Hallo, was ist der schnellste weg ohne eine Bibliothek eine 16 Bit Zahl, also eine Zahl bestehend aus 2 Registern, mit 10 zu multiplizieren und dividieren? Ich habe schon gesucht und ein paar gute Sachen gefunden, jedoch haben die gleich erklärt wie man mit beliebigen Zahlen multipliziert, was hier überhaupt nicht nötig ist und ich mir so etwas Speicher sparen will, wenn ich das ganze auf mal und durch 10 beschränke. Vielleicht kennt jemand nen guten Algorithmus dafür?
3 mal Schieben mach div oder mod mit 8. dann noch zwei mal dazu addieren oder subtrahieren. Ist in ASM schnell gemacht.
Durch 10 Dividieren (unsigned) geht sinngemäß so
1 | (0xcccd * x) >> 19 |
Die Multiplikation ist 16 * 16 = 32, und >> 19 ist Schieben um 19 Bits nach rechts.
chris schrieb: > http://piclist.com/techref/microchip/math/div/16byconst10-at.htm Will man sowas wirklich?
1 | ;Subroutine to divide by 10 by repeated subtraction of 10. |
Bis zu 6553 Schleifendurchläufe?
Servus, mit 10 multiplizieren geht einfach: Zahl 1x links-schieben (=Zahl*2) und dies als Zwischenergebnis speichern, dann Zahl noch 2x links-schieben (= dann ist Zahl= Zahl *8) und das Zwischenergebnis draufaddieren. Division /10 ist deutlich komplizierter...
Steht da wirklich "Techref/Microchip". Wenn man nicht versteht was Johann da macht, dann kann man ja immer noch 10000er, 1000er und 100er reduzieren, bevor man sich auf die 10er stürzt.
und Johanns * 0xcccd kann man umformen zu 0xcccc +1 und das cccc, also 0b1100110011001100 kann man auch durch einfaches Schieben und Addieren ersetzen.
Da hat mich mein alter Mathe-Lehrer doch voll verarscht! Der hat doch glatt behauptet: (Irgendwas * 10) / 10 = "kannst Du Dir schenken" bzw. bleibt Irgendwas.
Sebastian S. schrieb: > Da hat mich mein alter Mathe-Lehrer doch voll verarscht! > > Der hat doch glatt behauptet: (Irgendwas * 10) / 10 = "kannst Du Dir > schenken" bzw. bleibt Irgendwas. Dann war's der Informatik-Lehrer.
Methode1 braucht 347 cyclen . Es geht schneller, ist klar. Mul10 Ist (x<<2+x)<<1 Mul25 Ist (x<<1+x)<<3+x Oder (Mul10+x+x)<<1+x Div10 Ist x*25>>8 Wenn Result *10+10 kleiner gleich X ist, Inkrementiere Result.
Servus, hab schnell mal Johann's Vorschlag ((0xcccd * x) >> 19) in PIC-ASM codiert: (Laufzeit ca. 170 Zyklen)
1 | ;---------------- accu = reg16/10 |
2 | ;Multiplikation 16x16: akku = (reg * 0xCCCD) >> 16 |
3 | ;(die Multiplikation beginnt mit dem niederwertigen Bit des Multiplikanten) |
4 | div10 |
5 | lsrf reg16+1,W |
6 | movwf accu+1 |
7 | rrf reg16,W |
8 | movwf accu |
9 | |
10 | movlw 15 |
11 | movwf loopcnt |
12 | bcf STATUS,C |
13 | |
14 | mulLp |
15 | rrf accu+1,F ;(Carry -> MSB) accu >>= 1 |
16 | rrf accu,F |
17 | |
18 | bcf STATUS,C ;(fall keine Addition: kein Übertrag!) |
19 | btfss loopcnt,1 ;bit 1(loopcnt): 1-1-0-0-1-1-0-0... |
20 | goto skipAdd ;0: keine Addition |
21 | |
22 | movf reg16,W ;akku += reg |
23 | addwf accu,F |
24 | movf reg16+1,W |
25 | addwfc accu+1,F |
26 | |
27 | skipAdd |
28 | decfsz loopcnt,F |
29 | goto mulLp |
30 | |
31 | ;noch 3x rechtsschieben -> gibt >>19 |
32 | rrf accu+1,F |
33 | rrf accu,F |
34 | lsrf accu+1,F |
35 | rrf accu,F |
36 | lsrf accu+1,F |
37 | rrf accu,F |
38 | |
39 | return |
Das gibt einen Rekord. Noch nie ein Programm mit so vielen Fehlern wie dieses gesehen.
Div10 habe ich mal über eine Pseudo-Reihenentwicklung ausgeführt: x/10 <=> x(1/8 - 1/32 + 1/128 - 1/512 + 1/2048) Kann man hinten noch erweitern - je nachdem, wie genau das Ergebnis werden soll. Hatte in ASM nur wenige Befehle benötigt. Gruß TK
noop schrieb: > Das gibt einen Rekord. Noch nie ein Programm mit so vielen Fehlern > wie > dieses gesehen. Kannst Du die Fehler auch zeigen? Oder wenigstens eine Zahl angeben, mit der das Ergebis dieses Programms nicht korrekt ist?
Thomas E. schrieb: > hab schnell mal Johann's Vorschlag ((0xcccd * x) >> 19) > in PIC-ASM codiert: [...] Der Binärbruch 0b1100110011001100 ist offensichtlich periodisch. Man müsste also mit drei Schritten auskommen: t1 = (0xc000 * x) t2 = t1 + (t1 >> 4) t3 = t2 + (t2 >> 8) Der Shift um 8 Stellen kann sicherlich durch Rechnen mit High- und Lowbyte ersetzt werden.
TK schrieb: > Div10 habe ich mal über eine Pseudo-Reihenentwicklung ausgeführt: > x/10 <=> x(1/8 - 1/32 + 1/128 - 1/512 + 1/2048) Hübsch. Konstanter Faktor in CSD-Darstellung. Bringt zwar im vorliegenden Fall keine Ersparnis, schadet aber auch nix. Sollte man sich trotzdem merken; bei anderen Zahlen kann eine Einsparung resultieren.
Possetitjel schrieb: > Der Binärbruch 0b1100110011001100 ist offensichtlich > periodisch. Man müsste also mit drei Schritten auskommen: > > t1 = (0xc000 * x) > t2 = t1 + (t1 >> 4) > t3 = t2 + (t2 >> 8) Das stimmt wohl, nur spart es keine Rechenschritte (im Gegenteil!): die 16x16 Multiplikation hat man auch hier, dazu kommen dann noch die Additionen und Shifts von Zwischenergebnissen...
Thomas E. schrieb: > Possetitjel schrieb: >> Der Binärbruch 0b1100110011001100 ist offensichtlich >> periodisch. Man müsste also mit drei Schritten auskommen: >> >> t1 = (0xc000 * x) >> t2 = t1 + (t1 >> 4) >> t3 = t2 + (t2 >> 8) > > Das stimmt wohl, nur spart es keine Rechenschritte (im > Gegenteil!): die 16x16 Multiplikation hat man auch hier, > dazu kommen dann noch die Additionen und Shifts von > Zwischenergebnissen... Du willst mir jetzt nicht erzählen, dass Du die vierzehn Multiplikationen mit Null tatsächlich in der Schleife ausführen willst? Ich dachte eigentlich, dass die Idee, auf die Schleife zu verzichen, offensichtlich ist. Die Multiplikation mit 0xc ist durch kopieren, schieben, addieren und (die Zwischensumme) zweimal schieben erledigt. Zweiter Schritt: Zwischensumme kopieren, viermal schieben, addieren. Dritter Schritt: Zwischensumme aus Schritt 2 byteverschoben addieren.
Possetitjel schrieb: > Du willst mir jetzt nicht erzählen, dass Du die vierzehn > Multiplikationen mit Null tatsächlich in der Schleife > ausführen willst? Ok, sorry, manchmal sieht man halt den Wald vor lauter Bäumen nicht... ;)
TK schrieb: > Div10 habe ich mal über eine Pseudo-Reihenentwicklung ausgeführt: > x/10 <=> x(1/8 - 1/32 + 1/128 - 1/512 + 1/2048) > Kann man hinten noch erweitern - je nachdem, wie genau das Ergebnis > werden soll. Der von mir genannte Ausdruch Q = (0xcccd * N) >> 19 hat die Eigenschaft 0 <= N - 10*Q < 10 d.h. N - 10*Q ist gerade der Rest bei der Division durch 10 wie man ihn auch von C kennt. Dein Ausdruck liefert für 8 z.B. 1, zumindest wenn man nicht anfängt mit Nachkommastellen zu rechnen (was der von mir genannte Ausdruck ja auch implizit tut). Es kommt also ganz auf die Verwendung des Ergebnisses an, wie man vorgeht. Übrigens ist die Konstante in beiden Fällen i.W. die gleiche, d.h. besteht aus dem Bitmuster ...0011... wegen 0.1 = 4/30 - 1/30 und
Bei CCCD und mit 16 Bits gerechnet:
Solche Bitfummeleien hatte ich oben nicht ausgeführt; ich bin davon ausgegangen das wäre offensichtlich genug...
Ja, wenn ich die 8 vorgebe, dann kommt da eine 1 raus. Wenn man mit der Ungenauigkeit von 8/10 = 0.8 => aufgerundet 1 leben kann, dann denke ich, dass die ca. 30 Zyklen in ASM doch schon relativ schnell sind. Und wenn ich den TO Anfangsthread richtig gelesen habe, ging es auch um schnelle DIV10 und MUL10. Gruß TK
Kommt halt drauf an, wofür man es braucht. Wenn man /10 (wie vermutlich in den meisten Fällen) für eine Binär->Dezimal-Wandlung braucht, kann man keine Aufrundung gebrauchen, wenn man tatsächlich einen Wert auf das 0.1-fache verändern will, ist man mit Rundung evtl. näher dran...
Johann L. schrieb: > Bei CCCD und mit 16 Bits gerechnet: [...] Egal, ob man den Faktor als 1100110011001100 oder 0-0+0-0+0-0+0-0+ darstellt - man benötigt immer 7 Additionen/Subtraktionen für 32 bit. Wenn man die Periodizität ausnutzt, genügen 3.
Thomas E. schrieb: > picalic 160 ist die erste Zahl, welche nicht passt. ab 160 gibt es nur 2400 Zahlen, wo das Ergebniss stimmt, der Rest ist falsch. Cyclen braucht es 196 laut Simulator, wobei einige Instruction umgeschrieben wurden, weil diese im pic10 nicht implementiert sind.
Thomas E. schrieb: > Kommt halt drauf an, wofür man es braucht. Stimmt. Wenn man ein Aufgabe aus dem Kontext herauslöst, ist sie erheblich komplizierter zu lösen. Z.B. für eine Zahlenausgabe braucht man gar keine Division /10, da ist die Subtraktionsmethode am schnellsten und codesparendsten.
Angehängte Dateien:
-

DIV16_debug.PNG
16 KB
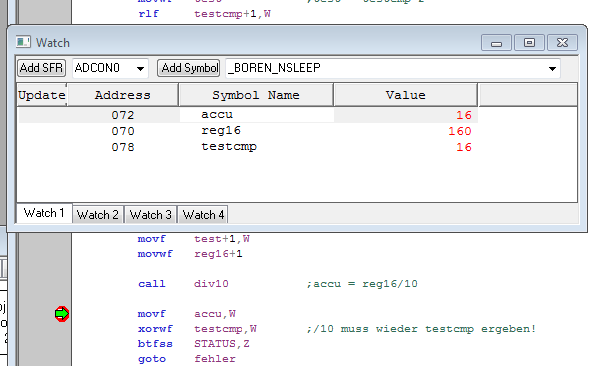
noop schrieb: > 160 ist die erste Zahl, welche nicht passt. > ab 160 gibt es nur 2400 Zahlen, wo das Ergebniss stimmt, der Rest > ist falsch. Cyclen braucht es 196 laut Simulator, wobei einige > Instruction > umgeschrieben wurden, weil diese im pic10 nicht implementiert sind. Dann wirst Du wohl selbst bei der Umsetzung auf den Base-Family Chip einen Fehler eingebaut haben! Mein Programm macht auf einer Enhanced Midrange CPU (für das es geschrieben wurde) jedenfalls, was es soll:
@noop: keine Ahnung, was Du da programmiert hast. Hier ist meine Version für Base- und Midrange-Core (Simulation getestet für PIC10F320). Laufzeit ist 194 Zyklen (incl."call" und "return"):
1 | ;---------------- accu = reg16/10 |
2 | ;Multiplikation 16x16: akku = (reg * 0xCCCD) >> 16 |
3 | ;(die Multiplikation beginnt mit dem niederwertigen Bit des Multiplikanten) |
4 | div10 |
5 | bcf STATUS,C |
6 | rrf reg16+1,W |
7 | movwf accu+1 |
8 | rrf reg16,W |
9 | movwf accu |
10 | |
11 | movlw 15 |
12 | movwf loopcnt |
13 | bcf STATUS,C |
14 | |
15 | mulLp |
16 | rrf accu+1,F ;(Carry -> MSB) accu >>= 1 |
17 | rrf accu,F |
18 | |
19 | bcf STATUS,C ;(falls keine Addition: kein Übertrag!) |
20 | btfss loopcnt,1 ;bit 1(loopcnt): 1-1-0-0-1-1-0-0... |
21 | goto skipAdd ;0: keine Addition |
22 | |
23 | movf reg16,W ;akku += reg16 |
24 | addwf accu,F |
25 | btfsc STATUS,C |
26 | incf accu+1,F |
27 | movf reg16+1,W |
28 | addwf accu+1,F |
29 | |
30 | skipAdd |
31 | decfsz loopcnt,F |
32 | goto mulLp |
33 | |
34 | ;noch 3x rechtsschieben -> gibt >>19 |
35 | rrf accu+1,F |
36 | rrf accu,F |
37 | bcf STATUS,C |
38 | rrf accu+1,F |
39 | rrf accu,F |
40 | bcf STATUS,C |
41 | rrf accu+1,F |
42 | rrf accu,F |
43 | return |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.