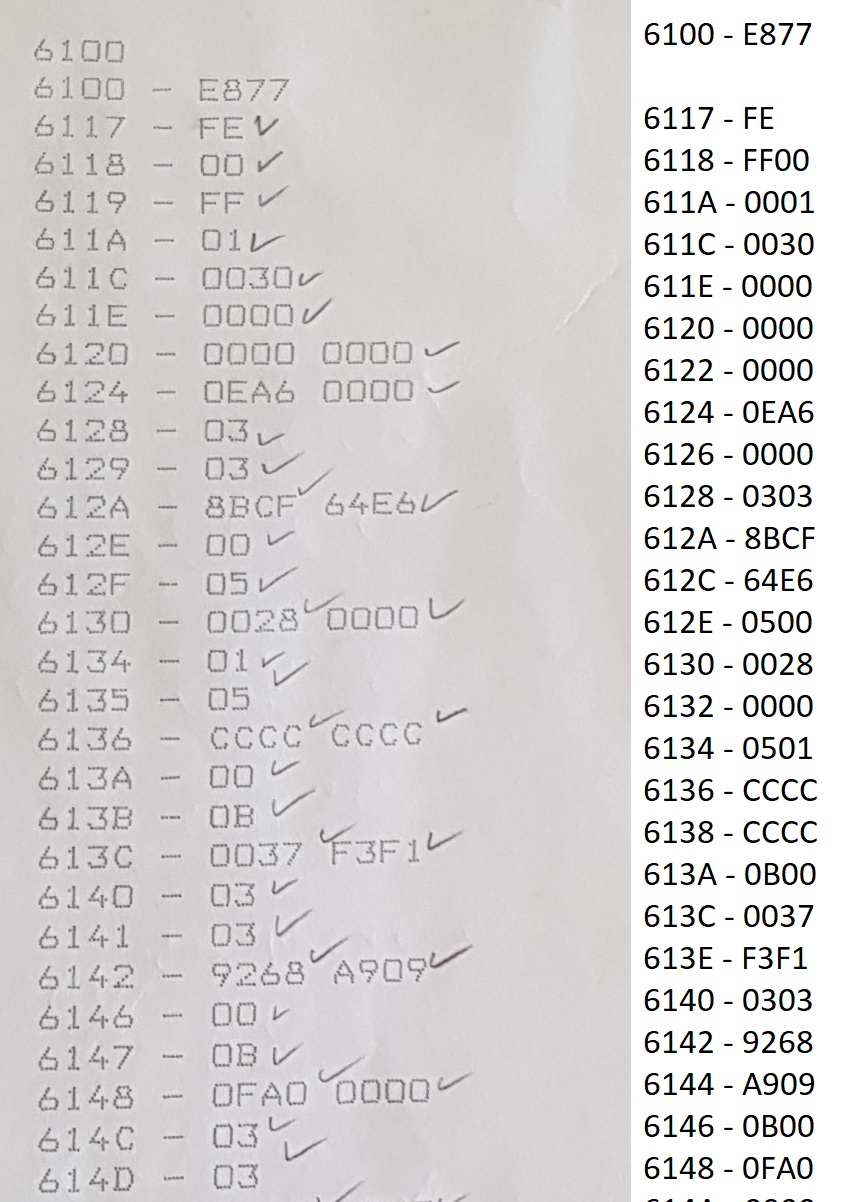
Hallo, ich stehe gerade etwas auf dem schlauch. <Habe den Beitrag leider ins falsch Forum gestellt bitte verschieben.> ich habe auf einem Endlospapier Maschinendaten die in einen speicher eingelesen werden sollen. ich schreibe sie von Hand in eine Programm welches mir die Daten per rs232 in die Maschine einlädt. jedoch verstehe ich die Adressierung der Bytes und doppelwörter noch nicht ganz. bei dem Bytes habe ich nun schon raus gefunden das die angegebene Adresse die hintere ist also wenn die Adresse 611A lautet muss es im Word an der hinteren stelle stehen. warum das so ist ist mir noch nicht 100%klar. bei dem Doppelwort weiß ich jedoch nicht ob das auch so läuft. wenn ich zb. Adresse 612A habe und die Daten 8BCF 64E6 welches Word wird in 612A und welches in 612C geschrieben.... Anbei ein kleines bild um es verständlich zu zeigen, links die Papier Daten und rechts mein abgeschriebenes. grüße
Angehängte Dateien:
-

Byte.jpg
280 KB
Die Fragestellung lässt sich nicht beantworten. Der Unterschied, in welcher Reihenfolge die zwei Bytes, aus denen ein 16-Bit-Wert, und die vier Bytes, aus denen ein 32-Bit-Wert gebildet werden, im Speicher angeordnet sind, ist von der Prozessorarchitektur abhängig und wird als "Little Endian" und "Big Endian" bezeichnet. https://de.wikipedia.org/wiki/Byte-Reihenfolge Solange Du nur eine Darstellung wie auf Deinem Ausdruck hast, *kann man nicht erkennen*, welche Variante vorliegt.
Danke für die schnelle Antwort kann man das auch nicht daraus erkennen dass das Byte mit der angegebenen Adresse hinten in einem Wort steht ? das wüsste ich ganz genau weil auslesen kann ich die wort teile mit angeben der adresse. nur ein Doppelwort kann ich nicht in einem anzeigen lassen
Aaron C. schrieb: > kann man das auch nicht daraus erkennen dass das Byte mit der > angegebenen Adresse hinten in einem Wort steht ? Was magst Du damit meinen? Wo in Deinem Ausdruck siehst Du so etwas?
Angehängte Dateien:
-

highlow.jpg
120 KB
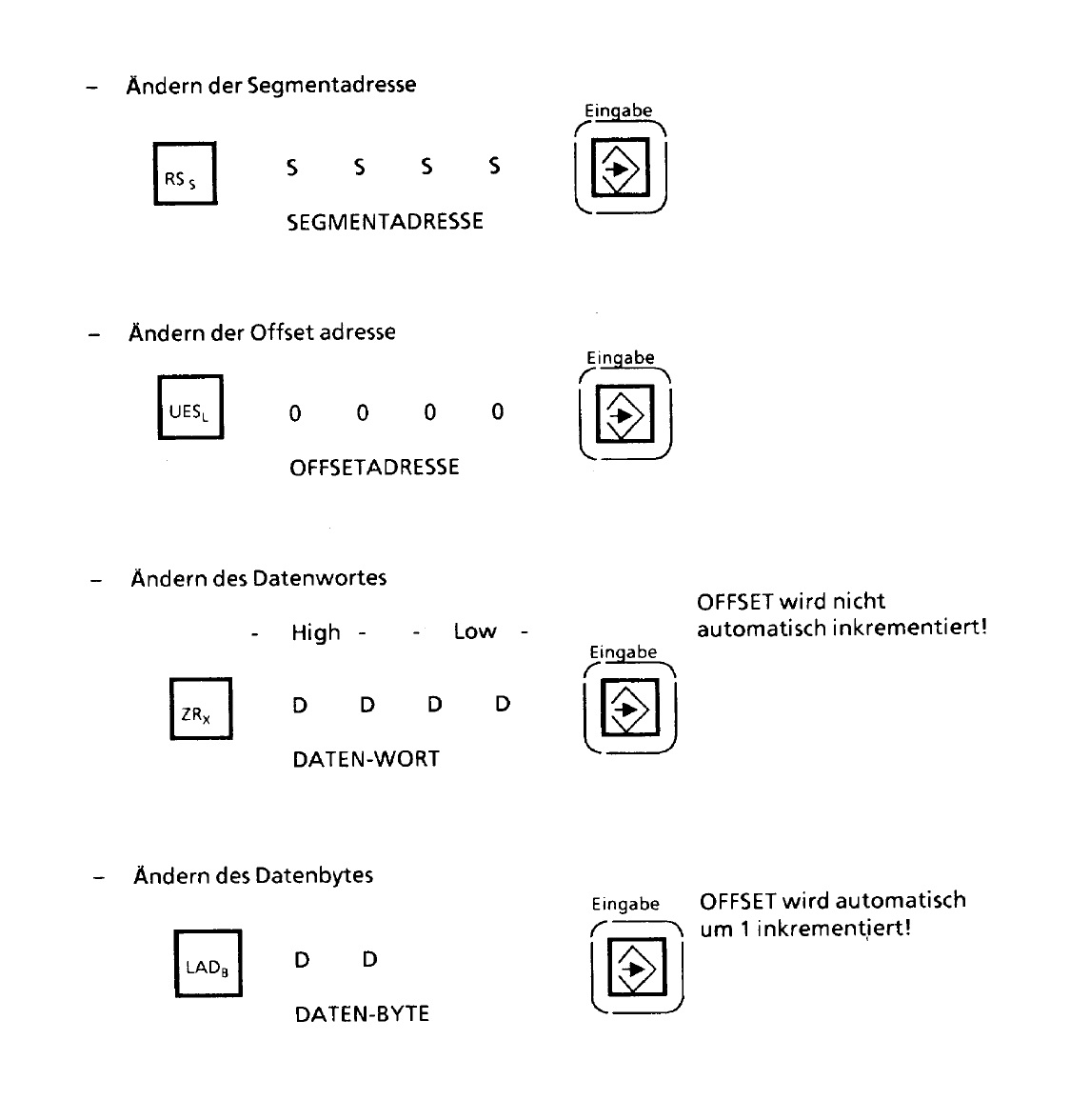
Rufus Τ. F. schrieb: > Aaron C. schrieb: >> kann man das auch nicht daraus erkennen dass das Byte mit der >> angegebenen Adresse hinten in einem Wort steht ? > > Was magst Du damit meinen? Wo in Deinem Ausdruck siehst Du so etwas? Das kann ich direkt in der Maschine einsehen, dort kann ich eine Wort Adresse angeben in dem 2 Bytes stehen und mir wird der wert angezeigt. wenn ich das Byte in der Adresse 6118 - 00 und 6119 - FF eingebe und danach anzeigen lasse wird es mir als Word mit 6118 - FF00 angezeigt. anbei noch ein Screenshot von der Anleitung vielleicht ist die Angabe des high oder low bytes noch von Bedeutung ?
Das ist ja eine Beschreibung der Eingabekommandos. Das muss nicht mit dem Format der Ausgabe übereinstimmen. Gibt es denn keine Dokumentation der Kommandos mit denen Du die Ausgabe erzeugt hast? Ansonsten, würde ich mal eine Eingabe machen, in der die Low und High-Bytes (und sogar die Nibbles) eindeutig zu unterscheiden sind. Etwa Hex A54F oder so und das dann auf dem selben Wege ausgeben lassen, wie Deine Liste. Das sollte einigermaßen schlüssig sein, denke ich.
Danke dafür, leider gibt es keine weitere dokumentation, der ausdruck ist von 1994 und ist leider nicht mehr zu erstellen das die erst möglich ist wenn die daten wieder richtig eingelesen sind. ich werde nun einfach einmal alle doppelwörter vertauschen und sehen ob die daten dann als richtig aktzepiert werden. es geht dabei um eine Siemens RCM Steuerung, genau um Roboterarme die wieder in betrieg genommen werden sollen, bzw. zum basteln herhalten sollen. grüße
Aaron C. schrieb: > wenn ich das Byte in der Adresse 6118 - 00 und 6119 - FF eingebe und > danach anzeigen lasse wird es mir als Word mit 6118 - FF00 angezeigt. Das würde auf eine litte-Endian-Maschine (Intel) deuten. Bietet Dein Gerät auch die Möglichkeit, einen 32-Bit-Wert einzugeben? Dann gib' mal 0x12345678 ein und lass Dir das als Bytes ausgeben.
Leider kann ich nur ein datenwort oder ein byte eingeben, nach dem lesen her würde ich nun auch eher auf little-endian-Maschine deuten. der Prozessor in dem Computer ist ein intel: SAB 8086 -C von 1979 grüße
Nun, ein x86 ist eine Little-Endian-Maschine. Und der kennt keine "Doppelworte", der kann nur 8- oder 16-Bit-Werte verarbeiten.
Aaron C. schrieb: > Leider kann ich nur ein datenwort oder ein byte eingeben, > nach dem lesen her würde ich nun auch eher auf little-endian-Maschine > deuten. > > der Prozessor in dem Computer ist ein intel: SAB 8086 -C von 1979 > > > grüße Na, das ist doch mal ein Wort. Der 8086 hat little-endianness. Dein Anhang stimmt damit überein, etwa an den Adressen 6118 612E.
Danke :) Verstehe ich es dann richtig das ich bei zb. Der adresse 612A daten 8BCF 64E6 stehen habe das ich in meiner abgeschriebenen liste in adresse 612A - 64E6 und in 612C - 8BCF eintrage ? Nurnochmal zur verständnis Die lernkurve bei diesem projekt ist sehr steil :D
Aaron C. schrieb: > Danke :) > > Verstehe ich es dann richtig das ich bei zb. Der adresse 612A daten 8BCF > 64E6 stehen habe das ich in meiner abgeschriebenen liste in adresse 612A > - 64E6 und in 612C - 8BCF eintrage ? > Nurnochmal zur verständnis > > Die lernkurve bei diesem projekt ist sehr steil :D Wenn der Ausdruck der üblichen Konvention folgt, ist das so. Die Konvention ist, bei Ausgabe von 32 Bit-Werten, die little-endian gespeichert sind, die Bytefolge umzudrehen um den Wert der menschlichen Leseweise (MSB link, LSB rechts) anzupassen. Ich kann das nicht garantieren. Aber es ist wiederum so üblich, dass ich das auch versuchen würde.
Aaron C. schrieb: > Nurnochmal zur verständnis Ja, wenn 16 bit little endian sind, dann gilt das auch für 32 bit. Es sei denn, ein völlig durchgeknallter Programmierer hätte das als 2 x 16 bit gespeichert und das in umgekehrter Reihenfolge. Wenn du aber keine 32 bit Werte am Stück eingeben kannst, kannst du das auch nicht klären, ausser du weisst aus anderen Angaben wie der 32 bit Wert lautet. Für etwas anderes als little endian spricht aber nichts, weil Rufus Τ. F. schrieb: > Und der kennt keine "Doppelworte", der kann nur 8- oder 16-Bit-Werte > verarbeiten. natürlich nicht stimmt, es gibt doubleword und sogar quadword, und auch Befehle und Register dafür, z.B. eax. Und die werden alle gespeichert mit "lowest byte first", siehe Assembler-Manual. Georg
Oh. Mist. Da habe ich mich verschrieben. Es steht "32" wo nur "16" stehen sollte. Entschuldigung. Es sollte heissen: Die Konvention ist, bei Ausgabe von 16 Bit-Werten, die little-endian gespeichert sind, die Bytefolge umzudrehen um den Wert der menschlichen Leseweise (MSB link, LSB rechts) anzupassen.
Aaron C. schrieb: > wenn ich das Byte in der Adresse 6118 - 00 und 6119 - FF eingebe und > danach anzeigen lasse wird es mir als Word mit 6118 - FF00 angezeigt. Und wenn du an 611A und 611B auch noch Werte schreibst und das als Doppelwort ab 6118 ausgeben lässt?
Dirk B. schrieb: > Aaron C. schrieb: >> wenn ich das Byte in der Adresse 6118 - 00 und 6119 - FF eingebe und >> danach anzeigen lasse wird es mir als Word mit 6118 - FF00 angezeigt. > > Und wenn du an 611A und 611B auch noch Werte schreibst und das als > Doppelwort ab 6118 ausgeben lässt? Das ist ne gute idee, teste ich gleich. Habe das nun auch umgedreht probiert und es sieht nicht so verkehrt aus. Der computer startet und ich kann nun einen drucker simulieren, also die daten ausgeben lassen wie auf dem papier. Melde mich wieder :)
georg schrieb: > natürlich nicht stimmt, es gibt doubleword und sogar quadword, und auch > Befehle und Register dafür, z.B. eax. Und Es geht hier um einen 8086. Der hat keine 32-Bit-Register, die gab es erst mit dem 80386.
So hier bin ich wieder. die Little endian variante hat sich als richtig herausgestellt. konnte einen Arm bereits erfolgreich bewegen hier ein kurzes video auf YouTube: https://youtu.be/9eiFM4Hswns es gibt beim 8086 wohl keine 32Bit Register deswegen kann man ein doppelwort wohl auch nicht anzeigen. vielen dank für die Hilfe.
Aaron C. schrieb: > die Little endian variante hat sich als richtig herausgestellt. Da die Intel-Architektur so dominierend ist, wird sich vielleicht auch unser Gehirn im Lauf der weiteren Evolution auf Little Endian umstellen. Wer oft Hexdumps lesen muss kann das eh schon. Georg
Einfach mal arabische Schreibrichtung anwenden, also von rechts nach links den Dump. Und schon passt alles wieder. Sind ja auch arabische Ziffern ...
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.