Hallo,
da mein Projekt auf dem STM32 inzwischen doch grösser wird und auch
viele Libs eingebunden sind frage ich mich langsam, wie man denn so die
Module organisiert?
Aktuell kennt jedes Modul alle anderen, da in main.h alle includes drin
sind. Variablen werden je nach Bedarf mit extern bekannt gemacht, alle
Funktionen, die publik sind werden im Header mit einem Prototypen
angegeben, alle lokalen Funktionen in einem Modul nicht, d.h. sie sind
auch von außen nicht erreichbar und haben ein static vor dem Namen.
Defintionen stehen in den Headern der Module drin, da wo sie verwendet
werden. Nur einige wenige in Main.h.
Wie wird es denn nun richtig gemacht, die Sache mit den Inkludes? Jedes
Modul kriegt nur die, die es braucht? Das ist nämlich ne ganz schöne
Rumprobierei.
Guss,
Christian
Christian J. schrieb:> Hallo,>> da mein Projekt auf dem STM32 inzwischen doch grösser wird und auch> viele Libs eingebunden sind frage ich mich langsam, wie man denn so die> Module organisiert?
Eigentlich ganz einfach.
Jedes Header File (*.h), jedes Source Code File (*.c) includiert die und
nur die anderen Header Files, die es benötigt um in sich vollständig zu
sein. Das gilt auch für Header Files! Die includieren genauso wieder
andere Header Files, je nachdem ob sie deren Inhalt benötigen oder
nicht.
> sind. Variablen werden je nach Bedarf mit extern bekannt gemacht
hoffentlich im Header File
> alle> Funktionen, die publik sind werden im Header mit einem Prototypen> angegeben, alle lokalen Funktionen in einem Modul nicht, d.h. sie sind> auch von außen nicht erreichbar und haben ein static vor dem Namen.
genau so macht man das
> Defintionen stehen in den Headern der Module drin
Du meinst zb struct-Definitionen?
Ist korrekt so, denn ohne sie könnten die Funktionsprotoypen sie ja
nicht in ihren Argumentlisten benutzen.
structs die dort nicht vorkommen, kommen ebenso ins C-File. Genauso wie
du es mit Variablen gemacht hast.
Im Grunde sehr simpel. Die Frage lautet: Muss irgendwer anderer ausser
dem Source Code dieses Moduls wissen, dass es XYZ gibt und wie es
aussieht? Wenn ja, dann kommt XYZ ins Header File. Wenn nein, dann kommt
XYZ ins C-File.
> Wie wird es denn nun richtig gemacht, die Sache mit den Inkludes? Jedes> Modul kriegt nur die, die es braucht? Das ist nämlich ne ganz schöne> Rumprobierei.
Was ist da Rumprobiererei?
Du hast das Zeug doch selbst geschrieben. Du weisst doch, welche anderen
Module von einem Modul benutzt werden. Und deren Header File includierst
du. Kommt in einer UART eine FIFO vor und ist die FIFO in einem eigenen
Header File, dann includierst du eben in UART.c das Header File FIFO.h.
Kommt in einer LED Ansteurung keine FIFO vor, dann wird das Header File
FIFO.h dort eben nicht includiert.
Macht man das von Anfang an konsequent (und nicht mittels
Masseninclude), dann ist das überhaupt keine Rumprobiererei sondern
entsteht ganz von alleine.
Voraussetzung ist natürlich, dass man seine Funktionen nicht einfach
kreuz und quer auf zig verschiedene C-Files aufteilt, sondern sie schon
nach Themenkreisen geordnet in C-Files unterbringt. Eben die bewussten
Module.
Christian J. schrieb:> Jedes> Modul kriegt nur die, die es braucht?
Ja
> Das ist nämlich ne ganz schöne> Rumprobierei.
Nein. Wenn doch, ist die ganze Softwarestruktur vermurkst.
Oliver
Ok,
das werde ich dann mal wieder ändern. Ich habe allerdings Grenzen der
Organisation, d.h. ich trenne nicht "ausgebende" Funktionen von
berechnenden usw. Das würde das Ganze unleserlich machen.
Naja, so sieht das halt aus. Meine Files, dazu die StdPeriphLib und noch
eine Middleware von TM, die das ganze erheblich vereinfacht, da die
Peripherie noch enger gekapselt ist. Leider lernt man dabei nicht den
STM32 kennen, den "sieht" man eigentlich gar nicht mehr, könnte auch ein
Backfin oder sonstwas sein.
Chef Mod?
Kannst Du das Ganze vielleicht nochmal umfassend beschreiben? Ich habe
alles umsortiert und alle Files nochmal angefasst nach folgenden Regeln:
1. In die Header gehört nur das hinein, was einem inkludierenden Modul
danach bekannt sein muss.
2. In die .c Datei gehören auch die structs, typedefs und Defines, die
nach außen nicht sichtbar sein sollen.
3. Alle globalen Variablen, die nach außen bekannt gemacht werden
sollen, gehören in den Header ?
Bisher habe ich aber noch keine Lösung für extern Variablen, die ich mir
"hineinholen" muss. Ich binde dann wohl den Modul Header mit ein, von
dem ich die Funktionen brauche aber beziehe des bisher nur auf
Funktionenn. Was ist mit den Variablen?
Christian J. schrieb:> Bisher habe ich aber noch keine Lösung für extern Variablen, die ich mir> "hineinholen" muss. Ich binde dann wohl den Modul Header mit ein, von> dem ich die Funktionen brauche aber beziehe des bisher nur auf> Funktionenn. Was ist mit den Variablen?
foo.h
1
externintValue;// Deklaration
foo.c
1
intValue;// Definition
Bindest du nun foo.h in bar.c ein, kannst du wie gewohnt auf die
Variable Value zugreifen.
Naja, bei mir sieht es bisher so aus, die extern Vars sind im C File.
Es sind alles nur "read only" variablen, die ich verwende, nicht aber
die ich nach außen bekannt machen muss.
Christian J. schrieb:> extern flags_t flags;
In welchem Modul steht die Definition zu obiger Variable? In genau
diesem Modul musst du die Variable im Header deklarieren.
Christian J. schrieb:> Naja, bei mir sieht es bisher so aus, die extern Vars sind im C File.> Es sind alles nur "read only" variablen, die ich verwende, nicht aber> die ich nach außen bekannt machen muss.
Wenn du sie nicht nach aussen bekannt machen müsstest, würde in deinem
Code kein "extern" vorkommen.
Die Systemzeit ist ein gutes Beispiel für dein Problem. Entweder machst
du die Variable, die den Wert hält, global, oder du stellst dafür eine
Funktion zur Verfügung, die dir die aktuelle Zeit liefert. So oder so
musst du aber entweder die Variable oder die Funktion im Header
deklarieren.
Die Funktion ist in diesem Beispiel in jedem Fall vorzuziehen, denn so
kann niemand ausser das Modul selbst den Wert ändern. Ausserdem kann man
den atomaren Zugriff (falls die Zeit in einem Interrupt verändert wird)
sauber in der Funktion kapseln.
be s. schrieb:> Bindest du nun foo.h in bar.c ein, kannst du wie gewohnt auf die> Variable Value zugreifen.
Moment.....
dann muss aber das Wort extern da weg.
Wenn foo.c eine Variable WELTWEIT bekannt machen wil, dann muss WELTWEIT
in den foo.h rein und dort steht sie dann mit
int WELTWEIT;
Ich probiere das gerade nämlich aus. Dann klappt das auch, dass alle
Nodule, die foo.h einbinden diese Variable auch kennen ohne Verwendung
von extern.
be s. schrieb:> Wenn du sie nicht nach aussen bekannt machen müsstest, würde in deinem> Code kein "extern" vorkommen.
Ah, so langsam lässt der Elefant das Wassser..... es klappt .....
rumtipper
Aber noch viele Linker Fehler, seit ich "Work" in config.h einmal
definiert habe und viel Module config.h einbinden.
Linking executable: bin\Release\STMF407_Display.elf
Creating Hex-file.
obj\release\src\graphik.o (symbol from plugin): In function
`gfx_DrawTextInfo':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
obj\release\src\init_system.o (symbol from plugin): In function
`Init_BMP180':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
obj\release\src\main.o (symbol from plugin): In function
`f_SwitchToTextMode':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
obj\release\src\rtc_user.o (symbol from plugin): In function `Work':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
obj\release\src\sensor.o (symbol from plugin): In function `Work':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
obj\release\src\tools.o (symbol from plugin): In function `Work':
(.text+0x0): multiple definition of `Work'
obj\release\src\eeprom.o (symbol from plugin):(.text+0x0): first defined
here
collect2.exe: error: ld returned 1 exit status
arm-none-eabi-objcopy.exe: 'bin\Release\STMF407_Display.elf': No such
file
Process terminated with status 1 (0 minutes, 6 seconds)
0 errors, 0 warnings (0 minutes, 6 seconds)
Ah ok .... leider klappt das Ganze nicht mehr, wenn man mit der
__attribute Funktion herumgespielt hat bei Variablen.
Work_t BKRAM Work;
kann nicht im Header definiert werden, es würde dann überall anders als
doppelt beklagt. Erst wenn ich BKRAM wegnehme würde das klappen.
#define BKRAM __attribute__((section(".bkram")))
Christian J. schrieb:> Moment.....>> dann muss aber das Wort extern da weg.
Du darfst eine Variable oder Funktion so oft deklarieren wie du willst,
aber nur einmal definieren. Beim Deklarieren sagst du dem Compiler, dass
die Variable irgendwo existiert, beim Definieren wird Speicher dafür
angelegt.
Christian J. schrieb:> Wenn foo.c eine Variable WELTWEIT bekannt machen wil, dann muss WELTWEIT> in den foo.h rein und dort steht sie dann mit>> int WELTWEIT;
Nee, dann hast hast du in jeder Source, in der du foo.h einbindest, eine
eigene Version von WELTWEIT.
foo.h
In deinem Code von 20.12.2015 15:42 (und nur in dem Code):
Wo wird da eine Definition aus stdbool.h oder stdint.h benötigt?
Nirgends: Dann brauchst du die auch nicht einbinden.
Wenn das in irgendeiner anderen .h oder .c benötigt wird, dann muss es
da eingebunden werden.
Karl H. schrieb:> Das gilt auch für Header Files! Die includieren genauso wieder> andere Header Files, je nachdem ob sie deren Inhalt benötigen oder> nicht.
Das halte ich für einen zwar gebräuchlichen, jedoch ausgesprochen
schlechten Stil. Es ist immer ein Rattenschwanz von irgenwelchem zumeist
obskurem Zeugs.
Also, deutlich sauberer ist es, wenn in einer .h keinerlei #include
steht.
Headerfiles werden ja niemals für sich kompiliert, also ist es auch
zumutbar, daß in der benutzenden .c zuvor ein etwa benötigtes anderes
Headerfile inkludiert wird.
Wenn's fehlt, kriegt man es eben um die Ohren gehauen und fertig. Dafür
hat man jedoch immer den sauberen Überblick, was die betreffende Quelle
sich so alles reinzieht. Und das sollte eben NUR das Zeugs sein, was
tatsächlich gebraucht wird, also kein allgemeines main.h oder ne Latte
von allen *.h die vorhanden sind.
W.S.
W.S. schrieb:> Also, deutlich sauberer ist es, wenn in einer .h keinerlei #include> steht.
Wie willst du das machen?
1
size_tfoo(void);
Du musst zwingend stddef einbinden, damit size_t bekannt ist. Genau so
verhält es sich mit allen anderen Typen auch. Für structs und unions
kann man eine forward declaration benutzen, für elementare Typen
funktioniert das aber nicht.
W.S. schrieb:> Karl H. schrieb:>> Das gilt auch für Header Files! Die includieren genauso wieder>> andere Header Files, je nachdem ob sie deren Inhalt benötigen oder>> nicht.>> Das halte ich für einen zwar gebräuchlichen, jedoch ausgesprochen> schlechten Stil.
Ich halte alles andere für ausgesprochen schlechten Stil. Ein Header
muss "self-contained" sein, d.h. wenn ich ihn irgendwo inkludieren will,
muss das funktionieren, ohne dass vorher noch ein anderer Header
inkludiert werden muss.
> Es ist immer ein Rattenschwanz von irgenwelchem zumeist> obskurem Zeugs.
Was für obskures Zeugs? Wenn der Header irgendwelche Sachen aus anderen
Headern braucht, braucht er sie so oder so. Nur im einen Fall hat er sie
dann auch schon, im anderen muss ich mich erstmal darum kümmern, dass er
alles kriegt, was er braucht.
> Wenn's fehlt, kriegt man es eben um die Ohren gehauen und fertig. Dafür> hat man jedoch immer den sauberen Überblick, was die betreffende Quelle> sich so alles reinzieht. Und das sollte eben NUR das Zeugs sein, was> tatsächlich gebraucht wird,
Eben, und wenn ein Header was braucht, damit er fehlerfrei nutzbar ist,
dann soll er das natürlich auch einbinden.
Rolf M. schrieb:> W.S. schrieb:>> Das halte ich für einen zwar gebräuchlichen, jedoch ausgesprochen>> schlechten Stil.>> Ich halte alles andere für ausgesprochen schlechten Stil. Ein Header> muss "self-contained" sein, d.h. wenn ich ihn irgendwo inkludieren will,> muss das funktionieren, ohne dass vorher noch ein anderer Header> inkludiert werden muss.
Ich finde es schon immer "befremdlich" wenn jemand mit "sauber"
argumentiert. Was soll den saubere Software sein? Ich habe dann immer
den Eindruck, dass da jemand nicht zu ende gedacht hat und eher eine
Gefühlslage ausdrückt. "un-/sauber" also eher ein diffuses Gefühl ist,
und nicht eine quantifizierbare Eigenschaft.
Was wäre den die Alternative zu "self-contained" headern?
- Ich müsste dokumentieren, welche header neben dem dokumentiertem
Header einzubinden sind.
oder
- Jeder Nutzer geht durch die Fehlermeldungen und sucht sich die nötigen
header und Deklarationen selbst raus.
- Jede Änderung / Erweiterung, die zusätzliche Deklarationen nötig
machen, die ganz einfach durch das zusätzliche Einbinden eines headers
umgesetzt werden können, führen jetzt dazu, dass an jeder Stelle, an der
der header verwendet wird, diese zusätzlichen Deklarationen durch
Einfügen des headers bekannt gemacht werden müssen.
Wenn diese Alternative "saubere" Software ist, dann bin ich ein Fan von
"unsauberer" Software! ;-)
Rolf M. schrieb:> Ein Header> muss "self-contained" sein, d.h. wenn ich ihn irgendwo inkludieren will,> muss das funktionieren, ohne dass vorher noch ein anderer Header> inkludiert werden muss.
Sehe ich auch so.
Header müssen auch so geschrieben sein, daß die Reihenfolge ihrer
Einbindung egal ist.
Ich includiere sie alphabetisch, aber zuerst alle Compiler-Includes
<*.h> und danach die Projekt-Includes "*.h".
Torsten R. schrieb:> Ich finde es schon immer "befremdlich" wenn jemand mit "sauber"> argumentiert. Was soll den saubere Software sein? Ich habe dann immer> den Eindruck, dass da jemand nicht zu ende gedacht hat und eher eine> Gefühlslage ausdrückt. "un-/sauber" also eher ein diffuses Gefühl ist,> und nicht eine quantifizierbare Eigenschaft.
Nicht alles lässt sich quantifizieren. Welcher Code schön, elegant oder
besonders lesbar ist, ist nunmal Geschmackssache, ist also zu einem
gewissen Grad immer auch subjektiv. Denke nur mal an Einrückungsstile.
Da gibt's teils sehr - sagen wir mal intensive - Meinungen dazu. Aber
welcher ist jetzt quantitativ der beste, und wie soll man das überhaupt
messen?
Peter D. schrieb:> Ich includiere sie alphabetisch, aber zuerst alle Compiler-Includes> <*.h> und danach die Projekt-Includes "*.h".
Ich halte mich möglichst an googles c++ styleguide, was deinen Stil noch
etwas weiter unterteilt:
https://google.github.io/styleguide/cppguide.html#Names_and_Order_of_Includes
Kann man genauso für C Projekte übernehmen.
Christian J. schrieb:> Jedes> Modul kriegt nur die, die es braucht? Das ist nämlich ne ganz schöne> Rumprobierei.
Wenn du es von Anfang an so durchziehst nicht. Es sorgt übrigens für
eine sauberere Aufteilung und besonders in grösseren Projekten wirst du
es zu schätzen wissen, die entsprechenden includes in den richtigen
header dateien zu haben, statt alle in der main.
Rolf M. schrieb:> Nicht alles lässt sich quantifizieren. Welcher Code schön, elegant oder> besonders lesbar ist, ist nunmal Geschmackssache, ist also zu einem> gewissen Grad immer auch subjektiv. Denke nur mal an Einrückungsstile.> Da gibt's teils sehr - sagen wir mal intensive - Meinungen dazu. Aber> welcher ist jetzt quantitativ der beste, und wie soll man das überhaupt> messen?
Sehe ich ganz genau so. Und dort, wo es Geschmacksache ist, würde ich
auch nicht diskutieren, oder auf die Idee kommen, anderen Geschmack als
"unsauber" zu defamieren. Aber auch wenn Lesbarkeit sehr subjektiv ist,
gibt es doch Heuristiken (Einheitlichkeit etc.) und Gepflogenheiten an
denen man so etwas beurteilen kann. Das ist ein Graubereich, aber wenn
ich 10 Entwickler auf ein Stück Code gucken lasse und mir 9 erzählen,
dass sie den Code unleserlich finden, dann ist da was nicht in Ordnung.
Peter D. schrieb:> Und jedes foo.c includiert natürlich auch sein foo.h, damit> Deklarationen und Definitionen zueinander passen.
Und das ist der erste Header, den es inkludiert, damit man auch gleich
sieht, ob man in foo.h noch irgendwelche Includes vergessen hat.
Hallo,
jedenfalls danke für die Tips, die ich jahrelang falsch gemacht habe.
Inzwischen hat jedes Modul ein übersichtliches Interface und das Wort
extern ist nahezu verschwunden aus allen Modulen aber ganz ohne ging es
doch nicht.
Gruss,
Christian
extern brauchst du an nur für globale Variablen. Und die braucht es beim
AVR eigentlich nur zum Datenaustausch mit ISRs. Alles andere geht ohne.
Oliver
Christian J. schrieb:> extern ist nahezu verschwunden aus allen Modulen aber ganz ohne ging es> doch nicht.
Wie meinst du das?
'extern' kommt sowieso nur in Header Dateien vor. Wenn du in einem
C-File dir Zugriff auf eine Variable mittels extern verschaffst, die in
einem anderen C-File definiert ist, so wie hier (ich gehe davon aus,
dass es sich da um ein C-File gehandelt hat)
/* ---- externe Variablen die benötigt werden------------------------ */
19
externTM_RTC_Time_tTime;// Datum und Uhrzeit
20
externflags_tflags;
21
externuint16_tLDRValue;
22
externWork_tWork;
dann ist das problematisch und ein strategischer Fehler.
Ein 'extern' kommt, genauso wie ein Prototyp einer Funktion nur in einem
Header File vor. Die Bedeutung muss sein, dass ein C-File (ein Modul)
über den Umweg des zu ihm gehörenden Header Files damit bekannt gibt,
dass es diese Variable zur Verfügung stellt. Benutzt du ein extern in
einem C-File, dann hat es eher die Bedeutung, dass dieses C-File diese
Variable 'anfordert'. Und genau das "steht ihm nicht zu". Wenn ein
C-File auf eine Variable aus einem anderen Modul zugreifen will, dann
hat es das zugehörige Header File zu inkludieren, indem dieses Modul
mittels extern bekannt gibt, dass es die Variable zur Verfügung stellt.
Punkt aus.
Technisch kommt es für den Compiler aufs gleich raus. Aber die
Anschauung an das, was mit diesem extern ausgedrückt wird, ist eine ganz
andere. Das eine mal ist es ein 'Ich gebe dir das' und das andere mal
ist es ein 'Ich will das haben'. Der UNterschied kann jedoch
lebenswichtig sein, wenn es um den Datentyp der bewussten Variablen
handelt. Das eine mal (im Header File - "Ich gebe dir das") gibt es eine
Möglichkeit wie der Compiler überprüfen kann, ob der Datentyp im Header
File mit dem Datentyp im definierenden C-File übereinstimmt (wenn das
zum Header gehörende C-File compiliert wird). Im anderen Fall, in dem
sich irgendein C-File ganz einfach mittels extern Zugung zu dieser
globalen Variablen verschafft ("Ich will das haben") habe ich diese
Garantie nicht. Compiler können dich nicht vor dem Fall
foo.c
1
doublemeineVariable;
2
3
voidfoo()
4
{
5
meineVariable=8.0;
6
}
bar.c
1
externintmeineVariable;// Ich will Zugang zu meineVariable haben!
2
3
voidbar()
4
{
5
intj=meineVariable;
6
}
schützen. Compiler übersetzen jedes C-File für sich alleine ohne Ansehen
aller anderen.
Aber so:
foo.h
1
externintmeineVariable;
foo.c
1
#include"foo.h"
2
doublemeineVariable;
3
4
voidfoo()
5
{
6
meineVariable=8.0;
7
}
bar.c
1
#include"foo.h" // über foo.h erhalte ich den Zugang
2
3
voidbar()
4
{
5
intj=meineVariable;
6
}
kann dich der Compiler auf deinen Fehler aufmerksam machen. Denn wenn er
foo.c compiliert kommt er drauf, dass die Deklaration in foo.h nicht mit
der Definition in foo.c übereinstimmt. Die Deklaration behauptet, dass
es eine Variable namens meineVariable gäbe, die ein int sei. Während die
Definition in foo.c klar stellt, dass genau diese Variable als double im
Speicher angelegt wird. Mööööp. Das passt nicht.
Oliver S. schrieb:> extern brauchst du an nur für globale Variablen. Und die braucht es beim> AVR eigentlich nur zum Datenaustausch mit ISRs. Alles andere geht ohne.
Gerade bei so kleinen µCs mit wenig RAM können globale Variable durchaus
hilfreich sein, da sie eine leicht nachvollziehbare und zur Compliezeit
ermittelbare Speicherbelegung haben.
Karl H. schrieb:> Benutzt du ein extern in> einem C-File, dann hat es eher die Bedeutung, dass dieses C-File diese> Variable 'anfordert'.
Hi,
was wäre die Welt ohne Dich :-) Die Geduld jemand etwas ausführlich zu
erklären bewundere ich echt. Und in diesem Fall habe ich JAHRELANG
vieles falsch gemacht.
Wenn ich echt nur 1 Variable brauche, zb den Spannungswert der in main.c
global steht, dann will ich nicht den ganzen Main.h einbinden, der noch
viel mehr enthält, wenn das Modul ansonsten auf main überhaupt keinen
Bezug nimmt.
In main.c steht das Hauptprogramm.
Von dort aus wird alles andere aufgerufen.
Was musst du davon in der main.h nach außen bekannt geben, dass diese so
viel enthält?
Dankeschön, an den Karl Heinz.
So langsam komm ich auch dahinter, wie man es machen sollte. Wenn ichs
jetzt noch schaffe mal solchen Code zu produzieren :)
Ganz ehrlich: Das ist Spaghetticode vom feinsten. :( So kannst Du Dir
die Aufteilung in mehrere Dateien auch gleich sparen, denn diese
"tools.c" kann man nicht in einem anderen Projekt wiederverwenden.
Reden wir mal nur über die Variablen:
- In tools.c definierst Du mehrere globale "public"-Variablen, die nicht
in tools.h auftauchen. Wahrscheinlich werden sie noch in anderen
C-Dateien deklariert und benutzt. Oder auch nicht. Man kann an den
Variablen keine Änderung (z.b. umbenennen oder anderer Datentyp)
vornehmen, ohne sich sicher sein zu können, ob danach das Programm noch
funktioniert. Wenn sie nicht außerhalb von tools.c verwendet werden,
sollten sie "private" (sprich static) sein, andernfalls muss die
Deklaration mit "extern" in tools.h.
- In tools.h deklarierst Du "extern gebiet_t Wetter". Die Variable wird
in tools.c allerdings nur an einer einzigen Stelle gelesen, nämlich in
gfx_Wettervorhersage(). Warum übergibst Du sie nicht als Parameter an
gfx_Wettervorhersage()?
- In tools.c deklarierst Du "extern uint16_t LDRValue" und "extern
Work_t Work". Das ist erstens falsch, denn diese Deklarationen sollten
in dem Header-File passend zum C-File stehen, in dem sie definiert sind,
wie Karl Heinz ja schon ausführlich erklärt hat. Zweitens sind sie
ebenfalls unnötig:
- "LDRValue" wird nur in TM_RTC_RequestHandler() gelesen. Warum
übergibst Du es nicht als Parameter an TM_RTC_RequestHandler()?
- "Work" wird in mehreren Funktionen verwendet, die aber alle keine
Parameter haben. Warum übergibst Du ihnen keinen Zeiger auf "Work"?
Mit allen anderen globalen Variablen kann man es vermutlich ebenso
machen. Als Anfänger sollte man aus meiner Sicht auf globale Variablen
komplett verzichten. Wie man sieht, verleiten sie zu einem
fürchterlichen "Stil" von lauter Funktionen ohne Parameter, die auf
globale Variablen zugreifen. Wahrscheinlich, weil es auf den ersten
Blick so leichter zu schreiben ist. Aber selbst in kleinen Projekten
kann man das nach kurzer Zeit praktisch nicht mehr überblicken. Ein
Fremder, der den Code nicht selber geschrieben hat, schon gar nicht.
Die Struktur "Work" macht übrigens den Eindruck, als ob dort mehrere
Member zusammengefasst sind, die nicht wirklich zusammengehören. Wenn
man einfach alle Variablen, die man im Programm hat, in eine Struktur
packt und als Zeiger an jede Funktion übergibt, hat man zwar formal
keine globalen Variablen, praktisch aber nichts anderes.
Bevor man eine Funktion schreibt, sollte man sich genau überlegen,
welche Parameter sie braucht und welche sie zurückgibt. Wenn man dabei
feststellt, dass es zu viele Parameter sind, macht die Funktion entweder
zu viel oder zu wenig. Ideal sind Funktionen mit wenig Parametern, die
auf keine globalen Variablen zugreifen, denn die kann man auch als
Fremder oder Jahre später noch leicht überblicken und wiederverwenden.
Noch ganz allgemein: Wenn es in einem Projekt eine "main.h" gibt, ist
das schon ein Zeichen dafür, dass Header-Files falsch benutzt werden
oder es ungeschickte Abhängigkeiten gibt. Denn wenn es eine "main.h"
gibt, dann wird sie wohl nicht nur in "main.c" inkludiert (sonst könnte
der Inhalt einfach in main.c stehen), sondern auch in anderen Modulen.
Das heißt, anderer Module hängen vom Hauptprogramm ab. Damit lassen sie
sich nicht in anderen Projekten verwenden. Es sollte immer nur das
Hauptprogramm von anderen Modulen abhängen, niemals umgekehrt.
Etwas anderes ist es, wenn "main.h" keine Deklarationen von Funktionen
oder Variablen aus "main.c" enthält, sondern nur allgemeine
Projektdefinitionen wie CPU-Frequenz und Pins/Ports von IO-Pins. Dann
sollte sie aber nicht "main.h" heißen, sondern z.B. "config.h".
Hans schrieb:> - "LDRValue" wird nur in TM_RTC_RequestHandler() gelesen. Warum> übergibst Du es nicht als Parameter an TM_RTC_RequestHandler()?>> - "Work" wird in mehreren Funktionen verwendet, die aber alle keine> Parameter haben. Warum übergibst Du ihnen keinen Zeiger auf "Work"?
Hans,
der Code ist sehr gut durchdacht und strukturiert, inzwischen aber auch
mehr an das angepasst was ihr mir gesagt habt. Nur verfolgen wir
unterschiedliche Ansätze. Da ist auch nichts mit Spaghetticode. Und
wiederverwendbar ist NICHTS, aus dem ganzen Projekt nichts, weil es eine
spezielle Anwendung ist. Alles wiederverwendbare ist unterhalb in der
Middleware Schicht, einer Riesen Libary, die alle Peripheriemodule
abdeckt und die zwischen StdPeriphLib und der Applikation steht.
Und einer Interruptroutine kann man auch keine Parameter übergeben, denn
wie der Name schon sagt ist der Handler ein Handler, der auf einen Timer
reagiert.
Parameterübergabe macht gar keinen Sinn, wenn global eine Struktur
vorhanden ist, in der alle "Wetterdaten" drin sind, inkl. einer Historie
usw. Dies ist in config.h zu sehen, alle Module binden diese ein.
main.h ist inzwischen sehr leer geworden, da muss nix rein.
Wozu Parameter, wenn diese Datenbasis global allen Modulen bekannt ist
und sie nur aus dieser und in diese hinein arbeiten? Und Struktur
deswegen, weil da alle Daten an einem Stück zusammen sind die per Funk
übertragen werden können.
// Variablen, die alle Modulen bekannt gemacht werden
5
flags_tflags;
6
TM_BMP180_tBMP180_Data;// Drucksensor Daten
7
TM_RTC_Time_tTime;
Nein.
Noch mal.
In Header Files kommen KEINE Defintionen von Variablen!
Du musst endlich anfangen zwischen einer Definition und einer
Deklaration zu unterscheiden!
EIne Definition ist etwas, bei dem auch tatsächlich Speicher allokiert
wird. Hier muss der Compiler dafür sorgen, dass im tatsächlichen
Programm dafür Speicher bereit gestellt wird.
1
inti;
wäre eine Definition
1
voidfoo()
2
{
3
....
4
}
wäre eine Definition. In beiden Fällen wird tatsächlich dafür im
endgültigen Programm Speicher reserviert.
Eine Deklaration ist etwas, bei dem du bekannt gibst, das es etwas gibt
und wie es aussieht. Dafür produziert der Compiler nichts. Er nimmt
einfach nur zur Kentniss, dass es dieses Teil gibt und welchen Datentyp
es hat. Mehr nicht. Eine Deklaration produziert nichts im endgültigen
Programm.
wäre eine Deklaration.
In C gibt es dir ODR, die 'One Definition Rule'. Die besagt, dass du
jedes Ding nur ein einziges mal definieren darfst. Und zwar über das
komplette Progamm gesehen! Du darfst es deklarieren so oft du willst,
solange nur alle Deklarationen übereinstimmen. Aber definieren darfst du
es nur ein einziges mal. Genau diese ODR ist der Grund warum
1
inti;
2
doublei;
3
4
voidfoo(inta)
5
{
6
...
7
}
8
9
voidfoo(doublea)
10
{
11
....
12
}
in C illegal ist. Weil hier dasselbe mehrfach definiert wird.
Aber auch
1
inti;
2
inti;
wäre illegal. Selbst wenn die Datentypen übereinstimmen ist es dennoch
eine Verletzung der ODR. (Auch wenn dich der gcc bzw. dessen Linker
damit davonkommen lässt)
Wenn du jetzt in einem Header File eine Variable definierst(!)
foo.h
1
inti;
und dieses Header File in 2 andern C-Files inkludierst
1
// a.c
2
#include"foo.h"
1
// b.c
2
#include"foo.h"
dann hast du genau den Fall, dass der COmpiler beim compilieren von a.c
die Definition einmal sieht und daher veranlasst, dass eine Variable
namens i auf globalem Scope erzeugt wird und du hast denselben Fall
nocheinmal wenn b.c compiliert wird. D.h. im kompletten Programmverbund
hast du 2 Definitionen dieser Variablen - eine klare Verletzung der ODR!
----> In Header Files gibt es keine Definitionen von Variablen!
In Header Files stehen immer nur Deklarationen. Deklarationen kannst du
haben soviele du willst. Und da du die nur im Header File hast und
dieses Hedaer File überall inkludierst wo du auf diese Variable
zugreifen möchtest, ist auch sichergestellt, dass alle Deklarationen in
den unterschiedlichen C-Files übereinstimmen. Alles paletti.
Wenn du also ein config.h hast, indem du ein paar Variablen aus
praktischen Gründen global bekannt machen willst, dann immer nur in Form
von Deklarationen
1
// config.h
2
externintscreen_X_Resolution;
3
externintscreen_Y_Resolution;
aber klarerweise müssen die Variablen auch irgendwo existieren. Es
reicht ja nicht immer nur zu behaupten "Die gibt es" (nichts anderes
macht ja das extern. Eine Deklaration ist nur die Behauptung "Irgendwo
existiert xyz und so sieht es aus"). Irgendwann muss der Fisch ins
Wasser springen und irgendwo müssen die Variablen dann aber auch
tatsächlich angelegt werden. Na wenn du schon ein config.h hast, dann
macht man dazu passend dann eben ein config.c dessen einzige Aufgabe
darin besteht, dann auch tatsächlich dort an einer einzigen Stelle die
Variablen dann auch tatsächlich zu definieren. Und wie immer includiert
dieses C-File sebstverständlich sein eigenes H-File
1
#include"config.h"
2
3
intscreen_X_Resolution;
4
intscreen_Y_Resolution;
dieses config.c wird für sich alleine compiliert, sorgt damit dafür dass
im Programmverbund die Variablen tatsächlich *ein einziges mal definiert
werden* und alle anderen includieren das config.h und erhalten so über
die Deklarationen Zugang zu diesen globalen Variablen.
Den Rest kommentiere ich nicht mehr. Hans hat in fast allen Punkten
recht. Lediglich den Ausdruck "Spaghetticode" würde ich nicht für
angebracht halten. Aber seine Anmerkungen zu nicht vorhandenen
Funtkionsparametern sind alle richtig und begründet. Auf den ganz
kleinen µC machen globale Variablen Sinn. Auch gibt es meistens keine
andere Möglichkeit, wie man einer Interrupt Service Routine sonst Zugang
zum restlichen System verschaffen kann. Das sind die beiden Ausnahmen.
Aber abgesehen davon ist man mit Funktionsparametern immer besser drann.
Gerade weil man damit einzelne Module voneinander enftlechtet und
voneinander unabhängig macht. Was hat die Berechnung einer
Regressionsgerade mit der Datenübertragung zu tun. Richtig. Nichts.
Aber wenn du das sowieso nicht annehmen willst, dann mach es so wie du
es für richtig hältst. Irgendwann landest du in der Hölle der globalen
Variablen und dann wirst du wissen, warum wir alle davon abraten. Die
ersten Anzeichen hast du ja schon gesehen, wenn du in deinem
Eröffnungsposting schreibst, dass du es zwar richtig machen willst das
das aber eine ganz schöne Rumprobiererei wäre. Seltsam, du redest hier
mit Leuten, die Projekte bearbeiten, in denen 100-erte C-Files vorkommen
und für die ist das keine Rumprobiererei. Irgendwas müssen die wohl
anders machen.
Karl H. schrieb:> Was hat die Berechnung einer> Regressionsgerade mit der Datenübertragung zu tun. Richtig. Nichts.
Es macht nur wenig Sinn für 2 einzelne Routinen extra neue Module auf zu
machen, daher packe ich alles in tools.c rein. Und die Berechnung einer
Regressionsgerade basiert nunmal eng auf Werten von Work.
Was wäre denn hiermit anders? : CalcRegression (work_t *ptr) ?
Und noch schlimmer wird es, wenn ich die Struktur durchreichen muss in
Subroutinen.
Ich denk mal drüber nach heute abend als Übung. Läuft ja alles soweit,
mehr wird nicht hinzukommen.
Christian J. schrieb:> Karl H. schrieb:>> Was hat die Berechnung einer>> Regressionsgerade mit der Datenübertragung zu tun. Richtig. Nichts.>> Es macht nur wenig Sinn für 2 einzelne Routinen extra neue Module auf zu> machen, daher packe ich alles in tools.c rein. Und die Berechnung einer> Regressionsgerade basiert nunmal eng auf Werten von Work.>> Was wäre denn hiermit anders? : CalcRegression (work_t *ptr) ?
Nein.
Eine Regressionsrechnung arbeitet auf einem Satz von Datenpunkten.
Ist Work ein derartiger Satz von Datenpunkten?
1
typedefstruct{
2
int32_tid;// = 0x1234 nach Initialisierung
3
uint16_tptr;
4
floatPressure_Now,// Aktueller Druckwert
5
Temperature_Now;// Aktueller Temperaturwert
6
uint32_tPressure_Max,// Aktuell oberer Druckwert
7
Pressure_Min;
8
floatTemperature_Max,// Schwankungen um den Messpunkt
floatRegrSteigung;// Steigung der Regressionsgeraden
22
23
}Work_t;
wohl kaum.
ein struct data_t könnte es sein. Es klingt zumindest danach. D.h. die
Regressionsrechnung kriegt das History Array als Datenwerte vorgeworfen
und berechnet die Steigung der Regressionsgerade dafür
braucht es zur Berechnung dieser Steigung den ganzen Rest aus work?
Bruacht es den Mittelwert P_History_Avg. Nein braucht es nicht. Also
soll sie das auch nicht kriegen. Wozu auch. Irgendwann schreibst du
vielleicht mal ein Modul für deinen Yachtclub, welches den Wasserstand
überwacht und dort bräuchtest du wieder eine Regressionsgerade. Super.
Hast du doch schon eine Funktion dafür. Du befüllst das Datenarray mit
den Werten (wenn du die nicht sowiso schon in einem Array vorliegen
hast), rufst die Funktion aus deinem Fundus auf und bingo: Aufgabe in 20
Sekunden erledigt.
> Und noch schlimmer wird es, wenn ich die Struktur durchreichen muss in> Subroutinen.
Was ist denn da schlimm daran? Das sind nur Pointer und ein paar
Integer. Die laufen von einer Funktion zur nächsten.
Karl H. schrieb:> Du befüllst das Datenarray mit> den Werten (wenn du die nicht sowiso schon in einem Array vorliegen> hast), rufst die Funktion aus deinem Fundus auf und bingo: Aufgabe in 20> Sekunden erledigt.
Stimmt, der kriegt eigentlich nur eine Datenreihe, die andere ist fix
1,2,3...12 als x Koordinaten. Was natürlich jetzt mehr der Lesbarkeit
zugute kommt, denn effizientem Code.
Ich schreibe das mal alles als Übung um, war ja ein lehrreicher Thread.
Mist, nur wenn ich da jetzt was in dem struct ändere sind meine 3 Tage
Messwerte im Backup Ram futsch :-(
PS:
Schreibe grad die Funktionen auf Parameterliste um. Allerdings.....
übergebe ich Work, woraus nunmal viel gebraucht wird (und nicht jeden
Wert einzeln daraus), so erzeugt mir das eine Kopie auf dem Stack und
die ist 800 Bytes gross. Denn wenn ich Call by Reference verwende
erzeuge ich ja Schreibrecht der Funktion auf die Werte was nicht immer
gewünscht ist. Ist das so ok oder "ineffizient"? Ich weiss ja nicht ob
da kopiert wird.
ich hab da auch mal 'ne Frage:
wenn ich ein c-Modul schreibe und dazu einen Header für die Funktionen,
die extern von anderen Modulen verwendet werden sollen, muss das
Header-File ja NICHT unbedingt gleichlautend mit dem c-File benamt sein
(also PID.h muss nicht unbedingt auf PID.c verweisen.
Wenn ich den Scope jetzt etwas objektorientierter haben möchte (a la
Interface-Zugriff), könnte ich ja ein Modul PID.c schreiben mit zwei
Headern (PIDParameterize.h und PIDCalculate.h) die mir die
entsprechenden Funktionendeklarationen spezifisch für die anderen Module
kapseln.
Frage: Ist das so Usus oder geht man da andere Wege?
Christian J. schrieb:> Denn wenn ich Call by Reference verwende> erzeuge ich ja Schreibrecht der Funktion auf die Werte was nicht immer> gewünscht ist.
Wenn ich richtig informiert bin, gibt es das Schlüsselwort `const` doch
auch schon seit über 10 Jahre in C, oder?
Torsten R. schrieb:> Wenn ich richtig informiert bin, gibt es das Schlüsselwort `const` doch> auch schon seit über 10 Jahre in C, oder?
Ja, gibt es. Und was ist vorzuziehen: const call by value oder const
call by reference?
Christian J. schrieb:> Ja, gibt es. Und was ist vorzuziehen: const call by value oder const> call by reference?
Bei größeren Daten sollte der default immer "call by const reference"
sein.
Torsten R. schrieb:> Christian J. schrieb:>> Ja, gibt es. Und was ist vorzuziehen: const call by value oder const>> call by reference?>> Bei größeren Daten sollte der default immer "call by const reference"> sein.
Ok, trotzdem vebraucht diese Lösung derzeit 500 Bytes mehr an Code. Denn
ein Array wird ja immer by reference übergeben, einer Struktur muss man
es durch & erst sagen. Sieht auf jeden Fall schon geschmeidiger aus.
Zumindest hoffe ich, dass Work.History als Zeiger übergeben wird.
Work.RegrSteigung = tls_CalcRegr(Work.ptr,Work.History);
Christian J. schrieb:> Ok, trotzdem vebraucht diese Lösung derzeit 500 Bytes mehr an Code.
500 Bytes mehr als was?
Ein paar Anmerkungen von mir (kannste gerne ignorieren, wenn Dir das zu
"akademisch" vorkommt):
- Einige Namen sind schlecht gewählt. Das erkennst Du selbst daran, dass
Du Dich genötigt siehst, sofort einen Kommentar neben die Namen zu
schreiben (data_t, RASTER, m, Xx..).
- Viele Variablen könntest Du später deklarieren. Damit wäre der Scope
einzelner Variablen deutlich kleiner und damit wird der Code lesbarer,
weil der Leser weniger Seiteneffekte auf eine Variable vermuten muss.
- Wenn Du Variablen generell bei der Deklaration auch initialisierst,
vermeidest Du die Fehlermöglichkeit, mit nicht initialisierten Variablen
zu arbeiten und nimmst dem Leser die Arbeit ab, zu prüfen, ob alle
Variablen initialisiert wurden.
- Kommentare vor einem abgesetzten Code-Block sind häufig ein Indiz
dafür, dass dieser Code-Block eine eigene Funktion sein könnte und das
der Kommentar ein guter Kandidat für den Namen der Funktion abgeben
würde.
- Xq ist eine Konstante, genau wie RASTER, vielleicht sollte man es dann
auch genau so als Makro implementieren?
- m wird genau einmal zugewiesen und einmal gelesen und das in zwei auf
einander folgenden Zeilen ;-)
mfg Torsten
Torsten R. schrieb:> - Xq ist eine Konstante, genau wie RASTER, vielleicht sollte man es dann> auch genau so als Makro implementieren?> - m wird genau einmal zugewiesen und einmal gelesen und das in zwei auf> einander folgenden Zeilen ;-)
Das ist jetzt rein persönlicher Stil, den der Compiler eh eliminiert.
Lieber eine Variable mehr als alles ineinander schachteln :-) Und einen
Code nach MISRA wollte ich privat nicht schreiben, den liest niemand
anderes als ich selbst.
Aber so siehts schöner fürs Forum aus :-)
return (XiXqYiYq / Xi_Xq2);
Torsten R. schrieb:> Und wozu die Klammern? ;-)
Ich steh auf kurvige Formen :-) Jedenfalls arbeitet die Prognose schon
sehr gut, der DAX hat heute 250 Punkte gemacht, genauso wie der
Luftdruck :-)
Christian J. schrieb:> Jedenfalls arbeitet die Prognose schon> sehr gut, der DAX hat heute 250 Punkte gemacht, genauso wie der> Luftdruck :-)
Wahrscheinlich gibt es da eine Korrelation! Ich könnte mir auch
vorstellen, dass man bessere Anlageerfolge erzielt, wenn man Frösche
nach Anlagetipps fragt, als wenn man Banker fragt ;-)
Torsten R. schrieb:> Wahrscheinlich gibt es da eine Korrelation! Ich könnte mir auch> vorstellen, dass man bessere Anlageerfolge erzielt, wenn man Frösche> nach Anlagetipps fragt, als wenn man Banker fragt ;-)
Ist echt verblüffend heute :-) Das Programm läuft ja trotz einiger
syntaktischer Schwächen. Hoffe nur, dass über die Feiertage nichts
Schlimmes passiert und es ein Riesen-Gap nächsten Montag nach unten
gibt. Das wäre gar nicht gut.
Nochmal ne Frage an die Profis:
Warum funktioniert die Sicherung von Daten im E2PROM nicht, wenn ich die
Optimierung nicht für diese Init Sequenz abschalte? Ich compiliere
normalerweise of -Os (for size) aber auch bei den anderen Stufen schlägt
direkt der erste Befehl fehl, da ich jeden einzelnen mit einer
Fehlerabfrage abgesichert habe.
Diese Optimerung ist manchmal umheimlich. Ich hoffe doch mal, dass die
mitgelieferten StdPeriphLibs dagegen immun sind aber ich benutze ja nur
genau die.
Nur eine Idee: Vielleicht solltest Du zuerst den Bus initialisieren und
erst dann einschalten? Sonst schaltest Du ihn ein, änderst danach aber
sofort den Takt etc.. Könnte sein, dass das Nebenwirkungen hat, wenn es
zu schnell geht.
Hans schrieb:> Nur eine Idee: Vielleicht solltest Du zuerst den Bus initialisieren und> erst dann einschalten? Sonst schaltest Du ihn ein, änderst danach aber> sofort den Takt etc.. Könnte sein, dass das Nebenwirkungen hat, wenn es> zu schnell geht.
Nee, war es nicht. Das Schlimme ist ja, dass wenn ich jetzt im Debug
Mode die gleiche Opt. einschalte und in Kauf nehme, dass der Balken wild
hin und her springt im Source Code das Problem nicht auftaucht :-( Das
hatte ich schonmal mit einem Luftdrucksensor. Im Debug Mode läuft ein
Programm langsamer ab.
Man sagt ja, dass man zuerst ohne Opt. entwickeln soll und dann erst
einschalten aber dann steht man oft vor "geht gar nichts mehr", während
ich jetzt bei jedem neuen Modul das Problem sofort sehe. Allerdings
weiss ich nicht was der da sonst noch so alles heimlich macht, was sich
vielleicht nicht sofort auswirkt.
Habe mir jetzt angewöhnt überall dot wo ich auf der Hardware rumklimper
die abzuschalten, nur Code, der ganz ohne HW Zugriffe auskommt, da
bleibt sie an.
Ohne Optmierung: 75 kb
Mit Optimierung: 59 kb
Das ist schon ne Hausnummer. Der Code soll ja gut sein, nahe am
Assembler.
Horst S. schrieb:> Wenn ich den Scope jetzt etwas objektorientierter haben möchte (a la> Interface-Zugriff), könnte ich ja ein Modul PID.c schreiben mit zwei> Headern (PIDParameterize.h und PIDCalculate.h)...
Nun ja, im Prinzip kann man sämtlichen Dateien einen Namen nach eigenem
Gusto verpassen, aber ich finde es deutlich besser, wenn eine C-Quelle
den gleichen Vornamen hat wie die zugehörige Headerdatei.
Ob man irgen welche Parameter oder so in jeweils separate Dateien faßt
(PIDCalculate.h) oder ob man das Zeugs einfach am Anfang der Quelle
hinschreibt oder ob man so eine doch eher sehr spezielle Datei dann
nicht PIDCalculate.h nennt sondern PIDCalculate.inc oder so - das ist
dann eher Geschmackssache. Mein Fall wäre das garnicht, denn eine xyz.h
ist nach allgemeinem Verständnis doch eher dafür gedacht, in anderen
Programmteilen verwendet zu werden - und was so spezielles ist nur für
die eine Quelle sinnvoll, nicht aber für andere Quellen.
Und nochwas: Die Ansicht, daß eine .h "self contained" sein sollte,
teile ich überhaupt nicht. Wenn jemand ein stdbool.h braucht, dann
sollte er das eben in ALLE seine .c inkludieren. Ist ja wohl nicht
zuviel verlangt.
W.S.
W.S. schrieb:> Und nochwas: Die Ansicht, daß eine .h "self contained" sein sollte,> teile ich überhaupt nicht. Wenn jemand ein stdbool.h braucht, dann> sollte er das eben in ALLE seine .c inkludieren. Ist ja wohl nicht> zuviel verlangt.
Hast Du noch irgend ein zweites Argument für das Einbinden eines Heiders
an allen Stellen, obwohl er nur an einer Stelle benötigt wird, ausser
das es nicht so schwer ist? Ich kann mir vieles vorstellen, dass nicht
zuviel verlangt ist, aber deswegen muss ja trotzdem keinen Sinn ergeben.
W.S. schrieb:> Und nochwas: Die Ansicht, daß eine .h "self contained" sein sollte,> teile ich überhaupt nicht. Wenn jemand ein stdbool.h braucht, dann> sollte er das eben in ALLE seine .c inkludieren. Ist ja wohl nicht> zuviel verlangt.
Und was, wenn irgendeine Funktion, die im Header deklariert ist, bool
braucht, aber ich diese Funktion gar nicht benutze und selber bool nicht
verwende? Dann muss ich stdbool.h inkludieren, obwohl ich es gar nicht
brauche, nur weil das Einbinden des Header sonst zu einem Fehler führt.
Also....
so wie ich das jetzt sehe soll das alles ein wenig wie C++ werden, wo
Klassen Code und Daten zusammen binden und nach außen ein definiertes
Interface besteht. C++ ist eben das bessere C, nur leider auch etwas
"kompliziert".
Ich frickel immer noch um. Inzwischen ist "Work" in einem C-File
"work.c" verschwunden und niemand hat mehr direkten Zugriff da drauf.
work.c enthält nur noch kleine Routinen, die die Außenwelt etwas
hineinschreiben oder auslesen lassen und Zeugs wie Regression wird auch
innerhalb von work.c erledigt.
Falsch kann das ja nicht sein, ich komme inzwischen mit nur noch 2
globalen Vars aus und habe nahezu alles auf Parameterübergabe
umgetextet.
Torsten R. schrieb:> Hast Du noch irgend ein zweites Argument für das Einbinden eines Heiders> an allen Stellen, obwohl er nur an einer Stelle benötigt wird, ausser> das es nicht so schwer ist?
Ja, hab ich bereits viel weiter oben geschrieben: die tatsächliche
Übersichtlichkeit ist es. Ich habe in .h Dateien schon so verdammt oft
solche Konstrukte lesen müssen:
#include "/../../../common/6.0/foo.h"
und dergleichen, daß ich davon die Nase gestrichen voll habe. Es ist
schlußendlich ein grottenschlechter Stil und nur zu vermeiden, wenn man
ganz konsequent keine includes in Headerdateien macht.
Rolf M. schrieb:> Und was, wenn irgendeine Funktion, die im Header deklariert ist, bool> braucht, aber ich diese Funktion gar nicht benutze und selber bool nicht> verwende?
Nö. So nicht.
Wenn du nen Modul brauchst, wo bool verwendet wird, und du genau
deswegen die Headerdatei zu diesem Modul inkludierst, dann brauchst du
bool ebenfalls.
Es sei denn, du hast die logische Aufteilung deines Projektes in
sinnvolle Moduln falsch gemacht und schlußendlich kein gutes Konzept
realisiert, sondern sowas wie ein Leipziger Allerlei fabriziert. Ich
kenne auch solche Projekte, wo Moduln namens misc.c und genmisc.c einem
unterkommen. Das ist dann sowas wie ein Mülleimer voll "general
miscellanious" Zeugs.
W.S.
W.S. schrieb:> Ja, hab ich bereits viel weiter oben geschrieben: die tatsächliche> Übersichtlichkeit ist es. Ich habe in .h Dateien schon so verdammt oft> solche Konstrukte lesen müssen:>> #include "/../../../common/6.0/foo.h">> und dergleichen, daß ich davon die Nase gestrichen voll habe. Es ist> schlußendlich ein grottenschlechter Stil und nur zu vermeiden, wenn man> ganz konsequent keine includes in Headerdateien macht.
Und in wie weit wird die Situation besser, wenn Du das obige include 15
mal in den C-files, die implizit foo.h verwenden, wiederholst? Ich
verstehe weder Dein Problem, noch Deine Lösung.
W.S. schrieb:> Rolf M. schrieb:>> Und was, wenn irgendeine Funktion, die im Header deklariert ist, bool>> braucht, aber ich diese Funktion gar nicht benutze und selber bool nicht>> verwende?>> Nö. So nicht.> Wenn du nen Modul brauchst, wo bool verwendet wird, und du genau> deswegen die Headerdatei zu diesem Modul inkludierst, dann brauchst du> bool ebenfalls.>> Es sei denn, du hast die logische Aufteilung deines Projektes in> sinnvolle Moduln falsch gemacht und schlußendlich kein gutes Konzept> realisiert, sondern sowas wie ein Leipziger Allerlei fabriziert.
Nein. Es ist nur lediglich so, dass ich nicht zwangsweise in jeder
C-Datei, in der ich einen Header einbinde, auch sämtliche in diesem
Header deklarierten Dinge auch benutze. Und ich möchte mich nicht um die
Dinge kümmern müssen, die ich nicht benutze.
Ein Beispiel: (Ist vielleicht arg konstruiert, aber die Idee sollte klar
werden)
1
#include"mylcd.h"
2
3
voidprint_hello_world(void)
4
{
5
lcd_print("Hallo, Welt");
6
}
und es kommt eine Fehlermeldung dass struct coordinates nicht definiert
ist, weil es in mylcd.h eine Funktion set_coord(struct coordinates)
gibt. Die brauche ich aber gar nicht. Trotzdem muss ich erstmal
rumsuchen, wo denn nun diese struct, die mich eigentlich überhaupt nicht
interessiert, definiert ist. Und dann muss ich am Ende noch irgendein
anderes Include in meiner C-Datei einfügen, das nichts definiert, was in
dieser C-Datei benutzt wird, nur damit "mylcd.h" fehlerfrei eingebunden
werden kann.
Und die Reihenfolge, in der die Header eingebunden sind, spielt auf
einmal auch eine Rolle.
Sowas nervt nur und hat genau gar keinen Vorteil.
Torsten R. schrieb:> Und in wie weit wird die Situation besser, wenn Du das obige include 15> mal in den C-files, die implizit foo.h verwenden, wiederholst?
Weil man es eben NICHT 15 mal wiederholen muß. Die Rückverfolgung eines
Pfades aus einer tief in einem anderen Pfad vergrabenen .h ist was
anderes als das zweimalige Einbinden von zwei völlig unterschiedlichen
.h aus zwei ebenso unterschiedlichen Pfaden. Kapito?
Rolf M. schrieb:> und es kommt eine Fehlermeldung dass struct coordinates nicht definiert> ist, weil es in mylcd.h eine Funktion set_coord(struct coordinates)> gibt.
Ach, und struct coordinates ist ganz woanders definiert als dort, wo es
tatsächlich gebraucht wird? Ich sag's ja immer: falsches Layout des
gesamten Projektes, falsche Aufteilung in Module, am Schluß ein
Riesensack von kreuz- und quer-Abhängigkeiten zwischen allen Quellen,
eben Spaghetticode in C. Das ist es, was schlußendlich dahinter steckt.
W.S.
W.S. schrieb:> Ach, und struct coordinates ist ganz woanders definiert als dort, wo es> tatsächlich gebraucht wird?
Vielleicht gibt's ja auch noch andere Stellen, wo Koordinaten benötigt
werden, und somit sind sie einmal zentral definiert, statt in X
verschiedenen Headern. Module dürfen durchaus aufeinander aufbauen. Ab
einer gewissen Komplexität macht man sonst alles doppelt und dreifach.
> Ich sag's ja immer: falsches Layout des gesamten Projektes, falsche> Aufteilung in Module, am Schluß ein Riesensack von kreuz- und quer-> Abhängigkeiten zwischen allen Quellen, eben Spaghetticode in C.
Nein, ganz im Gegenteil. Dir fehlt einfach das Verständnis, oder du
gehst meinen Fragen bewußt aus dem Weg.
Von mir aus können wir auch bei deinem Beispiel bool bleiben. Nehmen wir
an, die mylcd.h wird später erweitert um die Funktion
1
boolis_backlight_on(void);
Dann sind wir uns hoffentlich einig, dass bool nicht direkt in mylcd.h
definiert werden muss. Benutzt der Header es jetzt einfach ohne
vorherige Defintion? Dann muss ich ja in allen Files, die mylcd.h
einbinden, nachträglich ein #include <stdbool.h> einfügen oder zumindest
dafür sorgen, dass stdbool.h vor mylcd.h eingebunden wird. Was ein
Krampf!
Es ist ja eher unwahrscheinlich, dass jedes C-File, das die
LCD-print-Funktion nutzen will, auch prüfen will, ob das Backlight an
ist, und es sollte sich auch nicht um Abhängigkeiten, die sich daraus
ergeben, kümmern müssen.
Wenn ein Header Abhängigkeiten hat, dann hat sie der Header selbst, und
dann ist der auch dafür verantwortlich, die aufzulösen. Warum soll ich
diese Aufgabe wo anders hin verlagern, und noch dazu an mehrere Stellen,
nämlich alle, die den Header benutzen, statt nur an genau der einen, wo
die Abhängigkeit auftritt?
Wenn ein C-File, das mylcd.h einbindet, auch bool benutzt, dann soll es
natürlich auch selbst stdbool.h inkudieren, unabhängig davon, ob mylcd.h
es tut. Aber eben nur, wenn bool wirklich in diesem C-File benutzt wird.
Und die include-Reihenfolge sollte auch keine Rolle spielen.
Du hast übrigens immer noch versäumt, zu Erwähnen, was denn der Vorteil
deiner Methode ist. Ich kann nämlich immer noch keinen entdecken, nur
Nachteile, die du eifrig wegzudiskutueren versuchst.
W.S. schrieb:> Das ist dann sowas wie ein Mülleimer voll "general> miscellanious" Zeugs.
Der heisst bei mir immer "tools.c" :-) Alles was nicht woanders
reinpasst wird da reingeklatscht.
So, Feierabend mit dem Durcheinander:
mainc: Zyklisches Aufrufen aller Funktionen
config.c Datenstamm, isoliert, Funktionen zum Setzen/Holen
init.c Alle Hardware-Inits, Variablen Inits
sensor.c/h: Alles was mit Sensoren zu tun hat, die Werte liefern
füttert config.c
tools.c Management der LEDs und Relais
eeprom.c Alles was Daten in E2PROM wegspeichert und zurückholt
process.c/h Verarbeitung der Daten, Wegspeichern, Ummodeln usw.
holt von config.c
grafik.c Alles was etwas auf dem Display darstellt
holt von config.c
rtc.c Alles was mit Zeitsteueurng zu tun hat
Natuerlich bestehen zwischen den Modulen Interfaces, grafik.c braucht
auch etwas aus rtc.c, process bedient sich tools.c um LEDs zu setzen
usw.
Basta!
PS: Im Vergleich zu "alles global" ohne Parameterliste ist der
Programmcode von 58kb auf 67kb angewachsen, d.h. "optimaler Code" isz
zugunsten "lesbarer Code" gewichen. Und ich denke, anders geht es auch
nicht. Bei nem 4KB AVR vielleicht, nicht aber bei einem 1MB Flash mit
168 MHz Ticker ARM Core, da ist das völlig wumpe.
Frage an die STM32 Fans:
Wenn ich bei einem Port gemischte Pins habe, also OUT und IN, ist das so
richtig mit der StdPeriphLib? Ich setze erst die OUTs, dann modifizere
ich nur die member, die bei IN anders sind und rufe nochmal den Init auf
Oder gibt es eine Technik das alles mit einem einzigen Aufruf zu machen?
(ohne auf Registerebene zu arbeiten?)
1
// Port E mit den Wetter Tendenz LED einstellen (OUPUT)
Rolf M. schrieb:> Dann sind wir uns hoffentlich einig, dass bool nicht direkt in mylcd.h> definiert werden muss. Benutzt der Header es jetzt einfach ohne> vorherige Defintion?
Ja.
Schmeiß nicht Zeugs zusammen, was nicht zusammengehört. Die Definition
von grundlegenden Datentypen gehört NICHT in einen Treiber, sondern eben
in einen separaten Header, der von allen Quellen zu inkludieren ist, die
ebensolche grundlegenden Datentypen zu benutzen gedenken. Das ist die
eine Seite.
Die andere Seite sind Definitionen, die spezifisch zu einem Treiber bzw.
Modul gemacht werden müssen. Beispiel: struct coordinates. Du hast es im
Zusammenhang mit einem Display erwähnt. OK so, aber bedenke, daß es
vielleicht noch ganz andere Koordinaten gibt. Zum Beispiel bei jemandem,
der mit deinem µC einen 3D-Drucker bauen will oder einen anderen, der
ein Satellitenberechnungsprogramm implementieren will, um zur rechten
Zeit seine Antenne auf den aktuellen OSCAR ausrichten zu können. Völlig
unterschiedliche Koordinatensysteme, mal 2D mal 3D mal in Millimetern,
mal als double für kosmische Dimensionen.
Merkst du jetzt endlich was? Wenn ein LCD-Treiber "MyLCD.c" ein struct
coordinates braucht, dann sollte dieses NIEMALS separat und ganz
woanders difiniert sein, sondern immer nur in MyLCD.h und es sollte ein
sinnvoller Name gewählt werden, wie z.B. struct LcdXY oder so.
Deine Art, Includes in Headerdateien zu schreiben, führt zu ganz
schlecht wartbarem Code. Beispiel sind manche Headerdateien zu µC, wo
eigentlich nur die im Controller vorkommenden HW-Register definiert sein
sollten, aber dank diverser Includes der komplette Sack an CMSIS und
anderes inkludiert werden. Da in solchen Fällen ganz gewiß nicht die
richtige Festlegung über die konkrete CPU in der inkludierenden C-Quelle
hingeschrieben worden ist - oder noch schlimmer in manchen C-Quellen
diese Angabe steht und woanders nicht - werden die verschiedenen Quellen
mit unterschiedlichen Definitionen/Konstanten übersetzt. Und nun such
mal nach den dadurch verursachten Bugs.
W.S.
W.S. schrieb:> Die andere Seite sind Definitionen, die spezifisch zu einem Treiber bzw.> Modul gemacht werden müssen. Beispiel: struct coordinates. Du hast es im> Zusammenhang mit einem Display erwähnt. OK so, aber bedenke, daß es> vielleicht noch ganz andere Koordinaten gibt. Zum Beispiel bei jemandem,> der mit deinem µC einen 3D-Drucker bauen will oder einen anderen, der> ein Satellitenberechnungsprogramm implementieren will, um zur rechten> Zeit seine Antenne auf den aktuellen OSCAR ausrichten zu können. Völlig> unterschiedliche Koordinatensysteme, mal 2D mal 3D mal in Millimetern,> mal als double für kosmische Dimensionen.
Deswegen sollten Datentypen auch nicht nach ihrer Funktion sondern nach
ihren Eigenschaften benannt werden. Ein int ist eine Ganzzahl, ein char
ist ein Zeichen, ein coordinates2d sind 2D-Koordinaten usw.
Ein Beispiel aus C++:
Eine allgemein verwendbare Klasse benutzt std::vector um seine Daten zu
halten. Diese Klasse wird nun in X verschiedenen Source-Dateien
verwendet. Nun wird die Klasse überarbeitet und statt std::vector wird
std::list bemutzt. Willst du jetzt wirklich in allen X Source-Dateien
#include <vector> durch #include <list> ersetzten? Zumal du auch noch
schauen musst, ob du das #include <vector> wirklich entfernen darfst,
oder ob dein Code dies auch verwendest.
Wir könnten das noch weiter treiben:
Willst du in deiner Source auch alles inkludieren, was <vector>
inkludiert, und auch auch das, was diese wieder inkludieren? Auf die
richtige Reihenfolge musst du dabei auch noch achten.
be s. schrieb:> Ein Beispiel aus C++:> Eine allgemein verwendbare Klasse...
Weder C++ noch die damit verbundene dynamische Speicherverwaltung noch
"allgemein verwendbare Klassen" sind bei dem Schreiben von Firmware für
die hier üblichen µC irgend ein Thema.
Hier geht's um schlichtes C in Ermangelung von was wirklich besserem
und eben dieses schlichte C reicht im Großen und Ganzen eigentlich auch
aus. Das, was du da als Beispiel an den Haaren herbeigezerrt hast, nenne
ich mal schnöde "Programmier-Onanie". Sorry.
Aber vielleicht können hier mal Leute antworten, die auf ihrem AVR schon
mal einen Sack voll "allgemein verwendbarer Klassen" benutzt haben.
W.S.
W.S. schrieb:> Weder C++ noch die damit verbundene dynamische Speicherverwaltung noch> "allgemein verwendbare Klassen" sind bei dem Schreiben von Firmware für> die hier üblichen µC irgend ein Thema.
Also bindest du die Header bei einem PC-Programm in C++ ganz anders ein
als auf einem µC-Programm in C? Oder warum ist das für die Fage, ob
Header self-contained sein sollen, relevant? Dürfen die nur bei Firmware
nicht self-contained sein?
W.S. ist weder auf das Beispiel "vector vs. list" noch auf
"isBacklightOn" eingegangen.
Wie ein ehemaliger Assembler-Fanboy geht er den peinlichen Fragen aus
dem Weg.
Dein Argument mit dem ewig langen Pfad ("../../common...") versteh ich
auch nicht.
Inwiefern wird das besser wenn die Pfad-Orgie in 10 c-Files
ge-copy-pasted wird?
Mal abgesehen davon: wenn Pfade bei includes verwendet werden müssen ist
das Build-System schon mal nicht sauber aufgesetzt...
On-Topic:
Header sind self-contained.
Hab ich in der Industrie auch noch nie anders gesehen, und da sind (was
Architektur betrifft) in der Regel keine Anfänger am Werk.
Jaja, war wahrscheinlich nur in Bastel-Projekten unterwegs...
Christian J. schrieb:> Oder gibt es eine Technik das alles mit einem einzigen Aufruf zu machen?> (ohne auf Registerebene zu arbeiten?)
Warum scheust du dich so sehr davor, deine Hardware direkt anzusprechen?
Mit der ST-Lib wird das Ganze nur aufgebauscht, ohne daß das irgendwas
nützen würde. Und nun stell dir mal vor, du würdest mal nen anderen µC
benutzen. Da gibt es dann plötzlich keine ST-Lib dazu und was dann?
Natürlich kann man alles von dir Geschilderte mit einem einzigen Aufruf
machen - aber das heißt eben, direkt auf die HW zuzugreifen. Nur zu, du
brauchst da keine Angst zu haben. Du hast es ja selber gesehen, was das
alles für ein Aufwand ist: zuerst nen struct im RAM mit Dutzenden von
Konstanten befüllen, dann ein Unterprogramm aufrufen - und das klatscht
den ganzen Krempel anschließend zusammen und schreibt eben das, was du
selber auch formulieren könntest, ins HW-Register. Aufgeblasener geht's
nicht mehr. Dabei liefert diese Art, mit der HW umzugehen, keinerlei
wirkliche Abstraktion. Man muß trotz allem immer wieder alles selber
machen. Es sind eben keine wirklichen HW-Treiber, die da geboten werden.
Ich hatte mir diesen Schund vor Jahren schon angeschaut und verworfen.
W.S.
W.S. schrieb:> Warum scheust du dich so sehr davor, deine Hardware direkt anzusprechen?> Mit der ST-Lib wird das Ganze nur aufgebauscht, ohne daß das irgendwas> nützen würde.
Das ist wohl eine Frage der Philosophie, die bei mir hin zu lesbarem
Code geht. Das da untren schrieb ich mal vor 7 Jahren fuer den ARM7TDMI,
als es noch keine "Libs" gab und kein CMSIS. Ich finde das schrecklich,
ständig im Datenbuch rumzusuchen welches Bit grad wo versteckt ist.
Inzwischen habe ich eine IDE, die mir bei Eintippen einer Funktion
automatisch anzeigt welche Parameter möglich sind und diese werden
automatisch ergänzt nach 3 Buchstaben. Uns bei der Affengeschwinfigkeit
und 1 MB Flash ( Eine Million Byyes!) spielt es kaum mehr eine Rolle da
was zu optimieren. Der Compiler bricht das alles sowieso runter, im Asm
ist von den StdLibs und CMSIS nichts mehr zu sehen.
Schauer..... :-(
1
// ...und schalten sie aus
2
PLLCON=0;
3
PLLFEED=0xaa;
4
PLLFEED=0x55;
5
6
CLKSRCSEL=0x1;// PLL Source = Main Oscillator
7
8
// PLL neu konfigurieren
9
PLLCFG=PLL_M|(PLL_N<<16);
10
PLLFEED=0xaa;
11
PLLFEED=0x55;
12
13
// PLL einschalten aber abgetrennt
14
PLLCON=1;
15
PLLFEED=0xaa;
16
PLLFEED=0x55;
17
while(((PLLSTAT&(1<<26))==0));// Warte bis stabil
18
19
// CPU Clock Teiler setzen
20
CCLKCFG=CCLKDiv;
21
22
// PLL an Main Oscillator andocken....
23
PLLCON=3;
24
PLLFEED=0xaa;
25
PLLFEED=0x55;
26
while(((PLLSTAT&(1<<25))==0));/* Check connect bit status */
Anbei mal der gesamt Code des Projektes.
Wenn einer der Profis, die genauso gern programmieren wie ich und
vielleicht Zeit mal mal schauen und meckern möchten. Nuancen vielleicht
mal ausgeschlossen, sondern nur echte "dicke Dinger" anmerken......
Christian J. schrieb:> Anbei mal der gesamt Code des Projektes.
Hmm. Spaghetticode - wenn du mich fragst.
Ich habe allerdings nur deine config.c/.h angeschaut. Da findet sich der
Systemtick-Handler, aber nicht dessen tatsächliche Initialisierung - die
müßte also ganz woanders stehen. Und sowas wie "void cfg_Init_Runtime()
{..." ist ein Name, der im Grunde garnix sagt.
Naja, und in Stilfragen seh ich das auch anders, also nicht
void MyFunc (xyz..) {
...
}
sondern lieber
void MyFunc (xyz..)
{
...
}
aber das ist Geschmackssache. Wenn jemand zu einer schließenden Klammer
die öffnende lieber irgendwo rechts im Text sucht anstatt links in der
gleichen Spalte.. bittesehr.
Und was "void DelayMs(uint32_t msec) {..." in config.c zu suchen hat,
ist mir auch schleierhaft. Hat doch garnix mit Konfiguration zu tun,
sondern eher mit der Systemuhr, also SysTick.
Dafür ist dein config.h wesentlich zu umfänglich. So etwa 90% davon
gehört NICHT dort rein.
Wenn du so weiterschreibst, läufst du Gefahr, in deinem eigenen Code zu
ersticken.
Also:
1. Benenne und gruppiere dein Zeugs lieber so, wie es der tatsächliche
Sinn ist. Also in config.c eben nur die tatsächliche Konfiguration des
Chips, wozu gehört:
- Takte aufsetzen
- interne Enables aufsezen (Module einschalten usw.)
- Pin-Konfiguration aufsetzen
- ggf. wichtige Peripherie aufsetzen (externen SDRAM)
- ggf. Speicher und Peripheriebereiche ablöschen falls sinnvoll
Den Rest macht man dann in main.c, also
- Bootkonditionen auswerten (evtl. Resetgründe usw.)
- Systick aufsetzen
- UARTs aufsetzen
- Startmeldungen, Lebenszeichen usw.
- sonstige Peripherie aufsetzen (USB, Bildschirm usw.)
2. Schreibe dir Treiber für die HW, die die HW tatsächlich kapseln, so
daß man in den höheren Ebenen der Firmware sich NICHT mehr mit deren
Details herumschlagen muß.
Ich hänge dir mal ein paar (historische) Beispiele dran, nur zum Ansehen
und damit du ein Gefühl kriegst, wie viel oder wenig man in den
zugehörigen *.h wirklich braucht. Der Rest sollte in den jeweiligen
Moduln gekapselt sein, damit man nicht überall alles um die Ohren hat.
W.S.
W.S. schrieb:> Nun ja, im Prinzip kann man sämtlichen Dateien einen Namen nach eigenem> Gusto verpassen, aber ich finde es deutlich besser, wenn eine C-Quelle> den gleichen Vornamen hat wie die zugehörige Headerdatei.
Jo, besser finde ich das auch. Nur habe ich in letzter Zeit immer
häufiger die Herausforderung, dass ich Tests oder Servicefunktionen, wie
z.B.
- "Stell mal das angeschlossene Bluetoothmodul mit eigenem EEPROM auf
57k Baudrate"
oder
- "Leg mal die Grenzen eines Schmitt-Triggers im EEPROM ab"
oder
- "teste mal die intern verwendete Funktion eines Moduls mit den
möglichen Eingangsparametern im Simulator"
sinnvoll verwalten möchte. Da möchte ich weder dauerhaft den Code im
Projekt behalten, noch die eigentlich "internen" Funktionen, die ich
teste/verwende, dauerhaft im Header als Extern deklariert.
Was tun?
Präcompilerkonstanten? Finde ich eher komplizierter (insbesondere, wenn
sich die Funktionen für einzelne Tests/Funktionen überlappen) als ein
einzeln ausführbares Projekt auf die Schnelle zusammenzustecken, in dem
ein völlig sinnbefreit benamter Header die benötigten Funktionen
veröffentlicht.
Was gibt's noch für Alternativen?
Horst S. schrieb:> Stell malHorst S. schrieb:> Leg malHorst S. schrieb:> teste mal
Das kommt mir vor wie die Zurufe von Chaoten an den Programmierer.
Ich hab zumeist für solche (und andere) Zwecke einen residenten
Hintergrundmonitor in der Firmware drin. Wenn man einen UART übrig hat
und keinen allzukleinen µC, dann ist das genau die passende Lösung. Ein
Beispiel kannst du in der Lernbetty sehen (BettyBaee, cmd.c), das ist
ein komplett portables Stück, läuft bei mir auch auf ganz anderen
Plattformen. Man kann sich dort relativ beliebige Kommandos ganz leicht
einbauen und um dein Beispiel zu nennen, auch ein init_BT(beliebigezahl)
per Kommando hinkriegen:
Anders sieht es aus, wenn man keinen Zeitrahmen hat, um zu debuggen (wie
z.B. beim USB). Dann muß man sich eben einen kleinen postmortem-logger
oder debugger schreiben, dessen Datenbereich man eben mit Einsprengseln
füllt und nach Absturz in aller Ruhe augibt.
W.S.
Christian J. schrieb:> Anbei mal der gesamt Code des Projektes.
tools.[ch] würde ich auseinander nehmen und in separaten Modulen für
EEPROM-Zugriffe, RTC, RF, und BMP180 zerlegen. Auch wenn die einzelne
Modulen dann nur 1 oder 2 Funktionen haben werden, es sind halt komplett
verschiedene und von einander unabhängige Themen und sollen also auch
separat behandelt (= implementiert) werden.
Eric B. schrieb:> Nachtrag: Module mit der Name "tools" o.Ä. sind mir immer verdächtig ;-)
Ich habe auch noch "misc.c" im Angebot.
Nee, mal die Kirche im Dorf lassen, das schon genug Dateien und für 1
Funktion, nee....
Christian J. schrieb:> Nee, mal die Kirche im Dorf lassen, das schon genug Dateien und für 1> Funktion, nee....seufz Ich schrieb doch schon:
> Auch wenn die einzelne> Modulen dann nur 1 oder 2 Funktionen haben werden, es sind halt komplett> verschiedene und von einander unabhängige Themen und sollen also auch> separat behandelt (= implementiert) werden.
Ausserdem hast du schon ein Modul das eeprom.[ch] heisst. Warum dann
nicht die ein oder zwei EEPROM-Funktionen aus tools.c da reinflissen
lassen? (Ohne jetzt den Inhalt von eeprom.[ch] gesehen zu haben...
Hallo,
ich frickel schon wieder um, sieht aber schon sehr ordentlich aus.
Nochmal ne Frage, auch wenn ich keinen widerverwendbaren Code brauche.
Ist es usus, dass jede Funktion nur die Parameter kriegt, die sie auch
braucht? Ich übergebeb derzeit oft noch einen ganzen Struct wo alles
drin ist und habe dadurch weniger Code.
Würde ich zb einen Bargraphen mal einzeln programmieren und müsste dem
Parameter übergeben sind das folgende. Die zieht er sich natürlich
derzeit alle aus defines raus und dem Work Struct.
Parameter: X0 Position,
Y0 Position,
Höhe Graph,
linke Begrenzung Skala
rechte Begrenzung Skala
Temperaturwert,
Toleranzfeld links
Toleranzfeld rechts,
Beschriftung
Vorteil wäre, dass der Code wiederverwendbar wäre, ich könnte mehrere
Bargraphen zeichnen, einen für Druck, Feuchte, Temperatur und sie hätten
alle das gleiche Interface aber jeder eine Funktion __Handler drüber,
der sie mit Parametern füttert, Umschalten übernimmt usw. Die
Verschachtelungstiefe nimmt dann erheblich zu.
Mist, als Gast drin.... also drunter nochwas:
Gibt es eine Struktur mit der man bestimmten Ebenen in der Namensgebung
der C Dateien kennzeichnen kann?
Also
Anwendung
Protokoll und Verpackung
Low Level Bittreiber
zb besteht eeprom.c bei mir aus Basisroutinen, die Bits schubsen und die
Hardware bedienen, darüber dann Byte und String Befehle (read, write,
open, close) und darüber liegt dann zb eine Backupschicht, wo Prüfsummen
berechnet werden, Daten abgelegt, eine Zeigerkette aus den Datensatz
erzeugt wird usw.
Christian J. schrieb:> Nochmal ne Frage, auch wenn ich keinen widerverwendbaren Code brauche.>> Ist es usus, dass jede Funktion nur die Parameter kriegt, die sie auch> braucht?
Also erstens du brauchst in jedem Falle wiederverwendbaren Code -
möglicherweise NICHT auf dem Papier oder in der Quelldatei, dafür aber
in jedem Falle in deinem Kopf in Form von wiederverwendbaren Strategien.
Da hilft es ungemein, seine Projekte aufzuteilen und sowas wie
Hardware-Treiber (beliebtestes Beispiel: seriell) mit vereinheitlichter
Schnittstelle zum restlichen Programm zu schreiben - bis hin zu einer
einzigen Headerdatei für den jeweiligen Treiber, die du dann für alle
späteren Plattformen benutzt - unabhängig, wie der Treiber von innen
aussieht. Später wirst du merken, daß sich das lohnt.
Zu deinem zweiten Problem mit dem Bargraph oder so muß man ganz klar
sagen, daß genau dieses eigentlich nach objektorientierter
Programmierung schreit. In C gibt es das nicht, aber man kann es
nachbilden, indem man sich einen struct Typ baut, der alles abdeckt. Die
zugehörigen Methoden muß man dann eben durch ein in allen Objekten
gleiches Argument nachbilden.
z.B:
void Draw(mytyp* self, weiteres Zeug...);
so daß man dann etwa so das Ganze benutzen kann:
for all in my bunch { current.Draw(current, blabla); next member;}
W.S.
Christian J. schrieb:> Ist es usus, dass jede Funktion nur die Parameter kriegt, die sie auch> braucht? Ich übergebeb derzeit oft noch einen ganzen Struct wo alles> drin ist und habe dadurch weniger Code.>> Würde ich zb einen Bargraphen mal einzeln programmieren und müsste dem> Parameter übergeben sind das folgende. Die zieht er sich natürlich> derzeit alle aus defines raus und dem Work Struct.>> Parameter: X0 Position,> Y0 Position,> Höhe Graph,> linke Begrenzung Skala> rechte Begrenzung Skala> Temperaturwert,> Toleranzfeld links> Toleranzfeld rechts,> Beschriftung
Diese ganzen Informationen kannst Du in einem Struct zusammenfassen.
Eine Instanz dieser Struktur entspricht dann einem Bargraph. Jede
Funktion, die etwas an dem Bargraph macht, bekommt einen Zeiger auf die
Instanz übergeben.
Das ist der objektorientiere Ansatz. Auf die Struktur darf nur von
Bargraph-Funktionen zugegriffen werden. Alle dazugehörigen Funktionen
kommen in bargraph.c und bargraph.h.
In dem Beispiel habe ich noch einen Zeiger auf ein Display-Objekt
eingefügt, auf dem der Bargraph gezeichnet werden soll. Der Code des
Aufrufers könnte dann z.B. so aussehen:
1
structDisplaymyDisplay;
2
structBargraphmyBargraph;
3
4
DisplayInit(&myDisplay,...);
5
BargraphInit(&myBargraph,&myDisplay);
6
BargraphSetPosition(&myBargraph,32,32,128,24);
7
BargraphSetLabel(&myBargraph,"Temperatur");
8
BargraphSetValue(&myBargraph,23);
9
BargraphDraw(&myBargraph);
Auf die Weise bekommst Du wiederverwendbare Bausteine, die Du im
nächsten Projekt auf andere Weise zusammenstöpseln kannst. Und ganz
nebenbei wird der Code übersichtlicher, wenn man weiß, dass auf ein
Bargraph-Struct nur in Bargraph-Funktionen zugegriffen wird und nicht
sonstwo im Projekt.
Das erfordert in C natürlich Disziplin, weil der Compiler einen nicht
davon abhält, von anderswo in die Bargraph-Struktur reinzugreifen. In
C++ hat man dafür private-Member. Außerdem wird in C++ der Zeiger auf
ein Objekt implizit an die Memberfunktionen übergeben, so dass man ihn
nicht jedes Mal hinschreiben muss. Praktisch passiert aber genau das
gleiche.
Ach ja, Du kannst auf die Weise natürlich auch problemlos mehrere
Instanzen anlegen:
1
structDisplaymyDisplay;
2
structBargraphtempBg;
3
structBargraphpressureBg;
4
structBargraphhumidityBg;
5
6
DisplayInit(&myDisplay,...);
7
BargraphInit(&tempBg,&myDisplay);
8
BargraphInit(&pressureBg,&myDisplay);
9
BargraphInit(&humidityBg,&myDisplay);
10
11
BargraphSetPosition(&tempBg,32,32,128,24);
12
BargraphSetPosition(&pressureBg,32,64,128,24);
13
BargraphSetPosition(&humidityBg,32,96,128,24);
14
15
BargraphSetLabel(&tempBg,"Temperatur");
16
BargraphSetLabel(&pressureBg,"Druck");
17
BargraphSetLabel(&humidityBg,"Feuchtigkeit");
18
19
[...]
Auf die Bargraph-Objekte kann dann auch ruhig von unterschiedlichen
Stellen im Programm zugegriffen werden. An einer Stelle werden mit
BargraphSetValue neue Werte eingetragen, an einer anderen Stelle wird
regelmäßig BargraphDraw für alle Objekte aufgerufen.
Diese Bargraph-Objekte kannst Du in einem kleineren Projekt auch ruhig
global zugänglich machen. In einem größeren Projekt wärs allerdings
sinnvoll, diese Objekte wieder in Objekten zu kapseln, zum Beispiel das
Display mit allen Bargraph- und anderen GUI-Objekten in einem
WeatherStationGui-Objekt.
Hans schrieb:> void BargraphSetValue(Bargraph* bg, int value)> {> bg->value = value;> }
Hans, ich bin dabei das alles mal zu verbessern. Solche Konstrukte wie
oben werden aber doch inline optmiert? Ich schreibe ja jetzt lentendlich
an der Maschine vorbei für die eigene Übersicht, was für mich schon was
Neues ist, da ich bisher Laufzeit und Größe als die Kriterien betrachtet
habe, was allerdings bei 1MB Flash und 168 Mio Befehlen/s letzlich auch
hinfällig zu sein scheint....
Das hängt vom Compiler ab und wie Du es hinschreibst. Normalerweise
übersetzt der Compiler jede C-Datei inkl. der Header-Files, die sie
inkludiert (= "Übersetzungseinheit"), für sich. Wenn Du BargraphSetValue
also in bargraph.c implementierst und von main.c aus aufrufst, wird es
standardmäßig nicht optimiert.
Aktuelle GCC-Versionen haben das Feature "Link Time Optimization" (LTO),
damit werden auch Aufrufe über verschiedene Übersetzungseinheiten hinweg
optimiert. Das Feature muss man aber explizit aktivieren, sowohl beim
Compiler als auch Linker.
Eine andere Möglichkeit ist, die Funktion nicht in bargraph.c zu
implementieren, sondern in bargraph.h und "static inline" davor zu
schreiben. Dann wird sie ein Teil jeder Übersetzungseinheit, die
bargraph.h inkludiert, und kann geinlint werden. Das solltest Du aber
nur mit solchen kleinen Getter- und Setter-Funktionen machen, nicht mit
größeren Funktionen. Denn wenn der Compiler sie nicht inlint, werden sie
in jeder C-Datei dupliziert. Damit braucht das Gesamtprogramm mehr
Speicher.
Hans schrieb:> Aktuelle GCC-Versionen haben das Feature "Link Time Optimization" (LTO),> damit werden auch Aufrufe über verschiedene Übersetzungseinheiten hinweg> optimiert. Das Feature muss man aber explizit aktivieren, sowohl beim> Compiler als auch Linker.
Hallo Hans,
diese LTO führt bei mir regelmässig zu "Hard Fault" Errors. Obwohl sie
den Code wesentlich verkleinert, fast 10kb auf 75kb. Muss man da noch
etwas bei den eingebundenen Libs beachten?
Zu den Bargraphen. Ich schreibe gerad eine neue Routine, die eine
Balkenhinstorie darstellen soll. Es sollen mehrere Instanzen möglich
sein, oauch ohne C++.
D.h. ich habe einen array of struct an Messwerten und möchte frei
scalierbar zb die Werte 40 ... 90 als Auszug darstellen. Oder 0....150.
D.h. es soll eine Lupe auf den Struct gelegt werden und die Werte werden
in einem x/y Koordinatensystem dargestellt. Breite der Balken, Anzahl,
Höhe usw. werden dynamisch berechnet.
Du hast die Möglichkeit angesprochen einen Struct zu definieren, der
alle Eckdaten enthält. Ist das so üblich? Beim stm32 arbeitet die
StdPeriphLib ja so. Ich würde das jetzt so angehen, dass ich Eckdaten
übergebe und aus diesen Eckdaten dynamisch alle anderen Positionen wie
Beschriftung, Grösse der Löschfelder für vorherige Beschriftung usw.
berechne.
Ein Thema ist sicherlich noch der Bezug. Mein bisheriger Graph anthält
zb noch einen Punkt über dem aktuellen Wert, er hat eine Mittelinie des
Mittelwertes und eine Steigungsgerade, so wie Beschriftungen die
mitwandern. Dabei entstehen auch sog. Bezugsketten, ideal wäre es
sicherlich, wenn sich alles auf den Nullpunkt beziehen lassen würde aber
das ist nicht so einfach.
Das Display hat nur eine Page, d.h. Umschaltung und Hintergrund Aufbau
der nächsten gehen nicht. Um Flackern zu vermeiden werden nur
Differenzen geändert.
Hast da mal einen Tip für mich wie man so etwas aufbaut? Nicht dass ich
mich verrenne und alles wieder ändern muss.
Grusss,
Christian
Christian J. schrieb:> diese LTO führt bei mir regelmässig zu "Hard Fault" Errors. Obwohl sie> den Code wesentlich verkleinert, fast 10kb auf 75kb. Muss man da noch> etwas bei den eingebundenen Libs beachten?
Wie schon gesagt, das sind mit 99% Sicherheit Fehler in Deinem Code, die
ohne die Optimierung nur nicht in Erscheinung treten. Einen Hard Fault
kann man aber immerhin recht einfach debuggen.
> Zu den Bargraphen. Ich schreibe gerad eine neue Routine, die eine> Balkenhinstorie darstellen soll. Es sollen mehrere Instanzen möglich> sein, oauch ohne C++.>> D.h. ich habe einen array of struct an Messwerten und möchte frei> scalierbar zb die Werte 40 ... 90 als Auszug darstellen. Oder 0....150.> D.h. es soll eine Lupe auf den Struct gelegt werden und die Werte werden> in einem x/y Koordinatensystem dargestellt. Breite der Balken, Anzahl,> Höhe usw. werden dynamisch berechnet.>> Du hast die Möglichkeit angesprochen einen Struct zu definieren, der> alle Eckdaten enthält. Ist das so üblich? Beim stm32 arbeitet die> StdPeriphLib ja so. Ich würde das jetzt so angehen, dass ich Eckdaten> übergebe und aus diesen Eckdaten dynamisch alle anderen Positionen wie> Beschriftung, Grösse der Löschfelder für vorherige Beschriftung usw.> berechne.
Alles, was Du an Daten speichern musst und für eine Instanz gilt, sollte
in einer Struktur stehen. Jede Instanz der Struktur entspricht einer
Instanz des Diagramms.
Werte, die Du dynamisch aus anderen berechnen kannst, musst Du natürlich
nicht redundant in der Struktur speichern. Manchmal ist es eine Abwägung
zwischen Geschwindigkeit und Speicherverbrauch, ob man bestimmte Werte
zwischenspeichert. Dinge wie Positionen, Größe etc. sind aber ja kein
nennenswerter Rechenaufwand. Wenn Du die Werte an mehreren Stellen
brauchst, dann schreib Dir kleine Funktionen, die sie berechnen.
In dem Fall würde ich einen Zeiger auf die Messwerte sowie den Start-
und Endindex (z.B. 40 und 90) in der Struktur zu speichern. Außerdem wie
bei allen GUI-Elementen die Position auf dem Display, Größe, etc.
Mal grob als Anregung:
> Ein Thema ist sicherlich noch der Bezug. Mein bisheriger Graph anthält> zb noch einen Punkt über dem aktuellen Wert, er hat eine Mittelinie des> Mittelwertes und eine Steigungsgerade, so wie Beschriftungen die> mitwandern. Dabei entstehen auch sog. Bezugsketten, ideal wäre es> sicherlich, wenn sich alles auf den Nullpunkt beziehen lassen würde aber> das ist nicht so einfach.>> Das Display hat nur eine Page, d.h. Umschaltung und Hintergrund Aufbau> der nächsten gehen nicht. Um Flackern zu vermeiden werden nur> Differenzen geändert.
Das macht den Code in BarHistoryDraw natürlich komplizierter. Du musst
ja dann bei jedem Balken wissen, ob Du ihn gegenüber dem letzten Aufruf
vergrößern oder verkleinern musst und entsprechend einen vollen Balken
oder einen "Löschenbalken" zeichnen. Dafür brauchst Du eine Kopie der
vorherigen Daten. Oder Du sparst Speicher und merkst Dir in einem
Bitfeld nur, ob der Wert größer oder kleiner war.
Noch komplizierter wirds, wenn sich die Skalierung ändert. Aber da würde
ich persönlich das Flackern in Kauf nehmen und das Bild neu zeichnen. Ob
das Bild überhaupt neu gezeichnet werden muss, kannst Du Dir auch in
einer "dirty" Variable merken, die bei Änderungen gesetzt wird und beim
Zeichnen des Bilds zurückgesetzt.
Das alles ändert aber nichts an der grundlegenden Struktur. Wenn Du
zusätzliche Variablen brauchst, die sich auf die Instanz des
GUI-Elements beziehen, kommen sie in die struct BarHistory. Andere Daten
bekommen die Funktionen, die sie brauchen, vom Aufrufer übergeben.
@Hans:
Danke Dir erstmal, glaube Du sprichst sicher "fliessend C" :-)
Setze das grad um, 4h geschlafen, morgen frei, nachts denkt es sich am
Besten....
PS: 1 x Flackern pro Minute fällt kaum auf bei einem
Barometer/Thermometer, da reicht es auch alle 5 Minuten zu updaten.



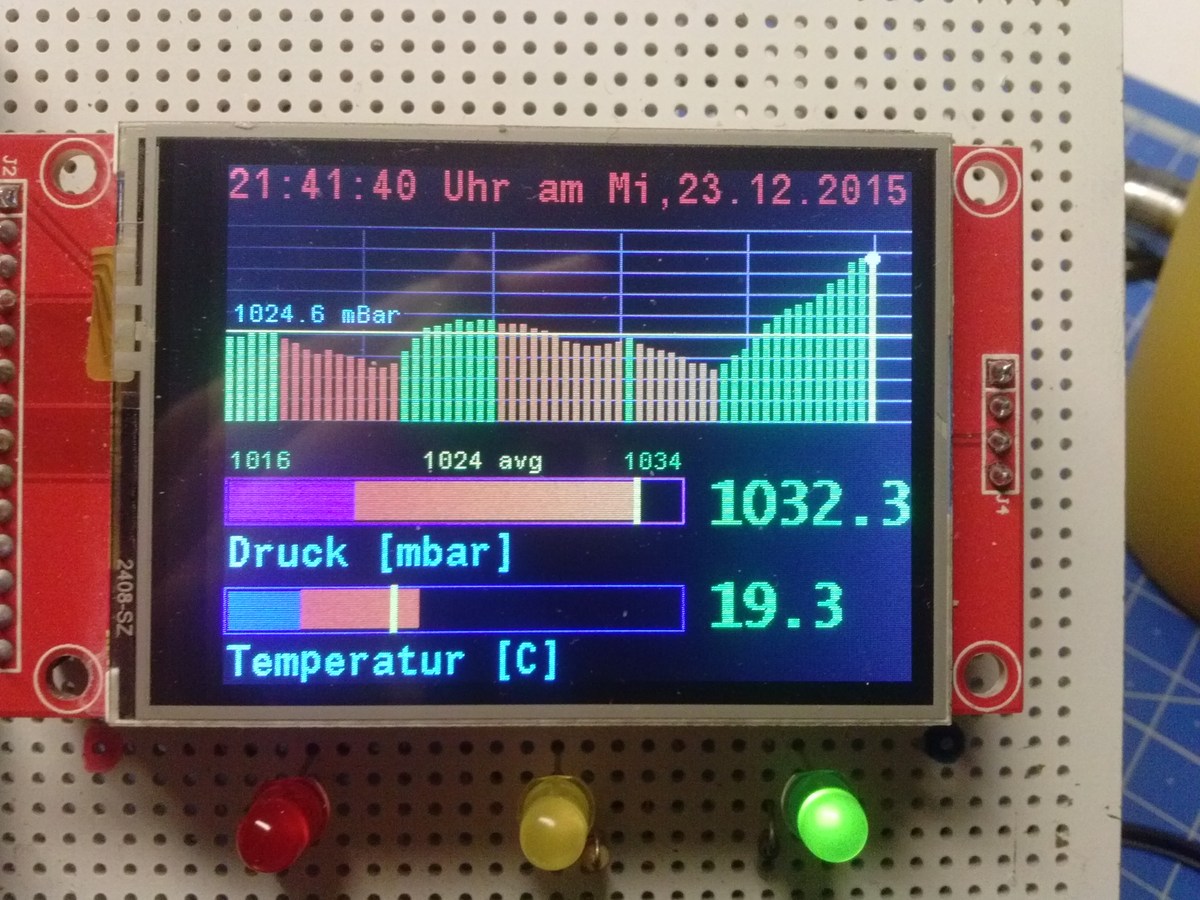
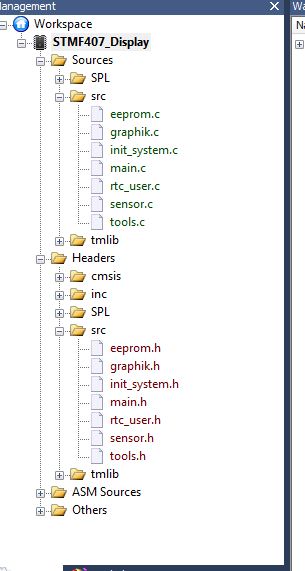{kind=link}