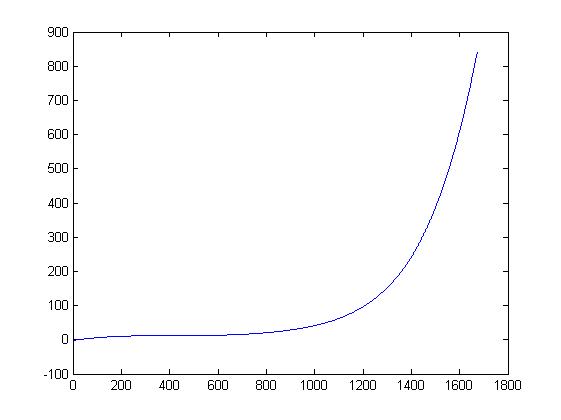
Hallo Zusammen, wusste jetzt nicht in welches Forum ich das hier posten soll. Un zwar habe ich folgendes Problem: Bei meiner Spannungsmesschaltung ergibt sich die im Anhang gezeigte Abweichung von den erwarteten Werten. Habe die Messreihe in Matlab eingetragen und mir dann die angenäherte Funktion ausgeben lassen. Die Funktion war folgende: p1 = 2.2106e-16; p2 = -5.7979e-13; p3 = 5.0961e-10; p4 = 9.9141e-09; p5 = -0.00021778; p6 = 0.10003; p7 = -1.7941; y = p1*x.^6 + p2*x.^5 + p3*x.^4 + p4*x.^3 + p5*x.^2 + p6*x + p7; Nun wollte ich die Formel in C umsetzen: float offset = 2.2106*10e-16*x^6 - 5.7979*10e-13*x^5 + 5.0961*10e-10*x^4 + 9.9141*10e-09*x^3 - 0.00021778*x^2 + 0.10003*x -1.7941; Es kommen in C aber falsche Werte raus und ich kann nicht nachvollziehen, wieso. Kann mir da evtl jemand weiterhelfen? Schonmal danke :) Grüße, dersoldi
Angehängte Dateien:
-

OFFSET.jpg
16 KB
Vielleicht weil ^ eher relativ impotent ist ;) Also ^ ist der XOR-Operator und nicht die Potenz :P
Detlef hat es bereits geschrieben: ^ ist in C kein Potenzierungsoperator; dazu benötigst Du die Funktion pow. Außerdem ist Deine Exponentialdarstellung nicht korrekt 2.2106*10e-16*x^6 wird zu 2.2106e-16 * pow(x, 6) Um pow nutzen zu können, musst Du noch math.h einbinden.
M. S. schrieb: > float offset = 2.2106*10e-16 "float" und Faktoren von 1E-16 passen nicht zusammen. "float" hat normalerweise nur 6...7 Dezimalstellen Genauigkeit. Selbst "double" bringt es nur auf 14 Stellen. 10E-16 ist was anderes als 1E-16. Wenn du 2.2106*10^-16 meinst, solltest du 2.2106E-16 schreiben.
Jörg Wunsch schrieb: > "float" und Faktoren von 1E-16 passen nicht zusammen. "float" hat > normalerweise nur 6...7 Dezimalstellen Genauigkeit. Selbst "double" > bringt es nur auf 14 Stellen. Das verstehe ich jetzt nicht. Es ist doch gerade der Sinn von Floating-Point, Zahlenwerte im Bereich vieler Größenordnungen darstellen zu können. Bei Fixed-Point mit 7 Nachkommastellen wäre die Sache problematisch, aber darum geht es hier ja nicht. Auch wenn das Ergebnis in eine FLoat-Variable gespeichert wir, erfolgt die Berechnung des ganzen Ausdrucks trotzdem in Double, so dass man innerhalb des angegebenen Wertebereichs wahrscheinlich auch nicht mit großen Auslöschungsfehlern zu rechnen hat. Man könnte allenfalls die Berechnung der vielen Potenzen einsparen, indem man den Term nach dem Horner-Schema umformt:
1 | y = ((((((2.2106e-16) |
2 | * x - 5.7979e-13) |
3 | * x + 5.0961e-10) |
4 | * x + 9.9141e-09) |
5 | * x - 2.1778e-04) |
6 | * x + 1.0003e-01) |
7 | * x - 1.7941e-00; |
Man muss dann auch den Unterschied zwischen pow und ^ nicht kennen ;-)
Yalu X. schrieb: > Jörg Wunsch schrieb: >> "float" und Faktoren von 1E-16 passen nicht zusammen. "float" hat >> normalerweise nur 6...7 Dezimalstellen Genauigkeit. Selbst "double" >> bringt es nur auf 14 Stellen. > > Das verstehe ich jetzt nicht. Es ist doch gerade der Sinn von > Floating-Point, Zahlenwerte im Bereich vieler Größenordnungen darstellen > zu können. Bei Fixed-Point mit 7 Nachkommastellen wäre die Sache > problematisch, aber darum geht es hier ja nicht. Schon, aber wenn man einen Koeffizienten p1 in der Größenordnung von 1e-16 nimmt und dann p7=-1,8 dazuaddiert, dann dürfte für (relativ) kleine x (x < 100 oder so) ziemlich viel absorbiert werden...
Cool, schonmal vielen Dank für die Hilfe, werds heute abend mal asuprobieren :) mir wurde gelernt, dass potenzen auch mit dem ^ gehen^^ welchen datentyp sollte ich dann statt float verwenden? sind solch kleine zahlen in c überhaupt möglich?
M. S. schrieb: > mir wurde gelernt, dass potenzen auch mit dem ^ gehen^^ Es gibt Programmiersprachen, in denen das so ist. C/C++ gehören nicht dazu. M. S. schrieb: > welchen datentyp sollte ich dann statt float verwenden? double.
M. S. schrieb: > Cool, schonmal vielen Dank für die Hilfe, werds heute abend mal > asuprobieren :) > mir wurde gelernt, dass potenzen auch mit dem ^ gehen^^ Dann solltest du deinen Lehrer mal drauf ansprechen. > welchen datentyp sollte ich dann statt float verwenden? sind solch > kleine zahlen in c überhaupt möglich? Freilich sind die möglich. Ein 'double' deckt üblicherweise einen Zahlenbereich von irgendwas zwischen 1e-300 bis 1e+300 ab. Aber dabei werden nur etwa 16 dezimale Stellen der Zahl gespeichert. Das heißt, mit einem 'double' kannst du sowohl p1=2.2106e-16 als auch p7=-1.7941 hinreichend genau verrechnen. Nur wenn du nun beispielsweise p1 und p7 addierst, dann musst du dich entscheiden, welche 16 Stellen du behalten möchtest. Einfacheres Beispiel. Angenommen, du speicherst genau drei Stellen plus Exponent:
1 | x = 0.00000001 wird gespeichert als 1.00 e -8, |
2 | y = 1.5 wird gespeichert als 1.50 e 0. |
Wenn du nun x und y addieren möchtest, wird dein Ergebnis wieder aus drei Stellen plus Exponent bestehen. Du kannst dir wieder aussuchen, welche drei Stellen das sein sollen. Den kleineren Fehler erhältst du aber, wenn du die Stelle vor dem Komma und zwei Nachkommastellen nimmst. Das bedeutet aber auch, das die Addition praktisch hinfällig ist, denn der Summand 'X' taucht da garnicht auf. Er wird absorbiert, weil er zu klein ist. Das bedeutet weiterhin, dass bei Gleitkommarechnungen die Kommutativität nicht mehr überall gegeben ist.
Yalu X. schrieb: > Das verstehe ich jetzt nicht. Es ist doch gerade der Sinn von > Floating-Point, Zahlenwerte im Bereich vieler Größenordnungen darstellen > zu können. Bei Fixed-Point mit 7 Nachkommastellen wäre die Sache > problematisch Im Prinzip natürlich schon. Aber wenn der letzte Koeffizient im Bereich 1E-1 ist, dann hat der 1E16-Koeffizient schon bei x im Bereich 1 keinen Einfluss mehr. Gut, für große x sieht das natürlich anders aus, so gesehen kann man das vielleicht stehen lassen. Mir ist noch dunkel in Erinnerung, dass das Horner-Schema für die maschinelle Berechnung von Polynomen die sinnvollere Wahl ist. Dann spart man sich auch den Salat mit dem umständlichen pow(). Die Details müsste ich mir aber auch in meinem Mathe-Hefter aus dem Studium wieder ansehen :) (oder im Wikipedia halt).
Jörg Wunsch schrieb: > Mir ist noch dunkel in Erinnerung, dass das Horner-Schema für die > maschinelle Berechnung von Polynomen die sinnvollere Wahl ist. Das dürfte erheblich schneller und genauer sein, da pow() auch Kommazahlen als Potenzen erlaubt. Vermutlich rechnet pow() erstmal den Logarithmus aus und nach der Multiplikation wieder zurück.
Jörg Wunsch schrieb: > Mir ist noch dunkel in Erinnerung, dass das Horner-Schema für die > maschinelle Berechnung von Polynomen die sinnvollere Wahl ist. Dann > spart man sich auch den Salat mit dem umständlichen pow(). Die Details > müsste ich mir aber auch in meinem Mathe-Hefter aus dem Studium wieder > ansehen :) Das ist nicht weiter dramatisch. Man klammert nur sukzessive die freie Variable aus. Z.B. a*x^3 + b*x^2 + c*x + d = d + c*x + b*x^2 + a*x^3 (Reihenfolge umgedreht, wird verständlicher) = d + x(c + b*x + a*x^2) (das 1. Mal x ausgeklammert) = d + x(c + x(b + a*x)) (das 2. Mal x ausgeklammert) = d + x(c + x(b + x(a))) (letztes Mal ausklammern, der Form halber) Wenn man das jetzt von innen nach außen ausrechnet, hat man genau das Horner-Schema. Das ist dann nicht nur arithmetisch stabil, sondern auch die Variante mit den wenigsten Operationen. Was das gefittete Polynom des TE angeht: ich würde schätzen, daß er genau genug wegkommt, wenn er einfach p1 .. p4 = 0 setzt. Kann man auch einfach überprüfen, indem man Matlab die Differenz der beiden Polynome ausrechnen läßt und die Abweichung mit seiner eigenen Meßgenauigkeit für die Stützstellen vergleicht. Im allgemeinen versucht man auch nicht, seine Stützstellen exakt zu fitten, sondern sucht gezielt ein Polynom kleinerer Ordnung mit minimalem Fehler (Methode der kleinsten Quadrate, Regression) XL
Was ist der physikalische Sinn dahinter? Wofür braucht man eine Spannungsmessung mit 16*6=96 Stellen hinter dem Komma? Mich erinnert das daran, dass man z.B. bei der Umrechnung von Meilen in Kilometer lustig viele Nachkommastellen angeben kann, ohne daran zu denken, dass man schon in subatomaren Gefilden angelangt ist... Heute ist mir nach Zitaten zumute: Der Mangel an mathematischer Bildung gibt sich durch nichts so auffallend zu erkennen wie durch maßlose Schärfe im Zahlenrechnen. Carl Friedrich Gauß.
So bald man einen Akkumulator benötigt kann das schon interessant werden.
Angehängte Dateien:
-

absoluter-fehler.png
14 KB -

relativer-fehler.png
18 KB -

abs-bez-auf-messwert.png
14 KB
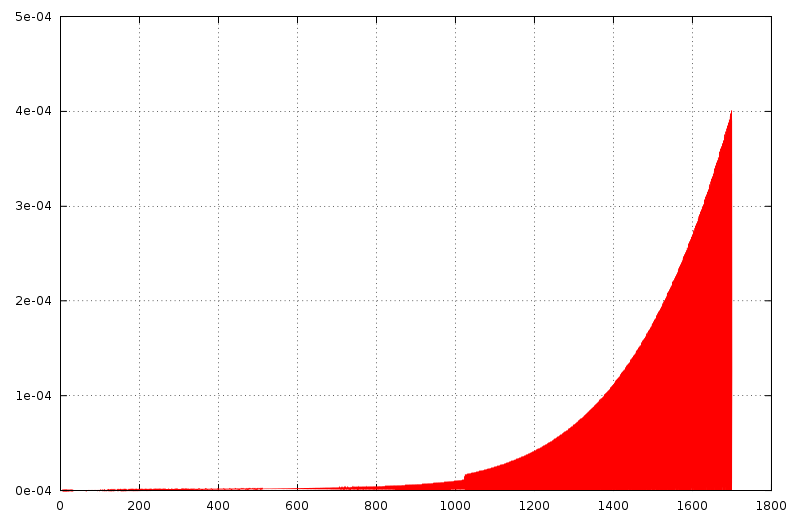
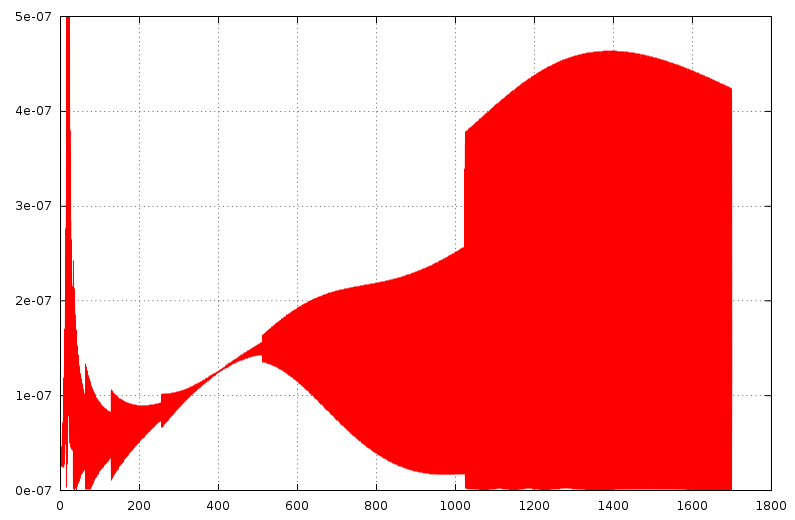
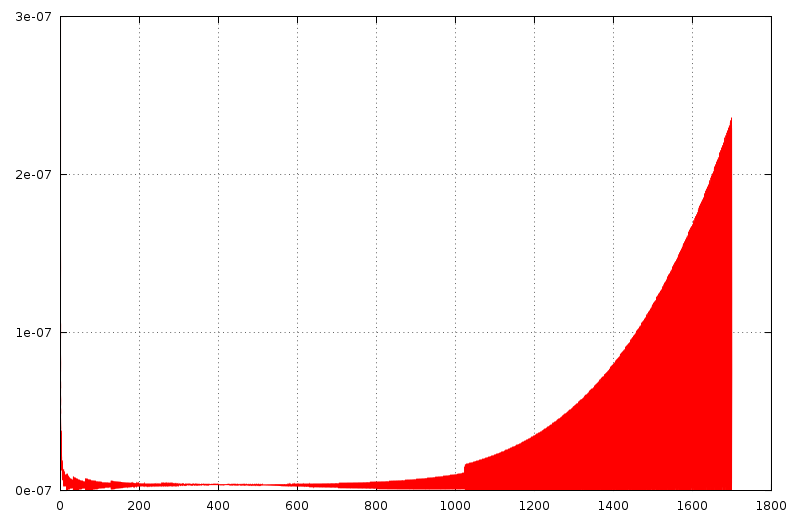
Ich habe mal den betragsmäßigen absoluten und relativen Fehler der Auswertung des Polynoms in Float bezogen auf die Auswertung in Double bestimmt. Der maximale absolute Fehler beträgt etwa 4.0E-4 und liegt innerhalb der Erwartungen, da der Funktionswert in diesem Bereich bei etwa 950 liegt (1. Diagramm). Der maximale relative Fehler beträgt für x<15 und x>21 etwa 4.6E-7. Auch das liegt im Bereich der Erwartungen. Nur im Bereich zwischen 15 und 21 steigt der relative Fehler stark an. Das liegt adaran, dass die Funktion bei x≈18.7 eine Nullstelle hat, an der schon die kleinste Abweichung den relativen Fehler unendlich werden lässt (2. Diagramm). Da nach Aussage des TE die Kurve nicht die Messwerte selbst, sondern deren Abweichung von den erwarteten Werte beschreibt, sollte die Genauigkeit der Berechnung auf die Messgröße bezogen werden. Ich nehme an, dass die x-Werte im Diagramm des TE die erwarteten Messwerte sind. Dann beträgt der durch die Rechenungenauigkeit verursachte relative Fehler im korrigierten Messwert maximal 2.4E-7 (3. Diagramm). Das ist der Wert, auf den es letztendlich ankommt. Und da es sich hier um keine ultrapräzise Messung zu handeln scheint, kann dieser Fehler problemlos vernachlässigt werden. Da aber, wie ich oben schon geschrieben habe, in C sowieso alle Floating-Point-Berechnungen in Double ausgeführt werden (für den Test habe ich deswegen jede Teiloperation explizit nach Float gecastet), wird der Fehler praktisch nur durch die Zuweisung des Ergebnisses an eine FLoat-Variable verursacht. Auf einem PC mit seinem großen Hauptspeicher ist es aber nur in den seltensten Fällen sinnvoll, Float anstelle von Double zu verwenden. Verwendet man Double, wird der Fehler noch einmal um mehrere Größenordnungen verkleinert. Peter Dannegger schrieb: > Vermutlich rechnet pow() erstmal den Logarithmus aus und nach der > Multiplikation wieder zurück. Ganz so schlimm ist es nicht: Die gängigen Implementationen von pow prüfen den Exponent auf Ganzzahligkeit und berechnen ggf. die Potenz als eine Serie von Multiplikationen, deren Anzahl in etwa dem Zweierlogarithmus des Betrags des Exponenten entspricht. Trotzdem ist die Gesamtzahl der für die Berechnung des Polynoms auszuführenden Multiplikationen immer noch deutlich größer als bei der Verwendung des Horner-Schemas. Es könnte höchstens sein, das der GCC durch die Built-In-Matheoperationen da noch etwas optimiert. Edit: Hab gerade nachgeschaut, wie der GCC (4.8.1) pow-Aufrufe optimiert: Ist der Exponent -1, 0, 1 oder 2, wird pow nicht aufgerufen, sondern stattdessen direkt eine Multiplikation, Division oder gar nichts ausgeführt. Bei allen anderen Potenzen wird pow aufgerufen, auch wenn sie Teil eines Polynoms sind und deswegen optimiert werden könnten. Vielleicht passiert das ja in GCC 5 ;-)
ernst oellers schrieb: > Der Mangel an mathematischer Bildung gibt sich durch nichts so > auffallend zu erkennen wie durch maßlose Schärfe im Zahlenrechnen. Carl > Friedrich Gauß. Interessant. Und ich dachte immer, dieses Übel wäre erst im Zeitalter der ersten Taschenrechner aufgekommen, weil man vorher schlicht und ergreifend zu faul war, um x sinnlose Nachkommastellen mit der Hand auszurechnen.
Karl Heinz schrieb: >> Der Mangel an mathematischer Bildung gibt sich durch nichts so >> auffallend zu erkennen wie durch maßlose Schärfe im Zahlenrechnen. Carl >> Friedrich Gauß. > > Interessant. > Und ich dachte immer, dieses Übel wäre erst im Zeitalter der ersten > Taschenrechner aufgekommen, weil man vorher schlicht und ergreifend zu > faul war, um x sinnlose Nachkommastellen mit der Hand auszurechnen. Vielleicht dachte Gauß dabei auch an den zwei Jahrhunderte früher lebenden Ludolph van Ceulen, der 30 Jahre seines Lebens damit verbracht hatte, die Zahl π auf 35 Nachkommastellen genau zu auszurechnen. Ohne Taschenrechner, versteht sich :) http://de.wikipedia.org/wiki/Ludolph_van_Ceulen
Zahlenformat "long double" mit 19 Stellen geht nicht ? http://www-user.uni-bremen.de/~wboeck/script.htm/einfhrg/einfhr08.htm
U. B. schrieb: > Zahlenformat "long double" mit 19 Stellen geht nicht ? "long double" kann alles Mögliche sein. Je nach Architektur und Compiler also auch nur 64 Bit.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.