Hallo,
wir benutzen bei uns ein paar Python Scripte die irgendwann mal
zusammengeschraubt wurden. Bei uns in Deutschland funktioniert das auch
ohne Probleme. Allerdings bei unseren Kollegen in Großbritannien die
Begutachtung diese Anwendungen bekommen sollen gibt es Probleme. Hier
wird eine Muschung aus Win 7 und Win 10 verwendet.
Soweit ich das analysieren könnte gibt es Probleme mit print Ausgaben.
Ich hoffe zumindestens, dass es nur die prints sind!
jedes Script startet mit
# -*- coding: utf-8
Wenn ich z.B.:
print ("Sönderzeichen")
schreibe, wie bekomme ich das auch in der UK genau so angezeigt?
gibt es sowas ähnliches wie z.B.
print ("S"\xf6"nderzeichen")
William schrieb: > wird eine Muschung aus Win 7 und Win 10 verwendet Wichtiger ist in diesem Fall die Python-Version! https://docs.python.org/3/howto/unicode.html https://docs.python.org/2/howto/unicode.html Gruß, Dennis
Python 3.4 und das wird über pyinstaller in eine benutzerfreundliche exe verwandelt
William schrieb: > Soweit ich das analysieren könnte gibt es Probleme mit print Ausgaben. Wohin erfolgen diese Ausgaben? In das Windows-Konsolenfenster? Und wie sieht die fehlerhafte Ausgabe aus?
William schrieb: > print ("Sönderzeichen") > > schreibe, wie bekomme ich das auch in der UK genau so angezeigt? > > gibt es sowas ähnliches wie z.B. > > print ("S"\xf6"nderzeichen") Nein, tu das nicht! Auf gar keinen Fall! Damit nagelst Du es auf eine Zeichen-Kodierung (deine eigene) fest und das wird oftmals nicht die Kodierung der Konsole des Endanwenders sein, dort liegt das ö vielleicht ganz wo anders. Es gibt stattdessen das: print u"Sönderzeichen" dann ist es ein Unicode-String, der funktioniert international wird bei der Ausgabe (egal wo) on the fly passend zur Kodierung des dortigen Ausgabegerätes kodiert und wenn der Zeichensatz des Ausgabegerät irgendwo ein "ö" enthält dann kommt das auch raus. Wenns natürlich den Kringel mit den zwei Punkten nirgendwo in seinem Zeichensatz hat, dann natürlich nicht. Und den Quelltext würde ich natürlich grundsätzlich als UTF8 codieren und den Editor mit dem Du arbeitest entsprechend einstellen (wichtig!), das ist Voraussetzung wenn Du unbedingt Strings mit Umlauten direkt im Quelltext stehen haben willst. Die Zeiten von Windows1252 und Iso-88-schlagmichtot sind gottseidank vorbei, UTF-8 ersetzt sie alle. Überall dort wo Du es einstellen kannst (fast überall): Nur noch UTF-8. Also zusammengefasst: * Editor (IDE oder wasauchimmer) auf UTF-8 umstellen, evtl vorhandene Dateien neu als UTF-8 speichern, bei der Umstellung zerschossene Umlaute wieder korrigieren so daß sie jetzt in UTF-8 vorliegen. * den open genannten Header in alle Python2 Dateien einbauen * Stringliterale mit Umlauten nur noch u"Hölle" statt "Hölle" dann wirds klappen.
:
Bearbeitet durch User
William schrieb: > wir benutzen bei uns ein paar Python Scripte die irgendwann mal > zusammengeschraubt wurden. Bei uns in Deutschland funktioniert das auch > ohne Probleme. Allerdings bei unseren Kollegen in Großbritannien die > Begutachtung diese Anwendungen bekommen sollen gibt es Probleme. Hier > wird eine Muschung aus Win 7 und Win 10 verwendet. Bitte die Kollegen doch mal, den Output des Kommandos "chcp" (ohne Argumente) mitzuteilen und vielleicht auch, was sich nach Eingabe von "chcp 850" und dann Programmstart als Output ergibt. Da Python 3.4 verwendet wird, ist es wurscht, ob eine Stringkonstante als "Grüßlich" oder als u"Grüßlich" geschrieben wurde. Sollte der Code allerdings auch mit Python 2.7 kompatibel sein sollen, wäre als einheitliche Schreibweise der u-Prefix zu bevorzugen.
ICh habe gerade einen Versuch geastartet
Ich habe in der ersten Zeile nach den impotfiles folgendes geschrieben:
os.system('chcp 850')
Bei dem ersten Versuchskaninchen geht es. Morgen mal abwarten ob es bei
den anderen auch geht.
Ist das Skript denn auch in utf-8 abgespeichert, oder steht da nur oben "utf-8" drin?
William schrieb: > ICh habe gerade einen Versuch geastartet > > Ich habe in der ersten Zeile nach den impotfiles folgendes geschrieben: > > os.system('chcp 850') Das ist nicht das, was ich meinte. Es wird Verwirrung stiften, weil es erst beim zweiten Programmstart funktioniert.
1 | # -*- coding: utf-8 -*- |
2 | import os |
3 | os.system("chcp")
|
4 | os.system("chcp 850")
|
5 | os.system("chcp")
|
6 | print("Grüßlich")
|
7 | print(u"Grüßlich") |
8 | |
9 | C:\temp>chcp 1250 |
10 | Aktive Codepage: 1250. |
11 | |
12 | C:\temp>\Python34\python umleute.py |
13 | Aktive Codepage: 1250. |
14 | Aktive Codepage: 850. |
15 | Aktive Codepage: 850. |
16 | Gr³▀lich |
17 | Gr³▀lich |
18 | |
19 | C:\temp>\Python34\python umleute.py |
20 | Aktive Codepage: 850. |
21 | Aktive Codepage: 850. |
22 | Aktive Codepage: 850. |
23 | Grüßlich |
24 | Grüßlich |
Mein Vorschlag lief darauf hinaus, zunächst zu prüfen, was die voreingestellte Codepage ist, diese dann in einem cmd.exe Konsolfenster zu ändern und dann dort das besagte Programm auszuführen. Falls das funktioniert, kann man immer noch überlegen, wie man das je nach den konkreten Umständen etwas zickige Verhalten von Python mit Codepages in den Griff bekommt.
Interessant, dass du das 2x ausführen musstest. Bei mir hat er das beim ersten mal umgesetzt und richtig geschrieben... Wenn es hilft, ich verwende Eclipse Mars. Vielleicht ist da der Fehler drin.
Bernd K. schrieb: > Es gibt stattdessen das: > > print u"Sönderzeichen" > > dann ist es ein Unicode-String, Das ist ja schon wieder steinalter mist, von leuten, die auf Python 2.x haengen geblieben sind und sich nicht weiterbilden... Hier geht es aber um Python 3! William schrieb: > Python 3.4 In Python 3 sind alle Strings Unicode-Strings, solange man nichts anderes angibt. Deswegen gibt es in PyQt5 auch kein QString mehr, weil QString auch Unicode war. Und damit man nicht 2x das selbe hat, wurde QString gestrichen. William schrieb: > Eclipse Eclipse bringt eine "eigene Umgebung" mit. Wenn du dein Programm aus Eclipse heraus startest, hast du andere Umgebungsvariablen, als wenn du es von der Konsole, oder als .exe startest.
Kaj schrieb: > Das ist ja schon wieder steinalter mist, von leuten, die auf Python 2.x > haengen geblieben sind und sich nicht weiterbilden... Hier geht es aber > um Python 3! Nun, selbst die eifrigsten Fans von Python 3 rudern inzwischen deutlich zurück und räumen ein, daß im wirklichen Leben, dort, wo Python benutzt und nicht nur drüber fabuliert wird, Python 3 zehn Jahre nach der Einführung weiterhin nur eine Fußnote ist. Eine aktuelle Zweiwochen-Downloadstatistik von pypi weist aus
1 | 2.7 85.90% |
2 | 2.6 6.66% |
3 | 3.4 4.64% |
4 | 3.5 2.09% |
5 | 3.3 0.56% |
6 | 3.2 0.12% |
Mit anderen Worten, Python-Pakete für alle Python 3.x-Versionen
zusammengerechnet werden etwa so häufig eingesetzt wie die alte, längst
aus der Wartung genommene 2.6.
Man wird mit der Spaltung, die die unüberlegte Einführung einer halbgar
kompatiblen Sprachvariante verursacht hat, wohl noch die nächsten zehn
oder zwanzig Jahre leben müssen. Ich habe Verständnis für diejenigen,
die sich für neue Projekte mit wenig Umgebungsabhängigkeiten, was Python
betrifft, der fraglos moderneren Implementation bedienen. Ich bitte aber
auch um Verständnis für z.B. diejenigen, die Python schon vor langer
Zeit ihrem Repertoire hinzugefügt haben und wenig Sinn darin sehen, das
alles, was sich da an kleinen und größeren Hilfsmitteln angesammelt hat,
für zweifelhafte Vorteile wegzuwerfen, deren Nutzen sich evtl. erst spät
oder nie manifestiert.
Jedenfalls treiben dumme Sprüche wie der obige ("steinalter Mist") die
Leute eher von Python weg als zu Python 3 hin. Die klügeren der Fans
haben inzwischen gelernt, daß derartiges Proselytentum vornehmlich
motiviert, sich mal bei Alternativen wie Go, Julia, Rust, Lua, Java,
Swift etc. pp umzuschauen.
Wolfgang S. schrieb: > Mit anderen Worten, Python-Pakete für alle Python 3.x-Versionen > zusammengerechnet werden etwa so häufig eingesetzt wie die alte, längst > aus der Wartung genommene 2.6. Nein. Diese Statistik ist nicht "randomly sampled" und damit nutzlos. Wenn ich einen alten Rechner habe, auf dem Python 2.6 oder 2.7 läuft, lade ich Pakete dafür natürlich viel eher aus dem package index runter als wenn ich irgendwas neueres benutze. Wenn ich 3.5 verwende, installier' ich mir unter Windows so einen blob wo eh alles drin ist oder kriege unter Linux alles aud meinem Paketmanager, und 99% der Nutzer werden den package index nie verwenden. Deshalb tauchen die auch nicht in der Statistik auf.
Wolfgang S. schrieb: > Jedenfalls treiben dumme Sprüche wie der obige ("steinalter Mist") die > Leute eher von Python weg als zu Python 3 hin. Die klügeren der Fans > haben inzwischen gelernt, daß derartiges Proselytentum vornehmlich > motiviert, sich mal bei Alternativen wie Go, Julia, Rust, Lua, Java, > Swift etc. pp umzuschauen. Ehrlich gesagt, und ohne dir auf die Füße treten zu wollen weil du prinzipiell Recht hast, hättest du dir das ganze Gebrubbel sparen können. Der TO sucht eine Lösung für v3.4. Wen interessieren da irgendwelche Downloadstatistiken? Gruß Dennis
Hi, ich habe gerade eine Rückmeldung erhalten. Die Betriebssysteme laufen alle auf Code Page 437. Und es muss tatsächlich 2x ausgeführt werden das es dann auch läuft. Als Fehlermeldung wird folgendes Ausgegeben. UnicodeEncodeError: 'charmap' codec can´t encode character '\xf8' in position 0: character maps to <undefined> test_script returned -1 In dem Testscript habe ich alle Sonderzeichen in print reingeknallt was wir in unseren Scripten verwenden. Jetzt die Frage aller Fragen, wie gehe ich das Problem am besten an?
Dennis S. schrieb: > Wolfgang S. schrieb: >> Jedenfalls treiben dumme Sprüche wie der obige ("steinalter Mist") die >> Leute eher von Python weg als zu Python 3 hin. Die klügeren der Fans >> haben inzwischen gelernt, daß derartiges Proselytentum vornehmlich >> motiviert, sich mal bei Alternativen wie Go, Julia, Rust, Lua, Java, >> Swift etc. pp umzuschauen. > > Ehrlich gesagt, und ohne dir auf die Füße treten zu wollen weil du > prinzipiell Recht hast, hättest du dir das ganze Gebrubbel sparen > können. Der TO sucht eine Lösung für v3.4. Dem TO habe ich die Lösung längst auf dem silbernen Tablett serviert, passend für das von ihm genannte Python 3.4 und mit komplettem Beispiel. > Wen interessieren da > irgendwelche Downloadstatistiken? Diejenigen, denen solche dummen Sprüche auf Dauer auf die Nerven gehen. Mich zum Beispiel. Wobei das eigentliche Argument ein inhaltliches ist, die Statistik diente nur der Illustration. Und ja, ich kenne die ganze Rabulistik, die dazu dient, diesen offensichtlichen Sachverhalt wegzureden und habe auch keine Lust, das zu vertiefen. Das kann man anderswo nachlesen. TL;DR Python 2.x-Benutzer öffentlich zu beschimpfen wurde zehn Jahre lang versucht, es hat nicht funktioniert, jedenfalls nicht in der gewünschten Weise. Zeit, etwas anderes zu probieren.
William schrieb: r in unseren Scripten verwenden. > > Jetzt die Frage aller Fragen, wie gehe ich das Problem am besten an? Das tun, was ich vorschlug. Und dann den kompletten (!) Input und Output zeigen.
Wolfgang S. schrieb: > Bitte die Kollegen doch mal, den Output des Kommandos "chcp" (ohne > Argumente) mitzuteilen und vielleicht auch, was sich nach Eingabe von > "chcp 850" und dann Programmstart als Output ergibt. Du meinst das hier? >"chcp" (ohne Argumente) Code Page 437 > nach Eingabe von "chcp 850" und dann Programmstart als Output ergibt.
1 | UnicodeEncodeError: 'charmap' codec can´t encode character '\xf8' in |
2 | position 0: character maps to <undefined> test_script returned -1 |
Wenn das programm dann direkt nochmal gestartet wird geht es dann
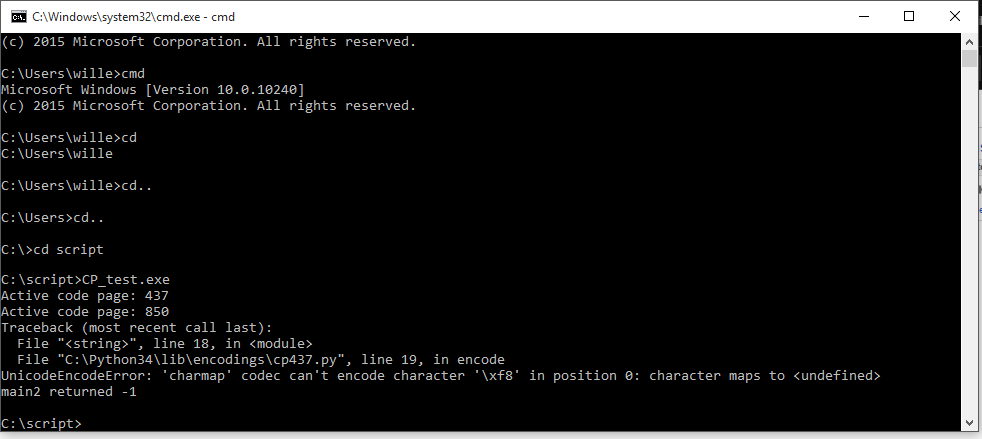
William schrieb: > Wolfgang S. schrieb: >> Bitte die Kollegen doch mal, den Output des Kommandos "chcp" (ohne >> Argumente) mitzuteilen und vielleicht auch, was sich nach Eingabe von >> "chcp 850" und dann Programmstart als Output ergibt. > > > > Du meinst das hier? > >>"chcp" (ohne Argumente) > > Code Page 437 Nein, denn das hattest Du ja schon geschrieben. > >> nach Eingabe von "chcp 850" und dann Programmstart als Output ergibt. > >
1 | UnicodeEncodeError: 'charmap' codec can´t encode character '\xf8' in |
2 | > position 0: character maps to <undefined> test_script returned -1 |
> > Wenn das programm dann direkt nochmal gestartet wird geht es dann Jetzt fehlt mir nur noch das Programm dazu. Mein Beispiel kann es nicht sein, denn das produziert auch mit Codepage 437 keinen Traceback. 0xf8 ist nicht utf-8, sondern ø in Latin-1 ø aka ø
# coding: utf-8
import os
os.system("chcp")
os.system("chcp 850")
print ("ø % ö ä ü ")
Ok, dann denke ich, dass ich in Eclipse nochmal nachsehen muss das alle
Dateien in UTF-8 gespeichert werden.
William schrieb: > # coding: utf-8 > import os > os.system("chcp") > os.system("chcp 850") > print ("ø % ö ä ü ") > > > Ok, dann denke ich, dass ich in Eclipse nochmal nachsehen muss das alle > Dateien in UTF-8 gespeichert werden. Ich denke eher, meine ursprüngliche Diagnose stimmt: Das Zeichen ø ist in der Codepage 437 nicht enthalten. Das Problem ist nicht, wie es im Programm codiert ist, sondern ob es in die gewünschte Outputcodierung überführt werden kann. Der erste chcp zeigt die beim Programmstart gültige Codepage, das ist die, welche Python 3.4 verwendet. Der zweite Aufruf setzt zwar die Codepage des aufrufenden Prozesses (cmd.exe), das hat auf den laufenden Python-Interpreter aber keine Wirkung mehr. Ob man die von Python verwendete Codepage für console output im laufenden Programm ändern kann bzw. wie, habe ich noch nicht herausgefunden, allerdings habe ich auch nicht intensiv gesucht. Mein Vorschlag bleibt, die Codepage vor Start des Programms auf 850 zu setzen.
Ich werde das mal testen. Ich denke das könnte gehen, wenn ich in main.py die codepage änder und dann die main2.py (das eigentliche script) importiere und ausführen lasse. Das zu mindestens als ersten Gedanken dazu. Ich danke dir vielmals und gebe ein Feedback ob das so funktioniert hat.
Das wird nicht gehen, der Interpreter ist derselbe auch wenn du ein import machst. Du müsstest schon einen neuen Prozess starten, wenn ich mich nicht sehr täusche.
William schrieb: > In dem Testscript habe ich alle Sonderzeichen in print reingeknallt was > wir in unseren Scripten verwenden. > > Jetzt die Frage aller Fragen, wie gehe ich das Problem am besten an? Hab ich doch schon geschrieben: * script in UTF-8 speichern * # -*- coding: utf-8 oben einbauen um python das auch mitzuteilen * print u"äöüß" anstelle von print "äöüß" Deine Fehlermeldung sagt aus daß Du den u-Prefix vergessen hast.
Bernd K. schrieb: > * print u"äöüß" anstelle von print "äöüß" > > Deine Fehlermeldung sagt aus daß Du den u-Prefix vergessen hast. print u macht keinen Unterschied. Python 3.4
Himmel, das u-Präfix ist tot seit 3.x, das existiert nur noch aus Kompatibilitätsgründen. Das wurde doch jetzt auch schon fünf mal gesagt.
Sven B. schrieb: > Himmel, das u-Präfix ist tot seit 3.x, das existiert nur noch aus > Kompatibilitätsgründen. Das wurde doch jetzt auch schon fünf mal gesagt Er hat ebenfalls gesagt daß das Script dort mit 2.7 ausgeführt wird.
Hier um Abnhang zur Demonstration wie das funktioniert. Problem gelöst, Thread kann geschlossen werden.
Bernd K. schrieb: > Hier um Abnhang zur Demonstration wie das funktioniert. Problem gelöst, > Thread kann geschlossen werden. Thema verfehlt. Wenn man den Teststring des Threaderöffners verwendet, stellt sich heraus, wie ich bereits vor einer Weile schrieb und vorführte, daß das Zeichen ø nicht encodiert werden kann, wenn die Codepage 437 eingestellt ist. Darauf, daß man unter 2.7 den u-Prefix verwendet sollte, hatte ich ebenfalls schon zu Beginn hingewiesen.
1 | #!/usr/bin/env python
|
2 | # -*- coding: utf-8 -*-
|
3 | |
4 | import sys |
5 | |
6 | # erstes: Den codoing header oben nicht vbergessen
|
7 | # zweitens: u-Prefix nicht vergessen, das macht Unicode-Strings
|
8 | # drittens: IDE so einstellen daß sie UTF-8 verwendet.
|
9 | |
10 | |
11 | # und los gehts...
|
12 | def main(): |
13 | print(sys.version) |
14 | print(sys.stdout.encoding) |
15 | print(u"dies geht noch: % ö ä ü ") |
16 | print(u"dies nicht mehr: ø % ö ä ü ") |
17 | |
18 | |
19 | # Das folgende Brimborium existiert haupsächlich
|
20 | # um die Konsole offen zu halten falls jemand es im
|
21 | # Explorer doppelklickt.
|
22 | if __name__ == '__main__': |
23 | try: |
24 | main() |
25 | except: |
26 | print(sys.exc_info()[0]) |
27 | import traceback |
28 | print(traceback.format_exc()) |
29 | finally: |
30 | print ("Press Enter to continue ...") |
31 | if sys.version_info[0] < 3: |
32 | raw_input() |
33 | else: |
34 | input() |
Und der Output
1 | C:\temp>python_UTF8_broken_with_cp437.py |
2 | 2.7.10 (default, May 23 2015, 09:44:00) [MSC v.1500 64 bit (AMD64)] |
3 | cp437 |
4 | dies geht noch: % ö ä ü |
5 | <type 'exceptions.UnicodeEncodeError'> |
6 | Traceback (most recent call last): |
7 | File "C:\temp\python_UTF8_broken_with_cp437.py", line 24, in <module> |
8 | main() |
9 | File "C:\temp\python_UTF8_broken_with_cp437.py", line 16, in main |
10 | print(u"dies nicht mehr: ø % ö ä ü ") |
11 | File "c:\python27\lib\encodings\cp437.py", line 12, in encode |
12 | return codecs.charmap_encode(input,errors,encoding_map) |
13 | UnicodeEncodeError: 'charmap' codec can't encode character u'\xf8' in position 1 |
14 | 7: character maps to <undefined> |
15 | |
16 | Press Enter to continue ... |
Daß das Programm diese Exception nicht wirft, wenn man auf den u-Prefix verzichtet, aber die Codepage 850 einstellt, sondern nur eine falsche Darstellung produziert, lasse ich mal als Übungsaufgabe stehen. :-)
Hi, kurzes Feedback. Ich habe eine Rückmeldung von den Kollegen erhalten. Die haben sich da etwas über eine Windows .bat gebastelt. Die startet erst du Konsole, stellt die Codeoage um und startet das eigentliche Programm. Ist ein kleiner Umweg, aber geht.
Ein besserer Ansatz wäre das Aufrufen der Win32-API-Funktion SetConsoleOutputCP aus dem Python-Programm heraus.
Rufus Τ. F. schrieb: > Ein besserer Ansatz wäre das Aufrufen der Win32-API-Funktion > SetConsoleOutputCP aus dem Python-Programm heraus. Besserer Ansatz als was? Auch win32console.SetConsoleOutputCP(850) hilft einem nicht aus der Sackgasse und das ist so dokumentiert: "Sets the output code page for calling process's console".
:
Bearbeitet durch User
William schrieb: > kurzes Feedback. Ich habe eine Rückmeldung von den Kollegen erhalten. > > Die haben sich da etwas über eine Windows .bat gebastelt. > > Die startet erst du Konsole, stellt die Codeoage um und startet das > eigentliche Programm. > > Ist ein kleiner Umweg, aber geht. Danke für die Rückmeldung. Dies ist jedenfalls ein sauberer Weg. Zwischenzeitlich habe ich ein wenig herumgelesen und hätte noch folgendes anzubieten:
1 | import codecs |
2 | sys.stdout = codecs.getwriter("850")(sys.stdout)
|
Mit Python 2.7.11 hat das die gewünschte unmittelbare Wirkung, daß auch "¢" ausgegeben werden kann. Mögliche negative Seiteneffekte habe ich nicht weiter untersucht. Unter Python 3.4 funktioniert das so nicht. Eine evtl. Lösung möge jemand aus der 3.x-Fraktion beisteuern, mir fehlt diesbezüglich jeder Ehrgeiz.
Wolfgang S. schrieb: > Besserer Ansatz als was? Ein besserer Ansatz als das per Batch zu machen. Ansonsten funktioniert die Ausgabe von Sonderzeichen in der Konsole nur dann wirklich brauchbar, wenn ein Truetype-Font verwendet wird. Die standardmäßig aktiven Pixelfonts (z.B. VGA850.FON) umfassen nur einen 8-Bit-Zeichensatz der bei der Installation des OS aktiven Codepage (das ist meistens CP850). Das lässt sich im Betrieb kaum sinnvoll wechseln.
Rufus Τ. F. schrieb: > Wolfgang S. schrieb: >> Besserer Ansatz als was? > > Ein besserer Ansatz als das per Batch zu machen. Ist es ja nicht. Per Batch läßt sich die Codepage vor dem Starten des Python-Interpreters einstellen, per win32console-Aufruf nicht. Man müsste also auch hier einen neuen Prozess starten. Das ist nun ganz bestimmt nicht eleganter oder einfacher, als in einer Aufruf-Batchprozedur die Codepage zu setzen. Da das Script ja offenbar mit Pyinstaller in ein exe verpackt werden soll, böte sich an, dessen runtime-hook in analoger Weise zu einer Batchprozedur zu verwenden, denn genau für so etwas ist der vorgesehen. "Path to a custom runtime hook file. A runtime hook is code that is bundled with the executable and is executed before any other code or module to set up special features of the runtime environment. This option can be used multiple times." Die Datails möge aber bitte der Threaderöffner (i.e. "William") selber untersuchen, denn das artet dann langsam doch in Arbeit aus. > Ansonsten funktioniert die Ausgabe von Sonderzeichen in der Konsole nur > dann wirklich brauchbar, wenn ein Truetype-Font verwendet wird. Mag im allgemeinen Fall so sein, ist aber eine ganz andere Baustelle. > Die > standardmäßig aktiven Pixelfonts (z.B. VGA850.FON) umfassen nur einen > 8-Bit-Zeichensatz der bei der Installation des OS aktiven Codepage (das > ist meistens CP850). Das lässt sich im Betrieb kaum sinnvoll wechseln. Mit dem ¢ gibt es jedenfalls auch mit den Rasterfonts kein Problem. Den vorhanden Satz an Zeichen und die Codierung kann man sich übrigens mit der kaum noch bekannten Utility "Zeichentabelle" anschauen.
Wolfgang S. schrieb: > Ist es ja nicht. Per Batch läßt sich die Codepage vor dem Starten des > Python-Interpreters einstellen, per win32console-Aufruf nicht. Das ist aber ein Unterschied. Im Batch-Fall wird die Codepage auch auf den Quelltext angewandt, im anderen Fall aber nur auf die Ausgabe. > Den vorhanden Satz an Zeichen und die Codierung kann man sich übrigens > mit der kaum noch bekannten Utility "Zeichentabelle" anschauen. Das ist charmap.exe, wenn man keine Lust hat, es in den Tiefen irgendwelcher Startmenüs o.ä. zu suchen, oder es auf einer nicht-deutsch lokalisierten Windows-Version sucht.
Rufus Τ. F. schrieb: > Das ist aber ein Unterschied. Im Batch-Fall wird die Codepage auch auf > den Quelltext angewandt, Unfug. Den Quelltext bekommt nur der Python-Interpreter zu Gesicht und der liest den direkt aus der Datei. Wie die Kodierung von stdout gerade eingestellt ist kümmert ihn nur wenn er was auf stdout ausgeben will und umcodieren muss.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.