

Hallo, Ich habe einen fertigen Code ( https://learn.adafruit.com/standalone-avr-chip-programmer/overview ), der unter anderem Hexcode aus ausliest und zyklisch in einen 128 Byte pagebuffer schreibt, der dann in den Flash eines ATTiny85 geschrieben werden soll. Da der Code aber Fehlermeldungen auswarf, habe ich mir den Hexcode angeschaut und mit einem "ähnlichen" (selbes Projekt) verglichen. Das Problem ist, dass jeweils die 5. Zeile vor dem Ende eine geringere Anzahl an Bytes enthält. Das ist in dem Adafruit-Code aber anscheinend nicht abgefangen... Weiß also jemand, warum bei beiden Dateien bei gleicher Zeilenposition vom Code-Ende diese "Anomalie auftritt? Und kann man im AtmelStudio die Generierung des Codes evtl. beeinflussen, dass alle Zeilen mit 16 Bytes aufgefüllt werden?
Angehängte Dateien:
-

HexFileComparison.png
51 KB -

HexFileComparison_2.png
31 KB
Prinzipiell darf ein Hex-file so aussehen. Wenn das Ziel damit nicht klar kommt, ist das Problem dort. Glaub ich aber auch nicht, Hex-Files einlesen ist Pipikram.
Johannes H. schrieb: > Das Problem ist, dass jeweils die 5. Zeile vor dem Ende eine geringere > Anzahl an Bytes enthält. Schätzungsweise endet an dieser Stelle eine section im ELF-File, die Daten der nächsten belegen dann eine neue Zeile im Hex-File. Vermutlich ist der Bereich bis zu dieser Zeile Programmcode, während danach die Initialisierungsdaten für .data kommen. Die werden später vom Startup-Code aus dem Flash in den RAM kopiert.
Johannes H. schrieb: > Weiß also jemand, warum bei beiden Dateien bei gleicher Zeilenposition > vom Code-Ende diese "Anomalie auftritt? Weil der File so erzeugt wurde. Wenn das Flash-Programm damit nicht zurecht kommt, ist es evtl. nicht für das Intel Hex Format geeignet. https://de.wikipedia.org/wiki/Intel_HEX
Es wird zwar meist von "Anfang" bis zum "Ende" geschrieben, aber das ist kein MUSS. Ob er Empfänger damit klar kommt ist eine andere Sache. Bei einem zeilenorientierten Format: [Adresse] ... [Prüfsumme] und einem Computer der das lesen muss, ist das aber egal.
Johannes H. schrieb: > [...] > Da der Code aber Fehlermeldungen auswarf, habe ich mir den Hexcode > angeschaut und mit einem "ähnlichen" (selbes Projekt) verglichen. Was sind denn die Fehlermeldungen? > [...]
Theor schrieb: > Was sind denn die Fehlermeldungen? Ich frag mich ja auch immer: was genau geht eigentlich in den Köpfen von Leuten vor, die von irgendwelchen Fehlermeldungen erzählen, aber nicht auf die Idee kommen, daß die irgendwas mit dem Problem zu tun haben könnten, und daß die insofern wichtig zur Fehlerermittlung sein könnten. Vielleicht kann der TO als Vertreter dieser Spezies ja mal ein Licht drauf werfen.
Nop schrieb: > Vielleicht kann der TO als Vertreter dieser Spezies ja mal ein Licht > drauf werfen. Scheint in der Natur des Menschen zu liegen. Als mein Sohn anfing zu programmieren, kam er auch immer mal wieder zu mir rüber: "Da gibt es einen Fehler." – "Welchen denn?" – "Hab' ich mir nich gemerkt, muss ich nochmal gucken gehen."
Johannes H. schrieb: > Ich habe einen fertigen Code ( > https://learn.adafruit.com/standalone-avr-chip-programmer/overview ), > der unter anderem Hexcode aus ausliest und zyklisch in einen 128 Byte > pagebuffer schreibt, der dann in den Flash eines ATTiny85 geschrieben > werden soll. > Da der Code aber Fehlermeldungen auswarf, habe ich mir den Hexcode > angeschaut und mit einem "ähnlichen" (selbes Projekt) verglichen. > Das Problem ist, dass jeweils die 5. Zeile vor dem Ende eine geringere > Anzahl an Bytes enthält. > Das ist in dem Adafruit-Code aber anscheinend nicht abgefangen... Bahnhof (erstmal). Ich und weitere kennen sich mit Arduino nicht so recht aus. Durch die CRLF vermute ich, dass es über einen Bootlader mit einer ser. Schnittstelle in den MC programmiert wird. Das kann kein reiner HEX-Code sein.
Beitrag #6540433 wurde vom Autor gelöscht.
Angehängte Dateien:
-

SerialOutput.png
3,7 KB
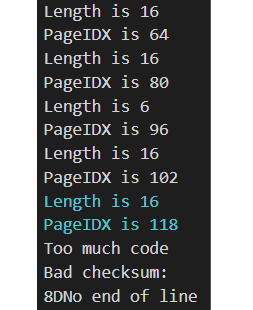
Danke für die erläuternden Antworten. Also die Fehlermeldung über die serielle Schnittstelle siehe Anhang. Es sollen ab PageIDX 118 noch 16 Byte (Bytelänge der Hexzeile) in pageBuffer[128] geschrieben werden. Und da kommt ab Index 129 dann halt "Too much Code". (Die Ausgaben "PageIDX" und "Length" sind nicht Bestandteil des Orgiginalcodes.) Die entsprechende Lesefunktion ist
1 | byte * readImagePage (...) |
aus dem Anhang. @michael_ Die Hex-Informationen werden mit dem anderen Code im Flash des Arduino-AVR abgelegt und seitenweise (128 Byte) in den Ziel-µC programmiert. Deswegen auch der Titel "Standalone". Es gibt online noch ein ähnliches Projekt von "Nick Gammon" (http://www.gammon.com.au/uploader), das werde ich mir morgen mal anschauen.
michael_ schrieb: > Ich und weitere kennen sich mit Arduino nicht so recht aus. Eine Intel-Hex-Datei hat nichts mit Arduino zu tun. Auch beim Programmieren ohne Arduino sind für den Flash-Vorgang Intel-Hex-Dateien sehr gebräuchlich. > Das kann kein reiner HEX-Code sein. Das ist eine Datei im Intel-Hex-Dateiformat und natürlich kein reiner Hex-Code, wie man unschwer an den Doppelpunkten und den CR-LF-Paaren erkennen kann. Lies erstmal hier: https://de.wikipedia.org/wiki/Intel_HEX
:
Bearbeitet durch Moderator
Frank M. schrieb: > michael_ schrieb: >> Ich und weitere kennen sich mit Arduino nicht so recht aus. > > Eine Intel-Hex-Datei hat nichts mit Arduino zu tun. Das ist aber ein Arduino-Projek! Lies erstmal hier: Johannes H. schrieb: > Ich habe einen fertigen Code ( > https://learn.adafruit.com/standalone-avr-chip-programmer/overview ), > der unter anderem Hexcode aus ausliest und zyklisch in einen 128 Byte > pagebuffer schreibt, der dann in den Flash eines ATTiny85 geschrieben > werden soll.
michael_ schrieb: >> Eine Intel-Hex-Datei hat nichts mit Arduino zu tun. > > Das ist aber ein Arduino-Projek! Frank M. schrieb: > Eine Intel-Hex-Datei hat nichts mit Arduino zu tun. !
Man sieht doch schon an der Konsolenausgabe, das das Empfangsprogramm Mist baut. Das sind eben keine 16 Bytes, die da reinkommen, sondern nur 6, wie es ja korrekt in der Intel HEX Datei steht. Die Empfangsroutine ist nun mal Bockmist. Ich verstehe ja, wenn so eine Routine nicht alle möglichen Record Typen versteht, die Intel HEX anbietet, aber die Anzahl der Bytes zu lesen, ist Pflicht.
Matthias S. schrieb: > aber die Anzahl der Bytes zu lesen, ist Pflicht Das macht sie durchaus:
1 | // Read the byte count into 'len'
|
2 | len = hexton(pgm_read_byte(hextext++)); |
3 | len = (len<<4) + hexton(pgm_read_byte(hextext++)); |
4 | cksum = len; |
Aber es scheint eine implizite Annahme darin zu geben, dass pagesize in kompletten Eingabezeilen aufgeht – zumindest ist das mein erster Eindruck vom Code. Habe nicht die Zeit gehabt, das bis zu Ende zu verstehen Es steht aber auch drüber:
1 | /*
|
2 | * Bootload images.
|
3 | * These are the intel Hex files produced by the optiboot makefile,
|
4 | * with a small amount of automatic editing to turn them into C strings,
|
5 | * and a header attched to identify them
|
6 | */
|
d.h. sie verlassen sich da wohl auf ihren Build-Prozess.
:
Bearbeitet durch Moderator
Offenbar stammt die gezeigte Fehlermeldung nicht aus dem gezeigten Code. Denn in dem Code kommt der Text "Length is: " nicht vor.
Theor schrieb: > Offenbar stammt die gezeigte Fehlermeldung nicht aus dem gezeigten Code. > Denn in dem Code kommt der Text "Length is: " nicht vor. Beitrag "Re: HexFile: Muss das so aussehen?"
1 | (Die Ausgaben "PageIDX" und "Length" sind nicht Bestandteil des Orgiginalcodes.) |
Ja, der Code sollte verbessert werden um auch mit kürzeren Records zurechtzukommen. Ein schneller Workaround unter Linux wäre: objcopy --input-target=ihex --output-target=ihex originalfile.hex neuesfile.hex
Jörg W. schrieb: > Theor schrieb: >> Offenbar stammt die gezeigte Fehlermeldung nicht aus dem gezeigten Code. >> Denn in dem Code kommt der Text "Length is: " nicht vor. > > Beitrag "Re: HexFile: Muss das so aussehen?" > >
1 | > (Die Ausgaben "PageIDX" und "Length" sind nicht Bestandteil des |
2 | > Orgiginalcodes.) |
3 | > |
Diese Bemerkung des TOs bedeutet aber m.M.n. nicht, oder nicht folgerrichtigerweise, dass der gezeigte Code die Fehlermeldung nicht enthält und das auch nicht zu erwarten ist. Eher im Gegenteil scheint es mir sinnvoll, gerade denjenigen Code zu zeigen, der die Fehlermeldung ausgibt.
Johannes H. schrieb: > Weiß also jemand, warum bei beiden Dateien bei gleicher Zeilenposition > vom Code-Ende diese "Anomalie auftritt? Weil die Ausgaberoutine deiner Toolchain das halt so macht, sie wird ihre Gründe haben. Bedenke mal, daß sowohl Intel- als auch Motorola-Hexdateien aus Blöcken bestehen. Jede Zeile ist ein separater Block. Und es gibt mehrere verschiedene Blocktypen: Datenblöcke, den Endeblock und mehrere Blöcke zum Setzen von Adreßbits, wenn der Adreßbereich > 64K ist, sowie 8086-spezifisches, z.B. den CS:IP-Block und einen Block zum Angeben eines Einsprungpunktes. Daß die Datenblöcke nicht alle gleich lang sind, ist der Normalfall. Immer dann, wenn wegen irgendwas die Speicherbelegung nicht kontinuierlich verläuft, weil z.B. eine ORG-Anweisung oder etwas Äquivalentes aufgetreten war, tritt sowas auf. Lies einfach mal nach, wie Intel-Hex aufgebaut ist, dann weißt du es selber. W.S.
W.S. schrieb: > Weil die Ausgaberoutine deiner Toolchain das halt so macht, sie wird > ihre Gründe haben. Die Details dazu schrob ich weiter oben schon, warum sie das so macht. Klobber schrieb: > Ein schneller Workaround unter Linux wäre: Das wäre jetzt der pragmatische Weg. Möglicherweise macht es auch die im Kommentar des Codes erwähnte Build-Infrastruktur so. Geht natürlich auch unter Windows, wenn man die Binutils installiert hat – und im Rahmen der AVR-Toolchain sind sie das ja. Heißt dort dann nur "avr-objcopy" [.exe].
Jörg W. schrieb: > Aber es scheint eine implizite Annahme darin zu geben, dass pagesize in > kompletten Eingabezeilen aufgeht So ist es. Die Abbruchbedingung der Schleife für den OK-Fall sieht so aus:
1 | if (page_idx == pagesize) |
2 | break; |
Bei der Zeile mit sechs Datenbytes wird das noch nicht erreicht, aber die nächste Zeile würde dann schon zu einer anderen 128-Byte-Page gehören. Sprich, die Empfangsroutine ist ein Fehldesign. Sie kommt mit Lücken im Hexfile nicht zurecht, und sie würde auch versagen, wenn man ein kontinuierliches Hexfile mit z.B. 17 Datenbytes pro Zeile bauen würde.
Nop schrieb: > Sprich, die Empfangsroutine ist ein Fehldesign. Sie scheint halt für genau den Zweck designt worden zu sein, der im Kopfkommentar genannt worden ist. Wenn man weiß, dass davor eine Toolchain sitzt, die sowieso immer 16 Daten-Bytes pro Zeile ausgibt, braucht man natürlich keinen Aufwand zu spendieren, andere Fälle abzuhandeln. (Kostet ja auch Platz im Flash.) Allerdings könnte sie dann natürlich sinnvollerweise auch gleich beim ersten Datensatz != 16 Byte spucken und aufhören.
Jörg W. schrieb: > Wenn man weiß, dass davor eine > Toolchain sitzt, die sowieso immer 16 Daten-Bytes pro Zeile ausgibt, > braucht man natürlich keinen Aufwand zu spendieren, andere Fälle > abzuhandeln. (Kostet ja auch Platz im Flash.) Dann kann man sich die Auswertung der Zeilenlänge aber auch sparen und spart gleich noch mehr Flash. Immerhin geht es nicht nur mit 16, sondern mit jeder Zweierpotenz kleiner gleich 128 (wobei das Intel-Hex-Format nur bis 32 erlaubt).
Nop schrieb: > (wobei das Intel-Hex-Format nur bis 32 erlaubt). Korrektur: doch, es geht mehr, solange der Bytecount pro Zeile nicht mehr als 255 ist.
Nop schrieb: > Dann kann man sich die Auswertung der Zeilenlänge aber auch sparen und > spart gleich noch mehr Flash. Hatte ich mir auch gedacht. ;-) Sauberer wäre es natürlich schon, den Kram so aufzuräumen, dass er mit beliebigen Zeilenlängen zurecht kommt.
Jörg W. schrieb: > Nop schrieb: >> Sprich, die Empfangsroutine ist ein Fehldesign. > Sie scheint halt für genau den Zweck designt worden zu sein Ja, "hingebastelt" halt. Ich habe früher auch schon mal so einen fehlerhaften Parser für IHex-Dateien geschrieben. Dabei hatte ich mich drauf verlassen, dass ab Anfang der Datei der Adresspointer mit jeder Zeile immer nur größer wird. Und bin dann auf die Nase gefallen, als nach einem Linkerupdate die Interruptvektoren (ab Adresse 0) auf einmal am Schluss angefügt wurden... ;-) Jörg W. schrieb: > Sauberer wäre es natürlich schon, den Kram so aufzuräumen, dass er mit > beliebigen Zeilenlängen zurecht kommt. Und schlimmstemfalls sogar mit beliebiger Zeilenreihenfolge. Denn so machen es "übliche" kommerzielle Brenner: sie laden die komplette IHex Datei als Image in ihren Speicher und brennen dann Byte für Byte (Sektor für Sektor) in den angeschlossenen Baustein.
Lothar M. schrieb: > Denn so machen es "übliche" kommerzielle Brenner: sie laden die > komplette IHex Datei als Image in ihren Speicher und brennen dann Byte > für Byte (Sektor für Sektor) in den angeschlossenen Baustein. So viel RAM wird man auf einem kleinen AVR nicht haben, dass man x-beliebig kreuz und quer durch die Adressen hüpfen kann. OK, man könnte sich damit behelfen, bei noch nicht vollständig gefüllten Pages einfach den Rest mit 0xFF zu füllen (wird ja auch schon gemacht), dann kann man die Page "vorab" bereits rausdumpen. Falls später für die gleiche noch was kommt, muss man die existierende einlesen und aktualisieren. Allerdings muss man sich dann eine Bitmap mitmeißeln, in der steht, welche Pages man bereits einmal gelöscht hatte, sonst würde man sie später nochmal löschen wollen. Insgesamt also doch einiges mehr an Aufwand. Linear aufsteigende Adressen über Page-Grenzen hinweg zu puffern, ist aber nicht ganz so viel Arbeit.
Lothar M. schrieb: > sie laden die komplette IHex > Datei als Image in ihren Speicher und brennen dann Byte für Byte Das tun sie i.A. nicht, jedenfalls nicht bei normalen EProms u.ä. Speichern: sie legen im Speicher eine Datei in der Grösse des Roms an und wenn man ein Hex-, Binär- oder sonstiges File einliest verfrachten sie die Daten an die angegebene Adresse (die man bei Binär wohl oder übel selber angeben muss). Das können beliebige Daten sein, solange sie in den durch die Bausteinauswahl vorgegeben Adressraum passen, neues Einlesen überschreibt im Zweifelsfall schon vorhandene Daten. Man kann also ohne weiters einen Programmcode aus einem Intel-Hexfile laden und danach eine Datentabelle aus einem Binärfile. Deshalb ist es auch wichtig, dass Daten aus einem Hex-File dahin geladen werden wo es die Adresse und die Länge angibt, und wenn es sich um ein einziges Byte handelt. Immerhin gibt es Intel-Hex wohl schon 50 Jahre oder so, das sollte also inzwischen bekannt sein. Georg
Georg schrieb: > Das tun sie i.A. nicht, Ähem, naja... Bei meinen Brennprogrammen (am PC) mache ich das so, merke mir aber, welche Bytes tatsächlich vom Hexfile belegt sind und welche nicht. Danach wird der Reihe nach das so erzeugte Binärfeld in den Chip geschrieben - unter Auslassung der eventuellen Lücken. Der Grund ist, daß es manche Chips nicht vertragen, ein Byte zweimal zu brennen. Ist aber selten geworden heutzutage. Dennoch vereinfacht das Verfahren, über einen programminternen Pufferbereich zu gehen, das Procedere gar sehr. Man kann gleichermaßen bin, intel-hex Motorola oder sonstwas als Input implementieren. Aber für irgendwelche kleinen µC ist es ohnehin nicht die beste Wahl, einen Bootlader so zu schreiben, daß er ein Standard-Hex versteht. Die Leute denken zwar, daß es das Einfachste sei, aber es ist nur das Gedankenloseste. Natürlich muß man einen Block zuerst komplett lesen, um auch die Prüfsumme zu kriegen. Dafür muß dann der nötige RAM da sein. Kommerzielle Bootlader machen es anders. Man schaue mal, was z.B. ein Bootlader bei den hier beliebten STM32 an Input haben will. W.S.
W.S. schrieb: > Dafür muß dann der nötige RAM da sein. Da ihex auf 255 Bytes pro Zeile limitiert ist, sollte das nicht so das große Problem sein, außer auf ganz kleinen MCUs. Auf denen will man natürlich wirklich einen Bootloader haben, der minimalistisch ist.
Georg schrieb: > Immerhin gibt es Intel-Hex wohl schon 50 Jahre oder so Naja, ganz so lange wohl denn doch nicht, einige wenige Jährchen fehlen noch. Davor war das 466-Lochband-Format. Der Bootlader dazu war nur so ungefähr 30 Worte lang, im Rückblick schon beeindruckend. Dieses Format wurde erst Ende der 70er Jahre so langsam obsolet und durch TAR ersetzt. Das war die Zeit, wo man nicht mehr direkt in den Kernspeicher ludt, sondern wo man Dateien per Betriebssystem hatte. W.S.
Georg schrieb: > sie legen im Speicher eine Datei in der Grösse des Roms an So meinte ich das. Und deshalb ist die Reihenfolge der Zeilen in der IHex-Datei insofern völlig uninteressant, als das natürlich das, was zuhinterst in der Datei kommt oder gar das, was danach aus einer anderen Datei noch geladen wird, die jeweils vorherigen Daten überschreibt. Das können auch einzelne Bytes oder Worte sein. W.S. schrieb: > Aber für irgendwelche kleinen µC ist es ohnehin nicht die beste Wahl, > einen Bootlader so zu schreiben, daß er ein Standard-Hex versteht. Richtig: der IHex-Parser samt korrekter Fehlerbehandlung gehört auf den PC. In Richtung µC werden von dem dann nur immer gleich große Blöcke auf die immer gleiche Art mit immer gleicher Prüfung übertragen.
W.S. schrieb: > Naja, ganz so lange wohl denn doch nicht, einige wenige Jährchen fehlen > noch. Zwei Jährchen etwa. HEX stamnt aus 1973. Insoweit passt "50 Jahre oder so" recht gut.
:
Bearbeitet durch User
michael_ schrieb: > Das kann kein reiner HEX-Code sein. Blitzmerker Wolfgang schrieb: > https://de.wikipedia.org/wiki/Intel_HEX
Lothar M. schrieb: > In Richtung µC werden von dem dann nur immer gleich große Blöcke... Dann ist die einzig mögliche Blockgröße 1 Byte bzw. Wort (je nach µC Typ). Schließlich kann niemand davon ausgehen, daß der Umfang einer Firmware ein exaktes Vielfaches einer Blockgröße > 1 ist. W.S.
W.S. schrieb: > Dann ist die einzig mögliche Blockgröße 1 Byte bzw. Wort (je nach µC > Typ). Oder halt pagesize, wenn man sowieso in einer solchen programmieren muss (weil die Hardware das so will). Falls weniger zu programmieren ist, fügt der Absender 0xff zum Auffüllen an. Aber das sind doch alles schon gelöste Probleme, es gibt Bootloader wie Sand am Meer (auch solche, die bspw. STK500-Protokoll sprechen und daher wie ein STK500 vom Host aus angesprochen werden können). Wenn ich mir den einleitenden Kommentar dieses Teils hier durchlese (irgendwie wird die Firmware in Hexfiles in C-Strings abgelegt ...), dann scheint das sowieso etwas ziemlich exotisches zu sein, warum auch immer.
Der Thread ist ja richtig in Tech-Talk ausgeartet 😅 Mit meiner recht überschaubaren Programmiererfahrung, was wären eure Tipps um diese Leseroutine zu verbessern und flexibler zu machen? Mein Ansatz: Wenn der pageBuffer voll ist, müssten die verbliebenen Bytes einer Hex-Zeile in eine neue Page geschrieben werden und dafür die initiale Suche nach dem ':' für die Anzahl dieser Bytes übersprungen werden.
Johannes H. schrieb: > Mein Ansatz: Wenn der pageBuffer voll ist, müssten die verbliebenen > Bytes einer Hex-Zeile in eine neue Page geschrieben werden D.h. du musst die aktuelle Page schreiben und den Pagebuffer wieder leeren (0xFF). > und dafür die > initiale Suche nach dem ':' für die Anzahl dieser Bytes übersprungen > werden. Nein, die nachfolgenden Bytes musst du natürlich schon berücksichtigen. Die Struktur deines Hexfiles da oben bedeutet, dass es ab der einen Zeile dann eben nicht mehr so ausgerichtet ("aligned") ist, dass man es 1:1 auf eine Page abbilden kann. Das Hexfile musst du aber trotzdem in kompletten Zeilen abarbeiten, denn nur so kannst du verifizieren, dass die Prüfsumme am Ende der Zeile auch passt. Die Bytes, die nicht mehr in die bisherige Page passen, musst du dann an den Anfang des Pagebuffers kopieren. Der nächste Lesevorgang aus dem Hexfile setzt dann dahinter fort (das passt dahingehend schon, dass der Index in den Puffer ohnehin aus der Adresse aus dem Hexfile gebildet wird).
Jörg W. schrieb: > Die Bytes, die nicht mehr in die bisherige Page passen, musst du > dann an den Anfang des Pagebuffers kopieren Ich verstehe nicht, wieso man nicht eine Zeile mit Länge, Adresse und Prüfsumme komplett verarbeiten soll, und dann die nächste usw. Was soll der Vorteil daran sein, die Zeilen in Stücke zu zerteilen? Georg
Georg schrieb: > Was soll der Vorteil daran sein, die Zeilen in Stücke zu zerteilen? Wenn du den Flash in Pages programmieren musst (weil das die Hardware so will), dann kannst du eben nicht einfach stur zeilenweise nach dem Intel-Hex-File durchgehen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.