Hallo Leute,
ich bin überfordert...
Kurzbeschreibung:
Über drei BCD Codierschalter soll eine Dezimalzahl eingestellt
werden...0-999.
Diese drei Codierschalter hängen an zwei Schieberegistern, allerdings
nicht so, dass ich die Bits der Reihe nach in eine 16 Bit Variable
shiften könnte. Die Stellen der drei Schalter sind nämlich vertauscht.
Ich muss daher die bits der beiden, aus dem Schieberegister gelesenen
Bytes, neu zusammensetzen und dabei auf drei 8-bit Variablen verteilen.
Und dazu auch noch negiert werden, denn was in den Ergebnis-Bytes eine 1
sein muss, kommt als 0 aus dem Schieberegister.
Also zum Beispiel:
1
uint8_thunderter=0;
2
uint8_tzehner=0;
3
uint8_teiner=0;
4
5
firstbyte=readBCDSwitches();
6
secondbyte=readBCDSwitches();
7
8
// Hunderter:
9
// 00000000
10
// ||||
11
// |||+--- !firstbyte.0
12
// ||+---- !firstbyte.2
13
// |+----- !firstbyte.1
14
// +------ !firstbyte.3
15
16
// Zehner:
17
// 00000000
18
// ||||
19
// |||+--- !secondbyte.4
20
// ||+---- !secondbyte.6
21
// |+----- !secondbyte.5
22
// +------ !secondbyte.7
23
24
// Einer:
25
// 00000000
26
// ||||
27
// |||+--- !secondbyte.0
28
// ||+---- !secondbyte.2
29
// |+----- !secondbyte.1
30
// +------ !secondbyte.3
31
32
hunderter=(..????..);
Kann mir vielleicht jemand ein Beispiel geben, wie man das Bit 2 aus der
Quellvariable negiert als Bit 1 in die Zielvariable schreibt?
Ich checks einfach nicht...
Vielen Dank für jeden Tip.
Ziel = 0;
if Quelle.bit=0 then ziel.bit=1;
und dann einfach 11 weitere ifs.
In Assembler sind das je nach Prozessor so ~27 Befehle (3 clr, 12x bit
test und bit set).
In C etwas mehr zu schreiben, aber ebenfalls trivial.
Wie man Bits abfragt und setzt weißt du aber?
negieren geht durch ein VerUNDen mit 0xffff
Und wenn die Zehner nur in der falschen Richtung laufen, kann man sie
z.B. über das Überlaufflag in eine andere Variable in umgekehrter
Richtung reinschieben. Aber hier sind die vier Bits ja noch
komplizierter angeordnet.
Am einfachsten mit einer Tabelle aus 16 Werten, also zu deiner Belegung
steht die jeweilig richtige Zahl. Dazu noch ein bisschen maskieren und
bei secondbyte 4xschieben.
Christoph db1uq K. schrieb:> negieren geht durch ein VerUNDen mit 0xffff
Seit wann? Wenn dann XOR. und ein Byte XORt man mit xFF.
Aber nötig ist das negieren hier nicht.
H.Joachim S. schrieb:> Am einfachsten mit einer Tabelle aus 16 Werten, also zu deiner Belegung> steht die jeweilig richtige Zahl. Dazu noch ein bisschen maskieren und> bei secondbyte 4xschieben.
Oh ja, eine LUT. Noch mehr Speicher und noch komplizierter. Und dann
noch maskieren und schieben.
oder mal nachdenken, ob es so gehen kann :-) :
1. Bit 1 in der Zielvariablen löschen
2. Inhalt der Quellvariablen so shiften, dass Bit 2 anschließend an der
Stelle Bit 1 steht.
3. alle Bits ausser Bit 1 löschen (inverse Maske von 1.)
4. mit der Zielvariablen "verodern"
Wenn du wirklich nur zwei Bytes bekommst, dann können Zehner und Einer
so nicht im zweiten Byte kodiert sein.
Ansonsten sind immer nur die mittleren Bits (2 <-> 1, bzw. 6 <-> 5)
vertauscht. Ausmaskieren und zurück tauchen:
1
unit8_tswap21(uint8_tin){
2
return(in&!0x06)|((in&0x02)<<1)|(in&0x04)>>1)
3
}
4
5
unit8_tswap65(uint8_tin){
6
return(in&!0x60)|((in&0x20)<<1)|(in&0x40)>>1)
7
}
Negieren kann man vorher oder nachher. firstbyte ist nach dem swap21()
direkt das hunderter Byte. secondbyte muss nach swap21() und swap(65)
noch auseinander "geshiftet" werden. Wie genau hängt davon ab wo sich
Zehner und Einer wirklich in secondbyte befinden.
NegativeOne! schrieb:> Diese drei Codierschalter hängen an zwei Schieberegistern, allerdings> nicht so, dass ich die Bits der Reihe nach in eine 16 Bit Variable> shiften könnte. Die Stellen der drei Schalter sind nämlich vertauscht.
Da wurden beim Routen der Platine ein paar Minuten eingespart, die
Entwicklungsarbeit wurde verkürzt. Die Software muss es jetzt ausbaden.
;-(
Wenigstens scheinen die Gebersignale alle in gleicher Weise verknotet zu
sein, so dass du mit einem über das Gebersignal indizierten Zugriff auf
ein 16er-Array die Sache ohne große Bitschieberei richten kannst.
Hallo zusammen,
vielen Dank für die Hilfestellung. Ich habe aus dem ein oder anderen
Kommentar eine Lösung geformt, die mir vorallem einigermaßen gut lesbar
erscheint.
Vielleicht probiere ich die kompakteren Möglichkeiten hier auch noch
aus, aber ich bin nicht so geübt damit und setze daher erstmal auf (für
mich) bessere Lesbarkeit ;)
1
hunderter|=!(firstbyte&(1<<0))<<0;
2
hunderter|=!(firstbyte&(1<<2))<<1;
3
hunderter|=!(firstbyte&(1<<1))<<2;
4
hunderter|=!(firstbyte&(1<<3))<<3;
Marten Morten schrieb:> Wenn du wirklich nur zwei Bytes bekommst, dann können Zehner und Einer> so nicht im zweiten Byte kodiert sein.
Stimmt - Formatierungsfehler. Sorry... so wäre es richtig:
Wolfgang schrieb:> Da wurden beim Routen der Platine ein paar Minuten eingespart, die> Entwicklungsarbeit wurde verkürzt. Die Software muss es jetzt ausbaden.> ;-(
Ich fürchte, genau das ist wurde hier gemacht. Oder ein Fall von
"Security by Obscurity"? ;)
Jens M. schrieb:> Oh ja, eine LUT. Noch mehr Speicher und noch komplizierter. Und dann> noch maskieren und schieben.
Schieben musst du auch...
Komplizierter ist es nicht.
Und ob mehr Speicher verbraucht wird, wäre erst mal zu überprüfen. Der
Unterschied wird minimal sein, vielleicht ist es sogar kompakter.
Spielt hier zwar keine Rolle, aber Laufzeit ist mit Sicherheit kleiner.
einer=tab[secondbyte & 0x0f];
zehner=tab[secondbyte>>4];
hunderter=tab[firstbyte & 0x0f];
Aber ich schiebe es trotzdem nicht durch den Compiler, beides geht.
Ok, da war Lothar schneller :-)
H.Joachim S. schrieb:> zehner=tab[secondbyte>>4];
Stimmt, da war ich zu übervorsichtig, da muss man eigentlich nichts
maskieren... ;-)
Dahingehend korrigiert sieht mein Vorschlag so aus:
Die Methode mit dem remap ist jedenfalls die lesbarste von Allen.
Ja, braucht mehr Platz und ist wohl auch nicht so schnell wie maskieren
und shiften.
Aber jedenfalls eleganter als die 12 if aus der 1. Antwort (OMG!)
Nick
Nick M. schrieb:> Ja, braucht mehr Platz und ist wohl auch nicht so schnell wie maskieren> und shiften.
Worauf basieren diese Annahmen?
Der Compiler kann so einen Arrayzugriff recht effizient umsetzen...
Das Array braucht einmalig Speicher (und wenn der unbedingt gespart
werden muss, dann kann man da auch ein uint8_t Array draus machen, muss
dann aber vor dem <<8 noch auf uint16_t casten, denn denn sonst kommt da
sicher 0 raus).
H.Joachim S. schrieb:> wills ja gar nicht in eine 16bit-Zahl haben, sondern in 3 einzelne chars.
Warts ab, was danach noch kommt. Üblicherweise braucht man solche Werte
im Programm nämlich "am Stück" in einer einzigen Variablen. Nenne es
einfach "Hellsehen"... ;-)
Lothar M. schrieb:> Warts ab, was danach noch kommt. Üblicherweise braucht man solche Werte> im Programm nämlich "am Stück" in einer einzigen Variablen. Nenne es> einfach "Hellsehen"... ;-)
Nee, glaube ich nicht. Er redet von BCD codieren. Das habe ich aber auch
überlesen.
Beides möglich :-)
Weil ich ja so gern recht habe:
Lieber schuchkleisser, dein if/foo/bar-Gekröse braucht 28Byte mehr.
Soviel zu voreiligen Behauptungen :-)
Andreas B. schrieb:> Er redet von BCD codieren.
Dann dürfte der Schaltern nur 10 Stellungen haben und dann muss man die
Umrechnung in 1 einzigen Wert so machen:
Lothar M. schrieb:> Dann dürfte der Schaltern nur 10 Stellungen haben
hat er ja auch:
NegativeOne! schrieb:> Über drei BCD Codierschalter soll eine Dezimalzahl eingestellt> werden...0-999.
H.Joachim S. schrieb:> hat er ja auch:> NegativeOne! schrieb:>> Über drei BCD Codierschalter soll eine Dezimalzahl eingestellt>> werden...0-999.
Da passt ja mein letzter Vorschlag wie die Faust ins Auge: als result
kommt genau so eine Zahl heraus... ;-)
Auf dem AVR braucht dieses Programm dann 280 Bytes im Programmspeicher
und 20 im Datenspeicher:
Die leere main(), also mit auskommentierter result Berechnung, braucht
172 Bytes im Programmspeicher und 0 Bytes bei den Daten. Verbleiben 108
Bytes für die Berechnung.
Die angepaste Lösung mit der if-Abfrage der Werte braucht 286 Bytes
Programm und 4 Bytes Daten, was abzüglich der leeren main() dann 114
Bytes Programmspeicherbedarf ergibt:
Fast, er will keine 16bit-Zahl.
Eigentlich war die Ursprungsfrage/Ziel absolut vollständig gestellt, das
ist selten hier :-)
-3 BCD-Schalter werden seriell in 2 Byte eingelesen
-die Schalter liefern negative Logik
-die Bitpositionen sind verwurstet, aber bei allen gleich
-Ziel: 3 8bit-Variablen mit je 0..9, also unpacked BCD
Und wer die LUT für beliebige Vertauschungen im Layout nicht zu Fuß
erstellen möchte (und auch zusätzlich noch eine Laufzeitfunktion zum
Vertauschen beliebiger Bits haben möchte), kann folgendes machen
(Erstellen der LUT zur Compile-Zeit):
H.Joachim S. schrieb:> Lieber schuchkleisser, dein if/foo/bar-Gekröse braucht 28Byte mehr.
Wo?
Im PIC geht das mit insgesamt 27 Instruktionen/Words.
Das Compiler so dämlich sind und das nicht können, und/oder das die
Architektur hier nicht genannt wurde, dafür kann ich nix.
LUT und Schieberei sind da definitiv größer. Das mag unter bestimmten
Prozessoren egal sein, aber ich bin ein Freund kompakten Codes, und
damit mein ich nicht das geschriebene, sondern das Ergebnis. Was nicht
bedeuten muss das es unleserlich wird.
Das mein Vorschlag natürlich ebenso gleich die dezimalisierung
übernehmen kann ist klar.
Und seid mir nicht böse, aber die Umsetzung der Tabelle (4bit) in ein
uint16 und die Schieberei der Bits finde ich alles andere als
übersichtlich.
Wenn da steht (Schalter a, Bit 1 = tausender bit 3) und man dann
"x+=800;" schreibt, da weiß man wenigstens wie der Wert berechnet wurde.
Auch wenn ich zugeben muss, das es als Zweizeiler sehr kompakt
geschrieben ist.
Wobei die Gesamtlösung auch z.B. vom Schaltplan abhängt: sind wirklich
alle 3 Schalter gleich vertauscht? Wenn nicht, braucht man 2 oder 3
LUTs.
Aber bitte, jeder hat seins.
Meine Lösung hat z.B. den Vorteil, beliebig viele Bits aus beliebigen
Bytes in andere beliebige Bytes transferieren zu können, inklusive
teilweiser negierung oder dezimalisierung.
Das erleichtert die Layouterstellung enorm, macht den Schaltplan aber
nicht unbedingt lesbarer...
H.Joachim S. schrieb:> -die Schalter liefern negative Logik
Also vorher noch invertieren ;-)
> -die Bitpositionen sind verwurstet, aber bei allen gleich> -Ziel: 3 8bit-Variablen mit je 0..9, also unpacked BCD
Dieses "Ziel" erscheint mir angesichts der Formulierung "ich muss
daher..." eher als "Zwischenziel", das dem sequenziellen Programm- und
Lösungsablauf geschuldet ist.
Finales Ziel dürfte die Aufgabenstellung in der ersten Zeile sein, wo
NegativeOne! schrieb:>>> soll eine Dezimalzahl eingestellt werden...0-999
Aber warten wirs ab...
Lothar M. schrieb:> foo = secondbyte&0xf;> bar = 0;> if (foo & 0x01) bar += 0x1;> if (foo & 0x02) bar += 0x4;> if (foo & 0x04) bar += 0x2;> if (foo & 0x08) bar += 0x8;> result += bar;
weil das ja auch gar nicht f-ing uneffizient implementiert ist.
Wenn man direkt if (secondbyte &0x..) macht und direkt (result += ..),
spart man die Maskierung, Zuweisungen und die Multiplikation ein, was
den Code verkürzt und die Lesbarkeit nicht verschlechtert.
Teste das bitte nochmal, aber diesmal mit nicht auf "ich beweis das
meine Lösung kürzer ist"-Voreinstellungen... ;)
Wilhelm M. schrieb:> Und wer die LUT für beliebige Vertauschungen im Layout nicht zu Fuß> erstellen möchte (und auch zusätzlich noch eine Laufzeitfunktion zum> Vertauschen beliebiger Bits haben möchte), kann folgendes machen> (Erstellen der LUT zur Compile-Zeit):
Ach du Sch....
Das ist weder lesbarer, noch kürzer. Mit Glück flexibler...
Wie lange muss man im dunklen Keller C büffeln bis man so ein Monstrum
lesen und konstruieren kann?
Jens M. schrieb:> Wie lange muss man im dunklen Keller C büffeln bis man so ein Monstrum> lesen und konstruieren kann?
C hilft da nicht weiter. Das ist C++. Und auch nicht jedes x-beliebige,
sondern ein neuerer Dialekt, wenn nicht sogar der allerneueste. Damit
verhindert man erfolgreich, dass man das Programm-Beispiel mit
demjenigen gcc-Compiler zum Laufen bringt, den man gerade so zufällig
auf dem Rechner rumfliegen hat. Wenn Wilhelm seine C++-Beispiele
auspackt, ist meistens erstmal eine Neuinstallation angesagt, um das
nachvollziehen zu können.
Möchte das vielleicht noch jemand in Oberon oder Python formulieren, um
noch mehr Unsicherheit für den TO zu schaffen?
Jens M. schrieb:> Teste das bitte nochmal, aber diesmal mit nicht auf "ich beweis das> meine Lösung kürzer ist"-Voreinstellungen...
Häh, wo habe ich das gemacht? Ich habe doch sogar bewiesen, dass die
if-Afragerei nur ein Fünftel des Datenspeichers braucht.
Das Weglassen der foo ändert gar nichts. So schlau ist der Compiler
offenbar sowieso, dass er die Berechnungen nicht 4 mal macht, sondern
einen Zwischenwert ausrechnet:
1
intmain()
2
{
3
unsignedcharbar=0;
4
5
if(firstbyte&0x01)bar+=0x1;
6
if(firstbyte&0x02)bar+=0x4;
7
if(firstbyte&0x04)bar+=0x2;
8
if(firstbyte&0x08)bar+=0x8;
9
result=bar*100;
10
11
bar=0;
12
if(secondbyte>>4&0x01)bar+=0x1;
13
if(secondbyte>>4&0x02)bar+=0x4;
14
if(secondbyte>>4&0x04)bar+=0x2;
15
if(secondbyte>>4&0x08)bar+=0x8;
16
result+=bar*10;
17
18
bar=0;
19
if(secondbyte&0xf&0x01)bar+=0x1;
20
if(secondbyte&0xf&0x02)bar+=0x4;
21
if(secondbyte&0xf&0x04)bar+=0x2;
22
if(secondbyte&0xf&0x08)bar+=0x8;
23
result+=bar;
24
25
while(1);
26
}
Ergebnis:
Program Memory Usage : 286 bytes
Data Memory Usage : 4 bytes
Und diese Lösung:
1
intmain()
2
{
3
result=0;
4
if(firstbyte&0x01)result+=100;
5
if(firstbyte&0x02)result+=400;
6
if(firstbyte&0x04)result+=200;
7
if(firstbyte&0x08)result+=800;
8
if(secondbyte>>4&0x01)result+=10;
9
if(secondbyte>>4&0x02)result+=40;
10
if(secondbyte>>4&0x04)result+=20;
11
if(secondbyte>>4&0x08)result+=80;
12
if(secondbyte&0xf&0x01)result+=1;
13
if(secondbyte&0xf&0x02)result+=4;
14
if(secondbyte&0xf&0x04)result+=2;
15
if(secondbyte&0xf&0x08)result+=8;
16
17
while(1);
18
}
braucht:
Program Memory Usage : 432 bytes
Data Memory Usage : 4 bytes
Bewertung (samt Abzug der leeren main() Funktion) bitte selber
durchführen, sonst wird nur wieder der Überbringer der Botschaft
gesteinigt.
Der Grund für den großen Codebedarf der letzten Variante liegt darin,
dass die ganzen zu addierenden unterschiedlichen Zahlen 1,2,...800 ja
alle als 16-Bit Integer in den Code müssen.
Wilhelm M. schrieb:> template<uint8_t Bit1, uint8_t Bit2, typename T>
und weitere ~30 Zeilen.
Wie immer die laengste, komlizierteste, unleserlichste und unnoetigste
"Loesung" weit und breit ;-)
leo
Danke für den Beweis.
OmfG was sind Compiler schlecht.
PIC kann so (Man möge mir verzeihen, AVR-Assembler kann ich nicht):
1
clrf result1
2
clrf result2
3
clrf result3
4
btfss firstbyte,x
5
bsf result1,y
6
btfss firstbyte,x
7
bsf result1,y
8
btfss firstbyte,x
9
bsf result1,y
10
...
Abseits der vorhandenen RAMs für die Eingangs- und Ausgangswerte kein
weiterer RAM-Verbrauch und nur 27 Flashzellen.
In AVR sollte das ähnlich gehen, der hat allerdings ja auch
mehrbyte-Befehle.
Gibts da BitTest und BitSet?
leo schrieb:> Wilhelm M. schrieb:>> template<uint8_t Bit1, uint8_t Bit2, typename T>>> und weitere ~30 Zeilen.>> Wie immer die laengste, komlizierteste, unleserlichste und unnoetigste> "Loesung" weit und breit ;-)
Naja, swapBits<> steckt man einmal in seinem Leben irgendwo in eine
Headerdatei. Fertig.
Die Generierung der LUT verhindert Copy-n-Paste-Fehler oder schlichtes
Verrechnen.
Zusätzlich hat man hier eine beliebig konfigurierbare Lösung für
beliebige Vertauschungen im Layout.
Und man kann wählen, welchen Speed <-> Memory-Tradeoff man haben will
(bis zu dem Punkt, wo die LUT 256 Einträge hat). Flexibler geht es kaum.
Und die LUT-Lösung ist die kürzeste und schnellste.
Lothar M. schrieb:> Andreas B. schrieb:>> Er redet von BCD codieren.> Dann dürfte der Schaltern nur 10 Stellungen haben und dann muss man die> Umrechnung in 1 einzigen Wert so machen:>
Viel zu einfach :-)
Da es im Thread nur noch um das Aufblasen von Code geht würde ich für
die Konvertierung von BCD nach Binär den Reverse Double Dabble
Algorithmus vorschlagen.
Da kommt anständig was zusammen. Bei drei BCD Ziffern sind das für die
Wandlung bis zu 10 Iterationen mit je einem Shift pro Iteration. Dazu
pro BCD Ziffer ein Vergleich pro Iteration, also drei pro Iteration,
eventuell mit vorheriger Maskierung. Nicht zu vergessen je nach Ergebnis
des Vergleichs eine Subtraktion pro BCD Ziffer und Iteration, also
maximal 30 Subtraktionen. Zum Schluss das Nachjustieren des Ergebnisses
mit Shifts wenn weniger als zehn Iterationen benötigt wurden. So macht
Code mit Bit-Shiften richtig was her :-)
Lothar M. schrieb:> if (secondbyte>>4 & 0x01) result += 10;> if (secondbyte>>4 & 0x02) result += 40;> if (secondbyte>>4 & 0x04) result += 20;> if (secondbyte>>4 & 0x08) result += 80;
Wozu denn die Bitshifterei?
426 Bytes, ein Horror.
Wird das weniger, wenn man statt der Addition den Compiler mit der Nase
drauf stößt und ein Or benutzt?
Ich denke, der hat tatsächlich eine gestackte 16-Bit-Addition mit
eingebaut und merkt sich 12 16bit große Integer, anstatt einfach ein
BitSet zu machen.
Jens M. schrieb:> Wird das weniger, wenn man statt der Addition den Compiler mit der Nase> drauf stößt und ein Or benutzt?
Nein, weil das falsch ist. Er will ein int als Ergebnis, damit er damit
rechnen kann.
Ich kenne keinen C-Compiler, der intern mit packed BCD rechnet.
Peter D. schrieb:> Sind auf dem AVR 72 Byte Code.
Alleine nur, weil keine 16bit-Addition dabei ist. Nice!
Peter D. schrieb:> Nein, weil das falsch ist. Er will ein int als Ergebnis, damit er damit> rechnen kann.
Was ist der Unterschied zwischen "Addiere 0x40" und "Setze Bit 6"?
Beides unter der Voraussetzung, das der Wert vorher genullt wurde...
Richtig: keiner. Nur ist der Compiler so dämlich das er das nicht merkt
und fröhlich den (leeren) 16-bit-Wert "0" auf den Stack schiebt, dann
den zu addierenden "0x0040" hinterher, dann kommt der Call der
offensichtlich ncht gerade kleinen Addierungsroutine, anschließend wird
der Wert des Ergebnisses vom Stack in den Variablenspeicher kopiert.
All das ist ein einziger BitSet-Befehl.
Der Peda hat's ja schon gezeigt, alleine nur die 8-Bit-Rechnung spart
schon ~80% Code ein.
Jens M. schrieb:> Wenn man direkt if (secondbyte &0x..) macht und direkt (result += ..),> spart man die Maskierung, Zuweisungen und die Multiplikation ein
Da sieht man, was der Compiler draus macht:
Er verwendet natürlich den sbrs Befehl. Aber er muss nach jeder
if-Abfrage den Wert mit 16 Bit berechnen und gleich darauf abspeichern,
weil es ja sein könnte, dass keine der nachfolgenden if-Abfragen mehr
greift.
Die Variante mit der direkten Abfrage von firstbyte/secondbyte und
Berechnung auf der lokalen Variabeln bar im
Beitrag "Re: Bits shiften - ich verstehe es nicht."
enthält noch einen Fehler: bar ist nur 8 Bit breit.
Mit der korrigierten Variante hier
1
intmain()
2
{
3
uint16_tbar=0;
4
5
if(firstbyte&0x01)bar+=0x1;
6
if(firstbyte&0x02)bar+=0x4;
7
if(firstbyte&0x04)bar+=0x2;
8
if(firstbyte&0x08)bar+=0x8;
9
result=bar*100;
10
11
bar=0;
12
if(secondbyte>>4&0x01)bar+=0x1;
13
if(secondbyte>>4&0x02)bar+=0x4;
14
if(secondbyte>>4&0x04)bar+=0x2;
15
if(secondbyte>>4&0x08)bar+=0x8;
16
result+=bar*10;
17
18
bar=0;
19
if(secondbyte&0xf&0x01)bar+=0x1;
20
if(secondbyte&0xf&0x02)bar+=0x4;
21
if(secondbyte&0xf&0x04)bar+=0x2;
22
if(secondbyte&0xf&0x08)bar+=0x8;
23
result+=bar;
24
25
while(1);
26
}
ergibt sich dann natürlich Mehraufwand:
Program Memory Usage : 312 bytes
Data Memory Usage : 4 bytes
Und das ist ein Ausschnitt fürs Hunderternibble vom Assemblercode:
1
int main()
2
{
3
uint16_t bar=0;
4
aa: 42 2f mov r20, r18
5
ac: 41 70 andi r20, 0x01 ; 1
6
ae: 50 e0 ldi r21, 0x00 ; 0
7
b0: ca 01 movw r24, r20
8
9
if (firstbyte & 0x01) bar += 0x1;
10
if (firstbyte & 0x02) bar += 0x4;
11
b2: 21 fd sbrc r18, 1
12
b4: 04 96 adiw r24, 0x04 ; 4
13
if (firstbyte & 0x04) bar += 0x2;
14
b6: 22 fd sbrc r18, 2
15
b8: 02 96 adiw r24, 0x02 ; 2
16
if (firstbyte & 0x08) bar += 0x8;
17
ba: 23 fd sbrc r18, 3
18
bc: 08 96 adiw r24, 0x08 ; 8
19
result = bar*100;
20
be: 24 e6 ldi r18, 0x64 ; 100
21
c0: 28 9f mul r18, r24
22
c2: a0 01 movw r20, r0
23
c4: 29 9f mul r18, r25
24
c6: 50 0d add r21, r0
25
c8: 11 24 eor r1, r1
Und zu guter Letzt nochmal die LUT-Variante, bei der vorrangig die
beiden Multiplikationen (und dabei besonders die *10 mit ihren vielen
Additionen) hervorstechen:
Wobei hier bereits das Abholen der Variabeln und Abspeichern des
Ergebnisses 16 Bytes brauchen... ;-)
Jens M. schrieb:> Der Peda hat's ja schon gezeigt, alleine nur die 8-Bit-Rechnung spart> schon ~80% Code ein.
Nur kommt da halt keiner drauf. Oder eben nur einer von vielen mit dem
Hintergrundwissen, dass man dem Compiler "nach dem Maul" programmieren
und zuerst so lange wie möglich mit einem 8-Bit Wert rechnen muss.
Peter D. schrieb:> Sind auf dem AVR 72 Byte Code.
Ich habe diesen "Netto"-Code mal angewendet und komme in der realen
"Brutto"-Anwendung wie hier:
1
uint16_tbcd3(uint16_tin)
2
{
3
uint8_toutl=0;
4
if(in&0x0001)outl+=100;
5
if(in&0x1000)outl+=10;
6
if(in&0x2000)outl+=40;
7
if(in&0x4000)outl+=20;
8
if(in&0x8000)outl+=80;
9
if(in&0x0100)outl+=1;
10
if(in&0x0200)outl+=4;
11
if(in&0x0400)outl+=2;
12
if(in&0x0800)outl+=8;
13
uint16_tout=outl;
14
if(in&0x0002)out+=400;
15
if(in&0x0004)out+=200;
16
if(in&0x0008)out+=800;
17
returnout;
18
}
19
20
intmain()
21
{
22
result=bcd3((uint16_t)firstbyte<<8+secondbyte);
23
24
while(1);
25
}
auf
Program Memory Usage : 288 bytes
Data Memory Usage : 4 bytes
Dann habe ich die LUT-Variante zum ernsthaften Vergleich auch mal
umgebaut und einen Funktionsaufruf draus gemacht:
Ergebnis:
Program Memory Usage : 290 bytes
Data Memory Usage : 20 bytes
Schlüsse bitte selber ziehen...
Peter D. schrieb:>> Ausführungszeit, Flash-Size, ggf. RAM-Size, Wartbarkeit, ...?> Diese Variante ist in allen 4 Punkten optimal.
Bei der Wartbarkeit möchte ich da mal einhaken: ich bin mir 100% sicher,
dass einige schon bei der ersten if-Abfrage in dieser Funktion ins
Schleudern kommen und die nach unten umsortieren. Dorthin, zu den
Hundertern, wo sie ihrem Gefühl nach auch hingehört... ;-)
So etwa:
1
uint16_tbcd3(uint16_tin)
2
{
3
uint8_toutl=0;
4
if(in&0x1000)outl+=10;
5
if(in&0x2000)outl+=40;
6
if(in&0x4000)outl+=20;
7
if(in&0x8000)outl+=80;
8
if(in&0x0100)outl+=1;
9
if(in&0x0200)outl+=4;
10
if(in&0x0400)outl+=2;
11
if(in&0x0800)outl+=8;
12
uint16_tout=outl;
13
if(in&0x0001)out+=100;
14
if(in&0x0002)out+=400;
15
if(in&0x0004)out+=200;
16
if(in&0x0008)out+=800;
17
returnout;
18
}
19
20
intmain()
21
{
22
result=bcd3((uint16_t)secondbyte<<8+firstbyte);
23
24
while(1);
25
}
Ergebnis dieser Änderung im obigen Gesamtprogramm:
Program Memory Usage : 292 bytes
Lothar M. schrieb:> Aber er muss nach jeder> if-Abfrage den Wert mit 16 Bit berechnen und gleich darauf abspeichern,> weil es ja sein könnte, dass keine der nachfolgenden if-Abfragen mehr> greift.
Und genau deshalb sollte man globale Variablen meiden, wie der Teufel
das Weihwasser.
Wilhelm M. schrieb:> Die Generierung der LUT verhindert Copy-n-Paste-Fehler> oder schlichtes Verrechnen.
Und wenn man dem Template falsche Parameter gibt (z.B. durch
Copy-n-Paste-Fehler oder schlichtes Verrechnen aus dem Schaltplan), dann
sucht man daran stundenlang herum. Einfach hinschreiben macht es für den
Menschen einfacher.
Lothar M. schrieb:> Bei der Wartbarkeit möchte ich da mal einhaken: ich bin mir 100% sicher,> dass einige schon bei der ersten if-Abfrage in dieser Funktion ins> Schleudern kommen und die nach unten umsortieren. Dorthin, zu den> Hundertern, wo sie ihrem Gefühl nach auch hingehört... ;-)
Manche Programmierer verwenden Kommentare um auf solche Besonderheiten
hinzuweisen :-)
> Ich habe diesen "Netto"-Code mal angewendet und komme in der realen> "Brutto"-Anwendung wie hier:>> uint16_t bcd3(uint16_t in)> {> uint8_t outl = 0;> if (in & 0x0001) outl += 100;> if (in & 0x1000) outl += 10;> if (in & 0x2000) outl += 40;> if (in & 0x4000) outl += 20;> if (in & 0x8000) outl += 80;> if (in & 0x0100) outl += 1;> if (in & 0x0200) outl += 4;> if (in & 0x0400) outl += 2;> if (in & 0x0800) outl += 8;> uint16_t out = outl;> if (in & 0x0002) out += 400;> if (in & 0x0004) out += 200;> if (in & 0x0008) out += 800;> return out;> }>> int main()> {> result = bcd3((uint16_t)firstbyte<<8 + secondbyte);>> while(1);> }
Ohne es ausgemessen zu haben und für einen Compiler der keine
Integer-Promotion von 8-Bit Argumenten macht:
1
//
2
// Convert the BCD input to an int.
3
// Accounts for the fact that bits 2 <-> 3 and 5 <-> 6 are
4
// swapped in the input due to hardware idiosyncrasies
5
//
6
uint16_tbcd3(uint8_tfirst,uint8_tsecond)
7
{
8
// perform as many operations as possible with 8-bit
9
uint8_toutl=0;
10
11
// Tenth (second byte high nibble)
12
if(second&0x80)outl+=80;
13
if(second&0x40)outl+=20;// \_ swapped
14
if(second&0x20)outl+=40;// /
15
if(second&0x10)outl+=10;
16
17
// Ones (second byte low nibble)
18
if(second&0x08)outl+=8;
19
if(second&0x04)outl+=2;// \_ swapped
20
if(second&0x02)outl+=4;// /
21
if(second&0x01)outl+=1;
22
23
// Hundreds (first byte low nibble)
24
// 100 still fits in the 8-bit outl variable, so we
25
// add it here, not below
26
if(first&0x01)outl+=100;
27
28
// Remaining values don't fit in the 8-but outl, so
Peter D. schrieb:> Und genau deshalb sollte man globale Variablen meiden, wie der Teufel> das Weihwasser.
Danke für den Impuls... ;-)
Durch eine lokale Variable auf diese Art:
1
#include<avr/io.h>
2
#include<stdio.h>
3
#include<stdint.h>
4
5
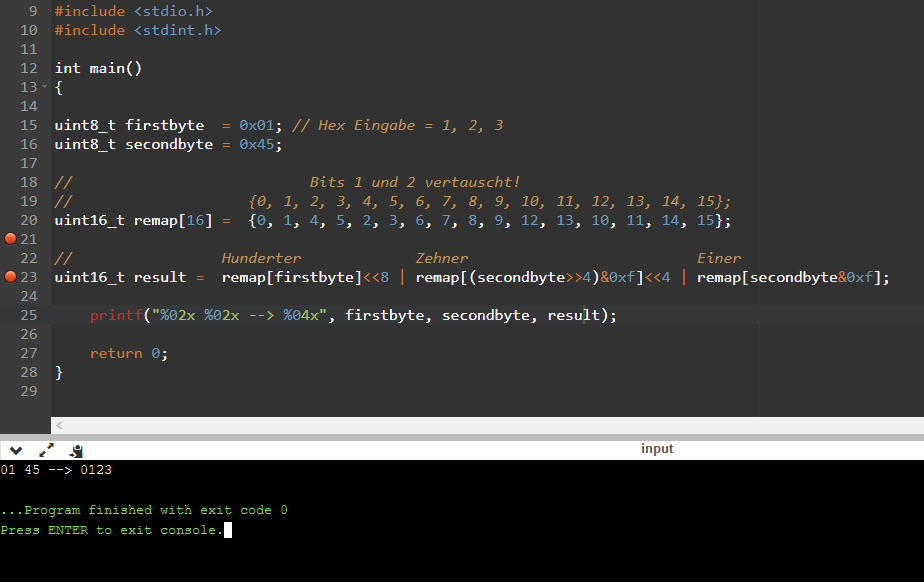
uint8_tfirstbyte=0x01;// Hex Eingabe = 1, 2, 3
6
uint8_tsecondbyte=0x45;
7
uint16_tresult;
8
9
intmain()
10
{
11
uint16_tr=0;
12
if(firstbyte&0x01)r+=100;
13
if(firstbyte&0x02)r+=400;
14
if(firstbyte&0x04)r+=200;
15
if(firstbyte&0x08)r+=800;
16
if(secondbyte>>4&0x01)r+=10;
17
if(secondbyte>>4&0x02)r+=40;
18
if(secondbyte>>4&0x04)r+=20;
19
if(secondbyte>>4&0x08)r+=80;
20
if(secondbyte&0x01)r+=1;
21
if(secondbyte&0x02)r+=4;
22
if(secondbyte&0x04)r+=2;
23
if(secondbyte&0x08)r+=8;
24
result=r;
25
26
while(1);
27
}
sieht das Ganze schon wesentlich besser aus:
Program Memory Usage : 270 bytes
Data Memory Usage : 4 bytes
Und auch die Variante mit Funktionsaufruf sieht gut aus:
1
uint16_tbcd3(uint8_tfirstbyte,uint8_tsecondbyte)
2
{
3
uint16_tr=0;
4
if(firstbyte&0x01)r+=100;
5
if(firstbyte&0x02)r+=400;
6
if(firstbyte&0x04)r+=200;
7
if(firstbyte&0x08)r+=800;
8
if(secondbyte>>4&0x01)r+=10;
9
if(secondbyte>>4&0x02)r+=40;
10
if(secondbyte>>4&0x04)r+=20;
11
if(secondbyte>>4&0x08)r+=80;
12
if(secondbyte&0x01)r+=1;
13
if(secondbyte&0x02)r+=4;
14
if(secondbyte&0x04)r+=2;
15
if(secondbyte&0x08)r+=8;
16
returnr;
17
}
18
19
intmain()
20
{
21
result=bcd3(firstbyte,secondbyte);
22
23
while(1);
24
}
Program Memory Usage : 278 bytes
Data Memory Usage : 4 bytes
Das simple Umsortieren der Abfragen und Zuweisungen analog zu Pedas
"erst mal nur Bytebearbeitung"-Strategie spart nochmal 4 Bytes:
Program Memory Usage : 274 bytes
1
uint16_tbcd3(uint8_tfirstbyte,uint8_tsecondbyte)
2
{
3
uint16_tr=0;
4
if(secondbyte&0x01)r+=1;
5
if(secondbyte&0x02)r+=4;
6
if(secondbyte&0x04)r+=2;
7
if(secondbyte&0x08)r+=8;
8
if(secondbyte>>4&0x01)r+=10;
9
if(secondbyte>>4&0x02)r+=40;
10
if(secondbyte>>4&0x04)r+=20;
11
if(secondbyte>>4&0x08)r+=80;
12
if(firstbyte&0x01)r+=100;
13
if(firstbyte&0x02)r+=400;
14
if(firstbyte&0x04)r+=200;
15
if(firstbyte&0x08)r+=800;
16
returnr;
17
}
18
19
intmain()
20
{
21
result=bcd3(firstbyte,secondbyte);
22
23
while(1);
24
}
Denn da erkennt der Compiler, dass er bei den ersten paar Rechnungen das
höherwertige Byte nicht beackern muss...
Marten Morten schrieb:> Ohne es ausgemessen zu haben
Program Memory Usage : 268 bytes
Das kommt allein vom Umformatieren von Pedas Code auf 2 Chars statt 1
Short als Aufrufparameter... ;-)
Der Assembler der 2-Char-Variante:
1
uint16_t bcd3(uint8_t first, uint8_t second)
2
{
3
// perform as many operations as possible with 8-bit
4
uint8_t outl = 0;
5
b0: 90 e0 ldi r25, 0x00 ; 0
6
7
// Tenth (second byte high nibble)
8
if (second & 0x80) outl += 80;
9
if (second & 0x40) outl += 20; // \_ swapped
10
b2: 66 fd sbrc r22, 6
11
b4: 9c 5e subi r25, 0xEC ; 236
12
if (second & 0x20) outl += 40; // /
13
b6: 65 fd sbrc r22, 5
14
b8: 98 5d subi r25, 0xD8 ; 216
15
if (second & 0x10) outl += 10;
16
ba: 64 fd sbrc r22, 4
17
bc: 96 5f subi r25, 0xF6 ; 246
18
19
// Ones (second byte low nibble)
20
if (second & 0x08) outl += 8;
21
be: 63 fd sbrc r22, 3
22
c0: 98 5f subi r25, 0xF8 ; 248
23
if (second & 0x04) outl += 2; // \_ swapped
24
c2: 62 fd sbrc r22, 2
25
c4: 9e 5f subi r25, 0xFE ; 254
26
if (second & 0x02) outl += 4; // /
27
c6: 61 fd sbrc r22, 1
28
c8: 9c 5f subi r25, 0xFC ; 252
29
if (second & 0x01) outl += 1;
30
ca: 60 fd sbrc r22, 0
31
cc: 9f 5f subi r25, 0xFF ; 255
32
33
// Hundreds (first byte low nibble)
34
// 100 still fits in the 8-bit outl variable, so we
35
// add it here, not below
36
if (first & 0x01) outl += 100;
37
ce: 20 fd sbrc r18, 0
38
d0: 9c 59 subi r25, 0x9C ; 156
39
40
// Remaining values don't fit in the 8-but outl, so
Man sieht, dass die Funktion selber exakt gleich lang ist, und der
Aufwand nur am Zusammenbasteln des Aufruf-Parameters für bcd3()
entsteht.
Lutz S. schrieb:> Wenn man das gleich am Anfang macht kann auch die Addition noch> entfallen.
Was wie macht?
Lothar M. schrieb:> Marten Morten schrieb:>> Ohne es ausgemessen zu haben> Program Memory Usage : 268 bytes
Ist das das text-segment? Dann solltest Du auch den µC-Typ angeben.
Eure Betrachtungen scheinen mir akademisch,
egal wie schnell nud mit wie vielen Befehlsbytes,
denn sie liefern ALLE das falsche Ergebnis,
Laut
NegativeOne! schrieb:> Und dazu auch noch negiert werden, denn was in den Ergebnis-Bytes eine 1> sein muss, kommt als 0 aus dem Schieberegister.
aber wir sehen hier:
1
uint16_tbcd3(uint8_tfirst,uint8_tsecond)
2
{
3
uint8_toutl=0;
4
if(second&0x80)outl+=80;
Wenn das bit in second GESETZT ist, wird auch das bit im Ergebniswert
gesetzt.
Es müsste
1
uint8_toutl=0;
2
if(!(second&0x80))outl+=80;
lauten.
Der tabellengesteuerte code braucht natürlich nur andere Tabellenwerte.
Peter D. schrieb:> Wilhelm M. schrieb:>> Worum geht es denn: Ausführungszeit, Flash-Size, ggf. RAM-Size,>> Wartbarkeit, ...?>> Diese Variante ist in allen 4 Punkten optimal.
Sicher nicht.
Die schnellste Variante ist die, die eine 8KB-LUT verwendet. Und die
kann man sich mit meinem oben gezeigten Code ganz simpel erstellen
lassen (zur Compilezeit).
Lothar M. schrieb:> Lutz S. schrieb:>> Wenn man das gleich am Anfang macht kann auch die Addition noch>> entfallen.> Was wie macht?
Wahrscheinlich meint er
Wilhelm M. schrieb:> Die schnellste Variante ist die, die eine 8KB-LUT verwendet.
Was glaubst Du, wieviele Millionen mal der TO die Schiebeschalter pro
Sekunde auslesen möchte?
Frank M. schrieb:> Wilhelm M. schrieb:>> Die schnellste Variante ist die, die eine 8KB-LUT verwendet.>> Was glaubst Du, wieviele Millionen mal der TO die Schiebeschalter pro> Sekunde auslesen möchte?
Steht hier nicht zur Debatte: es es ging um die u.g. Pauschalaussage,
und die ist nun mal falsch.
Wilhelm M. schrieb:> Peter D. schrieb:>> Wilhelm M. schrieb:>>> Worum geht es denn: Ausführungszeit, Flash-Size, ggf. RAM-Size,>>> Wartbarkeit, ...?>>>> Diese Variante ist in allen 4 Punkten optimal.
MaWin schrieb:> Eure Betrachtungen scheinen mir akademisch,> egal wie schnell nud mit wie vielen Befehlsbytes,> denn sie liefern ALLE das falsche Ergebnis,
Akademisch ist es schon lange - aber trotzdem interessant, wieviel
Optimierungspotential selbst in einfachen Sachen steckt.
Und falsch ist es auch nicht - es herrschte Übereinkunft, dass vorher
negiert wurde bzw. das es vorrangi um die Sortierei geht. Natürlich kann
man das weglassen und die Bits auf 0 testen bzw. dies bei einer
LUT-Lösung direkt berücksichtigen.
H.Joachim S. schrieb:> Akademisch ist es schon lange - aber trotzdem interessant, wieviel> Optimierungspotential selbst in einfachen Sachen steckt.
Wer das interessant findet, sollte sich mal die Diskussion um
std::midpoint() ansehen.
Wilhelm M. schrieb:> Steht hier nicht zur Debatte: es es ging um die u.g. Pauschalaussage,> und die ist nun mal falsch.
Wenn man es unbedingt falsch verstehen will, dann ja.
Gemeint ist natürlich, daß sie in der Summe aller Faktoren optimal ist.
Klar kann man einzelne Faktoren noch weiter optimieren, wenn man die
anderen ins Unterirdische absenkt.
Peter D. schrieb:> Gemeint ist natürlich, daß sie in der Summe aller Faktoren optimal ist.
Da legst Du dann Deine, persönliche Gewichtung zugrunde? Na prima, dass
ist ja Politikergeschwafel!
Marten Morten schrieb:> Wahrscheinlich meint er> uint8_t outl = 0;> if (second & 0x01) outl += 1;> an den Anfang zu setzen und dann durch> uint8_t outl = second & 0x01;> zu ersetzen.
Stimmt, spart nochmal 4 Byte:
1
uint16_tbcd3(uint8_tfirst,uint8_tsecond)
2
{
3
// perform as many operations as possible with 8-bit
4
uint8_toutl=second&0x01;
5
6
// Tenth (second byte high nibble)
7
if(second&0x80)outl+=80;
8
if(second&0x40)outl+=20;// \_ swapped
9
if(second&0x20)outl+=40;// /
10
if(second&0x10)outl+=10;
11
12
// Ones (second byte low nibble)
13
if(second&0x08)outl+=8;
14
if(second&0x04)outl+=2;// \_ swapped
15
if(second&0x02)outl+=4;// /
16
17
18
// Hundreds (first byte low nibble)
19
// 100 still fits in the 8-bit outl variable, so we
20
// add it here, not below
21
if(first&0x01)outl+=100;
22
23
// Remaining values don't fit in the 8-but outl, so
24
// convert to 16 bit for the remaining values
25
uint16_tout=outl;
26
27
if(first&0x08)out+=800;
28
if(first&0x04)out+=200;// \_ swapped
29
if(first&0x02)out+=400;// /
30
31
returnout;
32
}
33
34
intmain()
35
{
36
result=bcd3(firstbyte,secondbyte);
37
38
while(1);
39
}
Program Memory Usage : 264 bytes
Frank M. schrieb:> Hier eine Variante, die nochmals 2-4 Bytes Code einspart
Program Memory Usage : 288 bytes
Mehraufwand durch die zusätzlichen Funktionsaufrufe...
Jetzt habe ich aber genug. Inzwischen sind gut 15 unterschiedliche
Varianten zusammengekommen ;-)
Wilhelm M. schrieb:> Da legst Du dann Deine, persönliche Gewichtung zugrunde?
Naja, ganze 8 KB für eine Lookup-Table ist jetzt auch nicht der Burner
gegenüber schlanken 72 Bytes an Code. Schon bei einem ATmega88 wäre hier
Schicht im Schacht.
Mach doch mal eine Tabelle mit Gewichtungsfaktoren für Speicherbedarf,
Geschwindigkeit usw.
Dann kann man die vorgestellten Lösungen mit dem Taschenrechner
"ranken". ;-)
Beispiel: Wären alle Gewichtungsfaktoren gleich hoch, muss Dein Programm
bei 113 mal höherem Speicherbedarf auch 113 mal schneller sein, um noch
mitzuhalten.
P.S.
1
8192 / 72 = 113. Deinen Speicherbedarf für den Code habe ich hier noch nicht mitgerechnet.
Frank M. schrieb:> Naja, ganze 8 KB für eine Lookup-Table ist jetzt auch nicht der Burner> gegenüber schlanken 72 Bytes an Code. Schon bei einem ATmega88 wäre hier> Schicht im Schacht.
Der Code ist linear und 40 Bytes (s.a. Geschwindigkeit)
Natürlich ist es klar, das man das bei den Schaltern wohl nicht so
macht, oder?
Frank M. schrieb:> Wären alle Gewichtungsfaktoren gleich hoch, muss Dein Programm bei 113> mal höherem Speicherbedarf auch 113 mal schneller sein, um noch> mitzuhalten.
Wenn denn sonst kein anderer Parameter wie z.B. die
Wartbarkeit/Verständlichkeit auch noch beeinflusst werden könnte. Ich
zumindest möchte keinen Fehler in einer 8kByte großen LUT suchen... ;-)
Lothar M. schrieb:> Wenn denn sonst kein anderer Parameter wie z.B. die> Wartbarkeit/Verständlichkeit auch noch beeinflusst werden könnte. Ich> zumindest möchte keinen Fehler in einer 8kByte großen LUT suchen... ;-)
Den brauchst Du auch nicht zu suchen.
Wilhelm M. schrieb:> Natürlich ist es klar, das man das bei den Schaltern wohl nicht so> macht, oder?
Natürlich ist das klar.
Und wenn es keine Schalter, sondern sonstwie schnelle Signale wären, wo
man in Zeitnot geraten könnte:
Dann würde man so einen Fehler wie eine Vertauschung von 2 Pins partout
vermeiden. Und schon wäre die BCD-Wandlung ohne LUT nochmal um ein
Vielfaches schneller, wodurch der Geschwindigkeitsabstand zur Lösung mit
LUT auf jeden Fall geringer würde.
Lothar M. schrieb:> Frank M. schrieb:>> Hier eine Variante, die nochmals 2-4 Bytes Code einspart> Program Memory Usage : 288 bytes
Hm, mein avr-gcc 4.7.2 klumpt das zusammen auf 276 bytes. Aber ich weiß
jetzt auch nicht mehr, was der bisher minimalste Wert war.
> Mehraufwand durch die zusätzlichen Funktionsaufrufe...
Ja, kann sein. Ich dachte, die würden inline durchgehen...
Aber egal, mir reichts jetzt auch. :-)
Frank M. schrieb:> Hm, mein avr-gcc 4.7.2 klumpt das zusammen auf 276 bytes. Aber ich weiß> jetzt auch nicht mehr, was der bisher minimalste Wert war.
Na dann sag doch endlich mal für welchen Controller! Sonst kann man
nicht viel vergleichen. Oder gibt die tatsächliche Größe des Codes an,
ohne vector-table, etc.
Wilhelm M. schrieb:> Na dann sag doch endlich mal für welchen Controller!
Upps, der war für Atmega644. Ich habe es jetzt mal auf Atmega88
umgestellt:
Nun sind es nur noch 202 Bytes statt 276 Bytes Programmcode.
> Oder gibt die tatsächliche Größe des Codes an,
Blick in die lss-Datei:
bcdnibble: 36 Bytes
bcd3: 56 Bytes
Macht insgesamt 92 Bytes. Hm, da klingen Pedas 72 Bytes doch besser.
Aber auf jeden Fall besser als 8232 Bytes.. ;-)
P.S.
Ich frage mich, was Du da vergleichen willst:
1. Dein Code versagt für ATmega88
2. Dein Code versagt mit avr-gcc 4.7.2
Wilhelm M. schrieb:> leo schrieb:>> Wilhelm M. schrieb:>>> template<uint8_t Bit1, uint8_t Bit2, typename T>>>>> und weitere ~30 Zeilen.>>>> Wie immer die laengste, komlizierteste, unleserlichste und unnoetigste>> "Loesung" weit und breit ;-)>> Naja, swapBits<> steckt man einmal in seinem Leben irgendwo in eine> Headerdatei. Fertig.
Man kann das natürlich so machen, wenn man Spaß daran hat.
Aber mal Hand aufs Herz:
Hast du die Funktion swapBits schon jemals früher gebraucht?
Oder siehst du eine reelle Chance, sie jemals wiederzuverwenden?
Dazu ist die Funktion trotz Vertemplatisierung zu speziell, denn beim
nächsten ähnlich liegenden Fall wird der Hardwareentwickler sicher nicht
2, sondern 3 oder gar alle 4 Bits durcheinanderschmeißen oder seinen
Fehler einsehen und alle Bits in ihrer natürlichen Reihenfolge halten.
Peter D. schrieb:> Man kann das noch weiter optimieren, indem man zuerst das Low-Byte> berechnet:>
1
>uint16_tbcd3(uint16_tin)
2
>{
3
>uint8_toutl=0;
4
>if(in&0x0001)outl+=100;
5
...
6
>returnout;
7
>}
8
>
>> Sind auf dem AVR 72 Byte Code.
Nimmt man das Lesen zweier volatile (Ports) mit hinzu, so kommt man auch
hier auf 88 Bytes Code, gegenüber 90 Bytes bei der anderen if-Variante.
Gleiche 90-Bytes erzielt man (m.E. lesbarer und flexibler) mit
generischem C++, oder 40-Bytes mit 8K-Monster-LUT oder 66-Bytes mit
(256+32)-Bytes-LUT oder 82-Bytes mit 16-Bytes-LUT.
Yalu X. schrieb:> Wilhelm M. schrieb:>> leo schrieb:>>> Wilhelm M. schrieb:>>>> template<uint8_t Bit1, uint8_t Bit2, typename T>>>>>>> und weitere ~30 Zeilen.>>>>>> Wie immer die laengste, komlizierteste, unleserlichste und unnoetigste>>> "Loesung" weit und breit ;-)>>>> Naja, swapBits<> steckt man einmal in seinem Leben irgendwo in eine>> Headerdatei. Fertig.>> Man kann das natürlich so machen, wenn man Spaß daran hat.>> Aber mal Hand aufs Herz:>> Hast du die Funktion swapBits schon jemals früher gebraucht?
Ja.
> Oder siehst du eine reelle Chance, sie jemals wiederzuverwenden?
Ja.
Ich habe eine Klasse für ein PinSet (beliebige Pins eines Ports in
beliebiger Reihenfolge mit beliebiger LUT). Wenn es nicht sehr auf
Laufzeit ankommt, kann man sich dadurch ggf. auch das HW-Design
vereinfachen - also nicht versehentlich, sondern absichtlich
vertauschen.
Wilhelm M. schrieb:>> Hast du die Funktion swapBits schon jemals früher gebraucht?>> Ja.>>> Oder siehst du eine reelle Chance, sie jemals wiederzuverwenden?>> Ja.
Das soll einer verstehen: Du benutzt ständig diese sehr spezifische
swapBits-Funktion (ich persönlich hätte dafür noch nie Bedarf gehabt),
obwohl du eine weitaus generischere Funktion in der Hinterhand hast:
> Ich habe eine Klasse für ein PinSet (beliebige Pins eines Ports in> beliebiger Reihenfolge mit beliebiger LUT).
Yalu X. schrieb:> Wilhelm M. schrieb:>>> Hast du die Funktion swapBits schon jemals früher gebraucht?>>>> Ja.>>>>> Oder siehst du eine reelle Chance, sie jemals wiederzuverwenden?>>>> Ja.>> Das soll einer verstehen:
Was ist daran schwer (s.u.)?
> Du benutzt ständig diese sehr spezifische> swapBits-Funktion (ich persönlich hätte dafür noch nie Bedarf gehabt),> obwohl du eine weitaus generischere Funktion in der Hinterhand hast:
Nein. Die Funktion ist Teil der genannten Klasse.
Die Klasse zu posten wäre möglich, aber sinnlos.
Wilhelm M. schrieb:> Natürlich ist es klar, das man das bei den Schaltern> wohl nicht so macht, oder?
Ich dachte, du hast deine Lösung genau deswegen gepostet?