Hallo zusammen, ich habe eine Funktion geschrieben (Quadratwurzel), deren Geschwindigkeit ich profilen wollte. Die Funktion ist im großen und Ganzen ein Lookup-Table für den Startwert und dann ein Bisektionsverfahren. Also alles reine Integer-Operationen. Das Profiling mache in natürlich mit vielen unterschiedlichen Werten. Am längsten braucht die Funktion für Werte knapp unter INT32_MAX. Jetzt kommt der (für mich) überraschende Teil: Am STM32F103 bei 72 MHz messe ich max. ca. 7 µs durch Pinwackeln am Oszilloskop und aus dem DWT_CYCCNT lese ich eine Differenz von 597 Zyklen. Am STM32F446 bei 168 MHz messe ich max. ca. 2,5 µs/393 Zyklen. Im Groben und Ganzen passen die gemessenen Zeiten am Oszilloskop und per Taktzähler zusammen. Was mich allerdings wundert: Warum benötigt der M4F für reine Integer-Aufgaben weniger Rechentakte als der M3? Ist die Multiplikation wesentlich schneller (Divisionen kommen nur durch Zwei vor), oder wo liegt der Unterschied?
Ich tippe auf den I-Cache im Flash-Interface (ART accelerator).
Das kann mehrere Ursachen haben. Wenn der Code aus dem Flash läuft, könnten die wait states für Zugriffe des flash eine Rolle spielen. Welche Compiler optionen nutzt Du für die unterschiedlichen Prozessoren? Hatte mal einen Compiler für den 103er, der eine spezielle Option brauchte um 32bit*32bit->64bit ergebnis Multiplikation zu optimieren. Vielleicht nutzt der Compiler auch den DSP Befehlssatz des M4F. Sieht man im generierten Assemblercode.
Walter T. schrieb: > Jetzt kommt der (für mich) überraschende Teil: Am STM32F103 bei 72 MHz > messe ich max. ca. 7 µs durch Pinwackeln am Oszilloskop und aus dem > DWT_CYCCNT lese ich eine Differenz von 597 Zyklen. Am STM32F446 bei 168 > MHz messe ich max. ca. 2,5 µs/393 Zyklen. Bus- und Flash-Taktung in die Überlegung mit einbezogen? Sicher, dass keine Floating Point Operationen (aus versehen) enthalten sind (=wäre emuliert auf M3 über Library calls und M4F per FPU)? Sind Caches vorhanden? M4F hat einige SIMD Instruktionen; am besten per objdump ein Disassembly erzeugen und den generierten Code vergleichen.
Martin B. schrieb: > Hatte mal einen Compiler für den 103er, der eine spezielle Option > brauchte um 32bit*32bit->64bit ergebnis Multiplikation zu optimieren. 64-Bit-Multiplikationen kommen nicht vor. Der Compiler interessiert mich aber trotzdem. Welcher war es? x^y schrieb: > icher, dass > keine Floating Point Operationen (aus versehen) enthalten sind Da bin ich mir ziemlich sicher. Der Quelltext ist kein Geheimnis. Es wundert mich sowieso, dass Integer-Wurzel nicht in der Standard-Integer-Library vorhanden ist oder einfach zu bekommen ist, sondern selbst gebastelt werden muss. Weil mir der Vergleich fehlt, habe ich noch nicht einmal eine Vorstellung davon, ob meine Bastel-Wurzel von der Rechenzeit ganz OK oder schlecht ist.
1 | /* intsqrt.c
|
2 | *
|
3 | * Quadratwurzelfunktionen fuer Integer-Variablen
|
4 | *
|
5 | * $Date: 2019-04-03 08:27:07 +0200 (Mi, 03 Apr 2019) $
|
6 | * $Revision: 599 $
|
7 | *
|
8 | * 10.01.2018 Nicolas */
|
9 | |
10 | #include "intsqrt.h" |
11 | #include "myassert.h" |
12 | #if !NDEBUG
|
13 | #include <stdio.h> |
14 | #endif
|
15 | |
16 | |
17 | |
18 | |
19 | /* Schnelle Quadratwurzel */
|
20 | |
21 | /* https://stackoverflow.com/questions/1100090/looking-for-an-efficient-integer-square-root-algorithm-for-arm-thumb2 */
|
22 | /* Over the range 1->2^20, the maximum error is 11, and over the range 1->2^30, it's about 256. You could use larger tables and minimise this. It's worth mentioning that the error will always be negative - i.e. when it's wrong, the value will be LESS than the correct value.
|
23 | |
24 | You might do well to follow this with a refining stage.
|
25 | |
26 | The idea is simple enough: (ab)^0.5 = a^0.b * b^0.5.
|
27 | |
28 | So, we take the input X = A*B where A=2^N and 1<=B<2 Then we have a lookuptable for sqrt(2^N), and a lookuptable for sqrt(1<=B<2). We store the lookuptable for sqrt(2^N) as integer, which might be a mistake (testing shows no ill effects), and we store the lookuptable for sqrt(1<=B<2) at 15bits of fixed-point.
|
29 | |
30 | We know that 1<=sqrt(2^N)<65536, so that's 16bit, and we know that we can really only multiply 16bitx15bit on an ARM, without fear of reprisal, so that's what we do.
|
31 | |
32 | In terms of implementation, the while(t) {cnt++;t>>=1;} is effectively a count-leading-bits instruction (CLB), so if your version of the chipset has that, you're winning! Also, the shift instruction would be easy to implement with a bidirectional shifter, if you have one? There's a Lg[N] algorithm for counting the highest set bit here.
|
33 | |
34 | In terms of magic numbers, for changing table sizes, THE magic number for ftbl2 is 32, though note that 6 (Lg[32]+1) is used for the shifting. */
|
35 | |
36 | const uint32_t ftbl[33]={0,1,1,2,2,4,5,8,11,16,22,32,45,64,90,128,181,256,362,512,724,1024,1448,2048,2896,4096,5792,8192,11585,16384,23170,32768,46340}; |
37 | const uint32_t ftbl2[32]={ 32768,33276,33776,34269,34755,35235,35708,36174,36635,37090,37540,37984,38423,38858,39287,39712,40132,40548,40960,41367,41771,42170,42566,42959,43347,43733,44115,44493,44869,45241,45611,45977}; |
38 | |
39 | uint32_t usqrt32_approx(uint32_t val) |
40 | {
|
41 | assert( val <= INT32_MAX ); |
42 | int32_t cnt=0; |
43 | int32_t t=val; |
44 | |
45 | // TODO: Geschwindigkeitsunterschied builtin clz()
|
46 | while (t) |
47 | {
|
48 | cnt++; |
49 | t>>=1; |
50 | }
|
51 | |
52 | if (6>=cnt) |
53 | t=(val<<(6-cnt)); |
54 | else
|
55 | t=(val>>(cnt-6)); |
56 | |
57 | return (ftbl[cnt]*ftbl2[t&31])>>15; |
58 | }
|
59 | |
60 | |
61 | |
62 | /* Langsame, genaue Quadratwurzel
|
63 | * hierbei wird die Tatsache genutzt, dass der obengenannte schnelle Algorithmus immer
|
64 | * negativ vom exakten Ergebnis abweicht.
|
65 | * Fuer grosse Zahlen wird er recht langsam. */
|
66 | uint32_t usqrt32_naive(uint32_t val) |
67 | {
|
68 | assert( val <= INT32_MAX ); |
69 | uint32_t root = usqrt32_approx(val); |
70 | while( root * root <= val ) root++; |
71 | return --root; |
72 | }
|
73 | |
74 | |
75 | |
76 | |
77 | /* Bisektionsverfahren,
|
78 | * bietet (halbwegs) gleiche Rechenzeit ueber den gesamten Wertebereich (s.u. !) und ist
|
79 | * hoffentlich deutlich schneller als der naive Ansatz */
|
80 | uint32_t usqrt32_bisect(uint32_t val) |
81 | {
|
82 | assert( val <= INT32_MAX ); |
83 | if( val == 0 ) |
84 | {
|
85 | // Bisection method implemented in this way cannot find left or right border, so lower
|
86 | // Border will be lowered and zero value has to be taken special attention
|
87 | return 0; |
88 | }
|
89 | |
90 | |
91 | uint32_t root0, root1, root2; |
92 | uint32_t sq0, sq1, sq2; |
93 | |
94 | // Start value: Lower boundary
|
95 | root0 = usqrt32_approx(val)-1; |
96 | |
97 | // Start value: Upper boundary
|
98 | if( val < 1<<20 ) |
99 | // in range 0 ... 2^20, error of approximation is smaller or equal 16
|
100 | // bisection method takes 4 iterations
|
101 | root2 = root0 + 16; |
102 | else
|
103 | // in range 2^20 ... 2^31, error of approximation is smaller or equal 508
|
104 | // bisection method takes 9 iterations
|
105 | root2 = root0 + 512; |
106 | |
107 | |
108 | #if !NDEBUG
|
109 | sq0 = root0 * root0; |
110 | sq2 = root2 * root2; |
111 | if( (sq0 >= val) || (sq2 <= val) ) |
112 | {
|
113 | printf("val=%i, root0=%i, sq0 = %i, root2=%i, sq2 = %i ", val, root0, sq0, root2, sq2); |
114 | error(""); |
115 | }
|
116 | |
117 | //printf("\nval=%i, root0=%i, root2=%i \n", val, root0, root2);
|
118 | #endif
|
119 | |
120 | |
121 | do
|
122 | {
|
123 | root1 = (root0 + root2)/2; |
124 | sq1 = root1 * root1; |
125 | |
126 | |
127 | #if !NDEBUG
|
128 | //printf("[%i, %i] -> %i\n", root0, root2, root1);
|
129 | |
130 | if( sq1 == val ) |
131 | {
|
132 | error("This is going to never happen!"); |
133 | return root1; |
134 | }
|
135 | #endif
|
136 | |
137 | if( sq1 < val ) |
138 | {
|
139 | root0 = root1; |
140 | }
|
141 | else
|
142 | {
|
143 | root2 = root1; |
144 | }
|
145 | }
|
146 | while( (root2 - root0) > 1 ); |
147 | |
148 | return root0; |
149 | }
|
x^y schrieb: > Sind Caches vorhanden? Ja, aber die sprechen eher für den langsamer getakteten M3, weil der, nach meinem Verständnis, weniger Flash-Wait-Cycles benötigt. x^y schrieb: > am besten per objdump ein > Disassembly erzeugen und den generierten Code vergleichen. Das mache ich dann heute abend mal.
Walter T. schrieb: >> Sind Caches vorhanden? > > Ja, aber die sprechen eher für den langsamer getakteten M3, weil der, > nach meinem Verständnis, weniger Flash-Wait-Cycles benötigt. Der STM32F103 hat einen kleinen Prefetch-Buffer, aber keine Caches. Folge: Ausgeführte Sprünge leiden voll unter den Waitstates, Datenzugriffe auf Flash ebenfalls. Der STM32F446 hat vor dem Flash einen 1kB Instruction Cache, um Waitstates bei ausgeführten Sprüngen abzufedern, und einen 128 Byte Data Cache für Zugriff auf dort gespeicherte Konstanten. Bei Code, dessen Sprungziele im tempo-relevanten Teil des Codes in diesen I-Cache passen, spielen die Waitstates beim F4 also keine Rolle, beim F1 jedoch schon. Datenzugriffe auf Literal Pools im Flash sollten bei Optimierung auf Tempo (das hast du hoffentlich gemacht) deutlich weniger auftreten als bei Optimierung auf Grösse, somit nicht von grosser Bedeutung sein.
Angehängte Dateien:
-

Wurzelzwerg.png
49 KB
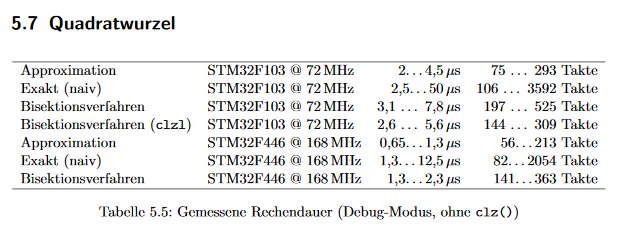
Wer auch immer in der Zukunft über Google hierhinfindet: Den obigen Quelltext bitte NICHT verwenden. Da ist ein Bug drin. Wie dem auch sei: Der hier im Anhang ist sogar noch ein paar Takte schneller. Die gemessenen Laufzeiten für große und kleine Werte (Debug-Modus, -O1) habe ich mal tabellarisch zusammengefasst. clz() spart auch noch einmal ein paar Takte. Keine Ahnung, ob die Geschwindigkeit gut ist, aber für mich ist sie ausreichend.

Hast du schon einmal das Heron Verfahren probiert?
Der hier beschriebe binäre Algorithmus ist m.E. der einfachste und schnellste: https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Binary_numeral_system_(base_2) Sollte in einer optimierten Implementierung für ein 32 bit integer eigentlich deutlich unter 200 takte kommen... Das ist auch die top-antwort in dem oben verlinkten Stackoverflow thread.
Muss es eigentlich eine Integer Wurzel sein? Der M4 kann 32bit-Float-Wurzel in 14 Takten: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0439b/BEHJADED.html
Dr. Sommer schrieb: > Muss es eigentlich eine Integer Wurzel sein? Der M4 kann > 32bit-Float-Wurzel in 14 Takten: Ja, und das bis volle 31 Bit. Aber stimmt schon: Die Wurzel einfach in zwei float zerlegen, multiplizieren und dann trunkieren ist auf dem M4F immer noch schneller als das da oben. Da habe ich mich wohl in eine falsche Richtung verrannt.
Walter T. schrieb: > Ja, und das bis volle 31 Bit. 32 Bit Fließkommazahlen haben 24 Bit Genauigkeit. D.h. bei 31 bit ist der Abstand zwischen zwei darstellbaren Zahlen maximal 128. Daraus resultiert bei der Quadratwurzel maximal ein Fehler von 1, falls beim Runden eine Quadratzahl übersprungen wird (die Abstände der Quadratzahlen sind wesentlich größer). Das Ergebnis sollte dann für die dargestellte Zahl genau sein, und weil es nur maximal 16 Bit hat, ist es auch darstellbar.
Walter T. schrieb: > Die gemessenen Laufzeiten für große und kleine Werte (Debug-Modus, -O1) > habe ich mal tabellarisch zusammengefasst. clz() spart auch noch einmal > ein paar Takte. Man darf die Performance von Algorithmen nicht im Debug-Modus vergleichen.
Aua schrieb: > Man darf die Performance von Algorithmen nicht im Debug-Modus > vergleichen. Na, dann hoffe ich einfach mal, daß mich keiner erwischt.
Walter T. schrieb: > Na, dann hoffe ich einfach mal, daß mich keiner erwischt. Naja, es bringt halt nichts. Die Ergebnisse können mit vs. ohne Optimierung dramatisch abweichen. Was nützt es dir, einen Algorithmus auszuwählen, welcher nur ohne Optimierung schneller ist? Dazu kommt, dass gut lesbare Schreibweisen ohne Optimierung ggf. langsamer sind und man sich so schwierig wartbaren Code baut.
Dr. Sommer schrieb: > Naja, es bringt halt nichts. Im Gegenteil. Ich weiß dann, daß der Code auch schon im Debug-Modus schnell genug ist. Eigentlich geht es doch (mir) meistens darum, nicht den letzten Takt herauszuquetschen, sondern nur darum, zu wissen, ob der jeweilige Ansatz schnell genug ist, oder ob man eine andere Lösung finden muß.
Walter T. schrieb: > Im Gegenteil. Ich weiß dann, daß der Code auch schon im Debug-Modus > schnell genug ist. Auch auf die Gefahr hin, einen Mikro-Optimierten Algorithmus zu wählen, der so clever ist dass er auch ohne Optimizer geht, während man auch einen lesbaren wartbaren Algorithmus hätte wählen können, der mit Optimizer mindestens genau so schnell, ohne Optimizer aber zu langsam wäre? Schau dir den unoptimierten Assemblercode mal an. Der ist wirklich furchtbar naiv. Damit der schnell genug ist, muss man im C-Code ggf. diverse Verrenkungen machen.
Jürgen S. schrieb: > Das Ergebnis sollte dann für die dargestellte Zahl genau sein, und weil > es nur maximal 16 Bit hat, ist es auch darstellbar. Da der Zahlenbereich von 0 bis 2147483648 ja noch überschaubar ist, habe ich einfach mal mit vollständiger Enumeration nachgeschaut. Bis 16785406 ist sqrtf() (erwartungsgemäß) korrekt, darüber beträgt der Fehler maximal ±1 in beide Richtungen. Damit kann ich leben.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.