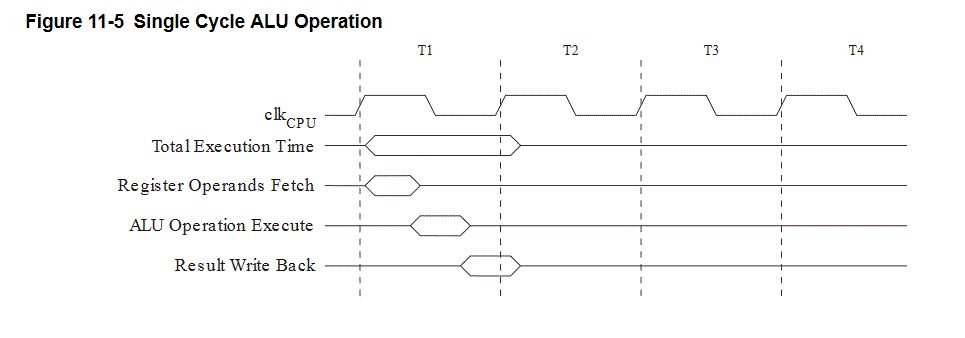
Hey, ich lese gerade das Datenblatt zum ATMega8 und wundere mich etwas darüber, dass der ALU offenbar mehrere -nun ja, am ehesen würde ich sie Instruktionen nennen - pro Taktereignis ausführen kann. Hier sieht man im Dokument (http://www.atmel.com/images/atmel-8159-8-bit-avr-microcontroller-atmega8a_datasheet.pdf, S. 30), dass der Alu innerhalb von einem Takt sowohl die Operanden einliest, die Rechenoperation ausführt wie auch das Ergebnis zurückschreibt. Wie funktioniert sowas auf Hardwareebene? Wird der Takt irgendwie verzögert auf Subschaltkreise des ALUs weitergeleitet? Mit freundlichen Grüßen
Das eine geschieht bei der negativen Clock-Flanke, das andere bei der positiven Clock-Flanke. Wenn ich mich recht entsinne...
_self schrieb: > dass der ALU offenbar mehrere -nun ja, am ehesen würde ich sie > Instruktionen nennen - pro Taktereignis ausführen kann. WO???? liest du das? Fetch, Execute und Writeback sind EINE INSTRUCTION!
:
Bearbeitet durch User
Da steht keine Subtakt-Sequenz oder Delayline dahinter. Wie man schon am Bild darüber erkennt, sind die dicken Teile der Balken jene Phasen, in denen dieser Teil der CPU relevant ist. Der Rest ist kein Tristate-Zustand, das sieht aufgrund der an Buszustände erinnernden Darstellung nur so aus. Aus dem Registerfile wird in der ersten Takthälfte gelesen, danach bleiben die Daten stabil. In das Registerfile wird nur in der zweiten Takthälfte geschrieben, was davor kommt wird ignoriert. Die ALU verbindet die beiden Read-Ports mit ihrer Operation mit dem Write-Port. Bevor die Daten aus dem Registerfile da sind und durch die ALU durch sind liefert die ALU Schrott, aber das stört nicht.
:
Bearbeitet durch User
Nur ist das, worum es hier gerade geht, keine Pipeline.
Angehängte Dateien:
-

alu.GIF
11 KB
{kind=link}
Das Bild ist gemeint? Das ist ein rein kombinatorischer Vorgang. Erst der Write-Back führt wieder zum latching der Daten. Da nichts besonders dran und es sind auch keine "sub-clocks" notwendig. Natürlich erlaubt eine solche Architektur keine sehr hohen Taktfrequenzen, aber das ist beim AVR wohl egal, da er sowieso durch da langsame Flash begrenzt ist.
:
Bearbeitet durch User
Tim . schrieb: > Das Bild ist gemeint? > > Das ist ein rein kombinatorischer Vorgang. Erst der Write-Back führt > wieder zum latching der Daten. Da nichts besonders dran und es sind auch > keine "sub-clocks" notwendig. Yep. Etwas irreführend an dem Bild ist, daß das Lesen der Operanden, die Verarbeitung und das Writeback so dargestellt ist, als wären es drei separate Vorgänge. Sind sie nicht. Das passiert alles gleichzeitig. Am Beginn des Zyklus schaltet ein Multiplexer die beiden Operanden auf die Eingänge der ALU. Die ALU selber führt praktisch ununterbrochen ihre Arbeit durch (ein paar Bits aus dem Befehlsdecoder sagen ihr dabei, was genau sie tun soll, z.B. ADD oder AND). Und am Ende des Zyklus wird das Ergebnis aus der ALU im Zielregister gelatcht. > Natürlich erlaubt eine solche Architektur keine sehr hohen > Taktfrequenzen Entscheidend ist nicht die Taktfrequenz, sondern der Durchsatz. Wenn man mehr Verarbeitungsschritte asynchron macht, dann braucht es wegen der Laufzeiten natürlich länger, bis das Ergebnis "steht". Wenn man die Verarbeitung in kleinere, taktsynchrone Einheiten aufteilt, dann wird zwar jede Einheit für sich schneller fertig, aber die Instruktion braucht am Ende genauso lange oder sogar länger. Klassisches Beispiel ist Z80 vs. 6502. Der erstere ist synchron aufgebaut und braucht entsprechend mehr Takte pro Instruktion. In der Praxis sind ein Z80 bei 2.5MHz und ein 6502 bei 1MHz ungefähr gleich schnell.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.