Hallo,
Ich grübel gerade mal wieder ein wenig über geeigneten Programmierstil
speziell in der Regelungstechnik.
Vor einer Weile habe ich meine Heizungsregelung in Python implementiert.
Eigentlich um die "Modesprache" auch mal auszuprobieren und weil ich als
meistens C programmierender Mensch OO eher theoretisch kennengelernt
habe.
Die Regelung ist schon relativ umfangreich, weil allerlei Gimmicks mit
Solar usw. enthalten sind. Also ein paar PID regler, allerlei
Hysteresekram und so. Das ganze funktioniert schon eine Weile recht gut,
aber trotzdem bin ich nicht ganz glücklich.
Im Vorfeld hatte ich ein paar Experimente mit scilab/scicos gemacht. Und
grundsätzlich wäre es vermutlich recht unkompliziert möglich ein
komplettes Modell der Regelung in scicos zu realisieren.
Soweit ich weiß kann man aus scicos auch direkt Code generieren lassen?
Eigentlich wäre es mir lieber den Code schon per Hand zu schreiben, aber
in einer Weise die sich möglichst nahe an dem Simulationsmodell bewegt.
Von meinem Objektorientierten Ansatz kann man das nun leider nicht
unbedingt behaupten. Es gibt zwar schon allerlei OO-Techniken, die sich
nutzbringend einsetzen lassen, aber der OO-Grundgedanke, dass es Objekte
gibt, die Nachrichten austauschen, entspricht meiner Meinung nach nur
bedingt einem Regelungsmodell.
Kürzlich bin ich über ein Interview mit J. Paul Morrison gestolpert über
das Thema Flow based Programming und habe mir dabei gedacht "ja, das
isses eigentlich!". Die Projekte die daraus hervorgegangen sind scheinen
mir aber eine Nummer zu groß, bzw. auch nicht ganz passend.
http://noflojs.org/ sieht dabei sehr interessant aus, aber hilft mir
nicht direkt weiter.
Ich meine mich an eine Bemerkung im Web zu erinnern, dass die scicos
Modelle eigentlich auch schon als grafische datenflussorientierte
Programmiersprache zu verstehen sind. Und an anderen Stellen wiederum
finden sich Hinweise, dass das Flow-Based Paradigma quasi eine Teilmenge
der funktionalen Programmierung darstellt.
Daher habe ich mich gefragt, ob eine funktionale Programmiersprache eine
Möglichkeit sein könnte so ein Regelungsmodell elegant zu
implementieren.
Da stellt sich aber das nächste Problem, dass mir eigentlich gar nicht
so ganz 100% klar ist, was eine funktionale Programmiersprache
eigentlich auszeichnet.
Pure Functions, Lambda Ausdrücke, closures und continuations tauchen in
dem Dunstkreis vermehrt auf. Z.T. erscheint mir manches sehr vertraut
und bekommt nur einen neuen Namen, vieles macht aber auch einen eher
dubiosen Eindruck auf mich :-).
Ist es nun zweckmäßig Lisp oder Haskell zu lernen um elegant Regler
programmieren zu können?
Python nennt sich Multiparadigmensprache und behauptet von sich auch
funktionale Programmierung zu unterstützen.
Kürzlich habe ich mal so im "Trockenversuch" über eine geeignete
Programmstruktur meines Reglers nachgedacht und bin schnell auf die Idee
gekommen, dass Rekursion sehr praktisch wäre, wenn man die Ideale der
funktionalen Programmierung ("reine", mathematische Funktionen)
beherzigen möchte. Aber da Python keine optimierung der Ende-Rekursion
unterstützt ohne den Stack zu füllen (richtig?), wäre damit in Python
schon das Ende der Fahnenstange erreicht?
In der funktionalen Programmierung wird ja eher so eine stateless
Struktur angestrebt, weil eine Funktion sonst ja nicht mehr "rein" wäre.
Nun ist mein Regelungsmodell aber prinzipbedingt alles andere als
stateless.
Irgendwie muss die Implementierung so eines Modells auf einem Computer
ja immer Wert- und Zeitdiskret sein. Es ist schließlich kein
Analogrechner.
D.h. die Berechnung der Regelungsergebnisse muss zwangsläufig iterativ,
oder eben auch rekursiv erfolgen.
Man könnte nun auf die (absurde?) Idee kommen und eine Funktion
schreiben, welche das komplette Reglermodell darstellt und aus allen
Soll- und Istwerten aber eben auch aus dem Zustand der vorhergenden
Iteration bzw. Rekursion die aktuellen Ausgangswerte berechnet sowie
auch Zustände wie z.b. Hysterese, Integratoren usw. In der Funktion
selbst wären aber keinerlei Zustände gespeichert und sie wäre im
mathematischen Sinne "rein". Die Funktion könnte sich dann in geeigneter
Weise rekursiv aufrufen.
Das hätte natürlich schon seinen charme, weil sich die Korrektheit der
Funktion recht einfach durch ein geeignetes Testprogramm nachweisen
lassen würde.
Andererseits hätte die Funktion eine irre Schnittstelle und ob das dann
insgesamt besser wartbar wäre habe ich meine Zweifel.
Habe ich jetzt "funktionale Programmierung" bereits im Ansatz völlig
falsch verstanden?
Bisher sehe ich jedenfalls noch nicht wo sich dabei die Ideen der
datenflussorientierten Programmierung widerspiegeln sollen?
Also jedenfalls alles gar nicht so einfach :-).
Viele Grüße,
Klaus
Manche beschäftigen sich mit Problemlösungen, für andere sind Probleme
die Lösung zur Beschäftigung...
Anstatt sich in Regelungstechnik & gute Programmierstile (=> Design
Pattern)
möglichst gut einzuarbeiten, fummelt man lieber an Simulationen und
exotischen Programmiersprachen rum...
Da das Problem das Ziel ist, ist eine zweckdienliche Hilfe sicher
unerwünscht...
Hallo,
um auch ein wenig "nutzlosen" Input zu geben.
Vielleicht lohnt sich der Blick auf die Sprache Erlang.
Die soll auch auf embedded Systemen laufen, z.B. Rasperry Pi.
Erlang ist eine funktionale Programmiersprache.
http://www.erlang-embedded.com/
Klaus W. schrieb:> aber der OO-Grundgedanke, dass es Objekte> gibt, die Nachrichten austauschen, entspricht meiner Meinung nach nur> bedingt einem Regelungsmodell.
Dann hast du OO-Programmierung nicht verstanden.
Ist doch ganz simpel: Man schreibt eine abstrakte Basisklasse
TRegulator
Die in ihrer einfachsten Form erstmal nur ein Property, eine Methode und
ein Event besitzt:
property NominalValue as <T(computable)>
MeasureSample(Sample as <T(computable)>)
event ControlValue(Value as <T(computable)>)
Von dieser Klasse leitet man dann z.B. einen P-Regler einen I-Regler und
einen D-Regler ab, die allesamt im Wesentlichen mit derselben Signatur
auskommen, diese allerdings durch ein zusätzliches Felder/Member oder
wie immer das die konkrete Ausprägung des OO-Paradigmas nennt erweitern:
property K as <T(computable)>
Dann schreibt man vielleicht noch einen PID-Regler, auch der kommt im
Wesentlichen mit der ererbten Signatur aus, benötigt allerdings drei
zusätzliche Felder/Member oder wie immer das die konkrete Ausprägung des
OO-Paradigmas nennt:
PRegulator as TREgulator
DRegulator as TREgulator
IRegulator as TREgulator
Diesen Feldern muß man dann natürlich Instanzen der Implementierungen
eines P,I bzw. D-Reglers zuweisen.
Alles in allem kann das fast als Paradebeispiel für OO-Programmierung
dienen. Allerdings soll mich der Teufel holen, falls ich jemals in
Versuchung kommen sollte, sowas auf einem µC tatsächlich in dieser Art
zu schreiben...
Klaus W. schrieb:> Soweit ich weiß kann man aus scicos auch direkt Code generieren lassen?
Weiß ich nicht, hab damit noch nie gearbeitet.
> Eigentlich wäre es mir lieber den Code schon per Hand zu schreiben, aber> in einer Weise die sich möglichst nahe an dem Simulationsmodell bewegt.>> Von meinem Objektorientierten Ansatz kann man das nun leider nicht> unbedingt behaupten. Es gibt zwar schon allerlei OO-Techniken, die sich> nutzbringend einsetzen lassen, aber der OO-Grundgedanke, dass es Objekte> gibt, die Nachrichten austauschen, entspricht meiner Meinung nach nur> bedingt einem Regelungsmodell.>> Kürzlich bin ich über ein Interview mit J. Paul Morrison gestolpert über> das Thema Flow based Programming und habe mir dabei gedacht "ja, das> isses eigentlich!".
Ja, FBP passt ganz gut zur Implementierung von Reglern und zur
Simulation von Regelstrecken, da man es dort schwerpunktmäßig mit
Datenströmen zu tun hat. Die einzelnen Übertragungsglieder nehmen am
Eingang jeweils einen Datenstrom auf, verarbeiten ihn und geben die
Ergebnisse wieder als Datenstrom aus.
> Ich meine mich an eine Bemerkung im Web zu erinnern, dass die scicos> Modelle eigentlich auch schon als grafische datenflussorientierte> Programmiersprache zu verstehen sind.
So ist es. Auch Simulink und Labview sind datenflussorientierte
grafische Sprachen. Für bestimmte Anwendungsfelder (aber beileibe nicht
für alle) ist der datenflussorientierte Ansatz – egal ob grafisch oder
textuell – der bessere als der imperative.
> Und an anderen Stellen wiederum finden sich Hinweise, dass das> Flow-Based Paradigma quasi eine Teilmenge der funktionalen> Programmierung darstellt.
Ich würde es eher so sehen, dass die Datenflussprogrammierung einige
die FP kennzeichnenden Konzeepte (wie z.B. die Unveränderlichkeit von
Variablen und die weitgehende Nebeneffektfreiheit von Funktionen)
umsetzt.
Allerdings bieten viele funktionale Programmiersprachen Mittel an, die
neben vielen anderen Dingen auch Entwicklung von datenflussorientierten
DSLs (domain specific languages) unterstützen. Aber auch in OO-Sprachen
wie C++ kommt man recht weit, wie bspw. die Boost.Dataflow-Bibliothek
zeigt:
http://dancinghacker.com/code/dataflow/> Daher habe ich mich gefragt, ob eine funktionale Programmiersprache eine> Möglichkeit sein könnte so ein Regelungsmodell elegant zu> implementieren.
Prinzipiell ja, weil man damit sehr gut nicht nur mit Datenstrukturen,
sondern mit ganzen Berechnungen herumjonglieren kann. Diese Berechnungen
sind in der Regelungstechnik die Übertragungsglieder, die man auf
komfortable Weise miteinander zu komplexeren Gebilden kombinieren
möchte.
> Ist es nun zweckmäßig Lisp oder Haskell zu lernen um elegant Regler> programmieren zu können?
Nur dafür würde ich es nicht tun, da ist der Einarbeitungsaufwand zu
hoch. Wenn du aber generell daran interessiert bist, etwas über den
Tellerrand zu schauen und zu sehen, wie sich die Programmierung abseits
von C, C++ und Java anfühlen kann: nur zu!
Selbst wenn du FP nicht primär für deine zukünftigen Projekte einsetzen
möchtest, verbessert die Beschäftigung damit auch deinen Programmierstil
in klassischen Sprachen.
> Python nennt sich Multiparadigmensprache und behauptet von sich auch> funktionale Programmierung zu unterstützen.>> Kürzlich habe ich mal so im "Trockenversuch" über eine geeignete> Programmstruktur meines Reglers nachgedacht und bin schnell auf die Idee> gekommen, dass Rekursion sehr praktisch wäre, wenn man die Ideale der> funktionalen Programmierung ("reine", mathematische Funktionen)> beherzigen möchte. Aber da Python keine optimierung der Ende-Rekursion> unterstützt ohne den Stack zu füllen (richtig?), wäre damit in Python> schon das Ende der Fahnenstange erreicht?
Python bietet noch andere interessante Mittel zur Unterstützung von
datenflussorientierter Programmierung, allen voran die Generatoren.
Explizite Rekursion wird auch in Funktionalsprachen seltener eingesetzt,
als die meisten Tutorials (die gleich als eines der ersten Beispiele die
rekursive Definition der Fakultätsfunktion bringen) vermuten lassen.
> In der funktionalen Programmierung wird ja eher so eine stateless> Struktur angestrebt, weil eine Funktion sonst ja nicht mehr "rein" wäre.> Nun ist mein Regelungsmodell aber prinzipbedingt alles andere als> stateless.
Ja, die vermeidbare Verwendung veränderlicher Zustände sind in der FP
zunächst einmal schlechter Stil, da sie die Überprüfung des Codes auf
Korrektheit (egal ob automatisch oder manuell) erschwert. In Programmen
für die reale Welt kommt man aber um Zustände nicht immer herum, sei es
aus Effizienzgründen oder weil durch die Natur vorgegeben (I/O ist bspw.
immer zustandsbehaftet).
> Man könnte nun auf die (absurde?) Idee kommen und eine Funktion> schreiben, welche das komplette Reglermodell darstellt und aus allen> Soll- und Istwerten aber eben auch aus dem Zustand der vorhergenden> Iteration bzw. Rekursion die aktuellen Ausgangswerte berechnet sowie> auch Zustände wie z.b. Hysterese, Integratoren usw. In der Funktion> selbst wären aber keinerlei Zustände gespeichert und sie wäre im> mathematischen Sinne "rein". Die Funktion könnte sich dann in geeigneter> Weise rekursiv aufrufen.
Die Idee ist nicht absurd, sondern ein grundlegendes Konzept, das
tatsächlich – wenn auch in stark elaborierter Form – in der FP angewandt
wird. So beruhen bspw. die Monaden in Haskell auf diesem Grundgedanken,
sind aber allgemeiner und abstrakter definiert, dass man sie noch für
viele andere Dinge verwenden kann (sogar viel mehr als deren "Erfinder"
ursprünglich ahnen konnten).
> Andererseits hätte die Funktion eine irre Schnittstelle und ob das dann> insgesamt besser wartbar wäre habe ich meine Zweifel.
Richtig, deswegen wird in den Monaden den Zustand gekapselt, so dass er,
wenn überhaupt, nur dort sichtbar wird, wo er auch wirklich gebraucht
wird.
> Habe ich jetzt "funktionale Programmierung" bereits im Ansatz völlig> falsch verstanden?
Nein, das was du geschrieben hast, hat Hand und Fuß. Es gibt aber noch
viele weitere Aspekte der FP, die du am besten dadurch erfährst, dass du
dir Einen Compiler oder Interpreter für Haskell, OCaml, F# oder was auch
immer, installierst und ein Anfängertutorial dazu durcharbeitest.
> Bisher sehe ich jedenfalls noch nicht wo sich dabei die Ideen der> datenflussorientierten Programmierung widerspiegeln sollen?
In Haskell gibt es bspw. noch das Kozept der Arrows. Das ist ein
alternativer Weg dur Darstellung von Berechnungen. Sie haben eine
gewisse Ähnlichkeit mit Monaden, sind aber noch allgemeiner gehalten.
Wenn du dir die Bilder auf folgenden Seiten anschaust, merkst du sicher,
wohin der Hase läuft (auch wenn du den Rest ganz sicher (noch) nicht
verstehen wirst):
http://www.haskell.org/arrows/http://www.haskell.org/arrows/syntax.html
Ein anderes Stichwort ist FRP:
http://en.wikipedia.org/wiki/Functional_reactive_programming
Damit hält ein wichtiger Aspekt in die FP Einzug, nämlich die Zeit.
Nur um dich ein Bisschen anzuteasen, hier ein paar Bilder zu Yampa,
einer FRP-Bibliothek für Haskell (bei Weitem nicht der einzigen):
http://www.haskell.org/haskellwiki/Yampahttp://www.haskell.org/haskellwiki/Yampa/pSwitch
Die Idee bei der FRP liegt darin, nicht mit einzelnen Zahlenwerten zu
hantieren, sondern mit kompletten (i.Allg. sogar endlosen) zeitlichen
Verläufen. Diese Verläufen können quasi-kontinuierlich (bspw. ein
Sensordatenstrom) oder zeitdiskret (bspw. in unregelmäßigen Abständen
eintreffende Events) sein. Da diese Verläufe aber immer als Ganzes
betrachtet werden können sie mit mathematisch reinen (nebeneffektfreien)
Funktionen verarbeitet und ineinander übergeführt werden. So sind z.B.
die Integration oder Differentiation reine Funktionen, wenn man in
ganzen Verläufen denkt, nicht aber, wenn man immer nur die einzelnen,
jeweils aktuellen Zahlenwerte betrachtet.
Um ein wenig auf den Geschmack zu kommen, muss man sich aber nicht
unbedingt mit Arrows und FRP herumschlagen. Für den Anfang reichen
einfache Listen von Zahlenwerten. Damit kann man in der Regelungstechnik
oder der Signalverarbeitung im festen Takt eingelesene Sensordaten oder
Sollwerte darstellen und diese mittels reiner Funktionen zu einer
ebensolchen Liste mit Stellwerten verarbeiten. Viele Funktionalsprachen
unterstützen lazy Evaluation
http://en.wikipedia.org/wiki/Lazy_evaluation
(in Haskell ist diese Auswertemethode sogar Default), so dass von den
Listen immer nur diejenigen Elemente gespeichert und berechnet werden,
die gerade benötigt werden. Damit ist es insbesondere möglich, mit
endlosen Listen zu arbeiten. Der Regler soll ja schließlich nicht nach
dem einmillionsten Sensorwert abbrechen, weil der Speicher voll ist. In
Python kann man ein ähnliches Verhalten mit den bereits oben erwähnten
Generatoren erreichen.
Wie gesagt: Wen diese Art der Programmierung interesseiert, der sollte
einfach mal ein einschlägiges Tutorial durcharbeiten. Evtl. wird man
dadurch angefixt und will immer mehr von diesen Dingen erfahren (so ging
es jedenfalls mir), oder man kann mit dem ganzen Zeugs überhaupt nichts
anfangen, dann ist das auch nicht schlimm.
Reine FP ist noch sehr weit weg vom Mainstream und wird ihn vielleicht
nie erreichen. Dass FP aber auch kein abgespacetes Hirngespinst
weltfremder Nerds ist, erkennt man daran, dass einzelne Facetten davon
immer mehr auch in etablierte Sprachen vordringen. So gibt es in C++
mittlerweile Lambdas und Closures, und in den Boost-Bibliotheken reifen
schon die nächsten FP-Features, um vielleicht irgendwann in den
C++Standard übernommen zu werden. In Python gibt es diese Dinge schon
lange. Und die für viele superabstrakten Monaden von Haskell gibt es
seit geraumer Zeit in C# (als Basis von LINQ).
Man muss also, um ein Bisschen FP zu schnuppern, nicht einmal unbedingt
eine neue Sprache lernen. Es genügt, hin und wieder mal nachzuschauen,
was die regelmäßig verwendete Brot- und Buttersprache (wenn's nicht
gerade Fortran oder C ist ;-)) an neuen Features anzubieten hat, und
diese einfach mal auszuprobieren.
c-hater schrieb:> Dann hast du OO-Programmierung nicht verstanden.
Naja, das habe ich auch nie behauptet :-).
> Ist doch ganz simpel: Man schreibt eine abstrakte Basisklasse> [...]
Den Rest den Du beschreibst, habe ich eigentlich genau so realisiert.
In der Tat kann man das Vererbungskonzept nutzbringend einsetzen, um die
verschiedenen Regler und Funktionen zu implementieren genau wie Du es
vorschlägst.
Aber die Art und Weise wie die ganzen Objekte dann (bei mir) miteinander
kommunizieren hat irgendwie noch keine rechte Struktur. Auch die
Organisation der Nebenläufigkeit ist ein ähnliches Problem.
Funktioniert zwar alles, aber gefällt mir nicht. Na, ich werde wohl
einfach nochmal etwas darüber nachdenken.
Die aus der OO-Welt bekannten Design-Patterns bringen mich da jedenfalls
auch nur bedingt weiter. Vermutlich fehlt es mir auch einfach an
Erfahrung. Hätte man halt doch Informatik studieren sollen :-).
> Alles in allem kann das fast als Paradebeispiel für OO-Programmierung> dienen. Allerdings soll mich der Teufel holen, falls ich jemals in> Versuchung kommen sollte, sowas auf einem µC tatsächlich in dieser Art> zu schreiben...
Aha! In welcher Art würdest Du es denn machen?
viele Grüße!!!
Hallo Yalu,
also erstmal ganz herzlichen Dank, dass sich offensichtlich doch jemand
die Mühe gemacht hat bis zum Ende zu lesen und auch noch so viel
Interessantes zu schreiben.
> Ja, FBP passt ganz gut zur Implementierung von Reglern und zur> Simulation von Regelstrecken, da man es dort schwerpunktmäßig mit> Datenströmen zu tun hat. Die einzelnen Übertragungsglieder nehmen am> Eingang jeweils einen Datenstrom auf, verarbeiten ihn und geben die> Ergebnisse wieder als Datenstrom aus.
Ganz genau.
In Python machen genau sowas ja eigentlich auch die Generatoren.
Allerdings kann ich doch mit einer Generatorfunktion immer nur EINEN
Datenstrom erzeugen, oder?
Für Python gibt es außerdem allerlei so "Frameworks" für FBP:
https://wiki.python.org/moin/FlowBasedProgramming> Allerdings bieten viele funktionale Programmiersprachen Mittel an, die> neben vielen anderen Dingen auch Entwicklung von datenflussorientierten> DSLs (domain specific languages) unterstützen. Aber auch in OO-Sprachen> wie C++ kommt man recht weit, wie bspw. die Boost.Dataflow-Bibliothek> zeigt:>> http://dancinghacker.com/code/dataflow/
Das sieht ja schon sehr interessant aus.
>> Daher habe ich mich gefragt, ob eine funktionale Programmiersprache eine>> Möglichkeit sein könnte so ein Regelungsmodell elegant zu>> implementieren.> Prinzipiell ja, weil man damit sehr gut nicht nur mit Datenstrukturen,> sondern mit ganzen Berechnungen herumjonglieren kann. Diese Berechnungen> sind in der Regelungstechnik die Übertragungsglieder, die man auf> komfortable Weise miteinander zu komplexeren Gebilden kombinieren> möchte.
Also mal blöd gefragt:
Bedeutet "funktionales Programmieren", dass ich mich auf Funktionen (im
Sinne einer Prozedur) beschränke, mit denen ich Funktionen (im
mathematischen Sinne) implementiere? D.h. also Objekte und Klassen
eigentlich irgendwie ihren Nutzen verlieren, weil ich Zustände, die sich
naturgemäß gut in einem Objekt kapseln lassen würden, sowieso versuche
zu vermeiden?
> Python bietet noch andere interessante Mittel zur Unterstützung von> datenflussorientierter Programmierung, allen voran die Generatoren.
Hm, aber die reinen Generatorfunktionen sind doch mehr für einen
linearen Datenfluss geeignet, oder? Also ich kann zwar in einer
Verarbeitungsfunktion mehrere Generatorfunktionen als Datenquellen
verarbeiten, aber das Ergebnis nicht auf mehrere weitere Verarbeitungs-
oder Ausgabefunktionen verteilen, richtig?
Aber da würden die diversen verfügbaren Erweiterungen für Python
entsprechend der C++ boost library vermutlich weiterhelfen.
> Die Idee ist nicht absurd, sondern ein grundlegendes Konzept, das> tatsächlich – wenn auch in stark elaborierter Form – in der FP angewandt> wird. So beruhen bspw. die Monaden in Haskell auf diesem Grundgedanken,> sind aber allgemeiner und abstrakter definiert, dass man sie noch für> viele andere Dinge verwenden kann (sogar viel mehr als deren "Erfinder"> ursprünglich ahnen konnten).
Tja, ich fürchte da kann ich (noch) nicht mitreden. Auch wenn mir die
Monaden auch schon hier und da begegnet sind :-).
>> Andererseits hätte die Funktion eine irre Schnittstelle und ob das dann>> insgesamt besser wartbar wäre habe ich meine Zweifel.> Richtig, deswegen wird in den Monaden den Zustand gekapselt, so dass er,> wenn überhaupt, nur dort sichtbar wird, wo er auch wirklich gebraucht> wird.
Hm, klingt spannend.
> In Haskell gibt es bspw. noch das Kozept der Arrows. Das ist ein> alternativer Weg dur Darstellung von Berechnungen. Sie haben eine> gewisse Ähnlichkeit mit Monaden, sind aber noch allgemeiner gehalten.> Wenn du dir die Bilder auf folgenden Seiten anschaust, merkst du sicher,> wohin der Hase läuft (auch wenn du den Rest ganz sicher (noch) nicht> verstehen wirst):
Ich meine es zu erahnen!
> Ein anderes Stichwort ist FRP:>> http://en.wikipedia.org/wiki/Functional_reactive_programming
Das klingt wiederum auch sinnvoll. Denn gerade der Umgang mit der Zeit
ist meiner Meinung nach in der Regelungstechnik unverzichtbar. Und genau
das fehlte mir irgendwie in allem was ich bisher über FP gelesen habe.
> betrachtet werden können sie mit mathematisch reinen (nebeneffektfreien)> Funktionen verarbeitet und ineinander übergeführt werden. So sind z.B.> die Integration oder Differentiation reine Funktionen, wenn man in> ganzen Verläufen denkt, nicht aber, wenn man immer nur die einzelnen,> jeweils aktuellen Zahlenwerte betrachtet.
Krass. Genau darüber hatte ich schonmal nachgedacht und wie sich das
realisieren lassen könnte. Mir ist in dem Zusammenhang auch die LaPlace
Transformation in den Sinn gekommen. Konventionell implementiere ich so
einen Regler eigentlich in Form einer Differenzialgleichung bzw. im
diskreten Fall einer Differenzengleichung und dabei kommt zwangsläufig
die Zeit ins Spiel. Wenn man nun aber stattdessen einfach die
Übertragungsfunktion hinschreiben könnte, hätte man es wieder mit einer
reinen Funktion zu tun. Ist das jetzt dann dass was die FRP leistet?
Ich fürchte an der Stelle wird man merken, dass ich nicht wirklich
Ahnung von der ganzen Thematik habe, sondern nur angelesenes Halbwissen
und mehr herumrate als dass ich wüsste was ich tue :-).
> unbedingt mit Arrows und FRP herumschlagen. Für den Anfang reichen> einfache Listen von Zahlenwerten. Damit kann man in der Regelungstechnik> [...]> dem einmillionsten Sensorwert abbrechen, weil der Speicher voll ist. In> Python kann man ein ähnliches Verhalten mit den bereits oben erwähnten> Generatoren erreichen.
Das ist mir theoretisch klar. Ich werde damit nun etwas mehr
experimentieren.
> Man muss also, um ein Bisschen FP zu schnuppern, nicht einmal unbedingt> eine neue Sprache lernen. Es genügt, hin und wieder mal nachzuschauen,> was die regelmäßig verwendete Brot- und Buttersprache (wenn's nicht> gerade Fortran oder C ist ;-)) an neuen Features anzubieten hat, und> diese einfach mal auszuprobieren.
Ich gebe mir Mühe :-).
nochmals vielen Dank und viele Grüße!!!
Ohne jetzt das obige gelesen zu haben ...
Eine Regelung macht man aus Zuverlaessigkeitsgruenden immer ihne
Firlefanz. Dh auf einem minimalen Controller, ohne Betriebssystem, ohne
Grafik, ohne dynamisches Memeory, ohne OOP und dergleichen.
Was man macht : Das Geraet muss kommunikationsfaehig sein. Und dort
haengt man die Debug-, Grafik-, Optimierungs-Funktionalitaet an.
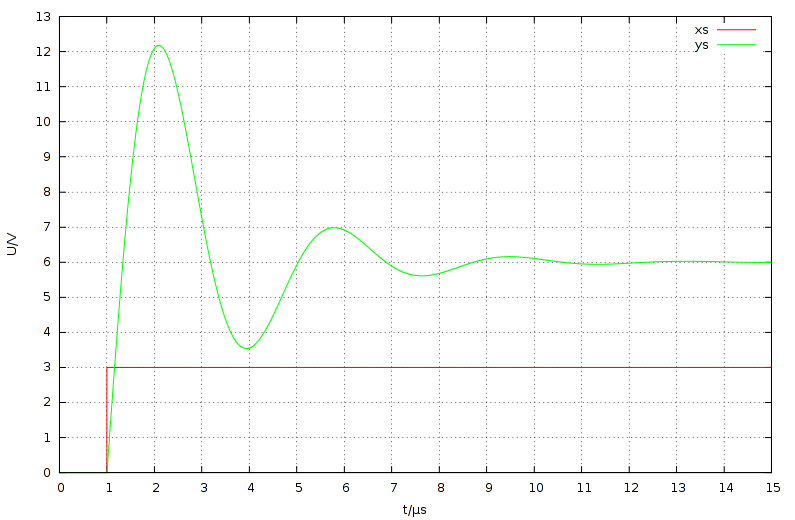
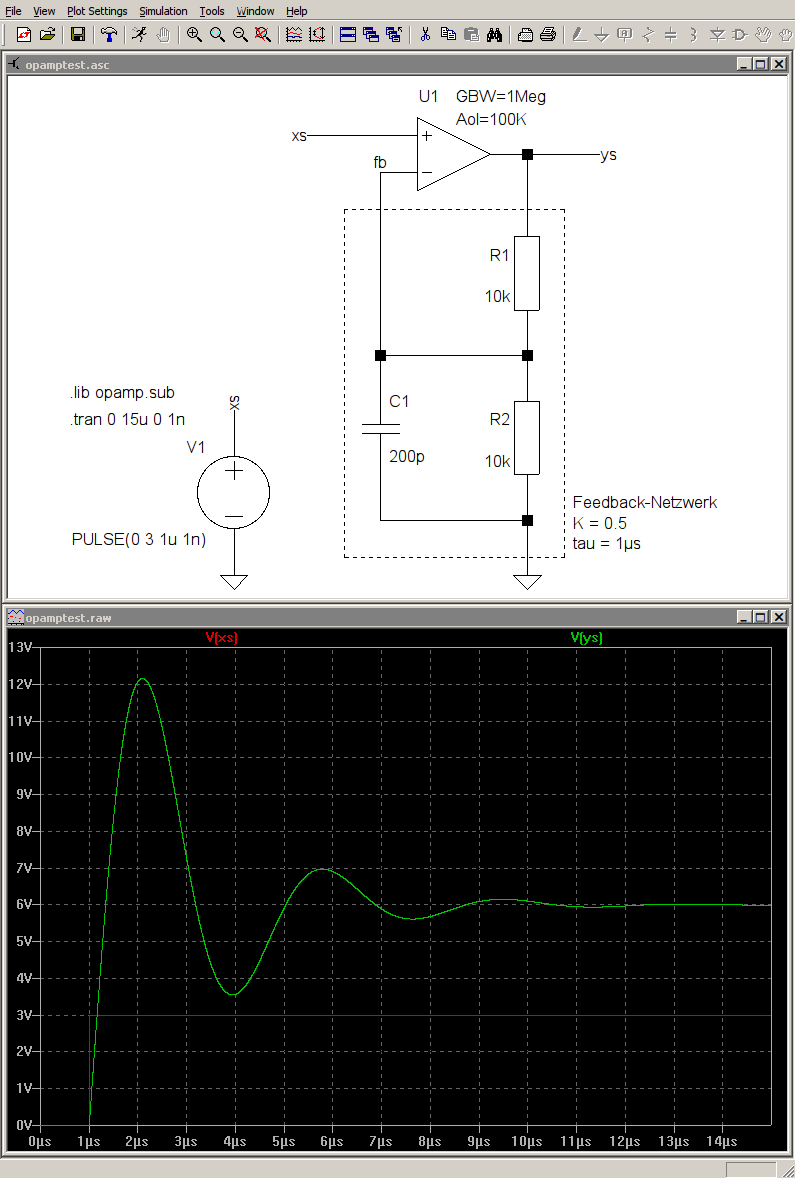
Ich habe die oben beschriebene Prinzip mit den endlosen Listen mal in
Haskell umgesetzt und damit eine einfache Simulation eines Regelkreises
realisiert.
Der angehängte Code definiert im ersten Teil verschiedene parametriebare
Übertragungsglieder und ein paar Hilfsfunktionen. Im zweiten Teil wird
eine nichtinvertierende Verstärkerschaltung (die ja letzendlich auch ein
Regler darstellt) mit einem Opamp simuliert. Damit es etwas zu sehen
gibt und die Schaltung schön überschwingt, liegt im Gegenkopplungszweig
an ungschickter Stelle ein Kondensator. Der Opamp und das Feedback-
Netzwerk sind jeweils als PT1-Glied modelliert. Ersterer entspricht
damit dem Modell "opamp" in LTspice. Bei den beiden Simulationen kommt
deswegen auch fast das gleiche Ergebnis heraus (s. Anhang).
Wie schon in meinem letzten Beitrag geschrieben, arbeiten die meisten in
diesem Programm definierten Funktionen nicht mit einzelnen Zahlenwerten,
sondern mit kompletten Signalverläufen. Ein Signal ist dabei als eine
endlose Liste von Zahlen der Typklasse Fractional (also einen beliebigen
rationalen, reellen oder komplexen Datentyp) implementiert. Ein
Übertragungsglied ist implementiert als eine Funktion, das ein Signal
als Argument und ein Signal als Funktionswert hat.
Vordefinierte Übertragungsglieder:
Größe der Zeitschritte festlegen (im Beispiel 1ms):
1
dt = 1E-3
Signal generieren (im Beispiel eine Sinusfunktion):
1
f t = 5 * sin (2*pi * 50 * t)
2
x = sigGen f
Ausgestattet mit diesen Hilfsmitteln können sehr leicht und mit wenig
Tipparbeit sowohl Regler als auch simulierte Regelstrecken geschrieben
werden. Im Beispiel werden zwei PT1-Glieder mit den entsprechenden
Parametern angelegt, beim Opamp zusätzlich noch die Differenz der
Eingangssignale gebildet und das Ganze anschließend "verdrahtet":
Im Programmcode stehen weiterführende Kommentare dazu.
Für diejenigen, die sich den Programmcode anschauen möchten, aber kein
Haskell können, sind hier noch ein paar Hinweise:
- Zeilen, die mit einem "--" beginnen, sind Kommentare. Ich habe
relative viele davon hineingeschrieben, so dass man zumindest den
zweiten Teil ("-- Test: nichtinvertierender Verstärker") auch ohne
Haskell-Kenntnisse halbwegs verstehen sollte.
- Im Gegensatz zu anderen Sprachen, werden in Haskell Funktionsargumente
nicht geklammert. Beispiel:
C: z = f(x, y);
Haskell: z = f x y
Auch bei Funktionsdefinitionen fällt der meiste Zierrat weg:
C: double f(double x, double y) { return x + y; }
Haskell: f x y = x + y
- Zeilen mit einem Identifier gefolgt von "::" sind Deklarationen und
von eher marginaler Bedeutung. Die meisten davon könnte man auch
weglassen, da der Compiler Funktionssignaturen und Variablentypen
mittels Type-Inference i.Allg. selber bestimmen kann.
Wenn der Code nicht nur zur Simulation, sondern in einer echten
Regelanwendung eingesetzt würde, müssen natürlich noch Schnittstellen
nach außen bereitgestellt werden. Im einfachsten Fall hat man einen
Sensordatenstrom als Eingabe und eine Stellwertdatenstrom als Ausgabe.
Die I/O muss so programmiert werden, dass beide Datenströme als endslose
Zahlenlisten repräsentiert sind
Ich muss noch dazu sagen, dass ich das Programm relativ schnell und ohne
viele Tests zusammengehackt habe, weswegen es wahrscheinlich noch viele
Fehler enthält. Es soll in erster Linie ein Proof-of-Concept für die in
meinem letzten Beitrag gemachten Vorschläge sein.
Klaus W. schrieb:> Bedeutet "funktionales Programmieren", dass ich mich auf Funktionen (im> Sinne einer Prozedur) beschränke, mit denen ich Funktionen (im> mathematischen Sinne) implementiere? D.h. also Objekte und Klassen> eigentlich irgendwie ihren Nutzen verlieren, weil ich Zustände, die sich> naturgemäß gut in einem Objekt kapseln lassen würden, sowieso versuche> zu vermeiden?
Für Haskell gesprochen (wohl eine der "reinsten" funktionalen
Programmiersprachen):
Man kann in der Tat nur "echte" Funktionen schreiben. Es gibt also keine
Variablen und demzufolge auch keine Schleifen. Objekte und Klassen wie
Du sie von Python oder C++, Java usw. kennst, gibt es in Haskell
natürlich auch nicht, da das keinen Sinn machen würde.
Dafür gibt es in Haskell neben Tupeln und Listen sogenannte
"Algebraische Datentypen" und "Typklassen". Diese beiden Konzepte sind
viel mächtiger als die Objekt-Klassensysteme in imperativen Sprachen.
Es ist auch nicht so, dass man bei der funktionalen Programmierung um
jeden Preis Zustände verhindern möchte. Es geht viel mehr darum, dass
man Zustände explizit macht, abstrahiert und auf einem viel höheren
Abstraktionsniveau damit umgeht.
Hallo Yalu,
vielen Dank für Deine Ausführungen!
Die grobe Vorgehensweise denke ich verstanden zu haben.
Wie Du schon vermutest, gibt mir der Haskell Code im Detail noch
allerlei Rätsel auf. Insgesamt scheint es aber keine Hexerei zu sein.
Insbesondere die Handhabung der Zeit ist mit dt doch eigentlich in
bekannter Weise gelöst?
Nur der Trick mit den scanxx Funktionen ist mir noch nicht ganz klar.
Das ist ja eigentlich der Kern der Sache. Für die Integration müsste man
doch immer den Wert des vorhergehenden Schrittes noch bereithalten -
konventionell gedacht. Wie die scan-Funktion das leistet ist mir noch
nicht klar :-).
Aber ich denke ich will Dich nicht weiter damit belästigen. Ein Haskell
Tutorial im Forum wäre wohl etwas viel verlangt. Ich denke ich werde
mich erstmal mit den zahlreichen Infos aus dem Web auseinander setzen.
Und wenn ich dann genauer verstehe, wovon ich eigentlich rede, kann ich
mich ja wieder melden :-).
Viele Grüße,
Klaus
Klaus W. schrieb:> Nur der Trick mit den scanxx Funktionen ist mir noch nicht ganz klar.> Das ist ja eigentlich der Kern der Sache. Für die Integration müsste man> doch immer den Wert des vorhergehenden Schrittes noch bereithalten -> konventionell gedacht. Wie die scan-Funktion das leistet ist mir noch> nicht klar :-).
Die scan<nx><ny>-Funktionen erzeugen jeweils aus einer endlose Liste xs¹
eine endlose Liste ys. Bei der Generierung jedes Elements wird dabei
jeweils auf die letzten nx Elemente in xs und auf die letzten ny
Elemente aus ys zugegriffen. Genauer gesagt ist jedes Element aus ys die
gewichtete Summe aus den letzten paar x- und y-Werten. Die Gewichte für
x heißen a0, a1, ... a<nx-1>, diejenigen für y b0, b1, ... b<ny-1>.
Die einfachste Form der diskreten Integration über die Zeit ist die
Aufsummierung der x-Werte, jeweils multipliziert mit ihrem zeitlichen
Abstand dt:
y_n hängt also vom aktuellen x und vom letzten y ab, deswegen würde man
für die gewöhnliche Integration die Funktion scan11 mit den Gewichten
a0 = Δt und b0 = 1 benutzen. Beim I-Glied kommt noch der Faktor K hinzu,
so dass man a0 = K·Δt setzt. Für die Differentiation bzw. das D-Glied,
die über den Differenzenquotienten berechnet werden, braucht man nur die
letzten beiden x, nicht aber die Historie von y, dewegen wird dafür die
Funktion scan20 verwendet. Das PT2-Glied wird mit scan12 berechnet, da
die y-Werte jeweils vom aktuellen x-Wert und den letzten 2 y-Werten
abhängen. Diese 1 oder 2 letzten y-Werte sind also der Zustand, der in
jedem Berechnungsschritt mitgeführt werden muss.
Wie die Listen tasächlich generiert werden, möchte ich schrittweise an
einfachen Beispielen zeigen. Dazu muss man aber erst einmal wissen, wie
in Haskell eine Liste überhaupt aufgebaut ist.
Es gibt zwei so genannte Konstruktoren für Listen:
[] liefert die leere Liste
a : as liefert eine Liste, deren erstes Element a und deren weitere
Elemente durch die Liste as repräsentiert sind.²
Eine Liste mit einem Element, bspw. [1] würde also gebildet mit
1 : []
denn das erste Element ist 1 und der Rest der Liste ist leer.
Hat die Liste mehrere Elemente, wird der :-Konstruktor einfach mehrfach
angewandt:
[1, 2] = 1 : [2]
= 1 : (2 : [])
= 1 : 2 : []
Die runden Klammern können dabei weggelassen werden, da der :-Operator
rechtsassoziativ ist.
Die übliche Listenschreibweise [a1, a2, a3, a4] ist letzendlich nur
syntaktischer Zucker für a1 : a2 : a3 : a4 : [].
Intern sind die Listen als einfach verkette Listen implementiert. Jedes
Element besteht aus seinem Wert (genauer gesagt einem Zeiger darauf) und
einem Zeiger auf eine weitere Liste bzw. das nächste Element. In C würde
man dafür ein Struct mit zwei Zeigern verwenden und [] als den
NULL-Zeiger definieren.
Es ist nun in Haskell erlaubt, Listen rekursiv zu definieren, also z.B.
ones = 1 : ones
Wenn man das ones wiederholt auf der rechten Seite einsetzt, ergibt sich
ones = 1 : ones
= 1 : 1 : ones
= 1 : 1 : 1 : ones
= 1 : 1 : 1 : 1 : ...
oder in der Form mit eckigen Klammern geschrieben
ones = [1, 1, 1, 1, ...]
Wenn man sich ones auf dem Bildschirm ausgeben lässt, wird tatsächlich
eine endlose Liste von Einsen angezeigt, bis die Ausgabe mit Strg-C
gestoppt wird.
Man kann nun eine Funktion f definieren, die eine endlose Liste
beliebiger gleicher Elemente erzeugt. Das gewünschte Element wird dazu
als Argument a übergeben:
f a = a : f a
So liefert f 42 die endlose Liste
[42, 42, 42,...]
Was liefert wohl f 0, wenn f folgendermaßen definiert ist:
f a = a : f (a + 1)
Gehen wir dazu einfach schrittweise vor:
f 0 = 0 : f 1
= 0 : 1 : f 2
= 0 : 1 : 2 : f 3
= [0, 1, 2, ...]
Um wie hier eine aufsteigende Folge von Zahlen zu bilden, braucht man
in jedem Schitt Zugriff auf das letzte ELement der generierten Liste.
In C würde man dafür eine Zustandsvariable verwenden, die in jedem
Schritt inkrementiert und damit mit einem neuen Wert überschrieben wird.
In Haskell können Variablen nicht überschrieben werden. Sie werden
direkt bei ihrer Entstehung initialisiert (auf FP-Deutsch "gebunden")
und behalten ihren Wert bis an ihr Lebensende. Deswegen wird in obigem
Beispiel der jeweils letzte Wert plus eins per Funktionsargument a an
den nächsten Berechnungsschritt übergeben. Diese Variable hat zwar in
jedem Schritt den gleichen Namen a, trotzdem sind alle diese a's
unterschiedliche Variablen, da sie innerhalb der jeweils aufgerufenen
Funktion lokal sind.³
Damit dürfte schon einmal deine Frage beantwortet sein, wo in Haskell
der Zustand steckt: nämlich im Funktionsargument. Also genau so wie in
deiner "absurden" Idee ganz am Anfang ;-)
Um übrigens die Liste [0, 1, 2, ...] zu erzeugen, muss man in Haskell
nicht selber eine Funktion schreiben. Dank einer ganzen Dose voller
syntaktischm Zucker muss man nicht einmal explizit eine Funktion
aufrufen. Es genügt, einfach zu schreiben:
[0..]
Weitere Möglichkeiten:
[42..] -> [42, 43, 44, ...]
[10,12..] -> [10, 12, 14, ...]
[5,5..] -> [5, 5, 5, ...]
Natürlich müssen Listen nicht immer endlos sein:
[1..4] -> [1, 2, 3, 4]
[3,5..11] -> [3, 5, 7, 9, 11]
Es müssen auch nicht unbedingt Zahlen sein:
['a'..'d'] -> ['a', 'b', 'c', 'd'] = "abcd"
Zum Schluss noch eine kleine Übungsaufgabe ;-)
Gegeben ist die Funktion f mit den beiden Argumenten y0 (eine Zahl) und
xs (eine Liste von Zahlen):
f y0 xs = y0 : f (y0 + head xs) (tail xs)
Was liefert folgender Ausdruck:
f 0 [1..]
Hinweis: Die Funktion head liefert das erste Element einer Liste, die
Funktion tail den ganzen Rest:
head [1, 2, 3, 4] -> 1
tail [1, 2, 3, 4] -> [2, 3, 4]
Am besten gehst du dazu die einzelnen Rekursionsschritte, wie oben in
den anderen Beispielen gezeigt, nacheinander durch.
Wenn du die Aufgabe gelöst hast, wirst du in der Lage sein, nicht nur
eine Intregrierfunktion, sondern fast beliebige andere auf Datenströmen
arbeitende Funktionen mit internem Zustand zu schreiben.
Noch eine letzte kleine Anmerkung:
Statt
x = head xs
t = tail xs
kann man in Haskell auch eleganter schreiben
x : t = xs
Man nennt dies "Pattern Matching", da auf der linken Seite ein Muster
steht in die der Ausdruck auf der rechten Seite eingepasst wird. Ist xs
= [1,2,3], was man auch als 1 : [2,3] schreiben kann (s.o.), ist
anschließend x = 1 und t = [2,3]. Pattern-Matching kann auch bei
Funktionsargumenten angewandt werden, weswegen man die Funktion aus der
Übungsaufgabe statt
f y0 xs = y0 : f (y0 + head xs) (tail xs)
auch kürzer so schreiben kann (und dies üblicherweise auch tut):
f y0 (x:xs) = y0 : f (y0 + x) xs
Zu beachten ist nur, dass xs in der zweiten Form nicht mehr für die
gesamte übergebene Liste steht, sondern nur noch für deren Tail.
—————————————
¹) Die der Suffix "s" in Variablennamen wird in Haskell oft verwendet,
um damit anzuzeigen, dass es sich um eine Liste handelt. Es stellt
ein Plural-"s" dar. Da in einer Liste von Äpfeln jedes Element (auf
Englisch) ein apple ist, nennt man die gesamte Liste einfach
apples. xs ist also in diesem Fall die Liste aller x-Werte, d.h.
der Eingangsdaten.
²) Falls du dir schon einmal Lisp etwas angeschaut hast: Dort heißen
diese beiden Konstruktoren nil und cons, haben sonst aber
praktisch die gleiche Bedeutung.
³) Trotzdem wird nicht für jede dieser Variablen eigener Speicherplatz
reserviert werden. Entweder bereits zur Compilezeit, spätestens aber
zur Laufzeit wird erkannt, dass bei der aktuellen Verwendung von a
alle früheren a's nicht mehr gebraucht werden, so dass der durch sie
belegte Speicherplatz wiederverwendet werden kann.
Klaus W. schrieb:> Ein Haskell Tutorial im Forum wäre wohl etwas viel verlangt. Ich denke> ich werde mich erstmal mit den zahlreichen Infos aus dem Web> auseinander setzen.
Das da ist ein gutes Buch für den Anfang:
http://learnyouahaskell.com/
In der Vergangenheit gab es auch gute Online-Haskell-Interpreter
(basierd auf GHCi), aber irgendwie scheinen die alle down zu sein.
Der ist noch übrig:
http://tryhaskell.org/
Er hat leider die Einschränkung, dass man nur Ausdrücke eingeben kann,
und der Interpreter sich keine Variablen- und Funktionsdefinitionen
merkt. Da macht die Benutzung etwas umständlich.
Das hier ist ein Online-Compiler:
http://www.compileonline.com/compile_haskell_online.php
Er ist gut, aber eben nicht interaktiv wie der Interpreter.
Wenn du das Gefühl hast , etwas länger als nur ein paar Stunden bei der
Sache bleiben zu wollen, ist es am sinnvollsten, sich den GHC (Compiler
+ Interpreter) auf dem PC zu installieren:
http://www.haskell.org/platform/
Wenn du noch Fragen hast, gerne.
Yalu X. schrieb:
Ich glaube mir geht zumindest ein kleines Licht auf:
Die scan<nx><ny>-Funktionen hätte ich mir zunächst vorstellen können bei
real existierenden endlichen Listen. Bei dem Regler hingegen trudeln die
Messwerte aber erst nach und nach ein. Bei genauerer Überlegung macht
das aber vermutlich überhaupt keinen Unterschied.
> Die einfachste Form der diskreten Integration über die Zeit ist die> Aufsummierung der x-Werte, jeweils multipliziert mit ihrem zeitlichen> Abstand dt:
Ja, die Theorie ist so weit klar :-).
> Was liefert wohl f 0, wenn f folgendermaßen definiert ist:>> f a = a : f (a + 1)
Na, das ist ja noch relativ einfach.
> Zum Schluss noch eine kleine Übungsaufgabe ;-)>> Gegeben ist die Funktion f mit den beiden Argumenten y0 (eine Zahl) und> xs (eine Liste von Zahlen):>> f y0 xs = y0 : f (y0 + head xs) (tail xs)>> Was liefert folgender Ausdruck:>> f 0 [1..]
0 1 3 6 10 15 usw....
würde ich sagen.... oder?
> Wenn du die Aufgabe gelöst hast, wirst du in der Lage sein, nicht nur> eine Intregrierfunktion, sondern fast beliebige andere auf Datenströmen> arbeitende Funktionen mit internem Zustand zu schreiben.
Wirklich? staun
Naja, ich denke das Prinzip ist mir schon klar!
Ich habe nur immer noch etwas Zweifel, ob das dann im Endergebnis
übersichtlicher und besser wartbar ist als es in einer
objektorientierten Sprache in ein Objekt zu kapseln und dort den Zustand
lokal begrenzt zu verstecken.
Aber interessant ist es auf jeden Fall.
> Klaus W. schrieb:>> Ein Haskell Tutorial im Forum wäre wohl etwas viel verlangt. Ich denke>> ich werde mich erstmal mit den zahlreichen Infos aus dem Web>> auseinander setzen.>> Das da ist ein gutes Buch für den Anfang:>> http://learnyouahaskell.com/
Hm, gibt's auch noch irgendwo Zeit zu kaufen? :-)
Na, mal sehen.
Also nochmals vielen Dank für Deine interessanten Ausführungen!
viele Grüße!
klaus
Klaus W. schrieb:> Bei dem Regler hingegen trudeln die Messwerte aber erst nach und nach> ein. Bei genauerer Überlegung macht das aber vermutlich überhaupt> keinen Unterschied.
Genau. Dank lazy Evaluation werden die Werte in den einzelnen
Übertragungsgliedern ja auch nur nach und nach verarbeitet.
Folgendes Bsipiel zeigt, wie man die Istwerte von der Tastatur einliest
und die Stellwerte auf dem Bildschirm ausgibt:
Die Funktion einlesen liest dabei einen endlosen Eingabestring ein und
formt daraus eine Liste mit endlos vielen Double-Werten. Die Funktion
ausgeben macht das Gleiche andersherum.
Was im Quellcode hintereinander steht (alles einlesen, regeln, alles
ausgeben), läuft bei der Ausführung ineinander verzahnt ab, d.h. mit
jedem eingegebenen Wert wird auch ein Wert ausgegeben.
Anstelle der Tastatur und des Bildschirms wird man in der Praxis
natürlich andere Schnittstellen benutzen, nämlich diejenigen zu dem zu
regelnden Prozess.
> 0 1 3 6 10 15 usw....>> würde ich sagen.... oder?
Richtig.
>> Wenn du die Aufgabe gelöst hast, wirst du in der Lage sein, nicht nur>> eine Intregrierfunktion, sondern fast beliebige andere auf Datenströmen>> arbeitende Funktionen mit internem Zustand zu schreiben.>> Wirklich? staun
Die Funktion aus der Übungsaufgabe liefert, wie du sicher ebenfalls
erkannt hast, die fortlaufende Summe der Eingangsdaten:
[0, 1, 3, 6, ...] = [0, 0+1, 0+1+2, 0+1+2+3, ...]
Das ist (bis auf den konstanten Faktor Δt) die Integralfunktion, die du
damit verstanden hast :)
Ok, eine Funktion nur nachzuvollziehen oder sie selber zu schreiben, das
sind zwei verschiedene Dinge. Aber Programmieren lernt man nicht an
einem Tag, sondern in einem Zyklus, in dem man abwechselnd sich Code von
anderen anschaut und ähnliche Dinge selber ausprobiert.
Funktionale Programmierung kann zugegebenermaßen (vor allem am Anfang)
sehr knifflig sein. Das ist aber bei jeder Form der Programmierung so.
Wie lange habe ich gebraucht, um mein erstes ernsthaftes Basic-Programm
zu schreiben? Anschließend die strukturierte Programmierung (Pascal und
C) zu lernen, ging recht leicht, da der Sprung dahin nur ein kleiner
ist.
Der Schritt zur objektorientierten Programmierung in Form von C++ war
(zumindest für mich, und obwohl ich schon gut C konnte) ein ziemlich
schwerer, aber einer, der sich gelohnt hat. Python war danach (mit
meinem Vorwissen aus Basic, C und C++) wieder sehr leicht, da dort keine
grundlegend neuen Programmierparadigmen eingeführt werden.
Der Sprung zur funktionalen Programmierung ist wieder sehr schwer, und
ich habe ihn deswegen auch noch nicht geschafft. Da ich aber jetzt schon
sehe, dass er sich für mich mindestens so sehr lohnt wie seinerzeit die
OOP, bleibe ich dran.
> Ich habe nur immer noch etwas Zweifel, ob das dann im Endergebnis> übersichtlicher und besser wartbar ist als es in einer> objektorientierten Sprache in ein Objekt zu kapseln und dort den Zustand> lokal begrenzt zu verstecken.
In diesem konkreten Beispiel (Framework für Reglerprogrammierung) ist
nur die Programmierung des Frameworks selbst knifflig. Wenn dieses
Framework aber erst einmal steht, kann man nach dem Baukastenprinzip mit
minimalem Aufwand fast beliebige Regler zusammenstellen.
Diese sind dann sowohl sehr übersichtlich als auch leicht wartbar, weil
man im Wesentlichen nur noch die Reglerstruktur hinschreiben und sich
nicht mehr um Dinge wie Schleifen, Zwischenspeicherung von Werten usw.
kümmern muss. Diese sind vollständig im Framwork gekapselt, das man,
wenn es einmal läuft, nur ganz noch selten anfassen wird.
Man kann ein entsprechendes Framework sicher auch in C++ erstellen.
Damit es hinterher aber genauso leicht zu nutzen ist wie das
Haskell-Framework, wird man auch dort ordentlich (wahrscheinlich sogar
deutlich mehr) Gehirnschmalz und Schreibarbeit hineinstecken müssen.
Da du deine bisherige Heizungsregelung objektorientiert in Python
programmiert hast, bietet es sich natürlich an, deinen bisherigen
Ansatz, mit dem du nicht so ganz zufrieden bist, durch einen anderen,
bspw. den oben vom c-hater vorgeschlagenen zu ersetzen.
Wie auch immer du weitermachst, würde mich ein kleiner Erfahrungsbericht
darüber interessieren, da ich das Thema sehr spannend finde, auch wenn
ich mich selber nur wenig mit Regelungstechnik beschäftige.
P.S.: Mir ist gerade eine Idee gekommen, wie man in Haskell auch das
Framwork viel übersichtlicher gestalten kann. Sollte es an einem der
nächsten Tage regnen, werde ich sie mal ausprobieren :)
Yalu X. schrieb:> Folgendes Bsipiel zeigt, wie man die Istwerte von der Tastatur einliest> und die Stellwerte auf dem Bildschirm ausgibt:
Aber hier fängt es doch schon an, dass eine Funktion nicht mehr
seiteneffektfrei ist. Du hast ja selbst schon weiter oben geschrieben,
wen n ich mich recht erinnere, dass I/O sowieso nie seiteneffekfrei sein
kann.
Ich der praxis kann man das doch dann eigentlich nur so lösen, dass man
eben vorwiegend seiteneffektfreie Funktionen schreibt, diese möglichst
gut testet und dann wo es nicht anders geht eben doch
seiteneffektbehaftete Funktionen drumherum bastelt?
> Ok, eine Funktion nur nachzuvollziehen oder sie selber zu schreiben, das> sind zwei verschiedene Dinge. Aber Programmieren lernt man nicht an> einem Tag, sondern in einem Zyklus, in dem man abwechselnd sich Code von> anderen anschaut und ähnliche Dinge selber ausprobiert.
Stimmt. Ich werde jetzt mal eine einfache hysteresefunktion probieren.
Das kann ja auch nicht so schwer sein.
> Wie auch immer du weitermachst, würde mich ein kleiner Erfahrungsbericht> darüber interessieren, da ich das Thema sehr spannend finde, auch wenn> ich mich selber nur wenig mit Regelungstechnik beschäftige.
Gerne. Leider fehlt mir momentan etwas die Zeit die ich gerne hätte um
mich in Ruhe damit zu beschäftigen. Aber naja, der Winter kommt ja auch
:-). Wenn es dann so weit ist, schreibe ich gerne nochmal was dazu!
viele Grüße!!!
Klaus
Klaus W. schrieb:>> Folgendes Bsipiel zeigt, wie man die Istwerte von der Tastatur einliest>> und die Stellwerte auf dem Bildschirm ausgibt:>> Aber hier fängt es doch schon an, dass eine Funktion nicht mehr> seiteneffektfrei ist.
Haskell-Funktionen sind grundsätzlich nebeneffektfrei, auch die
I/O-Funktionen. In Fällen, wo Nebeneffekte erwünscht sind, finden diese
nicht im Haskell-Programm selbst, sondern in der Laufzeitumgebung statt.
In fast jeder Programmiersprache gibt es eine Ausführungsebene oberhalb
von Main.
So gibt es bspw. in C das Modul crt0, das zuerst den Programmstack
einrichtet, alle statischen Variablen initialisiert, die eigentliche
main-Funktion aufruft und hinterher ggf. noch etwas aufräumt. Die I/O
wird in C allerdings nicht von crt0, sondern von Bibliotheksfunktionen
übernommen, die ihrerseits Funktionen des Betriebssystems aufrufen.
In Haskell gibt es ebenfalls so ein übergeordnetes Modul, das
Initialisierungen vornimmt und die main-Funktion aufruft. Im Gegensatz
zu C übernimmt dieses Modul aber auch die I/O. Wegen der Forderung nach
Nebeneffektfreiheit können dazu keine vom Haskell-Programm aufgerufenen
Bibliotheksfunktionen verwendet werden, da diese diese die aufrufenden
Haskell-Funktionen mit ihren Nebeneffekten "verseuchen" würden.
I/O läuft in Haskell über so genannte I/O-Actions ab. Funktionen wie
getChar und getLine liefern als Funktionswert nicht etwa die
eingelesenen Daten, sondern eine so genannte Action, die, wenn sie
ausgeführt wird, die Daten einliest. Diese Actions werden aber nicht vom
Haskellprogramm selbst ausgeführt, sondern von der Laufzeitumgebung.
Ebenso geben putChar und putStr die Daten nicht direkt aus, sondern
liefern eine Action, die dies tut. Um mehrere Ein- oder Ausgaben
hintereinander auszuführen, können mit den Operatoren >> und >>= mehrere
Actions zu einer komplexeren Action zusammengesetzt werden.
So ist folgender klassisch imperativ aussehender Code zur Ausgabe von
zwei Textzeilen
1
main = do
2
putStrLn "Erste Zeile"
3
putStrLn "Zweite Zeile"
in Wirklichkeit die syntaktisch gezuckerte Variante von
1
main = putStrLn "Erste Zeile" >> putStrLn "Zweite Zeile"
Der Wert von main ist die zusammengesetzte Action der beiden durch
putStrLn gelieferten Einzel-Actions, d.h. eine Datenstruktur, die eine
Anweisung an die Laufzeitumgebung enthält, die beiden Strings jeweils in
einer Zeile auszugeben.
Im obigen Beispiel sind die beiden Einzel-Actions nicht voneinander
abhängig. Das ändert sich aber, wenn Benutzereingaben mit ins Spiel
kommen. Das folgende Programm fragt eine Textzeile ab und gibt sie
anschließend unverändert aus:
1
main = do
2
zeile <- getLine
3
putStrLn zeile
Man beachte, dass zwischen zeile und getLine kein Gleichheitszeichen,
sondern ein Pfeil steht. zeile ist also nicht etwa der Funktionswert
von getLine, wie man zunächst vermuten könnte.
Entzuckert sieht das Ganze so aus:
1
main = getLine >>= \zeile -> putStrLn zeile
Der rechte Operand von >>= ist ein so genannter Lambda-Ausdruck, der
eine Funktion liefert, die die Funktion putStrLn auf das Argument
zeile anwendet. Da diese Funktion äquivalent zu putStrLn selbst ist,
kann man auch einfacher schreiben:
1
main = getLine >>= putStrLn
Der Wert von main ist in diesem Fall die aus getLine und putStrLn
zusammengesetze Action. Der >>=-Operator verknüpft die beiden Actions
so, dass das Ergebnis der ersten Action (die einglesene Textzeile) an
die zweite Action weitergereicht wird. Die Ausführung der Actions sowie
das Weiterreichen der Textzeile findet aber auch in diesem Fall in der
Laufzeitumgebung außerhalb von main statt. main selber sorgt nur für
die Verknüpfung der beiden Einzel-Actions. Das ist eine Operation
vergleichbar mit einer Addition und damit völlig frei von Nebeneffekten.
Interessant wird die Sache dann, wenn das Programm solche Actions in
einer Endlosschleife generiert. Normalerweise würde das Programm endlos
Actions zusammensetzen, ohne diese jemals ausführen zu können, bis
irgendwann der Speicher überläuft. Da aber Haskell aber lazy Evaluation
macht, wird die Gesamt-Action immer nur stückchenweise generiert und
durch die Laufzeitumgebung ebenso stückchenweise ausgeführt.
Eine Endlos-Action, die immer abwechselnd eine Zeile einliest und diese
ausgibt, kann man rekursiv folgendermaßen definieren:
1
main = getLine >>= putStrLn >> main
Syntaktisch gezuckert sieht das fast wieder klassisch imperativ aus, vor
allem dann, wenn man sich die letzte Zeile durch "goto main" ersetzt
denkt.
1
main = do
2
zeile <- getLine
3
putStrLn zeile
4
main
Wie du siehst, wird mit der do-Notation zwar imperative Programmierung
nachgebildet, wenn man aber hinter die Kulissen schaut, ist das nach wie
vor perfekt reine funktionale Programmierung.
> Stimmt. Ich werde jetzt mal eine einfache hysteresefunktion probieren.> Das kann ja auch nicht so schwer sein.
Ich habe mal, wie oben angekündigt, die einzelnen Übertragungsglieder
etwas anders definiert:
Der Grundgedanke besteht darin, jedes Element der endlosen Ausgangsliste
als Funktion eines Zustands (du wolltest doch Zustände, oder? ;-)) und
des entsprechenden Elements der Eingangsliste zu definieren. Der neue
Zustand ist ebenfalls eine Funktion des (alten) Zustands und des
Eingangselements. Da die beiden Funktionen dieselben Argumente haben,
kann man sie zu einer einzelnen Funktion zusammenfassen, die als
Funktionswert ein Paar aus Ausgangswert und neuem Zustand liefert. Die
Funktion hat also die Form
1
(z', y) = f z x
wobei z der aktuelle Zustand, x der Eingangswert, z' der neue Zustand
und y der Ausgangswert ist.
Ein zustandsbehaftetes Übertragungsglied kann man nun wie folgt
definieren:
1
zustBehGlied f z (x:xs) = y : zustBehGlied f z' xs
2
where (z', y) = f z x
Das Übertragungsglied ist also eine Funktion mit den Argumenten
- f: die oben beschriebene Zustandsübergangs- und Ausgangsfunktion
- z: der Anfangszustand
- (x:xs): die Liste der Eingangswerte bestehend aus dem ersten Element x
und dem Rest xs
Iher Funktionswert ist die Liste der Ausgangswerte.
Das erste davon ist der y-Teil des Funktionswerts (z', y) von f z x.
Der Rest der Ausgangsliste ergibt sich aus der rekursiven Anwendung von
zustBehGlied auf den Rest der Eingangsliste, wobei nun als
Anfangszustand der Folgezustand z' von z genommen wird, der ebenfalls
durch die Funktion f berechnet wird.
Das Beste an dieser Vorgehensweise: Der Zustand z kann von einem
beliebigen Typ sein. Hängt bspw. wie beim Integral der y-Wert vom
jeweils letzten y-Wert ab, so ist z einfach eine Zahl, nämlich der
letzte Wert vonm y. Hängt wie beim PT2-Glied y vom letzten und vom
vorletzten y ab, ist z ein Paar (2-Tupel) von zwei Zahlen. Der Zustand,
kann aber genauso gut ein Tupel von n Zahlen sein. Es müssen auch nicht
unbedingt Zahlen sein: Boolsche Werte, Textstrings oder beliebige andere
Datentypen gehen ebenso.
Auch die Eingangs- und Ausgangsdaten müssen nicht unbedingt Zahlenwerte
sein. Es könnten genauso gut komplexe Beschreibungen von Produkten in
einer Fabrik sein, womit sich eine Materialflusssimulation realisieren
ließen. Das Schöne an Haskell ist, dass man ohne große Anstrengungen
generische Funktionen schreiben kann, was ganz gewaltig die
Wiederverwendbarkeit von Code unterstützt. Die Wiederverwendbarkeit wird
zwar auch in der OOP immer als großer Vorteil gepredigt, aber eher
selten in die Tat umgesetzt, da dort generischen Code zu schreiben
einfach viel mehr Arbeit bedeutet.
Ist ein Übertragungsglied – wie bspw. das P-Glied – überhaupt nicht von
einem Zustand abhängig, d.h. zustandslos, könnte man als Typ und
einzigen Wert einfach () wählen. () ist in Haskell einfach "nichts",
vergleichbar mit None in Python.
Um aber bei so einfachen Übertragungsgliedern wie dem P-Glied nicht den
(nicht benötigten) Zustand herumschleppen zu müssen, kann man man als
zustandsloses Glied auch einfach die Haskell-Funktion map verwenden.
Die tut exakt das Gewünschte, nämlich eine Funktion auf jedes Element
einer Liste anzuwenden und aus den Ergebnissen eine neue Liste zu
bilden:
1
zustLosGlied = map
Damit kann man das P-Glied ganz simpel so definieren:
1
pGlied k = zustLosGlied (*k)
(*k) ist dabei die Kurzschreibweise einer Funktion, die ihr Argument mit
k multipliziert.
Die zustandsbehafteten Übertragungsglieder sehen folgendermaßen aus:
1
iGlied k dt = zustBehGlied f z0
2
where f z x = (z', y')
3
where y = z
4
y' = k * (y + 0.5 * x) * dt
5
z' = z + x
6
z0 = 0
7
8
dGlied k dt = zustBehGlied f z0
9
where f z x = (z', y)
10
where y = k * (x - z) / dt
11
z' = x
12
z0 = 0
13
14
pt1Glied k tau dt = zustBehGlied f z0
15
where f z x = (z', y')
16
where y = z
17
y' = (tau * y + dt * k * x) /
18
(tau + dt)
19
z' = y'
20
z0 = 0
21
22
pt2Glied k d w0 dt = zustBehGlied f z0
23
where f z x = (z', y'')
24
where (y, y') = z
25
y'' = (-y + (2 * d * dtw0 + 2) * y' + dtw0^2 * k * x) /
26
(1 + 2 * d * dtw0 + dtw0^2)
27
z' = (y', y'')
28
dtw0 = dt * w0
29
z0 = (0, 0)
Sie sind alle nach dem gleichen Schema aufgebaut und haben die Form
1
zustBehGlied f z0
wobei in den nachfolgenden Zeilen jeweils Definitionen für die Funktion
f und den Anfangszustand z0 gegeben werden.
Das I-Glied ist übrigens im Vergleich zur letzten Version etwas
modifiziert und berechnet das Integral nicht mehr mir dem Rechteck-,
sondern mit dem Trapezverfahren.
Noch eine Anmerkung zu der Wahl der Variablennamen: Den Suffix ' habe
ich zur Kennzeichnung des Nachfolgers einer anderen Variablen verwendet.
So ist z' der Folgezustand von z und y' der zeitliche Nachfolger von y.
Entsprechend ist y'' der übernächste Wert nach y. Im PT2-Glied heißt
deswegen der neu zu berechnende Ausgangswert y'', der von seinem
Vorgänger y' und seinem Vorvorgänger y abhängt.
Haskellschüler schrieb:> Damit wäre:zustBehGlied = snd . Data.List.mapAccumL
(Fast) genau nach dieser Funktion habe ich gesucht, als ich obiges
geschrieben habe. Ich hatte da irgendetwas in Erinnerung, wusste den
Namen der Funktion aber nicht mehr. Also habe ich die Signatur
1
(z -> x -> (z, y)) -> z -> [x] -> [y]
in Hoogle eingegeben, die bis auf den Funktionswert [y] exakt mit der
von mapAccumL übereinstimmt. Obwohl der Match-Agorithmus von Hoogle
normalerweise ja recht tolerant ist, hat er in diesem Fall aber keinen
einzigen Treffer geliefert.
Auf die Idee, dem Funktionswert noch den letzten Zustand hinzuzufügen
oder einfach mal Data.List durchzublättern, bin ich leider nicht
gekommen. Mit dieser geringfügig geänderten Eingabe
1
(z -> x -> (z, y)) -> z -> [x] -> (z, [y])
wäre mapAccumL gleich an erste Stelle vorgeschlagen worden.
Auf jeden Fall danke für den Hinweis!
Haskellschüler schrieb:> Und:>
> where y'' = (-y + (2 * d * dtw0 + 2) * y' + dtw0^2 * k * x) /
4
> (1 + 2 * d * dtw0 + dtw0^2)
5
> dtw0 = dt * w0
6
> z0 = (0, 0)
>> Dann sieht man auch, wie y' und y'' "durch-scrollen".
Ja, das stimmt schon. Ich dachte nur, dass es dem Verständnis eher
dienlich wäre, wenn ich die Definition von z' (genauso wie auch die von
y'' und z0) explizit hinschreibe, so dass das allen vier
Übetragungsgliedern gemeinsame Schema besser erkennbar ist.