Hallo zusammen,
ich will auf einem STM32F103 (Build-Umgebung ist der ARM-GCC none EABI,
aber auf dem PC muss die Lösung natürlich auch funktionieren) relativ
häufig eine Integer-Berechnung der folgenden Form durchführen:
Das Endergebnis ist eine recht überschaubare positive Zahl.
Allerdings sind die Zwischenergebnisse recht gross.
Die einzige echte Variable ist x - alle anderen Zahlen sind beim Start
dieses Programmteils bekannt und ab diesem Zeitpunkt konstant. Also wird
die Geschichte wohl am Ende auf eine Q64- oder Q32-Näherung
herauslaufen.
Bis auf die Tatsache, dass f höchstwahrscheinlich durch 2 teilbar ist,
kann ich auch nicht auf irgendwelche individuellen ganzzahligen
Teilungsverhältnisse bauen. Es gibt keine Garantie, dass Zähler oder
Nenner in 64 Bit passen.
Eine Näherung über double würde ich mir gern sparen, um mir die
Einbindung der entsprechenden Libaries zu ersparen.
Gibt es Tricks, wie man solche großen Integer-Rechnungen korrekt auf den
STM32 durchführen kann, oder bin ich auf float-Näherungen angewiesen
(und wenn ja, wie setze ich die sinnvoll um, um den Fehler minimal zu
halten)?
Walter T. schrieb:> Gibt es Tricks, wie man solche großen Integer-Rechnungen korrekt auf den> STM32 durchführen kann
Natürlich: Man implementiert einfach die "breite" Arithmetik, soweit
nötig. Multiplikation und Division sind ja nun kein Hexenwerk.
Solange du den Wertebereich der einzelnen Werte nicht weiter
einschränken kannst, wirst du keine allgemeingültige Lösung finden
können.
Nur mit der nötigen Stellenzahl kannst du die Rundungsfehler klein
halten. Float hat das selbe Problem, allerdings wird dort der
Dynamikbereich, zu Lasten der Stellenzahl, durch den Exponenten
erweitert und bei Multiplikation/Division immer mit voller Stellenzahl
gerechnet, was bei Integer, wie du schon festgestellt hat, nicht
funktioniert. Dafür hat float bei Addition/Subtraktion unterschiedlich
großer Zahlen mit vielen (Dual-)Stellen Probleme.
Walter T. schrieb:> y=x2⋅f22⋅L2⋅a
Mhh, wenn ich mich nicht täsuche, kann man das so schreiben.
y = 1/(2*a) * sqr(x*f/L)
Der Faktor 1//2a) ist einfach, die Quotient x*f/L läuft nicht aus dem
Ruder, damit kann man alles in 32 Bit rechnen, ohne großartig an
Genauigkeit durch Rundungsfehler zu verlieren.
Falk B. schrieb:> wenn ich mich nicht täsuche, kann man das so schreiben.
Stimmt. Manchmal sieht man den Wald vor lauter Bäumen nicht mehr. Danke
für den Ansatz.
Ein wenig bin ich noch von der Fehlerabschätzung überfordert.
Exakte Rechnung:
Integer-Näherung:
Näherung durch Division vor der Quadrierung:
Von der äußeren abrundenden Division ist der Fehler immer positiv und
kleiner als 1. Aber wie berücksichtige ich den Fehler von
(Wenn jemand ein gutes Lehrbuch zu diesem Thema kennt: Nur heraus. Das
interessiert mich schon lange.)
Spontan würde ich sagen: Der Fehler des Terms in der inneren Klammer ist
0...1. Quadriert immer noch. Bei der zweiten Division kann er sich auf
das Ergebnis auch nur auf maximal 1 auswirken, also
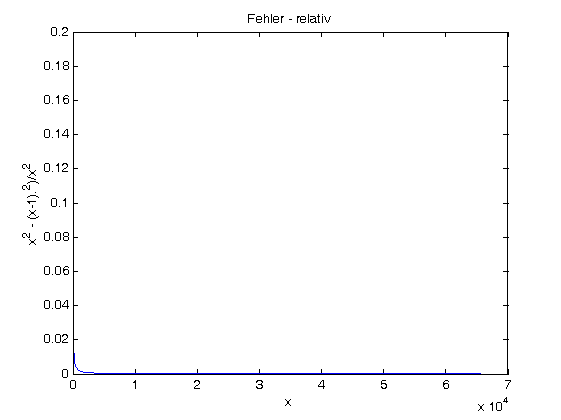
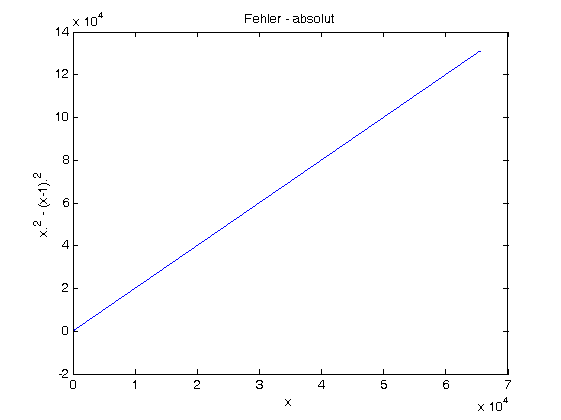
Der maximale absolute Fehler der zweiten Formel ist etwa 16711678,5
(L=2³², v=L-1, f=2²⁴-1 und a=1), der maximale relative Fehler -100%
(immer dann, wenn das exakte Ergebnis größer als 0 und das abgerundete
Ergebnis gleich 0 ist)
Bei deiner ersten Formal hält sich wenigstens der absolute Fehler in
Grenzen.
Nachtrag: Wieder ein Denkfehler. Der Fehler beim Quadrieren wächst ja
unbegrenzt an. Also habe ich keine konstante Fehlerschranke mehr,
sondern eine, die von den Einzelwerten abhängt.
Nachtrag: Hoppla, da haben wir parallel geschrieben.
Egal. Die Näherung ist auf jeden Fall ausreichend für meine Fälle.
Walter T. schrieb:> 0<f<2 hoch 24
Das sind aber nicht wirklich große Zahlen. Haben wir schon vor 25 Jahren
mit einem 56301 prozessiert. Auch auf PCs der 16 Bit Generation mit DOS
und Windows 3.1 ist das möglich, wenn man eine mathematische LIB Benutzt
hat. Die hat die Berechnungen aufgeteilt. 48 Bit breite INTs waren
damals keine Seltenheit, wenn 24er quadriert wurden. Auf einem 8 Bit AVR
ist es natürlich etwas Zeitraubend, geht aber auch.
-> binomische Formel heisst die Lösung.
Ich würde erstmal ermitteln, wie häufig die Berechnung gebraucht wird,
d.h. welche CPU-Last sich ergibt, wenn man alles in float berechnet.
Ich hab früher auch viel in Ganzzahl gemacht, um dann alle Nase lang in
Überläufe und Rundungsfehler rein zu rasseln. Das muß ich nicht haben.
Die CPUs sind heutzutage leistungsfähig genug und die Compiler-Libs sind
gut optimiert.
Da das Ergebnis maximal 16 stellen hat und keine Subtraktion vorkommt,
reicht float. Ggf rechenweg an die Grenzen anpassen. Notfalls später
zurück in int rechnen, mit 2-3 verschiedene Bereiche für x (bis 16 Bit,
24 und 32)
Walter T. schrieb:> Gibt es Tricks, wie man solche großen Integer-Rechnungen> korrekt auf den STM32 durchführen kann,
Teilweise: Ggf. ist Restklassenarithmetik einen Blick wert.
Probleme macht hierbei das Dividieren.
Andere Idee: Du spaltest die Faktoren der Formel soweit auf, dass die
Rechnung in den Zahlenbereich von 32 oder 64 Bit reinpasst, z.B.
L = Lhigh * 2^16 + Llow
Dito natürlich für die anderen Variablen.
math rulez
Cheers
Detlef
Float hat 23 Bit Mantisse (+ Vorzeichen) und kann den gesamten
Wertebereich von 24-Bit-Int und 24-Bit-unsigned-Bits ohne runden
abbilden. Wenn das Ergebnis in 16 Bit passt, habe ich tatsächlich keinen
Genauigkeitsverlust.
(Edit: Habe mich vorher unglücklich ausgedrückt und mich mit der
impliziten ersten Stelle mal wieder selbst durcheinandergebracht.)
Walter T. schrieb:> Hallo zusammen,>> ich will auf einem STM32F103 (Build-Umgebung ist der ARM-GCC none EABI,> aber auf dem PC muss die Lösung natürlich auch funktionieren) relativ> häufig eine Integer-Berechnung der folgenden Form durchführen
Solange Flash und RAM dafür ausreichen, würde ich dafür eine bewährte
Lösung nehmen. Da gibt es ja nun etliche Bibliotheken für:
https://en.wikipedia.org/wiki/List_of_arbitrary-precision_arithmetic_software
Hi,
ich habe das Problem in 32Bit Arithmetik mit gesplitteten Variablen
implementiert.
Das ist sicher nicht fehlerfrei, deswegen hab ich das auch nicht
getestet.
So funzt das ohne float und langer integer Arithmetik.
Cheers
Detlef
uint32_t x;
uint32_t f;
uint32_t a;
uint64_t L;
/* x*f , x <=2^31, f <= 2^24 */
/* (xhigh*2^16 + xlow )*(fhigh*2^16+flow) =
xhigh*fhigh*2^32 + xhigh*flow*2^16 + xlow*fhigh*2^16 +xlow*flow */
#define xhigh (x>>16)
#define xlow (x & 0xffff)
#define fhigh (f>>16)
#define flow (f & 0xffff)
/* jetzt x*f/L , l <= 2^32 , 33 Bit also passt das nur in 64 Bit
Variable, wahrscheinlich ein Fehler, aber egal */
/* zweigeteilt, um 32Bit Arithmetik zu nutzen
x*f/L = x*f/(2*Lh) =1/2 * x*f/Lh =
1/2 * ( xhigh*fhigh*2^32 + xhigh*flow*2^16 + xlow*fhigh*2^16
+xlow*flow)/Lh =
( xhigh*fhigh/Lh*2^31 + xhigh*flow/Lh*2^15 + xlow*fhigh/Lh*2^15
+xlow*flow/Lh/2) =
(z1*2^31+z2*2^15+z3) =
(z1*2^31+z4)
*/
#define Lh ((uint32_t)(L>>1))
#define z1 (xhigh*fhigh/Lh)
#define z2 ((xhigh*flow/Lh)+(xlow*fhigh/Lh))
#define z3 ((xlow*flow/Lh)>>1)
#define z4 ((z2<<15)+z3)
/* quadrieren (z1*2^31+z4)^2 =
z1^2*2^62 + 2*z1*z4 * 2^31 +z4^2 =
(z1high*2^16+z1low)^2*2^62+(z1high*2^16+z1low)*(z4high*2^16+z4low)*2^32+
(z4high*2^16+z4low)^2
=(z1high*z1high*2^32+2*z1high*z1low*2^16+z1low*z1low)*2^62+((z1high*z4hi
gh)*2^32+(z1high*z4low+z1low*z4high)*2^16+z1low*z4low)*2^32+z4high*z4hig
h*2^32+2*z4high*z4low*2^16+z4low*z4low)
=
(z5*2^32+z6*2^17+z7)*2^62+(z8*2^32+z9*2^16+z10)*2^32+(z11*2^32+z12*2^17+
z13)
*/
#define z1high (z1>>16)
#define z1low (z1 & 0xffff)
#define z2high (z2>>16)
#define z2low (z2 & 0xffff)
#define z5 (z1high*z1high)
#define z6 (z1high*z1low)
#define z7 (z1low*z1low)
#define z8 (z1high*z4high)
#define z9 (z1high*z4low+z1low*z4high)
#define z10 (z1low*z4low)
#define z11 (z4high*z4high)
#define z12 (z4high*z4low)
#define z13 (z4low*z4low)
/* jetzt noch durch 2*a, a<2^16 teilen
Da das Ergebnis in 16 Bit passt muss man nur die sich in den unteren 33
Bit aufhaltenden Bits
berücksichtigen, das ist z10..z13
y=(z10*2^32)/2a + (z11*2^32+z12*2^17+z13)/2a
=(z10*2^31/a) + z11*2^31/a+z12*2^16/a+z13/2/a
Da das Ergebnis in 17 Bit reinpasst spielen nur die letzten
beiden Terme ne Rolle:
y= (z12/a)<<16+(z13/a)>>1
*/
#define y ((z12/a)<<16+(z13/a)>>1)
Oder ein bisschen systematischer und debugfreundlicher:
Wenn man maximal blöd rechnet haben die Zwischenergebnisse maximal
70Bit.
Dan basteln wir uns ne 3*31=93 Bit Arithmetik.
Eine Zahl wird so dargestellt:
z = zoben * 2^(2*31) + zmitte * 2^(1*31) + zunten * 2 ^ (0*31),
zoben, zmitte, zunten sind 32 Bit Zahlen.
Die 31 Bit Arithmetik und keine 32 Bit Arithmetik um die Überläufe zu
handeln.
Dann drei Routinen:
z1*z2, z1/z2 und z1+z2 unter der Annahme, dass das Ergebnis in den
Zahlenbereich passt.
Ja, das ist das Bessere.
Cheers
Detlef
Detlef _. schrieb:> Mark B. schrieb:>> Ist das Code für den Obfuscated C Code Contest? ;-)^> Nicht alles, was Du nicht verstehst, ist obsfucated ;)
Wenn man Code beim Lesen nicht versteht, dann bedeutet das in nicht ganz
seltenen Fällen, dass die Wartbarkeit des Codes eher bescheiden ist. ;-)
Mark B. schrieb:> Detlef _. schrieb:>> Mark B. schrieb:>>> Ist das Code für den Obfuscated C Code Contest? ;-)^>> Nicht alles, was Du nicht verstehst, ist obsfucated ;)>> Wenn man Code beim Lesen nicht versteht, dann bedeutet das in nicht ganz> seltenen Fällen, dass die Wartbarkeit des Codes eher bescheiden ist. ;-)
Gerade deswegen hab ich ja nochmal nachgelegt.
Ingo E. schrieb:> Der ARM-GCC unterstützt im C99 Modus doch long long int, oder irre ich> da?
Für 64-Bit-Plattformen sind das auch 128 Bit, auf den 32-Bittern "nur"
64 Bit.
Okay, ich habe Deine Argumentation mißverstanden. Aber wir sind uns
einig, dass 128 Bit mit dem ARM-GCC für Cortex M3 nicht funktioniert.
Es ist auch gut zu wissen, dass der MSVC es auch nicht macht.
Auf ia64 mit dem GCC sollte es funktionieren, aber das ist an dieser
Stelle nicht weiter wichtig.
Wie gesagt ist man nicht auf die Wortbreiten der "eingebauten"
Datentypen begrenzt. Dafür gibt es ja eben die oben genannten
SW-Bibliotheken. Freilich ist die Frage, wieviel Speicherplatz man dafür
braucht und wieviel man zur Verfügung hat.
sagt mal..
Wir sind uns doch einig, dass ne 64-bit Integer auf dem STM3 kein
Problem darstellt, oder?
hat schonmal jemand über modulare arithmetrik nachgedacht?
man kann den term doch beliebig in eine Addition modular-arithmetrischer
Teile aufspalten,
und jeweils nur einer davon wäre im zweifel ein ganzzahliger Bruch,
die anderen beiden eine banale (deutlich kleinere) Integer
so wird zu keinem Zeitpunkt eine Zahl erzeugt die nicht in 64bit passt.
Speichertechnisch reichen zwei 64bit variablen zusätzlich,
(eventuell reicht sogar eine.. muss ich mal ausprobieren)
ICh versteh also ehrlich gesagt grade nicht so richtig,
wo hier das grosse Problem liegt, ja man braucht ne handvoll
Zwischenschritte,
klar, aber auch nicht genug um es nciht zu versuchen ;)
'sid
Mark B. schrieb:> Welcher Vollidiot vergibt hier eine negative Bewertung für einen> technisch absolut korrekten Beitrag? :-(
Darüber regst du dich noch auf? Passiert
doch ständig in diesem Forum.
merciless
Fehlerrechnung. Wenn du rundest, tust du so als wenn du genau Rechnest
aber ein Epsilon dazuaddierst. Damit rechnest du dann weiter.
Also:
Eps^2/2a ist jetzt eher klein. Da L>x, ist dein maximaler Fehler etwa
f/a+1. Je nachdem wie L und x sind aber deutlich kleiner.
Erweitert mit 2^8:
Der Dominante Term ist also um den Faktor 1/256 kleiner geworden. Der
mit eps^2 ist quasi weg (war ja aber auch vorher höchstens 1/2 und damit
nur im Ausnahmefall interessant)
Den schlimmsten absoluten Fehler bekommst du mit:
Nach der ersten Methode also etwa 2^23, nach der zweiten Methode 2^15.
Bei nem Ergebniss von 2^47 sind aber beide Fehler relativ gesehen nicht
so wild.
Den schlimmsten relativen Fehler zu finden, lasse ich als Hausaufgabe...
Anmerkung 1: Eps ist zwischen 0 und 1, in der Rechnung habe ich jetzt
einfach 1 eingesetzt. Das ist nicht ganz richtig, man wird aber schon
Zahlen in der Größenordnung finden, wo das nicht ganz daneben ist. Es
ist eine Abschätzung, die kleinen Terme hab ich auch unter den Tisch
fallen lassen.
Anmerkung 2: Du schreibst y sei < 2^16. Das wird sich bei deinen
praktischen Zahlen evtl. ergeben, deine Beschränkungen für xfLa geben
das nicht her.
edit Irgendwie hab ich beim Binomi eine zwei Vergessen gehabt. Ich
hoffe jetzt ist alles korrigiert.
Hat noch keiner an die Methode “Rechenschieber” gedacht?
Also alles erstmal logarithmieren und das Ergebnis nachher
de-logarithmieren?
Kann das vielleicht helfen mit Werte Bereichen und Darstellung der
Zahlen?
Blubb schrieb:> Hat noch keiner an die Methode “Rechenschieber” gedacht
Im Prinzip ist float das Prinzip Rechenschieber (Exponnent + n
signifikante Stellen). Nach den hilfreichen Hinweisen von PeDa und achs,
dass mit float hier aufgrund des Wertebereichs des Ergebnisses keinerlei
Genauigkeitsverlust verbunden ist (manchmal sieht man den Wald vor
lauter Bäumen nicht), ist es auch in float implementiert. Ich wollte nur
nicht die Diskussion abwürgen, die auch darüber hinaus interessant
geblieben ist.
Walter T. schrieb:> ist es auch in float implementiert.
Und hast Du mal ermittelt, wie oft je ms diese Berechnung benötigt wird?
In der Regel sollte der Compiler ein x² zu x*x optimieren.
Walter T. schrieb:> Nach den hilfreichen Hinweisen von PeDa und achs,> dass mit float hier aufgrund des Wertebereichs des Ergebnisses keinerlei> Genauigkeitsverlust verbunden ist (manchmal sieht man den Wald vor> lauter Bäumen nicht), ist es auch in float implementiert.
Das ist nicht allgemein richtig. Kann aber gut sein, dass es bei dir
nicht relevant ist. Ich guck mal, ob ich später noch die Float
Fehlerrechnung machen kann.
Aber wenn x und L schon größer sind als das, was float ohne runden
Darstellen kann ist klar, dass dein Ergebniss auch Fehler enthalten
(können) muss. Oder hast du doch double genommen?
Woher kommt jetzt eigentlich, dass es am Ende in 16 Bit passt?
Mathias M. schrieb:> Aber wenn x und L schon größer sind als das, was float ohne runden> Darstellen kann ist klar, dass dein Ergebniss auch Fehler enthalten> (können) muss. Oder hast du doch double genommen?
Da das Ergebnis in 16 Bit passt, interessiert nur noch, ob beim
Exponenten ein Überlauf passiert. Die Mantisse mit 22 Bit ist in jedem
Fall ausreichend.
Probleme kann es nur geben, wenn Subtraktion dazu kommt. Alle
Multiplikikationen/Divisionen, Logarithmen, Potenzen, Wurzeln etc.
spielen keine Rolle.
Weil jemand den Rechenschieber-Vergleich gebracht hat: Der kapituliert
auch nur bei der Subtraktion (weil der Exponent beim Rechenschieber
ausgelagert ist und damit beliebig viele Stellen hat)
Peter D. schrieb:> Und hast Du mal ermittelt, wie oft je ms diese Berechnung benötigt wird?
Zehnmal. Es gibt also keinen Anlass, das auf Gedeih und Verderb
tozuoptimieren.
Peter D. schrieb:> In der Regel sollte der Compiler ein x² zu x*x optimieren.
Das wollte ich mir noch angucken, ob ein powf(x,2) und ein x*x im
Assembler aufs gleiche hinauslaufen. Momentan ist letzteres
implementiert.
Mathias M. schrieb:> Aber wenn x und L schon größer sind als das, was float ohne runden> Darstellen kann ist klar, dass dein Ergebniss auch Fehler enthalten> (können) muss.
Wenn x und L gerundet werden, sind aber die vorderen 21 Bit des
Quotienten noch korrekt. Und ich brauche weniger als 16.
Mathias M. schrieb:> Woher kommt jetzt eigentlich, dass es am Ende in 16 Bit passt?
Das kommt aus Zufall/Systembeschränkung, wobei nicht auszuschließen ist,
dass bei einer späteren Hardware-Revision (meine private "Ariane 5")
diese Systembeschränkung nicht mehr zwangsläufig gilt. Aber mit 24 Bit
bin ich ohnehin noch sehr lange auf der sicheren Seite.
Theoretisch könnte ich auch mit Rundungsfehlern von mehreren Prozent
leben. Aber irgendwie hat man ja doch die Motivation, solche Sachen
bestmöglich zu machen - zumal dann auch die Modultests einfacher werden.
A. S. schrieb:> Probleme kann es nur geben, wenn Subtraktion dazu kommt. Alle> Multiplikikationen/Divisionen, Logarithmen, Potenzen, Wurzeln etc.> spielen keine Rolle.
Ähh das mag stimmen. Ist alles schon lange her. Danke für die
Erinnerung.
edit Ja ich ziehe meine Aussage zurück und behaupte das Gegenteil. Ich
hatte in meinem Gedanklichen Gegenbeispiel natürlich Minus mit drin...
Detlef _. schrieb:> sid schrieb:>> so wird zu keinem Zeitpunkt eine Zahl erzeugt die nicht in 64bit passt.>> Doch.>> Cheers
Ne wird nicht..
angenommen x, f, L und a sind vordefiniert wie im Eingangspost
also 31, 24, 32 und 16 bit maximal
dann hat man
1
uint64_txfj=x*f;// weil ich die variable im sinn ändere mit j
2
uint32_ty=floor(xfj/L);// der lesbarkeit halber mit pseudo funktion
3
uint32_tr=xfj%L;// der modulare rest.
4
/*
5
bis hier offensichtlich noch keinerlei Variable über 64 bit;
6
x ist max 31bit lang, f nur 24bit sind zusammen 55bit also kleiner 64 ;)
7
quadrieren ergibt y² + 2ry + r²/L²
8
da x < L ist y²< f² also maximal 48bit,
9
r ist maximal 32bit, y maximal 24bit, mit der 2 sind das 57bit
10
r²/L² ist kleiner eins IMMER, das merken wir uns nur im Kopf
11
*/
12
//weiter im Text...
13
xfj=y*(y+2*r);// die quadratur ist damit unterhalb von 64bit erledigt.
14
y=floor(xfj/(2*a));// wieder der lesbarkeit wegen ;) und nur maximal 1 daneben
15
r=xfj%(2*a);// modularer rest zum eventuellen runden
16
/*
17
hier kommt jetzt der gemerkte Rest kleiner eins von oben ins Spiel
18
in dem Fall wird er noch durch 2a geteilt ist also nur 1/(2a) maximal.
19
*/
20
y+=round((n+1)/(2*a));// und da ist das y, ohne je die 64bit zu überschreiten.
Na, war doch garnicht soo schwer, sieben Zeilen code,
eine 64bit, zwei 32bit ... ich hab leider keine Möglichkeit gefunden
sparsamer zu rechnen; aber wird schon gehen.
'sid
maximale anzunehmende Grösse für xfj ist zu keiner Zeit grösser
als bei diesem Schritt:
1
xfj=y*(y+2*r);
y ist max 24bit, r max 33bit
also 48bit + 57bit (ja addition) da kommt man immernoch nicht über die
58bit hinaus, egal wie man sich anstrengt.
(und schon da müssten die höchsten neun bit alle eins sein)
Dir fällt sicherlich auf, dass zu keinem zeitpunkt ein L² auftaucht;
eben weil der einzige Punkt an dem es wichtig wäre (r²/L²) ein Resultat
kleiner eins ausgibt, welches zu allem Überfluss noch durch 2*a geteilt
werden muss später... es wirkt sich also bei einem gerundeten
gesamtergebniss mit weniger als 1/2a aus...
im schlimsmten Fall ist r=L-1 und da r²/L² schnell wächst je grösser und
näher r und L sind addiere ich im letzten Schritt die 1/2a zum
final zu rundenden (neuen r) r/2a , eventuell macht es ja doch einen
Unterschied ;)
damit ist der Fehler garantiert kleiner 1.
ich glaub nicht, dass ich mich verrechnet hab...
also Detlef, erklär mir.. wo soll ich die 64bit überschritten haben?
'sid
sid schrieb:> Ne wird nicht..>> angenommen x, f, L und a sind vordefiniert wie im Eingangspost> also 31, 24, 32 und 16 bit maximal>> dann hat manuint64_t xfj = x*f; // weil ich die variable im sinn> ändere mit j> uint32_t y = floor(xfj/L); // der lesbarkeit halber mit pseudo funktion> uint32_t r = xfj%L ;
Ich habe mir die Rechnung jetzt nicht angeschaut, aber Du musst ja nicht
nur den Überlauf, sondern auch den Unterlauf berücksichtigen: Also dass
bei y durch die Division die signifikanten stellen nicht unter 16
rutschen. ISt das überall gewährleistet? also z.B. dass xfj wirklich
100.000 mal größer ist als L?
A. S. schrieb:> Ich habe mir die Rechnung jetzt nicht angeschaut, aber Du musst ja nicht> nur den Überlauf, sondern auch den Unterlauf berücksichtigen: Also dass> bei y durch die Division die signifikanten stellen nicht unter 16> rutschen. ISt das überall gewährleistet? also z.B. dass xfj wirklich> 100.000 mal größer ist als L?
Muss doch nicht..
also sowas gehässiges wie L=1 könnte y in den Überlauf zwingen,
und es müsste ebenfalls eine 64bit variable sein...
die Frage ist nur.. wie wahrscheinlich trifft das zu?
immerhin ist L in jedem Fall grösser als x
und f maximal 24bit
-so jdf lauten die Vorgaben-
also ist der extremste Fall (x*f)/(x+1)
und mein Gefühl sagt mir mit nem 24bit f wird das Ergebniss nie grösser
als besagte 24 bit
unterlauf gibt's da keinen nennenswerten
ist xfj *10000 = L (also zehntausendmal kleiner)
dann ist y ( floor(xfj/L) ) halt 0,
demnach 2ry auch
und es bleibt bei r/L kleiner eins (r ist dann xfj um genau zu sein)
im zweiten schritt wird xfj, y und r jeweils Null
und der letzte Schritt rechnet nur
1/(2*a) und spuckt das gerundet aus,
was in der Tat zu nem Rundungsfehler führen könnte,
denn das Ergebniss könnte 1 lauten obschon es 0 sein müsste.
(sofern x*f < L/2 gewesen wäre)
eine Abweichung von 1 für ein gerundetes ganzzahliges Ergebniss einer
dezimalzahl halte ich allerdings für "zu ertragen" ;)
falls man dem widerspricht (legitimerweise)
kann man aber mit einer zusätzlichen boolean und einer weiteren Zeile
korrigieren
man muss sich ja nur nach schritt zwei merken ob y > 2 war oder nicht
und danach entscheiden ob man im letzten Schritt 1/(4*a) rechnet um zu
kompensieren, sofern y null ist.
die wahren Probleme kommen erst bei L oder a gleich NULL
(divisionbyzero und so ;))
aber das war ja nicht die Frage.
Wie gesagt ich halte das Problem für kein wirkliches,
ich sehe - mit den im Eingangspost gemachten Vorgaben -
kein Problem darin das relativ schnell, relativ genau zu errechnen
(wie gesagt, maximal +1 Rundungsfehler für ein ganzzahliges Ergebniss)
Vielleicht übersehe ich in der Tat etwas,
das war ja nur aus der Hüfte geschossen,
aber Über/Unter-lauf sehe ich nicht als problematisch an bei meinem
Rechenweg.
vllt wenn Du mir ein Beispiel nennst bei dem Du vermutest dass es nicht
klappt?
ich bin ehrlich gesagt grade zu faul das mal zu compilieren um alle
werte durchzuorgeln um zu sehen bei welchen es klemmen könnte,
aber wie gesagt innerhalb der genannten Vorgaben seh ich dank x< L keine
Chance wahrhaft daneben zu liegen #schulterzuck
'sid