Hallo Zusammen, Ich habe hier 3x STM32L443CB Nucleo rumliegen und 2x STM32L443CB als Ic auf eigener Prototypenschaltung verlötet. Es gibt im Controller eine 96bit (12byte) Unique ID. Da ich für Statistikzwecke eine ID benötige welche maximal 4 byte gross ist, suche ich nach einer Lösung um die UID vom STM32 zu shrinken. Die ID besteht aus folgenden Bytes: Byte 0-3 : X-Y Position des Die auf dem Wafer Byte 4: Wafer-Numer Byte 5-11: Lot-Nummer Anbei ein Screenshot meiner Auswertung der Controller. MCU 1 und 2 kommen von Mouser, MCU3-5 sind Nucleos. Was ins Auge sticht ist, das die Lot-Number jeweils die selbe ist, was auch in gewissem Masse logisch ist, da die IC wohl von der selben Serie kommen. Auch ist relativ aufällig das Byte 1 und 3 immer 0 sind, das ist natürlich bei nur 5 IC's auch gut möglich das es sich um einen Zufall handelt. Das jedoch ein einzelner Wafer 65535 x 65535 Die's beinhaltet ist auch sehr unwarscheilich, weshalb ich annehme das es nur 255x255 sein werden, und die Bit nur als Platzhalter dort sind. Auf einem Wafer für den STM32L433 gibt es sicher weniger Die's als für ein Modell mit nur wenig Funktionen & Pins. Meine Implementation für einen Shrink der ID hätte ich aktuell so vorgestellt: CRC16 aus Byte 0..4 errechnen CRC16 aus Byte 4..11 errechnen aus den 2x2 byte einen fiktiven uint_32 zusammensetzen also CRC1 | CRC2<<16 In einer Serienproduktion von Platinen, ist zudem davon auszugehen das die Lot Nummer wohl pro Serie zu grossen Teilen gleich ist, somit ist es sehr schwer ein Duplikat zu in der Lot-Nummer zu erhalten. Was haltet ihr von der Idee? Hat jemand vielleicht schon etwas ähnliches Realisiert? Möchte mir jemand allenfalls noch weitere UID's zusenden, um nach einem Muster zu suchen?
Johnny S. schrieb: > Es gibt im Controller eine 96bit (12byte) Unique ID. Da ich für > Statistikzwecke eine ID benötige welche maximal 4 byte gross ist, suche > ich nach einer Lösung um die UID vom STM32 zu shrinken. Je nach verwendetem Verfahren kann es bei einer Reduktion von 12 auf 4 Byte passieren, dass IDs doppelt auftreten. Wenn dich diese Restwahrscheinlich für Mehrfachvergabe nicht stört, kannst du einen Hash-Wert berechnen und als ID verwenden. Andernfalls brauchst du eine verlustfreie Kompression, was fetailierte Kenntnisse über die Struktur der Unique ID und/oder deiner Stichprobe voraus setzt.
Ich verwende diesen code für UID, SID und RNG.
1 | typedef __int128 int128_t; |
2 | typedef unsigned __int128 uint128_t; |
3 | |
4 | uint32_t uid,sid |
5 | uint64_t rng; |
6 | #define ssid build128(sec64(sid,xorshift(&rng)),sec64(xorshift(&rng),uid)) |
7 | |
8 | uint64_t xorshift64(uint64_t *state) |
9 | {
|
10 | uint64_t x = *state; /* The state must be seeded with a nonzero value. */ |
11 | x ^= x >> 12; // a |
12 | x ^= x << 25; // b |
13 | x ^= x >> 27; // c |
14 | *state = x; |
15 | return x * UINT64_C(0x2545F4914F6CDD1D); |
16 | } |
17 | uint32_t xorshift(uint64_t *state) { return xorshift64(state)>>32; }
|
18 | |
19 | |
20 | uint64_t build64(uint32_t a, uint32_t b) { uint64_t c; c=a&0xAAAAAAAA|b&0x55555555|(b&0xAAAAAAAA|a&0x55555555)<<32; return c; }
|
21 | uint128_t build128(uint64_t a, uint64_t b) { return build64(a>>32|b>>32)<<64|build64(a,b); }
|
22 | uint64_t sec64(uint32_t a, uint32_t b) { uint64_t r=build64(a,b)^xorshift64(&rng); uint32_t c=xorshift(&rng); uint8_t w,i; r+=c>>11; i=c>>5; i%=50; for(w=50+i;w--;) xorshift64(&r); for(w=50-i;w--;) xorshift64(&r); r+=xorshift(&r)<<(17+(++i&7); r^=xorshift(&r)>>15; return r; }
|
23 | |
24 | |
25 | init_uid() {
|
26 | uint64_t a,b,c; uint8_t i; uint16_t w; |
27 | a=build64(*uniq_id_3,*uniq_id_2); |
28 | b=build64(*uniq_id_1,*uniq_id_3); |
29 | j=c=xorshift(&a)<<32|xorshift(&b); |
30 | i=(w=xorshift(&c))>>10; j^=w>>3; for(w=200+i;w--;) xorshift64(&a); for(w=0xff-i;w--;) xorshift64(&c); |
31 | i=(w=xorshift(&c))>>10; j^=w>>3; for(w=200+i;w--;) xorshift64(&b); for(w=0xff-i;w--;) xorshift64(&c); |
32 | for(w=200+j;w--;) { xorshift64(&a); xorshift64(&b);xorshift64(&c); }
|
33 | uid=xorshift(&c); |
34 | for(w=0xff-j;w--;) { xorshift64(&c); xorshift64(&c);xorshift64(&c); }
|
35 | sid=((xorshift(&c)^xorshift(&b)^xorshift(&a))+uid; |
36 | rng= build64(xorshift(&a),xorshift(&b)); |
37 | i=xorshift64(&rng)>>10; sid^=build64(xorshift(&rng),xorshift(&c); |
38 | for(w=200+i;w--;) { xorshift64(&sid); xorshift64(&sid);xorshift64(sid); }
|
39 | for(w=0xff-i;w--;) { xorshift64(&rng); sid+=xorshift(&c)<<(17+(++j&7); sid^=xorshift(&c)>>15; }
|
40 | } |
Johnny S. schrieb: > Meine Implementation für einen Shrink der ID hätte ich aktuell so > vorgestellt: > > CRC16 aus Byte 0..4 errechnen > CRC16 aus Byte 4..11 errechnen > > aus den 2x2 byte einen fiktiven uint_32 zusammensetzen also CRC1 | > CRC2<<16 Und wieso benutzt Du nicht die interne CRC calculation unit?
chris schrieb: > init_uid() { > uint64_t a,b,c; uint8_t i; uint16_t w; > a=build64(*uniq_id_3,*uniq_id_2); > b=build64(*uniq_id_1,*uniq_id_3); (...) > for(w=0xff-i;w--;) { xorshift64(&rng); sid+=xorshift(&c)<<(17+(++j&7); > sid^=xorshift(&c)>>15; } > } Für den Code würdest du bei uns sofort eine Abmahnung kassieren.
Mehmet K. schrieb: > Johnny S. schrieb: >> Meine Implementation für einen Shrink der ID hätte ich aktuell so >> vorgestellt: >> >> CRC16 aus Byte 0..4 errechnen >> CRC16 aus Byte 4..11 errechnen >> >> aus den 2x2 byte einen fiktiven uint_32 zusammensetzen also CRC1 | >> CRC2<<16 > > Und wieso benutzt Du nicht die interne CRC calculation unit? Es geht ja nicht darum wie der CRC berechnet wird, also mit welcher Logik, sondern um die Art Ich hatte vor mit der internen CRC die beiden CRCs zu rechnen und dann zusammenzusetzen
Byte 0-4 ist schwach da dies xy coordinates sind. 16 bit aber bei der Die Größe sind dies nur 2 byte. Nimm 8-11 und jeweils 0-3, 4-7
cdef schrieb: > Für den Code würdest du bei uns sofort eine Abmahnung kassieren. Bei uns würde da schon ein eiskalter Wind durch den Arbeitsvertrag wehen!
Mw E. schrieb: > cdef schrieb: >> Für den Code würdest du bei uns sofort eine Abmahnung kassieren. > > Bei uns würde da schon ein eiskalter Wind durch den Arbeitsvertrag > wehen! Gegen eiskalten Wind hilft ein dickes Fell ;-)
Man muss sehr auf Kollisionen aufpassen, z.B. die oft propagierte methode von MD5 oder SHA1 ist in der Praxis unbrauchbar, da auf 32bit reduziert extrem viele gleiche Nummern auftreten. Ich verwende mehrere LFR welches uid relative einfach und sid sowie rng aufwändiger generiert. RNG wird nur intern sowie für Bootloader/Auth/Freischalungscodes benutzt. Danach wird es mit rng=build64(xorshift(rng),TID) ersetzt. TID ist eine UnixTime Konstante welche bei jedem release geändert wird und dient auch im EEprom zum Check ob dies Initialisiert ist usw.
1 | struct Uid {
|
2 | uint16_t X; // x-coordinate binned code digit, 0x800a = position -10 , if msb is set, number have to be negate. |
3 | uint16_t Y; // y-coordinate bcd encoded, center of chip is 0. |
4 | uint8_t WAF; // Wafer number |
5 | char LOT[7]; // Lot number. It is possibe that it embed some non printable characters, this could be binning info to replace with space, or it could be something where some bits are lot id and some bits are speed/defect grade. |
6 | }; |
7 | |
8 | Batch of 100 Chips uniq X, Y and WAF data. |
9 | X: 0003, 0008, 0009, 000a, 000b, 000e, 0010, 0013, 0014, 0015, 0016, 0018, 001c, 0021, 0024, 002a, 8001, 8002, 801b, 801c, 801d, 8020 |
10 | Y: 0003, 0005, 0006, 0007, 000c, 000f, 0010, 0011, 0013, 0014, 0016, 0017, 0018, 0019, 001a, 001b, 001e, 001f, 0020, 0022, 0024, 0028, 0029, 002a, 002c, 002d, 002e, 0030, 0032, 0033, 0034, 0035, 0037, 0038, 0039, 003a, 003c, 003f, 0042, 0044, 0045, 0046, 0047, 0048, 0049, 004b, 004e |
11 | WAF: 0b, 0c, 0d, 0e, 18 |
12 | |
13 | |
14 | 0x00410024 0x3848500c 0 X: 36 Y: 65 W: 12 L: PH8 uid: 3375-512-1140 sid: 3200-155-4603 rng: 5140-046-7130 |
15 | 0x005f0027 0x3848500c 0 X: 39 Y: 95 W: 12 L: PH8 uid: 0634-264-2360 sid: 3767-170-7247 rng: 4055-036-5176 |
16 | 0x20343634 0x57325707 0x00250023 X: 35 Y: 37 W: 7 L: W2W464 uid: 1057-063-1222 sid: 1054-545-3717 rng: 3630-222-5031 |
17 | 0x20343634 0x57325707 0x001F002F X: 47 Y: 31 W: 7 L: W2W464 uid: 0766-465-5517 sid: 1763-717-6146 rng: 0421-137-5547 |
18 | 0x20343634 0x57325704 0x00220036 X: 54 Y: 34 W: 4 L: W2W464 uid: 0615-476-0473 sid: 0400-534-0605 rng: 5707-370-6725 |
19 | 0x20363532 0x50335711 0x003F0026 X: 38 Y: 63 W: 17 L: W3P256 uid: 2077-175-0241 sid: 3742-221-6705 rng: 5527-055-3510 |
20 | 0x000c0020 0x41434305 0x20303432 X: 32 Y: 12 W: 5 L: CCA240 uid: 1355-454-3223 sid: 1176-222-2612 rng: 1126-352-0045 |
Angehängte Dateien:
-

MCUSN.png
14 KB
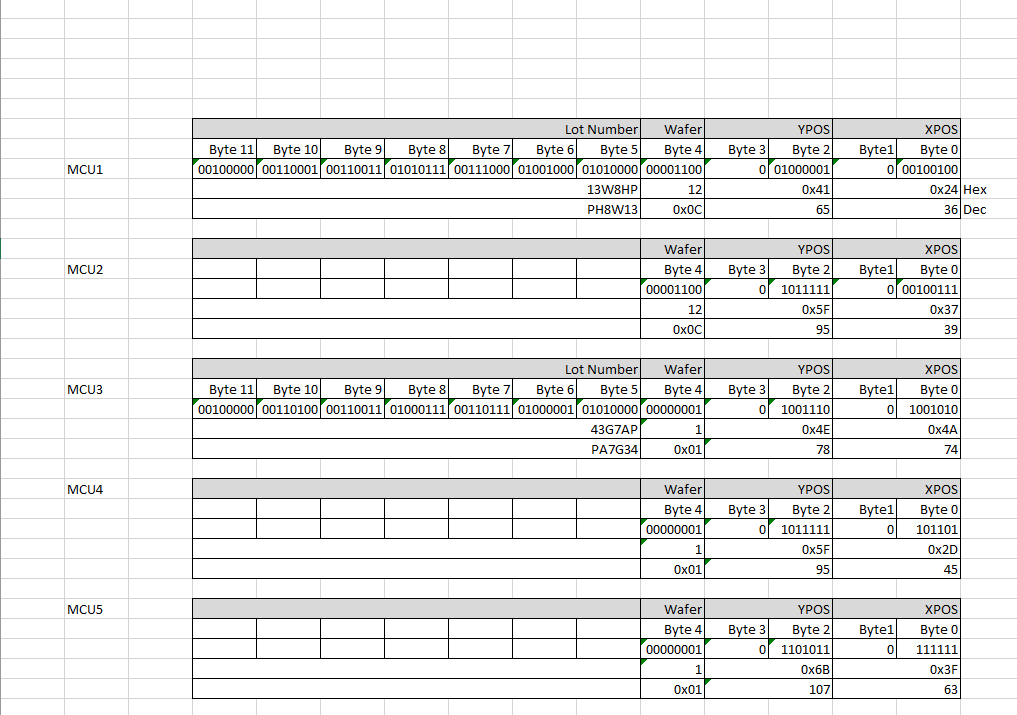
Anbei noch das Bild, was beim ersten Post vergessen wurde. Ich habe mir folgende Gedanken zu den Nummern gemacht: Lotnummer: Die Lotnummer wird in der Serienproduktion vermutlich den grössten Teil gleich sein, beziehungsweise es wird pro Produktionsserie nur 2-3 verschiedene Lots geben. Es ist stark anzunehmen das auf einenm Reel jeweils die selbe Lot-Nummer vorhanden ist, es macht ja keinen Sinn x-Lots zu mischen. Somit sind die Bytes 5-11 relativ wenig unterschiedlich. Selbst wenn man 20 verschiedene Lots kaufen würde, wäre das sicher viel. Die Bytes 0-4 ändern jedoch stark, kombiniert mit der wenig ändernden Lots, gäbe dies eine Relativ einfache ID. In meinem Fall reden wir vielleicht von insgesamt rund 25'000 Endprodukten, somit auch nicht die allergrösste Menge. Klar, wenn man nun z.b. 1 Million Endgeräte über einige Jahre baut steigt die Kollisionsgefahr. Zusätzlich kommt bei mir noch dazu, das pro "Anlage" nur 500-1000 Geräte verbaut sind. Zwei identische Nummern wären solange Egal, solange sie nicht in der gleichen Anlage im Einsatz sind, da Sie ja "nichts von einander Wissen" Die Anforderung ist folgende: Eine Unique 32bit ID zum einfügen von datensätzen in eine Datenbank, ist die ID gleich wie ein bestehnder Eintrag, soll statt "Insert" nur ein "Update" passieren. Es besteht keine Notwendigkeit von der generierten ID irgendwelche Rückschlüsse auf die tatsächliche ID zu machen. Früher wurde sowas mit "Silicon Serial Number" gemacht. Das würde ich mir aber gern sparen. Bei einer anderen Lösung wurde jeweils das EEPROM eines Mikrocontrollers beim Laden der Firmware mit einem aktuellen Zeitstempel bebrannt. Da der STM32L433 aber kein EEPROM hat, geht das hier nicht.
Wenn es um ganze Baugruppen geht, wäre eventuell der Einsatz eines externen ICs passender. Mit dem könntes du garantieren, dass es keine Kollisionen gibt.
Wenn es darum geht, wandel die 16bit bcd in 8bit signed int um. WAF ist
1-25,
da reichen dann 5 bits, bleiben 11 bits frei für die LOT.
Beispiel:
uint32_t make_uid() {
#define HASH_MULTIPLIER 36 // can be 1 too for intel type checksum
uint8_t i,j; uint16_t w; uint32_t res;
w=((uint16_t*)uniq_id_1)[0]; j=w; if(w&0x8000) j|=0x80; else j&=~0x80;
i=j; // X and Y Position, int8_t format. i==X, j==Y;
w=((uint16_t*)uniq_id_1)[1]; j=w; if(w&0x8000) j|=0x80; else j&=~0x80;
res=i<<24|j<<16; w=j=*uniq_id_2; res|=j<<11; // store X,Y,WAF
// build LOT id, start with WAF id, then xor all bytes, then hash it.
for(i=1;i<4;i++) { j=*uniq_id_2>>(i<<3); w^=j; }
for(i=0;i<4;i++) { j=*uniq_id_3>>(i<<3); w^=j; }
for(i=1;i<4;i++) { j=*uniq_id_2>>(i<<3); w*=HASH_MULTIPLIER; W+=j; }
for(i=0;i<4;i++) { j=*uniq_id_3>>(i<<3); w*=HASH_MULTIPLIER; W+=j; }
w&=0x7ff; res|=w; return res; // FORMAT MSB-LSB:
X(8)Y(8)WAF(5)LOT_HASH(11);
}
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.