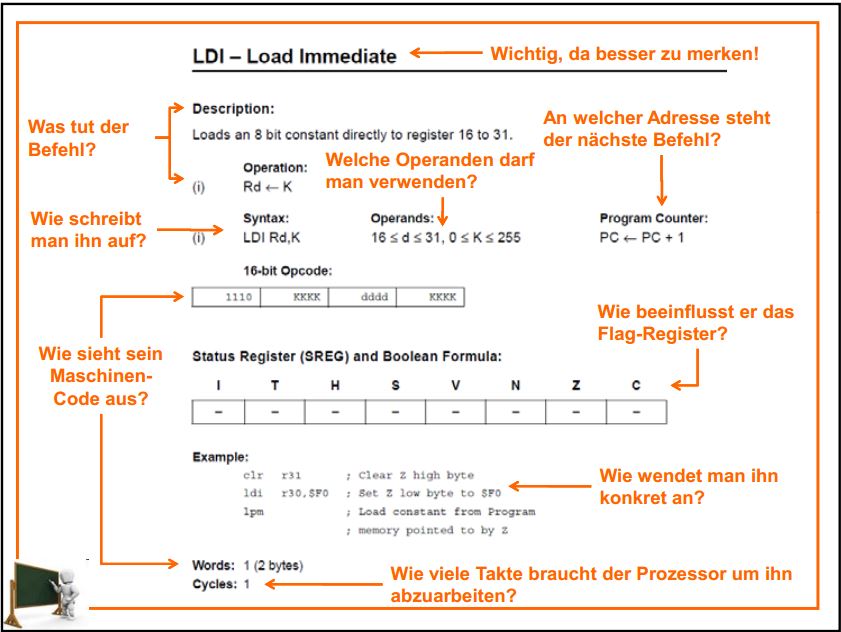

Hallo Ich verstehe den Opcode des AVRs nicht ganz, bzw verstehe ich nicht, wie das so implementiert werden kann: Im Foto ldi.png sieht man, dass der Befehl ldi in Binär 4 bit einnimmt, 4 bit für die Registerauswahl und 4 bit für die Konstante vorhanden sind. Nimt man jetzt aber den Befehl add, dann sieht man, dass der Befehlscode 6 bit lang ist. Meine Frage ist jetzt, wie es möglich ist, so einen Decoder zu bauen? Ich meine man kann ja nicht zuerst nur 4 Steuerleitungen und dann beim nächsten Befehl 6 Steuerleitungen verwenden, oder? Und noch eine Frage: Von wem wird der Befehl ldi ausgeführt? Die ALU macht das ja eigentlich nicht, da es keine arithmetische oder logische Operation ist, oder?
Angehängte Dateien:
-

ldi.png.JPG
89 KB -

add.png.JPG
27 KB
> Ich meine man kann ja nicht zuerst nur 4 Steuerleitungen und dann beim > nächsten Befehl 6 Steuerleitungen verwenden, oder? Doch. > Von wem wird der Befehl ldi ausgeführt? Vom Leitwerk.
Und ich habe noch eine Frage: Im Datenblatt des Atmega8 steht, dass der Befehl ADD nur 1 Takt braucht. Wie kann das sein? Ich meine es muss doch zuerst mal der Befehl aus dem Befehlsspeicher geholt werden (1 Takt), dann noch Dekodiert werden (1 Takt), dann muss der Inhalt des ersten Register in den Input der ALU geladen werden (1 Takt), dann der Inhalt des 2. Registers (1 Takt), dann der Befehl ausgeführt werden und dann muss das Ergebnis noch in das erste Register geschrieben werden (noch 1 Takt). Also wären das doch 5 Takte oder?
Danke für die Antwort. Wie genau geht das? Gibt es ein Bit, das angibt, ob der Befehl 4 oder 6 bit lang ist?
Samuel J schrieb: > dann muss der Inhalt des ersten Register in den Input der ALU geladen werden > (1Takt), dann der Inhalt des 2. Registers (1 Takt)... Stimmt das so eigentlich? Oder gehen 2 8 bit breite Busse (bei 8 bit breiten Register natürlich) zur ALU?
Samuel J. schrieb: > Meine Frage ist jetzt, wie es möglich ist, so einen Decoder zu bauen? > Ich meine man kann ja nicht zuerst nur 4 Steuerleitungen und dann beim > nächsten Befehl 6 Steuerleitungen verwenden, oder? Nein, das kann man nicht. Deswegen gibt es ja auch keine AVRs %-6 <sing> Alles nur geträumt </sing> > Von wem wird der Befehl ldi ausgeführt? Die ALU macht das ja eigentlich > nicht, da es keine arithmetische oder logische Operation ist, oder? Die ALU ist ein Block in der CPU. Keiner der Blöcke führt für sich allein eine Operation aus. Das ist immer ein Zusammenspiel mehrerer Blöcke. Meine Güte. Ist denn "dumme Fragen" Woche? Natürlich kann man einen Befehlsdecoder so bauen, daß er Befehle verschiedener Länge decodiert. Genau genommen ist das sogar die Variante, mit der alles angefangen hat. RISC Designs mit streng orthogonalem Befehlssatz und (wenn möglich) gleich langen Prefixen für alle Maschinenbefehle kamen erst später. Ist auch eine Frage der Ökonomie. Manche Maschinenbefehle haben gar keine Parameter, andere vielleicht nur ein paar Bit für ein Register, wieder andere brauchen zwei Register oder ein Register und ein Immediate. Wie soll man das in eine möglichst kurze mittlere Befehlslänge packen, wenn nicht mit verschieden langen Prefixen? XL
Samuel J. schrieb: > Im Datenblatt des Atmega8 steht, dass der Befehl ADD nur 1 Takt braucht. > Wie kann das sein? Das kann natürlich nicht sein!!1!elf! Ist alles gelogen in den Datenblättern! > Ich meine es muss doch zuerst mal der Befehl aus dem Befehlsspeicher > geholt werden (1 Takt), dann noch Dekodiert werden (1 Takt), dann muss > der Inhalt des ersten Register in den Input der ALU geladen werden (1 > Takt), dann der Inhalt des 2. Registers (1 Takt), dann der Befehl > ausgeführt werden und dann muss das Ergebnis noch in das erste Register > geschrieben werden (noch 1 Takt). > > Also wären das doch 5 Takte oder? Oder Leute, die reale CPUs bauen, gehen vielleicht nicht ganz so naiv vor wie du? Warum sollte man gleich zwei Takte dafür verschwenden, die Busmultiplexer so zu schalten, daß Register 1 am ersten Port der ALU hängt und Register 2 am zweiten ALU Port? Und warum sollte man damit überhaupt noch einen ganzen Takt nach dem Decodieren des Opcodes warten? Was soll denn überhaupt dieses "Decodieren" sein, wenn nicht gerade das Umschalten der diversen Datenpfade zwischen den CPU-Blöcken? (kopfschüttelnd) XL
Samuel J. schrieb: > Ich meine es muss doch zuerst mal der Befehl aus dem Befehlsspeicher > geholt werden (1 Takt), dann noch Dekodiert werden (1 Takt), dann muss > der Inhalt des ersten Register in den Input der ALU geladen werden (1 > Takt), dann der Inhalt des 2. Registers (1 Takt), dann der Befehl > ausgeführt werden und dann muss das Ergebnis noch in das erste Register > geschrieben werden (noch 1 Takt). > > Also wären das doch 5 Takte oder? Nein. Darum sind AVR-Instructionen 16-bit breit. Und werden 1 Takt vorher eingelesen. Google mal nach pre-fetch.
Axel Schwenke schrieb: > Nein, das kann man nicht. Deswegen gibt es ja auch keine AVRs %-6 Gut, ich habe die Frage vielleicht falsch formuliert: Wie realisiert man das? > Die ALU ist ein Block in der CPU. Keiner der Blöcke führt für sich > allein eine Operation aus. Das ist immer ein Zusammenspiel mehrerer > Blöcke. Das weiß ich. Ich wollte fragen, wer dann schlussendlich die Konstante in ein Register schreibt. Also wird die Zahl bereits nach dem Decoder auf den Datenbus gelegt, und der Decoder adressiert dann das richtige Register, welches dann die Daten vom Bus einliest? > Meine Güte. Ist denn "dumme Fragen" Woche? ... Vielleicht bis du in einem Forum, in dem Leute fragen zu Themen stellen, in denen sie sich nicht so gut auskennen (und deshalb kommen halt manchmal "dumme Fragen" dabei raus), nicht so gut aufgehoben. > Genau genommen ist das sogar die Variante, mit der alles angefangen hat. > RISC Designs mit streng orthogonalem Befehlssatz und (wenn möglich) > gleich langen Prefixen für alle Maschinenbefehle kamen erst später. Bedeutet das, dass man heute Befehle so aufbaut? : 8 Bit Befehlscode + 8 Bit Konstanten + 4 + 4 Bit für Adressierung der Register. Wäre das nicht eine Verschwendung, wenn man nur für ein paar Befehle Konstanten braucht? Dann wäre es doch Ökonomischer, wenn man alle Befehle, die eine Konstante benötigen, mit 4 Bit adressiert, und für alle anderen noch ein zusätzliches Bit einführt, welches anzeigt, ob eine Konstante benötigt wird. Wenn keine Konstante benötigt wird, können die 8 Bit (die vorhrer für die Konstanten waren) auch noch für den Befehlscode verwendet werden. Oder wird es in modernen Prozessoren doch mit so gemacht, wie ich es oben beschrieben habe? > Das kann natürlich nicht sein!!1!elf! > Ist alles gelogen in den Datenblättern! Das habe ich nie gesagt... Ich habe gefragt, WIE es möglich ist? > Leute, die reale CPUs bauen, gehen vielleicht nicht ganz so naiv vor wie > du? Das ist mir schon klar. Die machen das wahrscheinlich auch schon ein bisschen länger wie ich... > Warum sollte man gleich zwei Takte dafür verschwenden, die > Busmultiplexer so zu schalten, daß Register 1 am ersten Port der ALU > hängt und Register 2 am zweiten ALU Port? Aber das müsste dan bedeuten, dass 2 8-bit breite Busse von dem GPR zur ALU gehen, oder? Marc Vesely schrieb: > Darum sind AVR-Instructionen 16-bit breit. Wieso? Was hat das mit der Instructionsbreite zu tun? > Google mal nach pre-fetch. Ja, da hab ich schon etwas darüber gelesen. Aber das Pre-Fetching benötigt doch auch einen Takt, oder? Also müssten es doch mehr als ein Takt sein, oder? Meines Wissens nach sind es ja drei Stufen Pre-fetch fetch Execute Wird dann im Datenblatt nur die Taktanzahl für "Execute" angegeben?
Samuel J. schrieb: > Im Foto ldi.png sieht man, dass der Befehl ldi in Binär 4 bit einnimmt, > 4 bit für die Registerauswahl und 4 bit für die Konstante vorhanden > sind. 8 Bits für die Konstante. Aufgeteilt auf 2x 4 Bits.
Samuel J. schrieb: > Wird dann im Datenblatt nur die Taktanzahl für "Execute" angegeben? Gewissermassen. Letztlich ist das bei solch simplen Prozessoren grad jene Zeit, um die der Befehl eine Befehlsfolge verlangsamt. Bei komplexeren Prozessoren wie denen in PCs oder Handys wirds komplizierter.
Schau mal da rein. Das ist ein Modell der Implementierung einer simplifizierten AVR Architektur: http://web.engr.oregonstate.edu/~sinky/teaching/4.AVR_Microarchitecture.pdf
Samuel J. schrieb: > Bedeutet das, dass man heute Befehle so aufbaut? Es gibt kein Gesetz dafür, wie man Befehle aufbaut. Da gibts welche mit starrer Befehlslänge (z.B. ARM nativ), solche mit schier unendlicher Variantionsmöglichkeit (x86) und alles dazwischen. Es gab auch schon eine Architektur, deren Befehlscodierung nicht einmal Bytegrenzen respektierte. Aber nicht lang. ;-)
Samuel J. schrieb: > Marc Vesely schrieb: >> Darum sind AVR-Instructionen 16-bit breit. > Wieso? Was hat das mit der Instructionsbreite zu tun? Weil 2 Register gleichzeitig eingelesen werden. Das ist Takt-1. Addieren und zurückschreiben gehen zusammen in einem Takt. (Und da wird schon die nächste Instruction geholt). Das ist dann der aktuelle Takt. Klarer ?
Marc Vesely schrieb: > Darum sind AVR-Instructionen 16-bit breit. Und werden 1 Takt vorher > eingelesen. Es besteht kein unmittelbarer Zusammenhang zwischen der Codierung eines Befehls und der Breite des Instruction Fetch. Es ist allerdings einfacher, in 16 Bits codierte Befehle als 16-Bit Worte zu lesen. Und AVR ist auf Einfachheit optimiert. > Google mal nach pre-fetch. Die AVRs verwenden normales Pipelining, kein Prefetching. Prefetching ist eine andere Baustelle (z.B. 8088/8086).
A.K. schrieb: > Gewissermassen. Letztlich ist das bei solch simplen Prozessoren grad > jene Zeit, um die der Befehl eine Befehlsfolge verlangsamt. Bei > komplexeren Prozessoren wie denen in PCs oder Handys wirds > komplizierter. Ok, ich verstehe. Danke! :) > Schau mal da rein. Danke für den Link. Ich schau mir das mal durch. > Es gibt kein Gesetz dafür, wie man Befehle aufbaut. Da gibts welche mit > starrer Befehlslänge (z.B. ARM nativ), solche mit schier unendlicher > Variantionsmöglichkeit (x86) und alles dazwischen. Ok, ich dachte das machen alle gleich :P. Marc Vesely schrieb: > Weil 2 Register gleichzeitig eingelesen werden. > Das ist Takt-1. > Addieren und zurückschreiben geht alles in einem Takt. > (Und da wird schon die nächste Instruction geholt). > Das ist dann der aktuelle Takt. > Klarer ? Ja. So langsam komme ich dahinter :) > (Und da wird schon die nächste Instruction geholt). Damit meinst du pipelining, oder?
Samuel J. schrieb: > Wäre das nicht eine Verschwendung, wenn man nur für ein paar Befehle > Konstanten braucht? Dann wäre es doch Ökonomischer, wenn man alle > Befehle, die eine Konstante benötigen, mit 4 Bit adressiert, und für > alle anderen noch ein zusätzliches Bit einführt, welches anzeigt, ob > eine Konstante benötigt wird. Kommt bei Architekturen mit variabler Befehlslänge auch ungefährt so vor. In x86 lassen sich Konstanten mit 8, 16, 32 und 64 Bits direkt im Befehl codieren. Bei fester Befehlslänge hat das natürliche Grenzen, weshalb sich bei ARM Prozessoren Konstanten nicht in voller Breite in einem einzelnen Befehl codieren lassen. Variable Befehlslänge spart Platz, feste Befehlslänge Zeit/Aufwand. Versuch dir mal vorzustellen, wie man einen Befehlsfluss dekodiert, wenn man 4 Befehle pro Takt dekodieren will, von denen jeder einzelne irgendwas zwischen 1 Byte und z.B. 9 Bytes lang sein kann. > Aber das müsste dan bedeuten, dass 2 8-bit breite Busse von dem GPR zur > ALU gehen, oder? Richtig.
@Samuel Wie Du siehst, gibt es hier auch Leute, die in vernüftigem Ton antworten und nicht mitten in der Nacht (in wahrscheinlich volltrunkenem Zustand) Leute anpöbeln. Lerne daraus, merke Dir solche "Helfer" und laß Dich nicht provozieren.
Vielleicht wird Dir ja einiges klarer, wenn Du Dir mal bei opencores einen AVR-Core in VHDL anschaust. Suche einfach mal nach "AVR VHDL".
Marc Vesely schrieb:
> Addieren und zurückschreiben gehen zusammen in einem Takt.
Wie geht das eigentlich?
Ich meine, das ist doch alles Flankengesteuert, oder?
Wenn jetzt die ALU bei der Flanke beide Register (bspw) verundet, dann
steht das Ergebnis ein paar ns später am Datenbus bereit. Jetzt dürfte
aber erst die Flanke für die GPRs kommen, damit diese das Ergebnis vom
Datenbus einlesen können, oder?
g457 schrieb: > Vom Leitwerk. Da der Befehl strukturell eine grosse Ähnlichkeit mit ORI hat, ist durchaus möglich, dass der Datenpfad auch so arbeitet. Dass die Konstante also einen eigentlich überflüssigen Weg durch die ALU nimmt, bevor sie im Register landet.
A. K. schrieb: >> Google mal nach pre-fetch. > > Die AVRs verwenden normales Pipelining, kein Prefetching. Prefetching > ist eine andere Baustelle (z.B. 8088/8086). Da bin ich aber anderer Meinung. Pipelining bezieht sich auf Befehlsverarbeitung. Prefetching ist laden von Instructionen bevor diese tatsächlich verarbeitet werden. AVR hat sowohl Pipelining als auch Prefetching.
@A.K. > Kommt bei Architekturen mit variabler Befehlslänge auch ungefährt so > vor. Ok, danke. Das hilft mir sehr weiter! Perßtiesch-Berater schrieb: > Wie Du siehst, gibt es hier auch Leute, die in vernüftigem Ton > antworten und nicht mitten in der Nacht > (in wahrscheinlich volltrunkenem Zustand) Leute anpöbeln. Meistens bekommt man auch nette und HILFREICHE Antworten, aber manchmal eben nicht. Aber es ist eigentlich nie der Fall, dass man dümmer aus dem Forum geht, als man gekommen ist :D Bitflüsterer schrieb: > Vielleicht wird Dir ja einiges klarer, wenn Du Dir mal bei opencores > einen AVR-Core in VHDL anschaust. Suche einfach mal nach "AVR VHDL". Danke! Werd ich mir mal anschauen. :)
Samuel J. schrieb: > Marc Vesely schrieb: >> Addieren und zurückschreiben gehen zusammen in einem Takt. > > Wie geht das eigentlich? > Ich meine, das ist doch alles Flankengesteuert, oder? > Wenn jetzt die ALU bei der Flanke beide Register (bspw) verundet, dann > steht das Ergebnis ein paar ns später am Datenbus bereit. Jetzt dürfte > aber erst die Flanke für die GPRs kommen, damit diese das Ergebnis vom > Datenbus einlesen können, oder? Nein. Durchaus nicht. Stell Dir eine Kombination aus Addierer und nachfolgendem Register vor. Im vorherigen Takt wurden die Operanden an die Eingänge des Addierers angelegt. Jede Änderung an den Eingängen wird, nach der Durchlaufzeit durch den Addierer an seinem Ausgang reflektiert. Beim nachfolgenden Takt (also dem, von dem wir gerade reden) wird dann das Resultat in das Register geschrieben. Man muss nur darauf achten, das der nachfolgende Takt lange genug, nämlich wenigstens die Durchlaufzeit durch den Addierer lang, nach dem Anlegen der Operanden an die Eingänge stattfindet. Daraus (unter anderem) ergibt sich die maximale Taktfrequenz der CPU (eine simple Struktur vorausgesetzt). Eine Addition ist reine Kombinatorik (jedenfalls nicht notwendigerweise ein mehrschrittiger Prozess).
Marc Vesely schrieb: > Pipelining bezieht sich auf Befehlsverarbeitung. Richtig. Nur ist der Fetch des AVRs Teil davon. Einen zusätzlichen Prefetch gibt es nicht. Wenn ein Instruction Fetch nicht im Timing eines Befehls austaucht, ausser es handelt sich um einen Branch, dann impliziert das nicht notwendigerweise Prefetching. Sondern zunächst nur eine Pipelining. (1) Prefetching kann es z.B. in der Form des 8086 geben. Der hatte einen 5 Byte tiefen Puffer, der vom Prefetcher selbsttätig aufgefüllt und vom Dekoder geleert wurde. Ein separater Instruction Fetch existierte dabei nicht, weil der Puffer direkt den Dekoder fütterte. (2) Moderne Prozessoren versuchen beim Prefetching, Cache Misses vorherzusagen und vorsorglich aus dem Speicher zu holen. Ist im Prinzip ähnlich, die Rolle des Puffers übernimmt hier der Cache. Unter Prefetching versteht man also einen vom Pipelining abgekoppelten Vorgang. Der Instruction Fetch ist bei AVRs aber Teil der Befehlsverarbeitung, ein fester Teil der Pipeline. Somit handelt es sich um normalen Instruction Fetch, keinen Prefetch.
A.K. schrieb: > Man muss nur darauf achten, das der nachfolgende > Takt lange genug ist Das bedeutet, dass die ganze CPU pegel- und nicht flankengengesteuert ist?
Samuel J. schrieb: > A.K. schrieb: >> Man muss nur darauf achten, das der nachfolgende >> Takt lange genug ist > Das bedeutet, dass die ganze CPU pegel- und nicht flankengengesteuert > ist? Genau umgekehrt.
Samuel J. schrieb: > A.K. schrieb: >> Man muss nur darauf achten, das der nachfolgende >> Takt lange genug ist Der Quote stammt nicht von mir. > Das bedeutet, dass die ganze CPU pegel- und nicht flankengengesteuert > ist? Nein. Wo eine Pipeline ist, da sind flankengesteuerte Register. Nämlich zwischen den Stufen. Innerhalb der Stufe kann das pegelgesteuert sein (ok, bei Domino-Logik wird dann interessant ;-).
A. K. schrieb: > Unter Prefetching versteht man also einen vom Pipelining abgekoppelten > Vorgang. Der Instruction Fetch ist bei AVRs aber Teil der > Befehlsverarbeitung, ein fester Teil der Pipeline. Somit handelt es sich > um normalen Instruction Fetch, keinen Prefetch. Auch wieder anderer Meinung als du. Was du meinst ist: " Au Sch.., jmp als nächste Instruction, ganze Arbeit umsonst..." Prefetch ist Prefetch, ob smart oder als Teil der Pipelining ist eigentlich egal.
Lies bitte auch mal: http://de.wikipedia.org/wiki/Mikroprogrammierung Das war der zweite Entwicklungsschritt, nach den fest verdrahteten Schaltwerken. Auf dieser Seite wird auch ein interessanter Simulator verlinkt, mit dem Du selbst mal die Schritte verfolgen kannst. http://www.mikrocodesimulator.de/
Marc Vesely schrieb: > Was du meinst ist: Nein. Worin besteht bei dir der Unterschied zwischen "instruction fetch" und "instruction prefetch"? Bei mir besteht er im "pre", d.h. ein prefetch holt Befehlsworte auf Vorrat, oft bevor sie benötigt werden. Beim AVR ist das nicht der Fall, denn das erste Befehlswort wird in der ersten Stufe der Pipeline exakt zu dem Zeitpunkt geholt, zu dem es benötigt wird. Nicht vorher. Ein Grenzfall war die 68000, deren starrer Fetch-Mechanismus immer 2 Befehlsworte im Bauch hatte, bevor es mit dem Befehl weiter ging. Da das 2. Wort nicht immer gebraucht wurde (Sprung) kann man das dieser Definition gemäss als Prefetching bezeichnen, obwohl es Teil der Pipeline und nicht entkoppelt ist. Das wäre Fall (3). Aber auch dieser Fall trifft auf AVRs nicht zu.
A. K. schrieb: > Vorrat, oft bevor sie benötigt werden. Beim AVR ist das nicht der > Fall, denn das erste Befehlswort wird in der ersten Stufe der Pipeline > exakt zu dem Zeitpunkt geholt, zu dem es benötigt wird. Nicht vorher. Mag sein, dann haben die beim ATMEL keine Ahnung wovon die reden: "While one instruction is being executed, the next instruction is pre-fetched from the program memory".
A.K. schrieb: > Der Quote stammt nicht von mir. Oh, ja habs gerade gesehen. > Nein. Wo eine Pipeline ist, da sind flankengesteuerte Register. Nämlich > zwischen den Stufen. Innerhalb der Stufe kann das pegelgesteuert sein Aber die Pipeline ist ja Teil der Befehlsverarbeitung. Aber die ALU und GPRs sind ja nicht Teil der Pipeline. Sind die dann Pegel oder Flankengesteuert. Denn ich verstehe nicht, wie es sich ausgehen kann, dass die ALU das Ergebnis auf den Datenbus legt, und dann noch im selben Takt die Register das Ergebnis einlesen. Das geht sich ja dann nur mit Pegelsteuerung aus, oder? Bitflüsterer schrieb: > Auf dieser Seite wird auch ein interessanter Simulator verlinkt, mit dem > Du selbst mal die Schritte verfolgen kannst. Oh, danke! Das sieht interessant aus. Ich habe jetzt leider keine Zeit es zu testen, aber ich probiere es am Abend aus.
Marc Vesely schrieb: > Mag sein, dann haben die beim ATMEL keine Ahnung wovon die reden: Scheint so. ;-) Als "While one instruction is being executed, the next instruction is fetched from the program memory." hätte es besser ausgesehen. Weil es bei Atmels Verwendung des Begriffes im sequentiellen Fall keinen "instruction fetch" mehr gibt. Damit kommt man bei der Beschreibung einer Pipeline etwas in die Bredouille.
Samuel J. schrieb: > Sind die dann Pegel oder Flankengesteuert. Die ALU der AVRs ist pegelgesteuert. Das Registerfile übernimmt allerdings neue Inhalte erst zum nächsten Takt. Andernfalls wären Operationen der Art R1=R1+R2 unvorhersagbar.
Samuel J. schrieb: > A.K. schrieb: >> Der Quote stammt nicht von mir. > Oh, ja habs gerade gesehen. Dann wird das wohl ein Zitat von mir sein. Allerdings nicht korrekt zitiert. (Zugegeben, der Satz ist verschachtelt.) > Man muss nur darauf achten, das der nachfolgende Takt lange genug, > ... nach dem Anlegen der Operanden an die Eingänge stattfindet.
A.K. schrieb: >Andernfalls wären Operationen der Art R1=R1+R2 unvorhersagbar. Also nach deiner Aussage währe es so: Befehl decodieren uws... nächster Takt: Inhalt der GPR an eingang der ALU legen nächster Takt: ALU berechnen lassen nächster Takt: In 1. Register Ergebnis schreiben Bitflüsterer schrieb: >Jede Änderung an den Eingängen wird, nach der Durchlaufzeit > durch den Addierer an seinem Ausgang reflektiert. Beim nachfolgenden > Takt (also dem, von dem wir gerade reden) wird dann das Resultat in das > Register geschrieben. Man muss nur darauf achten, das der nachfolgende > Takt lange genug, nämlich wenigstens die Durchlaufzeit durch den > Addierer lang, nach dem Anlegen der Operanden an die Eingänge > stattfindet. (Ich habe jetzt einfach mal alles zitiert :D) Dann währe das: Befehl decodieren... nächster Takt: Inhalt der Register an ALU anlegen nächster Takt: Berechnen und wieder zurückschreiben Richtig?
Samuel J. schrieb: > Dann währe das: > Befehl decodieren... > nächster Takt: Inhalt der Register an ALU anlegen > nächster Takt: Berechnen und wieder zurückschreiben > Richtig? Nein. 1. Takt: Ende der vorherigen Operation. PC +1 a. Laufzeit: OP-Code holen, Dekodierung, Registerinhalte auf ALU-Eingänge. Berechnung des Resultats 2. Takt: Übernahme des Resultats, PC +1 b. Laufzeit: OP-Code holen, Dekodierung ... Mach Dir klar, was rein kombinatorische Vorgänge sind und was Zustandsübergänge. Das "holen" des OP-Code, seine Dekodierung und die daraus resultierende "Veröffentlichung" der Register-Inhalte für die ALU sind (in diesem einfachen Fall) rein kombinatorische Vorgänge. Ein Takt ist dazu nicht notwendig. Der Terminus "holen" für den OP-Code ist insofern auch leicht irreführend. Was aber einen Takt benötigt (oder jedenfalls so implementiert werden kann) ist die Übernahme des Resultats und die Inkrementierung des PC (Adressregisters). Am besten man stellt sich das mal graphisch vor (mir wenigstens hilft das). Es wird hier willkürlich angenommen, dass die Übergänge bei fallenden Flanken geschehen und das ein zwei Register-Befehl mit Ergebnis in einem Register ausgeführt wird. Takt stationärer Zustand Übergang (Kombinatorisch) (Flanke) +-+ ...............................> Finale Aktion vorheriger Befehl | PC liegt an. | OP-Code ist präsent | und dekodiert. (Laufzeit) | Registerinhalte liegen | an ALU-Eing. | Operation läuft | und endet. (Gatterlaufz.) +-+ . . . +-+................................> Ergebnis wird | im Zielregister | gespeichert. PC | inkrementiert. | . . . +-+ --- Mich irritiert übrigens irgendwie Dein insistieren auf "Pegel- oder Flankengesteuert". Ich bin nicht sicher ob Du das selbe darunter verstehst wie ich oder ein Dritter. So wie ich das auffasse, spielt diese Frage bei Flip-Flops eine Rolle. Siehe http://de.wikipedia.org/wiki/Flipflop#Taktzustands-_und_taktflankengesteuerte_Flipflops Ein Addierer oder ähnliches hingegen ist (in der Regel nur) kombinatorische Logik. Da spielt die Frage keine Rolle. Könntest Du bitte erklären, warum Du danach fragst?
Ich empfehle Dir mal folgende Aufgabe zu lösen: Skiziere auf dem Bildschirm (Zeichenprogramm) eine Struktur, die aus folgendem besteht: 1. Speicher (enhält OP-Codes) 2. Adressregister 3. Datenregister (Vier Stück - Auwahl via Opcode) 4. Addierer 5. Decoder (was dekodiert der in diesem Fall?) Eine primitive Maschine, die also nur eine Folge von Additionsbefehlen erhält, deren einziger variabler Inhalt drei Daten sind, die zwei Quellregister und ein Zielregister angeben. Dann sollte einiges klarer werden. Das Problem ist bei diesen Fragen auch, dass es viele mögliche Strukturen gibt. Es ist aber am besten wenn Du einfach mal mit dem primitiven beginnst und dann zum komplexeren fortschreitest. Alles auf einmal betrachten zu wollen, verwirrt nur - meine ich jedenfalls.
@Bitflüsterer: Danke! Diese Grafik hilft mir wirklich sehr! > Mich irritiert übrigens irgendwie Dein insistieren auf "Pegel- oder > Flankengesteuert". Ich bin nicht sicher ob Du das selbe darunter > verstehst wie ich oder ein Dritter. Ich meine es so: Pegelgesteuert: Des Ausgang kann sich währen des ganzen Pegels ändern. Flankengesteuert: Die Eingänge müssen VOR der Taktflanke anliegen, und werden dann bei der Taktflanke eingelesen (bei einem Addierer übernommen und berechnet). >Skiziere... Ok, mach ich.
Angehängte Dateien:
-

2014-09-06_17.16.00.jpg
780 KB
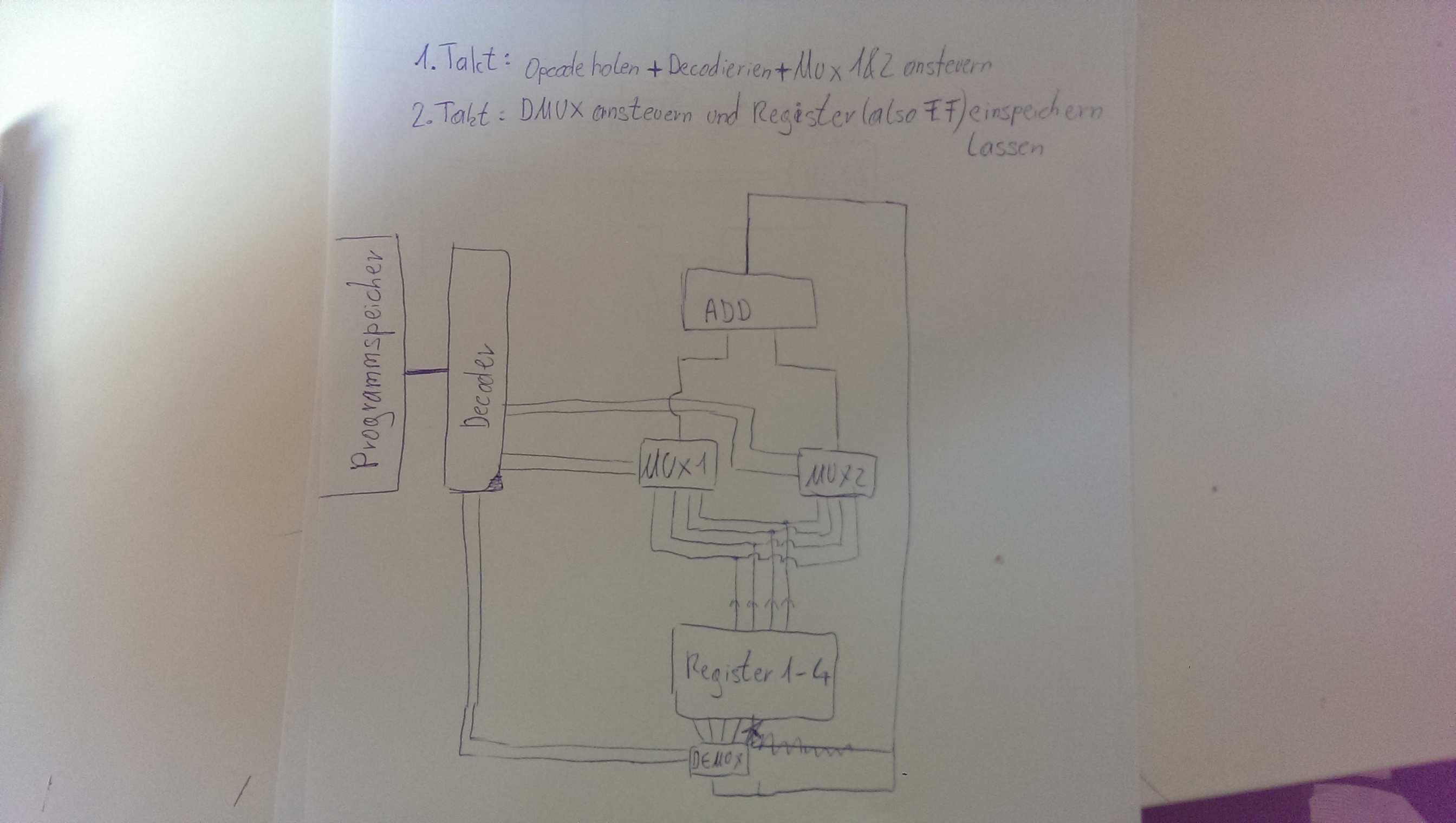
Ich hätte es jetzt so gemacht. Aber für was brauch ich dann noch das Adressregister?
OK. (Du hast nur Demultiplexer und Multiplexer verwechselt. Aber das wächst sich 'raus :-) ) Ich habe eine Taktsteuerung nicht erwähnt, sie aber vorausgesetzt. Wovon reden wir denn die ganze Zeit? ;-) Das Adressregister brauchst Du um eine Folge von Befehlen abarbeiten zu können. Im Moment geht das noch nicht.
Inhaltlich fällt mir gerade noch auf, dass die Steuerung des Multiplexers schon in dem Zeitraum nach der ersten Taktflanke erfolgen muss. Das geht ja auch, denn die Information steckt im Befehl. Wenn das erst beim zweiten erfolgt, dann ist es schon zu spät, denn in dem Augenblick soll ja das Resultat schon gespeichert werden.
> OK. (Du hast nur Demultiplexer und Multiplexer verwechselt. Aber das > wächst sich 'raus :-) ) Aber ein Multiplexer fasst doch mehrere Leitungen auf eine zusammen, oder? Dann hätte ich es ja richtig :) > Ich habe eine Taktsteuerung nicht erwähnt, sie aber vorausgesetzt. Wovon > reden wir denn die ganze Zeit? ;-) ohh ja stimmt :D Aber dann geht ja einfach immer eine CLK leitung zu den verschiedenen Bauteilen oder? > Das Adressregister brauchst Du um eine Folge von Befehlen abarbeiten zu > können. Im Moment geht das noch nicht. Hmm.. ok das mit den Adressregistern muss ich mir noch anschauen. Ich habe jetzt leider keine Zeit mehr aber werde es mir dann später noch etwas dazu durchlesen :) Vielen Dank für eure Hilfe! :)
Samuel J. schrieb: >> OK. (Du hast nur Demultiplexer und Multiplexer verwechselt. Aber das >> wächst sich 'raus :-) ) > Aber ein Multiplexer fasst doch mehrere Leitungen auf eine zusammen, > oder? > Dann hätte ich es ja richtig :) Au weia. Aber mach' Dir nichts d'raus. Ich verzeihe Dir, das Du mich diesen Fehler hast machen lassen. :-) >> Ich habe eine Taktsteuerung nicht erwähnt, sie aber vorausgesetzt. Wovon >> reden wir denn die ganze Zeit? ;-) > ohh ja stimmt :D > Aber dann geht ja einfach immer eine CLK leitung zu den verschiedenen > Bauteilen oder? Naja. Am Anfang sind die einfachen Sachen noch schwer. Es scheint mir wichtig, sich klar zu machen, was auf Flanken reagiert und was nicht. Der nächste Schritt wäre dann, anhand dessen zu überlegen und einzuzeichnen, wo Laufzeiten eine Rolle spielen und wie sie zu den Flankengesteuerten Einheiten stehen. >> Das Adressregister brauchst Du um eine Folge von Befehlen abarbeiten zu >> können. Im Moment geht das noch nicht. > Hmm.. ok das mit den Adressregistern muss ich mir noch anschauen. Ich > habe jetzt leider keine Zeit mehr aber werde es mir dann später noch > etwas dazu durchlesen :) > > Vielen Dank für eure Hilfe! :) Tja dann ...
In diesem Stadium der Diskussion, also bei Details zu Muxern, Registern usw wäre es wirklich angebracht, mal bei dem oben verlinkten Modell der Mikroarchitektur vorbei zu schauen. Wozu darin allerdings 7 Adessbits für Register auftauchen leuchtet mit nicht ein. Falls er die I/O-Register mit eingemeindet hatte, dann sollte man sich das wegdenken und auf 5 Adressbits gehen, denn Bitset/clear-Ops auf I/O brauchen bei den klassischen AVRs 2 Takte. Deren I/O-Register sind also mit RAM vergleichbar, nicht mit GPRs.
Bitflüsterer schrieb: > Au weia. Aber mach' Dir nichts d'raus. Ich verzeihe Dir, das Du mich > diesen Fehler hast machen lassen. :-) Da bei ihm das Wasser den Berg rauf fliesst, also der Hauptdatenpfad unten beginnt und oben endet, kann man schon mal stolpern. ;-)
Samuel J. schrieb: > A.K. schrieb: >> Man muss nur darauf achten, das der nachfolgende >> Takt lange genug ist > Das bedeutet, dass die ganze CPU pegel- und nicht flankengengesteuert > ist? Nicht notwendigerweise. Es gibt sowohl CPU bei denen alle internen Vorgänge strikt taktsynchron laufen. Z.B. der Z80 oder 8051. Und es gibt CPU-Designs, die intern weitgehend asynchron arbeiten. Z.B. der 6502. Meist ist es eine Mischung aus beidem. XL
Axel Schwenke schrieb: > Nicht notwendigerweise. ... Bei allem Respekt, Axel: Du schreibst ja hier nicht jemandem der die Grundlagen kennt und schon mal zwei- oder drei UP-Strukturen angeschaut hat, sondern einem Anfänger der so gut wie garkeine Ahnung hat. Hälst Du da Deinen Hinweis (wenn er auch korrekt er sein mag) wirklich für notwendig und hilfreich? Ich finde, er kompliziert die Lernsituation eher.
Bitflüsterer schrieb: > Bei allem Respekt, Axel: Du schreibst ja hier nicht jemandem der die > Grundlagen kennt und schon mal zwei- oder drei UP-Strukturen angeschaut > hat, sondern einem Anfänger der so gut wie garkeine Ahnung hat. Hälst Du > da Deinen Hinweis (wenn er auch korrekt er sein mag) wirklich für > notwendig und hilfreich? Ja.
Der Punkt ist, dass das alles nicht so einfach ist, weil es eben viele Möglichkeiten gibt und die auch in verschiedensten Mischformen im Einsatz sind. Manche CPUs nutzen den externen Takt, um die internen Verarbeitungsschritte zu synchronisieren. Dann dauern Befehle einfach mehrere Takte. Andere CPUs lassen sich nicht nur mit einem Taktsignal füttern, sondern auch mit einem dazu verschobenen Taktsignal. Auch damit kannst du die internen Einheiten der CPU synchronisieren, so dass du für jeden Befehl nur einen oder zwei Takte brauchst. Wieder andere CPUs generieren sich aus dem angelegten Takt einen höheren internen Takt, und führen mit dem dann alle Einzelschritte flankengesteuert und synchronisiert durch. Dann dauern komplexe Befehle nur "einen Takt", aber intern sind das dann mehrere, wie du ganz oben skizziert hast. Schließlich gibt es noch die Möglichkeit, dass jemand ausgerechnet hat, wie lange die einzelnen Werke der CPU brauchen, und dann mit "Verzögerungsleitungen" den Takt einfach so schnell (bzw. etwas langsamer) mitführen, wie die Kombinatorik arbeiten kann. Und all das wird oder wurde in Prozessorarchitekturen verwendet, und schließt sich auch nicht gegeneinander aus. In freier Wildbahn wirst du also auch auf Mischformen treffen. Das war das, was dir der Axel sagen wollte. ;-) Von der großen weiten Welt der Dinge, die das alles noch viel komplizierter (und schneller) machen, rede ich lieber nicht.
Das war das, was dir der Axel sagen wollte. ;-) Wieso mir? Meinst Du den TO? Und woraus ergab sich die Notwendigkeit dies in diesem Thread, zu dem gegebenen Stand des Dialogs zu schreiben? Wenn jemand grundsätzlich den einfachsten Fall erstmal verstehen und nachvollziehen will, dann hat es doch wenig Sinn, ihm noch alle möglichen Alternativen, Folgen aus Nebenumständen oder Optimierungen dazu zu servieren. Das verwirrt eher, weil er noch garnichts hat, wo er das einordnen kann. Die Alternativen etc. behandelt man hinterher und sagt dazu, dass das vorher Gelehrte in dieser und jener Hinsicht verbessert oder erweitert werden kann oder unter diesen und jenen Umständen anders betrachtet werden muss. Es geht doch in so einem Forum, bei so einer Fragestellung nicht darum, den TO mit allem möglichen Wissen zu "bombardieren", dass zwar korrekt, aber didaktisch völlig fehl Platze ist, sondern ihm das Thema methodisch und klar verständlich, schrittweise und folgerichtig nahe zu bringen. Sieh' Dir doch den Thread an. Der TO wusste am Anfang noch nicht wie ein Befehl aufgebaut ist, wann evtl. Multiplexer zu schalten sind und solch "einfaches" Zeug. Und erst vier Postings oder so vor diesem hier, hat er anhand des Diagramms von mir erkannt, wann was passiert und kurz danach das erstemal selbst so eine Struktur in einer ganz primitiven Variante gezeichnet. Was willst Du ihm da mit internen Takten, Laufzeitausgleich oder Pipelines (das war nicht von Dir, kam aber recht früh als Begriff in's Spiel) kommen? Ich sag ja nicht, dass er das nicht irgendwann mal brauchen kann, aber es ist zu früh. Das ist doch so schwer nicht einzusehen. Meine Güte.
Bitflüsterer schrieb: > Und woraus ergab sich die Notwendigkeit dies in diesem Thread, zu dem > gegebenen Stand des Dialogs zu schreiben? Damit wollte ich dem TO den Zahn ziehen, daß man CPU nur entweder synchron oder asynchron bauen kann. Genauso wie wir ihn vorher von der Idee abbringen mußten, daß - wenn Maschinenbefehle aus Präfix und Operanden bestehen - die Präfixe für alle Maschinenbefehle gleich lang sein müßten. Natürlich könnte und sollte man das alles viel genauer und ausführlicher beschreiben. Allerdings ist ein Forum eher nicht der richtige Platz dafür. Und es ist ja auch nicht so, daß man diese Information nirgendwo finden könnte. Jede Website, wo jemand seine eigene CPU gebaut hat, muß auf das Thema (mehr oder weniger tief) eingehen. Es gibt auch etliche Seiten, die existierende CPU Designs im Detail beleuchten. Für den 6502 gibts sogar eine Visualisierung auf Chipebene (http://www.visual6502.org/). Und für den Z80 hat letztens mal einer den Link auf einen Artikel gepostet, der auseinandernimmt wie die ALU des Z80 denn wirklich arbeitet (mit 4 Bit, pipelined). Und schließlich gibts auch Information außerhalb des Webs. Wenn ich in meinem Bucherschrank schaue, dann stehen da mindestens 5 Bücher, die das Thema von der einen oder anderen Seite behandeln. Wenn etwas nichts in diesem Thread zu suchen hat, dann eher der (IMHO kleinliche) Streit darüber, ob der AVR nun einen Prefetch für das erste Wort der Folgeinstruktion macht oder ob das das zarte Anfangsstadium einer Pipeline ist. XL Nachtrag: http://www.msxarchive.nl/pub/msx/mirrors/msx2.com/zaks/z80prg02.htm http://www.righto.com/2013/09/the-z-80-has-4-bit-alu-heres-how-it.html
Bitflüsterer schrieb: > Wieso mir? Meinst Du den TO? Ja. > Und woraus ergab sich die Notwendigkeit dies in diesem Thread, zu dem > gegebenen Stand des Dialogs zu schreiben? Ich finde es wichtig, dass man öfter mal darauf hinweist, dass man gerade einen Ansatz unter vielen erklärt und man in der Realität höchstwahrscheinlich auf Mischformen treffen wird, und kurz andere Ansätze anzureißen. Einfach nur, um klarzustellen, dass der einfache Fall eben nicht der allgemeine Fall ist, was sonst sehr schnell passiert.
Nun, ich sehe wir können uns darüber (bisher) nicht einig werden. Was für Euch am Rande hinzugefügte Bemerkungen sind (S.R.) oder Aufklärungen über alternative Implementierungen (Axel) sind für mich (immer noch) vom Grundlagenthema ablenkende Gesichtspunkte. Wiegesagt: Inhaltlich habe ich nichts dagegen einzuwenden, aber es hilft beim Grundlagenverständnis nicht weiter. Ich verstehe Euren Standpunkt auch wenn ich ihn nicht teile. Damit werden wir dann wohl erstmal leben müssen, falls sich der TO wieder meldet. Aber ich habe einen Vorschlag. Was haltet Ihr davon, das primitive Beispiel, dass ich hier Beitrag "Re: Opcode AVR Frage" vorschlug, mal als asynchrones Design zu beschreiben (Skizze)? Das iat für den TO sicher erhellend.
Bitflüsterer schrieb: > Was für Euch am Rande hinzugefügte Bemerkungen sind (S.R.) oder > Aufklärungen über alternative Implementierungen (Axel) sind für mich > (immer noch) vom Grundlagenthema ablenkende Gesichtspunkte. Wiegesagt: > Inhaltlich habe ich nichts dagegen einzuwenden, aber es hilft beim > Grundlagenverständnis nicht weiter. Sicher. Junge, wenn du über die Straße gehst, immer zuerst nach Links gucken. Ok, Pappi, kein Problem - der kleine Hans ist weg. Au Sch..., wir leben ja in einer Einbahnstrasse, das wollte ich ihm aber erst später beibringen...
Hallo an Alle! Ich habe mir jetzt mal eine Linkssammlung, mit den ganzen Links die ihr mir gegeben habt, erstellt und werde diese heute durcharbeiten. Und dann schau ich mir noch den Mikrocode Simulator an. Wenn ich Fragen habe dann meld ich mich wieder :) Bitflüsterer schrieb: > Aber ich habe einen Vorschlag. Was haltet Ihr davon, das primitive > Beispiel, dass ich hier > Beitrag "Re: Opcode AVR Frage" vorschlug, mal als > asynchrones Design zu beschreiben (Skizze)? Das wäre natürlich sehr hilfreich, danke! Aber ich fände es besser, wenn ich mich mal durch die ganzen Links durcharbeite und dadurch vielleicht GANZ wenige Grundkenntnisse zu haben, damit ihr euch nicht mit so Fragen wie "für was ist das Adressregister" herumschlagen müsst. Aber nochmal danke für eure Hilfe!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.