Ich habe zwei schreibende und einen lesenden Prozess mit jeweils unterschiedlichen Takten. Es muss in alle Richtungen gelesen und geschrieben werden können. Durch Semaphoren ist sichergestellt, dass immer nur einer auf einen Block schreiben kann. Nun möchte ich ein Blockram mit 3 Anschlüssen bauen. Aus meiner Altera-Zeit weiß ich, dass man da drei Anschlüsse machen konnte. wie geht das beim Grossen X?
Leider nicht, die haben nur Dual Port RAM. Da braucht es einen externen Arbiter.
Neu-Xilist schrieb: > Ich habe zwei schreibende und einen lesenden Prozess mit jeweils > unterschiedlichen Takten. Es muss in alle Richtungen gelesen und > geschrieben werden können. Durch Semaphoren ist sichergestellt, dass > immer nur einer auf einen Block schreiben kann. > > Nun möchte ich ein Blockram mit 3 Anschlüssen bauen. > > Aus meiner Altera-Zeit weiß ich, dass man da drei Anschlüsse machen > konnte. Geht wohl auch beim A nicht mehr, ist aber leicht nachbaubar: https://www.altera.com/support/support-resources/knowledge-base/solutions/rd08132012_451.html Dieser "workaround" ist auch bei X möglich. Wenn du bereits semophoren realisiert hast sollt es nicht schwierig sein einen datanmultiplexer zu ergänzen desen Auswahlsignal (select) auch von der Semaphor-steuerung geschaltet wird. MfG,
Angehängte Dateien:
-

Altera_TriPortRAM.png
37 KB
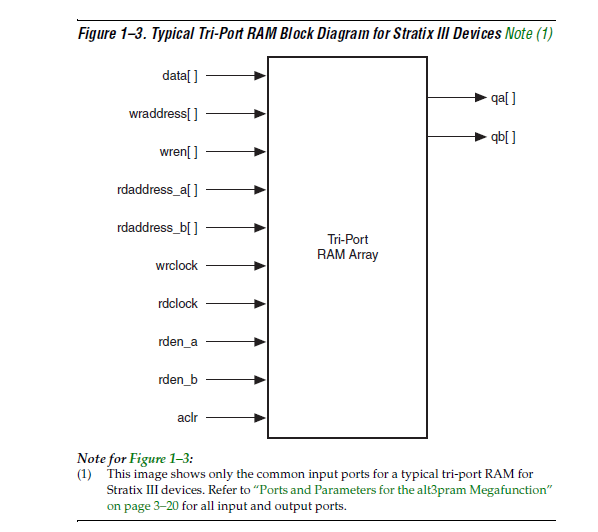
Fpga K. schrieb: > Geht wohl auch beim A nicht mehr, ist aber leicht nachbaubar:... Das ist aber kein "TriPortRAM", wo an jedem der 3 Ports gelesen und geschrieben werden kann. Sondern es werden wie bei Xilinx einfach 2 RAMs parallel geschaltet und von 1 Port ausschließlich geschrieben (also dort nicht mal gelesen!), sowie von den anderen beiden Ports nur gelesen. Neu-Xilist schrieb: > Es muss in alle Richtungen gelesen und geschrieben werden können. Es ist mit 3 Dual-Port-RAMs eigentlich recht einfach: man schaltet alle 3 parallel, jeder der 3 Teilnehmer bekommt einen Lese-Port. Und auf der anderen Seite wird über einen Multiplexer jeweils einem der drei Teilnehmer der Schreib-Port auf alle 3 RAMs zugeteilt... Fazit: Gesamtaufwand = 3 RAMs + 1 Adress/Datenmultiplexer > Es muss in alle Richtungen gelesen und geschrieben werden können. Was ist denn dein eigentliches Problem? Warum geht es nicht mit 1 RAM und 1 Arbiter, der das RAM zuteilt? Weltweit funktionieren milliarden Rechner auf diese Art. Ich hätte bei dieser Lösung mit 3 RAMs Bedenken, dass da mal Inkonsistenzen in den Speichern auftreten könnten...
Die im link beschriebene Lösung ist ein Shadow-Ram und ersetzt nicht die geforderte Funktionalität des vollständigen bidirektionalen Betriebs eines Dreifach-RAMs. Das geht nur über einen Sternpunkt, also ein einziges RAM mit gfs davor geschalteten FIFOs, um die Anforderungen handhaben zu können. Auch bei den Altera-RAMs bin ich mir nicht sicher, ob die wirklich einen dritten Schreibport hatte. Ich hatte mal eine APP, wo ich mit Shadow-RAMs gearbeitet habe, weil ein und dasselbe von zwi unterschiedlichen Abnehmern und leicht unterschiedlichen Zeiten gelesen wurde. In dem Fall in dem es doch derselbe Zeitpunkt war, hat es die Synthese erkannt und die RAMs zusammengeführt. Aber: Das war nur Lesend! Die einzige Möglichkeit, es wirklich mit voller Bandbreite und wahlfreiem Zugriff zu bauen, ist, das RAM per Hand aufzuziehen - eben so, wie man es für die Semaphore selbst auch tun muss. Ob das hier nötig ist, bezweifle ich ein wenig, weil sich meines Erachtens der erste und der zweite Satz des TE widersprechen.
Jürgen S. schrieb: > Ob das hier nötig ist, bezweifle ich ein wenig, weil sich meines > Erachtens der erste und der zweite Satz des TE widersprechen. Entsprechend dem ersten Satz würde ich auch sagen: ein einziges DPRAM reicht aus, weil ja gewährleistet ist, dass nur ein einziger Prozess darauf schreibt...
@ Neu-Xilist (Gast) >Ich habe zwei schreibende und einen lesenden Prozess mit jeweils >unterschiedlichen Takten. Wirklich unterschiedliche, sprich asynchrone Takte? Oder eher abgeleitete Takte? Taktung FPGA/CPLD > Lothar Miller (lkmiller) (Moderator) Benutzerseite >> Ob das hier nötig ist, bezweifle ich ein wenig, weil sich meines >> Erachtens der erste und der zweite Satz des TE widersprechen. >Entsprechend dem ersten Satz würde ich auch sagen: ein einziges DPRAM >reicht aus, weil ja gewährleistet ist, dass nur ein einziger Prozess >darauf schreibt... Denke ich auch.
Nein, es sind drei unterschiedliche Domänen - das ist ja das Problem. Und ich weiß nicht, wann sie schreiben. Funktionell ist das ziemlich entkoppelt, ich muss gfs die Schreiber in eine Warteschlange schicken.
@ Neu-Xilist (Gast)
>Nein, es sind drei unterschiedliche Domänen - das ist ja das Problem.
Das klingt sportlich. Dann würde ich aber auf jeden Fall den BRAM nur
mit EINEM Takt laufen lassen und alle drei Taktdomänen per asynchronem
Mini-FIFO oder ähnlichem ankoppeln. Dann entschärft sich auch das
Problem der 3 Ports. Der Arbiter hat dann 2 volle Port zur Verfügung und
kann ggf. 2 Zugriffe gleichzeitg machen. Wenn doch zufällig ein dritter
zeitgleich auftritt, fängt das der jeweilige FIFO ab.
Das macht aber dann richtig schön wenig Bandbreite. Vielleicht doch als distri Ram bauen?
Wie von Falk Brunner gesagt, kann man das gut mit FIFOs an den Ports und einem 2-Port RAM lösen. Den Speicher würde man eben entsprechend höher takten, sodass es sich immer ausgeht. Beachte allerdings die Anforderungen an read-after-write bei so einer Lösung. Durch die FIFOs erhöht sich die Antwortzeit um einige Takte und es kann vorkommen, dass Lesezugriffe Schreibezugriffe überholen. Da kann man dann Z.B. mit CAMs aushelfen, einfacher wird es damit aber nicht. Wenn das RAM klein ist, dann kann man es auch aus Registern bauen und sich den Aufwand sparen.
content addressable memory Eingangssignal ist der INHALT, welcher im Speicherarray gesucht wird. Ausgangssignal ist die ADRESSE, in welcher dieser zu finden ist. Ist quasi eine Suchmaschine mit vielen parallelen Komparatoren. Google in Hardware ;-)
Fragi schrieb: > Sym schrieb: >>CAM > > ??? > > Keine Abkürzungen unbekannter Art verwenden. Och, da kann man auch bei Wikipedia nachschlagen: https://de.wikipedia.org/wiki/CAM in dieser Abk.-liste findet sich auch der passende Link: https://de.wikipedia.org/wiki/Assoziativspeicher Wer diesen dt. Begriff geprägt hat gehört allerdings geschlagen ;-) In Praxis ist mir ein solcher Speicher bisher nur einmal vorgekommen und zwar in den Neunziger bei Evaluierung von Aufrüstoption für 386 PC Motherboard. Da konnte man den Cache aufrüsten und so den cachebaren Bereich aufrüsten. Allerdings auch nicht mehr als der Address tag RAM hergibt. der ist wohl als CAM organisiert, und da würde es wichtig zu wissen ob man einen n-fach aasoziativ Cache oder einen direct mapped Cache wählt. Nicht ganz trivial das Thema: https://de.wikipedia.org/wiki/Cache#Block.2FSatz-Aufteilung_der_Tags Eine IMHO bessere Darstellung findet sich in: ISBN: 978-3528051730
Wenn ich das alles so lese, dann frage ich mich, ob nicht ein round Robin mit entsprechender Frequenz das Einfachere ist.
Sorry wegen der Verwirrung mit den CAMs. Für mich ist das so alltäglich wie JTAG und AXI4. Round-Robin geht natürlich. Allerdings kann dadurch die Reihenfolge verändert werden. Nehmen wir drei Teilnehmer A, B, und C. Nehmen wir an der Pointer steht bei A. A setzt einen Schreibzugriff beim Übergangs des Pointers auf B ab, dieser kann aber erst in der nächsten Runde serviciert werden. Beim Übergang von B auf C setzt C einen Lesezugriff ab. Da nun C drankommt, wird der Lesezugriff durchgeführt. Somit hat der Lesezugriff den Schreibzugriff überholt. So, und nun kommt die CAM ins Spiel. Man speichert die Schreibaddressen im CAM ab und die Daten in einem zum CAM gehörenden Speicher. Beim Lesen fragt man zuerst mit der Leseaddresse im CAM nach: Wurde diese Addresse unlängst geschrieben? Falls ja, holt man die dazugehörigen Daten aus dem CAM zugehörigen Speicher. Falls nein, nimmt man die Daten aus dem (Round-Robin beschriebenen) RAM. Wenn man aber weiß, dass ein Read nach einem Write auf dieselbe Addresse erst viel später gelesen wird, dann kann man sich die CAM sparen, weil das RAM immer die richtigen Daten hat.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.