Hallo zusammen,
ich versuche gerade die Zeit für die Ausführung von Funktionen auf einen
Cortex M7 (STM32F746) zu messen. Das mache ich wie hier im Artikel (ganz
unten) beschrieben:
STM32 für Einsteiger
Beim M4 hat das so funktioniert. Beim F7 habe ich 2 Probleme:
- Der Counter lässt sich mit
1
DWT->CYCCNT=0;
nicht auf 0 zurücksetzen.
- Für ein einfaches inkrementieren einer int Variable werden lt. dem
Zähler 12 Taktzyklen benötigt. Obwohl im Disasembly nur ein Befehl zu
sehen ist. Beim M4 wurde bei gleichem code nur ein Zyklus angezeigt.
Ich benutze den IAR Compiler. Als Projekt Grundgerüst habe ich das
Template aus dem Cube Ordner genutzt
(..\STM32Cube_FW_F7_V1.1.0\Projects\STM32746G-Discovery\Templates\Src)
1
intmain(void)
2
{
3
/* This project template calls firstly two functions in order to configure MPU feature
4
and to enable the CPU Cache, respectively MPU_Config() and CPU_CACHE_Enable().
5
These functions are provided as template implementation that User may integrate
6
in his application, to enhance the performance in case of use of AXI interface
7
with several masters. */
8
9
/* Configure the MPU attributes as Write Through */
10
MPU_Config();
11
12
/* Enable the CPU Cache */
13
CPU_CACHE_Enable();
14
15
/* STM32F7xx HAL library initialization:
16
- Configure the Flash ART accelerator on ITCM interface
17
- Configure the Systick to generate an interrupt each 1 msec
18
- Set NVIC Group Priority to 4
19
- Low Level Initialization
20
*/
21
HAL_Init();
22
23
/* Configure the System clock to have a frequency of 216 MHz */
Falko J. schrieb:> - Für ein einfaches inkrementieren einer int Variable werden lt. dem> Zähler 12 Taktzyklen benötigt. Obwohl im Disasembly nur ein Befehl zu> sehen ist. Beim M4 wurde bei gleichem code nur ein Zyklus angezeigt.
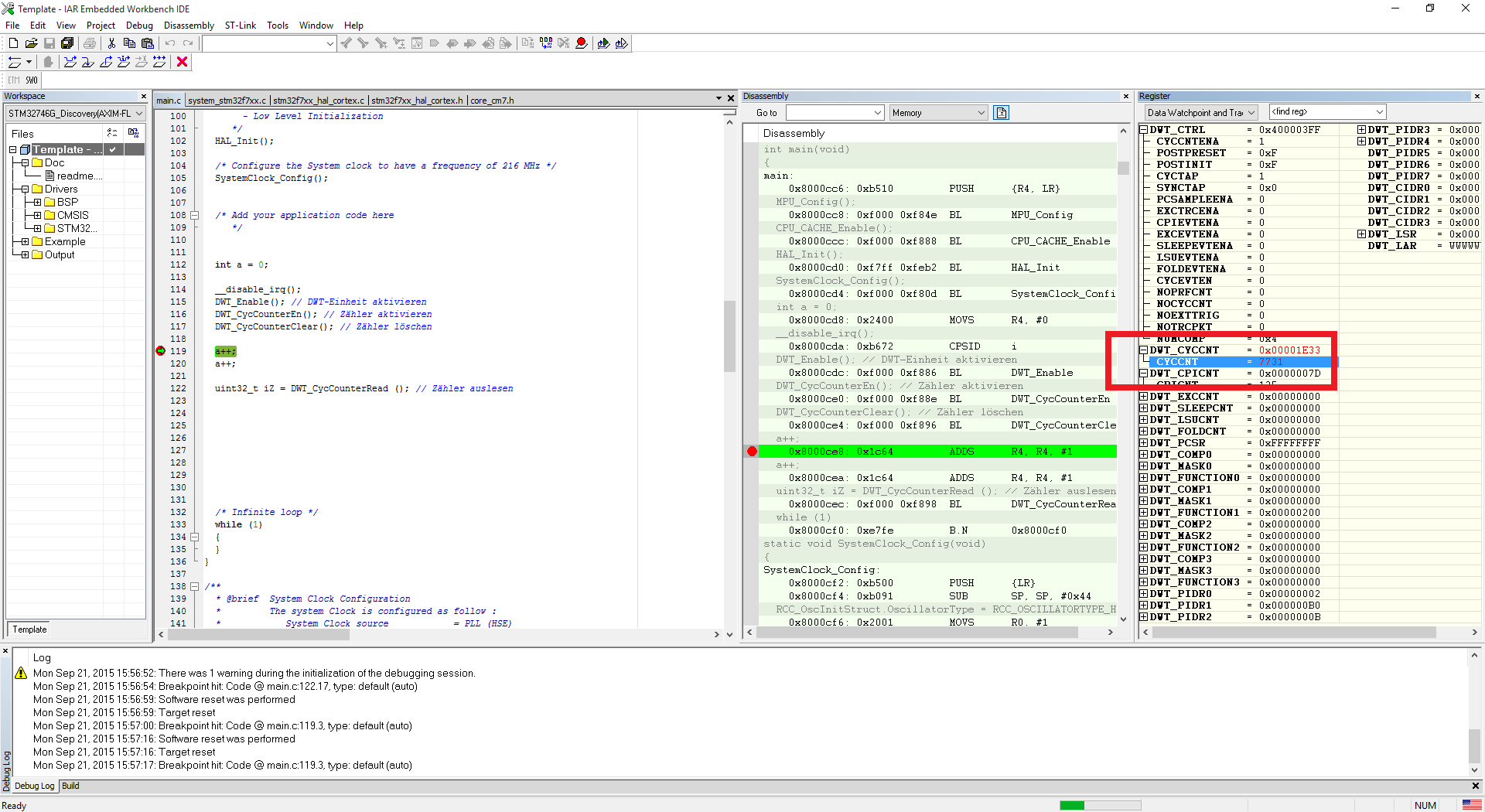
Dann zeig uns doch mal das Disassembly, inklusive des counter clear.
Lass Dein Programm einmal mit nur einem
a++;
laufen und danach mit 11:
a++;
a++;
a++;
a++;
a++;
a++;
a++;
a++;
a++;
a++;
Die Differenz beider Laufzeiten geteilt durch 10 ist die
Ausführungsdauer von:
a++;
bzw.
0x8000ce8: 0x1c64 ADDS R4, R4, #1
Gruß, Stefan
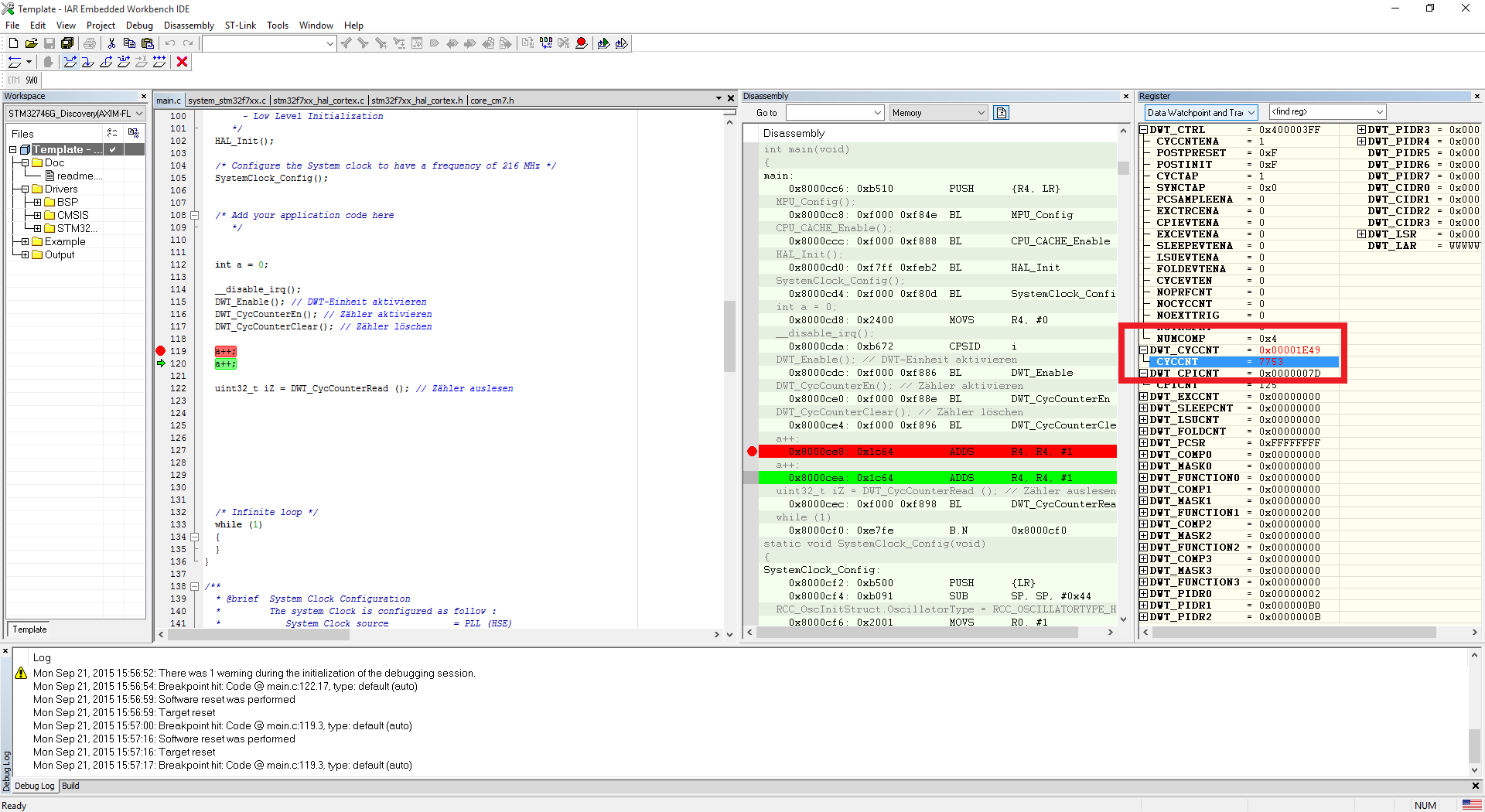
Aber mit Optimierung hat sich nichts geändert. Das inkrementieren der
Variable ist aber auch ohne Optimierung nur ein assembler Befehl.
Trotzdem erhöht sich der Cycle counter um 11, wenn in Debugger genau
diesen einen Schritt weiter gehe.
Mhh das kann's nicht sein, auch wenn ich mit dem Debugger den cycle
counter lese (also direkt das Register), werden viel zu viele Schritte
angezeigt.
Anbei 2 Bilder (vor und nach der Inkrementierung)
In die 22 Takte würde ein (fast)leerer Interrupt Handler passen, hattest
Du nicht oben den Systick eingeschaltet...?
Ich würde es mit __disable_fault_irq(); vorher probieren.
Hallo Jim,
gute Idee, aber das war es auch nicht. Denke ich zumindest...hab alle
Interrupts abgeschaltet, die ich gefunden habe (systick war an).
Zusätzlich das __disable_fault_irq(); von dir ausprobiert und
__disable_irq();
Keine Änderung :-( ... so langsam denk ich der M7 will mich mobben...
Steht irgendwo in Stein gemeisselt, dass sich dieser Zähler bei den
Aktivitäten des Debuggers nur im Rahmen eines einzelnen Befehlsschritts
des Anwenderprogramms bewegt? Ich kann mir nämlich schon vorstellen,
dass die Ausführung eines einzelnen Befehls im Debugger auf der
Zielhardware deutlich mehr macht, als nur diesen einen Befehl
auszuführen.
Zyklenmessung erfolgt üblicherweise anders. Zähler auslesen,
Messprogramm laufen lassen, Zähler nochmal auslesen, Differenz ausgeben
- und die Differenz bei leerem Messprogramm vorher abziehen. Dabei aber
aufpassen, dass der Optimizer des Compiler keinen Strich durch die
Rechnung macht und die Reihenfolge ändert. Und das alles ohne
Debugger.
A. K. schrieb:> Steht irgendwo in Stein gemeisselt, dass sich dieser Zähler bei den> Aktivitäten des Debuggers nur im Rahmen eines einzelnen Befehlsschritts> des Anwenderprogramms bewegt
Mhhh, wahrscheinlich hast du Recht, vielleicht könnte es trotzdem mal
noch jemand anderes mit einem M7 Board und anderen compiler/Debugger
probieren....
LG
Falko
Ich habe das Phänomen mit Crossworks und einem STM32F746VG auch
beobachtet. Debug HW ist ein Nucleo Board. Viel getestet habe ich aber
noch nicht da die Platine noch nicht vollständig bestückt ist. Heute
Abend löte ich weiter.
Als nächstes wollte ich es dann ohne den Cache probieren. Und auch
schauen ob es nur bei einem Singlestep auftritt oder auch bei einer
längeren Befehlssequenz wenn die CPU per BP gestoppt wird.
Zurücksetzen kann ich den Counter wobei ich mir das Register selbst
nicht angesehen habe. In der IDE gibt es einen Cycle Counter in der
Statusleiste. Mag sein daß dort nur ein relativer Wert angezeigt wird.
FLASH_SetLatency(FLASH_Latency_5);// für 180 MHz @2,7..3,6V
Das ist jetzt nicht die Einstellung für den STM32F7, aber so in etwa
könnte das aussehen.
Wenn das Flash zu langsam parametriert ist macht die CPU Waitstates.
Auch "SystemClock_Config();" nimmt erst mal an dass der Quarz 25MHz
hätte und stellt die CPU Clock auf eine Sichere Betriebsart ein, aber
das muss man anpassen.
Beim STM32F4xx ist es hier:
stm32f4xx.h:
1
/**
2
* @brief In the following line adjust the value of External High Speed oscillator (HSE)
3
used in your application
4
5
Tip: To avoid modifying this file each time you need to use different HSE, you
6
can define the HSE value in your toolchain compiler preprocessor.
7
*/
8
9
#if !defined (HSE_VALUE)
10
#define HSE_VALUE ((uint32_t)12000000) /*!< Value of the External oscillator in Hz */
ich muss zugeben das ich das mit den Flash Waitstates noch nicht ganz
verstanden habe. Bedeutet die 7, dass sieben Takte benötigt werden um
den nächsten Befehl aus dem Flash zu lesen?
Aber oben in der main werden noch verschieden cache's eingeschaltet
CPU_CACHE_Enable(); Die Funktion sieht so aus:
1
/**
2
* @brief CPU L1-Cache enable.
3
* @param None
4
* @retval None
5
*/
6
staticvoidCPU_CACHE_Enable(void)
7
{
8
/* Enable I-Cache */
9
SCB_EnableICache();
10
11
/* Enable D-Cache */
12
SCB_EnableDCache();
13
}
Wie gesagt, das ist der ST Beispiel Template aus dem cube Ordner für das
discovery board.
Der Systemtakt stimmt.
Gruß
Falko
So, die Platine ist fast komplett und ich habe noch etwas gespielt.
Den Cache Test habe ich mir gespart, das hat Falko ja bereits gemacht.
Also nun die Codeausführung "am Stück" mit BPs.
1
// Start der "Messung"
2
__GPIOE_CLK_ENABLE();
3
__GPIOC_CLK_ENABLE();
4
__GPIOH_CLK_ENABLE();
5
__GPIOA_CLK_ENABLE();
6
__GPIOB_CLK_ENABLE();
7
__GPIOD_CLK_ENABLE();
8
// Breakpoint
Den ASM Code lasse ich lieber weg. Ist ziemlich länglich (auch wegen
-O0) aber linear.
Mit Singlestep komme ich auf 789 Zyklen. Lasse ich den Code durchlaufen
und per BP stoppen sind es nur noch 140 Zyklen. Das ergibt ein
Verhältnis von 5.6:1
Weiter geht's mit einer Schleife. Die sollte nach einem Durchlauf in
einem der Caches liegen.
1
volatileintx;
2
3
intmain()
4
{
5
initHardware();
6
7
// Start
8
for(x=0;x<20;x++);
9
// BP
10
...
11
}
Hier sind es mit Singlestep 3412 Zyklen (immer noch -O0), mit BP dagegen
309 Zyklen. Das Verhältnis ist nun 11:1.
Es scheint daß der Cycle Counter zumindest zur Ermittlung der Laufzeit
einer Code Abschnitts (Funktion) zu gebrauchen ist.
Kleiner Hinweis: Auch Breakpoints können als Instruktionen zählen, denn
die Debugger fügen BKPT-Anweisungen in den Code im Flash ein, wenn die
Hardware-Breakpoints aufgebraucht sind. Dies passiert auch beim
Single-Stepping, denn der Prozessor weiß ja nicht wo eine Zeile aufhört,
und der Debugger fügt einen temporären Breakpoint nach der Zeile ein.
Könnte eventuell die Unterschiede erklären?
Wenn es immer so wäre vielleicht. Aber die CM-0/3/4 haben diese
Eigenheit ja nicht. Und die "Flash-BPs" sind soweit ich weiß eine
Spezialität von Segger.
Haben die Cortex-A Kerne auch einen Cycle Counter? Falls ja, wäre ich
nicht überrascht wenn die sich ebenso verhalten.
Hallo zusammen! Erster Post hier be mikocontroller.net; ich hatte schon
oft gute Infos im Forum gefunden, und bin nun hier auf diesen älteren
Thread gestossen... und dachte nun ich muss mich hier endlich mal
anmelden.
Mit dem Problem oben habe ich grad zu kämpfen.
1) Obwohl der Cycle-Counter (DWT->CYCCNT) in GDB ausgelesen UND
geschrieben werden kann (auf einem STM32F746ZGT6), ist es aus
irgendwelchen Gründen nicht möglich den Register-Inhalt auf 0
zurückzusetzen, wenn ich dieselbe Funktion in C schreibe. Echt
verwirrend.
2) Auch steigen die Werte viel zu schnell an, wie oben beschrieben.
1) Im Detail:
Der Cycle-Counter kann in GDB-Konsole manuell auf 0 zurückgesetzt
werden. Alles funktioniert, und man kann einzelne
Single-(Instruction)-Steps "messen", was ja recht praktisch wär.
Doch die Werte steigen zu schnell. Einzelne simple Instruktionen
brauchen > 10 Zyklen...
Und wenn ich folgendes kompiliere und einen Breakpoint da drunter setze
ist aus irgendwelchen Gründen das Register nie gleich 0:
LOG_INT(a);// drinlassen, dass nicht ausoptimiert wird
35
LOG_INT(b);
36
37
LOG("cycles: %u, %u, %u\r\n",t0,t1,t2);
...bekomm ich Resultate wie die hier (-O0 gcc switch):
1
cycles: 2438761695
2
cyc_start: 2439138883
3
a: 5
4
b: 1
5
cycles: 432981, 432987, 433003
Wenn hingegen der Wert in GDB manipuliert werd, geht das gut, doch wie
ich nehm nicht an, dass dies wirkliche der Anzahl Zyklen entspricht für
die paar Instruktionen die da ausgeführt werden:
Hab noch wenig Ahnung in Sache ARM und Embedded... und bin erst am
Anfang bei den STM32ern. Wär froh bald mal eine genauere Delay-Funktion
und eben solchen simplen Cycle-Counter zum Laufen zu bringen....
Korrektur: Die Zahlen stimmen, die Anzahl Cycles stimmt. Hab's
verglichen mit einem alten Resultat, das noch mit dem Sys-Tick (1 ms)
gemessen wurde. Problem 2) ist gegessen...
Aber warum dieses CYCCNT register nicht geresettet werden kann ist mir
nachwievor ein Rätsel...