Hallo leute,
ich möchte gerne mit vier sensoren am PORTA (PA0 bis PA4) rechnen.
also sensor1 = 1, sensor2 = 2 usw.
1
....
2
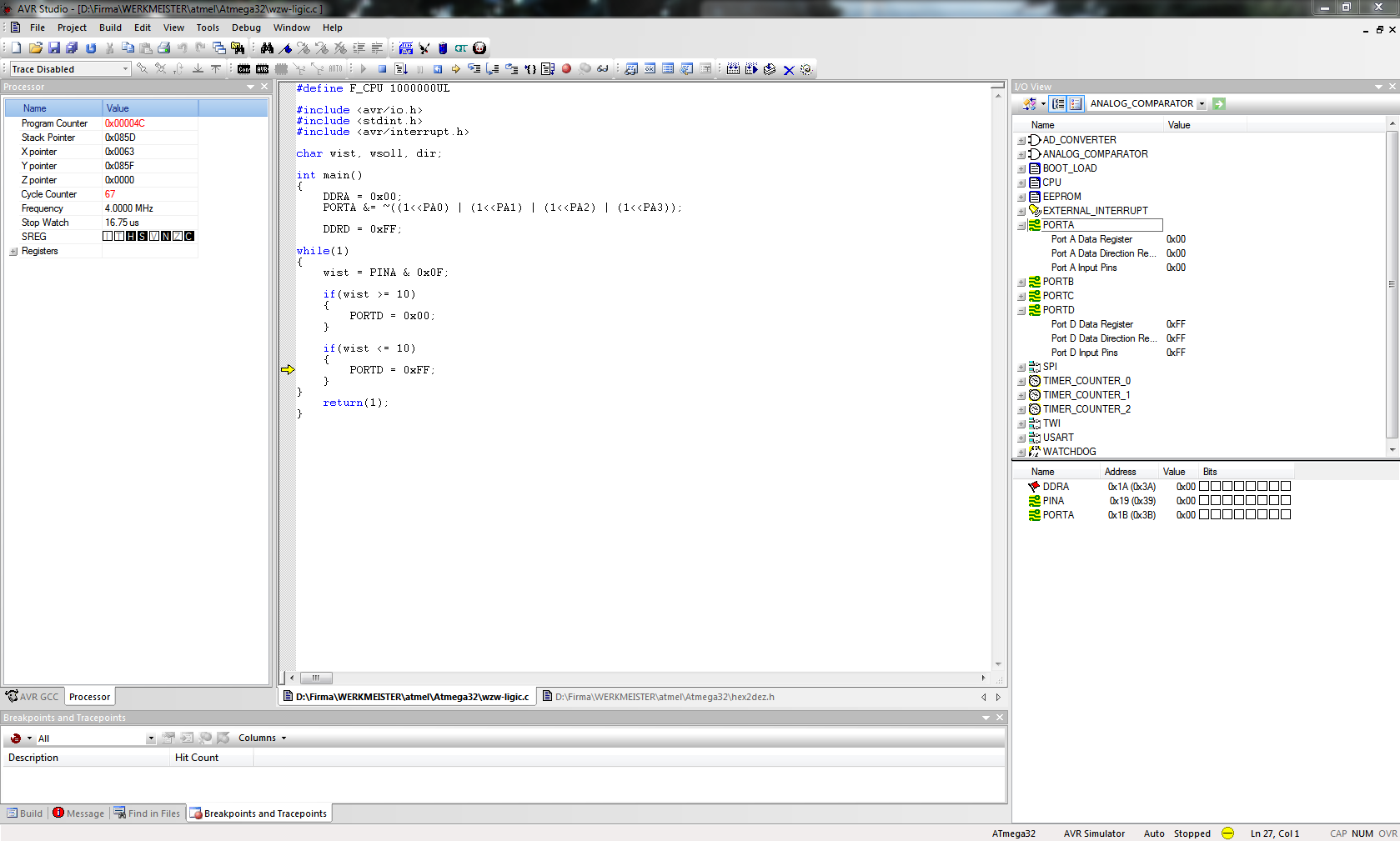
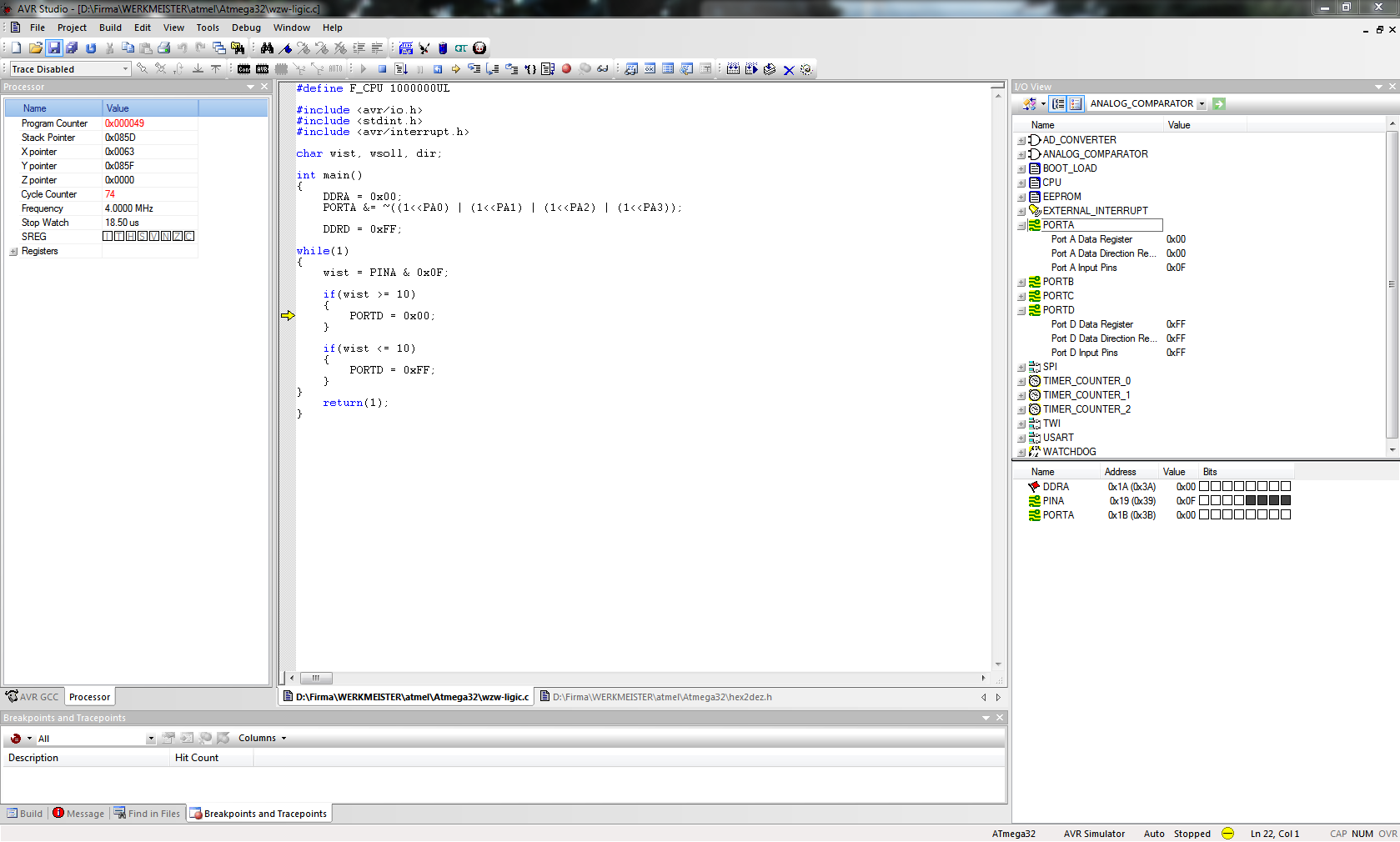
wist=PORTA;
3
4
dir=wist-wsoll
5
6
if(wist>=10)
7
{
8
PORTD=0x00;
9
}
10
11
if(wist<=10)
12
{
13
PORTD=0xFF;
14
}
15
....
habe im inet schon gesucht und sowas änliches gefunden. der code
funktioniert in der simulation aber praktisch nicht =(
ich hoffe mir kann da jemand helfen. danke
D. Kirschner schrieb:> wist = PORTA;
Was glaubst du denn, was es über PORTA einzulesen gäbe? Ganz sicher
jedenfalls nicht den Status der Sensoren.
Versuch's mal mit PINA...
D. Kirschner schrieb:> hab einen code gefunden und leut einem forum soll es gehn
link bitte, sonst glaub ich das nicht.
Der Code ist auch wenn er nicht für den AVR sein soll, einfach nur Müll.
also ich möchte mit den sensoren die position auslesen. (0x01 = 1, 0x02
= 2, usw.)
wenn "wist" größer ist als 10 dann sollen die leds nicht leuchten und
wenn "wist" kleiner ist als 10 dann sollen alle leuchten.
mit der formel "dir = wist - wsoll" möchte ich gerne die richtung von
einem werkzeugwechler (20 werkzeuge) bestimmen (ob er sich links oder
rechts dreht für den schnellsten weg). aber da ich jetzt noch nicht mal
die leds zum leuchten bringe muss da noch warten.
habs auch mit PINA versucht und es klappt leider auch nicht =(
Hi
>ich möchte gerne mit vier sensoren
Was für Sensoren?
>am PORTA (PA0 bis PA4) rechnen. also sensor1 = 1, sensor2 = 2 usw.
PA0...PA4 sind aber 5 Pins.
MfG spess
Zeig' uns am besten mal eine vollständigen, kleinen Code der
kompilierbar ist und gleichzeitig das Problem aufweist - also im
Simulator geht aber nicht auf dem uC. Dann brauchen wir nicht jedes
Detail einzeln von Dir zu erfragen.
Bitflüsterer schrieb:> Zeig' uns am besten mal eine vollständigen, kleinen Code der> kompilierbar ist und gleichzeitig das Problem aufweist
ja. Das wäre am Besten.
> ... der code funktioniert in der simulation aber praktisch nicht =(
Nun, ein Problem ist im Code nicht erkennbar.
Und was funktioniert nun praktisch nicht?
Genauer: Was erwartest Du und was geschieht tatsächlich?
Zeige uns auch mal Deine Schaltung und mache ein Foto vom Aufbau.
Jetzt widersprechen sich zwei Antworten von mir und Hans.
Meiner Ansicht nach, wird hier mit Werten gerechnet, aber keine
Zeichenmanipulation gemacht. Deswegen sollten die Werte integers sein.
Hans schrieb:> Bitflüsterer schrieb:>> Werte bitte int und nicht char>> Nee, PINA ist ein unsigned char.
Das ist hier unwichtig. Wichtig ist vielmehr in welcher Weise die Werte
nach dem Einlesen interpretiert werden. Da mit integers verglichen wird,
sollten die Variablen auch integers sein.
Bitflüsterer schrieb:> Jetzt widersprechen sich zwei Antworten von mir und Hans.>> Meiner Ansicht nach, wird hier mit Werten gerechnet, aber keine> Zeichenmanipulation gemacht. Deswegen sollten die Werte integers sein.
von mir aus kann er das auch machen, aber PINA hat eben nur 8-Bit. Wenn
er unbedingt "int" nehmen soll, dann auch dort "unsigned". Wobei das
sign-bit hier abgeschnitten wird, da bei 8-15 keine "1" stehen können.
Aber es ist einfach Verschwendung eine 16-Bit variable für ein
8-Bit-Register zu verwenden.
>> ist je nach Lvalue ein Int oder ein char.
Wo hat der TO das geschrieben? Ein Versehen beim kopieren?
Jedenfalls ist das Problem, denke ich, eines von signed/unsigned.
Wenn man eine kleine Variable verwenden will, dann eben unsigned short
int aber auf keinen Fall char, meine ich.
weis auch jemand wie man einen port aufteilen kann?
also vier eingänge (PA0 bis PA3) und vier eingänge (PA4 bis PA7)
auslessen
kann man das so machen:
i = PINA & 0b00001111;
k = PINA & 0b11110000;
also so das k 1 bis 4 ist und i auch
Bitlfüsterer schrieb:> Wenn man eine kleine Variable verwenden will, dann eben unsigned short> int aber auf keinen Fall char, meine ich.
Hm... jetzt ist aber eine Diskussion angebrochen. Ich vermute, Du kommst
aus der PC-Programmierung. Ein char ist einfach ein 8-Bit-Variable. Wenn
Du Dich durch die Header-Dateien gräbst, dann wirst Du sehen, dass
jedenfalls bei den AVRs sehr wohl unsigned char verwendet wird. Der
Compiler sieht in einem char einfach eine 8-Bit variable. Mit Strings
hat das nicht unbedingt was zu tun.
D. Kirschner schrieb:> weis auch jemand wie man einen port aufteilen kann?>> also vier eingänge (PA0 bis PA3) und vier eingänge (PA4 bis PA7)> auslessen>> kann man das so machen:>> i = PINA & 0b00001111;> k = PINA & 0b11110000;>> also so das k 1 bis 4 ist und i auch
Nein, dann so:
Bist Du Dir sicher, dass Du weist, was Du tust?
Eine Abfrage von Schaltern mittels XXX < YYY
ist außer in Sonderfällen, oder wenn man genau weis was man tut, Unsinn.
Im binären Bereich sollte man von vornherein mit unsigned Variablen
arbeiten.
Allerdings bin ich mir immer noch nicht darüber im Klaren, was Du
überhaupt vorhast. U. A. scheint das Erklären nicht zu Deinen Stärken
zu gehören.
Hans schrieb:> Bitlfüsterer schrieb:>> Wenn man eine kleine Variable verwenden will, dann eben unsigned short>> int aber auf keinen Fall char, meine ich.>> Hm... jetzt ist aber eine Diskussion angebrochen. Ich vermute, Du kommst> aus der PC-Programmierung.
Nein. Durchaus nicht. Programmiere ziemlich lange (jahrzehntelang) auch
uCs.
> Ein char ist einfach ein 8-Bit-Variable. Wenn> Du Dich durch die Header-Dateien gräbst, dann wirst Du sehen, dass> jedenfalls bei den AVRs sehr wohl unsigned char verwendet wird.
Es ist unstrittig, dass man das machen kann und das es auch
funktioniert. Dennoch ist das Argument plausibel, dass char, wie schon
das Wort sagt "Zeichen" bedeutet.
Daraus folgt, dass ein Wert der als Zahl verwendet wird eben auch als
int deklariert werden sollte. Das es viele anders machen ist meiner
Ansicht nach kein ebenso plausibles Gegenargument.
> Compiler sieht in einem char einfach eine 8-Bit variable. Mit Strings> hat das nicht unbedingt was zu tun.
Von Strings habe ich auch nichts gesagt. :-) (Schon der zweite Fall, das
Du behauptest etwas sei geschrieben worden, was nicht geschrieben
wurde).
Bitflüsterer schrieb:> Es ist unstrittig, dass man das machen kann und das es auch> funktioniert. Dennoch ist das Argument plausibel, dass char, wie schon> das Wort sagt "Zeichen" bedeutet.> Daraus folgt, dass ein Wert der als Zahl verwendet wird eben auch als> int deklariert werden sollte. Das es viele anders machen ist meiner> Ansicht nach kein ebenso plausibles Gegenargument.
Wenn Du die Plattform wechselst, dann bleibt ein unsigned char immer
noch 8-Bit. Ein int oder ein short int kann dort durch aus größer sein
als 16 bzw. 8 bit. Alleine für die Portierbarkeit sollte man bei
8-Bit-Variablen bleiben, wenn solche gemeint sind.
Bitflüsterer schrieb:> Von Strings habe ich auch nichts gesagt. :-) (Schon der zweite Fall, das> Du behauptest etwas sei geschrieben worden, was nicht geschrieben> wurde).
das hier:
Bitflüsterer schrieb:> Meiner Ansicht nach, wird hier mit Werten gerechnet, aber keine> Zeichenmanipulation gemacht.
hatte mich an Zeichketten/Strings denken lassen.
Aber Hans, lassen wir das. Das ist eine Meinungsfrage und nicht
entscheidend.
Was mich viel mehr irritiert, ist das es auf dem Chip mit unsigned char
geht und mit char nicht und das es in der Simulation mit beidem geht.
Da das Vorzeichen ja in PINA nicht gesetzt sein sollte, dürfte signed
unsigned garkeine Rolle spielen.
Hans schrieb:> Bitflüsterer schrieb:>> Es ist unstrittig, dass man das machen kann und das es auch>> funktioniert. Dennoch ist das Argument plausibel, dass char, wie schon>> das Wort sagt "Zeichen" bedeutet.>> Daraus folgt, dass ein Wert der als Zahl verwendet wird eben auch als>> int deklariert werden sollte. Das es viele anders machen ist meiner>> Ansicht nach kein ebenso plausibles Gegenargument.>> Wenn Du die Plattform wechselst, dann bleibt ein unsigned char immer> noch 8-Bit. Ein int oder ein short int kann dort durch aus größer sein> als 16 bzw. 8 bit. Alleine für die Portierbarkeit sollte man bei> 8-Bit-Variablen bleiben, wenn solche gemeint sind.
Sicher. Deswegen verwenden wir :-) ja auch nicht char sondern uint8_t.
Bitflüsterer schrieb:> Was mich viel mehr irritiert, ist das es auf dem Chip mit unsigned char> geht und mit char nicht und das es in der Simulation mit beidem geht.
Man weiß ja nicht, was an den Pins A4-A7 hängt. Wenn A7 immer high ist
;) dann kann bei einem signed char immer nur eine negative Zahl raus
kommen. Da wir die Schaltung nicht kennen, habe ich einfach geraten.
Hans schrieb:> Man weiß ja nicht, was an den Pins A4-A7 hängt. Wenn A7 immer high ist> ;) dann kann bei einem signed char immer nur eine negative Zahl raus> kommen. Da wir die Schaltung nicht kennen, habe ich einfach geraten.
Dieses mal glaube ich, dass ich da Quatsch geschrieben habe, da ja
ausmaskiert wird. Vielleicht wissen die Profis, wie Karl Heinz Buchegger
oder Jörg Wunsch, warum das geholfen hat.
Ich halte mich mal raus und duck mich weg
Hans schrieb:> Bitflüsterer schrieb:>> Sicher. Deswegen verwenden wir :-) ja auch nicht char sondern uint8_t.>> uint8_t ist folgendermaßen definiert:>>
1
typedef unsigned char uint8_t
>> aber ich hör mal auf mit dem Klugscheißern ;)
Das mag beim AVR-GCC so sein, aber wir haben ja davon gesprochen:
Beitrag "Re: mit eingänge rechnen">> Wenn Du die Plattform wechselst, ...
Hans schrieb:
> Man weiß ja nicht, was an den Pins A4-A7 hängt. Wenn A7 immer high ist> ;) dann kann bei einem signed char immer nur eine negative Zahl raus> kommen. Da wir die Schaltung nicht kennen, habe ich einfach geraten.
Selbst wenn das oberste Bit im Port gesetzt ist, dann sollte doch durch
& 0x1F das oberste Bit im Ergebnis immer 0 sein. Und zwar egal ob es nun
unsigned char oder signed char ist. Es sollte da auch keine Rolle
spielen ob Simulation oder echter Chip. Was meinst Du?
Hans schrieb:> Bitflüsterer schrieb:>> dann sollte doch durch>> & 0x1F das oberste Bit im Ergebnis immer 0 sein>> ja
OK. Wenn wir beide das so sehen und das bedeutet, dass es wirklich so
ist, dann lag ein völlig anderes Problem vor und der TO hat es nicht
gelöst.
Bitflüsterer schrieb:> OK. Wenn wir beide das so sehen und das bedeutet, dass es wirklich so> ist, dann lag ein völlig anderes Problem vor und der TO hat es nicht> gelöst.
ich glaube schon, dass das Problem gelöst ist. Möglicherweise
funktioniert die Bitmanipulation bei signed variablen nicht oder anders.
Bin aber zu faul das jetzt mit dem gcc mal auszuprobieren. Die großen
kommen bestimmt bald vom Sonntagsspaziergang :)
>unsigned char oder signed char...
Bei Bitmanipulationen gibt es kein "signed" oder "unsigned", da diese
Manipulationen eben auf Bitebene passieren.
XXXXXXXX
&00011111
_______
000????? ?: Hier kommt's auf X an
Gruß Jonas
jibi schrieb:> Bei Bitmanipulationen ...
Das ist hier schon geschrieben worden:
Bitflüsterer schrieb:> Selbst wenn das oberste Bit im Port gesetzt ist, dann sollte doch durch> & 0x1F das oberste Bit im Ergebnis immer 0 sein. Und zwar egal ob es nun> unsigned char oder signed char ist.
Bitflüsterer schrieb:> Jetzt widersprechen sich zwei Antworten von mir und Hans.>> Meiner Ansicht nach, wird hier mit Werten gerechnet, aber keine> Zeichenmanipulation gemacht. Deswegen sollten die Werte integers sein.
Der Typ für Text ist char, nicht signed char, nicht unsigned char,
sondern char.
Bitflüsterer schrieb:>> Compiler sieht in einem char einfach eine 8-Bit variable. Mit Strings>> hat das nicht unbedingt was zu tun.>> Von Strings habe ich auch nichts gesagt. :-) (Schon der zweite Fall, das> Du behauptest etwas sei geschrieben worden, was nicht geschrieben> wurde).
Nun, ein String ist halt ein Array aus char. Sonst nutzt C nirgends char
für Text. Für einzelne Zeichen wird in der Regel int benutzt. Schau dir
mal die ganzen Standard-Funktionen an, die mit einzelnen Zeichen
arbeiten, wie z.B. isalpha() oder toupper(). Dort wird als Parameter und
Rückgabetyp für Zeichen nicht etwa char, sondern int verwendet.
Bitflüsterer schrieb:>> uint8_t ist folgendermaßen definiert:>>>> typedef unsigned char uint8_t >>> aber ich hör mal auf mit dem Klugscheißern ;)>> Das mag beim AVR-GCC so sein,
Das muß eigentlich überall so sein, wo es ein uint8_t gibt.
Rolf Magnus schrieb:> Bitflüsterer schrieb:>> Jetzt widersprechen sich zwei Antworten von mir und Hans.>>>> Meiner Ansicht nach, wird hier mit Werten gerechnet, aber keine>> Zeichenmanipulation gemacht. Deswegen sollten die Werte integers sein.>> Der Typ für Text ist char, nicht signed char, nicht unsigned char,> sondern char.
Irrelevant. Das mag so sein, aber ich habe nirgendwo, auch nicht in dem
von Dir zitierten Text, das Gegenteil geschrieben.
> Bitflüsterer schrieb:>>> Compiler sieht in einem char einfach eine 8-Bit variable. Mit Strings>>> hat das nicht unbedingt was zu tun.>>>> Von Strings habe ich auch nichts gesagt. :-) (Schon der zweite Fall, das>> Du behauptest etwas sei geschrieben worden, was nicht geschrieben>> wurde).>> Nun, ein String ist halt ein Array aus char. Sonst nutzt C nirgends char> für Text.
Falsch. Ein einzelnes Zeichen wird als char deklariert. Nicht nur ein
Array von chars. Der Programmierer triftt die Entscheidung, nicht die
Sprache. Deine Aussage widerlegt auch nicht, dass ich nichts von Strings
geschrieben habe.
> Bitflüsterer schrieb:>>> uint8_t ist folgendermaßen definiert:>>>>>> typedef unsigned char uint8_t >>>> aber ich hör mal auf mit dem Klugscheißern ;)>>>> Das mag beim AVR-GCC so sein,>> Das muß eigentlich überall so sein, wo es ein uint8_t gibt.
Falsch. Auf der linken Seite des typedef kann jeder andere bekannte Typ
stehen. Es gibt durchaus auch Systeme in denen ein unsigned char 16 Bit
breit ist. Oder auf was bezieht sich "muß ... so sein"?
jibi schrieb:>>dann sollte doch durch > & 0x1F das oberste Bit im Ergebnis immer 0 sein.>> "sollte" gab mir zu denken übrig
Ach so. Dann bitte ich um Entschuldigung.
Bitflüsterer schrieb:>> Der Typ für Text ist char, nicht signed char, nicht unsigned char,>> sondern char.>> Irrelevant. Das mag so sein, aber ich habe nirgendwo, auch nicht in dem> von Dir zitierten Text, das Gegenteil geschrieben.
Und was meintest du dann damit:
Bitflüsterer schrieb:> Hans schrieb:>> Bitflüsterer schrieb:>>> Werte bitte int und nicht char>>>> Nee, PINA ist ein unsigned char.>> Das ist hier unwichtig.> Wichtig ist vielmehr in welcher Weise die Werte nach dem Einlesen> interpretiert werden. Da mit integers verglichen wird, sollten die> Variablen auch integers sein.
Dann schau mal in die ISO-Norm. char ist dort ein "integer type", ganz
genau wie int. Von den Regeln her unterscheiden die sich nicht, bis
darauf, daß die Mindest-Wertebereich unterschiedlich ist und daß für
char nicht festgelegt ist, ob es ohne entsprechende Angabe signed oder
unsigned ist. Deshalb gibt man, wenn man char für Integers benutzen
will, immer signed oder unsigned mit an.
>> Nun, ein String ist halt ein Array aus char. Sonst nutzt C nirgends char>> für Text.> Falsch.
Lies doch bitte den Rest meines Postings, den du beim Zitieren
unterschlagen hast.
> Ein einzelnes Zeichen wird als char deklariert. Nicht nur ein> Array von chars. Der Programmierer triftt die Entscheidung, nicht die> Sprache.
Klar kann man sich als Programmierer gegen das entscheiden, was die
Sprache vorgesehen hat. Klug ist das meistens allerdings nicht.
>> Bitflüsterer schrieb:>>>> uint8_t ist folgendermaßen definiert:>>>>>>>> typedef unsigned char uint8_t >>>>> aber ich hör mal auf mit dem Klugscheißern ;)>>>>>> Das mag beim AVR-GCC so sein,>>>> Das muß eigentlich überall so sein, wo es ein uint8_t gibt.>> Falsch. Auf der linken Seite des typedef kann jeder andere bekannte Typ> stehen. Es gibt durchaus auch Systeme in denen ein unsigned char 16 Bit> breit ist. Oder auf was bezieht sich "muß ... so sein"?
Es bezieht sich - genau wie ich geschrieben habe - auf Plattformen, bei
denen ein uint8_t überhaupt existiert. Wenn char 16 Bit breit ist, gibt
es schlicht kein uint8_t, denn char ist der kleinstmögliche Typ, da per
Definition sizeof(char)==1.
>Wenn char 16 Bit breit ist, gibt>es schlicht kein uint8_t
Verstehe ich nicht?
Warum sollte es keine vorzeichenlose 8bit breiten Datentypen geben nur
weil chars als Unicode (2byte) definiert sind?
he?
blamaster schrieb:>>Wenn char 16 Bit breit ist, gibt>>es schlicht kein uint8_t>> Verstehe ich nicht?>> Warum sollte es keine vorzeichenlose 8bit breiten Datentypen geben nur> weil chars als Unicode (2byte) definiert sind?
Das hat nichts mit Unicode zu tun. char ist als erstes mal ein
Integer-Typ wie short, int, long und long long auch. Es wird aber auch
für Text verwendet. Außerdem ist char die kleinste einzeln adressierbare
Einheit (byte). Daraus resultiert, daß sizeof(char) 1 ist. Es kann also
keinen kleineren Typ als char geben. char wird daher in der Regel nur
dann 16 Bit breit sein, wenn die Zielplattform mit kleineren Datentypen
nicht umgehen kann. Und genau deshalb wird es dann auch kein uint8_t
geben.
Rolf Magnus schrieb:> Bitflüsterer schrieb:>>> Der Typ für Text ist ...>> Irrelevant. ...> Und was meintest du dann damit:>>> Bitflüsterer schrieb:>>>> Werte bitte int und nicht char>>> Nee, PINA ist ein unsigned char.>> Das ist hier unwichtig.
Das es unwichtig sei, weil es ohnehin darum ging, mit dem Wert zu
rechnen resp. ihn mit der "<=" Operation zu vergleichen. Das ist aber
erstmal völlig unabhängig von Frage signed oder unsigned, sondern
bezieht sich auf char oder short.
>> Wichtig ist vielmehr ...> Dann schau mal in die ISO-Norm. char ist dort ein "integer type", ...
Da ich ja selbst ein Erbsenzähler bin, muss ich Dir leider recht geben.
:-{ Ich bezog mich mit "integer" auf den Typ int und nicht auf die
Terminologie in der Norm. Insofern war meine Ausdrucksweise unklar.
Um aber Mißverständnissen vorzubeugen, möchte ich betonen, das char
meiner Ansicht nach nicht für Werte verwendet werden sollte, die als
Zahlen interpretiert werden (wie das z.B. mit einem kleiner-Vergleich
geschieht).
Ich meine mich da in guter Gesellschaft mit Karl Heinz B. zu befinden,
mag aber in diesem Fall seine Aussagen falsch interpretieren.
Rolf Magnus schrieb:
>>> Nun, ein String ist halt ein Array aus char. Sonst nutzt C nirgends char>>> für Text.>> Falsch.>> Lies doch bitte den Rest meines Postings, den du beim Zitieren> unterschlagen hast.
Ich versichere Dir: Es war nicht meine Absicht, eine meiner Ansicht
widersprechende Aussage zu unterschlagen. Deinem nachfolgenden Text
betreffs itoa, atoi etc. wollte ich nicht widersprechen. Deswegen habe
ich ihn nicht zitiert. Er enthält aber meiner Ansicht nach nichts, was
Deine Aussage irgendwie unterstützt.
Es ging darum, das Deine Aussage impliziert das char anders als in
arrays für Zeichen nicht verwendet wird. Und das halte ich für falsch.
Deswegen auch das hier nachfolgende von mir, das Du zitiert hast.
Rolf Magnus schrieb:
>> Ein einzelnes Zeichen wird als char deklariert. Nicht nur ein>> Array von chars. Der Programmierer triftt die Entscheidung, nicht die>> Sprache.>> Klar kann man sich als Programmierer gegen das entscheiden, was die> Sprache vorgesehen hat. Klug ist das meistens allerdings nicht.
Das möchte ich im Zusammenhang verstanden wissen: Du schriebst:
>Sonst nutzt C nirgends char für Text.
und das ist meiner Ansicht nach, definitiv falsch, denn die Sprache
erlaubt ja die Deklaration einer Variablen dir nur ein char enthält.
Man mag darüber streiten ob das "was die Sprache vorsieht" das selbe ist
oder auch nicht, wie das "was die Sprache erlaubt auszudrücken". In
diesem Fall gehe ich aber davon aus, das sich beide Dinge decken.
>>> Bitflüsterer schrieb:>>>>> uint8_t ist folgendermaßen definiert:>>>> Das mag beim AVR-GCC so sein,>>> Das muß eigentlich überall so sein, wo es ein uint8_t gibt.>> Falsch. Auf der linken Seite des typedef kann jeder andere bekannte Typ>> stehen.> Es bezieht sich - genau wie ich geschrieben habe - auf Plattformen, bei> denen ein uint8_t überhaupt existiert. Wenn char 16 Bit breit ist, gibt> es schlicht kein uint8_t, denn char ist der kleinstmögliche Typ, da per> Definition sizeof(char)==1.
Au weia. Du hast recht. Ich bitte um Entschuldigung. Leider passiert mir
das nicht das erstemal.
Ich werde hier lieber nichts mehr zu C sagen und mich vorerst auf Fragen
beschränken, bevor ich nicht die Norm gründlich gelesen habe und sie mir
danach unter's Kopfkissen gelegt habe.
>>Wenn char 16 Bit breit ist, gibt es schlicht kein uint8_t>> Warum sollte es keine vorzeichenlose 8bit breiten Datentypen geben nur> weil chars als Unicode (2byte) definiert sind?
Unicode beschreibt die Zeichen, nicht deren Darstellung.
Wenn du Multibytezeichen verwenden möchtest, dann ist "char" der falsche
Datentyp, richtig ist dann "wchar_t".
Bitflüsterer schrieb:>> Klar kann man sich als Programmierer gegen das entscheiden, was die>> Sprache vorgesehen hat. Klug ist das meistens allerdings nicht.>> Das möchte ich im Zusammenhang verstanden wissen: Du schriebst:>>Sonst nutzt C nirgends char für Text.> und das ist meiner Ansicht nach, definitiv falsch, denn die Sprache> erlaubt ja die Deklaration einer Variablen dir nur ein char enthält.
Sicher. Ein "char" ist aber kein Zeichen, sondern ein gewöhnlicher
(normalerweiser) 8 Bit breiter Integer, nichts anderes. Im Gegensatz
dazu wird für einzelne Zeichen in der libc aber "int" verwendet, nun
rate mal, warum. ;-)
"char" stand mal für "character", zu einer Zeit, als Computer auch nicht
durch 8 teilbare Wortbreiten verwendeten. Dem ist nicht mehr so.
Lass dich nicht durch den Namen verwirren.
Gruß,
Svenska
Bitflüsterer schrieb:> Rolf Magnus schrieb:>> Bitflüsterer schrieb:>>>> Der Typ für Text ist ...>>> Irrelevant. ...>> Und was meintest du dann damit:>>>> Bitflüsterer schrieb:>>>>> Werte bitte int und nicht char>>>> Nee, PINA ist ein unsigned char.>>> Das ist hier unwichtig.>> Das es unwichtig sei, weil es ohnehin darum ging, mit dem Wert zu> rechnen resp. ihn mit der "<=" Operation zu vergleichen. Das ist aber> erstmal völlig unabhängig von Frage signed oder unsigned, sondern> bezieht sich auf char oder short.
Der Unterschied ist aber eigentlich nur, daß char in der Regel kleiner
ist.
> Um aber Mißverständnissen vorzubeugen, möchte ich betonen, das char> meiner Ansicht nach nicht für Werte verwendet werden sollte, die als> Zahlen interpretiert werden (wie das z.B. mit einem kleiner-Vergleich> geschieht).
Da gebe ich dir recht, allerdings nur für char ohne weitere Verzierung.
signed char und unsigned char können problemlos als kleine Integer
verwendet werden, während ich sie für Text nicht empfehlen würde.
Mit unsigned char zu rechnen, bringt aber eigentlich nur dann was, wenn
man eine 8-Bit-Plattform hat, auf der int halt teurer ist oder wenn man
sehr platzsparend programmieren muß. In anderen Fällen hat int
normalerweise keinen Nachteil gegenüber char zum rechnen.
> Ich versichere Dir: Es war nicht meine Absicht, eine meiner Ansicht> widersprechende Aussage zu unterschlagen. Deinem nachfolgenden Text> betreffs itoa, atoi etc. wollte ich nicht widersprechen. Deswegen habe> ich ihn nicht zitiert. Er enthält aber meiner Ansicht nach nichts, was> Deine Aussage irgendwie unterstützt.
Nun, es zeigt, daß ISO C für einzelne Zeichen int nutzt und nicht char.
> Es ging darum, das Deine Aussage impliziert das char anders als in> arrays für Zeichen nicht verwendet wird. Und das halte ich für falsch.
Es wird von den Standardfunktionen nicht für einzelne Zeichen verwendet.
Das hatte ich vielleicht auch etwas mißverständlich ausgedrückt. Selbst
kann man natürlich auch einzelne Zeichen in char speichern, aber auch
hier nur in char, niemals in signed char oder unsigned char.
> Deswegen auch das hier nachfolgende von mir, das Du zitiert hast.
Ja, auch das war sicher etwas mißverständlich.
Svenska schrieb:> "char" stand mal für "character", zu einer Zeit, als Computer auch nicht> durch 8 teilbare Wortbreiten verwendeten. Dem ist nicht mehr so.
Es hat sicher auch was mit der ursprünglichen Bedeutung des Bytes zu
tun. Zwei Definitionen waren da gängig:
- Die kleinste einzeln adressierbare Einheit der Plattform
- Die Menge Speicher, die für ein Zeichen des Standard-Zeichensatzes
genutzt wird
Somit war damals zwischen dem kleinsten Integer-Datentyp und dem
Datentyp für Zeichen ein fester Zusammenhang. In C ist ersteres als
"Byte" definiert, letzteres als "char", wobei beides dieselbe Größe hat.
Heute in Zeiten von Unicode und Multibyte-Zeichen und von Dutzenden von
unterstützen Zeichensätzen gibt es diesen Zusammenhang so natürlich
nicht mehr.