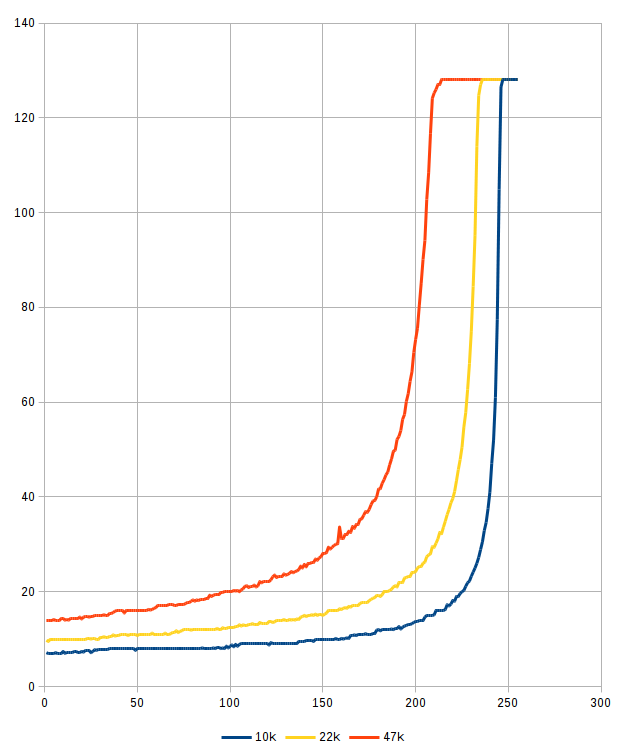
Hallo allerseits, folgende Kurve habe ich aufgenommen (mich interessiert primär die gelbe) nun würde ich die für eitere Untersuchugnen / Linearisierung gerne durch eine Funktion approximieren. Irgendwie sieht es exponentiell aus. Polynom soll mir aber auch recht sein. Wie geht man sowas an? "Trendlinie" im Excel liefert nciht wirklich ein sinnvolles Ergebnis. octave hätte ich zur Verfügung, weiss aber nicht wo ich da anfangen soll zu suchen...
Angehängte Dateien:
-

Gain.png
31 KB
> exponentiell .. Polynom ..
Einfach irgendwas zu verwenden macht wenig Sinn. Welche Funktion steckt
dahinter. Welche Funktion sollte dahinter stecken. Woher kommen die
Werte ?
Jetzt Nicht schrieb: >> exponentiell .. Polynom .. > > Einfach irgendwas zu verwenden macht wenig Sinn. Welche Funktion steckt > dahinter. Weiss ich nicht. > Welche Funktion sollte dahinter stecken. Weiss ich nicht. > Woher kommen die Werte ? Meßwerte Es handelt sich um einen normalen invertierenden OP-Verstärker, dessen Feedback-Widerstand ein LDR ist (parallel zu 100k), der LDR wird von einer LED mit PWM bestrahlt. Die Reihen (10k, 22k, 47k) sind der Vorwiderstand der LED. X-Achse ist der PWM-Wert (0..255 aber invertiertes PWM), Y-Achse der Ausgangspegel (bei konstantem Eingangssignal)
Die "Trendlinie" in Excel kann nicht nur linear, sondern u.A. auch exponentiell, logarithmisch oder Polynomisch. Das sieht schon stark exponentiell aus, so groß kann die Abweichung eigentlich nicht sein. Was heißt denn "nicht Sinnvoll"?
Weiss nicht ... Dann stell doch die Gleichungen auf. Wie sich der LDR unter Licht verhaelt ist im Datenblatt. Alternativ. Mach einen exponential fit. Vielleicht passt er. Gut. Vielleicht auch nicht. Falls nicht, ein Polynom. Vielleicht passt es mit tiefem Grad. Wenn die Ordnungen explodieren, ist nicht gut. Was bedeutet passen? Fehler kleiner als ?
Gerd schrieb: > Die "Trendlinie" in Excel kann nicht nur linear, > sondern u.A. auch exponentiell, logarithmisch oder Polynomisch. Hab alles durchprobiert. OpenOffice liefert bei polynomen hohen Grades (so ab 10) ein einigermaßen passendes Ergebnis, Excel (2010) kann nur bis 6. ordnung. > Das sieht schon stark exponentiell aus, so groß kann > die Abweichung eigentlich nicht sein. > Was heißt denn "nicht Sinnvoll"? extreme Abweichung
Jetzt Nicht schrieb: > Alternativ. Mach einen exponential fit. Vielleicht passt er. Gut. Wie macht man das (z.B. mit octave, mein Vertrauen in Excel ist endenwollend) > Vielleicht auch nicht. Falls nicht, ein Polynom. Vielleicht passt es mit > tiefem Grad. Wenn die Ordnungen explodieren, ist nicht gut. Auch hier wieder: Wie macht man das ohne Excel? > Was bedeutet passen? Fehler kleiner als ? erstmal würde mir ein "optisch schönes Resultat" genügen, dann mach ich mir Gedanken um fehler. Bisher ist es schon optisch komplett daneben
In Octave und Matlab gibt es die Funktion expfit, die würde ich mir mal anschauen. Kannst du die Messergebnisse als Tabelle hochladen?
Plotte doch mal enstelle der Ausgangsspannung des Verstärkers dessen Kehrwert, da wirst du eine wesentlich gutmütigere Kurve erhalten, die sich evtl. auch gut mit einem einfachen Polynom approximieren lässt.
Alexander F. schrieb: > In Octave und Matlab gibt es die Funktion expfit, die würde ich mir mal > anschauen. polyfit hab ich mal zum laufen bekommen:
1 | data=load('data.dat');
|
2 | x=data(:,1); |
3 | y=data(:,2); |
4 | |
5 | p = polyfit (x, y, 8); |
6 | |
7 | xx = linspace (min(x), max(x), 101) ; |
8 | yy = polyval (p, xx); |
9 | plot (xx, yy, '-', x, y, 's') |
expfit kapier ich grad noch nicht, aber ich arbeite an der Behebung des Problems :-) (ach, hätt ich doch damals im Mathe-Unterricht besser aufgepasst...) > Kannst du die Messergebnisse als Tabelle hochladen? hängt dran Yalu X. schrieb: > Plotte doch mal enstelle der Ausgangsspannung des Verstärkers dessen > Kehrwert, da wirst du eine wesentlich gutmütigere Kurve erhalten, die > sich evtl. auch gut mit einem einfachen Polynom approximieren lässt. Gute Idee, werd ich gleich probieren...
Yalu X. schrieb: > Plotte doch mal enstelle der Ausgangsspannung des Verstärkers dessen > Kehrwert, da wirst du eine wesentlich gutmütigere Kurve erhalten, die > sich evtl. auch gut mit einem einfachen Polynom approximieren lässt. Ist ja genial! Funktioniert ja (fast) perfekt! Wie kommst du auf sowas?
Empfehle ein Polynom 16. Ordnung. Das geht in Excel mit Hilfe der RGP-Funktion. Nur für faule Menschen, welche die Regressionsfunktion aus der Grafik abschreiben wollen, gilt die Beschränkung auf 6. Ordnung. :-)
Michael Reinelt schrieb: > Yalu X. schrieb: >> Plotte doch mal enstelle der Ausgangsspannung des Verstärkers >> dessen Kehrwert, da wirst du eine wesentlich gutmütigere Kurve >> erhalten, die sich evtl. auch gut mit einem einfachen Polynom >> approximieren lässt. > > Ist ja genial! Funktioniert ja (fast) perfekt! Wie kommst du auf > sowas? Er weiss, wie 1/x aussieht; er weiss, wie 1/n^n aussieht. Er weiss auch, dass Deine X-Achse physikalisch falsch herum ist; die Polstelle gehört also zu X->0. Deine Modellfunktion ist gebrochen-rational (nichts anderes hat Yalu geschrieben).
thomas s schrieb: > Empfehle ein Polynom 16. Ordnung. Sicher nicht. Eine Funktion mit Polstelle lässt sich durch ein Polynom nicht vernünftig approximieren. Ich würde es mal mit A/(B+C*x) probieren.
Possetitjel schrieb: > Er weiss, wie 1/x aussieht; er weiss, wie 1/n^n aussieht. Er weiss > auch, dass Deine X-Achse physikalisch falsch herum ist; die Polstelle > gehört also zu X->0. Jetzt, wo du's sagst... > Deine Modellfunktion ist gebrochen-rational (nichts anderes hat Yalu > geschrieben). wie ich schon schreib: Ach, hätte ich doch damals in Mathe besser aufgepasst :-( D A N K E !
Es wird immer besser: Wenn ihc den hinweis der "invertierten" X-Achse auch noch aufgreife, lässt sich die Kurve sehr genau durch einen logaritmus ausdrücken. Und die Umkehrfunktion (die ich vermutlich brauche) ist dann eine schöne Exponentialfunktion. Zumindest hat mir das mein OpenOffice Calc gezeigt. ich möchte mich aber trotzdem damit noch etwas in Octave spielen. ich hab mir das "expfit" genauer durchgelesen, Problem dabei ist dass dieses äquidistante X-Werte haben mag, die ich nicht habe wenn ich die Umkehrfunktion fitten will. expfit ist aber wohl nur eine Sonderform einer allgemeinen least root mean square Approximations- oder Regressionsfunktion. Hier komm ich leider nicht weiter, und wäre für ein Beispiel wie man sowas in octave angeht, sehr dankbar!
Angehängte Dateien:
-

fit.png
22 KB
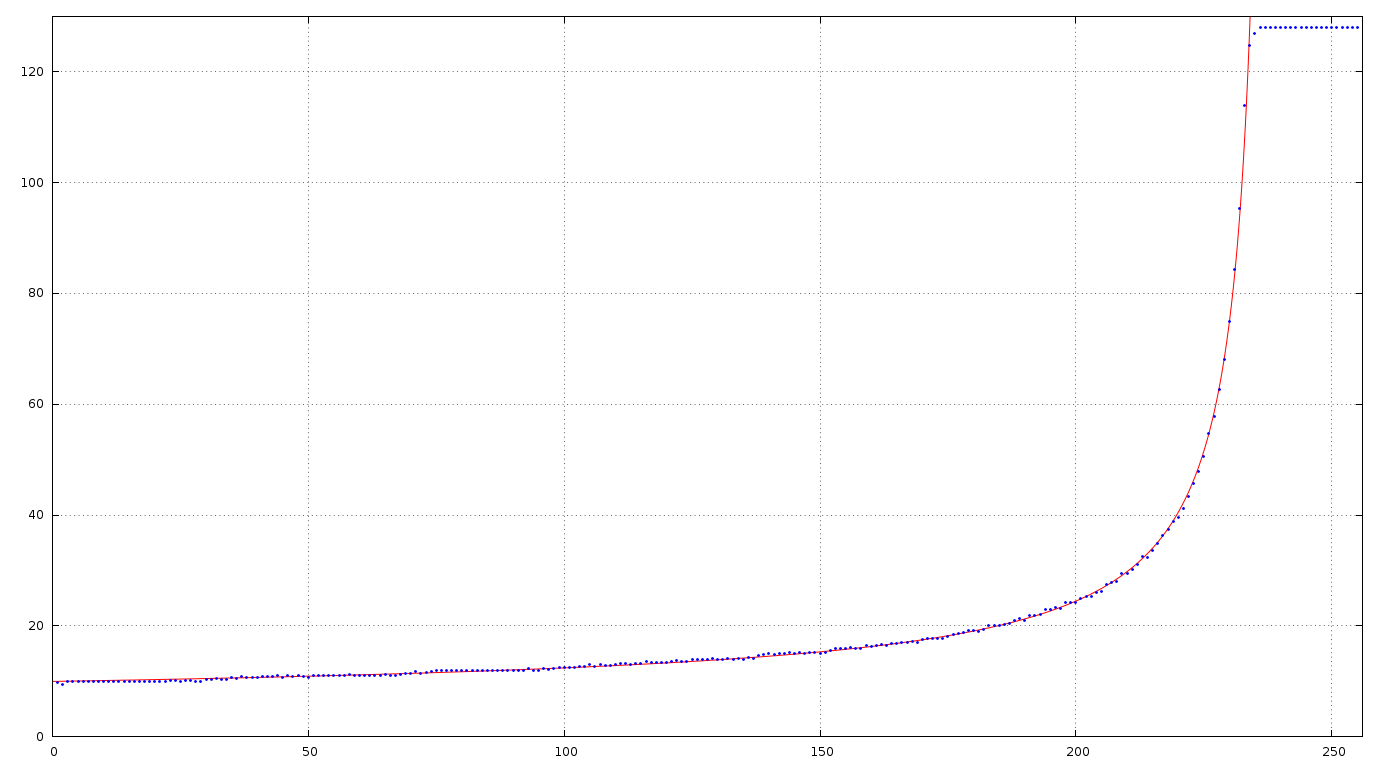
Michael Reinelt schrieb: > ich möchte mich aber trotzdem damit noch etwas in Octave spielen. > > ich hab mir das "expfit" genauer durchgelesen, Problem dabei ist dass > dieses äquidistante X-Werte haben mag, die ich nicht habe wenn ich die > Umkehrfunktion fitten will. > > expfit ist aber wohl nur eine Sonderform einer allgemeinen least root > mean square Approximations- oder Regressionsfunktion. > > Hier komm ich leider nicht weiter, und wäre für ein Beispiel wie man > sowas in octave angeht, sehr dankbar! In Octave gibt es im Paket optim die Funktion leasqr, die den Levenberg-Marquardt-Algorithmus implementiert: http://octave.sourceforge.net/optim/function/leasqr.html http://de.wikipedia.org/wiki/Levenberg-Marquardt-Algorithmus Damit kannst du nichtlineare Funktionen fitten, wie bspw. die folgende, gut zu deinen Messdaten passende:
Da ich Octave weder installiert habe noch mich damit auskenne, habe ich das Ganze mal in Haskell und der GSL (GNU Scientific Library) probiert. Hier ist das Programm:
1 | import Numeric.GSL.Fitting |
2 | |
3 | -- Datei mit den Messdaten |
4 | fileName = "data2.dat" |
5 | |
6 | -- Funktion |
7 | model [a,b,c] x = [a / log(b - c * x)] |
8 | |
9 | -- Ableitungen der Funktion nach a, b und c |
10 | derivs [a,b,c] x = [[ 1 / log(b - c * x) , |
11 | - a / ((b - c * x) * log(b - c * x) ^ 2) , |
12 | x * a / ((b - c * x) * log(b - c * x) ^ 2) |
13 | ]] |
14 | |
15 | startVals = [33, 25, 0.1] -- Startwerte für a, b und c |
16 | maxAbsErr = 1e-12 -- maximaler Absolutfehler von a, b und c |
17 | maxRelErr = 1e-12 -- maximaler Relativfehler von a, b und c |
18 | maxIter = 100 -- maximale Anzahl Iterationen |
19 | |
20 | -- Eingabezeile parsen |
21 | parseInput :: String -> [(Double, [Double])] |
22 | parseInput = map parseLine . lines |
23 | where parseLine s = (x, [y]) |
24 | where [x, y] = map read (words s) |
25 | |
26 | main = do |
27 | s <- readFile fileName |
28 | let samples = parseInput s |
29 | (solution,_) = fitModel maxAbsErr maxRelErr maxIter (model, derivs) samples startVals |
30 | print solution |
Die Startwerte für a, b und c habe ich durch Ausprobieren ermittelt. Sie sollten nicht zu falsch sein, weil die Messdaten relativ dicht an den Asymptoten der Logarithmus- und der Kehrwertfunktion liegen. Außerdem habe ich bei deinen Messdaten alle mit x>234 weggelassen, da bei diesen der Opamp offensichtlich übersteuert und sie deswegen das Ergebnis verfälschen würden. Die Ergebnisse für a, b und c:
1 | [24.310702356955158,11.487756749378562,4.3932603723006926e-2] |
Das Diagramm im Anhang zeigt deine Messdaten (blau) und die gefittete Kurve (rot).
Wahnsinn! ich staune Bauklötze! Die Übereinstimmung ist ja geradezu unheimlich! Ich bin verwundert, weil das heisst auch dass meine Messungen kaum Ausreißer haben... Mittlerweile bin ich auch schon weitergekommen mit dem leasqr, ich hab das mal grundsätzlich verstanden, laufe derzeit aber noch in Probleme, offensichtlich weil der ln im Zuge der Optimierung ins komplexe läuft... das krieg ich aber hin (Zeit! gebt mir Zeit!) Ganz abgesehen davon bin ich schwer beeindruckt von der Haskell'schen Eleganz. Verdammt, schon wieder was worin ich mich gerne vertiefen täte... Zeit! Gebt mir Zeit! Falls ich meine Pension noch erlebe, wird mir dann sicher nicht langweilig ;-) Nochmal ein riesengroßes Danke!
Michael Reinelt schrieb: > laufe derzeit aber noch in Probleme, offensichtlich weil der ln im > Zuge der Optimierung ins komplexe läuft... Dieses Problem hatte ich anfangs auch bis ich die Startwerte halbwegs vernünftig gewählt habe. Ebenso wichtig war es, die nicht zum Rest passenden Werte am Ende der Messreihe wegzulassen.
Yalu X. schrieb: > Michael Reinelt schrieb: >> laufe derzeit aber noch in Probleme, offensichtlich weil der ln im >> Zuge der Optimierung ins komplexe läuft... > > Dieses Problem hatte ich anfangs auch bis ich die Startwerte halbwegs > vernünftig gewählt habe. Ebenso wichtig war es, die nicht zum Rest > passenden Werte am Ende der Messreihe wegzulassen. Ich werde das Problem aus der anderen Seite angehen: X und Y vertauschen, Umkehrfunktion suchen. Dabei wird aus dem ln() ein e^x, und das ist da etwas robuster :-)
Ich habe mal vor Jahren eine Software geschrieben, die einfach durch systematisches Probieren nahezu beliebige Kurvenverläufe an ein Polynom n-ter Klasse approxximieren konnte - leider gibts die Software nicht mehr, aber ich kann beschreiben, wie die gearbeitet hat: - Basis war ein Polynom einstellbarer Länge nach dem Prinzip y=ax^n+bx^n-1+cx^n-2+dx^n-3+ex^n-4 ... usw. - am Anfang waren alle Multiplikatoren auf 1 gesetzt - beginnend mit a wurde jeweils die Schrittweite halbiert und das Vorzeichen gewechselt, bis das Quadrat der Fehlersumme zu den Messwerten ein Minimum oder die "Auflösung" des Compilers erreicht war - dann wurde zu b gewechselt und der Prozess wiederholt - dann wurde zu c gewechselt und der Prozess wiederholt usw. Das hat vor ca. 25 Jahren und in BASIC durchaus ein paar Stunden gedauert, hat aber hervorragende Resultate bei Druckkennlinien geliefert, die eine ganz ähnliche Form wie die des TO haben.
Frank Esselbach schrieb: > Das hat vor ca. 25 Jahren und in BASIC durchaus ein paar Stunden > gedauert, hat aber hervorragende Resultate bei Druckkennlinien > geliefert, die eine ganz ähnliche Form wie die des TO haben. Glaub ich gerne. Polynom-Approximation ist aber heutzutage eh einfach, kann ja sogar schon Excel :-) Wie aber weiter oben schon jemand angemerkt hat, meine Funktion hat eine Polstelle, und "normale" Polynome haben keine Polstellen :-(
Angehängte Dateien:
-

lsqr.png
26 KB
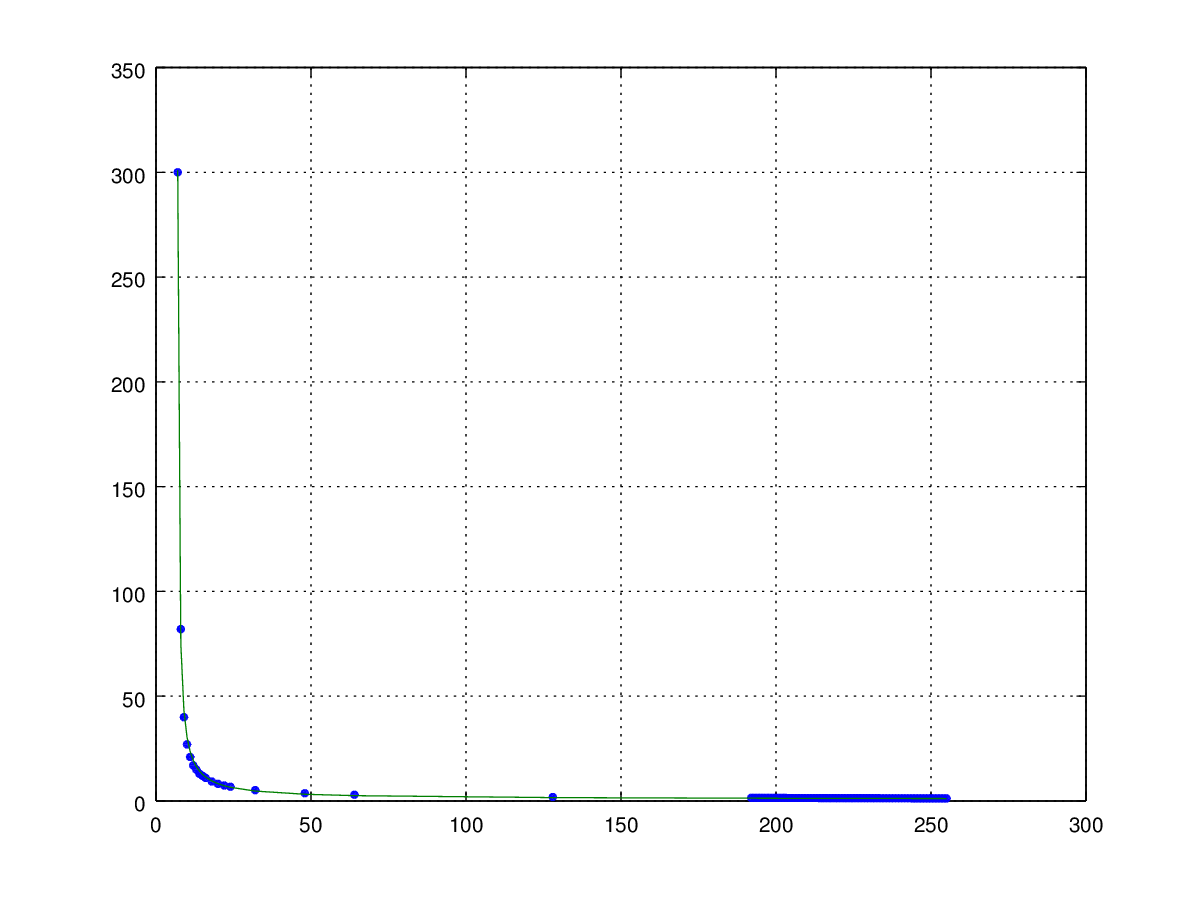
Ich bräuchte nochmal eure Hilfe (Yalu, hoffentlich liest du mit) ich hab das mittlerweile gut im Griff, kann das mit Octave gut optimieren, hab aber jetzt ein eher fundamentales Problem, wo ich nicht weiterkomme: Erstmal hab ich ein paar Rahmenbedingungen umgestellt, ich arbeite nicht mehr mit dem gain sondern direkt mit dem Widerstand des LDR. Damit schalte ich ein paar Nebeneffekte wie die Parallelschaltung eines zweiten Widerstands zum LDR aus, außerdem kann ich den Widerstand an relevanten Stützstellen genauer bestimmen. Weiters habe ich die PWM wieder "zurück-invertiert". Die resultierenden Messpunkte und die Approximation mit octave seht ihr im Bild (X = PWM, Y = Widerstand in kOhm) Sieht auf den ersten Blickt gut aus. ich hab die Fehler punktuell ausgewertet, liegen so bei +/- 0.5 kOhm ABER: Der Levenberg-Marquardt arbeitet mit kleinsten Quadraten und damit mit absoluten Fehlern. Die 0.5kOhm Fehler tun mir bei 300 kOhm genau überhaupt nicht weh, bei 1.25kOhm aber sehr wohl... Ein erster Schritt war, Y-Werte zwischen 192 und 255 vorher händisch zu interpolieren und hinzuzufügen (ich hatte keine Lust 60 fast identische Messwerte aufzunehmen), das sind die vielen Punkterln am rechten Rand. Das hat schon mal eine große Verbesserung gebracht, weil der Bereich der Kurve damit automatisch stärker gewichtet wird, aber das kanns irgendwie nicht sein... Irgendwie suche ich nach einer Variante, die mir den relativen Fehler minimiert. Gibts sowas überhaupt? Wenn ja, bräuchte ich ein paar Hinweise, wonach ich suchen soll. Edit: sorry, versehentlich zweimal Bild. Könnte ein Moderator bitte eins löschen? Danke!
Michael Reinelt schrieb: > Irgendwie suche ich nach einer Variante, die mir den relativen Fehler > minimiert. > > Gibts sowas überhaupt? Wenn ja, bräuchte ich ein paar Hinweise, wonach > ich suchen soll. Ja, gibt es, nämlich den Levenberg-Marquardt-Algorithmus ;-) In seiner allgemeinen Form http://de.wikipedia.org/wiki/Levenberg-Marquardt-Algorithmus dient er nicht nur der Fehlerminimierung beim Kurven-Fitten, sondern minimiert er eine (fast) beliebige Funktion F nach der Methode der kleinsten Quadrate. Die Octave-Funktion leasqr nimmt für F eine Funktion, die den Vektor der absoluten Fehler der Modellfunktion bzgl. der Messdaten liefert. Genauso gut könnte man F so definieren, dass bzgl. des relativen Fehlers optimiert wird. Leider kann man in leasqr das F nicht direkt angeben. In Matlab scheint das mit lsqonlin zu gehen, in Haskell und der GSL heißt die ensprechende Funktion nlFitting ¹. In Octave scheint die Funktion "missing" zu sein: http://wiki.octave.org/Optimization_package Hier gab es eine Diskussion dazu, in der auch Alternativen genannt wurden (der Thread ist allerdings schon recht alt): http://octave.1599824.n4.nabble.com/lsqnonlin-td1605962.html Vielleicht gibt dir das aber zumindest einen Startpunkt für weitere Recherchen. ————————————— ¹) Die von mir oben verwendete Funktion fitModel ist lediglich ein 5-Zeilen-Wrapper um nlFitting herum.
Yalu X. schrieb: > Vielleicht gibt dir das aber zumindest einen Startpunkt für weitere > Recherchen. Ja, Danke! leasqr() ist offensichtlich alt, und wurde durch das wesentlich flexiblere nonlin_residmin (non-linear residual minimization) ersetzt. Hier liefert die Funktion tatsächlich wie von dir beschrieben die residuals, und wie ich die erzeuge (relativ, absolut, ...) bleibt mir überlassen. Allerdings bereitet alleine das Lesen der diversen Dokus (sowie deines Beitrages) mir Mathe-Null schon körperliche Schmerzen ;-)
Michael Reinelt schrieb: > Allerdings bereitet alleine das Lesen der diversen Dokus (sowie deines > Beitrages) mir Mathe-Null schon körperliche Schmerzen ;-) Ein Messkurve mit einem Polynom 10. Grades zu fitten, grenzt dagegen an Körperverletzung. Schon eine Gleichung mit 5 Variablen reicht, um einen Elefanten ausreichend gut zu beschreiben. Michael Reinelt schrieb: > Gerd schrieb: >> Die "Trendlinie" in Excel kann nicht nur linear, >> sondern u.A. auch exponentiell, logarithmisch oder Polynomisch. > Hab alles durchprobiert. OpenOffice liefert bei polynomen hohen Grades > (so ab 10) ein einigermaßen passendes Ergebnis, Excel (2010) kann nur > bis 6. ordnung.
Michael Reinelt schrieb: > Erstmal hab ich ein paar Rahmenbedingungen umgestellt, ich > arbeite nicht mehr mit dem gain sondern direkt mit dem > Widerstand des LDR. Damit schalte ich ein paar Nebeneffekte > wie die Parallelschaltung eines zweiten Widerstands zum > LDR aus, außerdem kann ich den Widerstand an relevanten > Stützstellen genauer bestimmen. Weiters habe ich die PWM > wieder "zurück-invertiert". Sehr gut; alles vernünftige Maßnahmen. Generell ist es sinnvoll, alle bekannten Zusammenhänge schrittweise aus der Approximation herauszunehmen und nur den wirklich unbekannten Teil durch die Kleinste- Quadrate-Mühle laufen zu lassen. > Ein erster Schritt war, Y-Werte zwischen 192 und 255 vorher > händisch zu interpolieren und hinzuzufügen (ich hatte keine > Lust 60 fast identische Messwerte aufzunehmen), das sind die > vielen Punkterln am rechten Rand. Das hat schon mal eine > große Verbesserung gebracht, weil der Bereich der Kurve > damit automatisch stärker gewichtet wird, aber das kanns > irgendwie nicht sein... Äähhh... doch!? Die Kleinste-Quadrate-Methode ist gut gegen zufällige Fehler. Das setzt voraus, dass Dein System stark überbestimmt ist, d.h. dass Du sehr viel mehr Messpunkte hast, als Deine Modellfunktion Freiheitsgrade. Sonst ist nix mit Statistik. Um ein Polynom 4. Grades an 5 Punkte zu approximieren, braucht man keine kleinste-Quadrate-Methode. Selbstverständlich beeinflusst die Verteilung der Messpunkte die Güte Deiner Approximation. Das ist nicht zu vermeiden, das ist aus rein mathematischen Gründen so. U.U. kann man bei Levenberg-Marquard Gewichte für die Stütz- stellen angeben; trotzdem ist eine hinreichende Anzahl und gute Verteilung der Stützstellen anzustreben. > Irgendwie suche ich nach einer Variante, die mir den relativen > Fehler minimiert. > > Gibts sowas überhaupt? Selbstverständlich: Stützstellen und Modellfunktion logarithmieren, und dann erst approximieren. (Für alles weitere natürlich wieder mit der entlogarithmierten Modellfunktion arbeiten!) Auch wenn Du mich jetzt für bekloppt hältst: Es ist nicht dasselbe, ob eine Funktion an Daten oder der Logarithmus der Funktion an den Logarithmus der Daten approximiert wird.
Possetitjel schrieb: > Stützstellen und Modellfunktion logarithmieren, > und dann erst approximieren. Die Lösung ist wieder mal so genial einfach, dass ich selbst nie drauf gekommen wäre... Funktioniert ganz ausgezeichnet, danke!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.