Hallo Zusammen Bei all meinen Projekten kam ich bisher um das Rechnen mit Gleitkommazahlen herum. Habe das immer möglichst vermieden. Falls eines das Gefühl hat, er müsse etwas vonwegen Hausaufgaben schreiben: Lasst gut sein. Ich studiere in eine Komplett andere Richtung und Elektronik ist ein Hobby von mir. Die fragen basieren alle auf meiner persönlichen neugierde. Für mein neustes Projekt dass ich anstrebe, wird das allerdings nichtmehr gehen. Seit einiger Zeit gibt es nun Controller mit integrierter FPU. Dazu stellen sich mir nun einige Fragen: - Macht eine solche FPU einen grossen Zeitunterschied bei der Rechnung mit Gleitkommazahlen? (Beispielsweise Berechnung eines Sinus) - Bietet Microchip solche Controller mit FPU an? Zumindest für ihre 32-Bit Controller Serie finde ich da nichts... alles was ich dazu gefunden habe war eine Floating Point Math Library: http://www.microchip.com/stellent/idcplg?IdcService=SS_GET_PAGE&nodeId=2680&dDocName=en552826 Wäre da eine FPU schneller? Sinusberechnungen brauchen bei der Lib Beispielsweise 299 Zyklen... Da eine FPU allerdings Hardware ist, dürfte dich nochmal um einiges schneller sein oder irre ich mich da? - Wie muss man sich das ganze vorstellen bezüglich der Programmierung? Reicht es da, die FPU zu aktivieren und sämtliche Berechnungen werden dann damit ausgeführt, oder muss sowas speziell im Code erwähnt werden? (Ich weiss, ich könnte ein Datenblatt lesen und ein Unterschied bei den meisten Herstellern ist bestimmt auch vorhanden, es geht mir hierbei aber nicht um eine exakte Beschreibung wie ich sowas anzuwenden habe sondern eher um eine kleine Beschreibung, damit ich mir besser Vorstellen kann was eine FPU ist und wie diese in einem uC integriert ist). - Es existieren so wie ich das gesehen habe auch externe FPU's... lohnt sich sowas? Schliesslich müsste man die Daten ja auch erst einmal übertragen usw. Bei dem Projekt geht es um die Berechnung mehrer Kalmann Filter, das ganze sollte möglichst schnell laufen. Das wars erst einmal Fragen zur FPU. ------------------------------------------- Eine generelle Frage, ich mir in den Sinn gekommen ist während dem schreiben: Mir ist aufgefallen, dass viele Hersteller mittlerweile einige CPU's mit FPU anbieten... ausser Microchip. Zumindest nicht auf der 32-Bit Serie. Generell habe ich das Gefühl, dass immer weniger Leute auf PIC's setzen. Hat das seine Gründe? Sind die Controller schlechter / weniger weit entwickelt als diejenigen der Konkurrenz? Falls dem so sei, welche Hersteller sind denn relativ "aktuell." ? AVR ist hier ja relativ weit verbreitet, doch wie siehts mit STM usw. aus? Für die Beantwortung dieser Frage reicht mir sonst auch ein Link, bei dem ich mich dann selbst einlesen kann. Vielen dank für jeden der sich Zeit nimmt.
Ja eine FPU beschleunigt floating point, kostet Geld, kostet Strom. Wieviel von jedem steht jeweils im Datenblatt. Wozu brauchst du eine FPU ? Fuer'n Sinus braucht man's nicht. Falls doch, sollte man sich von einer Modellreihe, die das eben nicht bietet loesen koennen. Eine FPU muss man nicht einschalten, sondern per code ansprechen. Der passende Compiler macht das dann schon. Falls PIC32 keine FPU haben kann. hat zumindet AVR32 ein modell. Dann gibt es diverse andere Controller, zB Blackfin, Cortex
Peter Daniel schrieb: > Bei all meinen Projekten kam ich bisher um das Rechnen mit > Gleitkommazahlen herum. Habe das immer möglichst vermieden. Laß mich raten: Du vermeidest auch Bus, Bahn oder Flieger und gehst alle Strecken zu Fuß? Wenn Du float-Berechnungen brauchst, dann nimm sie. Falls Dein Controller zu langsam ist, float per Software auszurechnen, dann nimm einen mit FPU. Wo ist das Problem? Selbst ein AVR rechnet locker mit float- (32Bit) oder auch double-Werten (64Bit) hinreichend schnell, sodaß es keinen Grund gibt, darauf zu verzichten.
m.n. schrieb: > Selbst ein AVR rechnet locker mit float- (32Bit) oder auch double-Werten > (64Bit) Ist double beim avr-gcc mittlerweile 64 Bits breit?
@ Peter Daniel (Gast) >- Macht eine solche FPU einen grossen Zeitunterschied bei der Rechnung >mit Gleitkommazahlen? (Beispielsweise Berechnung eines Sinus) Ja. Wobei man einen Sinus leicht und schnell aus einer Tabelle rausholen kann. >- Bietet Microchip solche Controller mit FPU an? Zumindest für ihre Keine Ahnung. Diverse ARM der gehobenen Klasse haben eine FPU. >Wäre da eine FPU schneller? Sinusberechnungen brauchen bei der Lib >Beispielsweise 299 Zyklen... Da eine FPU allerdings Hardware ist, dürfte >dich nochmal um einiges schneller sein Ja. >- Wie muss man sich das ganze vorstellen bezüglich der Programmierung? >Reicht es da, die FPU zu aktivieren und sämtliche Berechnungen werden >dann damit ausgeführt, Ja. >sondern eher um eine kleine Beschreibung, damit ich mir besser >Vorstellen kann was eine FPU ist und wie diese in einem uC integriert >ist). Eine FPU ist ein mathematischer Koprozessor, also ein Stück Hardware, welche die Fließkommarechungen macht. Der C Compiler kümmert sich darum, dass deine Fließkommarechungen in passenden Code umgesetzt werden. In ASm nutzt man eine FPU nur selten. >- Es existieren so wie ich das gesehen habe auch externe FPU's... lohnt >sich sowas? Nein. Das war vor 20 Jahren mal so. >Generell habe ich das Gefühl, dass immer weniger Leute auf PIC's setzen. Das ist rein subjektiv. Ich glaube Microchip macht noch ganz gut Umsatz mit seinen vielen VERSCHIEDENEN PICs.
Moin Peter, STM ist hier mittlerweile auch recht verbreitet, wie du auch an der Anzahl der STM bezogenen Titel im Forum siehst. Von ST gibt es die STM32F4 mit FPU. Zur FPU Performance kann ich (noch) nichts sagen, da ich nur ein paar Floats habe und die in SW ausreichend schnell erschlagen werden. Bzgl. deiner generellen FPU Fragen: Bei vorhandener FPU kann der Compiler Fließkommaberechnungen einfach in wenige (schnelle) FPU Befehle statt in hunderte Software Instruktionen umsetzen. Dazu muss der Compiler nur wissen, dass eine FPU vorhanden ist und er sie nutzen soll. Und du solltest sie im Code natürlich aktivieren ;) Liebe Grüße, Jan
A. K. schrieb: > Ist double beim avr-gcc mittlerweile 64 Bits breit? Das glaube ich nicht, bin mir aber nicht sicher. Für 'echte' double nehme ich IAR.
Peter Daniel schrieb: > - Macht eine solche FPU einen grossen Zeitunterschied bei der Rechnung > mit Gleitkommazahlen? (Beispielsweise Berechnung eines Sinus) Letztens habe ich mit meinen Arduino-Boards mal ein paar kleine selbstgeschriebene Benchmarks laufen lassen und dabei festgestellt, dass selbst Controller ohne FPU erhebliche Leistungsunterschiede bei Gleitkommarechnungen zeigen können, die sich durch unterschiedliche Taktraten nicht erklären lassen, sondern durch die interne Architektur des Controllers und seinen Befehlssatz bedingt sind. Verglichen habe ich mal die Performance: Atmega328 @16 MHz, "Arduino UNO" mit SAM3X @84 MHz, "Arduino DUE" Der SAM3X ist fast immer nur zwischen 3,5 bis 10 mal schneller als der Atmega328, mit identischem Arduino-Testprogramm zum Testen von Integerberechnungen und Arrayzugriffen. Soweit normal. Compiler ist auch in beiden Fällen der GCC. Aber beim Testen der Gleitkommarechnungen mit float Variablen ist mir aufgefallen, dass der SAM3X sagenhafte 100 mal schneller ist als ein Atmega328, wenn der Benchmark hauptsächlich Gleitkommadivisionen durchführt. Testporogramm war dazu die Newton-Approximation für PI: Pi = 4* (1/1 - 1/3 + 1/5 - 1/7 + 1/9 ... Obwohl der SAM3X Controller nur ca. 5mal schneller taktet als der Atmega328 und ich im Datenblatt nichts von einer FPU sehen kann, kann er die Approximation ca. 100 mal schneller rechnen. Ob es an der 32-Bit Architektur des SAM3X liegt, dass der GCC soviel schnelleren Code für Gleitkommadivisionen erzeugen kann als für 8-Bit AVR-Controller? (Arduino-Testprogramm kann ich auf Wunsch zur Verfügung stellen.)
Jürgen S. schrieb: > Ob es an der 32-Bit Architektur des SAM3X liegt, dass der GCC soviel > schnelleren Code für Gleitkommadivisionen erzeugen kann als für 8-Bit > AVR-Controller? Der SAM3X hat immerhin eine 32/32-Bit-Integer-Division, die er auch gewinnbringend für 32-Bit-Float-Divisionen einsetzen kann. Ob das allerdings einen Geschwindigkeitsfaktor von 100 bringt, kann ich nicht sagen.
Jürgen S. schrieb: > Obwohl der SAM3X Controller nur ca. 5mal schneller taktet als der > Atmega328 und ich im Datenblatt nichts von einer FPU sehen kann, kann er > die Approximation ca. 100 mal schneller rechnen. Das kann man doch ganz exakt ausrechnen: 84MHz/16MHz * (32Bit-8Bit) -> 5,25 * 24 = 126. Das ist der Beweis! Dass nur Faktor 100 erreicht wird, liegt mit Sicherheit an den wait-states des Flash-Speichers :-)
> sondern eher um eine kleine Beschreibung, damit ich mir besser > Vorstellen kann was eine FPU ist und wie diese in einem uC integriert > ist). Programmierst du in Assembler? Dann darfst du dich natuerlich um alles persoenlich kuemmern. Die meisten Leute programmieren aber in C oder bei so dicken Projekten das eine FPU unabdingbar ist gerne auch in C++. Dann macht das der Compiler. Du musst da halt nur die richtige CPU einstellen und eventuell noch ein Flag mitgeben und danach geht alles. > Falls dem so sei, welche Hersteller sind denn relativ "aktuell." ? Der groesste Hersteller ist wohl derzeit Renesas. Allerdings haben die das durch Zukaeufe geschafft und deshalb sehr viele unterschiedliche Familien. Viele andere nutzen wohl ARM gerade weil sie nicht die Power haben um eigene Compiler und das ganze Tooling selber zu entwickeln. Olaf
Yalu X. schrieb: > Der SAM3X hat immerhin eine 32/32-Bit-Integer-Division, die er auch > gewinnbringend für 32-Bit-Float-Divisionen einsetzen kann. Ob das > allerdings einen Geschwindigkeitsfaktor von 100 bringt, kann ich nicht > sagen. Oh, oh. Faktor 100 stimmt auch nicht! Mein Fehler, ich nehme das oben geschriebene zurück, offenbar hat mir mein Gedächtnis einen Streich gespielt und ich habe den Faktor 100 mit einem anderen Benchmark-Test verwechselt. Tatsächlich ist es so (und das habe ich jetzt nochmal nachgemessen): PI-Benchmark auf Atmega328: 4.403720 Sekunden PI-Benchmark auf SAM3X : 0.502921 Sekunden Der Faktor bei der Rechengeschwindigkeit mit float ist also ca. 8,75 und liegt damit nur knapp über dem Faktor, den man durch die höhere Taktrate von 84 MHz vs 16 MHz erwarten kann. Sorry, mein Fehler. Wo es den Faktor 100 bei der Rechengeschwindigkeit gibt, ist tatsächlich mein Primzahlen-Benchmark. Mein Test versucht ganz brute-force, Primzahlen durch Modulo-Arithmetik zu ermitteln. Es werden alle mögliche Teiler zwischen 1 und der zu testenden Zahl ausprobiert, ob "Zahl % Teiler ==0" ist. Und bei diesem Prinzahlen-Benchmark gab es den Unterschied um Faktor 100. Offenbar ist die Modulo-Arithmetik im SAM3X Controller wesentlich scheller implementiert als in den 8-Bit AVRs. Bei Gleitkommadivisionen mit "float" liegt der echte Vorteil des 32-Bit Controllers, wenn man den Vorteil des schnelleren Taktes herausrechnet, nur bei 8,75 / 5,25 = ca. 1,67 Also nur um Faktor 8,75 (taktbereinigt Faktor 1,67) schnellere Gleitkommadivision mit float. Und Faktor 100 gilt leider nur für die Modulo-Divisionsrestbestimmung mit Integern.
@ Jürgen S. (jurs) >Unterschied um Faktor 100. Offenbar ist die Modulo-Arithmetik im SAM3X >Controller wesentlich scheller implementiert als in den 8-Bit AVRs. >>Yalu X. (yalu) (Moderator) >Der SAM3X hat immerhin eine 32/32-Bit-Integer-Division, die er auch >gewinnbringend für 32-Bit-Float-Divisionen einsetzen kann.
Jürgen S. schrieb: > Also nur um Faktor 8,75 (taktbereinigt Faktor 1,67) schnellere > Gleitkommadivision mit float. Du magst ein netter Mensch sein, aber das glaube ich nicht. Kontrolliere bitte, was tatsächlich gerechnet wird. Die Werte für 1/3, 1/5, 1/7, ... werden sicherlich vom Compiler schon aufgelöst, sodass garkeine Divisionen stattfinden, sondern lediglich eine Multiplikation mit 4 - wenn überhaupt. Ferner sieh bitte nach, ob in beiden Programmen die Variablen vielleicht mit double deklariert werden. In Folge würde der AVR-GCC mit 32 Bit rechnen und der SAM mit richtigen double (64 Bit). Wenn man am Ende vergleichbaren Code vorliegen hat, sollte wieder ein unbereinigter Faktor herauskommen, der deutlich über 8,75 liegt!
Yalu X. schrieb: > Der SAM3X hat immerhin eine 32/32-Bit-Integer-Division, die er auch > gewinnbringend für 32-Bit-Float-Divisionen einsetzen kann. Sicher? Mit 64:32=>32 kannst du da etwas gewinnen, aber mit 32:32=>32 kommt auf direktem Weg nichts raus, müsste per Iteration laufen.
Jürgen S. schrieb: > Der Faktor bei der Rechengeschwindigkeit mit float ist also ca. 8,75 und > liegt damit nur knapp über dem Faktor, den man durch die höhere Taktrate > von 84 MHz vs 16 MHz erwarten kann. Angesichts des doch recht unterschiedlichen Aufwands erscheint das kaum glaubhaft. Immerhin muss ein 8-Bitter für eine 24-Bit Mantisse schon bei Add/Sub mindestens 3mal so viel rechnen wie ein 32-Bitter. Und das ist noch ohne die Shifts gerechnet, die bei die Mantissen angleichen und das Ergebnis normalisieren. Die für einen CM3 trivial sind, für einen AVR jedoch arg aufwendig.
A. K. schrieb: > Yalu X. schrieb: >> Der SAM3X hat immerhin eine 32/32-Bit-Integer-Division, die er auch >> gewinnbringend für 32-Bit-Float-Divisionen einsetzen kann. > > Sicher? Mit 64:32=>32 kannst du da etwas gewinnen, aber mit 32:32=>32 > kommt bei den üblicherweise normalisierten Mantissen auf direktem Weg > nichts raus, müsste per Iteration laufen. Eine 64/32-Division wäre natürlich besser, weil man damit schon mit einer einzelnen Divison zu Ziel kommt. Von den 32/32-Divisionen braucht man IMHO 3 Stück, da die Mantisse von 32-Bit-Floats inkl. des impliziten führenden 1-Bits 24 Bit groß ist. Jede Division berechnet also 8 Bits des 24-Bit-Ergebnisses. Da die 32/32-Division auf dem M3 nur 2 bis 12 Zyklen dauert, sollte die gesamte Berechnung immer noch deutlich weniger Zyklen benötigen als auf einem AVR. Bei Double-Divisionen hilft einem der Divisionsbefehl überhaupt nicht mehr, aber auch eine 64/32-Bit-Division wäre nutzlos, weil die Mantisse des Divisors größer als 32 Bit ist. In diesem Fall muss man über alle Bits der Mantisse des Dividenden iterieren. Da bleibt dem ARM gegenüber dem AVR nur noch der Vorteil der größeren Wortbreite und der höheren Taktfrequenz.
damit da keine Verwirrung aufkommt, eine FPU bedeutet nicht, das alle mathematischen Funktionen automatisch mit einem Hardwarebefehl abgedeckt werden. Es bedeutet nur (Beispiel C), das die math-Lib auf Hardwarefunktionen in der CPU zurückgreifen kann, um die Berechnungen zu beschleunigen. Wie stark hängt von der Hardware ab, auch der bit-Breite der Recheneinheiten (8-bit CPU vs 16 32 usw bit CPU). ieee754 bietet eine Normierung, aber im DSP Bereich nimmt man auch gerne andere Formate, Schnittmengen nicht ausgeschlossen.
Yalu X. schrieb: > Bei Double-Divisionen hilft einem der Divisionsbefehl überhaupt nicht > mehr, Wär nicht erstaunt, wenn man den für Newton-Raphson verwenden kann. http://en.wikipedia.org/wiki/Division_algorithm#Newton.E2.80.93Raphson_division
m.n. schrieb: > Selbst ein AVR rechnet locker mit float- (32Bit) oder auch double-Werten > (64Bit) hinreichend schnell, sodaß es keinen Grund gibt, darauf zu > verzichten. Kommt drauf an... Eine Formel, um einen Sensorwert auf einem Display auszugeben, wirst du genügend schnell in Float rechnen können. Einen Signalgenerator für Audiofrequenzen in Float wird aber im AVR kaum drin liegen.
Scheint als wäre die Frage garnicht so verkehrt gewesen, gibt immerhin viel Gesprächsstoff und konnte schon sehr viel lernen. Vielen dank an alle, die hier geholfen haben! Ich weiss nun eigentlich alles was ich wollte, könnt aber gerne weiterdiskutieren. Man kann nie genug lernen und das hier ist definitiv besser als jede Literatur!!! Durch dieses Forum habe ich schon soviel gelernt, danke an euch!
A. K. schrieb: > Wär nicht erstaunt, wenn man den für Newton-Raphson verwenden kann. So wurde das u.a. auf dem TMS320C40 gemacht. Der hatte einen Befehl, der mit Hilfe einer Lookuptabelle einen 8 Bit genauen Näherungswert für den Kehrwert einer Zahl ermittelt hat. Das Newton-Raphson-Verfahren verdoppelt mit jedem Iterationsschritt die Anzahl der genauen Bits, so dass nach zwei Iterationsschritten bzw. 4 MACs das 32-Bit-Float-Ergebnis dastand. Die FPU eines damals aktuellen PC-Prozessors (i486) hat für eine Division die 50-fache Zeit benötigt (allerdings rechnete der in doppelter Genauigkeit). Auf ähnliche Weise und ähnlich schnell wurden auch Quadratwurzeln berechnet. Das Newton-Raphson-Verfahren bringt IMHO aber nur Vorteile, wenn bereits eine schnelle FP-Multiplikation und -Addition zur Verfügung stehen. Wenn diese erst mühselig aus Integer-Operationen zusammengesetzt werden müssen, dürfte die bitweise Division eher schneller sein.
A. K. schrieb: > Angesichts des doch recht unterschiedlichen Aufwands erscheint das kaum > glaubhaft. Immerhin muss ein 8-Bitter für eine 24-Bit Mantisse schon bei > Add/Sub mindestens 3mal so viel rechnen wie ein 32-Bitter. Muss er das wirklich? Haben nicht auch die 8-Bit AVR-Controller mindestens drei "Register-Pärchen", in Form des X-, Y- und Z-Registers, in denen zwei 8-Bit Register zusammengefaßt sind, und die zusammen 16-Bit Register bilden? Ich bin kein Assembler-Programmierer, aber das Instruction-Set der AVR 8-Bitter ist doch 16-Bit? Und in den 16-Bit Instructions gibt es auch welche, die mit den 16-Bit Registern (X-, Y-, Z-Register) arbeiten? Anyway, das ist der Code, den ich als meinen PI-Benchmark laufen lasse (ohne das Arduino-Programm drumherum):
1 | #define UINT uint16_t
|
2 | #define ULONG uint32_t
|
3 | #define FLOAT float
|
4 | #define BYTE uint8_t
|
5 | |
6 | FLOAT piBenchmark(UINT limit) |
7 | // Benchmark zur nährungsweisen Ermittlung der Zahl PI mittels der Formel:
|
8 | // Pi = 4* (1/1 - 1/3 + 1/5 - 1/7 +1/9 ...)
|
9 | {
|
10 | FLOAT pi=0.0; |
11 | ULONG teiler=1; |
12 | BYTE sign=1; // 1 für Vorzeichen + beim Addieren, 0 für Vorzeichen - |
13 | for (UINT i=1;i<10;i++) // Benchmarkschleife zehnmal laufen lassen für längere Messzeit |
14 | {
|
15 | for (UINT j = 1; j <= limit; j++) |
16 | {
|
17 | if(sign) |
18 | {
|
19 | pi += 1/(FLOAT)teiler; |
20 | sign=0; |
21 | }
|
22 | else
|
23 | {
|
24 | pi-=1/(FLOAT)teiler; |
25 | sign=1; |
26 | }
|
27 | teiler+=2; |
28 | }
|
29 | }
|
30 | return pi * 4.0; |
31 | }
|
Der von mir empfohlene Wert für den Parameter "limit" ist 10000, aber jeder andere Wert im Bereich einer uint16_t Variablen tut es auch. So eine Benchmark-Routine testet natürlich nicht ausschließlich die Gleitkommaverarbeitung, denn auch wenn diese Routine sehr viele Gleitkommaberechnungen ausführt, finden natürlich in den for-Schleifen auch Veränderungen des Laufindex und Vergleiche und Verzweigungen statt. In meinem Arduino-Sketch gibt man den "limit" Parameter als Startwert über Serial erst zur Laufzeit des Programms ein, so dass Vorab-Optimierungen des Compilers aufgrund eines bestimmten Parameters ausgeschlossen sind. Aber das ist glaube ich gar nicht notwendig und die Funktion liefert dieselbe Laufzeit, wenn man als Parameter eine bereits zum Zeitpunkt der Kompilierung feststehende Konstante übergibt. Als Laufzeit für den oben geposteten Code ermittele ich: Atmega328, 16 MHz, PI Benchmark: 3.940148 s SAM3X, 84 MHz, PI Benchmark: 0.446243 s Da liegt ein Faktor von ca. 8,8 zwischen, bei einem Faktor von 5,25 beim Takt des Controllers bei einem "Benchmark mit vielen Gleitkommadivisionen". Wenn man nur die Gleitkommadivisionen für sich betrachtet, ohne das Benchmark-Brimborium in der Schleife, dürfte der Faktor etwas höher liegen. Ich habe hier allerdings keine Möglichkeit, nur ein Timing für eine einzelne Division alleine zu machen. Dafür würde man wohl ein Oszilloskop benötigen, was ich als Hobbybastler aber nicht habe.
Jürgen S. schrieb: > Haben nicht auch die 8-Bit AVR-Controller mindestens drei > "Register-Pärchen", in Form des X-, Y- und Z-Registers, in denen zwei > 8-Bit Register zusammengefaßt sind, und die zusammen 16-Bit Register > bilden? Sind für Adressierung da. Bringt bei Rechnung nichts. > Ich bin kein Assembler-Programmierer, aber das Instruction-Set der AVR > 8-Bitter ist doch 16-Bit? Die Befehlsbreite ist an dieser Stelle völlig irrelevant.
Ich habe hier nur einen F407, den ich testen kann. Bei 168MHz braucht eine FDIV etwa: mit FPU 0,12µs ohne FPU 0,55µs double 1,05µs Als Erfahrungswert für einen ATmega mit 16MHz habe ich 20 bis 30µs in Erinnerung, lasse mich da aber gerne korrigieren.
Hat mir doch keine Ruhe gelassen, weil ich das auch immer schon mal wissen wollte. Hier der direkte Vergleich von Soft und Hard FPU auf einem STM32F407 bei 168 MHz. Relevanter Code ist im Anhang. Compiler: arm-none-eabi-gcc.exe (GNU Tools for ARM Embedded Processors) 4.8.3 20140228 (release) [ARM/embedded-4_8-branch revision 208322] Compiler/Linker options für SOFT: -O3 -std=gnu99 -c -fmessage-length=0 -mcpu=cortex-m4 -mthumb -mfloat-abi=soft -g3 -gdwarf-2 Compiler/Linker options für HARD: -O3 -std=gnu99 -c -fmessage-length=0 -mcpu=cortex-m4 -mthumb -mfloat-abi=hard -mfpu=fpv4-sp-d16 -g3 -gdwarf-2 Überraschend ist, dass die normalen double sin/cos Versionen keinerlei Unterschied zeigen. Offenbar sind die double Versionen nicht FPU optimiert. Die float Varianten sinf/cosf sind da schon besser. Werde ich mir merken. Start HARD FPU test..... Div/Mult: 0.032 Cosf/Sinf float version: 0.182 Cos/Sin std. double version: 0.789 FPU test: PI = 3.141597; time used: 1.873 Start SOFT FPU test..... Div/Mult: 0.263 Cosf/Sinf float version: 1.015 Cos/Sin std. double version: 0.792 FPU test: PI = 3.141597; time used: 14.955 Insgesamt also ein Faktor von ca. 6 - 10 von HARD ggü SOFT bei dem verwendeten Compiler und seinen Libs. Hätte mehr erwartet, aber offenbar sind die Integer Einheiten auch nicht schlecht. pitschu
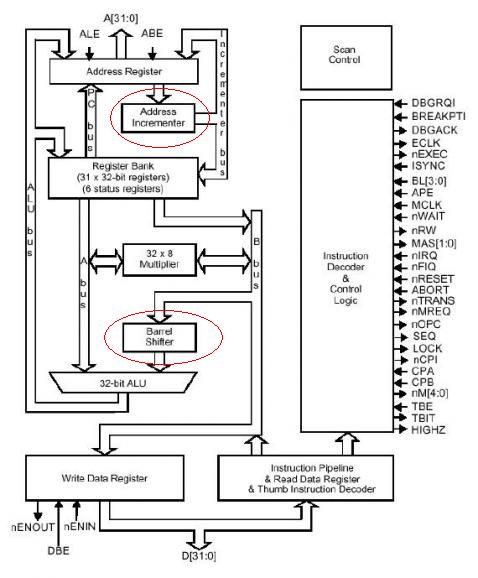
ARM Prozessoren haben den Barrel-Shifter direkt hinter der Alu und können eine Alu-Operation+Shift in einem Zyklus ausführen. Das kommt den Fließkommaberechnungen ohne FPU wohl ziemlich entgegen.
chris_ schrieb: > ARM Prozessoren haben den Barrel-Shifter direkt hinter der Alu Davor, nicht dahinter.
Bei µC-FPUs sollte man beachten, dass diese meistens nur single-precision (Datentyp float) können. Im Falle von double-Berechnungen kann es also gut sein, dass einem die FPU gar nichts bringt. Peter Daniel schrieb: > Wie muss man sich das ganze vorstellen bezüglich der Programmierung? > Reicht es da, die FPU zu aktivieren und sämtliche Berechnungen werden > dann damit ausgeführt, oder muss sowas speziell im Code erwähnt werden? Zumindest bei den Cortex-FPUs ist es so, dass im Programm-Code die FPU aktiviert und zusätzlich dem Compiler mitgeteilt werden muss, dass er auch die entsprechende Befehle benutzen soll. Zusätzliche Infos sind hier aufgelistet: http://community.arm.com/docs/DOC-7544
Beim fdiv-Test mit AVR-GCC (AVR Studio 4.19) habe ich zunächst einen Schreck bekommen. Die reine Division dauerte mit Standardeinstellung rund 115µs. Nachdem dem Linker die libm.a 'verordnet' wurde, ging es deutlich schneller. Beim ATmega162 mit 16MHz braucht eine FDIV etwa 32µs.
Peter Daniel schrieb: > Mir ist aufgefallen, dass viele Hersteller mittlerweile einige CPU's mit > FPU anbieten... ausser Microchip. Zumindest nicht auf der 32-Bit Serie. > Generell habe ich das Gefühl, dass immer weniger Leute auf PIC's setzen. > Hat das seine Gründe? Sind die Controller schlechter / weniger weit > entwickelt als diejenigen der Konkurrenz? Die Frage ist : wofür brauchst Du Gleitkomma? Viele industrielle Anwendungen kommen ganz gut mit Festkomma zurecht, darunter Audiosignalverarbeitung, Bildverarbeitung, Brushless DC Motorsteuerungen. Die meisten digitalen Signalprozessoren haben keine Gleitkommaeinheit, sondern arbeiten mit Festkommazahlen. Festkomma-DSPs haben oft eine höhere Taktfrequenz als die entsprechenden Gleitkomma-Äquivalente, brauchen weniger Strom pro MHz und sind billiger. Gleitkomma verwendet man nur da, wo es (a) geschwindigkeitstechnisch nicht darauf ankommt (b) für Prototypen und Einzelstücke (geringerer Entwicklungsaufwand) (c) wenn man einen hohen Dynamikbereich abdecken muss, d.h. es sowohl mit sehr kleinen als auch mit sehr großen Zahlen zu tun hat. Das Problem bei Festkomma ist, dass Du nur einen gewissen Zahlenbereich hast, d.h. Du kannst nur Zahlen von zB -1 bis +1 oder -8 bis +8 oder so darstellen. Das erfordert beim Berechnen das Einfügen von Normierungsfaktoren, damit Du (a) die volle Genauigkeit behältst und (b) den zulässigen Wertebereich nicht überschreitest. Wenn Du das berücksichtigst, kannst Du viel Hardware sparen und beispielsweise Berechnungen in FPGAs auslagern, wo sie parallel durchgeführt werden. fchk
Als ich damals meinem 286er mit FPU ausrüstete benachmarkte ich vorher die Gleitkommaleistung. Vorher 47Whetstones Nacher ca2000Whetstones Damit waren waren Schallberechnungen möglich.
chris_ schrieb: > ARM Prozessoren haben den Barrel-Shifter direkt hinter der Alu a.k. schrieb: >Davor, nicht dahinter. Du hast recht ;-) http://letsembed.files.wordpress.com/2013/12/barrel-shifter-and-ai.jpg
{kind=link}
Tolle Diskussion hier, sehr viel neues dazugelernt. Danke! Frank K. schrieb: > Die Frage ist : wofür brauchst Du Gleitkomma? Wie bereits erwähnt für die Berechnung mehrer Kalmann Filter. Würde evt. auch ohne gehen, müsste das mal durchrechnen wie genau das noch kommenwürde mit Festkomma... Aber ich habe mich nun dazu entschieden trotzdem mal einen uC mit FPU zu kaufen. Da ich sowiso gerne mal andere Controller kennenlernen will und mich die ARM Cortex Prozessoren sehr interessieren nutze ich die Chance direkt und habe mir jetzt einen ATSAM4 mit FPU gekauft. So arbeite ich einmal mit Cortex und habb dabei noch direkt eine FPU benutzen. Sehr gespannt wie das ganze wird, aber ich denke es wird schon ein Unterschied sein vom Umstieg von den kleinen 8-Bittern auf 32-Bit mit allem drum und dran. Bin gespannt! Vielen dank an all die tollen Leute hier!!!
Mittlerweile gibt es neuere Technologien als nur eine FPU um mathematische Berechnungen zu Beschleunigen. Vorteilhaft wäre vielleicht ein STM32F4 Discovery http://www.st.com/web/catalog/tools/FM116/SC959/SS1532/PF252419?sc=internet/evalboard/product/252419.jsp Ich habe gerade mal nachgesehen. Ein Cortex M4F hat eine DSP Einheit mit MAC. Ich nehme an, dass die MAC auch für Fließkomma geht. Dann sollte man ein 100Tap FIR mit Float in 1us rechnen können. Das Board gibt es für unter 20€.
Hier gibt es ein Dokument, das die DSP-Fähgkeiten des Discovery-Boards ein wenig beschreibt: http://www.dspconcepts.com/sites/default/files/white-papers/STM32Journal_DSPC.pdf Die MAC-Operation geht laut diesem PDF in einem Zyklus. Ob sie nur in Integer geht oder auch in Float konnte ich noch nicht heraus finden.
Peter Daniel schrieb: > Aber ich habe mich nun dazu entschieden trotzdem mal einen uC mit FPU zu > kaufen. Da ich sowiso gerne mal andere Controller kennenlernen will und > mich die ARM Cortex Prozessoren sehr interessieren nutze ich die Chance > direkt und habe mir jetzt einen ATSAM4 mit FPU gekauft. So arbeite ich > einmal mit Cortex und habb dabei noch direkt eine FPU benutzen. Sehr > gespannt wie das ganze wird, aber ich denke es wird schon ein > Unterschied sein vom Umstieg von den kleinen 8-Bittern auf 32-Bit mit > allem drum und dran. Bin gespannt! > > Vielen dank an all die tollen Leute hier!!! Das hier solltest Du Dir auf jeden Fall anschauen damit ersparst Du Dir viele "Erste Fehler", z.b. wie man die CMSIS Lib nutzt oder wie man dem Compiler überhaupt sagt dass er die FPU nutzen soll. http://www.atmel.com/Images/Atmel-42144-SAM4E-FPU-and-CMSIS-DSP-Library_AP-Note_AT03157.pdf Wenn es Dir auf Performance ankommt, rate ich Dir den IAR Compiler zu testen, der holt am meisten raus
Wie schneidet den der ATSAM4 gegenüber dem STM32F4 bezüglich Rechenleistung ab?
Das kannst so generell nicht aussagen, es kommt darauf an bei welcher Disziplin und bei welcher Frequenz. Du kannst Dir verifizierte Ergebnisse auf der offiziellen Benchmark Seite EEMBC.ORG ansehen, es kommt auch auf den Compiler drauf an. Z.b. bei max. Frequenz von 123MHz erreicht der SAM4S beim IAR 6.5 etwa 408Coremark Werte, bei 21MHz etwa 63 Coremark Werte. ST hat den STM32F417 mit Greenhills ins Rennen geschickt, erreicht bei 168MHz etwa 488Coremark Werte Auf den MHZ gesehen, liegt der SAM4S klar vorne mit 3.38Coremark / MHz, der STM32F4 mit 2.81Coremark / MHz. Beeindruckend dass der SAM4S unter allen CortexM4 die höchste Effizienz erreicht
Vielen Dank für den Vergleich. Mich würden vor allen Dingen Anwendungen wie digitale Filter aus der Signalverarbeitung interessieren. Ich habe mir gerade das Datenblatt für den SAM4SD32 angesehen ( ist einfach, es hat nur 1231 Seiten ). http://www.atmel.com/Images/Atmel-11100-32-bit-Cortex-M4-Microcontroller_Datasheet.pdf Auf Seite 93 sind die Floatingpoint-Funktionen aufgelistet. Dort gibt es beispielsweise
1 | VFMA.F32 {Sd,} Sn, Sm Floating-point Fused Multiply Accumulate
|
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.