Hallo zusammen Ich suche einen Algorithmus, der auf einer zweidimensionalen Karte die zwei Punkte findet, die am weitesten voneinander entfernt sind. Ich möchte ungern zwischen allen Punkten den kürzesten Weg bestimmen, um dann den längsten Weg auszuwählen. Auch können die Koordinaten der beiden Punkte sehr nah beieinander liegen, aber der Weg dazwischen kann trotzdem sehr lang sein. Mir fehlt einfach der Ansatz, um dieses Problem lösen zu können. Die Karte kann als zweidimensionales Array angesehen werden und hat eine Grösse von maximal 1000 * 1000 Felder. Die einzelnen Felder sind durch begehbar und nicht begehbar unterscheidbar. Diagonale Schritte sind zulässig und dauern gleich lange wie horizontale oder vertikale. Kennt jemand einen Algorithmus, der dieses Problem ohne brute force lösen kann oder nach N Schritten ein brauchbares Ergebnis liefert? Um das Wort "brauchbar" in eine Zahl zu fassen: Von insgesamt 100 Wegen sollen maximal 20 länger als der gefundene sein.
Welche Entfernung soll ermittelt werden wenn Start- oder Zielfeld nicxht begehbar ist? Wie stellst du sicher, daß es einen Weg von Start zu Ziel gibt?
Danke für die Antworten. Rene K. schrieb: > https://de.wikipedia.org/wiki/Pathfinding Den Artikel hab ich gelesen, weiss aber noch nicht, was er mir nützen soll. Den kürzesten Weg zwischen zwei Punkten zu finden, ist für mich nicht das Problem. Aber der längste kürzeste Weg schon, da Start- und Zielpunkt unbekannt sind. Andy P. schrieb: > Welche Entfernung soll ermittelt werden wenn Start- oder Zielfeld nicxht > begehbar ist? Da Start- und Zielpunkt das Resultat des Algorithmus sein sollen, werden diese sicher begehbar sein. Andy P. schrieb: > Wie stellst du sicher, daß es einen Weg von Start zu Ziel gibt? Die Karten werden zufällig generiert, dazu werden verschiedene Verfahren genutzt. Es gibt also verschiedene "Arten" von Karten. Einige werden anhand eines Weges erzeugt, dort ist der längste Weg bereits bekannt, bevor die Karte überhaupt existiert. Bei anderen wird Position und Länge der Wände so am Raster ausgerichtet, dass unzugängliche Bereiche gar nicht entstehen können. Andere werden nach dem Erzeugen mit flood fill getestet, ist der grösste begehbare Bereich < X%, wird die Karte verworfen, ansonsten die unzugänglichen Bereiche aufgefüllt. Blechtroll schrieb: > Standardansaetze sind zB Backtracking. Das schau ich mir mal an. Im Anhang ist eine Beispielkarte. Der längste Weg beginnt oben links und endet unten rechts. Nur wie finde ich diesen Weg einigermassen effizient?
Der laengste Weg... wird eine Schlange sein, bei welcher jede begehbare Kachel begangen wurde.
Dein Problem mit der 2D-karte lässt sich evtl. auf Graphen übertragen (reguläres Gitter). In der Algorithmentechnik gibt's viele Optimierungsalgos, z.B. um den kürzesten Pfad zwischen allen "Punkten" eines Graphne zu finden (Algorithmus von Floyd und Warshall). Probier doch einfach mal aus, was der Algo macht, wenn du MIN durch MAX ersetzt.
Ich denke er sucht schon den kürzesten Weg zwischen zwei Punkten aber dann eben den längsten für alle Paare von Start/Endpunkt. Ich glaub effizienter als mit dem passenden Algo (https://en.wikipedia.org/wiki/Shortest_path_problem#All-pairs_shortest_paths) alle möglichen kürzeste Pfade zu berechnen wirds wohl nicht.
Be S. schrieb: > Den Artikel hab ich gelesen, Den auch? https://en.wikipedia.org/wiki/Longest_path_problem >weiss aber noch nicht, was er mir nützen soll. Ich auch nicht.
Sebastian V. schrieb: > Ich denke er sucht schon den kürzesten Weg zwischen zwei Punkten aber > dann eben den längsten für alle Paare von Start/Endpunkt. Genau so ist es. Sebastian V. schrieb: > Ich glaub effizienter als mit dem passenden Algo > (https://en.wikipedia.org/wiki/Shortest_path_problem#All-pairs_shortest_paths) > alle möglichen kürzeste Pfade zu berechnen wirds wohl nicht. Hm, sowas hab ich befürchtet. Da nicht die optimale Lösung gefunden werden muss, könnte man das sicher noch etwas optimieren. z.B. nur jeden dritten Punkt abklappern und den Rest ignorieren oder dem Weg eine bestimmte Breite geben, und alles was auf diesem Weg liegt zukünftig ignorieren (warum die Strecke von A nach B prüfen, wenn diese bereits auf dem Weg von C nach D liegt?). Sigi schrieb: > z.B. um den kürzesten Pfad zwischen allen "Punkten" eines > Graphne zu finden (Algorithmus von Floyd und Warshall). > Probier doch einfach mal aus, was der Algo macht, wenn > du MIN durch MAX ersetzt. Dazu müsste ich zuerst den Algorithmus implementieren. Werde ich in den nächsten Tagen mal versuchen, wenn ich bis dann keine vernünftige Lösung gefunden habe. Stefan Salewski schrieb: > Den auch? > > https://en.wikipedia.org/wiki/Longest_path_problem Nein, den kannte ich noch nicht. Das werde ich mir mal durchlesen.
Be S. schrieb: > Sebastian V. schrieb: >> Ich denke er sucht schon den kürzesten Weg zwischen zwei Punkten aber >> dann eben den längsten für alle Paare von Start/Endpunkt. > > Genau so ist es. Ich hab jetzt auch rausgefunden wie der Fachbegriff dafür lautet: Durchmesser Unter "sparse graph diameter" findet man per Google mehrere Algorithmen. Keine Ahnung ob du dir einen davon antun willst. Wenn es nicht exakt sein muss reicht dir vielleicht auch der "pseudo diameter". Man startet mit einem beliebigen Punkt und findet dann alle kürzesten Pfade mit diesem Startpunkt (Dijkstra-Algorithmus). Dann nimmt man den am weitesten entfernten Knoten als neuen Startpunkt und wiederholt das ganze bis der längste Pfad nicht mehr länger wird. Gefühlt düfte das nach recht wenig Schritten passieren.
Sebastian V. schrieb: > Ich hab jetzt auch rausgefunden wie der Fachbegriff dafür lautet: > Durchmesser Danke, gut zu wissen. Sebastian V. schrieb: > Unter "sparse graph diameter" findet man per Google mehrere Algorithmen. > Keine Ahnung ob du dir einen davon antun willst. Dafür ist es heute zu spät. Das schau ich mir morgen an. Sebastian V. schrieb: > Wenn es nicht exakt > sein muss reicht dir vielleicht auch der "pseudo diameter". Man startet > mit einem beliebigen Punkt und findet dann alle kürzesten Pfade mit > diesem Startpunkt (Dijkstra-Algorithmus). Dann nimmt man den am > weitesten entfernten Knoten als neuen Startpunkt und wiederholt das > ganze bis der längste Pfad nicht mehr länger wird. Gefühlt düfte das > nach recht wenig Schritten passieren. Klingt nach überschaubarem Aufwand für einen ersten Versuch. Werde das in den nächsten Tagen mal testen und hier berichten. Und wenn der Algorithmus nicht den längsten aber immerhin einen langen Weg findet, bin ich fürs Erste schon mal zufrieden. Ich danke allen für die Hilfe und gute Nacht!
Der Dijkstra-Algorithmus liefert ganz gute Ergebnisse. Mit einer 120 * 1000 Karte liefert er in 2 bis 5 Durchläufen ein Ergebnis. Der Startpunkt wurde jeweils zufällig gewählt. Das Resultat ist nicht immer identisch, aber ein Resultat wird am häufigsten erzielt (10000 Versuche auf der gleichen Karte): Edit: Der Algorithmus wird abgebrochen, sobald er den vorherigen Startpunkt liefert (Start => Ende => Start). Er wird also in jedem Fall mindestens zweimal durchlaufen. Anzahl Durchläufe: 2 : 196 3 : 4091 4 : 4815 5 : 898 Start- und Endpunkt (können auch vertauscht sein): ( 19/998) (102/317) : 9940 ( 19/998) (109/495) : 1 ( 19/998) ( 86/448) : 1 ( 19/998) ( 99/347) : 2 ( 19/998) (113/496) : 3 ( 19/998) (112/413) : 3 ( 19/998) ( 91/448) : 1 ( 19/998) (104/334) : 2 ( 19/998) ( 90/504) : 1 ( 19/998) ( 93/324) : 1 ( 19/998) ( 87/475) : 1 ( 19/998) ( 34/ 1) : 6 ( 19/998) ( 99/332) : 2 ( 19/998) (107/362) : 1 ( 19/998) ( 96/404) : 1 ( 34/ 1) ( 92/663) : 1 ( 19/998) (104/442) : 2 ( 19/998) (106/490) : 3 ( 19/998) (109/419) : 1 ( 19/998) (107/481) : 2 ( 19/998) ( 90/330) : 1 ( 19/998) ( 86/474) : 1 ( 19/998) (115/498) : 1 ( 19/998) (110/493) : 3 ( 19/998) (102/337) : 1 ( 34/ 1) ( 98/618) : 2 ( 19/998) (109/431) : 1 ( 19/998) ( 90/321) : 2 ( 19/998) ( 90/326) : 1 ( 19/998) (109/406) : 1 ( 19/998) (106/444) : 3 ( 19/998) ( 94/399) : 1 ( 19/998) (112/508) : 1 ( 19/998) ( 99/410) : 1 ( 19/998) ( 92/445) : 1 ( 19/998) (108/452) : 1 ( 19/998) (107/341) : 1 ( 19/998) ( 95/402) : 1 ( 19/998) (109/373) : 1 Die Karte ist im Anhang, der Nullpunkt ist oben links. Ich habe Start- und Zielpunkt des regulären Falls mit X markiert (Ctrl-F ist dein Freund). Für die, die es interessiert, habe ich noch die Dijkstra-Karte als csv hochgeladen. Andere Karten werde ich in den nächsten Tagen auch noch testen, mal sehen, wann ich dazu kommen werde. Nachtrag (was mir erst nach dem 2. Kaffee aufgefallen ist): Mein Algorithmus liefert nur die erste Koordinate mit dem höchsten Dijkstra-Wert zurück (linear gesucht, beginnend mit (0/0), zuerst x erhöht). Das Ergebnis würde evtl. anders aussehen, wenn anders nach dem höchsten Wert gesucht wurde. Werde den Algorithmus bei Gelegenheit so umbauen, dass er einen Vektor mit allen Koordinaten, die den höchsten Wert haben, ausspuckt. Wird aber noch eine Weile dauern, da gerade keine Zeit.
Be S. schrieb: > Ich suche einen Algorithmus, der auf einer zweidimensionalen Karte die > zwei Punkte findet, die am weitesten voneinander entfernt sind. Das ist interessant. Und mit "Graph Diameter" auch gleich wieder was gelernt. Wenn man da die Distanz für jedes Knotenpaar berechnet, wird das ganz schön aufwendig. :-) Um die Suchmenge einzugrenzen, könnte man möglicherweise Knoten zu Knotenmengen (Sets) zusammen fassen und so die Anzahl "N" reduzieren. Auf die Sets (die einen neuen Graph bilden) werden dann die kürzesten Pfade berechnet. Bsp.: Jeder Set enthält seine Knoten + die Links zu den benachbarten Sets + den Durchmesser des Sets. Anfangs bildet jeder Knoten einen Set. Die Anzahl der Sets wird iterativ verringert. Dazu wird für jedes Paar von benachbarten Sets der gemeinsame Durchmesser berechnet. Das Paar mit den geringsten gemeinsamen Durchmesser wird zu einen neuen Set zusammengefasst. Bringt erstmal nicht die optimale Lösung. Auch das ungleichmäßige Anwachsen der Sets könnte ein Problem darstellen. Trotzdem, vielleicht einen Versuch wert.
Mikro 7. schrieb: > Um die Suchmenge einzugrenzen, könnte man möglicherweise Knoten zu > Knotenmengen (Sets) zusammen fassen und so die Anzahl "N" reduzieren. > Auf die Sets (die einen neuen Graph bilden) werden dann die kürzesten > Pfade berechnet. Das hab ich mit auch schon überlegt. Wenn man vier Kacheln zu einem Quadrat zusammenfasst, reduziert sich die Anzahl Knoten bereits um Faktor 4. Bei grösseren Sets muss man prüfen, ob das Set durchgängig verbunden ist oder eine Wand mitten durch führt. Ich kann mir vorstellen, dass da der angebliche Geschwindigkeitszuwachs ganz schnell wieder flöten geht. Momentan habe ich keine Performanceprobleme, die obigen 10000 Durchläufe (der Dijkstra-Algorithmus wurde 36415 Mal durchlaufen) waren in 45min durch, macht ca. 75ms pro Aufruf des Algorithmus. Und ich hab das Ding einfach irgendwie zusammengehackt (Knoten werden on the fly dynamisch allokiert und sonstige ineffiziente Spässe). Mikro 7. schrieb: > Die Anzahl der Sets wird iterativ verringert. Dazu wird für jedes Paar > von benachbarten Sets der gemeinsame Durchmesser berechnet. Das Paar mit > den geringsten gemeinsamen Durchmesser wird zu einen neuen Set > zusammengefasst. Die Sets dürfen aber nicht zu gross werden, im Extremfall hat man wieder nur ein Set, man ist also gleich weit wie zu Beginn.
Zu deinen Ergebnissen würde mich ja noch interessieren wie lang die verschiedenen Lösungen sind die dort gefunden werden. Ich habe gestern vorm einschlafen noch überlegt wieso der pseudo diameter nicht den echten diameter liefert aber mir ist auf anhieb kein gutes Gegenbeispiel eingefallen. Offensichtlich scheint er aber nicht immer den längsten Weg zu finden. Edit: Lässt du auch diagonale Schritte zu? Ansonsten sieht die Dijkstra-Map irgendwie falsch aus.
ich hab die Fragestellung immer noch nicht verstanden soll das so lauten: a) das Ergebnis ist der Kürzeste! Pfad zwischen 2 Punkten b) das Ergebnis sind die 2 Punkte die bei a) das größte Ergebnis liefern mit BF muss man also jeden begehbaren Punkt (als Start) mit jedem begehbarem Punkt (als Ziel) prüfen mein Taschenrechner kann das gar nicht anzeigen, soviele Möglichkeiten gibt es.. und dann kommt ja noch dazu , dass die Berechnung a) schon (sehr) aufwändig ist..
Be S. schrieb: > Das hab ich mit auch schon überlegt. Wenn man vier Kacheln zu einem > Quadrat zusammenfasst, reduziert sich die Anzahl Knoten bereits um > Faktor 4. Bei grösseren Sets muss man prüfen, ob das Set durchgängig > verbunden ist oder eine Wand mitten durch führt. Ich kann mir > vorstellen, dass da der angebliche Geschwindigkeitszuwachs ganz schnell > wieder flöten geht. Das wäre ein räumlicher Ansatz. Wenn ich es aber richtig verstanden habe, dann ist die Nachbarschaft nicht unbedingt durch den räumlichen Zusammenhang gegeben. Ich würde daher die "Karte" in einen bidirektionalen ungewichteten Graphen transformieren (als generische Datenstruktur). > Die Sets dürfen aber nicht zu gross werden, im Extremfall hat man wieder > nur ein Set, man ist also gleich weit wie zu Beginn. Ja und nein. Optimal (!) wäre ein Strategie wo die Sets zusammenwachsen bis nur ein Set übrig bleibt. Jeder Set enthält ja seinen Durchmesser: Mit dem finalen Set hätte man dann den gesuchten Durchmesser. Die Vorgehensweise ist sinnvoll, wenn man ein (schnelles) Verfahren hat, mit dem man aus den (bereits berechneten) Durchmesser zweier Sets den (neuen) gemeinsamen Durchmesser beider Sets berechnen kann. (Divide and Conquer Ansatz). Ich könnte mir allerdings auch vorstellen, dass es einige Abwandlungen des Ansatzes gibt, falls ein effizienter Merge von Sets nicht möglich ist. Das war der Ausgangspunkt für mein obiges Posting, da ich die (effiziente) Umsetzung des Divide and Conquer auf Anhieb nicht sehe. Wenn du aber schon eine Lösung hast, ist das alles Spielerei. ;-)
Definiere mal "Entfernung: a) Entfernung als Anzahl der Schritte in einem Raster oder b) Entfernung in der Gaußchen Ebene (mit Pythagoras) Lösungsansatz: bewerte zuerst jeden Punkt mit dem Abstandsbetrag der x-Koordinaten und sortiere diese 1. Liste (max. Abstand an 1. Stelle) dann bewerte jeden Punkt mit dem Abstandsbetrag der y-Koordinaten und sortiere diese 2. Liste (max. Abstand an 1. Stelle) Danach Abstandswerte zum Bezugspunkt nach a) oder b) für die Elemente aus Liste 1 und dann aus Liste 2 ausrechnen. Nicht für alle Elemente! Abbruchkriterium ist jeweils ein Abstand welcher kleiner ist als der größte Abstandsbetrag aus der jeweiligen Liste. Es gibt viele Sortierverfahren, welche entscheidend zur Gesamtrechenzeit beitragen.
>Lösungsansatz: >bewerte zuerst jeden Punkt mit dem Abstandsbetrag der x-Koordinaten >und sortiere diese 1. Liste (max. Abstand an 1. Stelle) >dann bewerte jeden Punkt mit dem Abstandsbetrag der y-Koordinaten >und sortiere diese 2. Liste (max. Abstand an 1. Stelle) im einfachsten Fall ist die Karte ein "V" Start und Ziel hätten die Selbe Y Koordinate.. (y Abstand = 0) ich glaub nicht, dass deine Sortierung irgendwie hilft..
Vielen Dank für die regen Antworten! Sebastian V. schrieb: > Zu deinen Ergebnissen würde mich ja noch interessieren wie lang die > verschiedenen Lösungen sind die dort gefunden werden. Werde ich das nächste Mal beifügen, ich habe den Code gerade nicht dabei. Edit: Werde auch noch hinzufügen, welche Lösung wie viele Durchläufe benötigt hat. Dass einige Male nur zwei Durchläufe zum Ziel geführt haben (also die Lösung auf Anhieb gefunden wurde), macht mich etwas misstrauisch. Sebastian V. schrieb: > Edit: Lässt du auch diagonale Schritte zu? Ansonsten sieht die > Dijkstra-Map irgendwie falsch aus. Ja, diagonale Schritte sind erlaubt. Musste aber auch dreimal hinsehen, um zu prüfen, ob die Karte wirklich stimmt. Sieht auf Anhieb ziemlich falsch aus. lrlr schrieb: > ich hab die Fragestellung immer noch nicht verstanden > > soll das so lauten: > a) das Ergebnis ist der Kürzeste! Pfad zwischen 2 Punkten > b) das Ergebnis sind die 2 Punkte die bei a) das größte Ergebnis liefern Genau so. Als wollte man eine möglichst lange Strecke wandern, ohne Umwege zu gehen. lrlr schrieb: > mit BF muss man also jeden begehbaren Punkt (als Start) mit jedem > begehbarem Punkt (als Ziel) prüfen > > mein Taschenrechner kann das gar nicht anzeigen, soviele Möglichkeiten > gibt es.. Genau deswegen will ich Brute Force vermeiden, so sehr, dass ich es gar nicht erst versucht habe. Mikro 7. schrieb: > Optimal (!) wäre ein Strategie wo die Sets zusammenwachsen bis nur ein > Set übrig bleibt. > > Jeder Set enthält ja seinen Durchmesser: Mit dem finalen Set hätte man > dann den gesuchten Durchmesser. Die Vorgehensweise ist sinnvoll, wenn > man ein (schnelles) Verfahren hat, mit dem man aus den (bereits > berechneten) Durchmesser zweier Sets den (neuen) gemeinsamen Durchmesser > beider Sets berechnen kann. (Divide and Conquer Ansatz). Ach so, dann hab ich dich falsch verstanden. Wäre natürlich möglich, aber ich sehe auf Anhieb gerade keine Möglichkeit, wie man dies konkret umsetzen könnte. Wenn ich das mit dem Durchmesser richtig verstanden habe, berechnet Dijkstra den Durchmesser, einfach nur von einem Punkt aus. Möchte man den Durchmesser von einem anderen Startpunkt wissen, muss man neu berechnen. Bei deiner Variante würde dieser Schritt wahrscheinlich (teilweise) entfallen. Mikro 7. schrieb: > Wenn du aber schon eine Lösung hast, ist das alles Spielerei. ;-) Vielleicht, vielleicht auch nicht. Ich will den aktuellen Ansatz noch ausgiebig testen. Ich bin insbesondere auf das Resultat mit einem Irrgarten gespannt. Schmale Gänge, viele Verzweigungen und viele Wege, die zum Ziel führen. Mal schauen was der Dijkstra-Algorithmus da für Resultate erzielt. Joe schrieb: > Definiere mal "Entfernung: > > a) Entfernung als Anzahl der Schritte in einem Raster Anzahl Schritte in einem Raster, wobei diagonale Schritte gleich viel kosten wie horizontale und vertikale. Später, wenns dann zuverlässig läuft, werden noch Felder mit einem Kantengewicht > 1 hinzugefügt, aber dies ist relativ einfach zu implementieren. Joe schrieb: > Lösungsansatz: > bewerte zuerst jeden Punkt mit dem Abstandsbetrag der x-Koordinaten > und sortiere diese 1. Liste (max. Abstand an 1. Stelle) > > dann bewerte jeden Punkt mit dem Abstandsbetrag der y-Koordinaten > und sortiere diese 2. Liste (max. Abstand an 1. Stelle) > > Danach Abstandswerte zum Bezugspunkt nach a) oder b) für die Elemente > aus Liste 1 und dann aus Liste 2 ausrechnen. Besteht der Ansatz darin, erst mal per Luftlinie nach möglichst grossen Abständen zu suchen, damit man einen Anhaltspunkt hat, wo man die Suche beginnen soll? Kannst du ein konkretes Beispiel machen oder hat der Algorithmus einen Namen?
Sebastian V. schrieb: > Ich habe gestern > vorm einschlafen noch überlegt wieso der pseudo diameter nicht den > echten diameter liefert aber mir ist auf anhieb kein gutes Gegenbeispiel > eingefallen. Offensichtlich scheint er aber nicht immer den längsten Weg > zu finden. Ich habe gerade geglaubt, einige Gegenbeispiele gefunden zu haben. Sobald ich diese jedoch auf Papier gezeichnet habe, wurde der längste Weg gefunden. Vielleicht muss ich alle Knoten berücksichtigen, deren Weg maximal ist und anschliessend alle diese Knoten als Startknoten verwenden. Nach jedem Durchlauf fliegen alle Wege, die nicht maximal sind, aus der Liste raus (die vorherigen werden ebenfalls berücksichtigt). Dies wird dann weitergeführt, bis alle verbleibenden Knoten zirkular sind. Dabei können leider auch Dreiecke oder Sterne entstehen, die erkannt werden müssen. Wird wohl doch etwas mehr Aufwand als erhofft. Dass nicht alle Lösungen gefunden werden, sieht man gut an einem leeren Quadrat, solange der Startpunkt nicht im Schwerpunkt ist. Dann wird das Maximum in eine Ecke gehen. Anschliessend in die Diagonale. Die andere Diagonale wird nicht erkannt.
ein Quadrat ist wirklich ein schlechtes Beispiel, das gibts ja Unmengen an Lösungen..
Angehängte Dateien:
-

graph.jpg
110 KB
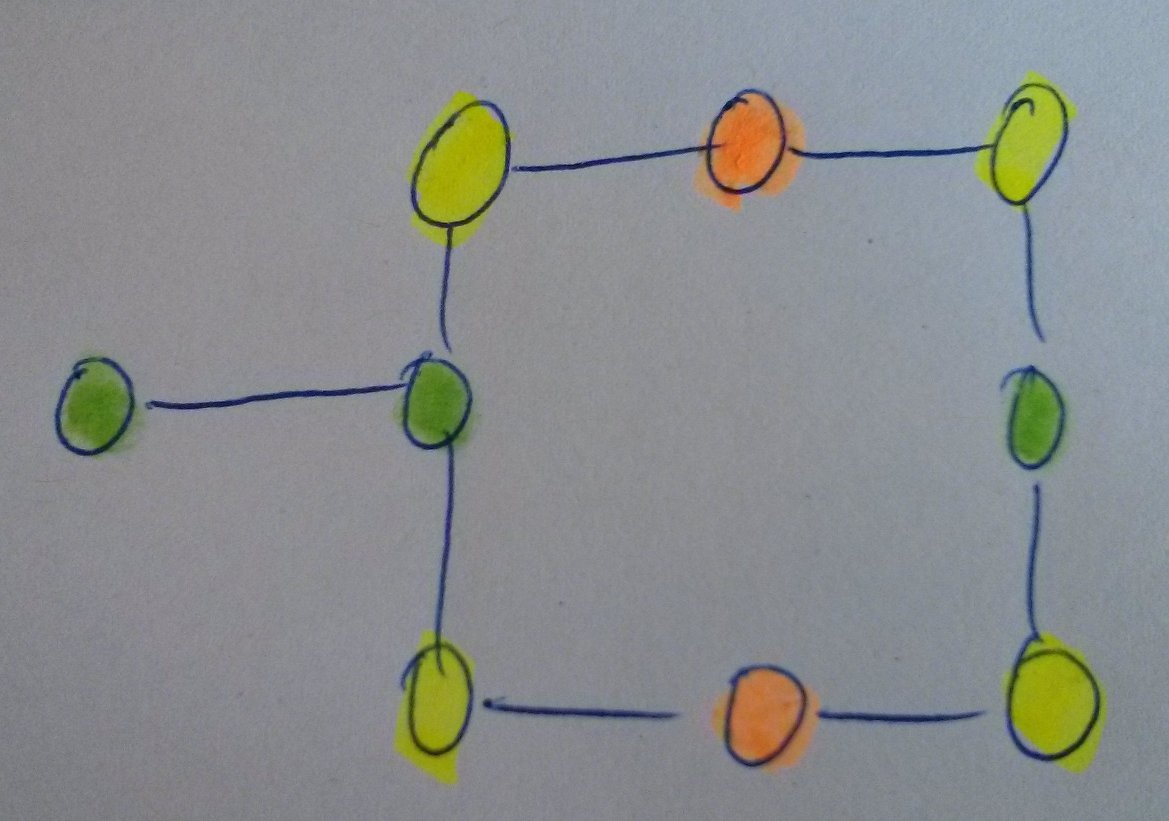
Ich habe ein gutes Gegenbeispiel gefunden (Anhang). Keine Ahnung ob du das mit deinem Quadrat meintest. Ich konnte deiner Erklärung nicht ganz folgen. Wenn man bei einem der grünen Knoten startet findet man garantiert den längsten Pfad. Wenn man bei den gelben startet nur wenn man nach dem Berechnen der Abstände den richtigen (oder alle) der beiden gleich weit entfernten Knoten wählt. Bei den roten Knoten wandert man nur zwischen diesen hin und her und kommt nicht zu dem längeren Pfad.
Sebastian war zwar schneller, da ich aber mein Gegenbeispiel schon gemalt habe, poste ich es trotzdem noch:
1 | ############# |
2 | ######D###### |
3 | ######·###### |
4 | ######·###### |
5 | ######·###### |
6 | ######·###### |
7 | #####·#·##### |
8 | ####·###·#### |
9 | ###·#####·### |
10 | #A·#######·C# |
11 | ###·#####·### |
12 | ####·###·#### |
13 | #####·#·##### |
14 | ######·###### |
15 | ######·###### |
16 | ######·###### |
17 | ######·###### |
18 | ######B###### |
19 | ############# |
A sei der Startpunkt. Der davon am weitesten entfernt liegende Punkt ist C mit einer Distanz von 10 (B und D liegen jeweils nur 9 Schritte von A entfernt). Der von B am weitesten entfernt liegende Punkt ist A, so dass der Algorithmus an dieser Stelle abbricht und als Pseudodurchmesser 10 liefert. Der tatsächliche Durchmesser ist aber 16 (die Distanz von D nach B). Topologisch gesehen ist dieses Beispiel dem von Sebastian allerdings sehr ähnlich.
lrlr schrieb: > ein Quadrat ist wirklich ein schlechtes Beispiel, das gibts ja Unmengen > an Lösungen.. Stimmt, habe vergessen, dass diagonale Schritte auch nur 1 kosten. Dann ist ein Quadrat ja noch schlimmer als ein Kreis... Sebastian V. schrieb: > Ich habe ein gutes Gegenbeispiel gefunden (Anhang). Es kann so einfach sein... Sebastian V. schrieb: > Keine Ahnung ob du das mit deinem Quadrat meintest. Nein, damit meinte ich sowas:
1 | ##### |
2 | #...# |
3 | #...# |
4 | #...# |
5 | ##### |
Schon alleine da sehe ich 36 gleichwertige Lösungen. Yalu X. schrieb: > Sebastian war zwar schneller, da ich aber mein Gegenbeispiel schon > gemalt habe, poste ich es trotzdem noch: Danke, sowas in der Art hatte ich auch im Kopf, konnte aber keine Karte konstruieren, die als Gegenbeweis taugt. Ich habs mit einem Kreis versucht, aber da funktioniert der Algorithmus. Solle Fälle muss ich zwar nicht abfangen können, finde das Thema aber gerade sehr spannend. Im Zusammenhang mit Graphen hab ich eh noch etwas Nachholbedarf.
Be S. schrieb: > Schon alleine da sehe ich 36 gleichwertige Lösungen. Du suchst also alle Lösungen und nicht nur eine der optimalen Lösungen? Aber gut selbst das leistet der pseudo Durchmesser ja nichtmal. Wenn man Wikipedia glaubt (https://en.wikipedia.org/wiki/Floyd%E2%80%93Warshall_algorithm#Comparison_with_other_shortest_path_algorithms) dann ist es für dein Problem recht effizient wenn man jeden Punkt als Startpunkt für den Dijkstra-Algorithmus nimmt. Dann kriegst du auch alle Lösungen und den Algorithmus hast du ja eh schon implementiert.
Sebastian V. schrieb: > Du suchst also alle Lösungen und nicht nur eine der optimalen Lösungen? Nee, eigentlich nicht einmal die optimale, nur eine die nah dran ist. Aber wie das halt so ist, plötzlich packt einem der Ehrgeiz und man wills immer besser machen. Schliesslich lernt man auch was dabei. Und zu einer genügenden Lösung, die dann auch einigermassen flott läuft, kann man immer abspecken. Werde die obige Karte sicher noch mir Brute Force durchrechnen, mal schauen wie lange das dauert. Wenn man die ideale Lösung nicht kennt, hat man ja keine Vergleichsmöglichkeit. Leider hab ich heute Abend schon was vor und keine Zeit zum proggen :(
>Brute Force durchrechnen
wie gesagt, das sind (Viel) zu viele Möglichkeiten
aber:
alle Flächen die bei einer Vorhergehenden Berechnung "auf dem Pfad"
lagen, braucht man nicht mehr als Start/Ziel verwenden..
IMHO genügt es auch wenn man "nur" die Flächen die "am Rand" liegen,
als Start und Ziel nimmt..(also die mindestens einen nicht begehbaren
als Nachbarn haben)
außerdem würde ich das ganze Feld in Quadrate einteilen, dort jeweils
nur ein paar punkte pro Quadrat
und dann mit den vielversprechendsten Quadraten beginnen genauer zu
testen..
Robert L. schrieb: > wie gesagt, das sind (Viel) zu viele Möglichkeiten So viele auch nicht. Er hat doch oben schon 10k mal den pseudo diameter berechnet. Mit der Anzahl an Schritten die das gebraucht hat waren das ~36k mal Dijkstra. Allerdings hat die Karte nur ~33k begehbare Punkte also hätte man in weniger Zeit auch alle Startpunkte testen können. Optimierungen machen natürlich trotzdem Sinn. Edit: Robert L. schrieb: > alle Flächen die bei einer Vorhergehenden Berechnung "auf dem Pfad" > lagen, braucht man nicht mehr als Start/Ziel verwenden.. Nein, die Bedingung ist falsch. Siehe mein Beispiel Bild oben. Der grüne Punkt rechts ist Start/Ziel des längsten Pfads aber wenn ich andere Punkte als Start wähle liegt dieser Punkt "auf dem Pfad". Edit2: Robert L. schrieb: > IMHO genügt es auch wenn man "nur" die Flächen die "am Rand" liegen, > als Start und Ziel nimmt..(also die mindestens einen nicht begehbaren > als Nachbarn haben) Auch die Bedingung ist falsch. Gegenbeispiel:
1 | ##B######B## |
2 | #...####...# |
3 | A...C##C...A |
4 | #...####...# |
5 | ##D######D## |
Felder mit gleichen Buchstaben sind jeweils miteinander verbunden und zwar so, dass alle Wege gleich lang sind (also von C zum anderen C ist genauso lang wie von A zum anderen A). Das lässt sich sicher erreichen, ich bin aber zu faul das tatsächlich zu konstruieren. Der längste Pfad startet und endet dann jeweils im Mittelpunkt der beiden Boxen.
Brute Force ergibt bei mir für die Punkte (y,x) (275,42) (277,42) (279,46) (279,47) (279,48) (681,26) (681,27) (681,28) (683,22) den Durchmesser 1619.
Hast du die # als begehbare Punkte verstanden? Ich glaub die Punkte sollen begehbar sein.
Zur Suche des kürzesten wurde ja schon der Dijkstra-Algorithmus genannt. In deinem Fall, weil du keinen beliebigen Graphen hast, sollte der A*-Algorithmus effizienter sein. https://de.wikipedia.org/wiki/A*-Algorithmus
Aber auf den Lattenzäunen (#) kann ich doch laufen, während ich bei den dünnen Pünktchen (.) keinen Halt finde und versinke! ;-) Nagut, nehmen wir die Punkte als Graph (dann sind sogar alle 33.860 Knoten connected). Das würde bei mir einen Durchmesser von 1013 ergeben für (317,101) und (998,18).
Tilo R. schrieb: > In deinem Fall, weil du keinen beliebigen Graphen hast, sollte der > A*-Algorithmus effizienter sein. Weil? Wir suchen ja nicht für zwei Punkte den Abstand sondern alle möglichen Abstände von einem bestimmten Startpunkt aus. Dafür schein mit A* ungeeignet. Mikro 7. schrieb: > Nagut, nehmen wir die Punkte als Graph (dann sind sogar alle 33.860 > Knoten connected). Das würde bei mir einen Durchmesser von 1013 ergeben > für (317,101) und (998,18). Das scheint ja auch die Lösung zu sein die man fast immer für den pseudo diameter kriegt.
Sebastian V. schrieb: > Robert L. schrieb: >> wie gesagt, das sind (Viel) zu viele Möglichkeiten > > So viele auch nicht. Er hat doch oben schon 10k mal den pseudo diameter > berechnet. Mit der Anzahl an Schritten die das gebraucht hat waren das > ~36k mal Dijkstra. Allerdings hat die Karte nur ~33k begehbare Punkte > also hätte man in weniger Zeit auch alle Startpunkte testen können. > Optimierungen machen natürlich trotzdem Sinn. das stimmt IMHO aber nicht.. er muss von JEDEN begehbaren Punkt als Start zu JEDEM begehbarem Punkt als ZIEL die kürzeste strecke ermittel und DANN die streckenlängen vergleichen > > Edit: > Robert L. schrieb: >> alle Flächen die bei einer Vorhergehenden Berechnung "auf dem Pfad" >> lagen, braucht man nicht mehr als Start/Ziel verwenden.. > > Nein, die Bedingung ist falsch. Siehe mein Beispiel Bild oben. Der grüne > Punkt rechts ist Start/Ziel des längsten Pfads aber wenn ich andere > Punkte als Start wähle liegt dieser Punkt "auf dem Pfad". > ja, die Bedingung ist "falsch" (ungenau), ich meinte: hat man einen Pfad zwischen 2 punkten (einer als start und einer als ziel) berechnet, kann man ALLE kombinatinen wo start und ziel auf diesem pfad liegen ignorieren (es ist nur schwierig alle pfade zu speichern, weil die viel platz brauchen würden) > Edit2: > Robert L. schrieb: >> IMHO genügt es auch wenn man "nur" die Flächen die "am Rand" liegen, >> als Start und Ziel nimmt..(also die mindestens einen nicht begehbaren >> als Nachbarn haben) > > Auch die Bedingung ist falsch. Gegenbeispiel: >##B######B## > #...####...# > A...C##C...A > #...####...# > ##D######D## sowohl A, B C also auch D liegen (nach meinder definition) am Rand.. welcher genau soll hier nicht "am rand" liegen.. gemeint ist, am RAND der begehbaren fläche: siehe: >>(also die mindestens einen nicht begehbaren >> als Nachbarn haben)
Robert L. schrieb: > das stimmt IMHO aber nicht.. > er muss von JEDEN begehbaren Punkt als Start zu JEDEM begehbarem Punkt > als ZIEL die kürzeste strecke ermittel und > DANN die streckenlängen vergleichen Doch stimmt. Dijkstra liefert von einem bestimmten Startpunkt aus die kürzeste Stecke zu jedem anderen Punkt. Also muss man es nur für jeden Startpunkt machen. Robert L. schrieb: > sowohl A, B C also auch D liegen (nach meinder definition) am Rand.. > welcher genau soll hier nicht "am rand" liegen.. Der Punkt in der Mitte liegt nicht am Rand. Hier mit 'x' markiert:
1 | ##B######B## |
2 | #...####...# |
3 | A.x.C##C.x.A |
4 | #...####...# |
5 | ##D######D## |
Unter der Annahme das die Strecken zwischen zwei gleichen Buchstaben genau gleich lang sind startet und endet die längste Strecke bei den 'x'
egal ob "." oder "#" jetzt begehbar sein sollen
man kommt überhaupt nicht von x zu x
(da ist ne wand dazwischen)
?
>Dijkstra
ja, hab ich mir Kurz angeschaut
sowas ähnlich hätte ich jetzt auch gemacht
also irgendwo Starten, und bei jeweiligen begehbaren Nachbarn, 1
addieren
beim nächten dann 2 addierne, beim nächsten 3 usw.
aber Dijkstra ist im Detail wohl etwas ausgeklügelter als mein einfall..
wenn man das bei genügend vielen startpunkten macht, müssten die 2
punkte mit der höchsten zahl eigentlich recht nahe am ergebnis sein..
(alle durchprobieren sollte bei "kleiner" Karten hier tatsächlich
möglich sein..)
ja, so könnte das gehen..
Robert L. schrieb: > egal ob "." oder "#" jetzt begehbar sein sollen > man kommt überhaupt nicht von x zu x > (da ist ne wand dazwischen) > ? Hab ich doch oben geschrieben... Das Beispiel ist nicht vollständig. Du musst dir vorstellen die beiden 'A' sind verbunden, die 'B' sind verbunden usw. und das Ganze noch so, dass die Strecke zwischen zwei gleichen Buchstaben gleich lang ist. Das kann man sicher so hinbiegen indem man zwischen den beiden 'C' viel hin und her laufen muss während zwischen den beiden 'A' direkt Strecke sehr direkt ist.
würde dir die dynamische Programmierung vorschlagen. Wenn man die Kostenfunktion richtig formuliert hat, ist es vermutlich die beste Wahl.
Achja, hier die brute-force Implementierung, falls der TE etwas zum Testen braucht. Ungetestet. ;-) Wer Fehler findet, darf sie behalten...
Sebastian V. schrieb: > Der Punkt in der Mitte liegt nicht am Rand. Hier mit 'x' > markiert: > ##B######B## > #...####...# > A.x.C##C.x.A > #...####...# > ##D######D## > Unter der Annahme das die Strecken zwischen zwei gleichen > Buchstaben > genau gleich lang sind startet und endet die längste Strecke bei den 'x' Hmm, Verschiebst Du dann aber das x auf der einen Seite 2 Felder nach unten und auf der anderen Seite 2 Felder nach oben, ergibt sich wieder die gleiche "längste Wegstrecke" UND Du bist am Rand der freien Fläche. Bei Rundkursen gleicher Länge kannst Du ALLE Wegpunkte als Start- und Zielpunkte angeben. Gefühlt würde ich wohl die Map auch erst einmal Sobeln, anschließend nach Ecken, Kreuzungen und Kanten sortieren und davon ausgehend den A* oder Dijkstra starten. Schönes Knobelspiel, das!
Jetzt weiß ich wie sich "reine" E-Techniker fühlen wenn sie "reine" Informatiker beim Schaltungen basteln beobachten... wenn man als Informatiker sieht wie gerade mit Algorithmen wahllos hantiert wird ;) Floyd-Warshall implementieren und MIN durch MAX ersetzen, der war gut :) ähnlich wie + und - an der Polung mal vertauschen :) Aber Diameter wurde ja schon genannt.
D. I. schrieb: > Jetzt weiß ich wie sich "reine" E-Techniker fühlen wenn sie "reine" > Informatiker beim Schaltungen basteln beobachten... wenn man als > Informatiker sieht wie gerade mit Algorithmen wahllos hantiert wird ;) > Floyd-Warshall implementieren und MIN durch MAX ersetzen, der war gut :) > ähnlich wie + und - an der Polung mal vertauschen :) Du hast wahrscheinlich eine naive Vorstellung von "Algoritmus" (für dich =Programmcode), dazu gehört aber wesentlich mehr, wie z.B. Theory, Analyse und auch Probiererei inkl. Fehlversuche (jeder Algo ist duch Ideen und Versuche entstanden). Und wussest du, dass LongestRun NP-Vollständig ist? Wenn man hier Informatiker fragt, dann bekommst du die gleiche Antwort. Von daher ist MIN durch MAX inkl. weiterer Anpassungen kein schlechter erster Versuch, wenn man berücksichtigt, dass man hier ein bis auf Hindernisse reguläres Raster hat (und damit immer noch NP-Vollständig??). Die Vertauschung der Operatoren ist also wesentlich komplexer als die Vertauschung von + und -.
Horst S. schrieb: > Gefühlt würde ich wohl die Map auch erst einmal Sobeln, Das erzeugt aber pauschal erst mal eine Menge Aufwand. Selectives Vorgehen wäre da besser.
Klaus L. schrieb: > Horst S. schrieb: >> Gefühlt würde ich wohl die Map auch erst einmal Sobeln, > > Das erzeugt aber pauschal erst mal eine Menge Aufwand. Selectives > Vorgehen wäre da besser. Meinst Du mit "selektivem Vorgehen" das iterative Verfolgen im Dijkstra über mehrere Durchläufe? Das geht doch nicht, haben Sebastian und Yalu doch gezeigt.
Ich habe gerade keine Zeit den ganzen Thread danach abzusuchen, ob das schon jemand vorgeschlagen hat, aber kann man hier nicht einfach mit Dijkstra oder Prim einen Maximum Spanning Tree bauen (Aenderung am Algo : anstatt die guenstigste Kante einfach immer die teuerste hinzufuegen, die keinen Loop generiert). Am Maximum Spanning Tree ist die Komplexitaet um die am weitesten entfernten Knoten zu finden um einiges einfacher, m.M.n. wird es reichen alle Blattknoten des entstandenen Baumes zu betrachten.
Sigi schrieb: > D. I. schrieb: >> Jetzt weiß ich wie sich "reine" E-Techniker fühlen wenn sie "reine" >> Informatiker beim Schaltungen basteln beobachten... wenn man als >> Informatiker sieht wie gerade mit Algorithmen wahllos hantiert wird ;) >> Floyd-Warshall implementieren und MIN durch MAX ersetzen, der war gut :) >> ähnlich wie + und - an der Polung mal vertauschen :) > > Du hast wahrscheinlich eine naive Vorstellung von "Algoritmus" > (für dich =Programmcode), dazu gehört aber wesentlich mehr, wie z.B. > Theory, Analyse und auch Probiererei inkl. Fehlversuche > (jeder Algo ist duch Ideen und Versuche entstanden). Sagen wir mal so, der Cormen ist mir mehr als nur ein Begriff oder Billyregalfüllung. ;) > > Und wussest du, dass LongestRun NP-Vollständig ist? Wenn man > hier Informatiker fragt, dann bekommst du die gleiche Antwort. > Von daher ist MIN durch MAX inkl. weiterer Anpassungen kein > schlechter erster Versuch, wenn man berücksichtigt, dass man hier > ein bis auf Hindernisse reguläres Raster hat (und damit immer > noch NP-Vollständig??). Die Vertauschung der Operatoren ist > also wesentlich komplexer als die Vertauschung von + und -. Ja und? Ich weiß, dass das Längster-Pfad-Problem NP-vollsändig ist, und nun? Wenn es beim Diameter-Problem bleibt ist Floyd-Warshall schon ein richtiger Ansatz, aber halt in O(n³), aber der Algo macht halt genau das was der OP im ersten Beitrag nicht will (alle kürzesten Wege berechnen und der längste ist der Diameter). Man kann zwar noch tricksen wenn die Kantengewichte alle 1 sind, aber wenn er tatsächlich das Optimum berechnen will, ... ohne weitere Infos wäre mein Ansatz die Knotenanzahl zu reduzieren, so dass man als Input wirklich direkt Knoten und Kanten reinbekommt anstatt so ein Grid mit 1000x1000 wovon das meiste leere Felder sind. Wenns nicht geht, dann kann man ja eventuell eine parallelisierte Version von Dijkstra hernehmen und das Ergebnis in der Cloud berechnen lassen... :)
D. I. schrieb: > Sagen wir mal so, der Cormen ist mir mehr als nur ein Begriff oder > Billyregalfüllung. ;) Na wunderbar, Corman ist ja für seine bildhafte Beschreibung der Algos bekannt (zumind. in meiner Erinnerung, Cover hat MOMA-Mobile von Alexander Calder?). Neben Graphenalgos ist doch sicherlich eine Einführung in Dynamisches Programmieren? Das reicht für das Grundverständnis des FW-Algo (Synthese aus Graphenalgo und DP). Wenn Du jetzt noch die Karte ein wenig aufbereitest und alle konvexe Komponenten und deren "diametrale" punkte identifizierst plus deren Zusammenhang (=Graph), dann lässt sich die Idee/Ansatz aus dem FW-Algo evtl. anwenden (und hier genau muss MIN mit MAX vertauscht werden), den Algo selbst direkt anzuwenden halte ich für blödsinnig, der wird dir nichts bringen. Aber so aus der Hüfte raus geschossen lässt sich dass nicht sagen, muss halt gestestet werden, ist ja nur ein Ansatz. D. I. schrieb: > Ja und? Ich weiß, dass das Längster-Pfad-Problem NP-vollsändig ist, und > nun? Schön es zu wissen, aber eine z.B. Reduktion eines Probems auf ein bekanntes NP-Problem aufzuzeigen ist nochmal eine andere Welt, die meisten ITs kriegen das nicht hin. Und genau das ist hier ja das Problem: Du hast zwar ein sehr reguläres Raster, dafür aber noch Hindernisse. Bist Du da noch sicher, das NP vorliegt? Und kleine Nebenbemerkung zu Diametral: Egal welche (technische) Fachrichtung, wer nicht schnell erkennt, dass die interessanten Punkte am Rand liegen (siehe z.B. Kreis bzw. Rechteck), der sollte Lötkolben, Hammer, Schraubenschlüssel oder Tastatur weglegen. So, jetzt beginnt Boxen..
Be S. schrieb: > Hallo zusammen > > Ich suche einen Algorithmus, der auf einer zweidimensionalen Karte die > zwei Punkte findet, die am weitesten voneinander entfernt sind. Hallo, es mag ein mathematisch reizvolles Problem sein, die Praxiis auf realen Karten zeigt deutliche Verienfahcungen. Bei dichten Straßennetzen wie in Frankreich und Deutschland gilt: Luftlinie x 1,2 ungefähr kürzeste Straßenentfernung. Luftlinie x 1,3 Autobahnentfernung. In den Alpen Faktor 1,4 bis 1,5. Auf das Problem bezogen, Orte auf den äusseren Punkten der Kartendiagonale sind auch am weitesten auf Straßen entfernt.
Danke erstmal für die vielen Antworten. Ich muss mir das mal alles in Ruhe anschauen und durchackern. Das Projekt muss leider aus verschiedenen Gründen pausieren, es gibt gerade Wichtigeres. Ich werde aber auf alle Fälle hier berichten, sobald sich wieder was getan hat.
Sie mir net böse Wolfgang, aber mit den pauschalen Angaben ist nix gewonnen. Praktisch jeder individuelle Vergleich zwischen Autobahn und Landstrasse wird damit falsch ausfallen. Mal zum Thema zurück: Man kann das Ganze sicher etwas vereinfachen, wenn man den Schwerpunkt des Systems kennt. Die beteiligten Punkte, die die entferntesten bilden, dürften am Rand liegen. Zumindest einer der beiden. Dort kann man anfangen und beim Auffinden von guten Werten andere Punkte, die zu weit innen liegen schon im Ansatz von einer weiteren Betrachtung ausschliessen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.