Guten Abend Gemeinde! Nachdem ich seit einiger Zeit mit dem WLAN Modul ESP8266 rum hantiere, habe ich es schon recht weit gebracht, was den Aufbau und den Erhalt einer Kommunikation zwischen PC und Modul angeht. Leider beobachte ich bei meinen Experimenten immer noch nichtzufriendenstellende Effekte, deren Aufklärung mir nicht gelingt. Bevor ich mit Code und Screen-Shots hantiere, beschreibe ich, was ich beobachte: Mein PC sendet über WLAN eine 30 Bytes (konstant)lange Nachricht an das Modul. Diese Nachricht besteht aus den immer wiederkehrenden Muster (dezimal geschrieben) 187, 187, 187, 1 und 6 Nutzbytes, das Ganze dreimal! Im Urzustand sind die 6 Nutzbytes 0 (willkürlich festgelegt). Vor erstem Senden ändere ich 1 von 18 Nutzbytes. Ich sende die dreißig Bytes einmal an den ESP8266, dieser sendet beim ersten Mal die vollständige richtige Antwort zurück! Jetzt ändere ich ein zweites Nutzbyte und sende, der ESP sendet mir die ursprüngliche Antwort (mit nur einem geänderten NutzByte) zurück! Jetzt kommts! Wenn ich diese neue Nachricht mehrfach und in schneller Folge sende, dann sendet irgendwann (sic!) der ESP die richtige Antwort zurück! Noch schlimmer! Zwischendurch sendet der ESP Daten zurück, die niemals gesendet wurden, die aber auf PC Seite mal existierten (Also Nutzbytes, die zwar eingestellt, aber nie gesendet wurden!) Meine Bitte: Kann mir jemand erklären, wie der Datenstrom zwischen PC und ESP tatsächlich stattfindet? Gibt es irgendeinen Puffer, in welchem meine alten Daten stehen könnten? Kann man den löschen (mit allen möglichen flushs hab' ich 's schon probiert)? Oder ...?
ArduStemmi schrieb: > Meine Bitte: Kann mir jemand erklären, wie der Datenstrom zwischen PC > und ESP tatsächlich stattfindet? Installier Dir doch auf dem PC einfach mal Wireshark und schau Dir die Datenpakete mal an.
Meine Art der Wichtigtuerei. (!) Hat aber nichts weiter zu bedeuten!
WireShark hab ich installiert und gestartet. Meine Frage, hat das Sinn, dass ich mich da einarbeite? Geht ja schon los, dass ich keinen Mitschnittfilter habe, den ich da eingeben könnte. Des Weiteren habe ich auch kein wpcap.dll installiert. Ich habe Angst, dass ich in die falsche Richtung renne.
Angehängte Dateien:
-

Zwischenablage02.jpg
39 KB -

Zwischenablage01.jpg
18 KB
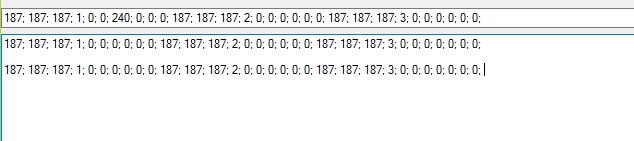

In Zwischenablage02 sieht man die zweite Nachricht in der ersten Zeile, in der zweiten Zeile die Antwort auf die erste Nachricht (korrekt) und in der dritten Zeile die Antwort auf die zweite Nachricht (falsch). Beide Antworten sind über WLAN zurückgekommen. Die Antworten, die seriell übertragen wurden (über einen COM Port), sieht man in Zwischenablage01.
Der Screenshot war doch nicht von Wireshark? Versuch damit umzugehen, weil er wirklich genau auflistet, was gesendet wird. Weiterhin fehlt mir die Angabe, wie überhaupt gesendet wird. Wenn es WLan ist, dann gehen doch nur TCP oder UDP. Und wenn TCP verwendet wird, sorgt das Protokoll dafür, dass nichts falsches ankommt. Dann reagiert also nur das Empfangsprogramm falsch. Auch fehlt hier eine Zeit. Was bedeutet 'schneller gesendet'? 2mal die Sekunde? oder alle Mikrosekunde? Mein Vorschlag: arbeite dich in Wireshark und die Protokolle ein. Sowas wirst du im richtigen Leben immer wieder brauchen.
PittyJ schrieb: > Wenn es > WLan ist, dann gehen doch nur TCP oder UDP. nein, Wlan arbeiten auf MAC Ebene. Es geht es alles übertragen was gültige Ethernet Pakete sind.
Peter II schrieb: > PittyJ schrieb: >> Wenn es >> WLan ist, dann gehen doch nur TCP oder UDP. > > nein, Wlan arbeiten auf MAC Ebene. Es geht es alles übertragen was > gültige Ethernet Pakete sind. das mag ja sein, aber wer sich so gut auskennt wie der TO wird wohl kaum ein eigenes Protokoll auf MAC Ebene aufsetzen. Also wird er sicher den IP-Stack von PC und ESP verwenden - und dort gibts nun mal TCP oder UDP. Sascha
Sascha W. schrieb: > Also wird er sicher den IP-Stack von PC und ESP verwenden - und dort > gibts nun mal TCP oder UDP. eventuell macht er es ja im ICMP packet (Ping) - dort kann man auch Nutzdaten übertragen.
PittyJ schrieb: > Der Screenshot war doch nicht von Wireshark? Nein, die Screenshots sind aus Hercules und meinem eigenen Programm. >Versuch damit umzugehen, > weil er wirklich genau auflistet, was gesendet wird. Das will ich gern versuchen. > > Weiterhin fehlt mir die Angabe, wie überhaupt gesendet wird. Meine Absicht ist, dass über TCP zu tun. Im Visual Basic sieht das so aus:
1 | myTcpClient = New TcpClient |
2 | |
3 | Try
|
4 | myTcpClient.Connect(IP_Adresse, IP_Port) |
5 | myTcpClient.SendBufferSize = 256 |
6 | myTcpClient.ReceiveBufferSize = 256 |
7 | myNetworkStream = myTcpClient.GetStream |
8 | Catch ex As Exception |
9 | MessageBox.Show(ex.Message, "Fehler beim Herstellen der WLAN Verbindung", |
10 | MessageBoxButtons.OK, MessageBoxIcon.Error) |
11 | End Try |
Gesendet wird so:
1 | Try
|
2 | If myTcpClient.Connected Then |
3 | For i As Integer = 0 To Message.Length - 1 |
4 | myNetworkStream.WriteByte(Message(i)) |
5 | Next
|
6 | Else
|
7 | MessageBox.Show("TCP-Client not connected!", "Fehler beim Senden ...") |
8 | End If |
9 | |
10 | Catch ex As Exception |
11 | MessageBox.Show(ex.Message, "Fehler beim Senden ...") |
12 | Exit Sub |
13 | End Try |
> Wenn es > WLan ist, dann gehen doch nur TCP oder UDP. Und wenn TCP verwendet wird, > sorgt das Protokoll dafür, dass nichts falsches ankommt. Dann reagiert > also nur das Empfangsprogramm falsch. > Auch fehlt hier eine Zeit. Was bedeutet 'schneller gesendet'? 2mal die > Sekunde? oder alle Mikrosekunde? Es bedeutet: so schnell ich mit der Maus klicken kann! > > Mein Vorschlag: arbeite dich in Wireshark und die Protokolle ein. Sowas > wirst du im richtigen Leben immer wieder brauchen. Oder: Jemand erklärt mir, ob es irgendwo einen Puffer gibt, den mein Programm vollschreibt.
Angehängte Dateien:
-

Zwischenablage01.jpg
470 KB

Hier der WireShark Mitschnitt - Aufzeichnung - Screenshot - Anhang. Und nun?
ArduStemmi schrieb: > Meine Absicht ist, dass über TCP zu tun. Dann solltest Du Dich mit den tatsächlichen Eigenschaften von TCP beschäftigen und nicht irgendwelche wirren Wunschvorstellungen hineininterpretieren. Bei der Gelegenheit solltest Du Dich mit den fundamentalen Unterschieden zwischen "stream oriented" und "message oriented" Prokollen informieren. Ein weiteres wichtiges Stichwort ist "NAGLE". Wie kommst Du überhaupt auf die irrige Annahme, dass bei TCP die zeitnahe Übertragung von Nachrichten fester Länge sichergestellt wird? TCP sichert nur zu, dass die vorne hineingesteckten Zeichen irgendwann und in korrekter Reihenfolge beim Empfänger ankommen. > Oder: Jemand erklärt mir, ob es irgendwo einen Puffer gibt, den mein > Programm vollschreibt. Ja, es gibt etliche Puffer auf Sende- und Empfangsseite. Insbesondere ist auch zu beachten, dass die von Empfangsfunktionen wie z.B. recv() gelieferte tatsächliche Länge an empfangenen Daten überhaupt nichts mit den Größe des gesendeten Datenpuffers zu tun haben muss. Der an recv() übergebene Längenparameter (size_t len) gibt auch nur die maximale Datenblockgröße an, nicht die in jedem Fall zu liefernde.
ArduStemmi schrieb: > Und nun? Dann analysiere diese Daten! Die TCP/IP-Spezifikation ist frei zugänglich, es gibt Unmengen an Publikationen zu diesem Thema, usw.. Was sollen wir hier mit solch einem blöden Screenshot anfangen? Wenn Du möchtest, dass hier jemand bei der Analyse Deines Mitschnitts assistiert, solltest Du ihn in einem brauchbaren Datenformat hochladen. Falls Du Dich auch nur ansatzweise mit der Funktion von Wireshark vertraut machen würdest, wüsstest Du das richtige Format.
Andreas S. schrieb: > zeitnahe Übertragung von Nachrichten Im privaten Netz kannst Du bei den hier besprochenen Daten (so schnell wie mit der Maus geklickt werden kann), von "sofort" ausgehen. Die Daten sind so klein, dass sie problemlos in ein Frame passen. Hier muss also nichts fragmentiert und wieder in der richtigen Reihenfolge zusammen gebaut werden.
Angehängte Dateien:
-

Zwischenablage01.jpg
140 KB -

Zwischenablage02.jpg
150 KB
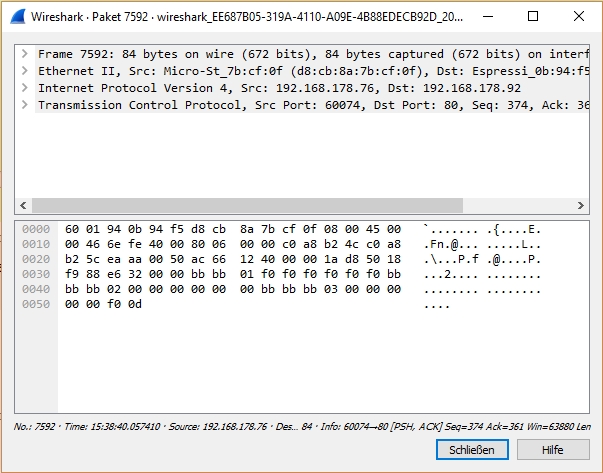
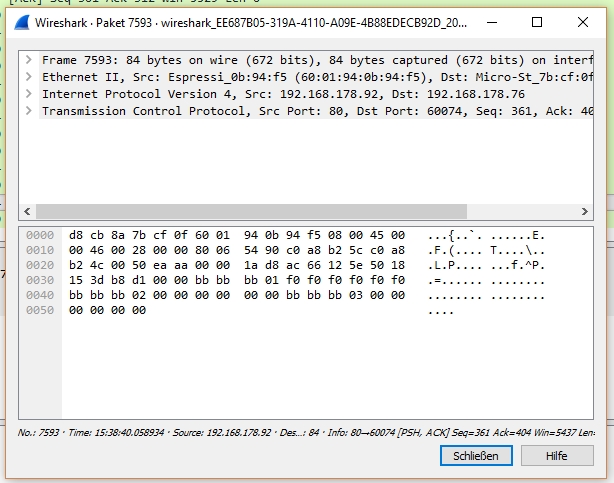
Also ich habe meine Daten mit WireShark tatsächlich gefunden, trotzdem ich, nach 10 Minuten Benutzung, noch kein Experte bin. Das gilt übrigens auch für TCP und WLAN. Ich muss zugeben, dass ich mein Hobby tatsächlich nicht mit der Intensität betreibe, dass ich auch noch in die Feinheiten der Datenübertragung einsteigen will. Zumal mir als Hobbyist das ganze Wissen ja gar nichts nützt. Ich war der irrigen Annahme, dass es mir gelingen sollte, 30 Byte Daten zu senden und zu empfangen, ohne das bis in's Detail zu verstehen. Über diese Meinung darf jeder seine Meinung haben. So. In Zwischenablage01.jpg ist der Datenstrom vom PC an den ESP zu sehen. Daran wundert mich, dass der Nutzdatenstrom mit "BB BB" startet (siehe Byte 36 und 37). Hier fehlt ein "BB". Ansonsten sind die Daten korrekt, ich kann das an Byte 52 erkennen: "f0". In Zwischenablage02.jpg ist der Datenstrom als Antwort darauf zu erkennen. Hier beginnt die Nutzlast mit den korrekten Präambelbytes "BB BB BB", zu erkennen ab Byte 36. Allerdings ist hier Byte 53 falsch, es steht "00" an Stelle von "f0" Das bedeutet einerseits, der Einsatz von Wireshark hat sich tatsächlich gelohnt, andererseits liegt der Fehler im ESP Programm. Der Ausschnitt, der für das Absenden der Daten verantwortlich lautet:
1 | while (client.connected()) |
2 | {
|
3 | if (client.available()) |
4 | {
|
5 | command = client.readStringUntil('\r'); |
6 | client.flush(); |
7 | Serial.print(command); |
8 | client.print(command); |
9 | }
|
10 | }
|
Das bedeutet, dass das Lesen Client.readstringuntil() irgendetwas Falsches liest, oder?
Andreas S. schrieb: > Dann solltest Du Dich mit den tatsächlichen Eigenschaften von TCP > beschäftigen und nicht irgendwelche wirren Wunschvorstellungen > hineininterpretieren. Bei der Gelegenheit solltest Du Dich mit den > fundamentalen Unterschieden zwischen "stream oriented" und "message > oriented" Prokollen informieren. Ein weiteres wichtiges Stichwort ist > "NAGLE". Das alles möchte ich eben gerade nicht tun! Ich bin überzeugt, dass ich zum Versenden und Empfangen von 30 Byte langen "Nachrichten", die keine lebenserhaltenden Systeme am Laufen halten, dieses Wissen nicht brauch, auch wenn ich nach Realisierung sagen muss, es funktioniert, aber wie genau weiß ich nicht! > > Wie kommst Du überhaupt auf die irrige Annahme, dass bei TCP die > zeitnahe Übertragung von Nachrichten fester Länge sichergestellt wird? > TCP sichert nur zu, dass die vorne hineingesteckten Zeichen irgendwann > und in korrekter Reihenfolge beim Empfänger ankommen. > Es ist noch schlimmer, ich habe mir darüber überhaupt keine Gedanken gemacht. >> Oder: Jemand erklärt mir, ob es irgendwo einen Puffer gibt, den mein >> Programm vollschreibt. > > Ja, es gibt etliche Puffer auf Sende- und Empfangsseite. Insbesondere > ist auch zu beachten, dass die von Empfangsfunktionen wie z.B. recv() > gelieferte tatsächliche Länge an empfangenen Daten überhaupt nichts mit > den Größe des gesendeten Datenpuffers zu tun haben muss. Der an recv() > übergebene Längenparameter (size_t len) gibt auch nur die maximale > Datenblockgröße an, nicht die in jedem Fall zu liefernde. Jetzt geht's um meine Frage, Deine Antwort lautet: ja es gibt Puffer. Meine nächste Frage: Können diese Puffer was mit dem von mir beobachteten Verhalten zu tun haben?
Ich habe jetzt mal die ganzen Nullen in 1 umgewandelt und siehe da, jetzt passt es! Wenn also im Nachrichtenstring genug Bits gesetzt sind, scheint es zu funktionieren. Ich wette, das ist für TCP über WLAN völlig unerklärlich!
ArduStemmi schrieb: > Ich wette, das ist für TCP über WLAN völlig > unerklärlich! Ganz genau, das hat mit TCP oder WLAN gar nichts zu tun, sondern eher mit den Streams/Strings, die Du benutzt, um binäre Datenblöcke zu versenden. Da Du aber wohl keine Notwendigkeit siehst, Dich auf Detailebene herabzulassen, mußt Du bei den 1en bleiben.
ArduStemmi schrieb: > Ich habe jetzt mal die ganzen Nullen in 1 umgewandelt und siehe da, > jetzt passt es! Wenn also im Nachrichtenstring genug Bits gesetzt sind, > scheint es zu funktionieren. Ein String kann kein Null-Byte enthalten da dieses als Stringendekennzeichen verwendet wird. Warum nimmst du im ESP eine Stringfunktion zum einlesen? Am Sender arbeitest du doch auch mit einem Bytearray. Sascha
Das werde ich versuchen! Da hätte ich wahrlich selbst draufkommen müssen!Danke!
ArduStemmi schrieb: > Oder: Jemand erklärt mir, ob es irgendwo einen Puffer gibt, den mein > Programm vollschreibt. Natürlich gibt es den. Alles, was du auf einen TCP-Socket ausgibst, landet natürlich zuerst mal in dessen Sendepuffer. Und da TCP letztlich genau dafür geschaffen ist, einen Stream (eigentlich sogar zwei, nämlich hin und zurück) zu implementieren, kommt bei fehlerfrei funktionierendem Netzwerk alles, was du in den Puffer geschrieben hast auch in genau der Reihenfolge und mit genau dem Inhalt bei dem Peer an, den du geschrieben hast. Das gerade ist das Goodie an TCP und natürlich auch so gewollt. AABERR: genauso natürlich kannst und darfst du niemals davon ausgehen, dass es auch in genau den Häppchen beim Peer ankommt, wie du sie ursprünglich in den Puffer geschrieben hast. Selbst in einem kabelgebundenen LAN nicht. Und schon garnicht in einem WLAN oder WAN. Das liegt einfach daran, dass ein Stream das Konzept eines "Häppchens" überhaupt nicht kennt, sondern sowas wie ein Endlos-Förderband ohne besondere Unterteilung in irgendwelche Fächer ist. Wenn du Fächer brauchst, musst du UDP nehmen. Genau nur dafür gibt's das als Alternative zu TCP. Allerdings hat es wieder andere Nachteile. Hier kannst du nämlich weder vollständige Übermittlung deiner Daten voraussetzen noch den Eingang in der Reihenfolge des Versands. Am schlimsten ist aber, dass auch hier die Fächer des Senders nochmal willkürlich unterteilt beim Empfänger ankommen können. Es sei denn, man konfiguriert ganz bewußt den Socket so, dass er die gewünschte Fachgröße erzwingt. Blöd nur: wenn irgendwas auf der Übertragungsstrecke mit dieser Fachgröße nicht klarkommt, wirft es die Pakete einfach ganz weg und schickt (bestenfalls) eine ICMP-Nachricht darüber an den Sender... Ein andere Möglichkeit für Häppchen ist, auf TCP noch ein eigenes Paketprotokoll drauf zu setzen. Damit hat man dann fast alles Gute beisammen. Außer hohe Effizienz und geringe Latenzen. Das beides geht dabei leider weitgehend den Bach runter... Kurzfassung: es gibt keine eierlegende Wollmilchsau als Protokoll, die für alle Zwecke gleich gut geeignet wäre. Genau deswegen gibt es ja auch so viele von diesen Dingern. Man muss sie halt einfach nur verstehen und entsprechend ihrer Eigenheiten sinnvoll benutzen. Diese Verständnis entsteht aber nunmal nicht aus dem Aneinanderfügen zusammenkopierten fremden Codes...
Herzlichen Dank für Deine ausführliche Beschreibung. Das kann ist im Wesentlichen, dass was ich bisher nocht verstanden hatte. Ich habe Daten gelesen und entweder erste oder letzte Teile als Teiler eines an Sich leeren Strings vorgefunden. Dazu kam noch erschwerend, dass ich auf der ESP Seite Charts eingelesen habe und Bytes erwartet hatte. Na gut. Ich werde jetzt byteweise lesen und Schreiben und einen Ringpuffer verwenden. Da kann ich mit dem Datentyp Byte arbeiten und brauch mir keine Gedanken um Sonderzeichen machen. Danke für Eure Geduld! Ich hab dann doch wieder etwas gelernt.
Was vielleicht nicht durchkam ... TCP verwendet man, um sicherzustellen dass etwas genau so rauskommt wie's reingeht. zB fuer einen Filetransfer. Das TCP macht dann die noetigen retries. UDP verwendet man wenn es nicht so genau drauf ankommt ob die Daten vollstaendig sind, wenn es aber drauf ankommt, daass etwas zeitnah rauskommt. zB Audio oder Video. Dort ist es egal, dass ob mal ein Sample oder ein Frame fehlt, wichtig ist, dass sofort etwas kommt. Daher zerscheibelt man fuer TCP den Transfer sinnvollerweise auf die maximale Blockgroesse, fuer UDP aber eher auf eine Groesse, die kontinuierliches Senden bringt.
Laut TCP Standard ist für das Aknowledge ein Zeit von bis zu 500ms zulässig. Wenn es also schnell gehen muss, bleibt nur UDP.
Brummbär schrieb: > Im privaten Netz kannst Du bei den hier besprochenen Daten (so schnell > wie mit der Maus geklickt werden kann), von "sofort" ausgehen. Die Daten > sind so klein, dass sie problemlos in ein Frame passen. Hier muss also > nichts fragmentiert und wieder in der richtigen Reihenfolge zusammen > gebaut werden. Man kann bei TCP von nichts ausgehen. ich habe mal wochenlang einen nichtreproduzierbaren Fehler gesucht, der nur beim Kunden auftrat. Ursahce war, daß bei einem Datenpaket bei dem zuerst die Länge als 2 Byte und dann di Daten gesendet wurden zwar bei den Daten geprüft wurde wie viele Bytes tatsächlich auf einen Aufruf empfangen wurden, nicht aber bei den 2 Bytes der Länge, weil die "ja am Angang des Datenpakets stehen und garantiert in den ersten Datenblock passen". Blöd gedacht und viel Ärger gekostet.
Decius schrieb: > Laut TCP Standard ist für das Aknowledge ein Zeit von bis zu 500ms > zulässig. Wenn es also schnell gehen muss, bleibt nur UDP. Die obige Aussage ist etwas unpräzise. Laut TCP-Standard muss der Empfänger ein Acknowledge innerhalb von 500ms senden. Das bedeutet aber nicht, dass es innerhalb dieser Zeit beim Sender eintreffen muss. Ganz im Gegenteil kommt es bei Netzwerkverbindungen, die eine zu geringe Übertragungsbandbreite besitzen, in solchen Fällen sogar zu Datenstau auf beiden Seiten der Verbindung. Auf der einen Seite stopft der Sender seine Retransmits in den Router, auf der anderen Seite der Empfänger seine Acknowledges. Bessere Routerimplementierungen entfernen daher bei überlasteten Leitungen bzw. Puffern selbsttätig einen Teil der Retransmits. Wie die Erfahrung nämlich zeigt, werden die o.a. Datenstaus in vielen Fällen gar nicht durch eine zu geringe Bandbreite verursacht, sondern eine kleine Störung führt zu Retransmitlawinen. Der Fachausdruck für Leitungen, die u.a. von solchen (und auch einigen anderen) Problemen betroffen sind, heißt "long fat pipe". Es würde bei weitem den Rahmen dieses Threads sprengen, all diese Themen zu diskutieren.
ArduStemmi schrieb: > Herzlichen Dank für Deine ausführliche Beschreibung. Das kann ist im > Wesentlichen, dass was ich bisher nocht verstanden hatte. Ich habe Daten > gelesen und entweder erste oder letzte Teile als Teiler eines an Sich > leeren Strings vorgefunden. Dazu kam noch erschwerend, dass ich auf der > ESP Seite Charts eingelesen habe und Bytes erwartet hatte. > > Na gut. Ich werde jetzt byteweise lesen und Schreiben und einen > Ringpuffer verwenden. Da kann ich mit dem Datentyp Byte arbeiten und > brauch mir keine Gedanken um Sonderzeichen machen. > > Danke für Eure Geduld! > > Ich hab dann doch wieder etwas gelernt. Nein nein, hier werden mal wieder Halbwissen und Märchen durch die Gegend geschoben, bis sie als "Wahrheiten" gelten... Du brauchst weder Byteweise lesen noch byteweise schreiben. Das Einzige, was Du nicht machen darfst, ist die Returnwerte von send() und receive() ignorieren. Sehr Viele wissen das auch nach 30 Jahren Lebensdauer von TCP/IP nicht! Also: Du machst einen recv() und wartest auf z.B. 10 Zeichen. Der Standardfehler ist zu denken, daß Du bei "Erfolg" des recv() (also Returnwert != -1) auch automatisch 10 Zeichen bekommen hast. In Aller Regel sind Transfers einer kleinen Zeichenmenge "atomisch," d.h. wenn eine Seite 10 Zeichen in einem send() Aufruf über TCP reinsteckt, kriegt die Andere Seite meistens auch die 10 Zeichen in einem einzigen Aufruf zurück. Es kann aber durchaus sein, daß der send() Aufruf die 10 Zeichen in 2 (low level) Pakete zerstückelt oder einen Teil in ein vorhergehendes Paket integriert und den Anderen Teil in ein Weiteres. Dann gibt Dir ein recv() mit 10 angeforderten zeichen mglw. nur einen Returnwert von 6 zurück, d.h. Du musst grundsätzlich in einer Schleife deinen Applikationspuffer voranstellen und solange weitere recv()s ansetzen, bis alle Daten zusammen sind (oder selbst verständlich bis ein Timeout eingetreten ist oder ein Fehler). Gleiches gilt auch für das send()! Ein send() mit 10 Zeichen kann auch einen Erfolgswert von 6 zurückgeben, dann muss die Applikationsseite genauso nachsynchronisieren. Solange Du diese Regeln befolgst, kannst Du fest davon ausgehen, daß TCP Dir genau den Datenstrom auf der Anderen Seite gibt, den Du auf der einen Seite hereinsteckst. Das ist die Definition von TCP, und die Sache ist nun lang genug auf der Welt, daß man davon ausgehen kann, daß eine konforme Implementation das auch garantiert. Manche TCP/IP Implementationen erlauben es, dem send() und recv() einen Parameter MSG_WAITALL mitzugeben, der erst dann zurückkehrt, wenn alle angeforderten Zeichen im Sender- bzw. Empfangspuffer verarbeitet sind. Wo es das nicht gibt oder das flag nicht benutzt wird, muss es auf Applikationsebene geschehen. All das entbindet Dich natürlich nicht von der Pflicht, das Schicht 5 Protokoll sauber zu implementieren, d.h. zu jedem Zeitpunkt genau zu wissen, wieviele Zeichen Du senden bzw. empfangen musst (davon hängt u.A. ab, wie Du die Schleife aufsetzt).
:
Bearbeitet durch User
Nachtrag: Manche Leute fragen sich nun, wie es passieren kann, dass ein "kleiner" Datensatz von einem Sender zerstückelt wird. Das hängt mit dem sogenannten "Fenster" zusammen. Während der Paketübertragung auf TCP Ebene meldet jede Seite einer offenen Verbindung der Anderen Seite in jedem Paket, wieviel Platz noch im Empfangspuffer zur Verfügung steht (das "Fenster"). Der Sender darf (auf TCP Ebene) nicht mehr Bytes in einem Paket senden, als das momentane Fenster des Empfängers gross ist. Ein typisches Szenario in unsychnronisierten Protokollen (wo also eine Seite fortwährend "neue" Pakete schickt, ohne auf ein applikatiosseitiges ACK zu warten) ist dass die empfängerseitige task, die die Daten wegschaufelt, hängt oder durch einen lockout selten dazu kömmt, Daten aus dem im TCP stack vorgehaltenen Puffer auszulesen. Was man im Sniffertrace hier sehr gut sehen kann, ist dass das Fenster dann immer kleiner wird. Das führt dann im Nachgang dazu, dass der Sender seinen eigenen Sendepuffer immer voller macht, und wenn der unter einen Schwellwert fällt, wird ein Aufruf zu send() nur noch einen Teil seiner Daten unterbringen können, und das socket API meldet das eben dadurch, dass der Returnwert von send() kleiner ist als die angeforderte Datengröße. Das Ganze darf man sich gerne als Stossdämpfer vorstellen. Die Schluckaufs in der Kommunikation werden durch die von TCP gemanagten verbindungsinternen Puffer abgefedert, aber wenn die zu heftig werden, ist das auch für die Applikation sichtbar. Diese Ausführungen haben aber erstmal nichts mit retransmissions zu tun. TCP interne retransmissions stecken nicht "mehr" Daten in einen Empfangspuffer, sondern sie synchronisieren die Sende- und Empfangspuffer miteinander. Wenn das Applikationsprotokoll allerdings fehlertolerant ist (was es selbstverständlich sein sollte), also timeouts implementiert und eigenständig nach Ablauf eines Timeouts Daten nochmal sendet, sind das für TCP "neue" Daten, die genauso den Stossdämpfer beanspruchen.
:
Bearbeitet durch User
Ruediger stellt die Sachverhalte zu den Puffer- und Fenstergrößen in TCP sehr gut und prägnant dar, ohne Fehler durch Vereinfachungen o.ä. zu begehen. Ruediger A. schrieb: > All das entbindet Dich natürlich nicht von der Pflicht, das Schicht 5 > Protokoll sauber zu implementieren, d.h. zu jedem Zeitpunkt genau zu > wissen, wieviele Zeichen Du senden bzw. empfangen musst (davon hängt > u.A. ab, wie Du die Schleife aufsetzt). Im TCP/IP-Schichtenmodell befindet sich die Applikation auf Schicht 4. Wenn es darum ginge, ein Kommunikationsprotokoll auf SSL, HTTP o.ä. aufzusetzen, z.B. indem man eine Anwendung für einen Webserver oder Servlet-Container implementiert, könnte man hier etwas unpräzise von Schicht 5 sprechen. Der Threadersteller verwendet jedoch nackte Socket-Schnittstelle, die die Funktionen der Transportschicht auf Schicht 3 bereitstellt. Somit befindet sich sein Programm auf Schicht 4. Ruediger A. schrieb: > Wenn das Applikationsprotokoll allerdings fehlertolerant ist (was es > selbstverständlich sein sollte), also timeouts implementiert und > eigenständig nach Ablauf eines Timeouts Daten nochmal sendet, sind das > für TCP "neue" Daten, die genauso den Stossdämpfer beanspruchen. Nein, in vielen Fällen sollte man keine eigenen Retransmits durchführen, insbesondere dann nicht, wenn sich die hierfür relevanten Timeouts noch innerhalb der TCP/IP-Timeouts bewegen. Ansonsten kann dies zu einer weiteren Verstopfung des Kommunikationskanals führen. Kürzere Timeouts auf Empfängerseite können hingegen durchaus sinnvoll sein, um die Anwendung z.B. in einen sicheren Zustand zu überführen, z.B. Antriebe anzuhalten. Nur wenigen Entwicklern bekannt, gibt es bei TCP auch noch die sog. Out-of-band-Signalisierung, mit der man hochpriore Daten an den schon in den Datenpuffern befindlichen "vorbeischmuggeln" kann, auch wenn das Fenster schon gefüllt ist. Allerdings sollte man bedenken, dass man sich hierdurch auch gewaltige Synchronisationsprobleme innerhalb der eigenen Applikation einhandeln kann. Die OOB-Signalisierung wird z.B. vom TELNET-Protokoll unterstützt, um Signale zu schicken, z.B. um einer Shell zu signalisieren, dass sie ein hängendes Programm beenden soll. Bei der Implementierung von Tunnelprotokollen, z.B. mittels SSH, trifft man auf das sog. TCP-over-TCP-Problem, d.h. eine stockende "äußere" TCP-Verbindung bewirkt Retransmits auch auf "inneren" TCP-Verbindungen. Deswegen verwenden viele Tunnelprotokolle stattdessen UDP für ihre äußere Verbindung oder klemmen sich zwischen Internet- und Transportschicht und verwenden UDP nur für Steuerdaten.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.