Hi, ich habe einen kleinen Server, wo ich eine OwnCloud drauf betreibe. Der Disk-Platz ist leider begrenzt, daher habe ich mir überlegt, ob man den Datenfolder von OwnCloud komprimieren kann. Die etwas schlechtere Geschwindigkeit würde ich in Kauf nehmen, da die Internetanbindung des Servers eh nicht so schnell ist. OwnCloud selber kann meines Wissens keine Kompression, ich habe mir aber überlegt, einen btrfs-Container anzulegen und zu mounten, der Owncloud Datenfolder kommt dann dort zu liegen. Was mich bisher von btrfs abschreckt: es wird als experimental bezeichnet. Läuft es stabil genug, dass man es für diese Anwendung einsetzen kann, oder gibt es Alternativen? Grüsse Tobias
Tobias P. schrieb: > Was mich bisher von btrfs abschreckt: es wird als experimental > bezeichnet. Läuft mittlerweile stabil so wie man in letzter Zeit hört, einige Distributionen bieten das sogar mittlerweile bei der Installation per Default anstelle von ext4 an. und wenn das eh nur ein Fileserver sein soll dann sind die Zugriffsmuster ja nicht so komplex daß man noch in ungetestete Szenarien reinstolpern könnte. Ich hab btrfs übrigens auf meiner externen Backup-Platte (mit compress-force=lzo um Zeit und Platz zu sparen) um damit inkrementelle Backups zu machen (mit rsync und subvolume snapshot anstelle der klassischen Methode rsync --link-dest), das läuft 5 Mal schneller als die Hardlink-Farm und bisher ohne Probleme. Ich habs vor einigen Jahren auch mal auf meinem alten Laptop genutzt für das gesamte root und home und es war performant und vollkommen problemlos, keine bösen Überraschungen. Das einzige was es nicht mochte und mit Schneckentempo bestrafte war die vollkommen überzogene fsync Orgie von apt-get und dpkg. Das hab ich jedoch kurzerhand mit Snapshots und eatmydata gekontert. Das Snapsot Feature ist schlichtweg genial.
btrfs läuft bei mir in 2-Disk Redundanz seit l,5 Jahren stabil auf dem heimatliches Fileserver. Allerdings ohne Komprimierung.
> es wird als experimental bezeichnet
Vermutlich haben die Linux-Frickler noch nicht einmal
einen fs-Debugger dafuer fertig.
Oder ein funktionierendes Dump/Restore mit dem auch bei
gemountetem Filesystem nicht nur Schrott gesichert wird.
Aber die tollen Features reissen ja wohl alles raus...
Meine letzte Erfahrung mit Btrfs schloss erzwungenen Read-only Modus durch den Kernel und korrupte Lesezugriffe mit ein. Hatte davor aber problemlos funktioniert, kann also sein, dass das ein kernelspezifisches Problem war. momentan liegt mein Backup in einem SquashFS auf XFS. SquashFS ist Read-only; Backuperstellung dauert entsprechend lange (aber: unschlagbare Kompression).
./. schrieb: > Oder ein funktionierendes Dump/Restore mit dem auch bei > gemountetem Filesystem nicht nur Schrott gesichert wird. Schau Dir mal das btrfs Dateisystem und dessen Tools an, ich glaube das bietet alles was Du brauchst.
Danke erstmal für eure Tips. Dann werde ich mir mal keine weiteren Sorgen wegen des 'experimental' machen. Ich habe folgendes Vorgehen gewählt, für Testzwecke: zuerst ein 100GB leeres Image erstellen:
1 | truncate -s 100G disk.img |
danach ein btrfs-System erstellen:
1 | mkfs.btrfs disk.img |
Dieses dann in einen Ordner mounten...
1 | mkdir disk_test |
2 | mount -o loop,compress-force=lzo disk.img disk_test |
danach kann man Files in den disk_test Ordner rein kopieren. Spricht etwas gegen dieses Vorgehen? Kann ich den disk_test Ordner in die fstab eintragen, um ihn beim Booten wieder zu mounten? Grüsse Tobias
Bernd K. schrieb: > Ich hab btrfs übrigens auf meiner externen Backup-Platte (mit > compress-force=lzo um Zeit und Platz zu sparen) um damit inkrementelle > Backups zu machen (mit rsync und subvolume snapshot anstelle der > klassischen Methode rsync --link-dest), das läuft 5 Mal schneller als > die Hardlink-Farm und bisher ohne Probleme. Mache ich auch so, allerdings ohne Kompression, weil Daten schon komprimiert. Snapshots sind schon genial will ich nicht mehr missen. War lange kein Freund von btrfs, überzeugt mich aber immer mehr, zerschossen hat es bis jetzt auch noch nix.
Tobias P. schrieb: > compress-force=lzo Wenn Die CPU in Deinem Server ein paar Kerne zu viel hat die sich sonst nur langweilen kannst Du auch mal compress-force=zlib probieren, das komprimiert noch besser (wenn die Dateien überhaupt komprimierbar sind), aber je nachdem wie schnell Du auf die Festplatte schreiben kannst könnte das schon das alle Kerne an den Anschlag treiben. Bei mir aufm Desktop (6*3.5GHGz) geht da schon der Lüfter an bei einigen Dateien, selbst bei der lahmen USB-2.0 Platte. Ob das einen Vorteil bringt musst Du durch Zeit- und Platzmessung bei einigen repräsentativen großen Dateien ermitteln. Beim Lesen jedoch kanns durch stärkere Kompression nur schneller werden.
Tobias P. schrieb: > Was mich bisher von btrfs abschreckt: es wird als experimental > bezeichnet. Das hat einen einfachen Grund: Ein Dateisystem ist etwas sehr wichtiges und kritisches. Bevor sich die Kernelentwickler nicht zu 200% sicher sind, dass es keine Probleme gibt, wird der "Experimentell"-Status nicht entfernt. Diese harte Überprüfung dauert eben viele Jahre, auch wenn es bereits bestens funktioniert.
Von btrfs mit RAID 5 Redundanz sollte man allerdings die Finger lassen. http://sdtimes.com/btrfs-raid-code-needs-rewrite/
> mit RAID 5
RAID5 ist so "zuverlässig" wie eine Weihnachtsbaumbeleuchtung mit
Reihenschaltung. Solange die Platten aus der selben Charge sind, können
sie am gleichen Tag sterben. Gibt es schon ein Tool um dieses Filesystem
zuverlässig zu reparieren? Sonst wird es sehr interessant...
Wahrscheinlich würde ich eher schnellere, größere Platten kaufen als
Experimente zu machen.
./. schrieb: >> es wird als experimental bezeichnet > > Vermutlich haben die Linux-Frickler noch nicht einmal > einen fs-Debugger dafuer fertig. > Oder ein funktionierendes Dump/Restore mit dem auch bei > gemountetem Filesystem nicht nur Schrott gesichert wird. > > Aber die tollen Features reissen ja wohl alles raus... Wird es auch NIE geben. Der Hauptmaintainer vom VFS (Virtual File System) hat sogar die Aufnahme von tracepoints in seinem Zweig verweigert. Das Problem von solchen "internen" Strukturen ist, sie werden dann für irgendwelche (zum Teil nutzlose) Dinge genutzt die keinen Sinn ergeben. z.B. die Ausgabe der Taktfrequenz mit /proc/cpuinfo von der/die CPUs. Ein Programm hat es genutzt und hat irgendwie die Latenz berechnet. Fliegt dann aber auf die Fresse, weil mal die CPU (auch von selber) heruntertacktet.
Hans Ulli K. schrieb: > Wird es auch NIE geben. Du kannst nen read-only Snapsot machen während es gemountet und in Benutzung ist (das ist eine atomare Operation die keine Zeit benötigt) und dann mit btrfs send gemütlich woanders hinschicken zum Sichern. Das zumindest gibts also schon.
oszi40 schrieb: > RAID5 ist so "zuverlässig" wie eine Weihnachtsbaumbeleuchtung mit > Reihenschaltung. Dummer Vergleich. > Solange die Platten aus der selben Charge sind, können > sie am gleichen Tag sterben. Können sie. Tun sie aber jenseits der Anfangsausfälle nur mit extrem geringer Wahrscheinlichkeit. Jedenfalls nicht HDDs, bei den Alterungseffekten von SSDs kann das anders sein. RAID ersetzt keinen Backup und schützt auch nicht vor Brand oder Überschwemmung. Aber hier ging es die RAID 5/6 Funktion in btrfs, und vor der wird aus ganz anderem Grund abgeraten. Der entsprechende Code enthält böse Bugs.
A. K. schrieb: > Aber hier ging es die RAID 5/6 Funktion in btrfs, und vor der wird aus > ganz anderem Grund abgeraten. Der entsprechende Code enthält böse Bugs. Ich bin nach wie vor nicht davon überzeugt, daß es eine gute Idee<tm> ist, Filesystem und Redundanz-Layer an einer Stelle zu implementieren. Das md Subsystem funktioniert doch bestens. Ist das ein Fall von NIH? Ich bin jedenfalls restlos zufrieden mit md RAID5 (neuerdings 6) und XFS (neuerdings ext4, vorher reiserfs). 0 Datenverlust seit > 10 Jahren. Die Anzahl der Festplattendefekte (die meisten davon auf Garantie getauscht) dürfte mittlerweile zweistellig sein.
Axel S. schrieb: > Ich bin nach wie vor nicht davon überzeugt, daß es eine gute Idee<tm> > ist, Filesystem und Redundanz-Layer an einer Stelle zu implementieren. Synergieeffekte. Ein klassisches RAID System hat keine Ahnung davon, ob Blöcke verwendet werden oder nicht und muss sie daher immer so betrachten, als ob sie gültigen Inhalt haben. Integriert man die Redundanz ins Filesystem, dann ändert sich das. Und ein klassisches Filesystem kann sich mangels Kenntnis nicht der Geometrie des zugrunde liegenden Redundanzlayers anpassen (welche Blöcke mit welchen anderen zu einem RAID Datensatz zusammengefasst sind). Auf Anhieb fällt mir deshalb dazu ein: So müssen in Filesystemen mit integrierter Redundanz bei einer ausgefallenen Disk nur belegte Blöcke regeneriert werden, während ein separat arbeitender RAID-Layer auch eine fast leere Disk komplett regeneriert. Analoges gilt beim Scrubbing. RAID arbeitet effizienter, wenn die Paritätsdaten von RAID-5/6/... aus den zu schreibenden Daten direkt erzeugt werden können, ohne vorher Daten von Disk lesen zu müssen. Dabei ist es von Vorteil, wenn man auf unbelegte Blöcke keine Rücksicht nehmen muss. Das Schreibverhalten von COW Filesystemen erleichtert ebendiese schnelle Paritätsgenerierung, da grössere zusammenhängenden Schreibdaten zusammen kommen. Hier ist es aber von Vorteil, wenn das Filesystem die Geometrie der Redundanz kennt oder sie möglicherweise sogar ad hoc der aktuellen Situation anpassen kann.
In den letzte Jahren kommt der Begriff "bit rot" vermehrt auf. In modernen Filesystemen werden Metadaten wie Daten daher mit Checksums abgesichert, die an anderer Stelle als die dadurch abgesicherten Daten platziert sind. Das spielt allerdings erst dann seine ganze Qualität aus, wenn die Redundanz Teil des Filesystems ist, und kein getrennter Layer darunter.
Axel S. schrieb: > Ich bin nach wie vor nicht davon überzeugt, daß es eine gute Idee<tm> > ist, Filesystem und Redundanz-Layer an einer Stelle zu implementieren. Es ist eine sehr gute Idee und funktioniert in ZFS seit ueber 10 Jahren bestens, inbesonders bei riesigen Dateisystemen. BRTFS wuerde wahrscheinlich gar nicht existieren , wenn ZFS Lizenz-Kompatibel zum Linux-Kernel waere. Somit ist es ausser in Solaris, leider nur in BSD Unix'es ab Installations-CD vorhanden. Filesysteme dieser neuen Generation sind ideal fuer grosse Datenmengen. Wir bauen z. Zt. einen container-basierten Cluster mit einigen 100 Servern und ZFS als Storage-Platform. Axel S. schrieb: > Ich bin jedenfalls restlos zufrieden mit md RAID5 (neuerdings 6) und XFS > (neuerdings ext4, vorher reiserfs) ext4 gibt dir nicht die gleiche Performance wie XFS. Auf einer privaten Box merkt man das normlerweise nicht, aber im professionalen Bereich ist das ausschlaggebend (Hadoop,..). Das war einer der Hauptgruende, warum Redhat von ext4 zu SGI's XFS gewechselt ist (ZFS ging leider nicht). Allerdings kann man XFS im Gegensatz zu ext4 nicht verkleinern.
olibert schrieb: > Es ist eine sehr gute Idee und funktioniert in ZFS seit ueber 10 Jahren > bestens, Die älteste Information zu NetApps WAFL, die ich fand, ist von 1994. Da ist das auch schon integriert.
Hier zu btrfs: https://btrfs.wiki.kernel.org/index.php/Status https://btrfs.wiki.kernel.org/index.php/Main_Page#News_and_Changelog https://btrfs.wiki.kernel.org/index.php/Incremental_Backup Ich stehe ebenfalls gerade vor der Entscheidung für kleine Datenmengen (<50GByte). CRC wäre toll. Aber das aktuelle Changelog und der Status machen mir eine Entscheidung für btrfs nicht gerade leicht. Hat hier abgesehen von User "Jemand" bereits jemand Crashes (SW als auch defekte HDDs) mit btrfs gehabt? Bzgl der inkrementellen Snapshot Backups: Die sind dann nicht mehr Datei-basiert, richtig? Das möge in vielen Fällen ein Vorteil sein, bei mir aber lediglich beim Komfort. Sonst eigentlich nur nachteilig, denn den Platz für die Dateien habe ich genug.
Lars R. schrieb: > Hat hier abgesehen von User "Jemand" bereits jemand Crashes (SW als auch > defekte HDDs) mit btrfs gehabt? Ich hatte im 2-Disk btrfs einmal versehentlich eine der beiden Disks überschrieben. War problemlos per btrfs Redundanz lösbar.
Lars R. schrieb: > Bzgl der inkrementellen Snapshot Backups: Die sind dann nicht mehr > Datei-basiert, richtig? Richtig. > Sonst eigentlich nur nachteilig, Inwiefern nachteilig?
> Wird es auch NIE geben. > Der Hauptmaintainer vom VFS (Virtual File System) hat sogar die Aufnahme > von tracepoints in seinem Zweig verweigert. > Das Problem von solchen "internen" Strukturen ist, sie werden dann für > irgendwelche (zum Teil nutzlose) Dinge genutzt die keinen Sinn ergeben. Ein fs-Debugger ist wohl kaum sinnlos. Und ein konsistentes Dump/Restore vermissen vermutlich nur die, die sowas auch routinemaessig benutzen. Linuxfrickler sind ja noch beim tar stehengeblieben. Mich stoert es aber auch nicht. Wer Linux kennt, nimmt Solaris. (Und hat schon seit einigen Jahrzehnten ZFS und andere nette Dinge.)
WebDepp schrieb: > Bernd K. schrieb: >> Ich hab btrfs übrigens auf meiner externen Backup-Platte (mit >> compress-force=lzo um Zeit und Platz zu sparen) um damit inkrementelle >> Backups zu machen (mit rsync und subvolume snapshot anstelle der >> klassischen Methode rsync --link-dest), das läuft 5 Mal schneller als >> die Hardlink-Farm und bisher ohne Probleme. > Mache ich auch so, allerdings ohne Kompression, weil Daten schon > komprimiert. Snapshots sind schon genial will ich nicht mehr missen. Ja. Ich hab die sogar genutzt, ohne das überhaupt zu wissen. Ich hatte mich mal gewundert, warum die Platte so voll ist und dann festgestellt, dass mein Kubuntu bei jedem Upgrade auf die nächste Distributionsversion vorher einen Snapshot gemacht hat, so dass man auf die alte wieder zurück kann, wenn was schiefgehen sollte. So hatte ich dann inzwischen schon eine ganze Reihe von Snapshots gesammelt. Eigentlich sehr praktisch - wenn man's weiß. ;-) > War lange kein Freund von btrfs, überzeugt mich aber immer mehr, > zerschossen hat es bis jetzt auch noch nix. Ich kenne ein nerviges Problem, das allerdings die Datenintegrität nicht betrifft. Das Dateisystem kann in einen Zustand kommen, in dem es meldet, dass die Platte voll sei, obwohl noch jede Menge Platz ist. Soweit ich das Problem verstehe, ordnet btrfs einen Block entweder den Nutzdaten oder den Metadaten zu. Und wenn diese Zuordnung einmal gemacht ist, gibt es keinen einfachen Standardweg, das wieder zu ändern. Man merkt das ganz besonders dann, wenn die Platte voll ist und man wieder Platz macht. Ich hab da natürlich bevorzugt große Dateien zum löschen gesucht (Urlaubsvideos, die eh auf dem NAS gespeichert sind und nur zum Bearbeiten lokal lagen und so). Danach einen umfangreichen Quellcode dort entpackt, und dann kam die Meldung, dass das nicht geht, weil kein Platz mehr, obwohl einige Gigabytes frei waren. Hä!? Hab doch grad extra Platz gemacht! Erklärung: Wenn die Platte voll ist, sind natürlich alle Blöcke zugeordnet. Löscht man wenige große Dateien, werden vor allem Nutzdatenblöcke frei. Legt man dann sehr viele kleine Dateien an, wird aber natürlich viel Platz für die Metadaten benötigt, der dann nicht mehr zur Verfügung steht. Somit meldet das System eine volle Festplatte trotz vieler freier Nutzdatenblöcke. Die Lösung ist etwas dubios. Man soll das btrfs-Tool nutzen und ihm einen Wert übergeben. Falls dann nicht die Meldung kommt, dass was geändert wurde, soll man den Wert vergrößern und es nochmal probieren, so lange, bis Blöcke umgewidmet wurden. Dann hat man mit etwas Glück wieder Platz.
A. K. schrieb: > Lars R. schrieb: >> Hat hier abgesehen von User "Jemand" bereits jemand Crashes (SW als auch >> defekte HDDs) mit btrfs gehabt? > > Ich hatte im 2-Disk btrfs einmal versehentlich eine der beiden Disks > überschrieben. War problemlos per btrfs Redundanz lösbar. Ich dachte eher an abgestürzte Schreibvorgänge, Reboots/Stromausfälle ohne unmount, defekte Sektoren, in SMART gemeldete defekte Sensoren; Sektoren, usw. Die Frage ist doch, was passiert, wenn die Dinge "richtig" schief laufen. Problemloser Funktion im täglichen Betrieb sollte eigentlich selbstverständlich sein. Aber auch diesbezüglich bin ich mir unsicher. (Beitrag "Re: Linux Filesystem Kompression"). Kann oder könnte btrfs "weak sectors" erkennen? A. K. schrieb: > Lars R. schrieb: >> Bzgl der inkrementellen Snapshot Backups: Die sind dann nicht mehr >> Datei-basiert, richtig? > > Richtig. > >> Sonst eigentlich nur nachteilig, > > Inwiefern nachteilig? Ein Fehler im Backup in einer Datei in einem Snapshot macht macht alle nachfolgenden Backups dieser Datei unbrauchbar. Weiterhin habe ich noch nicht verstanden, ob ich auf den x-beliebigen Stand einer Datei einfach zugreifen kann. Die inkrementellen Backups sollten ja nicht differenziell zum Original sein, sondern zum vorherigen inkrementellen Backup.
Lars R. schrieb: > Hat hier abgesehen von User "Jemand" bereits jemand Crashes (SW als auch > defekte HDDs) mit btrfs gehabt? Leider ja. 2014 habe ich auf einem HP Microserver mit 2 * 6 TB OpenSuse mit Btrfs installiert. Der Server dient als billiges iSCSI-Target und hat sich zweimal hintereinander im Abstand von ca. vier Wochen das Filesystem zerschossen. Ich habe dann zu Zfs-on-Linux gewechselt und keinen Datenverlust mehr gehabt, obwohl sich später herausgestellt hat, dass eine Platte sporadisch einen Wackelkontakt hat. Zfs konnte das aber immer kompensieren. Ein Nachteil ist, dass man es nach jedem Kernelupdate selbst neu kompilieren muss und dass das Init-Script manchmal klemmt. Das Root-Filesystem habe ich klassisch mit MD-RAID und XFS eingerichtet. Ist natürlich nur meine persönliche Erfahrung.
Lars R. schrieb: > Weiterhin habe ich noch nicht verstanden, ob ich auf den x-beliebigen > Stand einer Datei einfach zugreifen kann. Kannst du. Jeder Snapshot sieht aus wie ein vollständiges Filesystem vom betreffenden Zeitpunkt. Die interne Arbeitsweise braucht dich beim Zugriff nicht zu interessieren. Das sieht genauso aus wie die auf Hardlinks basierenden Backups von rsync, nur dass es intern auf Block- statt Filebasis arbeitet. > Die inkrementellen Backups > sollten ja nicht differenziell zum Original sein, sondern zum vorherigen > inkrementellen Backup. Bei Copy-On-Write Filesystemen werden neue Stände stets an leere Stellen auf den Disks geschrieben, mitsamt neuer Metadaten dazu. Als letztes wird dann einzig der Superblock überschrieben, der auf die neuen Metadaten verweist. Filesystem-Logging wird damit überflüssig, denn nach einem Crash hat man (dem Prinzip nach) stets den konsistenten Stand vom letzten Update des Superblocks. Ohne Snapshots werden die alten Daten und obsolet gewordene Metadaten automatisch freigegeben, mit Snapshots bleiben sie bis zur Löschung des letzten sie referenzierenden Snapshots einfach erhalten. Das "inkrementell/differenziell" Paradigma greift da folglich nicht richtig und die Arbeitsweise des Filesystems wird von der Existenz von Snapshots nicht beeinflusst (das ist bei NTFS Snapshots anders). Schmutzeffekt: Solche Filesysteme neigen zu Fragmentierung grosser nicht am Stück geschriebener Files. So werden die Blöcke von Datenbank-Containern mit der Zeit wild über die Platte verstreut, was sich im Durchsatz von Full Table Scans und bei sequentiellen Backups unangenehm bemerkbar macht. Da ist online arbeitende Defragmentierung angesagt, oder man schaltet dafür COW ab (geht bei btrfs).
A. K. schrieb: > Da ist online arbeitende Defragmentierung > angesagt, oder man schaltet dafür COW ab (geht bei btrfs). Oder in absehbarer Zeit setzen sich SSDs durch.
Lars R. schrieb: > Ein Fehler im Backup in einer Datei in einem Snapshot macht macht alle > nachfolgenden Backups dieser Datei unbrauchbar. Es gibt zwei grundsätzlich verschiedene Arten von Backups, vom Anspruch her. Die einen Backups sind dazu da, um nach komplettem Datenverlust oder Inkonsistenz ganze Filesysteme wiederherzustellen. Primärziel ist hier der Durchsatz, mindestens beim Backup, bei kritischen Systemen aber auch bei der Wiederherstellung. Aus den anderen Backups stellt man einzelne Files wieder her, beispielsweise weil ein Anwender sie versemmelt hat. Das kann man, wie früher bei Bandsicherungen üblich, mit dem gleichen Verfahren machen, oder man kann dafür getrennte Wege gehen. Snapshots sind nur für die zweite Backup-Kategorie geeignet, da aber sind sie exzellent. Für Disaster-Recovery sind Snapshots hingegen völlig untauglich.
A. K. schrieb: >2. Für Disaster-Recovery sind Snapshots völlig ungeeignet. Stimmt, da jede verstreute Datei einzeln von der Platte zusammengesucht wird dauert das 100x länger als ein komlettes Image in einem Rutsch.
oszi40 schrieb: >>2. Für Disaster-Recovery sind Snapshots völlig ungeeignet. > > Stimmt, da jede verstreute Datei einzeln von der Platte zusammengesucht > wird dauert das 100x länger als ein komlettes Image in einem Rutsch. Ich habe nicht den Eindruck, dass du das Prinzip von COW Filesystemen und deren Snapshots richtig verstanden hast. Ein Snapshot stellt keine Kopie der Daten auf ein anderes Medium dar, sondern bleibt im Original. Steht das Originalmedium nicht mehr zur Verfügung, beispielsweise weil der Plattentop unter Wasser steht, dann sind die Originale und sämtliche Snapshots gleichermassen weg. Wie man für solche Filesysteme Disaster-Backups durchführt ist ein völlig anderes Thema. Da muss man dann diese Systeme separat betrachten und sich ansehen, was dafür jeweils zur Verfügung steht. In dieser Frage gibt es zwischen COW-Filesystemen und klassischen Filesystemen aber nur wenig Unterschiede, da auch klassische Filesysteme die Files eines Verzeichnisses wild über die Disks streuen. Unterschiedlich ist dabei nur die Neigung zu Fragmentierung innerhalb grosser Container-Files. Erfahrung habe ich in dieser Frage mit NetApps WAFL, und da gibt es ein Backup-Verfahren, das in Name und Arbeitsweise an das klassische Unix "dump" Tool erinnert. Mit ansprechendem Tempo für Backup/Restore ganzer Filesysteme oder grossere Bereiche. Aber für häufige Einzelfilerestores will man das nicht verwenden müssen.
A. K. schrieb: > Für Disaster-Recovery sind Snapshots hingegen völlig > untauglich. Kommt auf die Backup-Strategie an. Mit btrfs-send+receive backups ist die recovery in etwa: - Kaputte Platte ausbauen - Backup-Platte einbauen - Live-System von USB/CD Booten - Einen Read-Write Snapshot vom "last-known-good"-Readonly Snapshot machen - grub beibringen, dass dieser Snapshot das neue Root-Fs ist - reboot - fertig. Denn: A. K. schrieb: > Jeder Snapshot sieht aus wie ein vollständiges Filesystem vom > betreffenden Zeitpunkt der Snapshot sieht nicht nur so aus, sondern ist (wenn RW) auch ein vollständiges Dateisystem, von dem auch direkt gebootet werden könnte (Kernel-CMDline: rootflags=subvol=MeinBackupSnapshot1234)
Planlos schrieb: > Kommt auf die Backup-Strategie an. > Mit btrfs-send+receive backups ist die recovery in etwa: Yep, aber in diesem Fall handelt es sich nicht um Snapshots innerhalb des COW-Filesystems. Sondern um ein Verfahren zur inkrementellen Sicherung von btrfs auf andere Medien. Andere Baustelle, eben für Disaster-Backups vorgesehen. Mit Snapshots hat das nicht allzu viel zu tun, ausser dass man sie nutzen kann, um einen konsistenten Stand zu erhalten und auf dem Zielsystem mehrere Stände vorzuhalten.
A. K. schrieb: > [zu btrfs] Sehr schön und verständlich erklärt. Danke :) Das hilft auch beim Lesen anderer Texte zu btrfs. A. K. schrieb: > Lars R. schrieb: >> Ein Fehler im Backup in einer Datei in einem Snapshot macht macht alle >> nachfolgenden Backups dieser Datei unbrauchbar. > > Es gibt zwei grundsätzlich verschiedene Arten von Backups, vom Anspruch > her. > > Die einen Backups sind dazu da, um nach komplettem Datenverlust oder > Inkonsistenz ganze Filesysteme wiederherzustellen. [...] > > Aus den anderen Backups stellt man einzelne Files wieder her, > > Snapshots sind nur für die zweite Backup-Kategorie geeignet, da aber > sind sie exzellent. Für Disaster-Recovery sind Snapshots hingegen völlig > untauglich. Der Fehlerfall tritt (bei mir typischerweise) eine gewisse Zeit nach dem letzten Backup ein. Daher versuche ich prinzipiell die Daten vom fehlerhaften System/Medium zu retten. Die Frage ist immer die Abschätzung "Aktualität der Daten im Backup" vs. "Datenintegrität auf dem Fehlermedium". Deshalb ist mir besonders wichtig, wie sich ein Dateisystem im Fehlerfall "verhält" und wie gut ich dann noch an die letzten Daten heran komme. Transparentes CRC ist prinzipiell extrem wertvoll. Tatsächlich hilfreich ist es jedoch nur dann, wenn die Tools und Fehlerbeherrschung wirklich ausgereift sind. Vielleicht braucht es dazu für btrfs noch ein klein wenig Zeit? Das (Betriebs)System habe ich nicht im Backup. So oft fallen mir die (Notebook-)Platten nicht aus. Ein alter Desktoprechner läuft mit Raid1 in HW... A. K. schrieb: > Planlos schrieb: >> Kommt auf die Backup-Strategie an. >> Mit btrfs-send+receive backups ist die recovery in etwa: > > Yep, aber in diesem Fall handelt es sich nicht um Snapshots innerhalb > des COW-Filesystems. Sondern um ein Verfahren zur inkrementellen > Sicherung von btrfs auf andere Medien. Andere Baustelle, eben für > Disaster-Backups vorgesehen. Mit Snapshots hat das nicht allzu viel zu > tun, ausser dass man sie nutzen kann, um einen konsistenten Stand zu > erhalten und auf dem Zielsystem mehrere Stände vorzuhalten. Aha, also doch. Schwierig.
A. K. schrieb: > oszi40 schrieb: >> Solange die Platten aus der selben Charge sind, können >> sie am gleichen Tag sterben. > > Können sie. Tun sie aber jenseits der Anfangsausfälle nur mit extrem > geringer Wahrscheinlichkeit. Jedenfalls nicht HDDs, Samsung HD204UI wäre das Gegenbeispiel: Ausfall nach 256 Power-Cycles, IIRC.
Lars R. schrieb: > A. K. schrieb: >> [zu btrfs] Eigentlich generell zu COW Filesystemen. Auch wenn sich diese erheblich unterscheiden mögen - grundlegende Prinzipien solcher Snapshots teilt btrfs mit anderes COW-Filesystemen wie ZFS und WAFL.
A. K. schrieb: > Für Disaster-Recovery sind Snapshots völlig > ungeeignet. Das einzige was fehlt sind doch nur Partitionstabelle und evtl. Bootsektor, was hindert einen daran jede Partition komplett (ab /) dateibasiert zu sichern (snapshot/rsync/snapshot oder snapshot/send/receive) und dann im Ernstfall ein Script laufen zu lassen das die neu eingebauten Platten wie gewünscht partitioniert und dann in jede einzelne Partition deren jeweils letzten Snapshot reinbügelt (rsync oder btrfs send/receive) und am Schluss evtl. noch den Bootloader installiert falls zutreffend? Ich bin sicher so ein Script um das zu automatisieren könnte man an ein paar ruhigen Tagen oder langweiligen Nächten mal in aller Ruhe entwerfen und testen. Komplett-Restore sollte man sowieso mal durchgespielt haben um im Notfall ohne langes Herumgesuche und Rätselraten zu wissen welche Handgriffe jetzt in welcher Reihenfolge anzuwenden sind und um zu sehen ob das überhaupt funktioniert oder nicht noch irgendwas vergessen wurde.
A. K. schrieb: > Aus den anderen Backups stellt man einzelne Files wieder her, > beispielsweise weil ein Anwender sie versemmelt hat. Ja, aber es gibt viele weitere Gründe.
Lars R. schrieb: > Vielleicht braucht es dazu für btrfs noch ein klein wenig Zeit? Für den Enterprise-Einsatz zweifellos. > Aha, also doch. Schwierig. Wat de Buur nich kennt, dat frett he nich? ;-)
Bernd K. schrieb: > was hindert einen daran jede Partition komplett (ab /) > dateibasiert zu sichern (snapshot/rsync/snapshot oder > snapshot/send/receive) Nichts. Nur ist das keine Eigenschaft von Snapshots, sondern ein Backup-Verfahren von btrfs. Ich versuche hier lediglich, etwas System in die hier durcheinander auftretenden Szenarien zu bringen. Und unterscheide deshalb Snapshots von btrfs-send/receive, auch wenn es in btrfs beides gibt.
A. K. schrieb: >> Aha, also doch. Schwierig. > > Wat de Buur nich kennt, dat frett he nich? ;-) Beim Backup auf jeden Fall! Man kann sich Einarbeiten aber meine Zeit und Expertise zum Austesten und Bewerten sind begrenzt.
Bernd K. schrieb: > A. K. schrieb: >> Für Disaster-Recovery sind Snapshots völlig >> ungeeignet. > > Das einzige was fehlt sind doch... Ich musste auch zweimal Lesen bevor ich die Klassifikation von A.K. verstanden hatte: -- "Snapshot" geschieht auf dem gleichem Medium -- "Desaster Recovery" benötigt ein separates physikalisches Medium
A. K. schrieb: > Nur ist das keine Eigenschaft von Snapshots, sondern ein > Backup-Verfahren von btrfs. rsync auf ne andere Festplatte wäre ein traditionelles backup-Verfahren, auf dem Backup-Medum (falls dieses btrfs formatiert ist) ersetzt der dortige snapshot jedoch die ganzen Hardlinks und erlaubt sehr schnelle inkrementelle dateibasierte Backups.
Mikro 7. schrieb: > -- "Snapshot" geschieht auf dem gleichem Medium Yep. Das ist mindestens bei COW-Filesystemen ein eindeutiger Begriff, sollte also sprachlich nicht mit Backups auf separate Medien vermischt werden. > -- "Desaster Recovery" benötigt ein separates physikalisches Medium Yep.
Bernd K. schrieb: > rsync auf ne andere Festplatte wäre ein traditionelles backup-Verfahren, Ja. Wobei es verteufelt lang dauern kann, diese Hardlink-Trees später wieder zu löschen. U.u. länger als sie anzulegen. ;-) Aber auch bei WAFL dauern Aufräumarbeiten teilweise recht lange. Also bis der bei Löschung eines Snapshots frei werdende Platz auch tatsächlich frei ist. Das ist allerdings Hintergrundaktivität.
Lars R. schrieb: > Ein Snapshot auf der selben Platte ist für mich kein Backup. Ich hatte oben zwei Szenarien präsentiert, die man häufig unter diesem Begriff findet. Snapshots decken eines davon ab. Anwender hat Mist gebaut und braucht das Excel-File von gestern. Oder jemand hat sich 11:14 einen Locky angefangen und man braucht von ein paar Dateibäumen die Inhalte aus dem letzten Snapshot, z.B. dem von 10:00. In solchen Fällen steht nicht die Konsistenz der Filesysteme in Frage.
A. K. schrieb: > Ja. Wobei es verteufelt lang dauern kann, diese Hardlink-Trees später > wieder zu löschen. U.u. länger als sie anzulegen. ;-) Deshalb ja keine Hardlink-Trees auf dem Backup-Medium mehr sondern stattdessen einfach einen btrfs snapshot AUF dem Backup Medium nach jedem rsync Lauf als Ersatz für die hunderttausend Hardlinks jedesmal. Läuft 5 mal schneller durch.
Bernd K. schrieb: > Deshalb ja keine Hardlink-Trees auf dem Backup-Medium mehr sondern > stattdessen einfach einen btrfs snapshot AUF dem Backup Medium nach > jedem rsync Lauf als Ersatz für die hunderttausend Hardlinks jedesmal. Yep. Siehe SnapVault bei NetApp, nur kopiert das blockweise inkrementell, statt fileweise. Snapshots spielen insoweit hinein, als sich die blockweise Differenz zwischen Quell- und Zielsystem aus der Differenz zweier Snapshots im Quellsystem direkt ablesen lässt. In einem solchen Szenario hat man beispielsweise im teuren Quellsystem innertägliche Snapshots für ein paar Tage, während das billigere Zielsystem über Wochen und Monate speichert.
A. K. schrieb: > Lars R. schrieb: >> Ein Snapshot auf der selben Platte ist für mich kein Backup. > > Ich hatte oben zwei Szenarien präsentiert, die man häufig unter diesem > Begriff findet. Snapshots decken eines davon ab. Anwender hat Mist > gebaut und braucht das Excel-File von gestern. Oder jemand hat sich > 11:14 einen Locky angefangen und man braucht von ein paar Dateibäumen > die Inhalte aus dem letzten Snapshot, z.B. dem von 10:00. In solchen > Fällen steht nicht die Konsistenz der Filesysteme in Frage. Doch, tut sie; z.B. wegen Dirty CoW und allem anderen, was uns zukünftig erwartet. Ein weiteres Szenario sind flippende Bits, sei es beim Kopieren im Controller der Platte, im Arbeitsspeicher oder an anderen Stellen. Erst kürzlich habe ich so etwas bei längeren Kopiervorgängen auf meinen aktuellen Intel-Systemen gesehen. In jedem Fall ist die Frage immer, wie lang (seit wann) der Fehler schon in der Datei ist. Solche "Fehler" sind aber nicht die einzige Art von Veränderungen, die Dateien im Laufe der Zeit erfahren. (Auch deshalb finde ich das CRC von btrfs interessant. Aber die positiven Erfahrungen für Fehlerfälle scheinen noch überschaubar) Last but not least: Wenn ich einmal den Aufwand verschiedener, inkrementeller Backups betreibe, dann möchte ich auf dem "Arbeitssystem" nicht Datei-Versionen vorhalten, die ich nach aktuellem Kenntnisstand "nur" sehr wahrscheinlich zukünftig nicht mehr benötige. Wenn sich zukünftig ein anderer Kenntnisstand ergibt, benötige ich die Datei unerwartet vielleicht doch noch einmal, und sei es nur zur Ansicht. Für diese Funktionalität lege ich nicht x Tausend Zip-Files an und dafür möchte ich auch nicht x hundert Snapshots in meinem Arbeitsdateisystem herum schleppen. Dafür habe ich bereits Backups. Demgegenüber ist die Handhabung eines "unbequem gewordenen" Backup-Containers relativ unkritisch.
Lars R. schrieb: > Doch, tut sie; z.B. wegen Dirty CoW und allem anderen, was uns zukünftig > erwartet. Snapshots ersetzen keine Disaster-Backups. Das hatten wir aber schon. Dass nicht bloss eindringendes Wasser, sondern auch Software-Bugs zu Problemen führen können, ist kein Geheimnis. Wobei diese Kuh allerdings nichts mit COW-Filesystemen zu tun haben dürfte, sondern mit COW-Methoden der Speicherverwaltung. > Wenn ich einmal den Aufwand verschiedener, inkrementeller Backups > betreibe, dann möchte ich auf dem "Arbeitssystem" nicht Datei-Versionen > vorhalten, die ich nach aktuellem Kenntnisstand "nur" sehr > wahrscheinlich zukünftig nicht mehr benötige. Richtig. Hatte ich vorhin auch schon aufgeführt.
Angehängte Dateien:
-

snapshots-src.gif
2,2 KB -

snapshots-dst.gif
2,1 KB
{kind=link}
{kind=link}
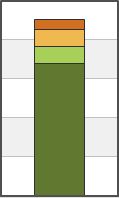
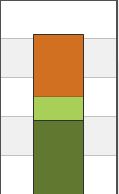
Um sich mal ein Bild davon machen zu können: src ist die Platzbelegung auf dem Produktivsystem, mit maximal 1 Woche alten Snapshots, dst zeigt das Zielsystem, auf dem Snapshots ein Jahr lang vorgehalten werden. Der unterste Teil des Balkens zeigt den vom aktuellen Stand belegten Platz, der oberste den von Snapshots belegten Platz. Inhalt sind normale Anwenderdaten im Unternehmen.
Gut, dann zu btrfs: Gibt es eine Statistik für aufgetretene und korrigierte CRC-Fehler? Was passiert typischerweise (Standardeinstellungen) mit nicht behebbaren Fehlern? Fehler beim Kopiervorgang von einem btrfs zu einem anderen btrfs detektiert der btrfs-eigene Mechanismus nicht, oder? A. K. schrieb: > Um sich mal ein Bild davon machen zu können: src ist die Platzbelegung > auf dem Produktivsystem, mit maximal 1 Woche alten Snapshots, dst zeigt > das Zielsystem, auf dem Snapshots ein Jahr lang vorgehalten werden. Der > unterste Teil des Balkens zeigt den vom aktuellen Stand belegten Platz, > der oberste den von Snapshots belegten Platz. Inhalt sind normale > Anwenderdaten im Unternehmen. Eine Woche lang nicht extern zu sichern, kann ich mir nicht leisten. Daher sichere ich gleich jedes mal auf extern und spare mir das Anlegen, Löschen und zugehöriges Defragmentieren direkt auf dem Produktivsystem.
Lars R. schrieb: > Eine Woche lang nicht extern zu sichern, kann ich mir nicht leisten. Das sind bereits zwei getrennte Systeme, d.h. das rechte Bild ist bereits extern, bezogen auf das Speichermedium. Das linke Produktivsystem ist zudem auf 2 Gebäude gespiegelt und eine Bandsicherung gibts auch noch. ;-) Die paar Prozent Mehrbelegung auf dem Produktivsystem durch 1 Woche Snapshots ersparen Arbeitzeit und Verzögerung bei Anwenderanfragen nach alten Versionen.
A. K. schrieb: > Lars R. schrieb: >> Eine Woche lang nicht extern zu sichern, kann ich mir nicht leisten. > > Das sind bereits zwei getrennte Systeme. Das hatte ich auch so verstanden. > Die paar Prozent Mehrbelegung auf dem Produktivsystem durch 1 Woche > Snapshots ersparen Arbeitzeit und Verzögerung bei Anwenderanfragen nach > alten Versionen. Sorry, dann verständlich. Da war ich irrtümlich von meinem kleinen Szenario ausgegangen. Hast Du Erfahrungen zu CRC mit btrfs? Alles Erkennbare fängt bei Dir wahrscheinlich bereits RAID ab, oder?
Lars R. schrieb: > Hast Du Erfahrungen zu CRC mit btrfs? Mein privates Serverlein hat sich trotz regelmässiger Überprüfung noch nicht beklagt. > Alles Erkennbare fängt bei Dir wahrscheinlich bereits RAID ab, oder? Nein, da das RAID ja Teil des Filesystem ist.
Was soll denn in der Cloud gespeichert werden? Wenn das überwiegend JPGs sind, kann man mit Kompression kaum noch was rausholen. Bei BMPs sieht das natürlich anders aus.
Tobias P. schrieb: > Datenfolder von OwnCloud komprimieren Oliver S. schrieb: > WAS soll denn in der Cloud gespeichert werden? Wenn das überwiegend JPGs > sind, kann man mit Kompression kaum noch was rausholen. Stimmt, Komprimiertes wird kaum kleiner durch nochmalige Komprimierung. Die AK-Diskussion über Snaps und Datensicherung war trotzdem recht nützlich. Wenn ich die letzten Jahre betrachte, so habe ich nur wenige wertvolle Snaps zurückgespielt aber mehr komplette Images gebraucht, um ein krankes System möglicht SCHNELL wieder ins Rennen zu bringen. Leider gab es auch kranke Images, die erst beim 3. Versuch durchliefen. Daher sollte man sich nie mit einem Backup begnügen.
A. K. schrieb: > Axel S. schrieb: >> Ich bin nach wie vor nicht davon überzeugt, daß es eine gute Idee<tm> >> ist, Filesystem und Redundanz-Layer an einer Stelle zu implementieren. > > Synergieeffekte. Die hätte ich gern praktisch belegt. > ... ein klassisches Filesystem kann sich mangels > Kenntnis nicht der Geometrie des zugrunde liegenden Redundanzlayers > anpassen (welche Blöcke mit welchen anderen zu einem RAID Datensatz > zusammengefasst sind). Praktisch alle aktuellen Linux-Filesysteme haben entsprechende Optionen für mkfs (typischer Name: stride). Und einige mkfs fragen das sogar selber ab. ext4 richtet sich bspw. automagisch an der chunksize aus. > So müssen in Filesystemen mit integrierter Redundanz bei einer > ausgefallenen Disk nur belegte Blöcke regeneriert werden, während ein > separat arbeitender RAID-Layer auch eine fast leere Disk komplett > regeneriert. Write bitmaps hat md jetzt schon eine ganze Weile. > RAID arbeitet effizienter, wenn die Paritätsdaten von RAID-5/6/... aus > den zu schreibenden Daten direkt erzeugt werden können, ohne vorher > Daten von Disk lesen zu müssen. Dabei ist es von Vorteil, wenn man auf > unbelegte Blöcke keine Rücksicht nehmen muss. Wie gesagt: in der Theorie ist das klar. In der Praxis alloziert und schreibt ext4 einfach entsprechend große Blöcke. Dann fällt das Rücklesen schon mal weg. Ansonsten gibt es ja den stripe cache in md. olibert schrieb: > ext4 gibt dir nicht die gleiche Performance wie XFS. Auf einer privaten > Box merkt man das normlerweise nicht Da muß ich dir widersprechen. Ich habe es getestet (bonnie++) und ext4 war meßbar schneller als XFS. Nicht beim rohen Lesen/Schreiben, sondern bei den inode-Operationen.
Oliver S. schrieb: > Was soll denn in der Cloud gespeichert werden? Wenn das überwiegend JPGs > sind, kann man mit Kompression kaum noch was rausholen. > Bei BMPs sieht das natürlich anders aus. In der Cloud liegt massenhaft Musik (mp3, ogg) sowie Bilder (JPEG) und eBooks (PDF). Mein vServer hat nur eine 40er Disk, weshalb ich eine Kompression anstrebe. Allgemein habe ich aber gesehen, dass die meisten Angebote für solche vServer ziemlich beschränkten Speicherplatz bieten, meist unter 100GB. Womit man recht schnell an die Grenze stösst. Dropbox bietet hingegen bis zu 1TB, aber ich will halt eben Dropbox nicht benutzen...
Tobias P. schrieb: > In der Cloud liegt massenhaft Musik (mp3, ogg) sowie Bilder (JPEG) und > eBooks (PDF). Mein vServer hat nur eine 40er Disk, weshalb ich eine > Kompression anstrebe. Die Formate, die du da nennst, sind alle schon sehr stark komprimiert. Da kann man nicht mehr viel rausholen. > Allgemein habe ich aber gesehen, dass die meisten Angebote für solche > vServer ziemlich beschränkten Speicherplatz bieten, meist unter 100GB. > Womit man recht schnell an die Grenze stösst. Dropbox bietet hingegen bis > zu 1TB, aber ich will halt eben Dropbox nicht benutzen... Weil du denen deine Daten nicht anvertrauen willst? Da gibt's ja Möglichkeiten, die vorher zu verschlüsseln, so dass außer dir keiner dran kommt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.