch den EMpfangscode unter Kontrolle
haben. Wenn dir der Aufs Auge gedrückt ist, dann kannst du nicht einfach
eine Datenkompression da einbauen, ohne das der Empfänger davon weiß)
> Verstehe ich dich richtig, dass du sagst, dass das NICHT echtes> little-endian ist, sondern eine proprietäre Verdrehung der Daten?
Das wäre es, wenn der nächste im Frame abzulegende Werte sich direkt an
die Bits im Byte 0A ankoppeln würde, so wie du dir das in deiner
Kompression vorstellst.
Hey,
also ich entwickel hier keine eigene Kompression. Ich habe nur
angenommen das wäre der Sinn und Zweck dieser Signaldefinitionen beim
Empfänger, da hier Information an Information gequetscht wird.
Und tatsächlich finde ich zum Beispiel gerade einen Wert mit der Angabe
Signal 5: Startbyte: 5 - Startbit: 7 - Länge 3
Also hier sind die Grenzen nicht mehr bündig an den Bytes angelegt. Das
ist durchaus auch nicht selten in dieser CAN Tabelle. Also ganz krumme
Geschichten wie oben genannt:
00 00 00 00 xx yy 00 00
xx = 000000xx
yy = y0000000
Also auch sowas ist denkbar.
> Signal 1: Temperatur - Startbyte: 4 - Startbit: 0 - Länge: 12Bit> Signal 2: Timestamp - Startbyte: 5 - Startbit: 4 Länge: 10Bit
D.h. du hast das hier
1
7 6 5 4 3 2 1 0
2
3
Byte 0 x x x x x x x x
4
5
Byte 1 x x x x x x x x
6
7
Byte 2 x x x x x x x x
8
9
Byte 3 x x x x x x x x
10
11
Byte 4 T7 T6 T5 T4 T3 T2 T1 T0 (Temperatur: BIts 7 bis 0
d.h. die eigentliche Fragestellung nach der Bitaufteilung stellt sich
doch gar nicht. Das ist ein einfache Aufteilung in Nibbles und neu
zusammenstellen der Nibbles. Auf Bitebene brauchst du doch da gar nicht
runter.
1
Byte[4]=Temperatur&0xFF;
2
Byte[5]=((Temperatur>>8)&0x0F)|(Zeit<<4)&0xF0;
3
Byte[6]=(Zeit>>4)&0x3F;
u..n..d fertig
Was wieder mal meine These unterstreicht, dass die Dinge einfach sind,
wenn man sie sich konkrekt aufmalt.
Karl Heinz Buchegger schrieb im Beitrag #3268098:
> d.h. die eigentliche Fragestellung nach der Bitaufteilung stellt sich> doch gar nicht. Das ist ein einfache Aufteilung in Nibbles und neu> zusammenstellen der Nibbles. Auf Bitebene brauchst du doch da gar nicht> runter.
Ganz genau so soll das aussehen.
Herbert D. schrieb:> Wobei es muss nicht zwangsläufig Nibble-weise passieren. Wie oben> geschildert kann es auch ganz krumm werden.
Dann mal dir den entsprechenden Frame auf und such nach Lösungen, wie du
mit ein bischen Schieben und maskieren den benötigten Teil an die
jeweils richtige Stelle im richtigen Byte bringst.
Karl Heinz Buchegger schrieb:> Herbert D. schrieb:>> Wobei es muss nicht zwangsläufig Nibble-weise passieren. Wie oben>> geschildert kann es auch ganz krumm werden.>> Dann mal dir den entsprechenden Frame auf und such nach Lösungen, wie du> mit ein bischen Schieben und maskieren den benötigten Teil an die> jeweils richtige Stelle im richtigen Byte bringst.
Schwere geburt: Jetzt sind wir ganz genau am Anfang des Threads
angelangt, wo ich genau die Frage stellen wollte, wie das geht :-)
Ich bin hier schon die ganze Zeit am maskieren und schieben.
Danke für die Mühe bisher!
Herbert D. schrieb:> Karl Heinz Buchegger schrieb:>> Herbert D. schrieb:>>> Wobei es muss nicht zwangsläufig Nibble-weise passieren. Wie oben>>> geschildert kann es auch ganz krumm werden.>>>> Dann mal dir den entsprechenden Frame auf und such nach Lösungen, wie du>> mit ein bischen Schieben und maskieren den benötigten Teil an die>> jeweils richtige Stelle im richtigen Byte bringst.>> Schwere geburt: Jetzt sind wir ganz genau am Anfang des Threads> angelangt, wo ich genau die Frage stellen wollte, wie das geht :-)>> Ich bin hier schon die ganze Zeit am maskieren und schieben.>> Danke für die Mühe bisher!
Welcher Teil von
1
Byte[4]=Temperatur&0xFF;
2
Byte[5]=((Temperatur>>8)&0x0F)|(Zeit<<4)&0xF0;
3
Byte[6]=(Zeit>>4)&0x3F;
gefällt dir nicht?
Nach dem aufmalen der Framestruktur konnte ich das in 10 Sekunden
hinschreiben.
Ich kann es nur nochmal betonen: Mach dir derartige Frameskizzen,
welches Bit wohin gehört! Daraus leitet sich der Code in 0-komma-nix ab.
Ist doch eh immer das gleiche Schema.
Achso natürlich, das verstehe ich.
Ich habe nur keine statischen Signale wie Temperatur oder Timestamp
sondern eine Liste mit knapp 200 solchen Signalen und Botschaften und
ich muss diese generisch zusammenfriemeln. Ich suche quasi einen
Algorithmus, der für jede kombination aus Startbit, Länge, und Datum das
CAN-Frame so zusammenbaut.
Daran hängts.
Herbert D. schrieb:> Achso natürlich, das verstehe ich.>> Ich habe nur keine statischen Signale wie Temperatur oder Timestamp> sondern eine Liste mit knapp 200 solchen Signalen und Botschaften und> ich muss diese generisch zusammenfriemeln. Ich suche quasi einen> Algorithmus, der für jede kombination aus Startbit, Länge, und Datum das> CAN-Frame so zusammenbaut.>> Daran hängts.
Dann musst du das Schema durchschauen.
Wie funktioniert es?
Du hast einen Wert mit zb den Bits
1
b13 b12 b11 b10 b9 b8 b7 b6 b5 b4 b3 b2 b1 b0
und du hast ein Byte, in welches ein Ausschnitt aus diesen Bits rein
soll
1
+---+---+---+---+---+---+---+---+
2
| | | | | | | | |
3
+---+---+---+---+---+---+---+---+
4
7 6 5 4 3 2 1 0
zb sollen die Bits b7 bis b11, an die Bitpositionen 2 bis 6.
Wie geht das?
Das ist also der Ausgangspunkt
1
b13 b12 b11 b10 b9 b8 b7 b6 b5 b4 b3 b2 b1 b0
2
3
+---+---+---+---+---+---+---+---+
4
| | | | | | | | |
5
+---+---+---+---+---+---+---+---+
6
7 6 5 4 3 2 1 0
Als erstes stellst du mal sicher, dass am Ziel die Bits auf 0 sind. Mit
einer Und-Operation ist das ja kein Problem. Die 0 sind deswegen
wichtig, damit man später die Bits von der Quelle einfach ein-Odern kann
Bitposition 2 bis 6 bedeutet, dass man eine Maske von 0x7C braucht
1
b13 b12 b11 b10 b9 b8 b7 b6 b5 b4 b3 b2 b1 b0
2
3
+---+---+---+---+---+---+---+---+
4
| | 0 | 0 | 0 | 0 | 0 | | |
5
+---+---+---+---+---+---+---+---+
6
7 6 5 4 3 2 1 0
Gut. Dann wird die Quelle entsprechend nach links oder rechts
verschoben, bis die gewünschten b-Bits über den 'Slots' im Ziel stehen.
In diesem Fall soll b7 über dem Bit 2 stehen kommen. Wie die Zeichnung
zeigt
1
b13 b12 b11 b10 b9 b8 b7 b6 b5 b4 b3 b2 b1 b0
2
|
3
+-------------------+
4
| |
5
| v
6
+--|+---+---+---+---+---+---+---+
7
| || 0 | 0 | 0 | 0 | 0 | | |
8
+--|+---+---+---+---+---+---+---+
9
7| 6 5 4 3 2 1 0
10
|
11
+-->1 |
12
+-->2 |
13
+-->3 |
14
+-->4 |
15
+-->5
muss dazu 5 mal nach rechts verschoben werden. (Rein rechnerisch: 7
minus 2 ergibt 5; und weil das Ergebnis positiv ist, ist es ein rechts
schieben)
Also machen wir das:
1
b13 b12 b11 b10 b9 b8 b7 b6 b5 b4 b3 b2 b1 b0
2
3
+---+---+---+---+---+---+---+---+
4
| | 0 | 0 | 0 | 0 | 0 | | |
5
+---+---+---+---+---+---+---+---+
6
7 6 5 4 3 2 1 0
Dann werden von der Quelle alle anderen Bits auf 0 gesetzt, damit sie
bei der abschliessenden Oder Operation nicht in die Quere kommen.
1
0 0 b11 b10 b9 b8 b7 0 0 0 0 0 0 0
2
3
+---+---+---+---+---+---+---+---+
4
| | 0 | 0 | 0 | 0 | 0 | | |
5
+---+---+---+---+---+---+---+---+
6
7 6 5 4 3 2 1 0
und zu guter letzt können die jetzt freigestellten b-Bits in das Zeil
reingeodert werden.
1
0 0 b11 b10 b9 b8 b7 0 0 0 0 0 0 0
2
| | | | |
3
+---+---+---+---+---+---+---+---+
4
| |b11|b10| b9| b8| b7| | |
5
+---+---+---+---+---+---+---+---+
6
7 6 5 4 3 2 1 0
Da vorher dort schon 0-Bits standen, reicht ein einfaches Oder. fertig.
Das ist das allgemeine Schema:
* Im Ziel die Zielbits auf 0 setzen
* Die Quelle entsprechend zurecht schieben
* In der Quelle die nicht interessierenden Bits auf 0 setzen
* Reinordern
Je nach konkreter Situation können einzelne Schritte entfallen bzw.
vereinfacht werden.
D.h. du musst nur noch die variablen Teile dieses Prozesses (die
Bitpositionen) definieren. Kann man zb in einer Tabelle machen.
Und dort kannst du dann zb auch definieren, dass eben die Bits 0 bis 7
ins Byte 4 müssen und die Bits 8 bis 12 ins Byte 5.
Karl Heinz Buchegger schrieb:> D.h. du musst nur noch die variablen Teile dieses Prozesses (die> Bitpositionen) definieren. Kann man zb in einer Tabelle machen.> Und dort kannst du dann zb auch definieren, dass eben die Bits 0 bis 7> ins Byte 4 müssen und die Bits 8 bis 12 ins Byte 5.
Ich könnte mir zb vorstellen, dass es ein Array von Strukturen gibt,
wobei jede Struktur eine CAN-Nachricht codiert. Der Index ins Array ist
die logische Identifikation der Nachricht
Im Endeffekt könnte die zb so aussehen
1
structCanMsg[...]=
2
{
3
// Variable Ab Bis Ziel- Ab
4
// Bit Bit Byte Bit
5
// | | | | |
6
// v v v v v
7
.....
8
// SendTimeStamp
9
{0x03AC,{// Temperatur Time Stamp
10
{&Temperatur,0,8,4,0},
11
{&Temperatur,8,11,5,0},
12
{&Zeit,0,3,5,4},
13
{&Zeit,4,9,6,0}
14
}
15
},
16
17
{....
eine allgemeine Routine arbeitet diese Definition ab und baut die Msg
entsprechend zusammen, wenn du nicht für jede Msg eine eigene Routine
haben willst. (*)
wenn ein wenig Verschwendung nicht stört macht man das Array mit den
'Bit-Anweisungen' direkt in die CanMsg Struktur heinein, sonst eben über
einen Zwischenpointer und einer extra Definition.
(*) gewiefte Programmierer würden ev. sogar über ein Hilfsprogramm
gehen, welches eine ähnliche Beschreibung zb in XML einliest und die
zugehörigen C-Funktionen für die einzelnen Nachrichten generiert. :-)
Es gibt keinen Grund, warum ein entsprechend aufwändiges Programm aus
obiger (sinngemässer) Beschreibung nicht das hier
generieren könnte.
Ja, manchmal schreibt man sich selbst Hilfsprogramme, welche den
eigentlichen Code aus einer Beschreibung dessen was der Code machen
soll, generieren. Vor allen Dingen dann, wenn man x-mal eine eigentlich
immer gleiche Funktion schreiben müsste, die nach Schema funktioniert
und sich nur durch die konkreten Zahlenwerte unterscheidet. Manchmal
kann man das mit dem Präprozessor abhandeln und manchmal muss man dafür
dann eben ein eigenständiges C-Programm schreiben. Wenn du 200
Funktionen schreiben müsstest, dann würde sich das schon lohnen, dafür
ein wenig Zeit zu investieren. Dann hast du das Beste aus 2 Welten: eine
einfache und wartbare Beschreibung UND nahezu maximalen Speed in der
eigentlichen Ausführung.
Viele Wege führen nach Rom.