Der Anlaß ist der Test des neuen Geniono 101, der ja einen schnelleren
Prozessor hat von Intel usw.
Ziel: die Geschwindigkeit der Programmausführung zu testen.
Methode: diese einfache Zählschleife (hinten gelistet).
Ergebnis an der seriellen Schnittstelle mit dem u.a. Programm:
FÜr den Uno: 378 KHz
Für den 101: 322 KHz
Was läuft da falsch? Was messe ich da eigentlich? SPielt die
COM-Schnittstelle eine ROlle?
Ich hab mit dem Uno auch schon 1.223 MHz gemessen, mit exakt demselben
Programm. Der Genuino 101 müßte doch um Längen schneller sein?
Xenophon
Programm:
Holger S. schrieb:> Serial.begin(9600);> Serial.print("Anzahl Durchgänge ");
Du hast gerade erfolgreich ein Benchmark der Geschwindigkeit eines auf
9600 Baud eingestellten Uart durchgeführt...
Das Inkrementieren einer Variable ist nun nicht gerade ein adäquater
Benchmark. Schon das Springen in und aus deiner loop-Funktion kostet
deutlich mehr Zeit als das Inkrement.
Wieso sollte er so viel schneller sein? Auf dem genuino 101 läuft doch
ein Intel-Curie oder?! Der hat ja zwei Kerne, den x86 Quark und den ARC
- bei laufen jeweils mit 32Mhz, sooo viel Unterschied dürfte das doch
gar nicht ausmachen.
Wie und auf welchem Core werden denn da diese Berechnungen
durchgeführt?! Auf den x86 Quark oder auf dem ARC? So richtig hab ich da
noch nicht durchgeblickt WELCHEN und WIE man die zwei Kerne
differenziert.
void schrieb:> Du hast gerade erfolgreich ein Benchmark der Geschwindigkeit eines auf> 9600 Baud eingestellten Uart durchgeführt...
Nö. Es wird einmal der zuvor ermittelte Messwert ausgegeben:
void schrieb:> Holger S. schrieb:>> Serial.begin(9600);>> Serial.print("Anzahl Durchgänge ");>> Du hast gerade erfolgreich ein Benchmark der Geschwindigkeit eines auf> 9600 Baud eingestellten Uart durchgeführt...
Aber wieso?
1. Damit kommt genau dasselbe heraus:
{
Serial.begin(115200);
prev_time=millis();
}
2. Ich ruf Serial.println nur einmal auf, nach 1 Mio Zähloperationen.
Ganz klar ist mir das nicht, was du meinst.
Wenn ich dieselbe Zählschleife auf meinem Billig-Laptop programmiere in
C, ist der tausend mal schneller.
WO LIEGT DER FEHLER?
Xenophon
PS: Ich hab im Eingangsbeitrag eine Klammer nicht mitkopiert. Natürlich
ist das Prog so mit Klammer zu:
void loop()
{
zaehler++;
if (zaehler>=MESSUNG)
{
periode=millis()-prev_time;
Serial.print("Anzahl Durchgänge ");
Serial.println(MESSUNG);
Serial.print("Zeit in ms ");
Serial.println(periode);
Serial.print("Frequenz kHz ");
Serial.println(MESSUNG/periode);
zaehler=0;
prev_time=millis();
} // Zaehler
}// loop
Holger S. schrieb:> Wenn ich dieselbe Zählschleife auf meinem Billig-Laptop programmiere in> C, ist der tausend mal schneller.>> WO LIEGT DER FEHLER?
An deiner Methode. Der Arduino ist ein Mikrocontroller und dein Laptop
ein PC. Auf dem Controller stehen nur kleine Speicher zur Verfügung,
wenn der etwas über UART senden will, kann er 1-2 Byte in Register
ablegen und muss dann warten bis die Hardware die Bits rausgeschoben
hat.
Auf dem PC hast du zig Puffer auf dem Weg zur Hardware, die kann dein
Programm füllen und muss nicht warten.
Der Mikrocontroller kann auch Ringpuffer etc. in der Bibliothek
mitbringen, oder DMA unterstützten. Das wird aber von der simplen,
generischen UART Lib sicher nicht unterstützt.
Holger S. schrieb:> WO LIEGT DER FEHLER?
Du kannst keinen x86 CPU mit mehreren GHz mit einem 32Mhz µC
verlgeichen. Das hingt hinten und vorne, außerdem ist das Incrementieren
eines Zählers kein adäquater Benchmark. Das kann man sich auch im Kopf
ausrechen, für einen RMW benötigt man (normalerweise, es sei denn es
gibt direkt einen Befehl dafür )drei Takte, das macht bei 32Mhz dann
10.666.666 RMW pro Sekunde - bei einer Schleife von 1.000.000
Durchgängen sind das dann 10 Durchgänge pro Sekunde.
Also schaut euch den Code an, ich sehe da keinen prinzipiellen Fehler.
Wieso das so lahm ist, ist echt eine gute Frage. Ich wäre jetzt davon
ausgegangen, dass die Frequenz bei vielleicht CPU/4 liegt
M. Keller schrieb:> Wieso das so lahm ist, ist echt eine gute Frage. Ich wäre jetzt davon> ausgegangen, dass die Frequenz bei vielleicht CPU/4 liegt
Wieso?
While(1) Schleife - 5 Takte
Zaehler++ - 3 Takte
if statement - 10 Takte
Ein CPU/18 kommt da schon eher hin ;-)
Klar, daß der PC schneller ist.
Mich interessieren eigentlich auch weniger die absoluten Werte,sondern
relative Performance, nämlich die Differenz zwischen
Genuino101 (32 MHz) und
Arduino Uno (16 MHz)
Der 101 ist doppelt so schnell getaktet. Ist aber bei dem Programm
langsamer als der Uno.
Wieso?
Irgendwas wird sich Intel doch gedacht haben, daß sie den 101 für den
mehr als doppelten Preis anbieten.
Wie kann man das denn nun so testen, daß es aussagefähig wird?
Xenophon
Holger S. schrieb:> Wie kann man das denn nun so testen, daß es aussagefähig wird?
du solltest eine eigene Schleife machen (nicht loop verwenden) damit der
ganze Overhead außenrum, der evtl. unterschiedlich ist, wegfällt
Also ich hab auch grad ein wenig herumexperimentiert. Meine USART lief
mit 56000BAUD. Ich hab Pseudozufallszahlen erzeugt, und die jeweils
einzeln mit ein wenig Text rausgegeben. Die Zufallszahlen waren 16bit
breit, also 65535 verschiedene möglich. Um einmal 65535 Zahlen zu
erzeugen und auszugeben, hat es gefühlte 5min gedauert (vermutlich
werden es ca 2 Minuten gewesen sein), und ohne Übertragung der einzelnen
Zahlen, sondern nur mit "Bescheid sagen" alle 65535 Zahlen hat es
ziemlich genau eine Sekunde gebraucht diese 65535 zu erzeugen und
Bescheid zu sagen.
Das ganze auf nem ATMEGA2560 @ 16MHz
P.S. Wenn ich nur den Überlaufszählerstand als 8bit binär übertrage,
komm ich sogar auf 0,76sek pro Durchlauf
MfG Chaos
Walter S. schrieb:> Holger S. schrieb:>> Wie kann man das denn nun so testen, daß es aussagefähig wird?>> du solltest eine eigene Schleife machen (nicht loop verwenden) damit der> ganze Overhead außenrum, der evtl. unterschiedlich ist, wegfällt
WAHNSINN
WAHNSINN
WAHNSINN
Wenn ich in das Loop() ein while(1) einsetze, geschieht folgendes:
Uno beschleunigt von 322 KhZ auf 1,3 MhZ
101 ist gar nicht mehr meßbar. Da rattern im ms-Takt 1 Milliarde
Zähloperationen durch, unfaßbar. Die Jungs von Intel wissen
wahrscheinlich schon, was sie tun. ;) Der 101 soll ja auch x86
kompatibel sein, und daß er zwei Prozessoren hat, ist wahrscheinlich
auch kein reiner Zufall. ;)
Was geschieht da? Schüttelt der Ferrari Intel das Gogomobil Framework
Arduino ab? Irgendwie sowas muß da abgehen.
Leider bei meinem Nano mit dem fertigen Programm einer Steuerung kommt
es nur von 100 auf 124, Zugewinn ja, aber doch recht spärlich.
Das mit dem 101 gibt mir zu denken. Der ist wahrscheinlich ein echter
Tiger, der im Käfig steckt.
Lohnt sich bestimmt, damit mal zu experimentieren.
Holger S. schrieb:> Wenn ich in das Loop() ein while(1) einsetze, geschieht folgendes:
...
> 101 ist gar nicht mehr meßbar. Da rattern im ms-Takt 1 Milliarde> Zähloperationen durch, unfaßbar.
Könnte das durch den Compiler wegoptimiert worden sein?
Problem ist, dass hier so viele Komponenten das Ergebnis beeinflussen,
z.B. auch Compiler und die benutzten Compiler-Switches.
Von dem x86 Quark Core hast du erstmal rein gar nichts, dort läuft ein
ViperOS der die einzelnen Komponenten des Curie "verbust" - ändern kann
man dies nicht und auch nicht neu beschreiben.
Deine erstellten Programme laufen ausschließlich auf und über den
zweiten Core, dem ARC RISC.
Zum Thema Speicher: Von den 80Kb Ram kann man maximal 24kb nutzen.
Ebenso beim Flash, er besitzt zwar 384kb, nutzbar allerdings bloß 192kb.
Irgendwie genauso eine Mogelpackung wie der Intel Gallileo 1 und 2.
Schön allerdings ist das integrierte Bluetooth, Gyro und
Beschleunigungssensor...
Markus schrieb:> Hallo Holger,>> lass doch den mal auf dem 101 laufen:>> https://www.mikrocontroller.net/attachment/highlight/327826> #
Mach ich. Vielleicht heute nicht mehr, weil Besuch kommt.
Aber das hier, das ist unfaßbar.
Ich stell mal hinten das Listing rein.
Und melde vornheraus die ERgebnisse (incl. Beweisfoto vom Bildschirm,
damit es hier nicht heißt, ich hätte Hallus ...):
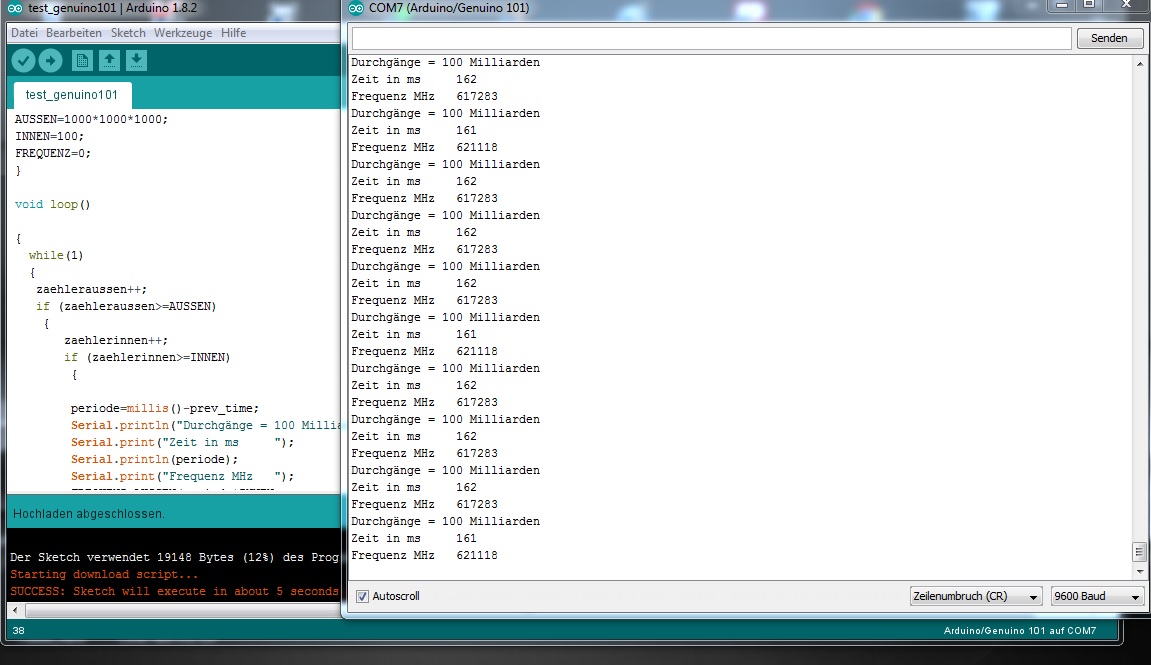
Für 100 Milliarden Zählvorgänge braucht der GEnuino101 exakt 162 ms.
Das ist eine unvorstellbare Frequenz.
Das ist WAHNSINN.
Natürlich, wer mißt, mißt Mist. Vielleicht hab ich da was übersehen.
Aber im direkten Vergleich zum uno liegen da nicht Welten dazwischen,
sondern ganze Universen, weil der Uno damit gerade mal schlappe 1,3 MHz
hinlegt. Da liegen Lichtjahre dazwischen, ich weiß nur nicht warum. An
den 32 MHz kann es nicht liegen.
Nehme ich das while(1) innerhalb des loop() raus, bricht die Performance
völlig zusammen auf besagte 220 kHz.
Also: was geht da vor?
Abbildung: Beweis, daß ich keine Hallus habe.
Sowie das komplette Programmlisting:
Holger S. schrieb:> Für 100 Milliarden Zählvorgänge braucht der GEnuino101 exakt 162 ms.>> Das ist eine unvorstellbare Frequenz.>> Das ist WAHNSINN.>> Natürlich, wer mißt, mißt Mist. Vielleicht hab ich da was übersehen.
Wie schon gesagt wurde: Der Compiler optimiert hier. Er weiß ja vorher
schon, was das Ergebnis sein wird und lässt das deshalb nicht den
Prozessor mühsam zur Laufzeit durch wiederholtes Inkrementieren
ausrechnen.
Mach doch deine Zählvariablen mal volatile, damit er auch tatsächlich
was machen muss, und schau, was dann rauskommt.
Und nochmal: Ein Inkrementieren einer Variable in einer Schleife ist
kein adäquater Benchmark. Das ist so, als ob du den Verbrauch eines
Autos darüber bewertest, wieviel Strom der Scheibenwischermotor zieht.
Holger S. schrieb:> void loop()>> {> while(1)> {> zaehleraussen++;> if (zaehleraussen>=AUSSEN)> {> zaehlerinnen ++;> if (zaehlerinnen>=INNEN)> {>> periode=millis()-prev_time;> Serial.println("Durchgänge = 100 Milliarden");> Serial.print("Zeit in ms ");> Serial.println(periode);> Serial.print("Frequenz MHz ");> FREQUENZ=AUSSEN/periode*INNEN;> Serial.println(FREQUENZ/1000);> zaehlerinnen=0;> prev_time=millis();> } // zaehlerinnen> zaehleraussen=0;> }//zaehleraussen> }//while> }// loop
Weißt du was dein Compiler dir daraus bastelt? ;-)
Im einfachsten Fall:
1
voidloop()
2
3
{
4
while(1)
5
{
6
zaehleraussen=100000000;
7
if(zaehleraussen>=AUSSEN)
8
{
9
zaehlerinnen=100;
10
if(zaehlerinnen>=INNEN)
11
{
12
13
periode=millis()-prev_time;
14
Serial.println("Durchgänge = 100 Milliarden");
15
Serial.print("Zeit in ms ");
16
Serial.println(periode);
17
Serial.print("Frequenz MHz ");
18
FREQUENZ=AUSSEN/periode*INNEN;
19
Serial.println(FREQUENZ/1000);
20
prev_time=millis();
21
}// zaehlerinnen
22
}//zaehleraussen
23
}//while
24
}// loop
Aber mit ganz großer Sicherheit dies:
1
voidloop()
2
{
3
periode=millis()-prev_time;
4
Serial.println("Durchgänge = 100 Milliarden");
5
Serial.print("Zeit in ms ");
6
Serial.println(periode);
7
Serial.print("Frequenz MHz ");
8
FREQUENZ=100000/periode*100;
9
Serial.println(FREQUENZ);
10
prev_time=millis();
11
}// loop
Und wenn er das NICHT so macht, würde ich ganz ganz arg am Compiler
zweifeln. Und je nachdem wie diese millis() aufgebaut ist, gehe ich
davon aus das dies ebenfalls wegcompiliert wird, sie macht ja im Grunde
auch keinen Sinn.
Wie oben schon erwähnt kann ein MC nicht schneller arbeiten als sein
Takt - sprich: 32Mhz bei deinem ARC. Ein Var++ (Read-Modify-Write)
dauert nunmal drei Takte, da bist du bei ~11Mhz - ein Schleifenkonstrukt
ringsrum (Ja auch Sprünge kosten Takte!) Eine Abfrage dabei... Da haut
das mit den 1,2Mhz schon hin.
Das macht ein Tiny so, ein Pic ein ARM oder whatever... Setz dich mit
der Arbeits- und Funktionsweisen von Microcontrollern bitte auseinander!
Lese die Datenblätter und verstehe den Zusammenhang zwischen Takt,
Registerbefehlen und deren Anzahl an Taktzyklen. Atmel hat zumindest in
seinen Datenblättern immer den Befehlssatz und deren Zyklen stehen.
In deinem "Benchmark" - sollte er denn Funktionieren - zeigt du
ausschließlich den Takt/3... bei jedem MC... Nen Mainstream Cortex-M0
mit 64Mhz wäre da z.b. doppelt so schnell und nen ATiny85 mit 16Mhz halb
so langsam.
Ich hoffe du verstehst so langsam was dir hier alle versuchen zu
erklären?!?
Holger S. schrieb:> Mich interessieren eigentlich auch weniger die absoluten Werte,sondern> relative Performance, nämlich die Differenz zwischen>> Genuino101 (32 MHz) und>> Arduino Uno (16 MHz)
In den achtziger Jahren waren mal zwei Benchmarks sehr populär:
whetstone und (Achtung, der Name ist ein Wortspiel:
Dhrystone
Tatsächlich hat der whetstone Benchmark nichts mit wet/nass zu tun und
der Dhrystone nichts mit dry/trocken.
da gab es damals auch die Quelltexte zu, die waren recht einfach
gehalten, der whetstone für die Messung der Leistungsfähigkeit bei
Gleitkomma-Rechenoperationen und der Dhrystone für die
Leistungsfähigkeit bei Integer-Operationen
Heutezutage sind die beide wohl ziemlich aus der Mode gekommen.
Auf einem Arduino würde ich ersatzweise vielleicht das machen:
- die Zahl PI auf tausend Nachkommastellen genau berechnen lassen und
dafür die Zeit messen.
Und je nachdem, wie lange ein Controller mit bestimmter Taktrate auf
einer bestimmten Plattform dafür braucht, kennzeichnet das die
Leistungsfähigkeit von Controller-Architektur, Taktrate und Güte des
Compilers.
Vor einer Weile habe ich mal einige Tage dran getüftelt, den Algorithmus
von borwein Bailey und Plouffe fit zu machen für die Arduino-IDE und
Arduino UNO (Atmega328 mit 16 MHz Taktrate).
Der rechnet daran einige Minuten, um Pi auf 1000 Dezimalstellen zu
berechnen.
Und ich habe mich NICHT darauf beschränkt, nur die dubiosen "HEX DIGITS"
von Pi auszurechnen, sondern ich habe auch noch eine
Dezimalstellenexpansion ausgetüftelt und drangehängt, so dass man echte
1000 Dezimalstellen bekommt und nicht nur 1000 Hex-Digits nach
borwein-bailey-plouffe.
Wenn Interesse besteht: Eventuell habe ich den Arduino-Quelltext noch
auf meiner Festplatte und könnte ihn heraussuchen und hier posten, falls
gewünscht und jemand Benchmarks mit Boards machen möchte, die von der
Arduino-IDE unterstützt werden.
>Könnte man auch mal mit stm32duino testen?
"stm32duino" beschränkt sich nicht auf eine MCU. Es werden viele mit
ganz unterschiedlichen Geschwindigkeiten unterstützt.
So ist z.B. ein BluePill Board ( STM32F103@72Mhz ) viel langsamer als
ein STM32F4 Discovery ( STM32F407@168Mhz ).
Außerdem gibt es unterschiedliche Arduino-Frameworks für die
STM-Prozessoren: Das von Roger Clark bassieren auf Maple Leaf, das von
STM und STM32GENERIC.
Ich würde momentan STM32GENERIC empfehlen, weil dort am meisten daran
gearbeitet wird und die meisten Boards unterstützt werden.
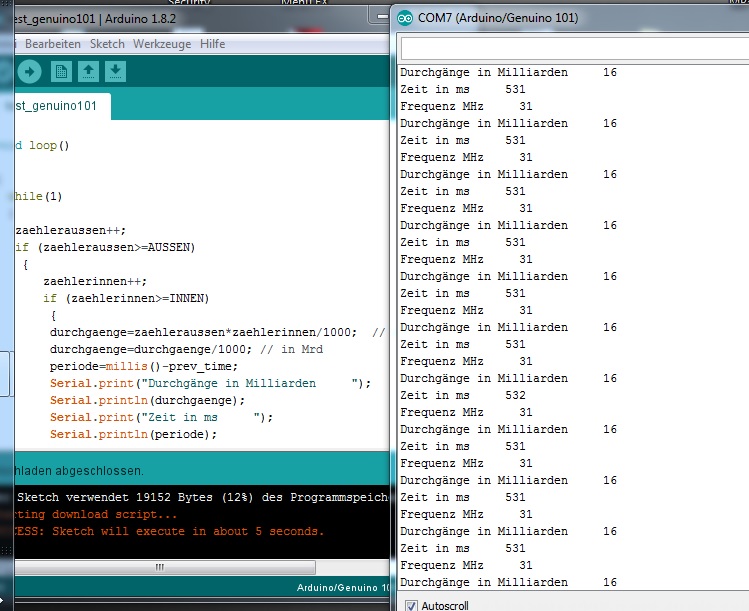
Korrektur.
Bei meiner Messung gestern abend vermute ich numerische Überläufe.
Wie hier schon gesagt wurde, die Frequenz kann nicht höher sein als die,
mit der das Bord getaktet wird, und das sind 32 MHz.
Und genauso ist es auch.
Der Genuino läuft bei dieser Zaehlschleife mit 31,x MHz.
Während der Uno mit demselben Programm 1,3 MHz läuft.
Die anderen vorgeschlagenen Möglichkeiten werde ich die nächste Zeit mal
testen. Danke für die Hinweise.
Jedenfalls in der Zählschleife ist der 101 dreiundzwanzig mal schneller
als der Uno.
Xenophon
1
intprev_time=0;
2
intperiode=0;
3
unsignedlongzaehleraussen=0;
4
unsignedlongzaehlerinnen=0;
5
unsignedlongAUSSEN=0;
6
unsignedlongFREQUENZ;
7
unsignedlongINNEN=0;
8
unsignedlongdurchgaenge=0;
9
10
11
voidsetup()
12
{
13
Serial.begin(9600);
14
prev_time=millis();
15
AUSSEN=1000*1000;
16
INNEN=1000;
17
FREQUENZ=0;
18
}
19
20
voidloop()
21
22
{
23
while(1)
24
{
25
zaehleraussen++;
26
if(zaehleraussen>=AUSSEN)
27
{
28
zaehlerinnen++;
29
if(zaehlerinnen>=INNEN)
30
{
31
durchgaenge=zaehleraussen*zaehlerinnen/1000;// in Mio
32
durchgaenge=durchgaenge/1000;// in Mrd
33
periode=millis()-prev_time;
34
Serial.print("Durchgänge in Milliarden ");
35
Serial.println(durchgaenge);
36
Serial.print("Zeit in ms ");
37
Serial.println(periode);
38
Serial.print("Frequenz MHz ");
39
FREQUENZ=(zaehlerinnen*zaehleraussen)/periode;// in kHz
Was ich noch anbieten könnte:
Einen DHRYSTONE MIPS Benchmark Test für Arduino.
Eine in den 80er Jahren revolutionäre Mini-Workstation
vom Typ VAX 11/780
der Herstellerfirma Digital Equipment schaffte es,
den DHRYSTONE Benchmark pro Sekunde 1757 mal auszuführen.
Dies wurde dann damals als "1 DHRYSTONE-MIPS" definiert.
Also 1.0 DHRYSTONE-MIPS" = 1757 DHRYSTONES pro Sekunde
Wenn ich auf meinem UNO den DHRYSTONE 300000 mal laufen lasse und die
dafür benötigte Zeit durch 300000 teile, dann komme ich drauf, dass der
DHRYSTONE auf einem Arduino UNO 56.09 Mikrosekunden dauert.
Das entspricht 17828.28 DHRYSTONES pro Sekunde
Also gut das zehnfache einer VAX 11/780 Workstation aus den 80er Jahren.
Wenn es jemand auf anderen Arduino-Boards testen möchte, kann ich den
Code hier posten, es sind zwei Dateien: Eine .ino Datei und eine .h
Hederdatei.
Also Ergebnis für einen Atmega328 @16MHz: VAX MIPS rating = 10.15
Nicht schlecht: Ein 8-Bit Mikrocontroller aus den 2010ern kommt auf die
DHRYSTONE-leistung von mehr als 10 Workstations aus den 1980er Jahren.
Die VAX 11/780 hatte seinerzeit aber auch nur 5 MHz Taktrate.
Für das STM32 Arduino Framework haben die schon für ziemlich viele
Dryhstones und Whetstones gemacht.
Ich kopier mal das erste raus:
First the integer maths Dhrystone:
ATmega2560 16MHz
Dhrystone Benchmark, Version 2.1 (Language: C)
Execution starts, 300000 runs through Dhrystone
Execution ends
Microseconds for one run through Dhrystone: 78.67
Dhrystones per Second: 12711.22
VAX MIPS rating = 7.23
STM32F103 72MHz
Dhrystone Benchmark, Version 2.1 (Language: C)
Execution starts, 300000 runs through Dhrystone
Execution ends
Microseconds for one run through Dhrystone: 11.66
Dhrystones per Second: 85762.68
VAX MIPS rating = 48.81
von http://www.stm32duino.com/viewtopic.php?f=3&t=76&hilit=benchmark
Markus schrieb:> ATmega2560 16MHz> VAX MIPS rating = 7.23>>> STM32F103 72MHz> VAX MIPS rating = 48.81
Dabei hast Du dann allerdings auf einem 16MHz Atmega eine fast 30%
niedrigere DHRYSTONE/VAX-MIPS Leistung gemessen als ich heute hier bei
mir.
Und auf der STM32F103 Plattform scheint es noch andere Zugewinne zu
geben als nur die höhere Taktfrequenz.
Die Taktfrequenz von 72MHz ist um Faktor 4.5 höher als die 16MHz des
Stmega.
Aber das VAX-MIPS Ergebnis ist um Faktor 6.75 höher geworden.
Ob der STM32F103 Controller Instruktionen effizienter ausführt ?
Oder nur der Compiler für den STM32F103 effizienteren Code erzeugt als
der AVR-GCC für den Atmega?
>Dabei hast Du dann allerdings auf einem 16MHz Atmega eine fast 30%>niedrigere DHRYSTONE/VAX-MIPS Leistung gemessen als ich heute hier bei>mir.
Ich habe die Ergebnisse nur aus dem Link kopiert. In dem Link gibt es
noch viel mehr Messungen und es wird auch ausgiebig diskutiert.
Ich vermute mal die Unterschiede zu Deiner Messung kommen einfach von
der Implementierung.
Beim Geschwindigkeitsvergleich von ATMEGA zu STM32F103 spielt nicht nur
die Taktfrequenz eine Rolle. Da gibt es auch die Wortbreite von 32Bit
und die Waitstates bei 72Mhz, die den Controller wieder bremsen.
Wenn man ein 8Bit Programm auf einen 32Bit ARM überträgt, kann es sein,
dass es nicht die maximal mögliche Geschwindigkeit erreicht, weil der
ARM Zeit braucht, um mit kürzeren Wortlängen zu arbeiten.
Als Richtwert kann man sich so ca. Faktor 3..6 zwischen ATMEGA und F103
merken
Holger S. schrieb:> Für 100 Milliarden Zählvorgänge braucht der GEnuino101 exakt 162 ms.>> Das ist eine unvorstellbare Frequenz.>> Das ist WAHNSINN.>> Natürlich, wer mißt, mißt Mist. Vielleicht hab ich da was übersehen.
Warum überprüfst du deine Ergebnisse nicht auf Plausibilität?
0,162 s
-------- = 1,62 ps
100 x 10^9
Das ist nicht Wahnsinn - das ist Blödsinn.
Auch wenn hier an konkretem Benchmark-Code kein großes Interesse
besteht, poste ich doch mal wenigstens einen Link zu einem
Arduino-Sketch mit Code für
einen Whetstone-Benchmark:
https://github.com/ghalfacree/Arduino-Sketches/blob/master/Whetstone/Whetstone.ino
Die Ausgabe auf einem Arduino UNO (Atmega328 mit 16 MHz) im seriellen
Monitor ist:
Loops: 1000, Iterations: 1, Duration: 16050 ms.
C Converted Single Precision Whetstones: 6.23 MIPS
Nochmal der Hinweis:
Der Whetstone-Benchmark liefertim wesentlichen ein Maß für die
Performanche bei Gleitkomma-Berechnungen.
Also gut ...
Auf dem STM32F4 Discovery ergibt der Benchmark:
Loops: 1000, Iterations: 1, Duration: 917 ms.
C Converted Single Precision Whetstones: 109.05 MIPS
Markus schrieb:> Also gut ...> Auf dem STM32F4 Discovery ergibt der Benchmark:>> Loops: 1000, Iterations: 1, Duration: 917 ms.> C Converted Single Precision Whetstones: 109.05 MIPS
Schön, dass Du Dir die Mühe gemacht hast-DANKE!
Also circa 17.5-fache Gleitkomma-Performance beim STM32F4 gegenüber dem
Atmega, bei nur 4.5-facher Taktrate.
Das ist sicher der Floating-Point-Unit (FPU) geschuldet, die in der ARM
Cortex-M4 Architektur vorhanden ist.
Gleitkommarechnungen in Hardware sind sicher vielfach schneller als mit
der AVR math-Library.
Ob der Themenstarter wohl auch noch mitliest und den Whetstone-Benchmark
mal auf seinem Arduino 101 laufen läßt?
>bei nur 4.5-facher Taktrate.
Das Discovery Board läuft aber mit 168Mhz.
Daher ist die Gleitkomma-Performance eher verdächtig niedrig, denn er
hat ja einen extra UNIT.
Markus schrieb:>>bei nur 4.5-facher Taktrate.> Das Discovery Board läuft aber mit 168Mhz.> Daher ist die Gleitkomma-Performance eher verdächtig niedrig, denn er> hat ja einen extra UNIT.
Die FPU muss man aber explizit aktivieren, wenn ich ich recht entsinne.
Die ist für das STM32GENERIC Arduino Framework standardmässig mit
fpu=fpv4-sp-d16
aktiviert:
...AppData\Local\Arduino15\packages\STM32\tools\arm-none-eabi-gcc\4.8.3-
2014q1/bin/arm-none-eabi-gcc" -mcpu=cortex-m4 -mfpu=fpv4-sp-d16
-mfloat-abi=hard -DF_CPU=168000000L -mthumb -c -g -MMD -Os -w -std=gnu11
-ffunction-sections -fdata-sections -nostdlib --param
max-inline-insns-single=500 -Dprintf=iprintf -MMD -DSTM32F4
-DARDUINO=10800 -DARDUINO_DISCOVERY_F407VG -DARDUINO_ARCH_STM32
-DSTM32F407VG -DHSE_VALUE=8000000 -DMENU_USB_SERIAL
-DMENU_SERIAL=SerialUSB "
Erklärung siehe https://gcc.gnu.org/onlinedocs/gcc/ARM-Options.html :
-mfpu=name
This specifies what floating-point hardware (or hardware emulation)
is available on the target. Permissible names are: ‘vfpv2’, ‘vfpv3’,
‘vfpv3-fp16’, ‘vfpv3-d16’, ‘vfpv3-d16-fp16’, ‘vfpv3xd’, ‘vfpv3xd-fp16’,
‘neon-vfpv3’, ‘neon-fp16’, ‘vfpv4’, ‘vfpv4-d16’, ‘fpv4-sp-d16’,
‘neon-vfpv4’, ‘fpv5-d16’, ‘fpv5-sp-d16’, ‘fp-armv8’, ‘neon-fp-armv8’ and
‘crypto-neon-fp-armv8’. Note that ‘neon’ is an alias for ‘neon-vfpv3’
and ‘vfp’ is an alias for ‘vfpv2’.
If -msoft-float is specified this specifies the format of
floating-point values.
If the selected floating-point hardware includes the NEON extension
(e.g. -mfpu=‘neon’), note that floating-point operations are not
generated by GCC’s auto-vectorization pass unless
-funsafe-math-optimizations is also specified. This is because NEON
hardware does not fully implement the IEEE 754 standard for
floating-point arithmetic (in particular denormal values are treated as
zero), so the use of NEON instructions may lead to a loss of precision.
You can also set the fpu name at function level by using the
target("fpu=") function attributes (see ARM Function Attributes) or
pragmas (see Function Specific Option Pragmas).
-mfp16-format=name
Specify the format of the __fp16 half-precision floating-point type.
Permissible names are ‘none’, ‘ieee’, and ‘alternative’; the default is
‘none’, in which case the __fp16 type is not defined. See
Half-Precision, for more information.
Jürgen S. schrieb:> Also circa 17.5-fache Gleitkomma-Performance beim STM32F4 gegenüber dem> Atmega, bei nur 4.5-facher Taktrate.
Da wird beim F407 wohl double gerechnet worden sein. Beim direkten
Vergleich mit float-Zahlen würde ich Faktor 300-500 erwarten.
m.n. schrieb:> Da wird beim F407 wohl double gerechnet worden sein. Beim direkten> Vergleich mit float-Zahlen würde ich Faktor 300-500 erwarten.
Ich habe keine Ahnung.
Jedenfalls:Auch beim Vergleich Arduino DUE (ARM Cortex-M3 mit 84MHz)
ergibt sich eine enttäuschende whetstone-Performance im Vergleich zum
UNO (Atmega mit 16 MHz):
Der Arduino DUE ist beim Whetstone-Benchmark nur ca. 30% schneller als
der Arduino UNO.
Trotz fünffachem Controller-Takt.
Mein Whetstone-Messergebnis mit dem Arduino DUE Board:
Whetstone Benchmark, Version 1.2 (Language: C)
Loops: 1000, Iterations: 1, Duration: 12815 ms.
C Converted Single Precision Whetstones: 7.80 MIPS
Aus meiner Sicht spricht das für die exorbitant performante
Implementierung der "math" Library in der AVR LIBC: Handoptimierte
Assembler-Routinen für Gleitkommaberechnungen.
Ein ARM Cortex-M3 hat zwar auch keine Hardware-FPU für 32-Bit 'single
precision Gleitkommarechnungen, also kein Unterschied zum Atmega, aber
offensichtlich sind die math-Funktionen für 'float' vergleichsweise viel
weniger performant als die math-Funktionen der AVR-LIBC für AVR.
Sonst müßte eine fünffach höhere Taktrate zu einer deutlichen Steigerung
der Whetstone-Performance führen, was beim Arduino DUE im Vergleich zum
UNO aber nicht der Fall ist.
Beim DHRYSTONE-Benchmark dagegen passt es:
Der DUE mit 84 MHz liefert circa fünfmal mehr Dhrystones pro Sekunde als
ein UNO mit 16 MHz.
>Aus meiner Sicht spricht das für die exorbitant performante>Implementierung der "math" Library in der AVR LIBC: Handoptimierte>Assembler-Routinen für Gleitkommaberechnungen.
Ich traue der Sache nicht.
Wenn ich das Ergebnis für den Arduino UNO genau ansehe
>C Converted Single Precision Whetstones: 6.23 MIPS
Und die MIPS als Floating Point MIPS interpretiere, kann das gar nicht
sein.
Das wären 3 Befehle für eine Fließkomma Instruktion und das ist meiner
Meinung nach auch bei Hand-optimierten Funktionen nicht möglich.
>>C Converted Single Precision Whetstones: 6.23 MIPS>> Und die MIPS als Floating Point MIPS interpretiere, kann das gar nicht> sein.
Da hast Du natürlich recht, und das ist wohl auch nicht gemeint.
Tatsächlich kommst Du wohl etwas ins Schwimmen bei gebräuchlichen
Benchmark-Abkürzungen wie
MIPS MOPS, FLOPS und MFLOPS
MIPS= Millionen Instruktionen pro Sekunde
Und zwar mit Bezug auf den DHRYSTONE-Benchmark auf einer VAX11/780.
Aufgrund des Dhrystone-Benchmarks wurde seinerzeit für die VAX 11/780
eine Leistung von 1 MIPS festgelegt.
Wenn man anstelle des Dhrystone-Bencharks auf derselben Maschine den
Whetstone-Benchmark laufen läßt, ändert sich an den 1 MIPS nichts.
Und wenn eine andere Maschine den Dhrystone-Benschmark in einem sechstel
der Zeit absolviert, hat sie 6 VAX-MIPS.
Und dieselbe Milchmädchen-Rechnung kannst u mit dem Whetstone-Benchmark
machen:
Wenn ein anderes System für den Whetstone-Test nur ein sechstel der Zeit
benötigt, wie das 1-MIPS-System VAX 11/780, dann beträgt die Leistung 6
VAX-MIPS.
Eine Gleitkomma-Operationwäre ein FLOP (floating-point operation".
Tausend sind ein Kilo-FLOP.
Eine Million ein MEGA-FLOP.
aber von FLOPS, kFLOPS oder gar MFLOPS ist beim Whetstone für den
Arduino überhaupt nicht die Rede.
Und MIPS verstehe ich immer als "Dhrystone VAX-MIPS.
Und 6 MIPS beim Whetstone steht NICHT für 6 MFLOPS, sondern dafür, dass
der Whetstone-Benschmark in einem sechstel der Zeit absolviert wird wie
auf der 1-MIPS Maschine VAX11/780
> Eine in den 80er Jahren revolutionäre Mini-Workstation> vom Typ VAX 11/780
Guter Witz!
Zu einer VAX-11/780 gehört ein Schreibtisch; wohingegen eine
Workstation auf/unter einen Schreibtisch passt.
Eine VAX-11/780 füllt so ca. 3 Schaltschränke voller Höhe. Im
Grundausbau, ohne wesentliche Peripherie. Aber das hat ab 1977, als die
11/780 auf den Markt kam, "niemand gestört".
Eine Mini-Workstation passt definitiv auf einen Schreibtisch: z.b. die
VAXStation3100/76 und die VAXStation4000/60 welche ich hier noch horte.
Diese haben das Volumen eines heutigen PC Towergehäuses, bloss liegend.
>C Converted Single Precision Whetstones: 7.80 MIPS>Und dieselbe Milchmädchen-Rechnung kannst u mit dem Whetstone-Benchmark>machen:>Wenn ein anderes System für den Whetstone-Test nur ein sechstel der Zeit>benötigt, wie das 1-MIPS-System VAX 11/780, dann beträgt die Leistung 6>VAX-MIPS
Dann würde ich sagen, ist der Whetstone-Test für die Ermittelung der
Floating Point Leistung ziemlich ungeeignet.
Ich schlage MAC/Sec vor.
> Ich habe keine Ahnung.
Ja aber: Wozu brauchen Antuinof1ckler einen Benchmark?
Das es schnarchlangsam ist, hat sich ja wohl schon herumgesprochen.
Der angpeilten Zielgruppe: technisch unbegabte "Kuenstler" und
Konsorten ist die Performance doch voellig egal.
Markus schrieb:>>Wenn ein anderes System für den Whetstone-Test nur ein sechstel der Zeit>>benötigt, wie das 1-MIPS-System VAX 11/780, dann beträgt die Leistung 6>>VAX-MIPS>> Dann würde ich sagen, ist der Whetstone-Test für die Ermittelung der> Floating Point Leistung ziemlich ungeeignet.
Und warum würdest du das sagen?
Markus schrieb:> Dann würde ich sagen, ist der Whetstone-Test für die Ermittelung der> Floating Point Leistung ziemlich ungeeignet.>> Ich schlage MAC/Sec vor.
Ja, Du hast Recht, die Whetstone-MIPS sind als Zahl für sich alleine
wohl wenig aussagekräftig, auch als Vergleichszahl.
Für die Messung der Gleitkomma-Performance in absoluten Zahlen fällt mir
noch der LINPACK-Benchmark ein, der wurde jahrelang eingesetzt, um die
Performance von Supercomputersystemen untereinander zu vergleichen.
Der LINPACK wirft als Zahl am Ende direkt MEGAFLOPS (MFLOPS) aus.
Und mit Hilfe von Google habe ich heute sogar einen LINPACK Benchmark
für Arduino gefunden.
Und gleich mal mit einem Arduino UNO und einem Arduino DUE getestet.
Die gemessenen Geschwindigkeiten differieren von Durchgang zu Durchgang
geringfügig, aber im Schnitt ergibt sich, wenn man die Mega-FLOPS in
Kilo-FLOPS umrechnet:
Arduino UNO: 77 KFLOPS
Arduino DUE: 392 KFLOPS
Der Faktor 392/77 korreliert dabei recht gut mit dem Verhältnis der
Taktfrequenzen 84MHz/16MHz
Wobei das vermutlich eher Zufall ist:
Der DUE rechnet den Benchmark wohl mit echten 64-bit 'double'.
Und beim UNO sind 'double' ja tatsächlich nur 32-bit 'float'
Dafür ist der DUE ein 32-Bit Controller und der UNO nur ein 8-Bitter.
Und rein zufällig hebt es sich so auf, dass die Gleitkomma-Performance
plattformübergreifend ziemlich genau von der Taktfrequenz abhängt.
>Und mit Hilfe von Google habe ich heute sogar einen LINPACK Benchmark>für Arduino gefunden.
Poste den doch mal hier im Arduino kompatiblen Format, dann kann ich den
mal auf dem STM laufen lassen.
Markus schrieb:>>Und mit Hilfe von Google habe ich heute sogar einen LINPACK Benchmark>>für Arduino gefunden.> Poste den doch mal hier im Arduino kompatiblen Format, dann kann ich den> mal auf dem STM laufen lassen.
OK, hier der LINPACK-Benchmark für Arduino:(Im Dateianhang zu diesem
Posting)
Markus schrieb:> Hallo Jürgen, da sind Haufenweise "printf" im Code.> Das geht beim STM irgendwo hin ...
Ja, habe ich gesehen.
Aber hast Du das jetzt ausprobiert, oder nur geraten, dass printf auf
Deiner Plattform von der Arduino-IDE mit diesem Sketch nicht unterstützt
wird?
Denn normalerweise hat ein UNO, DUE, etc. zwar kein
Standard-Ausgabegerät, aber IN DIESEM SKETCH wird ein Stream als FILE
erzeugt und auf Serial umgeleitet, so dass die printf Ausgaben dann
nicht im Nirvana, sonden auf Serial landen.
Das sind die entscheidenden Zeilen im Sketch:
# include <stdio.h>
und:
static FILE uartout = {0} ;
static int uart_putchar (char c, FILE *stream)
{
Serial.write(c) ;
return 0 ;
}
Und natürlich " Serial.begin(9600) ;" in der setup() Funktion nicht zu
vergessen.
Auf dem UNO (Plattform AVR/ATMEGA) und dem DUE (Plattform ARM/Cortex-M3)
funktioniert es jedenfalls.
Code compiliert einwandfrei.
Auf das gewünschte Board laden und den seriellen Monitor öffnen.
Mehr Aufwand ist das nicht, um printf auf Serial umzuleiten.
Jedenfalls beim UNO oder DUE und dem geposteten LINPACK Benchmark.
Ich habe es mit der Arduino-IDE 1.8.1 getestet.
Aber es mag natürlich sein, dass manche
Nicht-Arduino-Controllerplattformen von der Arduino-IDE nicht dieselbe
Unterstützung bekommen wie Arduino UNO und Arduino DUE.
>Auf dem UNO (Plattform AVR/ATMEGA) und dem DUE (Plattform ARM/Cortex-M3)>funktioniert es jedenfalls.
Auf dem STM nicht. Aber da bin ich auch zu faul zu suchen, warum.
Markus schrieb:> Auf dem STM nicht. Aber da bin ich auch zu faul zu suchen, warum.
OK, ich werde jetzt einfach mal den Versuch machen, und mich über den
Tellerrand von Arduino UNO und DUE hinauswagen.
Aber Dein 168 MHz Board ist mir dafür einfach zu teuer, um nur mal zu
gucken.
Ich bestelle mir nun in China ein 2-Euro Board mit 32-Bit Controller:
Arduino IDE kompatibles Board STM32 STM32f103C8T6 ST ARM 32-bit Cortex
-M3
Und dann schaue ich mal, wie ich das in die Arduino-IDE eingebunden
bekomme, und was die Benchmarks DHRYSTONE, WHETSTONE und LINPACK auf dem
Board auswerfen.
Und wenn der Arduino-LINPACK nicht direkt auf dem kleinen STM32 läuft,
werde ich mir mal die Mühe machen, ihn zum Laufen zu bekommen. Notfalls
dadurch, dass alle printf() Ausgaben auf Serial.print umgeschrieben
werden. Das kann ja wohl kein großer Aufwand sein, denn der LINPACK gibt
ja keine Romane aus, sondern nur ein paar Stichworte mit Zahlen.
Zwei Euro für ein 32-Bit Developer-Board, da lohnt es sich ja echt
nicht, noch irgendwas mit AtTiny85 8-Bittern zu basteln.
Holger S. schrieb:> Ich hab mit dem Uno auch schon 1.223 MHz gemessen, mit exakt demselben> Programm. Der Genuino 101 müßte doch um Längen schneller sein?
snap
> void loop()> }
Snip
Benchmarks in C sind eh Humbug, das misst nur ob der C-Compiler schlecht
oder schlechter ist - erst in Assembler geschrieben deckt ein Bemchmark
Stärken/Schwächen der CPU auf.
Und ohnehin gilt für jeden Benchmark das was für den MIPS-Benchmark gilt
- "Meaningless Indication of Processor Speed" oder auch
"Meaningless Information Provided by Sales droids"
... oder berechne Apfelmännchen immer mit den selben Parametern ...
Aber grundsätzlich bin auch ich der Meinung, dass man bei Arduino nicht
an der richtigen Stelle ist, wenn man nach Leistung schreit.
Gruß
Jobst
>Aber grundsätzlich bin auch ich der Meinung, dass man bei Arduino nicht>an der richtigen Stelle ist, wenn man nach Leistung schreit.
Im Bezug auf den Rechenkern ist es egal. Nur wenn man die Peripherie
ausreizen will, spielt es eine Rolle.
Whetstone oder Drystone laufen gleich schnell. Mit oder ohne Arduino.
Bitwurschtler (Gast)
>Benchmarks in C sind eh Humbug, das misst nur ob der C-Compiler schlecht>oder schlechter ist - erst in Assembler geschrieben deckt ein Bemchmark>Stärken/Schwächen der CPU auf.
Nö, sind sie nicht wenn sich die Leute für die real erzielten Ergebnisse
ihres Compilers interessieren und nicht für theoretische Höchstmarken.
Markus schrieb:>>Aber grundsätzlich bin auch ich der Meinung, dass man bei Arduino nicht>>an der richtigen Stelle ist, wenn man nach Leistung schreit.>> Im Bezug auf den Rechenkern ist es egal. Nur wenn man die Peripherie> ausreizen will, spielt es eine Rolle.> Whetstone oder Drystone laufen gleich schnell. Mit oder ohne Arduino.
Ich glaube es ging Jobst darum, dass ein typischer Arduino-Nutzer
entweder direkt (durch eigenen Code) oder indirekt (durch irgendwelche
Libraries) dafür sorgt, dass der Prozessor 95% seiner Zeit in
irgendwelchen delay()-Schleifen verbummelt. Will man den Mikrocontroller
also um den Faktor 20 schneller machen, muss man lediglich die
delay()-Geschichte loswerden. Auf der anderen Seite gibt es für
ungenutzte Rechenzeit kein Geld zurück (es sei denn der Controller hängt
an einer Batterie) und 99% aller Arduino-Projekte die ich bisher so in
freier Wildbahn gesehen habe waren schon mit dem ATMega 328 völlig
übermotorisiert. Was willst du denn mit der nichtgenutzten Rechenzeit
machen? Bitcoins minen?
Es gibt sicher einige Argumente warum ein STM32 in der Praxis
leistungsfähiger ist als ein ATMega aber die reine Rechenleistung steht
da meiner Meinung nach sehr weit hinten in der Liste.
Jürgen S. schrieb:> Ich bestelle mir nun in China ein 2-Euro Board mit 32-Bit Controller:>> Arduino IDE kompatibles Board STM32 STM32f103C8T6 ST ARM 32-bit Cortex> -M3>> Und dann schaue ich mal, wie ich das in die Arduino-IDE eingebunden> bekomme, und was die Benchmarks DHRYSTONE, WHETSTONE und LINPACK auf dem> Board auswerfen.>> Und wenn der Arduino-LINPACK nicht direkt auf dem kleinen STM32 läuft,> werde ich mir mal die Mühe machen, ihn zum Laufen zu bekommen. Notfalls> dadurch, dass alle printf() Ausgaben auf Serial.print umgeschrieben> werden. Das kann ja wohl kein großer Aufwand sein, denn der LINPACK gibt> ja keine Romane aus, sondern nur ein paar Stichworte mit Zahlen.>> Zwei Euro für ein 32-Bit Developer-Board, da lohnt es sich ja echt> nicht, noch irgendwas mit AtTiny85 8-Bittern zu basteln.
Das ist so ein Blu Pill Board?
http://wiki.stm32duino.com/index.php?title=Blue_Pill
Lief bei mir eigentlich recht problemlos gleich unter Linux. Musste nur
paar Tools für den Upload passend für mein System neu compilieren.
Hast gleich den ST Link V2 mitbestellt? Sonst ist ner Upload bisserl
nervig.
Die Attiny werden den Vorteil mit den 5V Ausgängen haben. Bei stm32 halt
nur 3,3V, weshalb man manchmal Level-Shifter braucht.
Aber vom Preis-Leistungsverhältnis scheinen mir AtMega und Co kaum noch
Sinn zu machen.
Ich hab übrigens gerade das Problem, dass man das Board unter stm32duino
nicht so einfach richtig zum Stromsparen bekommt, wie es aussieht. Man
scheint nicht auf alle Teile Zugriff zu haben.
Muss ich wohl noch bisserl tüfteln...
Jürgen S. schrieb:> Und wenn der Arduino-LINPACK nicht direkt auf dem kleinen STM32 läuft,> werde ich mir mal die Mühe machen, ihn zum Laufen zu bekommen. Notfalls
Hier:
ESP 8266
Und hier das Nucleo 64 L476RG
http://www.st.com/en/evaluation-tools/nucleo-l476rg.html
Loops: 1000, Iterations: 1, Duration: 2014 ms.
C Converted Single Precision Whetstones: 49.65 MIPS
Nur halb so schnell ? wie das
>Auf dem STM32F4 Discovery>Loops: 1000, Iterations: 1, Duration: 917 ms.>C Converted Single Precision Whetstones: 109.05 MIPS
Hier der Benchmark für ein STM32F746 Discovery@216Mhz:
Loops: 1000, Iterations: 1, Duration: 493 ms.
C Converted Single Precision Whetstones: 202.84 MIPS
Doppelt so schnell wie das F4 Discovery.
Nicht schlecht, Herr Specht :-)