Mikrocontroller STM32F407 Welchen Zweck hat TXFE bit (Tx FIFO empty)? Wenn dieser auslöst, dann steht DTXFSTS nicht auf maximum, FIFO ist also nicht leer. Nur wenn XFRC auslöst(transfer complete), dann erst zeigt DTXFSTS, dass FIFO leer ist. Und dann im Datenblatt: "In interrupt mode, the application waits for the TXFE interrupt (in OTG_FS_DIEPINTx) and then reads the OTG_FS_DTXFSTSx register, to determine if there is enough space in the data FIFO." Das macht doch keinen Sinn. Wenn TXFE anzeigt, dass FIFO leer ist, dann brauche ich doch nicht im DTXFSTS nachzuschauen.
In Kapitel 34.12.2 steht eine Erklärung: " The OTG_FS core issues the periodic Tx FIFO empty interrupt (PTXFE bit in OTG_FS_GINTSTS) as long as the periodic Tx-FIFO is half or completely empty, depending on the value of the periodic Tx-FIFO empty level bit in the AHB configuration register (PTXFELVL bit in OTG_FS_GAHBCFG). The application can push the transmission data in advance as long as free space is available in both the periodic Tx FIFO and the periodic request queue. The host periodic transmit FIFO and queue status register (HPTXSTS) can be read to know how much space is available in both. " Der Interrupt kann (je nach Konfiguration) auch nur bedeuten, dass der Puffer halb leer ist. Ich denke es geht darum, den Puffer in zwei Hälften aufzuteilen und diese Hälften in der ISR wechselweise zu befüllen, um eine lückenlose kontinuierliche Datenübertragung zu erreichen.
Sorry, habe vergessen zu schreiben, dass ich im device mode bin. 34.12.2 bezieht sich auf host mode. Mist. TXFELVL in GAHBCFG ist bei mir 0, 0: the TXFE (in OTG_FS_DIEPINTx) interrupt indicates that the IN Endpoint TxFIFO is half empty. Heisst das, dass der flag für alle Füllstände zwischen "FIFO leer" und "FIFO halb leer" gesetzt wird oder nur exakt bei "FIFO halb leer"?
Tycho B. schrieb: > Heisst das, dass der flag für alle Füllstände zwischen "FIFO leer" und > "FIFO halb leer" gesetzt wird oder nur exakt bei "FIFO halb leer"? Du stellst aber auch Fragen - wie ich :-) Jetzt kommt das Glatteis: Ich vermute, dass die Daten den Puffer Byteweise verlassen und daher dann irgendwann diese Schwelle erreicht wird. "This interrupt is asserted when the TxFIFO for this endpoint is either half or completely empty." Ich interpretiere das so: Wenn der Puffer vorher schon weniger als halb voll war, wird der Interrupt vermutlich nicht ausgelöst und das Flag nicht gesetzt. Sonst hätte da wohl gestanden, dass das Flag gesetzt wird, wenn der Puffer weniger als halb voll ist. Das Flag bleibt jedenfalls 1, bis es zurück gesetzt wird: "The application must clear the appropriate bit in this register to clear the corresponding bits in the OTG_HS_DAINT and OTG_HS_GINTSTS registers."
Angehängte Dateien:
-

1.png
36 KB

Stefanus F. schrieb: > Tycho B. schrieb: >> Heisst das, dass der flag für alle Füllstände zwischen "FIFO leer" und >> "FIFO halb leer" gesetzt wird oder nur exakt bei "FIFO halb leer"? > > Du stellst aber auch Fragen - wie ich :-) Das Manual ist unter aller Sau. Das ist schon unverschämt, imho. Ich sitze hier schon drei Wochen und schreibe ein VCP anhand des CMSIS-Beispiels. Und: CMSIS ist fehlerhaft, aufgebläht, ineffizient und unwartbar. Das verstehe ich nicht, da sitzt Hardware und Software im selben Haus, schaffen aber nicht etwas Vernünftiges zu schreiben. > Jetzt kommt das Glatteis: > > Ich vermute, dass die Daten den Puffer Byteweise verlassen und daher > dann irgendwann diese Schwelle erreicht wird. > "This interrupt is asserted when the TxFIFO for this endpoint is either > half or completely empty." > > Ich interpretiere das so: Wenn der Puffer vorher schon weniger als halb > voll war, wird der Interrupt vermutlich nicht ausgelöst und das Flag > nicht gesetzt. Sonst hätte da wohl gestanden, dass das Flag gesetzt > wird, wenn der Puffer weniger als halb voll ist. Bei mir ist der flag immer gesetzt, ich habe ihn mit DIEPEMPMSK wegmaskiert, weil ich ständig in diesem Interrupt lande. Das ist z.B. auch im CMSIS-Beispiel so. Deswegen tendiere ich eher dazu, dass der flag für alle Füllstände zwischen "FIFO leer" und "FIFO halb leer" gesetzt wird. Programmiertechnisch ist es auch deutlich sinnvoller, da man so stets weiss, ob mehr als Hälfte noch frei ist. > Das Flag bleibt jedenfalls 1, bis es zurück gesetzt wird: > > "The application must clear the appropriate bit in this register to > clear the corresponding bits in the OTG_HS_DAINT and OTG_HS_GINTSTS > registers." Korrektur nr.2: ich bin in full speed, nicht high speed) Das Zitat ist aus HS. Aber so ähnlich steht es auch in FS. Nur: TXFE kann nur gelesen aber nicht gelöscht werden, siehe Bild. Nachtrag: Sorry, steht nicht nur ähnlich, sondern genauso in FS.
Tycho B. schrieb: > CMSIS ist fehlerhaft, aufgebläht, ineffizient und unwartbar. Kann es sein, dass du da etwas verwechselst? Die CMSIS besteht nur aus Register Definitionen und einer Hand voll Makros. Du meinst vermutlich irgendeine Bibliothek, die auf CMSIS aufbaut - wobei das für alle Bibliotheken gilt. Auch die Cube HAL baut auf CMSIS auf. Dass die Doku nicht immer eindeutig ist (um nicht zu sagen: direkt irreführend), habe ich auch gerade am Wochenende bei I²C bemerkt.
Stefanus F. schrieb: > Tycho B. schrieb: >> CMSIS ist fehlerhaft, aufgebläht, ineffizient und unwartbar. > > Kann es sein, dass du da etwas verwechselst? > > Die CMSIS besteht nur aus Register Definitionen und einer Hand voll > Makros. Du meinst vermutlich irgendeine Bibliothek, die auf CMSIS > aufbaut - wobei das für alle Bibliotheken gilt. Auch die Cube HAL baut > auf CMSIS auf. Ja, stimmt. Ich benutze die "STM32F105/7xx, STM32F2xx and STM32F4xx USB On-The-Go Host and Device library" Ich dachte es gehört zu CMSIS.
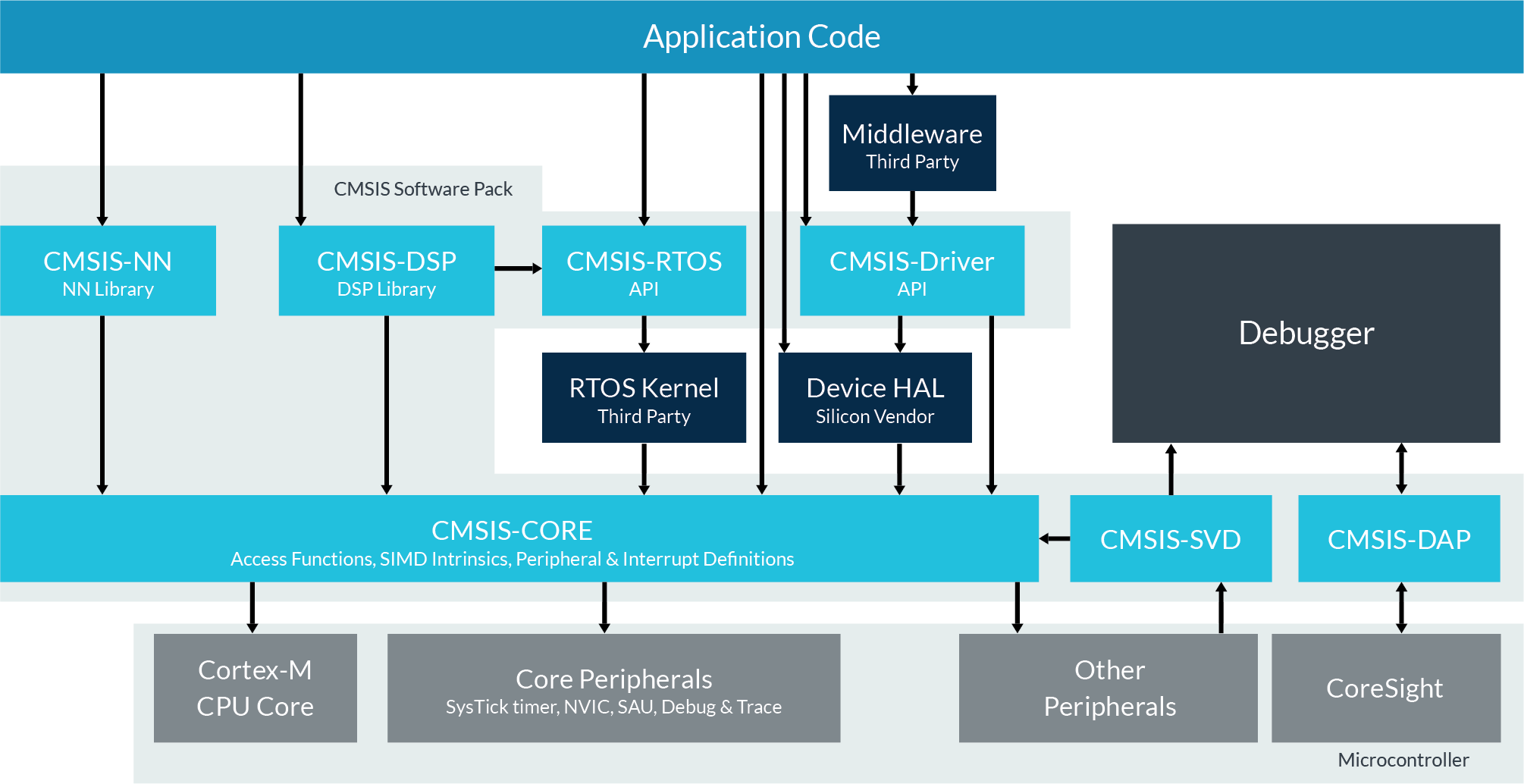
Tycho B. schrieb: > Ich dachte es gehört zu CMSIS. Die CMSIS ist genau gesagt CMSIS-Core. Darauf aufbauend gibt es zum Beispiel CMSIS-RTOS, CMSIS-DSP und einige weitere standard Libraries, die von ARM spezifiziert sind. Siehe dieses Schaubild: https://developer.arm.com/-/media/Arm%20Developer%20Community/Images/Block%20Diagrams/Cortex%20Microcontroller%20Software%20Interface%20Standard%20-%20CMSIS/CMSIS%20Diagram%20v2.png Und hier noch ein Schaubild spezifisch für STM32: http://www.keil.com/pack/doc/STM32Cube/General/html/STM32Cube_Overview.png Die Library, die du verwendest, baut auf der alten SPL auf, welche vor etlichen Jahren durch Cube HAL abgelöst wurde. Cube HAL ist noch "fetter".
{kind=link}
{kind=link}
Mein Buffer für IN_EP1 ist 0x10D Worte groß, also 1076 Byte. Paketgröße habe ich auf 512 Byte gesetzt. Jetzt sende ich 2 Pakete mit Gesamtbytezahl von 768 und aktiviere TXFE Interrupt.
1 | dieptsiz1.d32 = USB.INEP_REGS[1]->DIEPTSIZ; |
2 | dieptsiz1.b.pktcnt = 2; |
3 | dieptsiz1.b.xfrsiz = 768; |
4 | USB.INEP_REGS[1]->DIEPTSIZ = dieptsiz1.d32; |
5 | USB.INEP_REGS[1]->DIEPCTL |= DIEPCTL0_EPENA|DIEPCTL0_CNAK; |
6 | for (uint32_t i = 0; i < 192; i++){ |
7 | *(USB).DFIFO[1]=*((uint32_t *)(test_string)+i); |
8 | }
|
9 | USB.DREGS->DIEPEMPMSK |= DIEPEMPMSK_INEPTXFEM_1; |
Dieser wird ausgelöst und ich lese sofort DTXFSTS1 ein. Diese liefert: 0xCD, also 820 freie Bytes im FIFO. Keine Hälfte(
Stefanus F. schrieb: > Tycho B. schrieb: >> Ich dachte es gehört zu CMSIS. > > Die CMSIS ist genau gesagt CMSIS-Core. Darauf aufbauend gibt es zum > Beispiel CMSIS-RTOS, CMSIS-DSP und einige weitere standard Libraries, > die von ARM spezifiziert sind. Siehe dieses Schaubild: > https://developer.arm.com/-/media/Arm%20Developer%20Community/Images/Block%20Diagrams/Cortex%20Microcontroller%20Software%20Interface%20Standard%20-%20CMSIS/CMSIS%20Diagram%20v2.png > > Und hier noch ein Schaubild spezifisch für STM32: > http://www.keil.com/pack/doc/STM32Cube/General/html/STM32Cube_Overview.png Danke! > Die Library, die du verwendest, baut auf der alten SPL auf, welche vor > etlichen Jahren durch Cube HAL abgelöst wurde. Cube HAL ist noch > "fetter". Deswegen habe ich geziehlt nach einem Beispiel ohne Cube gesucht, damit es noch halbwegs verständlich bleibt zum reverse engineeren.
Wozu man sowas benoetigt ? Es gibt dir speziell bei hohen Baudraten genuegend Zeit den Buffer zu Fuellen. Bedeutet die Echtzeitanforderungen werden einfacher zu erfuellen. So kommt man vielleicht mit kooperativ Multitasking durch und benoetigt das Preemptiv Zeugs nicht. Es gibt serielle Uebertragungen, resp Treiber mit 25MBit, da hat man fuer jedes Byte nur noch 400ns Zeit.
Tycho B. schrieb: > Dieser wird ausgelöst und ich lese sofort DTXFSTS1 ein. Was heißt schon sofort? Bis die erste Zeile C-Code aus deiner ISR ausgeführt wird, vergehen etliche Takte. Selbst nackter Assembler Code wird als ISR nicht "sofort" ausgeführt.
Tycho B. schrieb: > da sitzt Hardware und Software im > selben Haus, schaffen aber nicht etwas Vernünftiges zu schreiben. Das USB-Modul ist zugekauft, wahrscheinlich ist das der hier: https://www.synopsys.com/dw/ipdir.php?ds=dwc_usb_2_0_hs_otg Tycho B. schrieb: > Deswegen habe ich geziehlt nach einem Beispiel ohne Cube gesucht, damit > es noch halbwegs verständlich bleibt zum reverse engineeren. Ich glaube es hat noch niemand im Open Source-Bereich diese "OTG"-Hardware "bare metal" ohne jegliche Bibliothek angesteuert. Die einfachere "USB" genannte Hardware der kleineren STM32 ist machbarer. Daher: Spannendes Projekt... Zitronen F. schrieb: > So kommt man vielleicht mit kooperativ > Multitasking durch und benoetigt das Preemptiv Zeugs nicht. Wie hilft denn präemptives Multitasking beim Erfüllen von Echtzeit-Anforderungen? Wenn das kooperativ/asynchron nicht geht, geht's präemptiv erst recht nicht (Overhead und so).
Stefanus F. schrieb: > Tycho B. schrieb: >> Dieser wird ausgelöst und ich lese sofort DTXFSTS1 ein. > > Was heißt schon sofort? Bis die erste Zeile C-Code aus deiner ISR > ausgeführt wird, vergehen etliche Takte. Selbst nackter Assembler Code > wird als ISR nicht "sofort" ausgeführt. Ja, stimmt. Aber die FS-Übertragung ist jetzt auch nicht die schnellste. Genau die Hälfte wäre 538 Bytes. Würde ich ca. 600 Bytes sehen, also dass zwischendurch 62 Bytes gesendet wurden (was eigentlich auch viel zu viel ist, geschätzt eher 540-542), dann würde ich es verstehen. Aber 820?
Niklas G. schrieb: > Tycho B. schrieb: >> da sitzt Hardware und Software im >> selben Haus, schaffen aber nicht etwas Vernünftiges zu schreiben. > > Das USB-Modul ist zugekauft, wahrscheinlich ist das der hier: > https://www.synopsys.com/dw/ipdir.php?ds=dwc_usb_2_0_hs_otg Das habe ich sogar irgendwo gelesen, dass USB-Text im Manual von Synopsys stammt. Habe es damals nicht verstanden und weiter nicht beachtet. Jetzt macht es Sinn. > Tycho B. schrieb: >> Deswegen habe ich geziehlt nach einem Beispiel ohne Cube gesucht, damit >> es noch halbwegs verständlich bleibt zum reverse engineeren. > > Ich glaube es hat noch niemand im Open Source-Bereich diese > "OTG"-Hardware "bare metal" ohne jegliche Bibliothek angesteuert. Die > einfachere "USB" genannte Hardware der kleineren STM32 ist machbarer. > Daher: Spannendes Projekt... Zumindest für F407 habe ich nichts gefunden, nur F1 u.ä.
Habe jetzt den FIFO komplett gefüllt, 3 Pakete, 1076 Bytes.
1 | dieptsiz1.d32 = USB.INEP_REGS[1]->DIEPTSIZ; |
2 | dieptsiz1.b.pktcnt = 3; |
3 | dieptsiz1.b.xfrsiz = 1076; |
4 | USB.INEP_REGS[1]->DIEPTSIZ = dieptsiz1.d32; |
5 | USB.INEP_REGS[1]->DIEPCTL |= DIEPCTL0_EPENA|DIEPCTL0_CNAK; |
6 | for (uint32_t i = 0; i < 269; i++){ |
7 | *(USB).DFIFO[1]=*((uint32_t *)(test_string)+i); |
8 | }
|
9 | USB.DREGS->DIEPEMPMSK |= DIEPEMPMSK_INEPTXFEM_1; |
Zwei IN Interrupte werden ausgelöst, der erste TXFE, der zweite XFRC; TXFE: DTXFSTS1=256 (1024 bytes frei) XFRC: DTXFSTS1=269 (1076 bytes frei) Entweder kriege ich es nicht hin, den FIFO schnell genug zu füllen (?!) oder es stimmt irgendwas nicht. Ach ja, der komplette Datensatz kommt auf dem PC an. Nachtrag: ich habe direkt nach dem Befüllen (nach der for-Schleife) DTXFSTS1 ausgelesen: =0. Also komplett voll.
Ich glaube, ich habe die Funktion des TXFE verstanden. Er wird nur evaluiert wenn ein komplettes Paket gesendet wurde. Da mein FIFO 1076 bytes groß und komplett gefüllt ist, hat er nach dem Senden des ersten Paketes 512 Bytes frei (ich habe die Paketgröße auf 512 eingestellt), was weniger als die Hälfte ist. Nach dem zweiten Paket sind es 1024 freie Bytes und da wird er gesetzt. Damit ist DTXFSTS1=256, also 1024. Wenn ich nicht 1076, sondern 1072 bytes sende, dann bekomme ich beim Auslösen des TXFE DTXFSTS1=257, also ein leeres word mehr. Macht alles Sinn. Nur: warum schreibt man das nicht ins datasheet??? Genau das selbe Trauerspiel beim DIEPTSIZ. Da steht: "Bits 18:0 XFRSIZ: Transfer size This field contains the transfer size in bytes for the current endpoint. The core only interrupts the application after it has exhausted the transfer size amount of data." Welcher Interupt wird denn ausgelöst? Auf jeden Fall nicht TXFE und XFRC, diese beziehen sich wohl auf DTXFSTS-Füllstände. Es gibt aber keine weiteren Interrupte im DIEPINT! Welcher Interrupt wird denn ausgelöst wenn "exhausted the transfer size amount of data"?
Tycho B. schrieb: > Macht alles Sinn. Ja, das klingt plausibel. > warum schreibt man das nicht ins datasheet??? Vermutung: Weil ST selbst keine Ahnung hat und der Hersteller der Komponente lieber Software dazu verkauft, anstatt alles gut zu dokumentieren. Das nimmt auch bei anderen Mikrochips überhand (z.B. bei Espressif und bei den SOC für Raspberry Pi). Die schlechtere Doku ist für mich der Grund, Anfängern immer noch 8bit Controller zu empfehlen.
Stefanus F. schrieb: > Vermutung: Weil ST selbst keine Ahnung hat und der Hersteller der > Komponente lieber Software dazu verkauft, anstatt alles gut zu > dokumentieren. Die Software gibt's aber als Free Software, z.B. in Form des Linux-Treibers für diesen USB-IP. Stefanus F. schrieb: > Die schlechtere Doku ist für mich der Grund, Anfängern immer noch 8bit > Controller zu empfehlen. Wenn die einen OTG-Core haben der nicht der von Synopsys ist...
Tycho B. schrieb: > for (uint32_t i = 0; i < 269; i++){ > *(USB).DFIFO[1]=*((uint32_t *)(test_string)+i); > } > Entweder kriege ich es nicht hin, den FIFO schnell genug zu füllen (?!) Wieso machst Du das nicht mit memcpy() aus der Standardlibrary?
Johnny B. schrieb: > Wieso machst Du das nicht mit memcpy() aus der Standardlibrary? Vor allem weil das Casten auf uint32_t Probleme mit Alignment machen kann... Witzigerweise ist im USB-Treiber-Code für die LPC genau so ein Fehler, welcher das Programm auf Cortex-M0 zum Absturz bringt. Beim STM32F4 ist es entweder langsam oder führt zum Absturz (je nach Konfiguration).
Niklas G. schrieb: > Die Software gibt's aber als Free Software, z.B. in Form des > Linux-Treibers für diesen USB-IP. Ich meinte die entsprechenden Teiler in der Cube HAL oder SPL. Das hat ST vermutlich zusammen mit dem Chip-Design eingekauft.
Stefanus F. schrieb: > Ich meinte die entsprechenden Teiler in der Cube HAL oder SPL. Ja, aber die wird auch nicht verkauft! Stefanus F. schrieb: > und der Hersteller der > Komponente lieber Software dazu verkauft Ich glaube es gibt sogar eine (gute?) Dokumentation zum USB Core von Synopsys. Auf der Produktseite ist sie verlinkt. Nur leider darf/kann man die ohne Lizenz (welche nur ST & Konsorten haben) nicht herunterladen.
Johnny B. schrieb: > Tycho B. schrieb: >> for (uint32_t i = 0; i < 269; i++){ >> *(USB).DFIFO[1]=*((uint32_t *)(test_string)+i); >> } >> Entweder kriege ich es nicht hin, den FIFO schnell genug zu füllen (?!) > > Wieso machst Du das nicht mit memcpy() aus der Standardlibrary? Weil ich die Standardlibrary nicht benutze. 32bit-Alignment kommt später, ich hab's aber auf dem Schirm. Wie bereits geschrieben, das Füllen ist schnell genug.
Tycho B. schrieb: > Weil ich die Standardlibrary nicht benutze. Aber warum? Das Standard-memcpy dürfte gut optimiert sein und falls möglich auch mehr als 1 Byte auf einmal übertragen.
Niklas G. schrieb: > Tycho B. schrieb: >> Weil ich die Standardlibrary nicht benutze. > > Aber warum? Das Standard-memcpy dürfte gut optimiert sein und falls > möglich auch mehr als 1 Byte auf einmal übertragen.
1 | void *memcopy (void *dest, const void *src, uint8_t len) |
2 | {
|
3 | char *d = dest; |
4 | const char *s = src; |
5 | while (len--) |
6 | *d++ = *s++; |
7 | return dest; |
8 | }
|
Das habe ich als Implementierung im Netz gefunden. Allein wegen function call bin ich schneller, ganz abgesehen von "char".
Tycho B. schrieb: > Das habe ich als Implementierung im Netz gefunden. Und das ist auch der Code vom memcpy in deiner Standard-Bibliothek? In der newlib, welche vom GCC-ARM-Embedded genutzt wird, sieht das so aus: https://sourceware.org/git/gitweb.cgi?p=newlib-cygwin.git;a=blob;f=newlib/libc/string/memcpy.c;h=52f716b9275f5d24cedb7d66c41541945d13bfb6;hb=HEAD Tycho B. schrieb: > Allein wegen function > call Den memcpy()-Aufruf kann der Compiler wegoptimieren und durch einzelne Instruktionen ersetzen, wenn die Länge klein ist. Bei großer Länge ist der Overhead sowieso insignifikant.
Niklas G. schrieb: > Tycho B. schrieb: >> Das habe ich als Implementierung im Netz gefunden. > > Und das ist auch der Code vom memcpy in deiner Standard-Bibliothek? Ich weiss gar nicht wie die Bibliothek heisst oder wo sie liegt. > In der newlib, welche vom GCC-ARM-Embedded genutzt wird, sieht das so > aus: > > https://sourceware.org/git/gitweb.cgi?p=newlib-cygwin.git;a=blob;f=newlib/libc/string/memcpy.c;h=52f716b9275f5d24cedb7d66c41541945d13bfb6;hb=HEAD Kannst du erklären, warum das schneller sein sollte?
Tycho B. schrieb: > Ich weiss gar nicht wie die Bibliothek heisst oder wo sie liegt. Hängt vom Compiler/Toolchain ab. Tycho B. schrieb: > Kannst du erklären, warum das schneller sein sollte? Weil in pro Schleifendurchlauf 4 Words kopiert werden, entfällt ggf. weniger Overhead auf die Schleifensprünge. Das Argument war aber, dass es das Alignment prüft und falls nötig Bytes kopiert. memcpy ist erprobt, portabel, funktioniert immer und ist gut optimiert. Es gibt wenig Grund das nicht zu nutzen...
Niklas G. schrieb: > Tycho B. schrieb: >> Ich weiss gar nicht wie die Bibliothek heisst oder wo sie liegt. > > Hängt vom Compiler/Toolchain ab. > > Tycho B. schrieb: >> Kannst du erklären, warum das schneller sein sollte? > > Weil in pro Schleifendurchlauf 4 Words kopiert werden, entfällt ggf. > weniger Overhead auf die Schleifensprünge. Das Argument war aber, dass > es das Alignment prüft und falls nötig Bytes kopiert. memcpy ist > erprobt, portabel, funktioniert immer und ist gut optimiert. Es gibt > wenig Grund das nicht zu nutzen... Also wenn alles stimmt (if (!TOO_SMALL(len0) && !UNALIGNED (src, dst))) dann wird das ausgeführt: 100 while (len0--) 101 *dst++ = *src++; und das ist genau das, was ich mache. Wie gesagt, für Testzwecke habe ich einen uint8_t buffer, den ich mit einem Pattern fülle, um die Übertragung zu verifizieren. Wenn die Implementierung funktioniert, dann wird es ein uint32_t puffer, der aligned ist. Nachtrag: Ach ja, ganz vergessen - memcpy funktioniert hier gar nicht. Es ist ein FIFO.
Tycho B. schrieb: > Also wenn alles stimmt (if (!TOO_SMALL(len0) && !UNALIGNED (src, dst))) > dann wird das ausgeführt: > 100 while (len0--) > 101 *dst++ = *src++; > und das ist genau das, was ich mache. Nur für die restlichen 3 Bytes. Der "große" Teil am Anfang geht damit:
1 | /* Copy 4X long words at a time if possible. */
|
2 | while (len0 >= BIGBLOCKSIZE) |
3 | {
|
4 | *aligned_dst++ = *aligned_src++; |
5 | *aligned_dst++ = *aligned_src++; |
6 | *aligned_dst++ = *aligned_src++; |
7 | *aligned_dst++ = *aligned_src++; |
8 | len0 -= BIGBLOCKSIZE; |
9 | }
|
Tycho B. schrieb: > Nachtrag: Ach ja, ganz vergessen - memcpy funktioniert hier gar nicht. > Es ist ein FIFO. Achja, die Ziel-Adresse wird nicht inkrementiert...
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.