Im Prinzip wird hier limit mit einem Wert geladen, der sich aus einer
Division durch 56 ergibt.
Später im code wird der clock_enable_count mit limit verglichen, und
eine weitere Variable inkrementiert um nicht mehr mit 100MHz zu takten,
sondern mit einer passenden Frequenz.
Um Rundungsfehler zu vermeiden, wird clock_enable_count mit der Hälfte
von (count_100MHz/56) geladen ZUSÄTZLICH +1 wenn (count_100MHz/56)
ungerade ist.
Sorry wenn die Erklärung zu unverständlich und der Zweck nebulös wirken,
aber das ist nicht der Punkt.
Sondern: Da die Division komplex in der Implementierung ist, wollte ich,
dass diese nur ein mal ausgeführt wird. Nätürlich könnte man so etwas
machen:
clock_enable_count wird jedoch erst mit der zweiten Ausführung des
Codeblocks mit dem richtigen Wert geladen. Ich verliere also eine
Taktflanke.
Deshalb habe ich den Teilungsteil im ersten Schnipsel überall gleich
gestaltet in der Hoffnung, dass der Ausgang der Teilung für weitere
Berechnungen verwendet wird.
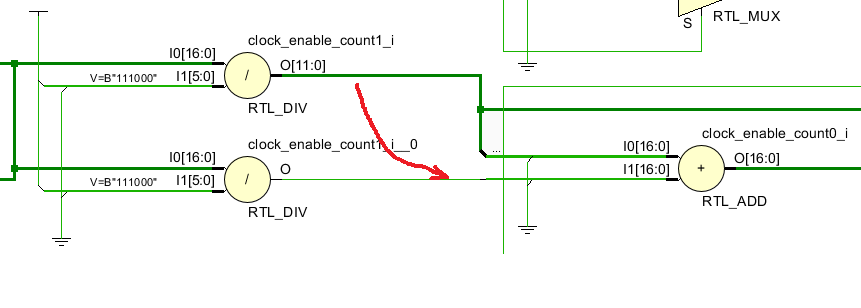
Schematic zeigt jedoch zwei Teilungen. In Rot habe ich die Stelle
markiert, wo ich einfach das nullte Bit abzweigen würde.
Geht das irgendwie?
Tycho B. schrieb:> Da die Division komplex in der Implementierung ist, wollte ich, dass> diese nur ein mal ausgeführt wird.
Eine Division durch eine Konstante ist nicht zeitaufwändig, wenn man sie
durch eine Multiplikation ersetzt und "übrige" Bits abschneidet. Die
Berechnung
ergebnis = (wert*299593)/(2**24)
entspricht bis auf eine Genauigkeit von 1/3000000 stel der Division
ergebnis = wert/56
(exakt: ergebnis = wert/56,0000267). Und die Division 1/(2**24) wird
einfach durch "Umverdrahten" erledigt, die unteren 24 Bits werden
schlicht ignoriert.
> clock_enable_count wird jedoch erst mit der zweiten Ausführung des> Codeblocks mit dem richtigen Wert geladen.
Da hast du irgendwo noch Latency mit eingebaut...
Robotix schrieb:> O(0) ist das Bit.
Diese dünne Leitung aus dem zweiten Dividierer? Ja, denke ich auch. Ich
will aber den zweiten Dividierer weg haben.
> Du hast ausserdem überall 16 to 1, statt 16 to 0 stehen. Stimmt das?
links muss das so, rechts kann auch 15 downto 0 stehen.
Lothar M. schrieb:> Tycho B. schrieb:>> Da die Division komplex in der Implementierung ist, wollte ich, dass>> diese nur ein mal ausgeführt wird.> Eine Division durch eine Konstante ist nicht zeitaufwändig, wenn man sie> durch eine Multiplikation ersetzt und "übrige" Bits abschneidet. Die> Berechnung>> ergebnis = (wert*299593)/(2**24)>> entspricht bis auf eine Genauigkeit von 1/3000000 stel der Division>> ergebnis = wert/56>> (exakt: ergebnis = wert/56,0000267). Und die Division 1/(2**24) wird> einfach durch "Umverdrahten" erledigt, die unteren 24 Bits werden> schlicht ignoriert.
Dessen war ich mir überhaupt nicht bewust. Das werde ich mir genauer
ansehen. Danke. Bedeutet das, dass der Compiler das als Multiplikation
implementiert, weil ja bekannt ist, dass durch eine Konstante geteilt
wird? Oder muss ich selbst ran?
>> clock_enable_count wird jedoch erst mit der zweiten Ausführung des>> Codeblocks mit dem richtigen Wert geladen.> Da hast du irgendwo noch Latency mit eingebaut...
Dann habe ich VHDL wohl nicht verstanden. Ich dachte, dass innerhalb
eines Prozesses
1
measure:process(CLK100MHZ)begin
2
if(rising_edge(CLK100MHZ))then
3
wert1<=INPUT;
4
wert2<=wert1;
5
endif;
6
endprocessmeasure;
mit der ersten Flanke wert1 INPUT bekommt und wert2 bekommt den alten
wert1, der vor INPUT da war. Genau das würde bei mir passieren wenn ich
die Division explizit ausführe
s_ - Signal
v_ - Variable
Und siehe da, genau wie ich es haben wollte. Bleibt nur noch die Frage
ob der Compiler die Division als Multiplikation ausführt oder nicht?
Lothar M. schrieb:> ergebnis = (wert*299593)/(2**24)
Sorry für OT:
Wie kommt man darauf? Schlichtes Ausprobieren
oder gibt es da eine Näherungsformel/-Verfahren?
merciless
Durch 56 teilen ist eine Multiplikation mit der Zahl 1/56. Und das
teilst du auf in die Division durch eine hohe Zweierpotenz und die
Multiplikation mit einer normalen ganzen Zahl.
Also 1/56 = Zahl/Zweierpotenz. Die Zweierpotenz kannst du einfach groß
genug wählen und dann die Zahl ausrechnen. Beispiel:
Zweierpotenz 1024, also folgt dass Zahl = (1/56)*1024 = 18,28...
Zweierpotenz 1048576, also folgt dass Zahl = (1/56)*1048576 =
18724,57...
Du siehst also, dass die Rundungsfehler geringer werden wenn man eine
größere Zweierpotenz wählt.
Ergebnis = (Wert*18724)/2^20
In VHDL kann man das (fast) so hinschreiben.
Lothar M. schrieb:> ergebnis = (wert*299593)/(2**24)>> entspricht bis auf eine Genauigkeit von 1/3000000 stel der Division>> ergebnis = wert/56
ich hab's mal spasseshalber mit Additionen gemacht. Ist auch zur
Laufzeit eine Option:
Tycho B. schrieb:> Oder muss ich selbst ran?
Ja. Der Synthesizer optimiert da von sich aus nichts.
Dirk K. schrieb:> Wie kommt man darauf? Schlichtes Ausprobieren
Ich sags mal so: es gibt ein Verfahren, aber vor ich mich da wieder
schlau mache, versuche ich es mit dem "Educated Guess" und probiere das
in einer halben Minute durch, bis der Fehler hinreichend klein ist.
Das geht so: ich will 16 Bit Genauigkeit, dann beginne ich mit 256/56
und merke mir 8. Dann multipliziere ich solange mit 2, bis die
Nachkommastellen entweder 0 werden (Idealfall!) oder eben so klein, dass
der Fehler hinreichend klein wird. Das ist spätestens der Fall, wenn
65536 vor dem Komma steht (oder eben, wenn da 6553,67 stünde, denn auch
diese 0,07 Abweichung sind hinreichend klein). Und jedesmal, wenn ich
mit 2 multipliziere zähle ich eine Zehnerpotenz hoch. Zum Schluss ist
der Multiplikator die Vorkommastellen und der Divisor die gezählten
Zehnerpotenzen... ?
berndl schrieb:> Lothar M. schrieb:>> ergebnis = (wert*299593)/(2**24)>>>> entspricht bis auf eine Genauigkeit von 1/3000000 stel der Division>>>> ergebnis = wert/56>> ich hab's mal spasseshalber mit Additionen gemacht. Ist auch zur> Laufzeit eine Option:
> Das ganze fuer einen SENT-Protokoll Empfaenger, deshalb die Div durch 56> mit hinreichender Genauigkeit
Ja, SENT)
Ich habe zwei Fragen zu deinem Code.
1. (REC_WCNT-1 downto 12) Ich dachte es gibt keinen Präprozessor. Wie
definierst du die Konstante REC_WCNT, mit constant?
2. cnt_arr (to_integer (state_cnt_end)) Was macht diese Struktur?
Lothar M. schrieb:> Tycho B. schrieb:>> Oder muss ich selbst ran?> Ja. Der Synthesizer optimiert da von sich aus nichts.>> Dirk K. schrieb:>> Wie kommt man darauf? Schlichtes Ausprobieren> Ich sags mal so: es gibt ein Verfahren, aber vor ich mich da wieder> schlau mache, versuche ich es mit dem "Educated Guess" und probiere das> in einer halben Minute durch, bis der Fehler hinreichend klein ist.> Das geht so: ich will 16 Bit Genauigkeit, dann beginne ich mit 256/56> und merke mir 8. Dann multipliziere ich solange mit 2, bis die> Nachkommastellen entweder 0 werden (Idealfall!) oder eben so klein, dass> der Fehler hinreichend klein wird. Das ist spätestens der Fall, wenn> 65536 vor dem Komma steht (oder eben, wenn da 6553,67 stünde, denn auch> diese 0,07 Abweichung sind hinreichend klein). Und jedesmal, wenn ich> mit 2 multipliziere zähle ich eine Zehnerpotenz hoch. Zum Schluss ist> der Multiplikator die Vorkommastellen und der Divisor die gezählten> Zehnerpotenzen... ?
Das Verfahren ist sehr einfach, nennt sich Dreisatz.
1/56 = x/2^24, x ausrechnen und runden.
Anstelle 2^24 beliebige Zweierpotenz einsetzen. Je höher die
Zweierpotenz desto genauer die Approximation.
Tycho B. schrieb:> 1. (REC_WCNT-1 downto 12) Ich dachte es gibt keinen Präprozessor. Wie> definierst du die Konstante REC_WCNT, mit constant?
ist ein generic den ich uebergebe. Damit werden die clock-counter
definiert (z.B. 16 bit breit)
>> 2. cnt_arr (to_integer (state_cnt_end)) Was macht diese Struktur?
das ist ein Array mit 16 entries, in dem werden die Clock-counts der
letzten 16 Symbole (SYNC, S&C, D0..D5, CRC, PAUSE) abgelegt
Tycho B. schrieb:> Das Verfahren ist sehr einfach, nennt sich Dreisatz.
Schon, aber dieser triviale Ansatz ignoriert ein "lokales
Genauigkeitsmaximum", das ggfs schon bei weniger Stellen ein hinreichend
genaues Ergebnis liefern würde.
> Je höher die Zweierpotenz desto genauer die Approximation.
Im Prinzip ja, aber wenn ich z.B. x/33 rechnen will, dann reichen mir
x*31/(2**10) für eine Genauigkeit von 1/1000, weil der genaue Faktor
eigentlich x*31,0303/1024 wäre:
Hier sieht man, dass diese Faustformel eben nicht uneingeschränkt gilt,
denn von 2**10 bis 2**14 ist der Fehler der Rechnung immer gleich groß.
> ausrechnen und runden.
Denn der Witz ist: wenn die gewählte Zweierpotenz ungünstig ist und der
gerundete Wert genau bei x,5 liegt, dann ist die Abweicung maximal. Im
Idealfall nimmt man eben einen Faktor, der, geteilt durch die
entsprechende Zweierpotenz, genau x,000 gibt. Dann ist die gewünschte
Division optimal und ohne Fehler implementiert. Fazit: generell sind
Faktoren mit geringstmöglicher Rundung optimal.
Lothar M. schrieb:> Tycho B. schrieb:>> Das Verfahren ist sehr einfach, nennt sich Dreisatz.> Schon, aber dieser triviale Ansatz ignoriert ein "lokales> Genauigkeitsmaximum", das ggfs schon bei weniger Stellen ein hinreichend> genaues Ergebnis liefern würde.
Ich habe mal den Fehler von 1/33 bis 1/200 durchgeplottet (von 2^8 bis
2^38), es gibt nirgends ein lokales Genauigkeitsmaximum, der Verlauf des
Fehlers ist monoton fallend (nicht streng monoton!). Man kann es also
mit mehr Stellen nicht schlechter machen. Ansonsten stimme ich zu, man
muss nicht unbedingt 2^32 nehmen, es kommt auf den zu akzeptierenden
Fehler an.
>> ausrechnen und runden.> Denn der Witz ist: wenn die gewählte Zweierpotenz ungünstig ist und der> gerundete Wert genau bei x,5 liegt, dann ist die Abweicung maximal. Im> Idealfall nimmt man eben einen Faktor, der, geteilt durch die> entsprechende Zweierpotenz, genau x,000 gibt. Dann ist die gewünschte> Division optimal und ohne Fehler implementiert. Fazit: generell sind> Faktoren mit geringstmöglicher Rundung optimal.
Wie gesagt, im ungünstigsten Fall führt die Einführung einer weiteren
Zweierpotenz zum gleichen Fehler, niemals größer.
berndl schrieb:> Tycho B. schrieb:>> 1. (REC_WCNT-1 downto 12) Ich dachte es gibt keinen Präprozessor. Wie>> definierst du die Konstante REC_WCNT, mit constant?> ist ein generic den ich uebergebe. Damit werden die clock-counter> definiert (z.B. 16 bit breit)>>>>> 2. cnt_arr (to_integer (state_cnt_end)) Was macht diese Struktur?> das ist ein Array mit 16 entries, in dem werden die Clock-counts der> letzten 16 Symbole (SYNC, S&C, D0..D5, CRC, PAUSE) abgelegt
Das heisst du teils jedes Nibble durch 56?
Tycho B. schrieb:> es gibt nirgends ein lokales Genauigkeitsmaximum
Das hatte ich evtl. falsch rübergebracht: das Verhältnis
"Genauigkeit/Wortbreite" hat lokale Maxima. Und das kann sich dann ggfs.
in Richtung "Genauigkeit/Aufwand" auswirken.
> Wie gesagt, im ungünstigsten Fall führt die Einführung einer weiteren> Zweierpotenz zum gleichen Fehler, niemals größer.
Oder mit anderen Worten: für das gleich gute Ergebnis können durchaus
auch weniger Bits ausreichen. Und damit ggfs. der beteiligte
Multiplizierer anders/effizienter implementiert werden. So lässt sich
hier die Multiplikation (x*31) ganz leicht so darstellen (x&"00000" -
x). Mit (x*124) sieht man das nicht so leicht (obwohl es im Prinzip das
selbe ist: x&"0000000"-x&"00")...
Lothar M. schrieb:> Tycho B. schrieb:>> es gibt nirgends ein lokales Genauigkeitsmaximum> Das hatte ich evtl. falsch rübergebracht: das Verhältnis> "Genauigkeit/Wortbreite" hat lokale Maxima. Und das kann sich dann ggfs.> in Richtung "Genauigkeit/Aufwand" auswirken.
Bin einverstanden)
>> Wie gesagt, im ungünstigsten Fall führt die Einführung einer weiteren>> Zweierpotenz zum gleichen Fehler, niemals größer.> Oder mit anderen Worten: für das gleich gute Ergebnis können durchaus> auch weniger Bits ausreichen. Und damit ggfs. der beteiligte> Multiplizierer anders/effizienter implementiert werden. So lässt sich> hier die Multiplikation (x*31) ganz leicht so darstellen (x&"00000" -> x). Mit (x*124) sieht man das nicht so leicht (obwohl es im Prinzip das> selbe ist: x&"0000000"-x&"00")...
Wenn man von c kommt, dann denkt man gar nicht mehr daran...
Zum Einen sind die Operationen schon in Logik gegossen, auch Division,
zum Anderen optimiert der Compiler den sonstigen Rest.
Ist es so, dass der Synthetisierer so etwas wie dein Beispiel nicht
erkennt? Wie gut sind die Optimierungen dieser Tools? Kann man am
schematic erkennen wie es implementiert wurde?
Tycho B. schrieb:> Das heisst du teils jedes Nibble durch 56?
das laeuft halt frei mit. Im Prinzip finde ich durch vergleichen der
Clock-counter heraus, wo der SYNC liegt. Der geteilt durch 56 gibt mir
dann die Ticktime, die ich fuer was anderes wieder benoetige
berndl schrieb:> Tycho B. schrieb:>> Das heisst du teils jedes Nibble durch 56?>> das laeuft halt frei mit. Im Prinzip finde ich durch vergleichen der> Clock-counter heraus, wo der SYNC liegt. Der geteilt durch 56 gibt mir> dann die Ticktime, die ich fuer was anderes wieder benoetige
Das habe ich mir auch überlegt, aber da die tick time zw. 3 und 90
liegen kann und gleichzeitig ein Pausenpuls vorliegen kann, der zwischen
12 und 768 ticks liegt, ist es schwierig z.B. den Pausenpuls vom sync zu
unterscheiden wenn man zuvor nicht die nominelle tick time vorgibt,
oder?
Tycho B. schrieb:> ist es schwierig z.B. den Pausenpuls vom sync zu> unterscheiden wenn man zuvor nicht die nominelle tick time vorgibt
der worst-case waere, wenn der SYNC faelschlicherweise als 27 Ticks im
Vergleich zum PAUSE waere. Dann waere weiterhin gefordert, dass die
'laengste' gueltige SENT Botschaft =0xFFFEFFFE immer noch als mindestens
12 Ticks berechnet wuerde. Das passt nicht! For allem, weil ja zum
Beispiel der S&C ueblicherweise nur 4, 8, oder 12 als numerischen Wert
hat (slow-channel).
Tycho B. schrieb:> Kann man am> schematic erkennen wie es implementiert wurde?
Es gibt üblicherweise zwei verschiedene Schematics die du ansehen
kannst: RTL Schematic und Technology Schematic (So heisst es in
Synplify) bzw. Schematic beim Design-Flow Schritt "Synthesize" und
Schematic beim Design-Flow Schritt "Map" (Das müsste etwa so zu finden
sein in Vivado und Diamond).
Das RTL Schematic ist das, was du uns als Screenshot gegeben hast. Das
ist im Prinzip die Darstellung was der Synthesizer verstanden hat (Im
Compiler Bau vergleichbar zum Abstract Syntax Tree). Das müsste grob dem
entsprechen, was du vorher als Blockdiagramm geplant hattest.
Das Technology Schematic bildet die selbe Funktionalität ab, nutzt dazu
aber Elemente, die in deiner Zielhardware vorhanden sind. Dies variiert
also zwischen verschiedenen FPGA Typen (Beim Compiler vergleichbar mit
dem Assembler Listing).
> der worst-case waere, wenn der SYNC faelschlicherweise als 27 Ticks im> Vergleich zum PAUSE waere. Dann waere weiterhin gefordert, dass die> 'laengste' gueltige SENT Botschaft =0xFFFEFFFE immer noch als mindestens> 12 Ticks berechnet wuerde. Das passt nicht! For allem, weil ja zum> Beispiel der S&C ueblicherweise nur 4, 8, oder 12 als numerischen Wert> hat (slow-channel).
Hm.
Nehmen wir mal als Basis die tick time und folgende Sequenz:
Pausenpuls, sync, 8*Nibble
und als Zeiten(tick time als 1):
115, 56, 8*27 (ich betrachte mal die zwei 0xE als 0xF)
rechnet man 115 als sync, dann bekommt man:
56, 27, 7*13 + 13 (die letzte 13 wird als Pausenpuls interpretiert)
56 + 27 + 7*13 = 174 ist größer als Mindestlänge von 154 ticks.
Oder habe ich dich falsch verstanden?
Christophz schrieb:> Es gibt üblicherweise zwei verschiedene Schematics die du ansehen> kannst: RTL Schematic und Technology Schematic (So heisst es in> Synplify) bzw. Schematic beim Design-Flow Schritt "Synthesize" und> Schematic beim Design-Flow Schritt "Map" (Das müsste etwa so zu finden> sein in Vivado und Diamond).>> Das RTL Schematic ist das, was du uns als Screenshot gegeben hast. Das> ist im Prinzip die Darstellung was der Synthesizer verstanden hat (Im> Compiler Bau vergleichbar zum Abstract Syntax Tree). Das müsste grob dem> entsprechen, was du vorher als Blockdiagramm geplant hattest.>> Das Technology Schematic bildet die selbe Funktionalität ab, nutzt dazu> aber Elemente, die in deiner Zielhardware vorhanden sind. Dies variiert> also zwischen verschiedenen FPGA Typen (Beim Compiler vergleichbar mit> dem Assembler Listing).
Vielen Dank für die Erklärung!
Und so sieht es in Vivado aus...
Tycho B. schrieb:> Oder habe ich dich falsch verstanden?
1. Dein PAUSE Puls ist ungewoehnlich lang
2. Dein S&C wuerde noch startup und error anzeigen
3. Deine CRC waere falsch
4. Der Wert 0xFFF fuer die FC-Daten bedeuted ueblicherweise einen Fehler
Fehlerwahrscheinlichkeit also annaehernd Null, ausserdem kannst du
folgende Botschaften ja mit der berechneten Ticktime plausibilisieren.
Laeuft hier seit (gerade nachgeguckt) 2012 ohne Probleme.
achso, nochwas:
5. Beim naechsten Nibble wuerdest du ja wieder den Prozess anschmeissen
und eine gueltige Message finden. Auch das kannst du zum
plausibilisieren ausnutzen
berndl schrieb:> Tycho B. schrieb:>> Oder habe ich dich falsch verstanden?>> 1. Dein PAUSE Puls ist ungewoehnlich lang> 2. Dein S&C wuerde noch startup und error anzeigen> 3. Deine CRC waere falsch> 4. Der Wert 0xFFF fuer die FC-Daten bedeuted ueblicherweise einen Fehler>> Fehlerwahrscheinlichkeit also annaehernd Null, ausserdem kannst du> folgende Botschaften ja mit der berechneten Ticktime plausibilisieren.> Laeuft hier seit (gerade nachgeguckt) 2012 ohne Probleme.
1. Eher normal. Pausenpuls wird verwendet um Frames konstanter Dauer zu
produzieren. Bei z.B. 3us tick time und 1ms Frame ist der Pausenpuls
zwischen ca. 63 und 183 ticks.
2. Ja
3. Alle? Es gibt ja einige mögliche Kombinationen. Der CRC hat auch
einen gewissen Fehler. Muss ich nachrechnen, kann aber sein.
4. Ja
5. Klappt nicht. Wenn man diese Logik verwendet, so würde man bei einem
Frame ohne Pausenpuls eventuell trotzdem einen detektieren, z.B.:
56, 27, 7*13
Wenn der Prozess bei 27 neu startet, so kann 27 als sync interpretiert
werden, 13 als 27 und 56 als Pausenpuls.
Die Synchronisierung anhand der Punkte 2-4 ist indirekt, d.h. es müssen
schon alle Werte dekodiert worden sein, um Entscheidung zu treffen. Ich
habe gehofft eine direkte Methode finden zu können, die sich allein aus
Pulslängen ableiten lässt. Das ist im FPGA deutlich einfacher zu
implementieren, imho.
Tycho B. schrieb:> würde man bei einem> Frame ohne Pausenpuls eventuell trotzdem einen detektieren, z.B.:> 56, 27, 7*13
deine Daten (max 27 Ticks) muessen kleiner als ein halber SYNC (56
Ticks) sein. Das klappt ganz sicher da 2x27=54 ist
berndl schrieb:> Tycho B. schrieb:>> würde man bei einem>> Frame ohne Pausenpuls eventuell trotzdem einen detektieren, z.B.:>> 56, 27, 7*13>> deine Daten (max 27 Ticks) muessen kleiner als ein halber SYNC (56> Ticks) sein. Das klappt ganz sicher da 2x27=54 ist
Wenn man diese Sequenz nimmt:
56, 27, 7*13
und 27 als sync interpretiert, so ist 13 (und 12 sowieso) kleiner als
die Hälfte.
So kann 56 Pausenpuls sein, 27 sync und der Rest Daten.

{kind=link}