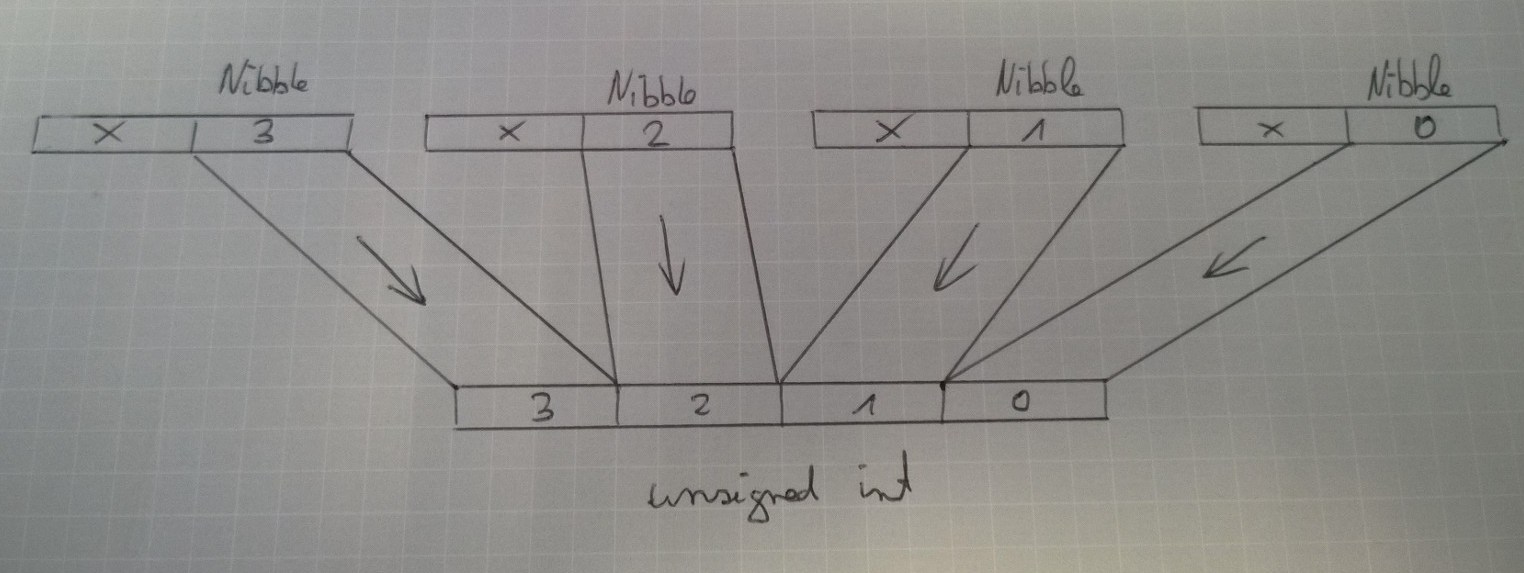
Hallo, hat jemand eine Idee wie ich die 4 LSB aus dem oberen vier char rauslöse und auf einen 16Bit unsigned int packen kann? Klar geht das mit schieben- dauert aber zu lange, geht da was mit Struct oder Unions ?
Angehängte Dateien:
-

WP_20160616_11_11_08_Pro.jpg
160 KB
Richi D. schrieb: > Klar geht das mit schieben- dauert aber zu lange, geht da was mit Struct > oder Unions ? Selbst wenn es ginge, warum denkst Du daß das notwendige Maskieren und Schieben dann schneller gehen sollte als wenn Du das das notwendige Maskieren und Schieben explizit hinschreibst?
Hallo, schieben dauert einige µs. Ich habe hier zum Beispiel mit ner Union/Struct eine Funktion die aus 4x 8-bit Werten einen 32 Bit Wert macht- dauert 8 clocks...
Richi D. schrieb: > schieben dauert einige µs. > > Ich habe hier zum Beispiel mit ner Union/Struct eine Funktion die aus 4x > 8-bit Werten einen 32 Bit Wert macht- dauert 8 clocks... und was sagt uns das? Wie sollen wir clocks und µs vergleichen? Auch Struct können nicht zaubern uns sind im allgemeinen langsamer als wenn man es von Hand optimiert.
>Ich habe hier zum Beispiel mit ner Union/Struct eine Funktion die aus 4x >8-bit Werten einen 32 Bit Wert macht- dauert 8 clocks... Natürlich ganz ohne Schieben und so... Gruß J
Richi D. schrieb: > schieben dauert einige µs. Also bei mir dauert die obige Aufgaben unter einer 1 µs.
Richi D. schrieb: > hat jemand eine Idee wie ich die 4 LSB aus dem oberen vier char rauslöse > und auf einen 16Bit unsigned int packen kann? > > Klar geht das mit schieben- dauert aber zu lange Wieso? Es gibt duchaus MCUs, die einen SWAP-Befehl kennen, also Low- und High-Nibble vertauschen können. Damit wäre Deine Operation ganz ohne log. Shift-Operationen umsetzbar. Falls der Compiler zu "dumm" ist, muss man eben zum Assembler greifen. Grüßle, Volker.
Also das hier dauert gemessene 2µs bei 32MHz, 16 Bit PIC:
1 | SENSORWERT_32 = MAKE32(DIGITALWERT[2], DIGITALWERT[3], DIGITALWERT[4], DIGITALWERT[5]); |
Zeigt mir mal wie ihr das mit schieben schafft... unmöglich!
Richi D. schrieb: > Hallo, > > schieben dauert einige µs. > > Ich habe hier zum Beispiel mit ner Union/Struct eine Funktion die aus 4x > 8-bit Werten einen 32 Bit Wert macht- dauert 8 clocks... Kannst Du endlich mal mit dem Rumgeeiere aufhören. Also konkret, was braucht mit welchem Code auf welcher Maschine wie lange. Und warum muß es wie schnell sein, d.h. wieviel % CPU-Load wird damit verbraucht und wieviel steht zur Verfügung.
Richi D. schrieb: > Zeigt mir mal wie ihr das mit schieben schafft... unmöglich! wer sagt schieben? je, nach Plattform geht einfach ein memcpy
1 | memcpy( &SENSORWERT_32, &DIGITALWERT[2], 4 ); |
>Zeigt mir mal wie ihr das mit schieben schafft... unmöglich!
Auch MAKE32 mainpuliert die Daten im RAM mit Instruktionen wie shift und
masken, wie anders stellst du dir das den vor?
>je, nach Plattform geht einfach ein memcpy
1 | memcpy( &SENSORWERT_32, &DIGITALWERT[2], 4 ); |
Um 4 Nibbles zu kopieren?
Richi D. schrieb: > Zeigt mir mal wie ihr das mit schieben schafft... unmöglich! Es geht hier im Thread nicht um Bytes, die in einen Long "umgewandelt" werden sollen (das ist so derart unglaublich simpel, weil ein Long im Speicher sowieso 4 Bytes hintereinander sind), sondern um das filetieren von 4 Bytes und das Zusammenfassen dieser Nibbles (falls dieser Begriff nicht ganz geläufig ist: https://de.wikipedia.org/wiki/Nibble) in 2 Bytes. DAS geht nicht mit memcpy(), weil memcpy() nicht mit Nibbles arbeiten kann...
:
Bearbeitet durch Moderator
arr schrieb: > Auch MAKE32 mainpuliert die Daten im RAM mit Instruktionen wie shift und > masken, wie anders stellst du dir das den vor? Da klappt noch der Byteweise zugriff über eine union.
Richi D. schrieb: > Klar geht das mit schieben- dauert aber zu lange Das liegt aber nicht am Schieben, denn in ASM sind das wenige swap, andi und or. Das liegt daran, daß der Compiler unter C gern mal ein eigentlich unnötiges Multiply aus einem Shift macht. Ist mir schon mehrfach aufgefallen und läßt sich nur schwer abstellen. Schau Dir mal das Compilat an.
Richi D. schrieb: > Klar geht das mit schieben- dauert aber zu lange, Auf einem AVR 'inline' 24 Takte.
1 | uint16_t concat(uint8_t a, uint8_t b, uint8_t c, uint8_t d){ |
2 | return (a&0xf)|(b<<4)|((uint16_t)(c&0xf)<<8)|((uint16_t)d<<12); |
3 | }
|
macht der avr-gcc zu:
1 | 000001ca <concat>: |
2 | 1ca: 4f 70 andi r20, 0x0F ; 15 |
3 | 1cc: 30 e0 ldi r19, 0x00 ; 0 |
4 | 1ce: 32 2f mov r19, r18 |
5 | 1d0: 22 27 eor r18, r18 |
6 | 1d2: 32 95 swap r19 |
7 | 1d4: 30 7f andi r19, 0xF0 ; 240 |
8 | 1d6: 34 2b or r19, r20 |
9 | 1d8: 8f 70 andi r24, 0x0F ; 15 |
10 | 1da: 90 e1 ldi r25, 0x10 ; 16 |
11 | 1dc: 69 9f mul r22, r25 |
12 | 1de: b0 01 movw r22, r0 |
13 | 1e0: 11 24 eor r1, r1 |
14 | 1e2: 68 2b or r22, r24 |
15 | 1e4: c9 01 movw r24, r18 |
16 | 1e6: 86 2b or r24, r22 |
17 | 1e8: 97 2b or r25, r23 |
18 | 1ea: 08 95 ret |
Das sind 16/17 Befehle (je nachdem ob man ret dazuzählt). Afaik ist jeder der enthaltenen Befehle single-cycle (OK, mul nicht), also braucht ein AVR bei 16Mhz Takt ziemlich genau 1 µs für diese Operation. Das sollte doch reichen.. €dit: mul is nich single-cycle
:
Bearbeitet durch User
Um welche CPU geht es denn überhaupt? Das ist schon wichtig zu wissen. Ein Corei7 z.B. schafft das in unter einem Cycle mit dem pext Befehl.
Nils P. schrieb: > Um welche CPU geht es denn überhaupt? Das ist schon wichtig zu wissen. Vermutlich um: Richi D. schrieb: > 32MHz, 16 Bit PIC Wobei dem Threadersteller nicht klar zu sein scheint, was der Compiler aus einer Funktion wie make32() generiert. (und die nebenbei bemerkt sein Problem nicht löst)
:
Bearbeitet durch User
Max D. schrieb: > return (a&0xf)|(b<<4)|((uint16_t)(c&0xf)<<8)|((uint16_t)d<<12); Echt scharf! Nur die Reihenfolge ist invers ...
Die Kernfrage bleibt aber immer noch: Wieviel % CPU-Zeit belegt welcher Code bezogen auf das gesamte Programm und wieviel % wären verkraftbar. Natürlich soll eine CPU nicht permanent mit 100% laufen, aber bei 0,1% CPU-Last mache ich keinen Finger mehr krumm für Optimierungen. Da die Funktion sehr kurz ist, kann es nur sein, daß sie extrem häufig (>100kHz?) aufgerufen wird, um eine hohe CPU-Last zu bewirken. Konkrete Angaben wären daher von Vorteil.
Richi D. schrieb: > Also das hier dauert gemessene 2µs bei 32MHz, 16 Bit PIC: > SENSORWERT_32 = MAKE32(DIGITALWERT[2], DIGITALWERT[3], DIGITALWERT[4], > DIGITALWERT[5]); > Zeigt mir mal wie ihr das mit schieben schafft... unmöglich! Bei 16MHz AVR und GCC ( aber mit Wertzuweisung beim Aufruf und nochmaliger Wertzuweisung beim return) dauert es genau so lange. Ohne Wertzuweisung ist es 1us. Mit Assembler und Wertzuweisung dauert es 20 Takte oder 1.25us. Ohne Wertzuweisung sind es 0.5us. Wie schnell hättest du es gerne ? 1-2 Takte ?
:
Bearbeitet durch User
Wahrscheinlich ein klassischer Fall von "premature optimization". Die ja bekanntlich die Wurzel alles Bösen ist. :-)
Mark B. schrieb: > Wahrscheinlich ein klassischer Fall von "premature optimization". > Die ja > bekanntlich die Wurzel alles Bösen ist. :-) Wird häufig in Haus- oder Übungsaufgaben angewendet. :)
Ich wollte hier keine große Diskussion auslösen und es ist immer das gleiche: jemand stellt ne Frage, da wird dann gleich der Sinn dahinter in Frage gestellt, völlig vom Thema abgewichen und alle stellen einen als Deppen hin. Ich wollte aus guten Grund eine andere Lösung als Schiebeoperationen- ihr habt auch keine andere Lösung, also hört auf hier den Thread voll zu müllen! Für die die sich bemüht haben: Danke. Es geht genauer um einen PIC24FJ. Ich verwende den C30 Compiler.
Richi D. schrieb: > Ich wollte aus guten Grund eine andere Lösung als Schiebeoperationen- > ihr habt auch keine andere Lösung, also hört auf hier den Thread voll zu > müllen! Meinen Hinweis auf den SWAP-Befehl hast Du gelesen (und verstanden)? Grüßle, Volker.
Richi D. schrieb: > Ich wollte aus guten Grund eine andere Lösung als Schiebeoperationen- Der "gute Grund" würde uns sehr interessieren!
Richi D. schrieb: > Ich wollte hier keine große Diskussion auslösen und es ist immer das > gleiche: jemand stellt ne Frage, da wird dann gleich der Sinn dahinter > in Frage gestellt Das muss man tun, wenn man den Job eines Informatikers oder Ingenieurs richtig machen will. > Ich wollte aus guten Grund eine andere Lösung als Schiebeoperationen Wenn es einen guten Grund gibt, dann kannst Du ihn doch sicher benennen? "Zu langsam" ohne Angabe dessen, wie schnell es denn sein müsste, ist keine sinnvolle Begründung. > ihr habt auch keine andere Lösung Das kann in manchen Fällen durchaus daran liegen, dass eine solche nicht existiert.
Mark B. schrieb: > Das kann in manchen Fällen durchaus daran liegen, dass eine solche nicht > existiert. Ich kann das hier zwar nur für den gcc auf einem AVR nachvollziehen... Aber von den Schiebeoperationen im Quelltext bleibt im Assemblercode nichts mehr übrig.
Ralf G. schrieb: > Ich kann das hier zwar nur für den gcc auf einem AVR nachvollziehen... > Aber von den Schiebeoperationen im Quelltext bleibt im Assemblercode > nichts mehr übrig. Ich könnte mir gut vorstellen dass es beim Microchip-Compiler nicht viel anders aussieht. Habe allerdings keinen da um das zu testen.
Richi D. schrieb: > Klar geht das mit schieben- dauert aber zu lange Ohne hier kurz auch nur einen Gedanken daran zu verschwenden. Rechne (oder überschlage) einfach mal kurz wie lange das wirklich dauert und wo du hin willst von der Zeit her. Das sind einfachste Operationen geschickt programmiert kommst du hier nicht schneller weg als Verunden und Schieben.
Angehängte Dateien:
-

ShiftLeft_PIC24FJ64.PNG
5,1 KB -

Swap_PIC24FJ64.PNG
5,5 KB


Richi D. schrieb: > und alle stellen einen als Deppen hin. Wo genau haben dich "alle" als Deppen hingestellt? > Ich wollte hier keine große Diskussion auslösen und es ist immer das > gleiche: jemand stellt ne Frage, da wird dann gleich der Sinn dahinter > in Frage gestellt, völlig vom Thema abgewichen Wenn man sich die interne Struktur und den Aufbau eines Prozessors mal genauer anschaut, dann sieht man, dass es ohne Schieben nur dann geht, wenn der Prozessor einen Nibble-Swap beherrscht. Alternativ reicht es, wenn er einen Barrelshifter hat. > Es geht genauer um einen PIC24FJ. Ich verwende den C30 Compiler. Diese Information kommt tatsächlich reichlich spät. Denn die Umsetzung eines Hochsprachen-Quelltextes in Maschinencode hängt genau zu 100% von diesen beiden Faktoren ab. > Es geht genauer um einen PIC24FJ. Du hast Glück: der hat einen Barrelshifter. Und kennt auch den SWAP-Befehl. Eigentlich kann man erst ab jetzt (und eigentlich erst mit dem Wissen, welche Version des Compilers) eine brauchbare und verbindliche Aussage machen. Und wenn man das nicht gesagt bekommt, dann ist das hier kein Wunder: > da wird dann gleich der Sinn dahinter in Frage gestellt, völlig vom > Thema abgewichen Wir konnten bisher gar nicht vom Thema abweichen, weil ein Thema gar nicht hinreichend definiert war. > Ich wollte hier keine große Diskussion auslösen und es ist immer das > gleiche: jemand stellt ne Frage, da wird dann gleich der Sinn dahinter > in Frage gestellt Und es wäre eigentlich immer gut, wenn man dann darauf eine Antwort hat...
:
Bearbeitet durch Moderator
Bisher weiß ja niemand, welcher Code zu lange dauern soll. Er hat ihn ja nirgends gezeigt. Daher kann ihn natürlich auch niemand schneller machen. Und dann noch sich darüber beschweren.
Mark B. schrieb: > Wahrscheinlich ein klassischer Fall von "premature optimization". > Die ja bekanntlich die Wurzel alles Bösen ist. :-) http://xkcd.com/1691/
Richi D. schrieb: > Klar geht das mit schieben- dauert aber zu lange, geht da was mit Struct > oder Unions ? Wenn Du schon Taktzyklen zählst, dann ist C einfach die falsche Sprache. Der Kompiler nutzt die Möglichkeiten der CPU schon recht gut aus. Ob da noch geschoben wird, wage ich zu bezweifeln. Ein Stück Assembler in Deinen C-Code einzubauen wird Dich aber auch nicht weiter bringen, da Einsprung, Übergabe, Register retten Dir die Zeit wieder zunichte macht. Also das ganze Programm in ASM. Oder eine flottere CPU nehmen. Ich werkle hier derzeit mit PIC32MZ. Der erledigt das problemlos in 100ns. Richi D. schrieb: > Ich wollte hier keine große Diskussion auslösen Wozu sind Foren sonst da? Ist wieder so eine 'fordern'-Geschichte!? > und es ist immer das > gleiche: jemand stellt ne Frage, da wird dann gleich der Sinn dahinter > in Frage gestellt, völlig vom Thema abgewichen und alle stellen einen > als Deppen hin. Natürlich werden Fragen dazu gestellt. Möglicherweise ist auch Deine ganze Herangehensweise falsch. Und so, wie Du mit der gesamten Materie umgehst sogar wahrscheinlich. Wenn ich eine Frage stelle, dann freue ich mich in aller Regel, wenn mir jemand einen besseren Weg zeigen kann. > Ich wollte aus guten Grund eine andere Lösung als Schiebeoperationen- Nein. Dein Grund ist Blödsinn, denn Lothar M. schrieb: > Du hast Glück: der hat einen Barrelshifter. ... den der Compiler auch nutzen wird! > ihr habt auch keine andere Lösung, also hört auf hier den Thread voll zu > müllen! Wie gesagt, man könnte Dir helfen. Aber Du lässt es erst gar nicht zu, weil dann möglicherweise Kritik kommt. Und: Die CPU schiebt beliebig viele Schritte in einem Arbeitstakt. Schneller geht mit der CPU nicht. Gruß Jobst
:
Bearbeitet durch User
Es geht auch ohne Schiebeoperationen.
1 | union u { |
2 | uint16_t all; |
3 | |
4 | struct { |
5 | uint16_t a : 4; |
6 | uint16_t b : 4; |
7 | uint16_t c : 4; |
8 | uint16_t d : 4; |
9 | };
|
10 | } un1; |
11 | |
12 | uint16_t concat(uint8_t a, uint8_t b, uint8_t c, uint8_t d) { |
13 | |
14 | un1.a = a; |
15 | un1.b = b; |
16 | un1.c = c; |
17 | un1.d = d; |
18 | |
19 | return un1.all; |
20 | }
|
Auf dem PC X86-64 GCC mit -O2 ergibt das:
1 | .globl concat2 |
2 | .type concat2, @function |
3 | concat2: |
4 | .LFB13: |
5 | .loc 1 71 0 |
6 | .cfi_startproc |
7 | .LVL24: |
8 | .loc 1 75 0 |
9 | sall $4, %esi |
10 | .LVL25: |
11 | andl $15, %edi |
12 | .LVL26: |
13 | .loc 1 77 0 |
14 | sall $4, %ecx |
15 | .LVL27: |
16 | andl $15, %edx |
17 | .LVL28: |
18 | .loc 1 75 0 |
19 | orl %edi, %esi |
20 | .loc 1 77 0 |
21 | orl %ecx, %edx |
22 | .loc 1 75 0 |
23 | movb %sil, un1(%rip) |
24 | .loc 1 77 0 |
25 | movb %dl, un1+1(%rip) |
26 | .loc 1 80 0 |
27 | movzwl un1(%rip), %eax |
28 | ret |
29 | .cfi_endproc |
Das sind 9 Zeilen Assemblercode. Der PIC24 hat "bit insert" und "bit extract" Operationen, da könnte das noch kompakter ausfallen.
:
Bearbeitet durch Moderator
c-lover schrieb: > Auf dem PC X86-64 GCC mit -O2 ergibt das: > Das sind 9 Zeilen Assemblercode. Nein, es sind mehr, aber egal. > Der PIC24 hat "bit insert" und "bit extract" Operationen, da könnte das > noch kompakter ausfallen. Mit i7-5960X dürfte es noch ein bisschen kompakter und schneller sein. Weisst du überhaupt wovon hier die Rede ist ?
Marc V. schrieb: > Weisst du überhaupt wovon hier die Rede ist ? Ja, glaube schon. Richi D. schrieb: > hat jemand eine Idee wie ich die 4 LSB aus dem oberen vier char rauslöse > und auf einen 16Bit unsigned int packen kann? > > Klar geht das mit schieben- dauert aber zu lange, geht da was mit Struct > oder Unions ? Da geht was mit Struct und Unions, und wenn der Controller bit insert kann, dann kann der C-Compiler sehr schnellen und kompakten Code für den Zugriff auf Bitfields in Structs generieren. Aber ich habe mich geirrt, der PIC32 hat bit insert und bit extract Operationen, der PIC24 kann nur einzelne Bits setzen oder testen. So sieht's beim PIC32 aus:
1 | 10: union u {
|
2 | 11: uint16_t all; |
3 | 12: |
4 | 13: struct {
|
5 | 14: uint16_t a : 4; |
6 | 15: uint16_t b : 4; |
7 | 16: uint16_t c : 4; |
8 | 17: uint16_t d : 4; |
9 | 18: }; |
10 | 19: } un1; |
11 | 20: |
12 | 21: uint16_t concat2(uint8_t a, uint8_t b, uint8_t c, uint8_t d) {
|
13 | 9D000110 308400FF ANDI A0, A0, 255 |
14 | 9D000114 30A500FF ANDI A1, A1, 255 |
15 | 9D000118 30C600FF ANDI A2, A2, 255 |
16 | 9D00011C 30E700FF ANDI A3, A3, 255 |
17 | 22: //union u un1; |
18 | 23: |
19 | 24: un1.a = a; |
20 | 9D000120 97828010 LHU V0, -32752(GP) |
21 | 9D000124 7C821804 INS V0, A0, 0, 4 |
22 | 25: un1.b = b; |
23 | 9D000128 7CA23904 INS V0, A1, 4, 4 |
24 | 26: un1.c = c; |
25 | 9D00012C 7CC25A04 INS V0, A2, 8, 4 |
26 | 27: un1.d = d; |
27 | 9D000130 7CE27B04 INS V0, A3, 12, 4 |
28 | 9D000134 A7828010 SH V0, -32752(GP) |
29 | 28: |
30 | 29: return un1.all; |
31 | 30: } |
32 | 9D000138 03E00008 JR RA |
33 | 9D00013C 3042FFFF ANDI V0, V0, -1 |
Vielleicht ist das Problem ja ganz simpel: Der C30 ist eben ein Profi-Compiler, d.h. der will bezahlt werden wenn er mehr als -O0 machen soll, sprich optimieren. Der AVR-GCC ist ein Amateur-Compiler, d.h. der will zum optimieren überredet werden. Und wenn man ihn rumkriegt, dann macht er dieses "Pack nibbles" auch mit 2 swap's und ohne mul 16. Warnung: Nicht jedes Wort in diesem Post ist wider dem tierischen Ernst.
c-lover schrieb: > Es geht auch ohne Schiebeoperationen. > sall $4, %ecx Ich bin mir jetzt allerdings fast sicher, dass "sall" doch eine Schiebeoperation ist... c-lover schrieb: > der PIC32 hat bit insert und bit extract Operationen Und auch die verwenden implizit den Barrelshifter. Denn das Problem des TO ist eben nur entweder mit Schieben oder mit einem Nibble-Swap zu lösen, weil ein Prozessor keinen Nibble-orientierten Speicher hat, sondern als kleinste einheit nur Bytes adressieren kann. Dei letzten 4-Bit-Nibble-Prozessoren (ja, sowas gab es) sind Ende letztes Jahrtausends ausgestorben... Carl D. schrieb: > Der AVR-GCC ist ein Amateur-Compiler Knapp daneben, denn Richi D. schrieb: > Es geht genauer um einen PIC24FJ. Ich verwende den C30 Compiler.
:
Bearbeitet durch Moderator
Aufgabenstellung: uint16_t x = (Byte3 & 0x0F)*2^12 + (Byte2 & 0x0F)*2^8 + (Byte1 & 0x0F)*2^4 +(Byte0 & 0x0F) Welche Implementierung in einem gegebenen uC ist die schnellste ? Lösungsansatz: Da sich der Rechenbedarf nie ändert (Anzahl der Operationen ist nicht abhängig von den Werten der Variablen) kann man das mit Zählen der benötigten Takte pro benötigtem Maschinenbefehl lösen. Hat die CPU Recheneinheiten für höhere Mathefunktionen wird das vielleicht schneller sein als reine Logikoperationen. Wenn Byteoperationen zur Verfügung stehen kann ein aufteilen von uint16_t x in uint8_t x[2] sinnvoll sein, damit man bei den Potenzen Rechenschritte sparen kann. Logisches UND als elementare Funktion kann nicht beschleunigt werden. Gruß, dasrotemopped.
Ach ja, hat der uC mehrere gleichwertige Register, auf die alle Rechenoperationen angewendet werden können oder nur einen Akkumulator? Ggf. fallen noch MOV Befehle an um die Zwischenergebnisse umzukopieren. Muss man bei der Laufzeit mitbedenken. Gruß, dasrotmeopped.
Nils P. schrieb: > Um welche CPU geht es denn überhaupt? Das ist schon wichtig zu wissen. > Ein Corei7 z.B. schafft das in unter einem Cycle mit dem pext Befehl. Der muss in dem Fall auch mehrmals PEXT und PDEP/shifts machen, wenn man BMI verwenden kann/will. Kann man das vielleicht so umbauen, dass von vornherein nur das eine Wort genommen wird oder die 4 Byte passend hintereinander stehen? Dann geht das echt mit einem PEXT.
in: r16, r17, r18, r19, low Nibbles out: r20, r21
1 | andi r16, 0x0F |
2 | andi r17, 0x0F |
3 | andi r18, 0x0F |
4 | andi r19, 0x0F |
5 | mov r20, r17 |
6 | swap r20 |
7 | or r20, r16 |
8 | mov r21, r19 |
9 | swap r21 |
10 | or r21, r18 |
10 Takte im AVR. Keine Ahnung, ob der PIC diese Befehle auch so verwursten kann. Und die Anforderung des TO wird erfüllt: Es wird nicht geschoben. ;-)
Chris F. schrieb: > Kann man das vielleicht so umbauen, dass von vornherein nur das eine > Wort genommen wird oder die 4 Byte passend hintereinander stehen? Dann > geht das echt mit einem PEXT. Das kannst du machen, wie du willst! Denn: Richi D. schrieb: > Ich wollte hier keine große Diskussion auslösen [...] > Für die die sich bemüht haben: Danke.
Timm T. schrieb: > in: r16, r17, r18, r19, low Nibbles > out: r20, r21 [OT - weil AVR]
1 | byte16_set: |
2 | andi r24, 0x0F |
3 | andi r25, 0x0F |
4 | swap r25 |
5 | or r24, r25 |
6 | andi r26, 0x0F |
7 | mov r25, r26 |
8 | andi r27, 0x0F |
9 | swap r27 |
10 | or r25, r27 |
11 | ret |
[/OT] Wenn ich mich nicht verhauen habe, müsste das mit diesen Registern sogar den Aufrufkonventionen vom gcc entsprechen, so dass die Funktion, so wie sie ist, in eine Datei und zum Projekt dazu gepackt werden kann.
War also doch Käse... :-(
1 | byte16_set: |
2 | andi r24, 0x0F |
3 | andi r22, 0x0F |
4 | swap r22 |
5 | or r24, r22 |
6 | andi r20, 0x0F |
7 | mov r25, r20 |
8 | andi r18, 0x0F |
9 | swap r18 |
10 | or r25, r18 |
11 | ret |
So müsste es jetzt richtig sein.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.