Hi,
ich bin gerade dabei ein etwas größeres C Projekt richtig zu
strukturieren.
Dabei bin ich leider auf ein paar Probleme gestoßen die mir noch nicht
ganz klar sind.
In vielen Projekten habe ich gesehen, dass in den Header Files #includes
gemacht werden.
Unter welchen Voraussetzungen ist es üblich #includes in eine Header
Datei anstelle der entsprechenden C Datei zu schreiben ?
Ein weiteres "problem" betrifft globale Variablen. Es geht momentan
darum den Code in übersichtliche Teilbereiche zu untergliedern. Es sind
also keine unabhängigen Module.
Die globalen Variablen sind in den entsprechenden C Files definiert. Ist
es nun üblich ein großes globales Headerfile anzulegen z.B. "global.h"
und dort komplett alle globalen variablen mit extern davor aufzulisten ?
Anschließend würde die "global.h" in alle C Files eingebunden die
Zugriff auf eine der globalen Variablen benötigen. Oder ist es eher die
übliche Art die extern definitionen wirklich nur in der jeweils
zugehörigen header Datei zu setzen ?
Ich habe versucht mir ein paar open source C Projekte anzusehen um dort
eventuell ein paar Tricks / Möglichkeiten abschauen zu können dabei bin
ich oft auf folgenden Aufbau gestoßen:
test.h
1
test.h
2
#ifndef _TEST_H
3
#define _TEST_H
4
5
int varA
6
7
#endif
test.c
1
#include "test.h"
2
3
int varA
Wozu steht da int varA ohne extern in der Header Datei ? Ich war immer
der Meinung das die Header Files später an der #include stelle in die C
Datei eingesetzt werden. Ist dann nicht varA doppelt definiert was nicht
erlaubt sein dürfte ?
HeaderFile schrieb:> Unter welchen Voraussetzungen ist es üblich #includes in eine Header> Datei anstelle der entsprechenden C Datei zu schreiben ?
wenn du in einer Header Datei z.b. Datentypen aus einer andere Header
Datei brauchst.
HeaderFile schrieb:> Unter welchen Voraussetzungen ist es üblich #includes in eine Header> Datei anstelle der entsprechenden C Datei zu schreiben ?
Wenn in der Header-Datei auf Datentypen verwiesen wird, die dort nicht
definiert sind. Wenn also z.B. eine Struktur an eine Funktion übergeben
werden muss und die Struktur in einer anderen Header-Datei definiert
ist.
Jede Header-Datei sollte also alles inkludieren, was ein nichts-ahnender
Benutzer der Datei benötigt, um die Schnittstelle benutzen zu können. Ob
das erfüllt ist, kann man ganz einfach sicherstellen, indem man die
H-Datei in der dazugehörigen C-Datei als allererstes inkludiert. Das
darf keine Fehler geben.
Darüber hinaus sollte sie nichts weiter inkludieren, um möglichst
eigenständitg zu sein.
> Ein weiteres "problem" betrifft globale Variablen. Es geht momentan> darum den Code in übersichtliche Teilbereiche zu untergliedern. Es sind> also keine unabhängigen Module.
Das ist schon mal suboptimal. Code sollte immer nach dem Prinzip "Lose
Kopplung, starke Bindung" in Module aufgeteilt sein. Das heißt möglichst
unabhängige Teilmodule mit klar definierten Schnittstellen. Wenn Module
dagegen wechselseitig voneinander abhängen und gemeinsame Variablen
nutzen (müssen), spricht das stark dafür, dass dieser Code nicht an der
Stelle aufgeteilt gehört.
> Die globalen Variablen sind in den entsprechenden C Files definiert. Ist> es nun üblich ein großes globales Headerfile anzulegen z.B. "global.h"> und dort komplett alle globalen variablen mit extern davor aufzulisten ?> Anschließend würde die "global.h" in alle C Files eingebunden die> Zugriff auf eine der globalen Variablen benötigen. Oder ist es eher die> übliche Art die extern definitionen wirklich nur in der jeweils> zugehörigen header Datei zu setzen ?
Die Deklaration (mit extern) gehört in die H-Datei mit dem gleichen
Namen wie die C-Datei, nirgendwo anders hin. Außerdem ist dringend zu
empfehlen, dass der Variablenname als Prefix den Modulnamen enthält.
Grundsätzlich sollten globale Variablen wo immer möglich vermieden
werden. Außer in wirklich performancekritischen Situationen gibt es
keinen Grund, globale Variablen zu verwenden. Statische Variablen mit
get/set-Funktion erfüllen den gleichen Zweck. Wobei reine
get/set-Funktionen ohne weitere Bedeutung oft ebenfalls schon ein Indiz
für schlecht gekapselten Code sind.
> Ich habe versucht mir ein paar open source C Projekte anzusehen um dort> eventuell ein paar Tricks / Möglichkeiten abschauen zu können dabei bin> ich oft auf folgenden Aufbau gestoßen:>> [,..]>> Wozu steht da int varA ohne extern in der Header Datei ? Ich war immer> der Meinung das die Header Files später an der #include stelle in die C> Datei eingesetzt werden. Ist dann nicht varA doppelt definiert was nicht> erlaubt sein dürfte ?
Völlig richtig, daher ist das Beispiel einfach nur Murks. Nicht
nachmachen.
Fabian O. schrieb:> Darüber hinaus sollte sie nichts weiter inkludieren, um möglichst> eigenständitg zu sein.
Das lässt sich übrigens auch leicht testen: Wenn man ein "include <xy>"
in einer H-Datei vom Anfang der H-Datei ganz ans Ende (also unter alle
Funktionsdeklarationen etc.) verschieben kann, ohne dass sich der
Compiler beschwert, dann wird dieser Include in der H-Datei nicht
benötigt und gehört dort dementsprechend nicht hin.
Gilt auch für Includes in C-Dateien. ;-)
Fabian O. schrieb:> Das lässt sich übrigens auch leicht testen: Wenn man ein "include <xy>"> in einer H-Datei vom Anfang der H-Datei ganz ans Ende (also unter alle> Funktionsdeklarationen etc.) verschieben kann, ohne dass sich der> Compiler beschwert, dann wird dieser Include in der H-Datei nicht> benötigt und gehört dort dementsprechend nicht hin.>> Gilt auch für Includes in C-Dateien. ;-)
Ja, Nein, vielleicht.
Was ist, wenn eine andere Headerdatei schon die benötigten Informationen
einbindet?
1
foo.h:
2
# include <limits.h>
3
4
5
bar.h:
6
# include <limits.h> // diese Zeile könntest du löschen. Ist aber nicht sinnvoll
Vielen Dank das hat schonmal ein ganzes Stück geholfen :)
Zwei kleine Fragen kamen jetzt allerdings doch noch dazu.
Der allgemeine trend geht in Richtung globale Variablen vermeiden. Okay
das ist soweit nachvollziehbar.
Bei mir sind momentan die meisten der globalen Variablen aus den
folgenden Gründen global.
- Es sind flags die aus einem Interrupt gesetzt werden um dem
Hauptprogramm Timeouts, Zeitabläufe, Freigabesignale usw. zu erteilen.
Diese müssen meiner Meinung nach zwingend global sein oder gibt es da
doch bessere Lösungen ?
- Es sind relativ große Arrays bei denen ich ein schlechtes Gefühl habe
wenn sie bei einem Methodenaufruf auf dem Stack laden. Hier habe ich
jetzt allerdings Zweifel. Wenn ein Array innerhalb einer methode mit
static deklariert wird landet das Array dann überhaupt auf dem Stack ?
Bzw unterscheidet sich ein static Array innerhalb einer Methode von der
Speicherorganisation überhaupt von einem global definierten Array ?
HeaderFile schrieb:> Diese müssen meiner Meinung nach zwingend global sein oder gibt es da> doch bessere Lösungen ?
Müssen sie nicht. Es genügt, wenn sie lokal innerhalb des Moduls
verfügbar sind, in dem die ISR definiert ist. Der modulübergreifende
Zugriff auf die Variablen kann durch eine im gleichen Modul
untergebrachte Zugriffsfunktion erfolgen (die natürlich nicht als
static definiert sein darf).
> Wenn ein Array innerhalb einer methode mit> static deklariert wird landet das Array dann überhaupt auf dem Stack ?
Nein, statische Variablen landen nicht auf dem Stack.
> Bzw unterscheidet sich ein static Array innerhalb einer Methode von der> Speicherorganisation überhaupt von einem global definierten Array ?
Von der Speicherorganisation her nicht, nur ist ein Zugriff auf das
Array von außerhalb der das Array definierenden Funktion nicht möglich.
Im übrigen spricht man in C von Funktionen, nicht von "Methoden".
Dirk B. schrieb:> Ja, Nein, vielleicht.>> Was ist, wenn eine andere Headerdatei schon die benötigten Informationen> einbindet?>> foo.h:> # include <limits.h>>> bar.h:> # include <limits.h> // diese Zeile könntest du löschen. Ist aber nicht> sinnvoll> # include "foo.h">> Gilt auch für Includes in C-Dateien.
Stimmt, den Fall habe ich nicht bedacht.
Da hat man etwas Entscheidungsfreiraum. Bei Standarddateien wie limits.h
ist es natürlich sinnvoll, sie in jede H-Datei, die etwas daraus
braucht, einzubinden. Wenn der doppelte Include in bar.h allerdings
ausschließlich in Zusammenhang mit einer Funktion aus foo.h benötigt
wird, bräuchte man ihn nicht nochmal in bar.h einbinden.
HeaderFile schrieb:> Bei mir sind momentan die meisten der globalen Variablen aus den> folgenden Gründen global.>> - Es sind flags die aus einem Interrupt gesetzt werden um dem> Hauptprogramm Timeouts, Zeitabläufe, Freigabesignale usw. zu erteilen.> Diese müssen meiner Meinung nach zwingend global sein oder gibt es da> doch bessere Lösungen ?
Wie schon erwähnt: Statische Modulvariable, also eine "globale" Variable
mit static. In dem Modul (C-Datei) ist dann sowohl die ISR (z.B.
UART-ISR) als auch die dazugehörigen Funktionen (z.B. uart_send,
uart_receive etc.) enthalten, die auf die Variable Zugriff benötigen.
Von außerhalb des Moduls ist die Variable dagegen nicht erreichbar, d.h.
es darf problemlos eine Variable mit gleichem Namen in einem anderen
Modul geben. Und man kann sich sicher sein, dass niemand außerhalb des
eigenen Moduls auf die Variable zugreift, außer vielleicht über einen
wildgewordenen Zeiger ...
> - Es sind relativ große Arrays bei denen ich ein schlechtes Gefühl habe> wenn sie bei einem Methodenaufruf auf dem Stack laden. Hier habe ich> jetzt allerdings Zweifel. Wenn ein Array innerhalb einer methode mit> static deklariert wird landet das Array dann überhaupt auf dem Stack ?> Bzw unterscheidet sich ein static Array innerhalb einer Methode von der> Speicherorganisation überhaupt von einem global definierten Array ?
Du kannst das Array ebenfalls als statische Modulvariable anlegen. Dann
haben sogar mehrere Funktionen (eben alle in dem Modul) darauf Zugriff.
Falls ein anderes Modul mit dem Array arbeiten muss, übergibst Du beim
Funktionsaufruf nur einen Zeiger auf das Array (bzw. auf dessen erstes
Element) sowie die Länge des Arrays. Dann landet der Arrayinhalt nicht
auf dem Stack.
Fabian O. schrieb:> Falls ein anderes Modul mit dem Array arbeiten muss, übergibst Du beim> Funktionsaufruf nur einen Zeiger auf das Array (bzw. auf dessen erstes> Element)
Das ist in C sowieso nur so möglich. Einen "call by value" gibt es bei
Arrays nicht.
Ja, könnte man.
Denn dann wird ja ein Strukturobjekt übergeben und nicht in erster Linie
ein Array. Und wie bei allen anderen Datentypen auch, mit Ausnahme eines
Arrays, bedeutet das, dass eine Wertkopie erzeugt wird, die an die
Zielvariable in der Funktion gebunden wird.
Ab und an kommt sowas schon mal vor, wenn die Funktion sowieso eine
Kopier der Daten machen müsst um mit ihnen zu arbeiten.
Karl Heinz schrieb:> Und wie bei allen anderen Datentypen auch, mit Ausnahme eines> Arrays, bedeutet das, dass eine Wertkopie erzeugt wird, die an die> Zielvariable in der Funktion gebunden wird.
Wie bei allen Datentypen.
Arrays werden nicht by-reference übergeben, Arrays werden gar nicht
übergeben. Und die Zeiger auf Arrays, die C in einer etwas quirkigen
syntaktischen Verrenkung tatsächlich übergibt, sind dann wieder
by-value.
Ich weiß, du weißt das.
Hi,
ich muss das Thema doch nochmal ausgraben.
Folgende Frage. Wenn man wirklich zwingend globale Variablen benötigt
aber das Risiko der doppelten Namensgebung möglichst weit minimieren
möchte würde dann sowas gehen ?
main.h
1
#include<inttypes.h>
2
3
typedefstruct{
4
uint8_ttimer_flag;
5
uint8_ttimeout_flag;
6
uint8_tupdate_flag;
7
}FLAGS;
8
9
externvolatileFLAGSstatus_flags;
main.c
1
#include"main.h"
2
3
volatileFLAGSstatus_flags={0,0,1};
4
5
intmain(void)
6
{
7
while(1){
8
if(status_flags.timer_flag){
9
status_flags.timer_flag=0;
10
}
11
12
if(status_flags.update_flag){
13
status_flags.update_flag=0;
14
// mach was
15
}
16
}
17
}
18
19
ISR(TIMER0_COMPA_vect){
20
status_flags.timer_flag=1;
21
}
test.c
1
#include"main.h"
2
3
voidfoo(){
4
if(status_flags.timer_flag){
5
// mach was
6
}
7
}
So hätte man die Flags schonmal alle schön kompakt in einer Struktur
zusammengefasst was zum einen übersichtlicher ist und zum anderen die
Anzahl der globalen Variablennamen reduziert.
Folgende Fragen dazu. Funktioniert das volatile so wie oben verwendet
bei einem struct ? Oder anders werden so wie oben verwendet jetzt alle
variablen im struct automatisch volatile ?
Der Zugriff auf einzelne Flags muß atomar sein, ansonsten gibt's
Glitches, wenn in der ISR Flag gesetzt wird während in main gerande ein
anderes Flag verändert wird.
Außerdem ist FLAGS unglücklich, sieht aus wie ein Makro...
stimmt FLAGS als Name ist wirklich unglücklich. War ja aber auch nur
eine schnelle Idee.
Zum atomaren Zugriff. Bytezugriffe sollten meines Wissens automatisch
atomar sein oder ändert sich durch das Struct etwas daran ?
Ja, Bytezugriffe sind atomar, aber das Setzen / Löschen / Invertieren
eines Bits beinhaltet i.d.R mehr als ein Speicherzugriff und ist damit
nicht mehr atomar.
Schau dir einfach mal die vom Compiler erzeugte Codesequenz an.
if(status_flags.update_flag) endet in einem LDS Befehl der atomar ist.
Anschließend ist der Wert eh "sicher" im Register 24. Bei der if Abfrage
brennt also schonmal nichts an.
status_flags.update_flag = 0; endet in einem atomaren STS.
Würde zwischen der If Abfrage und dem zurücksetzen die ISR aufegrufen,
dann wäre zwar das flag wieder gesetzt, würde durch den STS aber
überschrieben. Also das was man an der Stelle ja auch bezwecken möchte.
Ich sehe da akut keine Probleme ?
Oder bezog sich deine Antwort auf den Fall das man nicht eine direkte
Zuweisung wie flag = 1 oder flag = 0 macht, sondern das Flag Byte als
Byte über 8 Flags sieht und dann mit |= bzw &= einzelne Bits des Flags
setzt / löscht. Dann sieht das natürlich anders aus.
Aber bei direkten Zuweisungen dürfte so wie ich das sehe eigentlich
nichts passieren oder ?
HeaderFile schrieb:> Aber bei direkten Zuweisungen dürfte so wie ich das sehe eigentlich> nichts passieren oder ?
Ah, stimmt. Aus irgendwelchem Grund bin ich davon ausgegangen, daß es
sich um Bitfelder handelt...
Ich bin gerade etwas verunsichert wie ich feststellen muss.
Kann man das wirklich so pauschalisieren, dass bei Bytevariablen und
einem direkten Zugriff wie lesen oder einer direkten Wertzuweisung
atomares Verhalten gegeben ist unabhängig davon ob sich um eine einzelne
Bytevariable, um eine Byte Variable in einem Struct oder aber um eine
Byte Variable in einem Array handelt ?
Wenn ich mich richt erinner gab/gibt es bei manchen AVRs ja auch Port
Register die nicht mehr im 8 Bit Adressraum liegen und daher nicht mehr
über SBI oder CBI Befehle direkt angesprochen werden können.
Kann unter irgendwelchem Umsatänden sowas auch bei Variablen passieren ?
HeaderFile schrieb:> - Es sind flags die aus einem Interrupt gesetzt werden um dem> Hauptprogramm Timeouts, Zeitabläufe, Freigabesignale usw. zu erteilen.> Diese müssen meiner Meinung nach zwingend global sein oder gibt es da> doch bessere Lösungen ?
Ja.
Arbeite einfach ohne irgendwelche Flags, die von mehreren
Programmteilen geschrieben werden. Wenn es nur eine einzige Instanz
gibt, die Flags setzt oder löscht und alle anderen nur zuschauen und
sich informieren dürfen, gibt es keine Probleme.
Für eine einseitige Verständigung arbeitet man besser mit (salopp
gesagten) Events, die in eine Event-Warteschlange kommen. Das ist
schlichtweg ein Ringpuffer. Dazu gibt es einen einzigen Modul im System,
der nach außen hin nur ganz wenige Funktionen aufweist (EVENTTYPE ist,
was dir grad paßt, z.B. int, long, dword, byte,.. oder was auch immer):
bool AddEvent(EVENTTYPE Event);
bool EventAvailable(void);
EVENTTYPE GetEvent(void);
und alle anderen Interna dieses Moduls braucht der Rest der Welt nicht
zu kennen. Will ein Modul nem anderen eine Botschaft zukommen lassen,
dann ruft er AddEvent(meineBotschaft) auf. Ein Verteiler in der
Grundschleife von main holt später all diese Event der Reihe nach aus
der Warteschlange und schmeißt sie allen vorhandenen Modulen in den
Rachen und welcher Modul sich dafür interessiert, der macht halt was
draus. Die anderen ignorieren ihn.
Wenn dir das zu aufwendig erscheint und es nur ne bilaterale Abstimmung
zwischen zwei Partnern sein soll (z.B. Exceptionhandler und
Grundprogramm), dann bietet sich ein simpleres Verfahren an:
Beide Partner haben eine Variable, z.B. ein char. Parallel dazu gibt es
(falls benötigt) eine Ergebnis-Variable, quasi einen Topf irgendeiner
Art. Wenn der eine was in den Topf getan hat, inkrementiert er seine
Variable. Der andere kann sie sich hereinladen und mit der seinigen
vergleichen und aus einer Ungleichheit ersehen, daß was Neues im Topf
liegt. Wenn er es dort herausgenommen hat, speichert er die geladene
Kopie des anderen in seiner Variablen. Daraus kann der andere wiederum
ersehen, daß die Beute abgeholt wurde. Und das Schöne ist, daß keiner
von beiden schreibend auf die Variable des anderen zugreifen muß.
Datenknatsch ist also ausgeschlossen. Lediglich das Überlaufen des
Topfes kann da noch passieren, aber das ist ne andere Sache.
W.S.
Dirk B. schrieb:> Was ist, wenn eine andere Headerdatei schon die benötigten Informationen> einbindet?
Dann ist das Zufall und man kann sich nicht drauf verlassen.
@W.S
Der Ansatz ist gut. Allerdings für die angedachte Aufgabe zu
überdimensioniert.
So viele unabhängige Module sind es in wirklichkeit garnicht. Das
arbeiten über einfache Byte Flags ist da definitiv die einfachste Lösung
voraussgesetzt das diese bytezugriffe halt wirklich atomar sind.
Das eigentliche Problem besteht an folgender Stelle. Ein Sd Karten Modul
will eine Variable hochgezählt haben um die Dateizeit im Fat System
setzen zu können. Diese wird per extern in der Headerdatei nach außen
gereicht. (SD Lib ist eine Fremdlib).
Eins meiner eigenen Module benötigt einen Timeoutflag falls der Serielle
Datenempfang abreißen sollte.
Ein andere Modul benötigt ein Flag das alle x ms gesetzt wird um
signalisiert zu bekommen das LCD Inhalte erneuert werden sollen.
Ein letztes Modul behandelt Tasterabfragen und benötigt eine Variable
die im Timerinterrupt inkrementiert wird um die Druckdauer ermitteln zu
können.
Alle diese Flags könnten in dem jeweiligen Modul auch static deklariert
werden. Es findet kein wechselseitiger Zugriff auf diese Flags zwischen
den einzelnen Modulen statt.
Was mich doch dazu bewegt sie ebend global sichtbar zu machen ist die
Tatsache das ich alle diese Flags von einem einzigen Timer steuern
lasse. Ich sehe es irgendwo nicht ein für so einen "pipifax" unnötig
viele Timer zu verschleudern. Würden Sie nicht global sichtbar sein so
müsste ja jedes Modul einen eigenen Timer mit eigener ISR innerhalb des
Moduls zwecks Sichtbarkeit haben. Um das zu umgehen sitzt der Timer halt
in der Main und alle nötigen Flags aus den anderen Modulen werden per
extern eingebunden und in der Timer ISR der Main gesetzt/behandelt.
Du brauchst also einfach nur mehrere Software-Timer, die auf einem
gemeinsamen Hardware-Timer basieren.
Als Anregung, wie so etwas aussehen kann (oder auch gerne zum direkt
wiederverwenden), hänge ich mal die Timer-Implementierung aus dem
Contiki-Betriebssystem an, die ich in einem Projekt mit
AVR-Mikrocontrollern eingesetzt habe.
Anpassen muss man nur die Datei "clock_config.h". Dort muss die
Initialisierung des Hardware-Timers rein, der Name der ISR definiert
werden und wie viele Ticks (ISR-Aufrufe) pro Sekunde stattfinden.
Die Verwendung sieht dann z.B. so aus:
1
#include"timer.h"
2
3
statictimer_ttimer1;
4
statictimer_ttimer2;
5
6
intmain(void)
7
{
8
clock_init();
9
sei();
10
11
timer_set(&timer1,(CLOCK_SECOND/50));
12
timer_set(&timer2,(CLOCK_SECOND/2));
13
14
while(1)
15
{
16
if(timer_expired(&timer1)){
17
timer_reset(&timer1);
18
led1_toggle();
19
}
20
21
if(timer_expired(&timer2){
22
timer_reset(&timer2);
23
led2_toggle();
24
}
25
}
26
}
Der Code lässt die erste LED 50 Mal pro Sekunde (also alle 20 ms) und
die zweite LED zwei Mal pro Sekunde (also alle 500 ms) blinken. Man kann
so einen Software-Timer sowohl für regelmäßige Intervalle als auch für
einmalige Timeouts benutzen, und zwar beliebig viele an beliebigen
Stellen im Programm, ganz ohne globale Variablen.
Sehr schicke Lösung nahezu Ideal für meinen Zweck :)
Aber eine kurze Frage dazu.
1
while(1){
2
if(timer_expired(&timer1)){
3
timer_reset(&timer1);
4
led1_toggle();
5
}
6
}
Das ganze ist ja nichts andere als Polling der vergangenen Zeit. Mit
jedem timer_expired() Aufruf wird intern ja clock_time() aufgerufen.
clock_time() sperrt für dem Atomaren Zugriff kurze Zeit die Interrupts.
Pollt man nun in einer Dauerschleife permanent timer_expired() führt das
doch zu einer ziemlich großen Zeitspanne in der Interrupts deaktiviert
sind. Könnte das nicht dazu führen das Interrupts anderer Module
verloren gehen ?
Oder ist das eher als unkritisch anzusehen ?
Ein Interrupt geht ja nicht sofort verloren, nur weil das auslösende
Ereignis auftritt, während die Interrupts deaktiviert sind. Das
Interrupt-Flag wird trotzdem im Hintergrund gesetzt. Sobald die
Interrupts wieder aktiviert werden, werden die ISRs aller aufgelaufenen
Interrupts angesprungen. Erst wenn alle abgearbeitet sind, geht es im
Hauptprogramm weiter.*
Ein Problem entsteht erst, wenn die Interrupts so lange am Stück
deaktiviert sind, dass zwei (oder mehr) Interrupts einer Sorte
auftreten. Also wenn z.B. der Timer zwei Mal überläuft. Dann bekommt man
den zweiten Überlauf nicht mehr mit, da das Interrupt-Flag halt nur ein
Bit ist und sich nicht die Anzahl der Interrupts merken kann.
Da bei dem Timer die Interrupts nur für das Lesen von zwei Bytes (oder
vier, wenn Du einen uint32_t nimmst) deaktiviert sind, ist das völlig
unkritisch. So schnell hintereinander treten keine zwei gleichen
Interrupts auf.
Es kommt also nicht darauf an, wie viel Prozent der Zeit das Programm
mit deaktiverten Interrupts verbringt, sondern wie lang (absolut
gemessen) die einzelnen Phasen maximal sind.
Du hast aber natürlich recht, dass in dem Beispielprogramm quasi die
ganze Zeit nur der Counter gepollt wird. Aber irgendwas muss der
Prozessor nun mal machen, wenn er sonst nichts zu tun hat. Wenn es Dich
stört, könntest Du ihn auch am Ende der Hauptschleife in den Sleepmodus
schicken. Dann wacht er erst beim nächsten Interrupt wieder auf und
spart in der Zwischenzeit Energie. In einem realen Programm gibt es in
der Hauptschleife aber ja auch noch andere Dinge zu tun. Und wenn nicht,
sei froh, dann hast Du zumindest kein Performanceproblem. ;-)
*) Beim AVR wird afaik zwischen zwei ISRs noch (mindestens) ein
Maschinenbefehl des Hauptprogramms ausgeführt. Ist für die Erklärung
aber egal.
Was mir gerade noch auffällt. Wieso werden eigentlich immer oder besser
so oft einfach alle Interrupts global gesperrt freigegeben.
Würde es nicht auch reichen immer nur den Interrupt zu
aktivieren/deaktivieren der für den entsprechenden Zugriff wirklich von
Relevanz ist ?
Oder spielen andere Interrupts da intern eventuell doch noch zwischen ?
Wenn man einen Timinghandler wie oben beschrieben implementiert. Ist die
Genuigkeit dann nicht immer zufällig ungenau ? Nimmt man mal an der
Timer hat ein Intervall von 10 ms in dem die counter variable
incrementiert wird.
Wartet man jetzt auf counter == 2, dann könnte das doch so ziemlich
alles zwischen 10 und 20 ms sein. Man weiß ja nicht genau wo sich TCCNT
intern gerade befindet. Sprich für eine möglichst hohe Genauigkeit
müsste das Timerintervall möglichst hoch sein richtig ? Bei einem 1 ms
Intervall hätte man dann eine maximale Abweichung von 1ms aber halt auch
eine höhere Auslastung des systems durch höhere Anzahl an Interrupts.
HeaderFile schrieb:
> Was mir gerade noch auffällt. Wieso werden eigentlich immer oder besser> so oft einfach alle Interrupts global gesperrt freigegeben.>> Würde es nicht auch reichen immer nur den Interrupt zu> aktivieren/deaktivieren der für den entsprechenden Zugriff wirklich von> Relevanz ist ?
Ist halt die einfachste Möglichkeit, weil man überall den gleichen
Befehl nutzen kann. Wenn man nur genau den einen Interrupt ausschaltet,
ist das fehleranfälliger und der Code nicht mehr so leicht in
verschiedenen Projekten einsetzbar. Im Beispiel oben bräuchte z.B. man
in clock_config.h eigene Funktionen/Makros, die den richtigen Interrupt
aktivieren/deaktiveren.
Wenn man die Phasen, in denen die Interrupts ausgeschaltet sind, kurz
hält, ist das ja auch kein Problem. Wozu also unnötigen Aufwand
betreiben ...
HeaderFile schrieb:
> Wenn man einen Timinghandler wie oben beschrieben implementiert. Ist die> Genuigkeit dann nicht immer zufällig ungenau ? Nimmt man mal an der> Timer hat ein Intervall von 10 ms in dem die counter variable> incrementiert wird.>> Wartet man jetzt auf counter == 2, dann könnte das doch so ziemlich> alles zwischen 10 und 20 ms sein. Man weiß ja nicht genau wo sich TCCNT> intern gerade befindet. Sprich für eine möglichst hohe Genauigkeit> müsste das Timerintervall möglichst hoch sein richtig ? Bei einem 1 ms> Intervall hätte man dann eine maximale Abweichung von 1ms aber halt auch> eine höhere Auslastung des systems durch höhere Anzahl an Interrupts.
Bei einmaligen Wartezeiten ja. Da weißt Du beim Starten des Timeouts
nicht, wo zwischen zwei Ticks sich der Timer gerade befindet. Das
Timer-Intervall muss also mindestens so hoch wie die benötigte
Genauigkeit sein.
Bei gleichmäßigen Intervallen (z.B. eine LED alle 50 ms blinken lassen)
hängt die Genauigkeit dagegen nur von der Ausführungsgeschwindigkeit der
Hauptschleife ab, sofern das Intervall ein Vielfaches des
Timer-Intervalls ist. Wenn die Timer-ISR (z.B. alle 10 ms) ausgeführt
wird, bekommt man es ja spätestens im nächsten Durchgang der
Hauptschleife mit.
Typischerweise nutzt man so einen Software-Timer aber ja auch nur für
Zeiten im Millisekundenbereich. Eine Timer-ISR pro Millisekunde ist für
den Mikrocontroller kein Problem. Für kürzere Zeiten sollte man eher
einen dedizierten Hardware-Timer oder delay_us() verwenden.
Hi,
ja klingt plausibel und ist für zwecke vie einfache Timeouts,
Aktualisierungsevents usw. wirklich eine schicke Sache wenn es nicht auf
die letzte ms Genauigkeit ankommt.
Habe die Software Timer geschichte gerade nochmal selber nach einem
etwas anderen Prinzip gestrickt.
Mag jemand da eventuell mal drüber sehen ob das so passt ?
timer.h
HeaderFile schrieb:> Mag jemand da eventuell mal drüber sehen ob das so passt ?
Ich finde deine Wahl der Datentypen ungeschickt.
Bei Timern hat man es praktisch immer mit unsigned Typen zu tun. Denn
man wird sich einen Timer immer nur für die Zukunft stellen und nicht
für die Vergangenheit. D.h. niemand wird je einen Timer anfordern, der
alle -100ms seinen Event auslöst.
Das Problem ist nämlich 2-teilig.
Zum einen verschenkst du so Timerauflösung.
Gut, das wär noch nicht so schlimm.
Aber: dein 16 Bit Zähler wird irgendwann überlaufen. Wenn das
Millisekunden sind, dann läuft der nach 32 Sekunden über. Und dann wird
das hier
> cli();> timeDiff = timerEvent->timeExpired - time_count;> sei();>> if (timeDiff <= 0) {> tmp_result = 1;> setTimerEvent(timerEvent, timerEvent->delay);> }
nämlich grauslich in die Hose gehen.
Darüber solltest du nochmal nachdenken, was da alles passiert, wenn der
time_count von 32767 auf -32768 überläuft.
Wenn du deine Interrupts so kurz wie es nur geht sperren möchtest, dann
mach dir eine Zugriffsfunktion für den time_count, und nur für den
time_count. In der Funktion sperrst du die Interrupts, holst den Wert
und gibst die Interrupts wieder frei
und diese Funktion benutzt du dann an allen Stellen, an denen du den
aktuellen time_coutn abfrägst.
1
uint8_tgetTimerEvent(timer_event*timerEvent){
2
int16_ttimeDiff=0;
3
uint8_ttmp_result=0;
4
5
timeDiff=timerEvent->timeExpired-getTimeCount();
6
...
auf die Art hast du dann die Interruptsperre auf die kürzest mögliche
Zeit gedrückt. Es wird zwar bei dir mit den Timern nicht die große Rolle
spielen, aber Programme entwickeln sich ja auch weiter. Und irgendwann
kommen dann auch mal andere Interrupts ins Spiel.
Man muss ja nicht mutwillig, die Dinge länger sperren als nötig. Zumal
das ja auch kein Aufwand ist.
wo kommen die 0xE5 her?
Die hängen ja sicherlich irgendwie von der Taktfrequenz ab. Es spricht
nichts dagegen, hier die tatsächliche Berechung, basierend auf F_CPU
einzufügen. Dann kannst du erstens bei einer Umstellung der Taktfrequenz
(vielleicht auch auf einem anderen Prozessor), nicht darauf vergessen
und zum anderen ist auch nachvollziehbar wie sich der Wert berechnet
(und zwar auf bessere Art als durch einen Kommentar).
Wie auch immer, ist aber dieser Wert mit Sicherheit ein Wert, den man
besser dezimal anschreibt und nicht hexadezimal. Denn um den Wert in
Beziehung zu deinen Millisekunden zu setzen und verstehen zu können,
muss man ihn erst mal auf dezimal umformen um dann nachrechnen zu
können.
Jetzt ist es aber so, dass du den Wert ausgerechnet hast, auf Hex
umgeformt hast. Jemand der dein Programm verstehen will, muss als erstes
den Wert wieder von Hex auf Dezimal zurück umformen.
Wozu?
Schreibs doch gleich dezimal hin.
Dann kannst du beim Umformen auf Hex keinen Fehler machen, und der der
das alles wieder entziffern muss, kann beim Zurückumwandeln auf Dezimal
keinen Fehler machen.
Benutze immer die Schreibweise, die im gegebenen Fall die zweckmässigste
ist. Das kann Dezimal sein, das kann Hex sein, das kann Binär sein, das
kann die Shift-Bitnamen Schreibweise sein. Aber es ist immer nur eine
Schreibweise. Das Ergebnis (wenn richtig angeschrieben), ist sowieso
immer das selbe: Ein Bitmuster wird erzeugt und mit dem wird irgendwas
gemacht.
1
OCR0A=229;
macht genau dasselbe die Zuwiesung von 0xE5.
Aber es ist zumindest ein bischen besser zu lesen und in Beziehung zur
Taktfrequenz bzw. dem Vorteiler zu setzen.
Am besten ist natürlich, den Wert vom Compiler ausrechnen zu lassen.
Zwei sehr gute Tipps. Timer Berechnung mache ich jetzt über ein Makro
das war so etwas ungeschickt das stimmt.
Zum Übrlauf nehme wir mal den Fall time_count ist gerade 32767 und das
Delay bzw Intervall ist 100ms.
Aus timerEvent->timeExpired = time_count + timerEvent->delay;
wird dann timeExpired = -32569
Nehmen wir an noch im selben Zeitzyklus würd die Abfrage
timeDiff = timerEvent->timeExpired - time_count;
erfolgen. Dann würde das wie zu erwarten timeDiff = -32569 - 32569 =>
timeDiff = 200 ergeben.
Nehmen wir an der Timer ist jetzt ein wenig gelaufen und time_count
hatte nun auch seinen Overflow. Sagen wir er ist 50ms gelaufen. Dann ist
der aktuelle time_count Wert jetzt -32719.
Jetzt wieder die Berechnung der Differenz.
timeDiff = -32569 - -32719 => timeDiff = 150. Auch das war so zu
erwarten. An welcher Stelle könnte da etwas passieren ? Ich dachte da
ist gerade das schöne an der Signed Overflowrechnung. Sobald man die
Differenz berechnet spielt der Overflow keine Rolle mehr.
HeaderFile schrieb:> timeDiff = -32569 - -32719 => timeDiff = 150. Auch das war so zu> erwarten. An welcher Stelle könnte da etwas passieren ? Ich dachte da> ist gerade das schöne an der Signed Overflowrechnung. Sobald man die> Differenz berechnet spielt der Overflow keine Rolle mehr.
UNsigned.
Bei unsigned Berechnungen kannst du den Overflow ignorieren, solange das
Ergebnis nicht größer als (in deinem Fall) 65535 sein kann. Erst dann
hast du das Problem, dass du den Overflow berücksichtigen müsstest. ABer
bis dahin hast du durch unsigned die Gewissheit, dass du einfach
Subtrahieren kannst, ohne dich um den Wrap-Around kümmern zu müssen.
Hi,
meine obige Beispielrechnung hatte ich leider ein paar Dreher drin.
Hier nochmal die Richtige Beispielrechnung:
Aus timerEvent->timeExpired = time_count + timerEvent->delay;
wird dann timeExpired = -32669
Nehmen wir an noch im selben Zeitzyklus würd die Abfrage
timeDiff = timerEvent->timeExpired - time_count;
erfolgen. Dann würde das wie zu erwarten timeDiff = -32669 - 32767 =>
timeDiff = 100 ergeben.
Nehmen wir an der Timer ist jetzt ein wenig gelaufen und time_count
hatte nun auch seinen Overflow. Sagen wir er ist 50ms gelaufen. Dann ist
der aktuelle time_count Wert jetzt -32719.
Jetzt wieder die Berechnung der Differenz.
timeDiff = -32669 - -32719 => timeDiff = 50. Auch das war so zu
erwarten.
An welcher Stelle siehst du denn konkret das Problem ? Die obige
Rechnung provozierte ja exakt den Overflow wechsel.
@kbuchegg
wäre super wenn du dich nochmal zu der Geschichte melden könntest. Und
ob du eine konkrete Situation im Kopf hattest die sich einfach an einer
kleinen Beispielrechnung nachvollziehen lässt.
Habe gestern noch den halben Tag drüber gegrübelt aber keine potentiell
gefährlichen Fälle in der unsigned Differenzbildung gefunden.
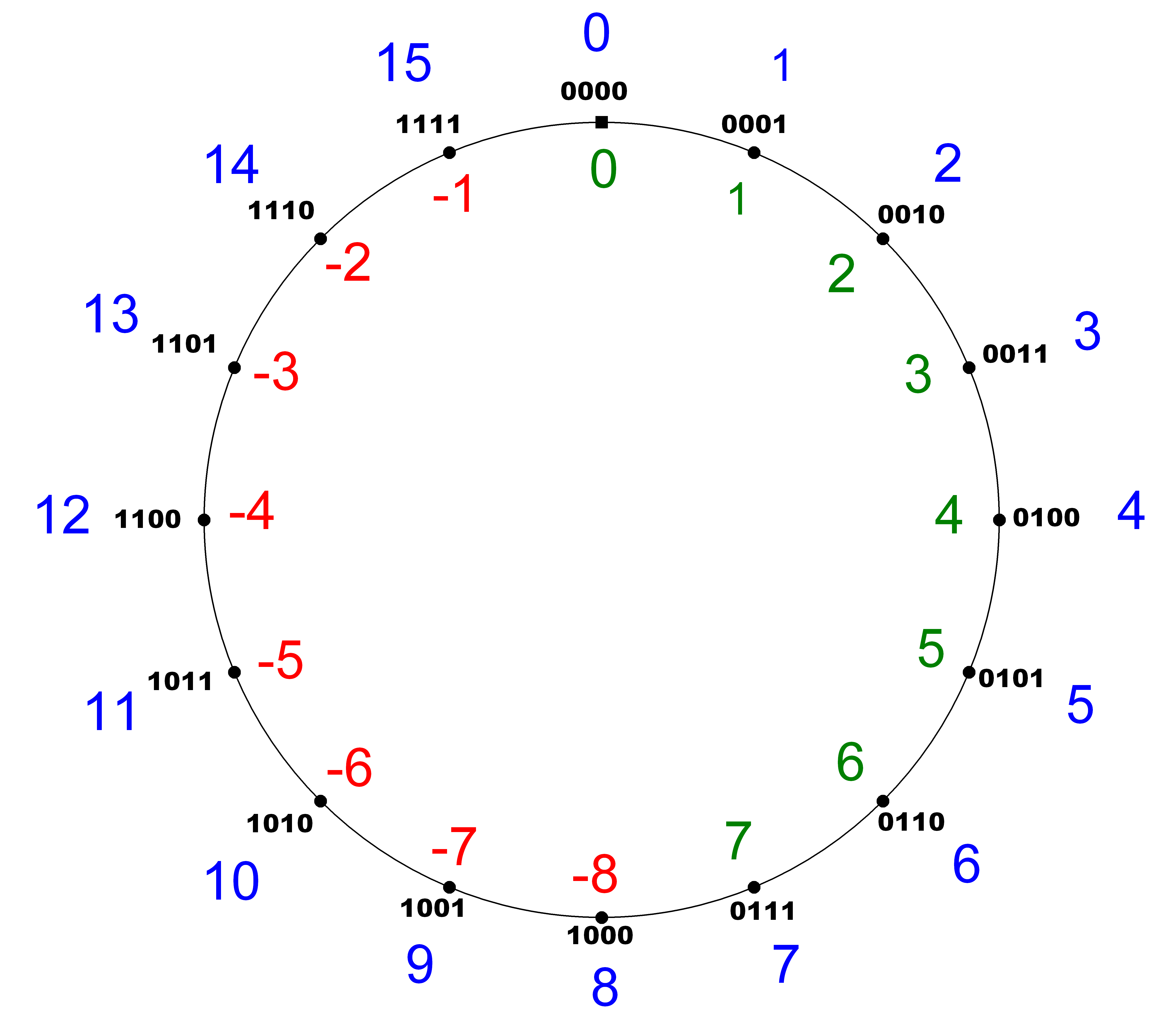
Ich bin gestern noch auf ein paar ältere Unterlagen aus der Uni
gestoßen. Dort wurden anfangs "Zahlenkreise" verwendet um das Thema
Over-/Underflow sichtbar zu machen.
http://www.gk-informatik.de/hw/grafik/zahlkreis_z.png
Die blauen Zahlen außen entsprechen der unsigned Denkweise. Die roten
und grünen Zahlen innen der signed Denkweise.
Der Over und Underflow dürfte also unahängig von signed oder unsigned
gefahrlos ignoriert werden können wenn die folgenden Voraussetzungen
erfüllt sind.
TimerEndwert (unsigned) = TimerAktuell(unsigned) + Delay(unsigned)
Differenz (unsigned) = TimerEndwert(unsigned) - TimerAktuell(unsigned)
oder
TimerEndwert (signed) = TimerAktuell(signed) + Delay(signed)
Differenz (signed) = TimerEndwert(signed) - TimerAktuell(signed)
Sprich solange alle an der Zeitrechnung beteiligten Variablen den selben
Typ (unsigned / signed) und die gleiche Bitweite haben, spielt der
Overflow weder für signed noch unsigned eine Rolle.
Dann noch der Grund wieso ich signed für die Differenzbildung
praktischer finde.
Ich kann mit der signed Rechenweise bei der Differenzbildung auf <= 0
also negative Differenzwerte prüfen. Gleichzeitig habe ich die
"negative" Zeit also die Zeit wie lange der Counter bereits abgelaufen
ist. Hierfüh finde ich ist signed auch die natürliche Denkweise.
Würde ich die Differenzbildung so wie oben auf unsigned durchführen
würde die Differenzbildung nicht mehr sicher funktionieren. Die
Differenz müsste aufjedenfall signed bleiben um negative Werte bei Zeit
bereits abgelaufen aufnehmen zu können. Unsigned hätte ich da nur
positive Werte und könnte einen Ablauf des Timers so nicht mehr
bestimmen.
Würde man Den Timer auf Unsigned laufen lassen und lediglich die
Differenzvariablen Signed ausführen, dann wäre das ganze nicht mehr
Überlaufsicher, da die maximal mögliche Zeitdifferenz bei unsigned ja
doppelt so groß ist wie bei signed.
Dann noch zur Frage wieso der Delay parameter signed ist obwohl negative
Delaywerte nicht der menschlichen Denkweise entsprechen und somit
unsinnig sind. Das Problem dabei ist das selbe wie im Absatz hier drüber
nur andersherum. Wäre der Delay parameter unsigned aber die komplette
interne Rechnung signed, dann ließe sich ein zu großer Delaywert
übergeben, da der Parameter eine größere positive weite hätte als die
Rechenvariablen.
Oder nochmal kurz zusammengefasst solange alles an der Rechnung
konsequent signed mit identischer Bitweite oder unsigned mit identischer
Bitweite ist kann man sicher sein das die komplette Rechnung in sich
Überlaufsicher ist.
Da negative Differenzen so nur mit unsigned möglich ist finde ich
unsigned für die komplette Rechnung am praktischsten.
Kann jemand bestätigen/dementieren ob die Ausführung so schlüssig ist ?
Ich hätte bei der Geschichte wirkoich gerne die Sicherheit zu wissen was
ich da tue, bevor später schwer debugbare und sporadische Fehler
auftreten.
HeaderFile schrieb:> Oder nochmal kurz zusammengefasst
Der C-Standard definiert signed-overflow als "undefined behaviour". Das
bedeutet, es kann alles passieren, und alles ist erlaubt.
Und ja, gcc nutzt daß aus, und erzeugt im Falle eines Falles Code, der
garantiert nicht das macht, was du erwartest. Der darf das, wegen
"undefined behaviour". Da gabs erst letztens hier einen nettes Beispiel
dazu.
Also egal, ob kurz oder lang:
NUR unsigned-Datentypen haben ein definiertes overflow-Verhalten. Ob das
jetzt jemand gut oder schlecht findet, spielt keine Rolle.
Oliver
Oliver schrieb:> Und ja, gcc nutzt daß aus, und erzeugt im Falle eines Falles Code, der> garantiert nicht das macht, was du erwartest.
Was macht denn der gcc bei einem signed Überlauf? Würd mich mal
interessieren, dachte eigentlich der läuft so über "wie erwartet" (tm).
Oder fliegen mir Dämonen aus der Nase? :-)
Okay das war mir nicht bewusst. Ich ging bisher immer fest davon aus das
im C Standard das Overflowverhalten für signed genauso fest definiert
wurde wie für unsigned.
Hat jemand zufällig eine Idee wie ich meinen Code von oben so umbauen
könnte das er unsigned arbeitet und ich dennoch eine differenz bestimmen
kann die mein gewolltes verhalten hat, sprich eine negative differenz
bilden kann um sehen zu können wie lange ein timer schon abgelaufen ist
?
Und dann noch eine zu dem von Fabian geposteten code.
1
/* Note: Can not return diff >= t->interval so we add 1 to diff and return
2
t->interval < diff - required to avoid an internal error in mspgcc. */
3
clock_time_tdiff=(clock_time()-t->start)+1;
4
returnt->interval<diff;
Bezieht sich der obige Hinweis nur auf ein Eigenverhalten des mspgcc ?
Oder anders gefragt kann ich unter dem gcc problemlos folgendes
schreiben:
{kind=link}