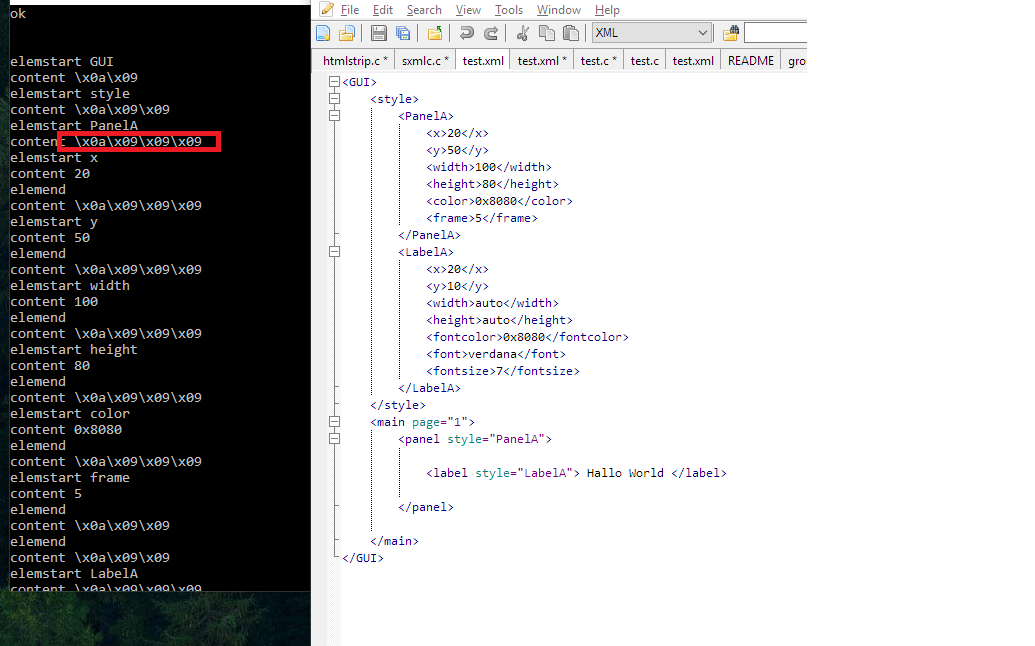
Hallo zusammen Ich habe hier: Beitrag "XML HTML CSS Interpretieren" Nach einer Möglichkeit zum parsen eines HTML gefragt. Inzwischen habe ich erkannt, dass es wohl effizienter ist, wenn ich einfach eine eigene Struktur in Form eines XMLs voraussetze anstelle einen HTML Parser zu schreiben. Ich bin nun auf yXML gestossen und bin dabei ein paar Versuche damit in Visual Studio Express durchzuführen. Anbei das erste ergebnis. Grundsätzlich funktioniert es ganz gut. Ich habe einfach ein Problem. In meinem XML File gibt es zwecks lesbarkeit, einige Tabstopps uns Linebreaks. Diese werden leider von yXML als content interpretiert. Nun dachte ich zuerst daran, einfach alle Linebreaks und Tabs zu entfernen. Was aber, wenn in einem Text tatsächlich ein Linebreak gewünscht ist? Ich konnte bisher keinen vernünftigen Ansatz finden, das Problem elegant und sauber zu lösen. Deshalb hoffe ich auf ein paar Ideen von der Community. Danke schonmal.
Angehängte Dateien:
-

xml.png
90 KB
:
Verschoben durch User
Holger K. schrieb: > In meinem XML File gibt es zwecks lesbarkeit, einige Tabstopps uns > Linebreaks. Diese werden leider von yXML als content interpretiert. yXML ist ein nicht-validierender Parser, d.h., es überprüft nicht die korrekte Reihenfolge der Elemente. Deshalb weiß es auch nicht, an welchen Stellen Text erlaubt ist, und kann also überflüssigen Text nicht entfernen. Wenn du nicht auf einen anderen Parser umsteigen willst, dann musst du dir merken, in welchem Element du gerade bist (dafür brauchst du einen Stack der Element-Namen oder -Typen), und davon abhängig Text ignorieren.
Clemens L. schrieb: > Holger K. schrieb: >> In meinem XML File gibt es zwecks lesbarkeit, einige Tabstopps uns >> Linebreaks. Diese werden leider von yXML als content interpretiert. > > yXML ist ein nicht-validierender Parser, d.h., es überprüft nicht die > korrekte Reihenfolge der Elemente. Deshalb weiß es auch nicht, an > welchen Stellen Text erlaubt ist, und kann also überflüssigen Text nicht > entfernen. > > Wenn du nicht auf einen anderen Parser umsteigen willst, dann musst du > dir merken, in welchem Element du gerade bist (dafür brauchst du einen > Stack der Element-Namen oder -Typen), und davon abhängig Text > ignorieren. Danke für deine Antwort. Dann sollte ich mir wohl doch lieber den sxmlc ansehen.
Clemens L. schrieb: > yXML ist ein nicht-validierender Parser, d.h., es überprüft nicht die > korrekte Reihenfolge der Elemente. Deshalb weiß es auch nicht, an > welchen Stellen Text erlaubt ist, und kann also überflüssigen Text nicht > entfernen. naja ohne xsd kann das kein Parser. Man ist ja immer innerhalb eines Elementes.
Holger K. schrieb: > Inzwischen habe ich erkannt, dass es wohl effizienter ist, wenn ich > einfach eine eigene Struktur in Form eines XMLs voraussetze anstelle > einen HTML Parser zu schreiben. Es ist sogar deutlich effizienter, wenn du eine eigene Struktur in JSON voraussetzen kannst. Man kann ohne weitere Probleme korrekte und wohlformatierte XML-Dokumente erstellen, die mehrere GB RAM zum Parsen benötigen. Schaue dich mal jenseits von HTML und XML um. Nachtrag: Aus einer JSON-Beschreibung eine HTML-Seite (mit CSS) zu machen ist einfacher als umgekehrt. Dein Problem ist mir nicht ganz klar, aber evtl. wäre das sinnvoller.
:
Bearbeitet durch User
Rein Interessenhalber, da ich vor ähnlichen Aufgaben stehe: - Mit welchem Tool generierst Du Deinen Input? - Welche Funktionalitäten möchtest Du am Ende damit festlegen?
HolgerKraehe schrieb: >> Schaue dich mal jenseits von HTML und XML um. > In welchem Bereich? JSON. Einfaches Format, einfach zu parsen.
Die überflüssigen Whitespace entfernt der Xml-Parser. Genau dafür gibt es die Attribute xml:space="preserve" und xml:space="default" im XML-Standard.
Noch einer schrieb: > Die überflüssigen Whitespace entfernt der Xml-Parser. Warum schreibst du das, wenn im ersten Beitrag gezeigt wird, dass der Parser es eben nicht macht? > Genau dafür gibt es die Attribute xml:space="preserve" und > xml:space="default" im XML-Standard. Die XML-Spezifikation (https://www.w3.org/TR/xml/#sec-white-space) sagt: > An XML processor MUST always pass all characters in a document that > are not markup through to the application. Das ist, was yXML macht. > A validating XML processor MUST also inform the application which > of these characters constitute white space appearing in element > content. yXML ist aber kein validierender XML-Prozessor. > A special attribute named xml:space may be attached to an element to > signal an intention that in that element, white space should be > preserved by applications. Und "signal an intention" heißt, dass man sich nicht unbedingt dran halten muss. (Und xml:space="preserve" ist hier eh' nicht gewünscht.)
> (Und xml:space="preserve" ist hier eh' nicht gewünscht.) Nanu? Hab es so verstanden: Der Parser soll mit xml:space="default" anfangen. Innerhalb von <label> soll er auf xml:space="preserve" umschalten. Stimmt das so? >yXML ist aber kein validierender XML-Prozessor. Es gibt keinen kleinen in C geschriebenen non-validating XML parser, der xml:space berücksichtigt?
Noch einer schrieb: > Es gibt keinen kleinen in C geschriebenen non-validating XML parser, der > xml:space berücksichtigt? Es gibt keinen kleinen, vollständigen XML-Parser. XML ist erstaunlich schwierig nach Standard zu parsen, deswegen haben wir die Diskussion ja.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.