Hier nun meine neue Version des VCP mit Header Files für usb1.1 und
vcp1.2. Das ganze ist noch nicht 100% ausgereift, funktioniert aber als
Replacement für usb.c. Im Quelltext hab mal ein paar Stellen mit todo
markiert, die ich noch für buggy halte.
Noch entspricht das Endpoint Management dem Original, d.h. die
bidirektionalen sind noch nicht implementiert.
Die entgültige Version werde ich dann vermutlich in Projekte & Code
einstellen.
Mal noch ein paar Anmerkungen meinerseits:
uint16_t UsbSetup(void)
Ein int würde ausreichen, da in diesem Treiber niemals etwas anderes als
0 zurückgegeben wird. Wahrscheinlich täte es ein bool auch. Das ganze
ist ne historisch gewachsene Altlast und wenn du ohnehin erhebliche
Änderungen machst, dann wäre mMn ein bool oder gar ein void eher
angebracht.
volatile bool receiving = false;
volatile bool transmitting = false;
Sowas setzt die Vorbelegung des RAM im Startup voraus. Ich würde die
beiden Flags schlichtweg in UsbSetup auf null setzen, dann kann der
Startup tun oder lassen, was er will. Ist mal wieder eine Fehlerquelle
weniger.
void UsbStrOut(char* S)
Schmeiß es lieber ersatzlos raus. Ich hatte mich schon vor Jahren
darüber geärgert, daß ich es überhaupt mal dort hineingesetzt hatte.
Hab's dann nur der Kompatibilität zuliebe drin gelassen.
/* holt ein Zeichen vom USB ab */
/* Achtung: wenn nix abzuholen ist, wird 0 zurückgeliefert */
char UsbGetChar(void)
{ char c;
c = 0;
if (!configurationSet || suspended)
{ return -1;
...
Naja, return 0 wäre mMn eher passend. Ist ja ein 8 Bit Char.
Und in UsbGetChar()
... if (!receiving)...
Wenn das denn schon im Usercode-Bereich behandelt werden soll, dann
kommt mir dabei der kühne Gedanke, auf den Ringpuffer in Richtung
PC-->µC ganz und gar zu verzichten. Immerhin haben wir ja Bulk_Out_A und
Bulk_Out_B zum eventuellen Umschalten, wenn man sich diese Mühe machen
will. Vorbereitet ist das alles schon seit langem, ich hatte es bloß
damals nicht benutzt, weil ich eben nicht wollte, daß der Usercode in
den Innereien des USB-Interrupts herumfuhrwerkt, sondern daß der
Usercode sich eben damit begnügt, im zuständigen Ringpuffer
nachzuschauen, ob's was gibt oder nicht.
W.S.
W.S. schrieb:> Mal noch ein paar Anmerkungen meinerseits:
Danke, einiges was du aufzählst ist mir selbst schon aufgefallen.
Momentan arbeite ich nur am USB Teil.
Am Usercode bzw Buffer Code ist alles noch original zu der Version von
Stefan.
Im Moment stelle ich gerade die beiden Bulk EPs so um, dass Sie beide
auf EP1 liegen.
Im Endausbau soll das dann so sein, das es bis zu 4 VCPs gibt VCP 1 wie
gehabt, die restlichen auf ser. Schnittstellen umgeleitet.
Thomas Z. schrieb:> Im Endausbau soll das dann so sein, das es bis zu 4 VCPs gibt VCP 1 wie> gehabt, die restlichen auf ser. Schnittstellen umgeleitet.
Bist du sicher, daß man das tatsächlich braucht?
Nicht alles, was man können kann, muß man auch tatsächlich tun.
Sinn und Zweck der ganzen Übung war ja ursprünglich, daß man an seinem
µC eine Serielle per USB hat, um darüber mit dem PC kommunizieren zu
können. Da reicht eine Serielle völlig aus.
Und ich hatte auch drauf achten wollen, daß der Treiber nicht unnötig
umfänglich wird, damit auch diejenigen, die IAR oder Keil bis jeweils
32K benutzen, noch genug Flash haben für ihr eigentliches Zeugs.
Vorschlag: Mach ruhig deine Vollst-Version, aber mach auch gleich drauf
eine wieder abgespeckte Version nur für das Nötigste.
W.S.
W.S. schrieb:> Vorschlag: Mach ruhig deine Vollst-Version, aber mach auch gleich drauf> eine wieder abgespeckte Version nur für das Nötigste.
Na ja meine Idee ist es konfigurierbar zu machen im einfachsten Fall ist
es dann funktionsgleich zum Original.
Das ist auch gleichzeitig meine Spielwiese um mit der ST Peripherie warm
zu werden.
Ich habe jetzt die bidirektionalen BulkEps eingebaut und auch sonst
einiges umgestellt. Noch ist der Code funktionsgleich zum Original,
wobei ich die Kopier Funktionen von und zum usbmem etwas verändert habe.
Es wäre gut wenn das jemand auf einem Controller gegenchecken kann der
UMEMSHIFT=0 benötigt. Ich habe nur auf den BluePills getestet.
Der code ist momentan sogar etwas kleiner als das Original. Noch nicht
imlementiert, aber vorbereitet ist der mehrfach VCP.
Usb2CV läuft ohne Fehler durch, im Moment funktioniert
SetConfiguration(0) noch nicht, das wird aber nur als Hinweis gemeldet.
Ich würde mich über Rückmeldungen freuen.
Thomas Z. schrieb:> Es wäre gut wenn das jemand auf einem Controller> gegenchecken kann der UMEMSHIFT=0 benötigt.> Ich würde mich über Rückmeldungen freuen.
Funktioniert auf den ersten Blick.
Danke für den Test. Dann hab ich das ja soweit richtig verstanden. Ich
hatte sowieso nur die Kopierfunktionen für EP0 geändert. Wenn ich einen
Fehler gemacht hätte, würde Enum auf dem f303 nicht mehr funktionieren.
Hallo Thomas,
ich hab gestern Abend endlich wieder Zeit gefunden, um an den Modulen
weiterzumachen. Hab deine obige Version in meinen F042 reingespielt und
hat bei mit unter Win10 funktioniert.
Auf Win7 ging es nicht, Win behauptet dass es keinen passenden Treiber
hat.
Der einzige Unterschied, den ich fand ist, dass mit der neuen Version
von dir die Hardware-ID im Gerätemanager
'USB\VID_0416&PID_5011&REV_0100&MI_00'
ist.
Mit der alten Version (usb.c. von S.F.) war das MI_00 nicht dabei.
nachdem ich auf Win7 die NuvotonCDC.inf wie folgt angepasst habe, läuft
es.
Nur falls sonst noch jemand W7 laufen hat... :-)
Ein anderes Thema hab ich leider immer noch:
Hab die Version von dir auf einem jener Module getestet, die beim
Runterschicken von Befehlen immer Probleme hatten (auf einem alten,
nicht dem mit dem ich diesen Thread gestartet hab).
Die Übertragungsprobleme hab ich damit immer noch.
Manchmal verträgt es 1-2 Befehle, aber irgendwann ist Schluss mit
Runterschicken.
Alex
Alex schrieb:> Manchmal verträgt es 1-2 Befehle, aber irgendwann ist Schluss mit> Runterschicken.
Tja, wenn ich mir all die Bemühungen anschaue, die es hier in diesem und
in anderen Threads so gegeben hat, dann stellt sich mir das
(generalisiert gesagt) etwa so dar:
1. Einführung von #ifdef's oder zusätzlichen Headern, um mit 1 Treiber
mehrere STM32Fxxx abdecken zu können. Meine Ansicht: 1 Treiber für exakt
1 Plattform gefällt offenbar manchen nicht.
2. Meine Quasi-Automatik, den Datenfluß per Timertick des USB wieder in
Gang zu kriegen, gefällt offenbar auch nicht, deswegen die Bemühungen,
dieses stattdessen von der 'userland'-Seite aus zu tun.
3. Änderungen bei Features und Status und Verhalten wenn nicht
angeschlossen, zu denen ich damals keine ausreichende Dolumentation
hatte, was aber bei mit trotzdem bislang funktioniert hatte. ( Warum
eigentlich? Sind das Dinge, die bei einer popligen Seriellen per USB gar
nicht wirklich relevant sind? )
4. Einführung von chipspezifischen Seriennummern.
5. Aufregung über die simple Verzögerungsschleife, obwohl das eigentlich
recht nebensächlich (und nur GCC-spezifisch) ist.
Naja, und der Rest ist eigentlich gleich geblieben. Nun hab ich ja schon
vor Zeiten und auch mit anderen µC so meine eigenen Tests gemacht, Daten
von wenig bis massiv in beiden Richtungen über den USB geschickt und war
damit eigentlich zufrieden. Eigentlich deshalb, weil ich vom Device aus
nicht wirklich habe feststellen können, ob auf dem PC nun irgend eine
Anwendung den seriellen Kanal geöffnet hat oder nicht - da ist eben
immer das OS mit seinem Treiberstack und der Fileverwaltung dazwischen.
Und nun geht es bei dir nach all diesen gehabten Änderungen noch immer
nicht - und noch immer weißt du nicht, woran es denn tatsächlich liegt.
Und ebenso noch immer kann jeder andere hier nur spekulieren über das,
was ihm dazu so einfällt:
- Hardwarefehler
- Firmwarefehler durch Verwendung von irgendwas (Cube und Konsorten),
das umbemerkt an irgend einer Stelle dazwischenfunkt.
- Fehler in deinem Algorithmus, die Befehle auszuwerten oder auf
unverständliche Befehle zu reagieren
- Probleme mit dem OS auf dem PC
- Irgend etwas Unbedachtes in deiner Anwendung auf dem PC
- Irgend eine Art Synchronisationsproblem zwischen PC und µC
und so weiter.
Das alles hilft hier offenbar auch bloß nicht.
Also nochmal mein Vorschlag: alles, was der µC über den USB empfängt,
auf einem anderen Kanal (z.B. UART) auszugeben und dort dann mal zu
schauen, was da so kommt.
W.S.
@Alex
dass du eine geänderte inf umter W7 braucht liegt ganz einfach daran
dass das Device nun ein Compound Device ist (wg IAD) der Treiber wird
nun nicht mehr auf das Device installiert sondern auf das Interface
(MI_00). Änderungen in der Funktionalität gibts noch keine. Es ist also
sehr unwahrscheinlich dass dies bei deinen Übertragungsproblemen hilft.
@W.S.
mir ist klar dass dir die includes bez der spec nicht gefallen. Die
machen aber letztendlich auch nichts anderes als defines im Quelltext.
Es ist bei mir halt so dass diese Header files zentral in einem Ordner
\usb liegen. Ich habe diese Dinger über die Jahre gepflegt und
erweitert, weshalb ich die immer benutze. Es gibt aber ansonsten
keinerlei Unterschied.
Die Feature Geschichte hab ich korrigiert weil deine Version einfach
nicht funktionierte (TimeOut beim Request). Ursache war der Stall(1) an
diversen Stellen. GET_LINE_CODING funktioniert übrigens auch nicht, da
du in OnEpCtrlIn() das an der falschen Stelle auswertest.
Die Feature Geschichte geht übrigens auch beim 3fach VCP von Niklas
nicht er antwortet aber korrekt mit einem STALL Handshake. Das sind aber
formale USB Geschichten. Der VCP funktioniert trotzdem.
Die einzige Sache die ich bis jetzt wirklich neu gemacht habe sind die
beiden CopyFunktionen von und USB Mem für EP0. Deshalb auch die
Testanfrage für andere MCUs.
Eine Sache noch:
Meiner Meinung nach ist die Initialisierung der EpTable[0].TxCount mit 0
falsch. (Ergibt nur einen 2 Byte Buffer)
> Also nochmal mein Vorschlag: alles, was der µC über den USB empfängt,> auf einem anderen Kanal (z.B. UART) auszugeben und dort dann mal zu> schauen, was da so kommt.
Das hatte ich ja schon mit dem Hello-World / Echo - Beispiel von S.F,
dort war der Fehler reproduzierbar.
> - Hardwarefehler
Mit Sicherheit hat es was mit bestimmten Chip-Exemplaren zu tun. Der
Fehler tritt bei manchen µCs auf, egal auf welche PCB sie gelötet sind.
> - Fehler in deinem Algorithmus, die Befehle auszuwerten oder auf> unverständliche Befehle zu reagieren
Ist durch den Echo-test ausgeschlossen
> - Probleme mit dem OS auf dem PC
Wurde bereits ausgeschlossen. Tritt auf verschiedenen PCs und OS auf
(W7, W10, Linux)
> - Irgend etwas Unbedachtes in deiner Anwendung auf dem PC
Wurde ausgeschlossen. Tritt auch in Terminalprogrammen auf.
> - Irgend eine Art Synchronisationsproblem zwischen PC und µC> und so weiter.
?
> - Firmwarefehler durch Verwendung von irgendwas (Cube und Konsorten),> das umbemerkt an irgend einer Stelle dazwischenfunkt.
Gut möglich, aber wenn ich den Codegenerator nicht anwerfe, sollte doch
nur der Code aus meinen Files verarbeitet werden, oder?
Folgende beiden Fragen stell ich mir aktuell:
Nachdem ich ja mit wireshark schon rausgefunden habe, dass es immer dann
auftritt, wenn auf ein Bulk_out -Paket keine Antwort von STM kommt:
a) Werden diese Antwortpaket vom STM in Hardware erzeugt, oder macht das
die usb.c?
b)
Thomas schrieb am 22.2.:
> Dann gibt es einen Bug beim Get/SetFeature bzw GetStatus liefert nicht> das erwartete Ergebnis. (STALL oder 0).
Hier wurde ja kein relevanter Bug gefunden, oder?
Alex
Alex, hast du mal den originalen Code von 2015 ausprobiert? Ich denke
das wäre ein einfacher Schritt und damit würdest W.S. auch wieder
einfangen, so dass er möglicherweise mehr Lust hat, dir zu helfen,
anstatt die Anderungen zu kritisieren.
Siehe Beitrag "Re: STM32 USB Übertragungsproblem mit Code von S.F.", da
habe ich seine originale Variante als Cube IDE Projekt angehängt.
Alex schrieb:> Folgende beiden Fragen stell ich mir aktuell
Also, wenn ich mich recht erinnere, dann wird bei meinem Original beim
EpBulkOut solange der Puffer nicht geleert, bis dessen Inhalt in den
Ringpuffer hineinpaßt. Was soll der Treiber auch anderes machen? Egal
was man sich ausdenkt, es kommt immer die Situation, wo der Host einen
mit Daten vollpflastert, die dann eben warten müssen, bis sie von der
Anwendungsschicht der Firmware abgeholt werden (und wann das sein wird,
kann der Treiber nicht wissen).
Das ist sozusagen das Gegenstück zu der Situation beim Bulk-In, wo man
selber zusehen muß, daß man bei anstehenden Daten im Ringpuffer den
EpBulkIn befüllen und damit den ganzen Transfer in Gang setzen muß.
Nun weiß ich nicht, ob es zum Leeren des EpBulkIn-Puffers an irgend
einer Stelle eine Art Timeout gibt, so wie das beim Hängenlassen des
Timerticks passiert.
Mal ne Frage an dich: Ändert sich das Verhalten deiner Firmware, wenn du
testeshalber den Ringpuffer für die Richtung PC-->µC mal riesengroß
machst? Mir kommt da nämlich der Verdacht, daß es irgend einen
zeitlichen Stau geben mag, der dazu führt, daß für eine zu große
Zeitspanne die vom PC gesendeten Daten nicht abgeholt werden und dann
irgend ein Timeout zuschlägt, oder daß bei dem Herumschalten am
Interruptcontroller irgend etwas verloren geht. Ja, das sind auch nur
weitere Vermutungen, aber was soll man machen?
W.S.
Nachtrag: ich seh grad, daß ich oben eigentlich EpBulkOut gemeint habe,
also die Situation, wo der Puffer vom PC gefüllt wurde und man keinen
Platz hat, die Daten dort raus und woanders rein schaufeln zu können.
W.S.
Auf einem STM32F405 läuft es bei mir nicht. Prinzipiell habe ich die
Clocks genauso initialisiert wie bei den Codevarianten vom MCD-Team, und
da läuft CDC/VCP auf dem F4.
Muß noch etwas drüber grübeln, und kann meine geliebten #ifdefs leider
noch nicht reinpfriemeln :(
heulend und schluchzend
Stefan ⛄ F. schrieb:> Der STM32F4 hat ein andere USB Peripherie, darauf wird der hier> diskutierte Code niemals laufen können.
Ja, aber ... dann muß ich ja zwei verschiedene USB-Treiber für zwei
verschiedene Chips nehmen. Das wäre schrecklich :)
Muß mal den Code noch genauer anschauen, wo Registerzugriffe
stattfinden, wie und welche. Der Code vom MCD-Team war bei mir schon
ge#ifdefd und lief sowohl für den F103 und den F407 (wenn ich mich recht
entsinne).
Edit: Danke für die Beschreibung. Schmöker ich mal durch.
@ W.S.
>Mal ne Frage an dich: Ändert sich das Verhalten deiner Firmware, wenn du>testeshalber den Ringpuffer für die Richtung PC-->µC mal riesengroß>machst?
Klingt grundsätzlich plausibel, aber es tritt der Fehler ja manchmal
schon auf, wenn ich nur 'stop<crlf>' sende. Also nur 6 Zeichen (in einem
einzigen BulkOut). Die Buffer sind alle deutlich größer.
Trotzdem werd ich morgen VM kurz testen, ob die Buffergrößen einen
Einfluss haben...
Alex
@ Stefan:
den Originalen Code von W.S. 2015 hab ich nicht probiert, da ich ja
UMEM_SHIFT 0 habe und die Unterscheidung da ja noch nicht drin ist.
Und das selbst umzustricken ist sicher keine gute Idee...
Test zu den Buffergrößen:
Die Buffergröße hat keinen merklichen Einfluss.
Der Echo Test bleibt mal nach 10 chars stecken, mal nach 30.
Rx Buffer von 128 auf 512 erhöht -> keine Änderung.
Anbei mein main.c. von dem Test
Allerdings scheint es so zu sein, dass das Verhalten durch das Senden
von einem langen String auf einmal sehr zuverlässig reproduzeirbar ist.
Und zwar unabhängig von der Buffergröße.
Schicke ich
'123456789012345678901234567890<crlf>' steht der bulkOut sofort.
'1234567890<crlf>' verträgt er mit kurzen Pausen länger.
Um auszuschließen, dass es durch eine der Änderungen von euch ohnehin
behoben wurde, hab ich eben den Echo Test noch mit dem neuen Code von
Thomas probiert. Zeigt grundsätzlich selbes Verhalten.
Ich hab das selbe .bin-file jetzt auf 2 der 'schlechten' µCs
aufgespielt.
Der eine steigt bei 10 Zeichen reproduzierbar aus, der andere schafft
jedesmal 40.
@Alex:
es könnte durchaus sein dass was mit dem UMEM Shift nicht so
funktioniert wie es sollte. Ich hab ja alle meine Tests mit den Bluepill
Boards gemacht. Um ehrlich zu sein habe ich den Fall mit UMEMSHIFT =0
noch nicht näher betrachtet. Ich muss mir das mal genauer anschauen und
mit einem Datenblatt vergleichen.
Die ganzen bisherigen Änderungen meinerseits beziehen sich im
Wesentlichen auf die Enum und Kompatibilität zur Spec. Der einzige
offene Punkt auf meiner Liste ist nur noch GetLineCoding was sich aber
nicht auf die Buffer auswirkt.
So wies scheint ist das Risiko, dass der BulkOut steckenbleibt größer,
je mehr Zeichen übertragen werden.
Wo im Code muss ich mich hinsetzen (breakpoint), um den Fall abzufangen,
wo das passiert?
Ich denke dass irgendwas mit der EP_Table nicht stimmt. Halte die
Funktion einfach mal in der Main an nachdem die ENum abgeschlossen ist
und gib die Ep_Table aus. Wenn ich richtig liege stimmt dort was nicht
mit den Einträgen.
Es ist übrigens egal ob du meine Version oder die Version von Stefan
benutzt.
Du solltest das nur die Version angeben, da meine EP_Table etwas anders
aussieht. (wg dem bidirktionalen EP).
Mich würde der Inhalt der TableStruct interessieren. (mindestens 64
Bytes)
Zusatzlich solltest du sicherstellen dass die APB Freq. > 10MHz ist.
Siehe Errata:
Possible packet memory overrun/underrun at low APB
frequencyDescriptionSome data sheet and/or reference manual revisions
may omit the information that 10 MHz minimum APB clockfrequency is
required to avoid USB data overrun/underrun issues.
Thomas Z. schrieb:> Zusatzlich solltest du sicherstellen dass die APB Freq. > 10MHz ist.>> Siehe Errata:
wenn ich mir das so recht überlege passt das sehr gut zu deinem
"Manchmal" Problem.
Anbei ein screenshot von der EpTable,
die Basisadresse ist ja 0x40006000,
EpTableOffset 0x190
Die Clock sollte 48Mhz sein, der µC läuft auf HSI48 (SYSCLK), und HPRE
und PPRE sind jeweils 0.
Hab den HPRE auf 2 gesetzt, SYSCLK damit auf 24MHz -> keine Änderung.
Der Screenshot der EpTable war aber im Debug-Modus gemacht, mit dem
.bin-file konnte ich den Effekt wieder nicht reproduzieren.
Also Alex, ich habe deine main.c und den Stand von Thomas:
Beitrag "Re: STM32 USB Übertragungsproblem mit Code von S.F."
mal zusammengebaut und auf meinem Nucleo32 mit STM32F042K6 probiert.
Außer dass meine Finger schon blutig sind vom Tippen im hterm kann ich
keine Auffälligkeiten feststellen.
Allerdings sehe ich folgendes:
Ich toggle im 1ms Systick einen PIN und messe bei meinem Board 505,7Hz.
Mit anderen Worten die CSR arbeitet nicht. Wir haben dich von Anfang an
auf den Taktpott gesetzt, ohne Reaktion. Wenn ich die Stelle mit meinen
Code ersetze, bin ich bei 499,8Hz->CRS geht. Ich erwarte jetzt von dir,
dass du mal deine Messwerte des Takts nennst, sonst quatschen wir bis
Weihnachten über Endpunkte und Fehler im Code die keine sind.
1
voidSystemInit(void)
2
{
3
// Enable the Internal High Speed oscillator (HSI48)
Nachtrag: Ich habe bei mir die Werte in CSR->CFGR so gelassen wie sie
beim Reset sind. Die passen. Dein Fehler ist das CRS_CFGR_SYNCDIV_0. Das
bedeutet das 0. Bit und somit Division durch 2. Damit kann das nicht
gehen.
Thomas Z. schrieb:> es könnte durchaus sein dass was mit dem UMEM Shift nicht so> funktioniert wie es sollte. Ich hab ja alle meine Tests mit den Bluepill> Boards gemacht.
Ich habe allerdings mit dem STM32F303 und STM32L073 getestet. Die würden
gar nicht funktionieren, wenn dieser Teil fehlerhaft wäre.
Alex schrieb:> Wo im Code muss ich mich hinsetzen (breakpoint), um den Fall abzufangen,> wo das passiert?
Breakpoints sind ungünstig. Sobald das Programm stoppt, fällt die USB
Verbindung aus.
Wenn du debuggen willst, dann mit Hilfe der eingebauten Text-Ausgaben
auf SWO. Eventuell wirst du weitere Meldungen hinzufügen, um das problem
einzukreisen.
Du hast recht, sas mit dem CRS schaut definitiv nach einem Fehler aus.
Ich hab zwar andere Header, aber es ist auch bei mir eine Division /2.
Diese Einstellungen hab ich aus dem Codegenerator vom Cube, bevor ich
auf W.S.-Usb umgestellt hab, nicht auszuschließen, dass da beim
'entfernen' der HAL Mist passiert ist.
Den Takt direkt hab ich (wie ich schon weiter oben mal geschrieben hab)
nie exakt geprüft, weil ich kein MCO (main clock out) auf dem Package
habe.
Allerdings tritt der Kommunikationsfehler auch mit externem TCXO auf,
daher hatte ich die Taktsache ausgeschlossen (abgesehen von ev. zu
großem Jitter, den ich wegen fehlendem MCO nicht prüfen kann).
Was ich nicht kapier ist, wieso das dann bei 20 Modulen funktioniert.
Und es funktioniert wochenlang mit 10 Modulen parallel ohne Fehler.
Der CRS müsste ja komplett daneben sein.
Ich fang gleich an zu testen.
Alex schrieb:> Den Takt direkt hab ich (wie ich schon weiter oben mal geschrieben hab)> nie exakt geprüft, weil ich kein MCO (main clock out) auf dem Package> habe.
Dann mach's doch wie ich, im Systick-Handler (1ms) einfach einen
beliebigen Pin toggeln und mit dem Multimeter messen. Ich hab hier ein
Meterman 37XR.
Alex schrieb:> Was ich nicht kapier ist, wieso das dann bei 20 Modulen funktioniert.> Und es funktioniert wochenlang mit 10 Modulen parallel ohne Fehler.> Der CRS müsste ja komplett daneben sein.
Kann sein, dass die falschen CRS Einstellungen den Takt noch mehr
verbiegen als wenn es ausgeschaltet ist. Und dass bei 20 Modulen die
RC-Oszillatoren nicht gleich sind ist auch klar. Eventuell sind ein paar
davon auf Kante. Die gemessenen 505,x Hz bei meinem Modul sind ja schon
mehr als 1%. Keine Ahnung ab wann das kritisch wird. Allerdings, wenn
man das CRS einschaltet, dann sollte es schon richtig funktionieren.
Im Netz findet man:
The USB 2.0 Specification defines the tolerances for data rates on the
USB bus, including all drift sources. For low-speed communications, the
data rate is specified to be 1.5 Mbps +/- 1.5%. For full-speed
communications, the data rate is specified to be 12 Mbps +/- 0.25%.
If an external clock source is used as the USB clock, it must meet the
above specifications for reliable USB communications. The internal
oscillator on the device family can be used for either low or full-speed
USB. If the internal oscillator is used for full-speed USB
communications, 'clock recovery' must be enabled to ensure the data rate
tolerance specification of +/- 0.25%.
Tu uns doch bitte mal den Gefallen und miss. Es würde uns alle
interessieren ob, und wenn ja in wie weit die Module streuen.
Hab bei einem 'schlechten' Modul mit Echo-Test den Divider korrigiert,
und es läuft definitiv besser. Konnte noch keinen Fehlerfall
verursachen, auch nicht durch exterem lange Zeichenketten.
-> Diese Fehlerursache ist damit verifiziert.
Ich hab ja einen PWM-Pin an den Modulen, da hab ich die Frequenzen mal
von mehreren Modulen (mit scope) verglichen. Jitter war deutlich zu
erkennen, aber keine Frequenzunterschiede zwischen den Modulen.
Ich hab daraus geschlossen, dass der CRS gundsätzlich funktioniert.
Wenn aber der CRS so total falsch konfiguriert war, dürfte das ja
garnicht sein.
Morgen Vormittag wird gemessen (das ist ein Versprechen :-)
Nur um Verwirrung wegen unklarer Formulierung auszuschließen: die
Messung mit dem Scope hatte ich vor einiger Zeit gemacht, hatte weiter
oben darüber berichtet.
Messung an den PWM-Ausgängen:
Sollfrequenz = 48MHz/78 = 615,38kHz
bei 2 Modulen (davon ein 'schlechtes') am Scope die Frequenzen gemessen:
616,07 und 616,14 kHz (schwankt jeweils um +- 0,1 kHz).
die selben Module mit korrigierter CRS-Einstellung:
beide ca. 615,5kHz mit +- 0,4 kHz (schwankt deutlich mehr !?).
Ich bin bei meiner letzen Messung (post vom 24.2.) von der Annahme
ausgegangen, dass wenn der CRS nicht funktioniert, die
Frequenzabweichungen zwischen den Modulen deutlich zu sehen sein
sollten. Dementsprechend hatte ich die Frequenzen der Module miteinander
verglichen, den Absolutwerten aber keine übermäßige Bedeutung
beigemessen. Das war offenbar ein entscheidender Fehler.
Dennoch bin ich extrem erstaunt, wie 'gut' die nicht nachgetunten
RC-Oszillatoren sind.
Alex schrieb:> Messung an den PWM-Ausgängen:> Sollfrequenz = 48MHz/78 = 615,38kHz>> bei 2 Modulen (davon ein 'schlechtes') am Scope die Frequenzen gemessen:> 616,07 und 616,14 kHz (schwankt jeweils um +- 0,1 kHz).>> die selben Module mit korrigierter CRS-Einstellung:> beide ca. 615,5kHz mit +- 0,4 kHz (schwankt deutlich mehr !?).
Das erscheint mir trotzdem noch komisch. Bei meinem Teil lag die
Abweichung bei einem Prozent und es ging noch. Ob ein Oszilloskope da
zum Messen taugt wage ich fast zu bezweifeln. Aber egal, wenn es
geholfen hat ist's gut.
Das erscheint nicht nur dir komisch.
Mich ärgert vor allem, dass ich mich offensichtlich ziemlich massiv
selbst ausgetrickst habe, bei der Fehlersuche.
Klassisches Layer-8-Problem ...
Und was es mit dem externen 24MHz TCXO auf sich hat, den ich ja
testhalber auf eines der Module 'draufgepopelt' habe, ist mir aktuell
auch noch nicht klar. Da muss ich ja auch irgendeinen Bock geschossen
haben...
Jetzt hol ich mir einen Kaffee und Schokolade....
Beim H743 gibt es auch das CRS, dummerweise funktioniert das in einigen
Revisionen nicht, ist im Errata festgehalten. Aber so einen Boliden wird
man sowieso mit Quarz(oszi) betreiben.
Stefan ⛄ F. schrieb:> Die Frage ist, was wir jetzt daraus lernen. Taugt das CRS nicht?
Doch, aber halt nicht, wenn es so wie bei Alex falsch konfiguriert
wurde.
Deinem Jittern bei deinen Messungen traue ich immer noch nicht über den
Weg.
Hier mal 2 Oszibilder vom Toggeln im (jetzt 100µS) SystickHandler.
Das wackelt und jittert auch nichts.
Könnte eventuell eine mangelhafte (noch nicht ganz kaputte) USB
Verbindung zum Versagen des CRS führen?
Schlechte USB Verbindung müsste man vermutlich an unregelmäßigen SOF
Paketen erkennen können, wenn man da mal einen I/O Pin toggelt.
Stefan ⛄ F. schrieb:> Könnte eventuell eine mangelhafte (noch nicht ganz kaputte) USB> Verbindung zum versagen des CRS führen?
Nochmal zum Mitschreiben, der CRS Teil ist im Code von Alex falsch
konfiguriert gewesen, und, kaum macht man's richtig -> schon geht's.
temp schrieb:> Nochmal zum Mitschreiben, der CRS Teil ist im Code von Alex falsch> konfiguriert gewesen, und, kaum macht man's richtig -> schon geht's.
Aber du hast gerade erst zitiert:
> bei 2 Modulen (davon ein 'schlechtes') am Scope die Frequenzen gemessen:> 616,07 und 616,14 kHz (schwankt jeweils um +- 0,1 kHz).> die selben Module mit korrigierter CRS-Einstellung:> beide ca. 615,5kHz mit +- 0,4 kHz (schwankt deutlich mehr !?).
Das war nach seiner letzten Korrektur - habe ich zumindest so
verstanden.
Stefan ⛄ F. schrieb:> Das war nach seiner letzten Korrektur - habe ich zumindest so> verstanden.
Was er da misst ist das eine, mit CRS auf alle Fälle die richtige
Frequenz von 615.5kHz bei 615.38kHz Soll, was beweist dass sie
funktioniert.
Und damit geht es ja. Er muss für sich nur klären, ob seine Messungen
was taugen.
Oder seine Chips entsorgen. Eventuell werden die von den Chinesen auch
schon gefälscht oder der Ausschuss verkauft.
Ich teste gerade die Änderungen auf mehreren Modulen,
dabei ist mit eine Kleinigkeit in der initSerial aufgefallen:
1
#define U_ID (*(volatile uint8_t *)( 0x1FFFF7E8UL)) //for F103 only
2
3
...
4
...
5
6
while(i > -1) //r�ckw�rts lesen
7
{
8
b = U_ID + i;
9
*s = toAscii(b); s += 2;
10
*s = toAscii(b >> 4); s += 2;
11
i--;
12
}
die U_ID müsste erst nach der Summe in der Schleife dereferenziert
werden.
Sonst haben alle die gleiche, komische Seriennummer ...
Hab grad einen ziemlichen Sauhaufen auf meinem Rechner mit
Geister-Treibern den ich versuche aufzuräumen. Manche der Module melden
sich jetzt zwar als COMxx an, ich kann sie aber nicht öffnen. Auch das
Deinstallieren der Treiber hilft da nicht. So kann ich die Änderungen
nicht mal wirklich durchtesten. Hat da jemand eine Idee, wie man das
unter W7 aufräumt?
Alex schrieb:> Hat da jemand eine Idee, wie man das> unter W7 aufräumt?
Versuche mal das Batch Script, nachdem du alle verzichtbaren COM-Ports
aus der Systemsteuerung entfernt hast (auch die verborgenen!):
1
@echo off
2
3
for /L %%A in (1,1,300) do (
4
echo Deleting OEM%%A.INF
5
pnputil /d OEM%%A.INF
6
)
Es entfernt alle Treiber, die gerade nicht benutzt werden, und erzwingt
somit bei Bedarf eine Neuinstallation dieser.
Alex schrieb:> die U_ID müsste erst nach der Summe in der Schleife dereferenziert> werden.
Ups du hast Recht, das ist Käse....
Wegen der Tests:
Es ist vermutlich sinnvoll die SerienNummer ganz auszuschalten, solange
du am testen bist. Das verhindert dass immer neue Vom Ports angelegt
werden.
Zum Aufräumen gibt es mehrere Möglichkeiten:
im Gerätemanager ausgeblendet Geräte anzeigen und dann löschen. Das geht
auch unter W7.
Oder im system32\ Driver die entsprechenden PNF Dateien löschen. Oder in
der Registry unter HKLM\system\CurrentControlset\Enum\Usb\ die
entsprechenden Einträge löschen. Dieser Registry Zweig sollte auch unter
W7 vorhanden sein.
Stefan ⛄ F. schrieb:> Der Code ist nur für die Variante "A" geeignet.
Yep, verstanden. Ich habe mir auch noch das Referenzhandbuch zum F4 und
USB_OTG_FS angeschaut, das sind alleine 140 Seiten. Das ist zuviel
jammer
Immerhin kommt ihr dem eigentlichen Problem von Alex immer mehr auf die
Schliche, da lernt man auch was dabei. Von CRS hab ich noch nie was
gehört :)
Jürgen S. schrieb:> das sind alleine 140 Seiten. Das ist zuviel
Yepp.
Ich hatte auch kurz erwägt, mit einen F4 zu kaufen nur um den Code dafür
anzupassen. Aber als ich dann die Doku dazu sah, fiel mir wieder ein,
dass selbst ein L0 schon sehr viel mehr kann, als ich jemals brauchte.
Damit hat sich das für mich wieder erledigt.
Die Ausgeblendeten COMs hatte ich entfernt, aber erst das Entfernen der
'USB-Verbundgeräte' hats gelöst. :-)
Noch eine Beobachtung:
Mir ist auch aufgefallen, dass die neue Version von Thomas (die mit dem
MI_00 im descriptor) weniger 'gutmütig' bei Wackelkontakten ist.
Beispiel:
COM ist im Terminal offen, und die Verbindung wird mechanisch kurz
unterbrochen (z.B. Wackelkontakt).
In der vorigen Version von S.F. hab ich den COM geschlossen und wieder
geöffnet, und es ging weiter.
In der neuen muss der Port geschlossen werden, dann das Modul aus- und
wieder Eingesteckt werden, erst dann kann ich den Port wieder öffnen.
(So war es aber auch mit der Version vor diesem Thread).
Hat das was mit der Vorbereitung zur multi-VCP zu tun?
Alex schrieb:> Hat das was mit der Vorbereitung zur multi-VCP zu tun?
Der IAD ist vermutlich nicht die Ursache. Allerdings habe ich die
Initialisierung der Bulk EPs von InitEndpoints() nach USB_ConfigDevice()
verschoben. Die Bulk Endpoints dürfen ja erst arbeiten wenn das Device
conigured ist. Zusätzlich habe ich bei USB_SET_INTERFACE die ToggleBits
zurückgesetzt. Das könnte das Problem erklären. Entferne Mal die If A
Abfragen an der Stelle.
Ich glaube auch, dass Thomas Änderungen diesbezüglich relevant sind. Nur
welche genau, das vermag ich nicht zu erkennen. Auch mir ist
aufgefallen, dass das Re-connecten nach einer kurzen Unterbrechung nun
viel zuverlässiger funktioniert.
Was mir dazu noch einfällt
Vielleicht werden in ClassStart nicht alle Variablen zurückgesetzt, das
ist noch original. Beim Öffnen des Comports sollte ein USB_SET_INTERFACE
Request kommen. Dort müsste eigendlich auch eine Abfrage der Interface
Nummer rein. Darauf hab ich bisher verzichtet.
Wieder mal ein Testreport zu meinen Übertragungsproblemen.
Hab aktuell 10 Module mit der korrigierten Software, die werden das
Wochenende über durchlaufen.
Das Korrigieren des CRS hat die Stabilität bei langen Strings erhöht,
vollständig gelöst ist die Sache damit aber nicht.
Ich hab derzeit 3 Patienten isoliert, die auch mit der korrekten
CRS-Einstellung Probleme machen. Auch bei sehr kurzen Strings (mein
'stop<crlf>'-Befehl).
Bei allen ist aber die CLK gut.
Hab mit einem Counter mal die Taktraten an meinem PWM-Ausgang gemessen,
die passen alle. Da muss noch was im Busch sein...
Nachtrag zu den Frequenzmessungen: Durch den CRS zappelt der Takt (Wert
am Counter) deutlich mehr rum als wenn der CRS abgeschaltet ist.
Je kürzer die Gatezeit umso deutlicher wird das. Wahrscheinlich wär es
weg, sobald die Gatezeit mit dem SOF synchronisiert würde, das muss ja
vom nachtunen im SOF-Takt stammen.
Vielleicht könnte man das Nachstellen noch sanfter machen, aber ich
glaub mich zu erinnern dass die Schrittweite relativ grob ist und man
das daher nicht wirklich 'smooth' hinbekommt.
Also, wenn du den Takt im Qszi jittern siehst, ist wohl noch was mit
deiner Hardware im Argen. Besorg dir mal ein Nucleo32 mit dem F042 damit
du wenigstens mal zum Vergleich etwas hast was richtig geht. Oder zeig
uns mal ein Bild von Schaltung und Layout. Wenn du hier von PWM
sprichst, uns aber einen andern Code vor die Füße wirfst, brauchst du
dich nicht wundern wenn dich bald keiner mehr ernst nimmt. Fehler sucht
man meiner Meinung nach anders. Wenn hier im Thread nicht noch an einem
guten Code für USB gearbeitet würde wäre ich längst raus.
Ich habe dieses Wochenende den Code erweitert und einen 2. VCP in die
Deskriptoren eingehängt. Dazu habe auch einige defines aktiviert und die
Kopierroutinen für die Bulk EPs so erweitert, dass die Routinen auch mit
anderen EPs funktionieren.
Das hat soweit funktioniert, ich kann einen zweiten VCP sehen. Leider
habe ich mir beim Testen das einzige BluePill Board mit WCH Controller
abgeschossen.
Ich kann also im Moment nur noch mit STM testen.
Der Bug mit der SN ist gefixt.
Vermutlich hab ich nächstes WE was vorzeigbares, dann auch mit Umleitung
zu den ser. Schnittstellen.
@temp
Ich versteh deinen Frust, vor allem das mit der Taktgeschichte ist
wirklich sehr blöd gelaufen.
Von allen Seiten kamen die Hinweise mit dem Takt und wie wichtig ein
Quarz ist bei USB.
Ich hab ehrlich nicht gedacht, dass es (noch dazu mit einem falsch
laufenden) RC-Oszillator überhaupt möglich ist, überhaupt eine
lauffähige Übertragung hinzubekommen, und diesen Fehler als Ursache
ausgeschlossen.
Und ich denke, dass ich damit zumindest nicht ganz allein bin hier.
Zudem hab ich ein Modul mit einem TCXO getestet, und die
Übertagungsprobleme hatte ich damit auch.
Da das Verhalten der 'schlechten' Module nicht immer 100%ig gleich
reproduzierbar ist, ist ein zuverlässiger Vergleichstest immer
schwierig.
Die Entscheidung, welche Informationen hier reinsollen und welche nicht,
ist nicht immer ganz einfach, und führt ja nicht von ungefähr immer
wieder zu Diskussionen. Dass es da unterschiedliche Auffasungen gibt ist
völlig logisch.
Ich gehe eigentlich davon aus, dass die CLK-Sache jetzt passt.
(Nur um klarzustellen: meine Jitter-Aussage betraf nicht eine Messung an
benachbarten CLK-Pulsen sondern eine optische Wahrnehmung bei Messung
mit verzögerter Zeitbasis bzw. die Schwankung der Frequenzmessung.)
Die Board-Level Hardware würde ich eigentlich ausschließen, aber das war
beim CRS ja ich so.... Daher Schaltungsteil und Layout anbei.
Folgendes wurde schon alles probiert:
- Abblock-Cs vergrößern
- Die 33pF an den USB Leitungen austauschen (auf 22p) (um falschen Wert
auszuschließen)
- Die 33pF an den USB Leitungen wegnehmen
- Den Spannungsregler tauschen
- die 10R-Widerstände in den USB-Leitungen prüfen
- auf Lötfehler kontrollieren
- 3V3 prüfen
- mit und ohne Kabel betreiben
- externen TCXO auflöten
- den STM auf ein anderes Board löten (mit und ohne anderer Peripherie)
- den STM auf ein anderes Board löten (von einem 'guten' Modul)
Letzter Stand:
ein 'schlechtes' Modul, CLK wurde überprüft,
echo-Test funktioniert mit 10 Zeichen zuverlässig immer,
mit 11 Zeichen bleibts beim ersten Versuch stehen.
Die Hello Worlds kommen munter weiter.
Auch hier ist es so, dass ein längerer String dazu führt, dass die
Übertragung zusammenbricht. War bei der CRS-Sache auch so.
Aber der CRS ist ja jetzt korrigiert und vermessen ist dieses Modul
auch.
1. Wenn aum Ausgang des NCP700 wirklich nur 100nF sind, wundert mich
hier überhaupt nichts mehr. "Stable with Ceramic Output Capacitors as
low as 1µF" sagt das Datenblatt. Und dann sollte der auch >=1µF haben
wenn 3,3V anliegen. Also ich hätte da irgendwas zwischen 2,2 und 10µF
verwendet. Gerade bei den Spannungswandlern und Kerkos habe ich selbst
schon genügend Lehrgeld bezahlt.
2. Die Reset Leitung offen als Antenne zu führen ist eventuell auch
nicht optimal. Das wird zwar hier nicht das Problem sein, aber wer weiss
das so genau.
3. So wie ich das sehe ist im Layout am Ausgang des Sapnnunsreglers
überhaupt kein C. Du hast zwar in gefühlt 1km Abstand und ein paar Vias
2 C's an den 3.3V des Controllers, aber der Sapnnungsregler selbt hängt
so gesehen in der Luft. Das solltest du unbedingt vermeiden, egal ob das
die Ursache für deine Probleme ist oder nicht.
Wieso kommt der Plan eigentlich erst jetzt und nicht vor 265 Beiträgen?
Und dann ist er auch noch total unspektakulär, nichts was dieses
Staatsgeheimnis erklären würde.
Thx für comments,
@0 :-)
Solange der Osc-Block abgeschaltet ist, dürfts da nix geben.
@1 die Bestückung ist bei 2x1µ, aber ja, sie sind zu weit weg, vor allem
da neben dem noise-c noch Platz gewesen wäre. Zumindest einen von denen
werd ich direkt zum Regler setzen.
(In die Falle mit der Minimum-C. an LDOs bin ich schon öfter getappt.)
@2 der RST hat einen Pullup mit max 55k, dürfte m.E. nach bei dem kurzen
Stück unkritisch sein.
@3 -> @1, die 3V3 sind sauber, auch bei den 'schlechten' Modulen.
Alex schrieb:> @1 die Bestückung ist bei 2x1µ, aber ja, sie sind zu weit weg, vor allem> da neben dem noise-c noch Platz gewesen wäre. Zumindest einen von denen> werd ich direkt zum Regler setzen.
2x1µF ist aber auch falsch. Beim Abblocken kann man nicht davon ausgehen
dass mehr immer nur besser ist. Ein 0,1µF C verhält sich bei hohen
Frequenzen nun mal anders als ein 1µ oder mehr. Wenn, dann sollte der
100nF drin bleiben und ein größerer (10µ) parallel. Und der hautnahe zum
Spannungsregler zusätzlich, aber nicht verschieben.
Wenn du dir mal das Blockschaltbild vom STM32F042 ansiehst, wirst du
auch sehen, dass die RC-Generatoren von Vdda gespeist werden. Da würde
ich auch mal L und C überprüfen ob das konform mit der Spezifikation
ist. Die schreibt insgesamt größere Kapazitäten vor.
> Ein 0,1µF C verhält sich bei hohen> Frequenzen nun mal anders als ein 1µ oder mehr. Wenn, dann sollte der> 100nF drin bleiben und ein größerer (10µ) parallel.
Nein, das ist in der Regel keine gute Idee. Die
Hochfrequenz-Eigenschaften der Cs werden durch die Serieninduktivität
bestimmt, die in erster Linie von der Bauteilgeometrie (also vom
Package) abhängt.
Durch Parallelschalten von Cs unterschiedlicher Werte können sich
Resonanzen ergeben, die in einem schmalen Frequenzbereich die
Abblock-Wirkung deutlich reduzieren.
Wenn man unterschiedliche Werte parallel schaltet, dann sollte einer
davon einen höheren ESR haben, um die Sache zu dämpfen.
Hab grad versucht an der VDDA das Rauschen zu messen, bin aber mit den
Scope nicht weit gekommen. Rauschlevel ist etwa so groß als wenn ich den
Tastkopf mit dem Gnd-Clip verbinde. Also nicht aussagekräftig und nicht
größer als 1mVeff.
Konnte auch keine 48-MHz Signalkomponente im Spektrum finden.
Im Datenblatt ist ein 1µ // 10n vorgeschlagen, nachdem aber der HSI48
nur ca. 330µA braucht und ein recht guter Ferrit davorsitzt, müssten die
100nF leicht ausreichen.
Die überraschend gute Stabilität des RC-Osc bestätigt das ja auch.
Nur um die Gefühlsmäßige Abschätzung mit den 100n @ VDDA zu untermauern:
Wenn der STM im Mittel 330µA zieht, dann sind das in einer Periode des
HSI48 knapp 7pC (330µA/48MHz).
Selbst wenn der die 7pC jetzt als Impuls aus dem 100nF rauszieht, wären
das nur 7pC/100nF = 70µV.
Klar mess ich das nicht mit dem Scope :-)
Alex schrieb:> Im Datenblatt ist ein 1µ // 10n vorgeschlagen,
bedenke mal, daß vieles in älteren Dokumentationen noch von der Annahme
ausgeht, daß Kondensatoren im µF Bereich Elkos sind. Die waren bis vor
einiger Zeit ja auch die billigsten für größere Kapazitäten. Aber das
ist vorbei. Der allgegenwärtige keramische 10µ/10V im 0805 ist seit
Jahren der Universal-Abblocker, wenngleich er neuerdings von 0603 oder
noch kleiner abgelöst wird. Ich hatte mich zu diesem Thema nämlich mal
mit unserer Bestückerfirma unterhalten, als ich die letzten Tantal-Elkos
aus den Produkten entfernt hatte. Kannst dich ja mal bei
Wittig-Electronic in Brand-Erbisdorf nach den am besten gehenden C's
erkundigen.
W.S.
Alex schrieb:> Nein, das ist in der Regel keine gute Idee.
komisch nur dass das STM so vorschreibt.
Alex schrieb:> Die überraschend gute Stabilität des RC-Osc bestätigt das ja auch
Da stehe ich auf der Leitung. Hast du nicht weiter oben geschrieben dass
deine Messwerte wackeln? Und auch mit CRS darf da nichts wackeln.
Hast du das ganze auch mal an einem anderen USB Port oder hinter einem
Hub probiert?
Alex schrieb:> Rauschlevel ist etwa so groß als wenn ich den> Tastkopf mit dem Gnd-Clip verbinde. Also nicht aussagekräftig und nicht> größer als 1mVeff.
Es geht auch nicht um das Rauchlevel. Schließlich haben wir hier keine
statischen Verhältnisse. Der interessante Punkt ist dabei wie das System
auf dynamische Laständerungen reagiert. Und das kriegt man wohl schlecht
mit dem Draufgucken auf das Oszi mit. Da wäre es ehr angesagt das
Speicheroszi vom Controller an den zeitlich relevanten Stellen zu
triggern und da im zeitlichen Umfeld was festzustellen oder
auszuschließen.
Fakt ist doch eins, deine Probleme liegen in der Hardware. Immerhin bist
du der einzige mit solchen Problemen und dann auch noch mit
unterschiedlichen Ergebnissen bei unterschiedlichen Platinen.
>> Nein, das ist in der Regel keine gute Idee.>komisch nur dass das STM so vorschreibt.
findet man in vielen Datenblättern, ist aber Mist.
Lässt sich auch in Spice leicht zeigen, dass es Mist ist.
>> Die überraschend gute Stabilität des RC-Osc bestätigt das ja auch>Da stehe ich auf der Leitung. Hast du nicht weiter oben geschrieben dass>deine Messwerte wackeln? Und auch mit CRS darf da nichts wackeln.>Hast du das ganze auch mal an einem anderen USB Port oder hinter einem>Hub probiert?
Mit CRS muss es wackeln, schließlich schraubt der CRS jede ms mal an
der Einstellung vom Oszillator rum. Daher wackelt es auch weniger, je
länger die Gate-Zeit des Counters ist, weil sich die Änderungen dann
rausmitteln.
Und wie schon öfters geschrieben, gibts das Problem unter W7, W10, Linux
und auf verschiedenen PCs, mit und ohne Kabel usw.
Noch nicht geschriebem: mit verschiednen aktiven und passiven Hubs
konnte ich keine Änderung im Verhalten feststellen.
> Es geht auch nicht um das Rauchlevel. Schließlich haben wir hier keine> statischen Verhältnisse. Der interessante Punkt ist dabei wie das System> auf dynamische Laständerungen reagiert.
Nachdem am AVDD nur der HSI48 läuft, dürfte es da kaum Lastwechsel
geben, die mit dem Empfang über USB zu tun haben.
Wenn eine Störung von der 3V3 / 5V - Seite kommt, sollten die Ferrite
das sehr gut abfangen. Die Messung war, um auszuschließen dass die 100nF
zu klein sind. Daher hab ich auch speziell nach der 48MHz-Komponente im
Rauschen gesucht.
> Fakt ist doch eins, deine Probleme liegen in der Hardware. Immerhin bist> du der einzige mit solchen Problemen und dann auch noch mit> unterschiedlichen Ergebnissen bei unterschiedlichen Platinen.
Richtig, aber die Probleme hängen mit bestimmten STM-Exemplaren zusammen
und dem darauf laufenden Code zusammen. Ich hab bei allen Test bisher
keinen Ansatzpunkt dafür gefunden, dass es an der Beschaltung liegt.
Stichwort: 'schlechten' Chip auf eine andere Platine löten usw...
Mein aktueller Ansatz:
nachdem ich ja mal beobachtet hab, dass es einen Unterschied macht, ob
ein Programm als Debug oder als Release kompiliert ist, werd ich
versuchen jeweil 'gutes' und ein 'schlechtes' Minimalbeispiel mit
reproduzierbarem Ergebnis zu bekommen.
Dein Text ist voll von "müsste" und "dürfte" und da du es sowieso besser
weißt wie es geht nehme ich hier nichts mehr ernst.
Alex schrieb:> Messung an den PWM-Ausgängen:> Sollfrequenz = 48MHz/78 = 615,38kHz>> bei 2 Modulen (davon ein 'schlechtes') am Scope die Frequenzen gemessen:> 616,07 und 616,14 kHz (schwankt jeweils um +- 0,1 kHz).>> die selben Module mit korrigierter CRS-Einstellung:> beide ca. 615,5kHz mit +- 0,4 kHz (schwankt deutlich mehr !?).Alex schrieb:> Mit CRS muss es wackeln, schließlich schraubt der CRS jede ms mal an> der Einstellung vom Oszillator rum. Daher wackelt es auch weniger, je> länger die Gate-Zeit des Counters ist, weil sich die Änderungen dann> rausmitteln.
Sorry, aber liest du selbe was du schreibst? +-0,4kHz bei 615,5kHz sind
1,3% Abweichung. Welchen Sinn soll den das CRS haben wenn der Oszillator
am Ende um 1,3% wackelt. Lies dir den entsprechend Abschnitt im Manual
durch. Da wird nicht ständig was verändert. Es wird einmal solange
verändert bis die Differenz in einem gewissen Fenster bleibt und danach
ist gut. Jedenfalls solange der Oszillator nicht soweit driftet, dass es
aus dem Fenster läuft. Das passiert aber nicht jede ms und wenn doch
liegt da aber massiv was daneben. Temperatur und Spannung haben einen
Einfluss, ohne Frage. Beides sollte aber so stabil sein, dass hier
nichts wackelt. Noch dazu im ms Takt.
Ich bleibe dabei, besorg dir eine vernünftige Vergleichshardware und
such dann deine Fehler.
Alex schrieb:> +-0,4 von 615 sind bei mir +-0,06% Abweichung, der Bereich ist dann> 0,12% groß.> Das 'sollte' auch deiner Meinung nach genügen, oder?
ok, diesmal hast du Recht und ich die Tomaten auf den Augen.
dann geht uns jetzt beiden wieder besser :-)
Spiel grad mit der Compiler-Optimierung rum:
sobald die Optimierung ausgeschaltet ist, läuft die Sache.
Bei -Os (size) gehts mit max. 10 chars,
bei -O3 enumeriert das device nicht korrekt.
Alex schrieb:> Spiel grad mit der Compiler-Optimierung rum:> sobald die Optimierung ausgeschaltet ist, läuft die Sache.> Bei -Os (size) gehts mit max. 10 chars,> bei -O3 enumeriert das device nicht korrekt.
Das nützt nur leider keinem was, solange du nicht deinen Code oder das
Projekt hier rein stellst. Das was wir bisher haben ist ja was anderes
mit PWM u.s.w.
Also, ohne dass du da eine 1:1 Kopie rüberwachsen lässt, und wir vom
selben Code sprechen, kann man dir softwareseitig nicht mehr helfen.
War schon in Arbeit.
Ist der Code von S.F. Echo-Test umgemünzt auf die neuen files von
Thomas.
Der PWM-Teil ist da jetzt wieder auskommentiert (aber noch zu sehen).
Wir kennen deine Umgebung nicht und der Startupcode fehlt, ebenso die
HAL. Also bitte so vervollständigen dass man ein identisches Projekt
bauen kann.
Ich werde mir jetzt das nicht irgendwo zusammentragen.
Ich arbeite mit der Segger IDE. Also entweder du lieferst alles oder ich
ändere es für Segger und du installierst die mal zum Vergleich.
Hast du dir das RefManual mal durchgelesen? Da steht eindeutig: "One
wait state, if 24 MHz < SYSCLK ≤ 48 MHz"
das FLASH->ACR Register in deinem Code ist aber 0.
Da fehlt:
1
// Enable Prefetch Buffer and set Flash Latency
2
FLASH->ACR=FLASH_ACR_PRFTBE|FLASH_ACR_LATENCY;
Ausser dein Gefühl sagt auch hier, scheiß egal was im Manual steht, es
dürfte auch so gehen.
System: CubeIDE 1.4.2
bezgl. Flash-Zugriff: Punkt für dich!!!!
Ist bei der Anpassung vom Echo-Test-Beispiel verlorengegangen.
Habs eben getestet: der Fehler ab 11 Chars bleibt.
Mein Gefühl sagt mir, es ist nicht die Ursache für den Fehler.
Ne, Cube und Hal, damit baue ich mir jetzt kein Projekt zusammen. Soviel
Zeit habe ich auch nicht. Ich hänge dir aber mal mein Projekt dran. Ist
für stm32f042f6 gebaut. Wenn du willst kannst du das ja mal bei dir
probieren.
da ich im Moment einiges umbaue (mit wechselndem Erfolg) macht es nicht
so viel Sinn eine neue Variante einzustellen.
Mir ist aber bei den EP Tables noch ein potentielles Problem aufgefallen
welches ich noch nicht zuordnen kann. Ich hatte ja weiter oben schon mal
die Behauptung aufgestellt dass EpTable[0].TxCount = 0; falsch sei. Dem
ist nicht so. Nun gibt es Stellen wo bei TxCount in reservierte Bits
geschrieben wird.
Beispiel: EpTable[1].TxCount = (i & 0x3FF) | EpBulkLenId;
Das ist vermutlich schon sehr lange im Code drin. Ich habe keine blassen
Schimmer ob und wie sich das auswirkt. Aufgefallen ist mir das weil ich
Speicher im USB Mem sparen muss, und deshalb die EP Tables kräftig
umbauen muss.
@Thomas
würdest du sagen, dass ich mit dem Fehlersuchen eher warten sollte, bis
du das 'fertig' hast?
Weil meine Fehlersuchkompetenz (besonders was C-Code anbelangt) ist ja
nicht die Beste (da muss ich temp definitiv Recht geben !!)
@temp
Ich hab aus deinem Zip-File das Release-ELF in einen 'schlechten' Chip
reingespielt. Der Fehler ist auch da, sobald ich mehr als 10 Zeichen
runterschicke, ist Schluss mit BulkOut.
Im 'guten' Chip läufts. Verhält sich exakt so, wie bei meinen ELFs.
Thomas Z. schrieb:> Dem> ist nicht so. Nun gibt es Stellen wo bei TxCount in reservierte Bits> geschrieben wird.>> Beispiel: EpTable[1].TxCount = (i & 0x3FF) | EpBulkLenId;
Beim F103 steht im Manual:
Den Grund warum das W.S. so gemacht hat weiß ich nicht. Man kann das mit
0 definieren und es geht trotzdem alles. Negative Auswirkungen würde ich
nicht befürchten. Vielleicht hat sich da mal einer ein paar Marker in
den Speicher gebaut zu Debugzwecken um Überschreibungen zu detectieren
o.ä.
1
#define EpCtrlLenId 0 // ((1<<15)|(1<<10))
2
#define EpBulkLenId 0 // ((1<<15)|(1<<10))
Alex schrieb:> Ich hab aus deinem Zip-File das Release-ELF in einen 'schlechten' Chip> reingespielt. Der Fehler ist auch da, sobald ich mehr als 10 Zeichen> runterschicke, ist Schluss mit BulkOut.> Im 'guten' Chip läufts. Verhält sich exakt so, wie bei meinen ELFs.
Eventuell solltest du bei den schlechten Chip den Fehler mit dem Hammer
suchen. Einmal kräftig draufhauen und du weißt genau warum er nicht mehr
geht...
Ich traue deiner Hardware immer noch nicht. Der Software schon. Alles
was wir hier diskutieren hat mit deinen Problemen nichts zu tun. Wo hast
du die Chips gekauft?
Chips sind von Digikey.
> Eventuell solltest du bei den schlechten Chip den Fehler mit dem Hammer
suchen.
Ich sehe du bist ein Jünger Bob Widlars :-)!!!
'to widlarize something'
Der Ansatz ist möglicherweise der einzig sinnvolle.
Bisher wars immer so, dass die Fehler sporadisch mal da waren, und dann
wieder weg.
Lag möglicherweise an der CLK-Geschichte.
Bei einem von 3 'schlechten' ist es jetzt exakt reproduzierbar, die
anderen hab ich jetzt nicht durchgecheckt.
Vielleicht sollte ich die Chips einfach eintüten und beschriften, wenn
sie dann mal in der Ecke liegen wächst sowieso Gras drüber...
Alex schrieb:> @Thomas> würdest du sagen, dass ich mit dem Fehlersuchen eher warten sollte, bis> du das 'fertig' hast?
Ich würde sagen, dass mein Code eigendlich bei dir keine Veränderung
bringen sollte. Ich werde da am 1. VCP nichts wesentliches verändern.
Wenn sich da was tun sollte ist es eher ein Seiteneffekt, jedenfalls
nichts absichtliches. Der Code von W.S. ist soweit ja ok und
funktioniert.
Moin Leute
Um die schlechten Chips eindeutig zu identifizieren hab ich mir
PC-seitig ein Skript geschrieben, das in einer Schleife die Anzahl der
Zeichen die runtergeschickt werden kontinuierlich erhöht.
Ich sehe dann, bei wievielen Zeichen der STM aussteigt.
Die 'Hello World' Zeile und die beiden Delays hab ich auskommentiert.
Bei den meisten Modulen komme ich auf 47-51 Zeichen, dann stehts.
Bei manchen komme ich auf 5, 7, mal auf 13 oder 19
Jetzt hab ich, um zu verifizieren dass das wirklich an der Hardware
liegt, mit cube ein HAL-USB-Echo-Projekt gebaut, dass auch die Zeichen
einfach zurückschickt.
Meine Schleife geht bis 512 Zeichen, das schafft mit dem HAL-USB auch
jenes Modul problemlos, das mit W.S. / Thomas Code immer bei 5
aussteigt.
Für mich schaut das schon sehr danach aus, dass da in der Programmierung
irgendwas nicht so glatt läuft wie es sollte.
Ich weiß, die Buffer sind nicht exakt gleich groß, der HAL-Treiber nimmt
standardmäßig 1k Buffer, aber in Thomas code sind es auch 512 Bytes.
Alex schrieb:> Ich weiß, die Buffer sind nicht exakt gleich groß, der HAL-Treiber nimmt> standardmäßig 1k Buffer, aber in Thomas code sind es auch 512 Bytes.
Mir kommt da ein übler Verdacht auf:
Für die Richtung µC-->PC hatte ich ja den Wiederanlauf per Timertick
gemacht, von euch wurde das in den Userbereich mit "flush.." verschoben,
aber immerhin ist für diese Richtung ja etwas da, was der Datenfluß in
Gang hält bzw. wieder in Gang bringt. Diese Richtung sollte also
abgehakt sein, denke ich mir mal...
ABER: für die umgekehrte Richtung, also PC-->µC, ist da nichts
vorgesehen, weil da eigentlich der PC immer wieder dran erinnert, daß
der Transferpuffer entleert werden soll.
Kann das also sein, daß bei dir diese wiederholten Interrupts
ausbleiben, während der Ringpuffer noch zu voll ist, um den
Transferpuffer in ihn auszuleeren? Daß das also einfach ein Effekt von
zu langsamem oder zu spätem Abholen der eintreffenden Zeichen ist, der
die Situation aufkommen läßt, wo der Ringpuffer leer ist, der
Transferpuffer von EpBulkOut noch nicht entleert ist und sich NIEMAND
drum kümmert, ihn zu entleeren?
Vielleicht sollte man sich doch überlegen, all die Eingriffe vom
Userland in den USB wieder zurückzubauen und stattdessen beim 1ms
Timertick grundsätzlich beide (bzw. alle) Bulk-EP's nachzuschauen, ob
es da etwas zu leeren oder zu füllen gibt.
W.S.
Stefan ⛄ F. schrieb:> Bedenke,...
Ja was kann/soll man sich denn sonst noch als Szenario für die Probleme
des TO ausdenken, wenn bereits alles ausprobiert worden ist?
Mir ist da durchaus klar, daß die krampfhafte Suche nach irgend etwas,
wo man annimmt, daß vielleicht noch keiner dran gedacht hat, irgendwann
mal in die Irre gehen muß.
Also, wenn's nicht daran liegt, dann war dieser Gedanke umsonst und kann
abgehakt werden.
W.S.
Ich hab jetzt den minimalen Echo-Test mit debuglevel -g1 und
optimization -Os kompiliert, auf diese Weise ist der Fehler noch
reproduzierbar und ich kann Breakpoints setzen.
Hab als ersten Versuch einen Breakpoint im OnEpBulkOut in die Zeile
1
avail = EpTable[1].RxCount & 0x3FF;
gesetzt.
Wenn ich nur ein Zeichen sende, dann komm ich an den Breakpoint,
wenn ich zu viele schicke dann kommt das Programm dort nicht hin.
eingebaut und einen BP reingesetzt, um alle IRQs außer den SOF zu
erkennen.
Hier ist es auch so, dass der BP nicht erreicht wird, wenn viele Zeichen
geschickt werden.
Ich glaube ich kann noch was zur allgemeinen Verwirrung beitragen.
Gestern habe ich ein kleines Tool geschrieben das ungefähr das macht was
Alex sein Script auch macht. Mit dem Ergebnis, dass es bei mir mit dem
STM32F042 und STM32F103 nicht stabil läuft. Irgendwann steht die
Geschichte immer.
Warum hat das noch keiner gemerkt? Weil niemand so etwas im realen Leben
macht:
1
while(1)
2
{
3
// Send echo of received characters back
4
while(UsbRxAvail())
5
{
6
charc=UsbGetChar();
7
UsbCharOut(c);
8
}
9
}
Bei mir geht das immer so: Packet hin als Commando, Packet zurück. Bei
den SLCAN-Interfaces z.B. auch nur mit Längen < 64Byte. So etwas macht
keine Probleme. Ich hänge das Programm mal hier dran und würde mich über
Testergebnisse von anderen freuen. Einfach nur aufrufen "usbcdctest
comx" oder ./usbcdctest /dev/ttyACM0
Bei mir ist es häufig aber nicht immer so, das die es bis 63 Byte geht
und ab 64 klemmt es. Deshalb wartet das Programm vor der 64 auf Enter.
Wenn man sich da die Ringbuffer Variablen ansieht, sieht man, dass die
alle genau die 64Byte weiterzählen, und trotzdem kommt nichts mehr am
Host an.
Ich habe auch einige Versionsstände probiert, aber keine hat den Test
bestanden. Ich habe das unter Windows und unter Linux (Raspi) probiert
mit dem gleichen Ergebnis.
Wenn ich den Test nur bis 63Byte mache, läuft es stundenlang ohne
Probleme.
Bitte keine Kommentare zur Qualität des Testprogramms. Das ist mit
heißer Nadel zusammengebaut, aber so einfach, dass jeder selbst
Änderungen machen kann.
temp schrieb:> Eins kann ja ein freundlicher Moderator ja löschen.
Lohnt sich nicht, das File ist erfrischen klein.
Ich mache alles unter Linux, deswegen werde ich es nicht ausprobieren.
Ich habe aber eigene Tests unter Linuc gemacht, die liefen gut.
Die Zahl 63/64 macht mich allerdings stutzig. Ist das nicht die maximale
Größe, die per USB am Stück übertragen werden? Dazwischen wird es wohl
kleine Pause geben, wo das Programm warten muss.
Stefan ⛄ F. schrieb:> Ich mache alles unter Linux, deswegen werde ich es nicht ausprobieren.> Ich habe aber eigene Tests unter Linuc gemacht, die liefen gut.
Es ist doch eine Linux Version dabei? Auf build.sh kannst du doch noch
drücken?
Stefan ⛄ F. schrieb:> Die Zahl 63/64 macht mich allerdings stutzig. Ist das nicht die maximale> Größe, die per USB am Stück übertragen werden?
Das ist richtig alles kleiner 64 ist ein sogenannter short Transfer (bei
USB1.1) und beendet die Übertragung bei 64 Bytes gehen die Treiber davon
aus dass es weiter geht. Das ist zum Beispiel ein wesentlicher
Unterschied zu den FTDI Protokollen, die haben immer nur 62 Bytes
Nutzdaten + 2 Statusbytes.
Ich habe auf dem Control EP etwas ganz ähnliches erlebt als ich die
EP0_SIZE auf 8 reduziert habe, weil mir der Speicher im USB Mem knapp
wurde. Da waren plötzlich Vendor und Device String weg weil diese genau
ein vielfaches von 8 waren.
Da könnte durchaus noch ein Bug vergraben sein. Noch habe ich mich
allerdings nicht mit den Bulkdetails beschäftigt, da muss ich auch noch
Mal in der Spec nachlesen, aber möglicherweise muss bei genau 64 Bytes
ein ZLP hinterher kommen.
Es ist nur leider so ein geht/geht nicht Fehler.
Ich habe noch was interessantes. Mit dem Code von Stefans Webseite läuft
der Test auf dem f042 bei mir jetzt durch. Da waren aber die Änderungen
von Thomas glaube ich nicht drin. Irgendwann blickt man durch die vielen
Versionen nicht mehr durch.
temp schrieb:> Da waren aber die Änderungen von Thomas glaube ich nicht drin.
Doch teilweise schon. Zumindest die, wo er meinte, dass sie akute Fehler
korrigieren.
Später kamen dann Erweiterungen für neue Funktionen dazu, die habe ich
nicht mehr übernommen.
Ein paar Änderungen sind auch in Stefans Version von mir drin. Das
bedeutet aber doch ganz einfach dass sich in meinen Versionen noch ein
dicker Bug befindet....
Der kann dann ja nur in einer der beiden Copy Funktionen für die Bulk
EPs stecken...
Ich schau mir das nochmal an.
@Thomas
Der Fehler ist mit deiner Version vom 12.3. rein gekommen. Mit der vom
4.3. geht es bei mir auch noch.
Alex hatte die vom 12.3. verwendet, mit der Version von Alex hatte ich
meine Tests mit dem stm32f042 gemacht und so ist die Falle zugeschnappt.
@temp danke für den Hinweis. Das hatte ich schon vermutet da in der
Version neue Bulkcopy Funktionen eingebaut habe...
Hier hab ich die schon wieder verworfen. Ich bitte also um etwas Geduld.
Andere Frage:
Ich glaube du warst es der gefragt hat ob man irgendwie erkennen kann
wenn der Host den Port geöffnet hat oder?
Ich glaube ich hab da eine Lösung mit Hilfe des SetLineCoding requests
sollte man das realisieren können. Ich hab hier ein Test laufen der beim
Öffnen eine LED in Main toggelt. Es gibt manchmal noch Fehlanzeigen, da
muss ich wohl noch ein paar Extras einweben. Darauf bin ich beim
Überprüfen der Class Requests gekommen.
Thomas Z. schrieb:> Ich glaube du warst es der gefragt hat ob man irgendwie erkennen kann> wenn der Host den Port geöffnet hat oder?> Ich glaube ich hab da eine Lösung mit Hilfe des SetLineCoding requests> sollte man das realisieren können.
Das habe ich auch schon mal geprüft. Beim Öffnen wird SetLineCoding
gerufen, beim Schließen nicht.
Ich hab das aber für mich mit der DTR Leitung gelöst.
Es läuft sowohl unter Debian 11 als auch Windows 10 tadellos durch.
UsbRxAvail() funktioniert auch.
Unter Windows sehe die Eingabeaufforderung "please press enter" nicht.
Braucht Windows vielleicht ein "\r\n" am Ende der Zeile? Ach egal,
scheiß drauf.
Stefan ⛄ F. schrieb:> ich habe dein Testprogramm mit meinem Projekt> http://stefanfrings.de/stm32/STM32F303CC_usb_test.zip getestet
Vielen Dank.
Stefan ⛄ F. schrieb:> Es läuft sowohl unter Debian 11 als auch Windows 10 tadellos durch.>> UsbRxAvail() funktioniert auch.>> Unter Windows sehe die Eingabeaufforderung "please press enter" nicht.> Braucht Windows vielleicht ein "\r\n" am Ende der Zeile? Ach egal,> scheiß drauf.
Das bestätigt meine Beobachtung.
Stefan ⛄ F. schrieb:> Unter Windows sehe die Eingabeaufforderung "please press enter" nicht.> Braucht Windows vielleicht ein "\r\n" am Ende der Zeile? Ach egal,> scheiß drauf.
Am besten die gesamte Eingabeaufforderung auskommentieren. Das ist ja
nur für den speziellen Fall gedacht den ich hatte.
temp schrieb:> Am besten die gesamte Eingabeaufforderung auskommentieren.
So, ich habe noch einen Nachtrag. Und zwar mache ich seit Gestern
Dauertests. Die Eingabeaufforderung aus dem Testprogramm habe ich raus
geschmissen. Mir war gestern schon mal aufgefallen, dass der Code von
Stefans Webseite original mit Stm32Cube auch Hänger hat (release Mode
-O3). Hier mal 4 Beispiele
1
send409bytes
2
-read345bytes
3
timeout,read345bytes,ges:59212613bytes
4
5
send420bytes
6
-read356bytes
7
timeout,read356bytes,ges:62487578bytes
8
9
send174bytes
10
-read110bytes
11
timeout,read110bytes,ges:48809529bytes
12
13
send493bytes
14
-read429bytes
15
timeout,read429bytes,ges:28770411bytes
Mit anderen Worten, da steckt noch ein Bug drin.
Ich selbst baue seit geraumer Zeit an meiner eigenen Version des ganzen.
Die hat von Gestern zu Heute ein paar GB durchgespült ohne Hänger. Die
Variante von Stefan (und die anderen davor sicher auch) schafften nicht
mal 100MB. Im realen Leben dürfte das keine große Rolle spielen, aber
ich gebe mich erst dann zufrieden wenn so etwas nicht mehr auftritt. Wie
man an den Zahlen aber schön sehen kann, fehlen immer 64Byte am Ende.
Thomas Z. schrieb:> Das ist richtig alles kleiner 64 ist ein sogenannter short Transfer (bei> USB1.1) und beendet die Übertragung bei 64 Bytes gehen die Treiber davon> aus dass es weiter geht. Das ist zum Beispiel ein wesentlicher> Unterschied zu den FTDI Protokollen, die haben immer nur 62 Bytes> Nutzdaten + 2 Statusbytes.
Das vermute ich auch als Ursache. Änderungsvorschlag wäre entweder alle
Pakete auf < 64 zu begrenzen oder nur das letzte.
1
voidEpBulkBeginTransmit(void)
2
{
3
inti,n;
4
UMEM_FAKEWIDTHL,A;
5
UMEM_FAKEWIDTH*P;
6
7
P=(UMEM_FAKEWIDTH*)EP1TxABuffer;
8
i=txw-txr;
9
if(i<0)
10
{
11
i+=USB_TXLEN;// i = number of bytes to send
12
}
13
if(i>EpBulkMaxLen)
14
{
15
i=EpBulkMaxLen;
16
}
17
// verhindern, dass als letztes! Packet eines mit 64byte gesendet wird
18
elseif(i==EpBulkMaxLen)
19
{
20
i=EpBulkMaxLen-2;
21
}
Hier besteht aber noch das Restrisiko, wenn aus dem Userland jemand den
tx- Ringbuffer genau nach diesem Zeitpunkt löscht, fehlt wieder das
letzte kurze Paket.
Ich habe gestern die halbe Nacht nach einem Fehler gesucht der mir bei
den Classrequests aufgefallen ist. Nichts was ich probiert habe hat
funktioniert. Das war wie wenn ich das Programmieren verlernt hätte.
Irgendwo gibt's noch ein prinzipielles Problem im Code, oder im
Verständniss des USB cores. Um auszuschliesen dass ich mir selbst ein
Bein stelle bin ich dabei bis zurück zum Original von W.S. gegangen.
Gefunden hab ich bis jetzt nichts. Am WE geht's weiter.
temp schrieb:> Ich glaube ich kann noch was zur allgemeinen Verwirrung beitragen.> Gestern habe ich ein kleines Tool geschrieben das ungefähr das macht was> Alex sein Script auch macht. Mit dem Ergebnis, dass es bei mir mit dem> STM32F042 und STM32F103 nicht stabil läuft. Irgendwann steht die> Geschichte immer.
Ich habe jetzt ebenfalls ein Minimal Beispiel für das Bluepill gebaut
und habe das Projekt ausgegraben was ich vor einiger Zeit hier
getriggert hatte, siehe auch
Beitrag "USB CDC von Stefan Frings und WS"
Dann habe ich dein kleine Testprogramm verwendet und dies läuft ohne
irgendwelche Probleme durch, kein einziger hänger.
Ich vermute das mit all den verschiedenen Versionen Chaos entsteht aber
das wurde ja alles schon einmal aufgeräumt. Im Anhang mal ein Testfile
für deine Versuche. Lass mich wissen ob es damit Probleme gibt dann
grabe ich mal weiter. Ich glaube aber das funktioniert ohne Probleme.
Dank gilt hierfür Niklas.
Für mich sieht die Lage nicht so eindeutig aus, wie ich es gerne hätte.
Ich hasse solche "Fehler" zutiefst.
Ich habe ja am Donnerstag berichtet, das ich den Fehler nicht
reproduzieren konnte. Doch da hatte ich das Testprogramm nur wenige
Minuten laufen lassen. Die Anmerkungen von temp animierten mich jedoch
dazu nochmal genauer hin zu schauen, was ich heute morgen tat.
Nach nur 5 Minuten hatte ich den ersten Aussetzer. Der nächste ließ
allerdings satte 4 Stunden auf sich warten. Dann hatte ich wieder einen
quasi sofort nach nur wenigen Sekunden.
Also muss ich meine vorherige Aussage revidieren, ich kann das Problem
doch reproduzieren. Und ja, auch bei mir fehlten immer genau 64 Bytes.
Nun habe ich die drei Zeilen Workaround in den Quelltext eingefügt und
teste seit dem wieder. Das ist nun zwei Stunden her, ohne Aussetzer. Ich
werde es wohl auch mindestens bis morgen laufen lassen, um Gewissheit zu
bekommen.
Ich frage mich, ob temp hier auf einen Hardware-Bug gestoßen ist?
Frage an die 3-4 Kollegen, die sich mit USB auskennen: Wenn der µC die
letzten 64 Zeichen an den PC sendet und sie dort (warum auch immer)
nicht ankommen, wie funktioniert da der Wiederhol-Mechanismus?
Bernd N. schrieb:> Dann habe ich dein kleine Testprogramm verwendet und dies läuft ohne> irgendwelche Probleme durch, kein einziger hänger.
Fakt ist eins, der Bug ist da noch drin. Ich habe das gesamte Projekt
von Stefans Seite so genommen wie es ist. Optimierung O3. Wenn du was
anderes hast, brauchen wir nicht drüber reden. Und Laufen lassen heisst
ein paar Stunden und nicht 10s.
Es ist genau so wie Thomas es beschreibt. Werden vom STM genau 64 Byte
in einem Usb-Endpoint-Paket verschickt und der PC will genau 64 Byte
lesen steht die Geschichte augenblicklich. Sendet der STM fröhlich
weiter, wird diese Klippe übersprungen. Verkleiner der STM das Packet
auf 63 und 1 Byte im nächsten Usb-Endpoint-Paket tritt das Problem nicht
auf.
Was die Fehlersuche an dieser Stelle erschwert ist die Tatsache, dass im
STM-Testprogramm alles Byteweise abgehandelt wird.
1
while(1)
2
{
3
charc;
4
if(UsbGetChar(&c,10))// warte max. 10ms
5
{
6
UsbSendChar(c,10);// warte max. 10ms
7
}
8
}
Hier wird im UsbSendChar() auch das Triggern des Endpointtransfers
angestoßen. Somit ist es in Verbindung mit dem PC-Testprogramm völlig
zufällig, was für Packetgrößen wirklich per USB übertragen werden. Die
Wahrscheinlichkeit ist sogar ziemlich gering, dass das Device 64Byte am
Block und noch dazu im letzten Block sendet und der PC genau auf diese
64 Byte wartet. Hier spielt dann auch die Abhängigkeit von der
Optimierung eine Rolle. Mit einem angepassten Testprogramm ist das mit
dem ersten Senden reproduzierbar. Dieser Bug ist schon von der ersten
W.S. Version drin. Zusätzlich einer der in den Endpoint schreibt, obwohl
der noch den STAT_TX 0x03 hat. Das hat dann Niklas mit viel Gedöhns und
Flags und Verlagern von Teilen in den Usercode gefixt. Nicht elegant,
aber es half.
Ihr könnt das glauben oder nicht, ich habe damit kein Problem. Ich habe
aber auch keinen Bock für jeden einzelnen noch ein Demoprogramm zu
schreiben. Es war schon nervig genug den STMCubeMx Kram nur für die
Spielerein hier zu installieren.
Bernd N. schrieb:> Dank gilt hierfür Niklas
Niklas hat erst die Vermischung von User- und Interruptcode hier rein
gebracht. Dafür gibt es von mir keinen Dank.
Stefan ⛄ F. schrieb:> Ich frage mich, ob temp hier auf einen Hardware-Bug gestoßen ist?
Nein, das ist Spezifikation USB1.1 lt. Thomas. Wenn ein Endpoint-Packet
genau 64Byte lang ist, geht der Host davon aus es kommt noch was und
liefert die Daten noch nicht an das Userprogramm weiter. Also ist mein
Trick, wenn der Ringbuffer noch genau 64 Byte hat, sende ich nur 62 und
die nächsten 2 im nächsten Endpointpaket. Damit sind dann alle
zufrieden.
temp schrieb:> Fakt ist eins, der Bug ist da noch drin. Ich habe das gesamte Projekt> von Stefans Seite so genommen wie es ist
Ich nicht, deswegen habe ich das Angebot gemacht. Probier es aus oder
lass es, ich teste seit Stunden ohne Aussetzer.
Bernd N. schrieb:> Ich nicht, deswegen habe ich das Angebot gemacht. Probier es aus oder> lass es, ich teste seit Stunden ohne Aussetzer.
Sorry, du kannst testen soviel wie du willst. Es ist mir auch Wumpe was
du für Ergenisse erziehlst. Und ich will auch niemandem bekehren. Fakt
ist, der Code hat diesen Bug, da er die o.g. Besonderheit der Spec nicht
berücksichtigt. Mir reicht diese Erkenntnis für mich, und nur das ist
mir wichtig. Ich wüsste auch nicht was mich deine Projekte interessieren
sollten. Mehr als meine Erkenntnisse und Erfahrungen bringe ich hier
nicht ein, und wer's nicht hören will, des lässt es halt bleiben. Punkt.
Bernd N. schrieb:> Ich nicht,
Genau das ist das Problem. Es spielen in dieser Konstellation zu viele
Zufälliglkeiten rein und auch definitiv die Abhängikeit von der
Optimierungsstufe.
Und nicht weil da falscher Code raus kommt, sondern weil er sich
zeitlich anders verhält und bei dieser Testkonstellation der Bug nur
selten auftritt.
Stefan ⛄ F. schrieb:> Nach nur 5 Minuten hatte ich den ersten Aussetzer. Der nächste ließ> allerdings satte 4 Stunden auf sich warten. Dann hatte ich wieder einen> quasi sofort nach nur wenigen Sekunden.
Danke Stefan, das bestätigt, dass ich nicht an geistiger Umnachtung
leide.
Ich habe vorhin schon geschrieben, dass ein passender Test das sofort
reproduzieren kann. Ich wüsste nur nicht warum ich hier mit jemanden
darum streiten sollte. Was das Problem ist habe ich geschildert. Wer es
nicht glaubt baut sich bitte seine Tests selber oder denkt weiter es ist
alles ok.
Und ja, viele realen Anwendungen, auch meine, laufen mit dem Bug ohne
Probleme. Jedenfalls solange nicht jemand auf ein letztes Paket mit 64
Byte wartet.
temp schrieb:> Es spielen in dieser Konstellation zu viele> Zufälliglkeiten rein und auch definitiv die Abhängikeit von der> Optimierungsstufe.
Ich konnte den Fehler auch mit -O1 reproduzieren.
Mit der Korrektur von temp lief es seit gestern ca 14:00 ohne Stopp
durch. Selbst wenn sich heraus stellen sollte, dass die Änderung noch
keine 100% Lösung ist, so macht sie zumindest nichts kaputt.
Ich habe die Downloads auf meine Homepage (unter
http://stefanfrings.de/stm32/index.html) entsprechend aktualisiert.
Ich will hier nicht streiten sondern herausfinden was da falsch läuft.
temp schrieb:> Ich habe vorhin schon geschrieben, dass ein passender Test das sofort> reproduzieren kann.
Also dann her mit dem Test, kostet dich das Testen nur ne halbe Minute.
Ich teste es auch gerne selbst.
Bernd N. schrieb:> Also dann her mit dem Test
Das hört sich etwas dummdreißt an...
trotzdem in die usb.c am Ende muss eine neue Methode:
1
boolUsbSendCharBlock(constchar*pc,intlen)
2
{
3
for(intn=0;n<len;n++)
4
{
5
// check space
6
inti=(txw+1)&(USB_TXLEN-1);
7
if(i==txr)
8
{
9
returnfalse;
10
}
11
12
// write into the buffer
13
UsbTxBuf[txw]=pc[n];
14
txw=i;
15
}
16
DisableUsbIRQ();
17
EpBulkBeginTransmit();
18
EnableUsbIRQ();
19
returntrue;
20
}
Die füllt zuerst den Ringbuffer und triggert danach erst das
EpBulkBeginTransmit an. Damit landen dann auch bis max 64byte im ersten
Bulktransfer.
Die main sieht dann so aus:
1
boolUsbSendCharBlock(constchar*pc,intlen);
2
intmain()
3
{
4
init_clock();
5
init_io();
6
UsbSetup();
7
// Initialize system timer
8
SysTick_Config(SystemCoreClock/1000);
9
while(1)
10
{
11
charbuf[65];
12
intn=0;
13
while(n<64)
14
{
15
charc;
16
if(UsbGetChar(&c,10))
17
{
18
buf[n]=c;
19
n++;
20
}
21
}
22
UsbSendCharBlock(buf,64);
23
}
24
}
Mit anderen Worten, ich warte bis ich genau 64 Byte vom Host kriege, und
sende die dann im Block zurück. Das angepasste PC Testprogramm ist im
Anhang. Ohne meine Änderung kommt nicht mal der erste Block beim PC
wieder an.
Im Anhang das frisch von Stefans Seite geladene Projekt mit den o.g.
Änderungen. Die Zeile 1351 in usb.c ist auskommentiert um den Fehler zu
zeigen. Wird der Kommentar entfernt funtioniert es.
Stefan ⛄ F. schrieb:> Selbst wenn sich heraus stellen sollte, dass die Änderung noch> keine 100% Lösung ist, so macht sie zumindest nichts kaputt.
Mittlerweile weiss ich was die 100% Lösung ist. Nachdem das letzte Paket
mit 64byte raus ist und der Ringbuffer leer, muss ein weiteres leeres
Paket an den Endpoint gesendet werden. Das funktioniert in meinem Code
auch schon. Allerdings basiert der mehr auf der W.S. Version. In der
Version von Stefan sind die ganzen Änderungen von Niklas drin, da ist es
etwas schwieriger zu realisieren. Da wir nun die Ursache und Lösung des
Problems kennen, können sie die Herren über dieser Version dem ja
annehmen. Oder mit der 2.besten Lösung leben.
temp schrieb:> Mittlerweile weiss ich was die 100% Lösung ist.
Das du davon überzeugt bist, hast du bereits glaubwürdig rüber gebracht.
Danke, dass du dich da so tief rein gehängt hast.
Interessant ist, dass der Code nach so vielen (weit über 5) Jahren immer
noch reproduzierbare Bugs enthält. Selbst der HAL Code scheint nicht
unproblematisch zu sein und Arduinos mit integriertem USB zicken auch
herum.
Mich stört noch, dass die USB Schnittstelle sofort ausfällt, wenn ich
das Programm im Debugger anhalte. Das schränkt den Nutzen des Debuggers
massiv ein. Doch gerade das bessere (und damals erheblich billigere)
Debugging war für mich der Hauptgrund, mir die STM32 überhaupt
anzuschauen.
Was ich daraus für mich lerne ist, dass die externen USB-UART Chips noch
lange nicht obsolet geworden sind.
Stefan ⛄ F. schrieb:> Mich stört noch, dass die USB Schnittstelle sofort ausfällt, wenn ich> das Programm im Debugger anhalte. Das schränkt den Nutzen des Debuggers> massiv ein.
Das Problem mit dem Debugger ist, meistens bleiben die nach dem Start in
der main() stehen. Das kann man sicher anders konfigurieren. Wenn die
USB Enumerierung einmal durch ist, kann man auf einem Breakpoint stehen
bleiben ohne dass der USB-Kram ausfällt.
Bei den Bluepill-Boards mache ich immer folgendes. Vor der
main()-Methode konfiguriere ich den PA12 (der mit dem 1.5k Widerstand)
als OpenDrain Ausgang und auf LOW. Wenn der Debugger in der main anhält
wird das USB-Device im PC entfernt. Nach dem USBInit() o.ä. Wird dann
A12 wieder auf FloatInput gesetzt und ab da erst beginnt die
Enumeration. Bei dir würde das so aussehen:
temp schrieb:> Wenn die USB Enumerierung einmal durch ist, kann man auf einem> Breakpoint stehen bleiben ohne dass der USB-Kram ausfällt.
Aber wenn ich das Programm anhalte beantwortet er die SOF Interrupts
nicht mehr. Das wertet der PC als Disconnect. Oder habe ich da etwas
übersehen?
Stefan ⛄ F. schrieb:> Aber wenn ich das Programm anhalte beantwortet er die SOF Interrupts> nicht mehr. Das wertet der PC als Disconnect. Oder habe ich da etwas> übersehen?
Das Beantworten des SOF macht die Hardware, das hat nichts mit dem
Interrupt zu tun. Der wird nur zur Information gerufen. Ebenso wie ESOF.
Probiers doch aus und setze im laufenden Betrieb auf das
1
UsbSendChar(c,10);// warte max. 10ms
einen Breakpoint. Da hängt sich nichts auf, auch wenn du ein paar
Sekunden da stehen bleibst. Klar das PC-Programm geht irgendwann in den
Timeout, aber selbst wenn das passiert kann man es neu starten und der
USB Stack hängt sich nicht auf.
Kritisch ist bei mir immer nur die Enumeration am Anfang. Wenn da
zeitlich was klemmt kommt es zu Fehlern. Deshalb der Trick die
Enumeration nicht gleich beim Reset zu starten.
temp schrieb:> Da hängt sich nichts auf, auch wenn du ein paar> Sekunden da stehen bleibst.> Kritisch ist bei mir immer nur die Enumeration am Anfang.
Hmm, letztes Jahr hatte ich die vielen Trace-Meldungen eingebaut weil
das Enumerieren nicht klappte.
Das war damals der Part, den ich Debuggen wollte. Darüber sind wir ja
schon lange hinweg. Ich würde gerne mein Anwendungsprogramm debuggen.
Habe ich danach gar nicht mehr versucht. Da hatte ich wohl ein Brett
vorm Kopf.
Stefan ⛄ F. schrieb:> Interessant ist, dass der Code nach so vielen (weit über 5) Jahren immer> noch reproduzierbare Bugs enthält
Bugs lassen sich fast immer finden. Das ist aber auch kein Problem, es
gibt keinen fehlerfreien Code. Der Code von W.S. war ja ursprünglich für
eine ganz bestimmte Aufgabe gedacht, und das hat er ja auch gemacht. Im
Laufe der Zeit sind viele zusätzliche Anforderungen und Wünsche dazu
gekommen. So ist mir aufgefallen dass die Classrequests nicht arbeiten,
was aber erst wichtig wird wenn man eine richtige ser. Schnittstelle
ansprechen will.
Stefan ⛄ F. schrieb:> Was ich daraus für mich lerne ist, dass die externen USB-UART Chips noch> lange nicht obsolet geworden sind.
Ja dass ist sicherlich die einfachste Lösung. Wenn man aber sowieso
einen USB fähigen Controller hat, kann der das gleich miterledigen. Ich
mache das schon viele Jahre so. Ich gebe aber zu, dass ich bisher noch
sehr wenig mit ARM gemacht habe. Was ich anfangs nicht erkannt habe ist
die schlechte Umsetzung von USB bei den STMs und speziell den F103.
Selbst die pobligen CH552 schaffen es einen internen Connect Widerstand
auf den Bus zu legen, und bieten DMA von und zum USB core. Da ist z.B
ein FX2 geradezu übersichtlich.
Ich jedenfalls habe mir fest vorgenommen wenn meine Umsetzung fertig
ist, das gleiche auch mal auf einem F407 auf dem Discovery Board from
Scratch zu probieren.
Noch ein Update zu meinem VCP:
Ich hab das Ding hier soweit am laufen, bis zu 3 VCPs sind möglich mehr
gibt das USB Mem nicht her. Der erste arbeitet wie bisher, die anderen
gehen auf 2 Comports. Ich arbeite gerade an den ser. Schnittstellen.
Parallel baue ich das gleiche auch für die WCH CH552.
Thomas Z. schrieb:> Ich jedenfalls habe mir fest vorgenommen wenn meine Umsetzung fertig> ist, das gleiche auch mal auf einem F407 auf dem Discovery Board from> Scratch zu probieren.
Über das Ergebnis würden sich bestimmt viele Leute freuen, falls du es
veröffentlichst. Ich werde die F4 in diesem Leben wohl nicht mehr
einsetzen, da mir die kleineren schon mehr als ausreichend sind.
ich hatt gestern endlich wieder die Möglichkeit, an dem USB
weiterzuwerkeln.
Wenn ich euch richtig verstanden habe, betrifft die 64-Byte-Geschichte
ja den EpBulkIn (µC -> PC).
Der Fehler bei mir (Breakpoint-Test, Posting vom 25.3. ) ist ja beim
EpBulkOut, der µC empfängt die Daten dann ja garnicht richtig.
Konnte dieses Verhalten schon irgend jemand von euch reproduzieren?
Ich hab die Version von temp vom 28.3. ( mit Zeile 1351 in der usb.c)
jetzt mal auf einem Problemkandidaten laufen lassen:
Der µC wartet ja, bis 64 chars beisammen sind, und schickt die wieder
hoch.
Das funktioniert auch, wenn die einzelnen EpBulkOut-Transfers nur wenige
Zeichen lang sind.
Sobald ich einmal einen Block mit 30 Zeichen runterschicke, ist es
vorbei.
Da muss noch irgendwas anderes drinstecken, das verhindert dass ein
EpBulkOut IRQ kommt.
Alex schrieb:> Sobald ich einmal einen Block mit 30 Zeichen runterschicke, ist es> vorbei.
Ich denke wir können dir hier nicht mehr weiterhelfen. Mehrere Leute
haben unabhängig von einander den Test so gemacht wie du ihn uns
beschrieben hast. Dabei wurde ein Problem erkannt und gefixt was schon
lange im Code geschlummert hat und nur bei bestimmten Konstellationen
auftritt, die häufig niemals eintreffen. Dazu musste das Testprogramm
auch noch teilweise stundenlang laufen. Nach meiner Änderung traten
keine Probleme mehr auf.
Das hat mit deinen Problemen nichts zu tun denke ich. Irgendetwas ist
bei dir anders. Wenn du willst, kannst du mir ja mal eins von deinen
sowieso schlechten Modulen zum Testen überlassen.
Hast du die Tests mit dem Testprogramm von mir auch mal gemacht?
hab dein Programm jetzt auch mal kurz drüberlaufen lassen.
Bei einem guten Modul läufts, kommen Ausgaben, scheinen ok zu sein.
Bei einem schlechten stehts, keine Ausgab (nicht eine Zeile).
Ist im Grunde das, was nach meinen Tests auch zu erwarten ist, oder
nicht?
Dein Testprogramm schickt sofort 64 bytes runter, die kommen unten dann
nicht an (kein IRQ).
Alex schrieb:> Ist im Grunde das, was nach meinen Tests auch zu erwarten ist, oder> nicht?> Dein Testprogramm schickt sofort 64 bytes runter, die kommen unten dann> nicht an (kein IRQ).
Wie gesagt, ich wüsste nicht wie man dir noch helfen kann. Vor allem
weil du der einzige seit Jahren mit so einem Problem bist.



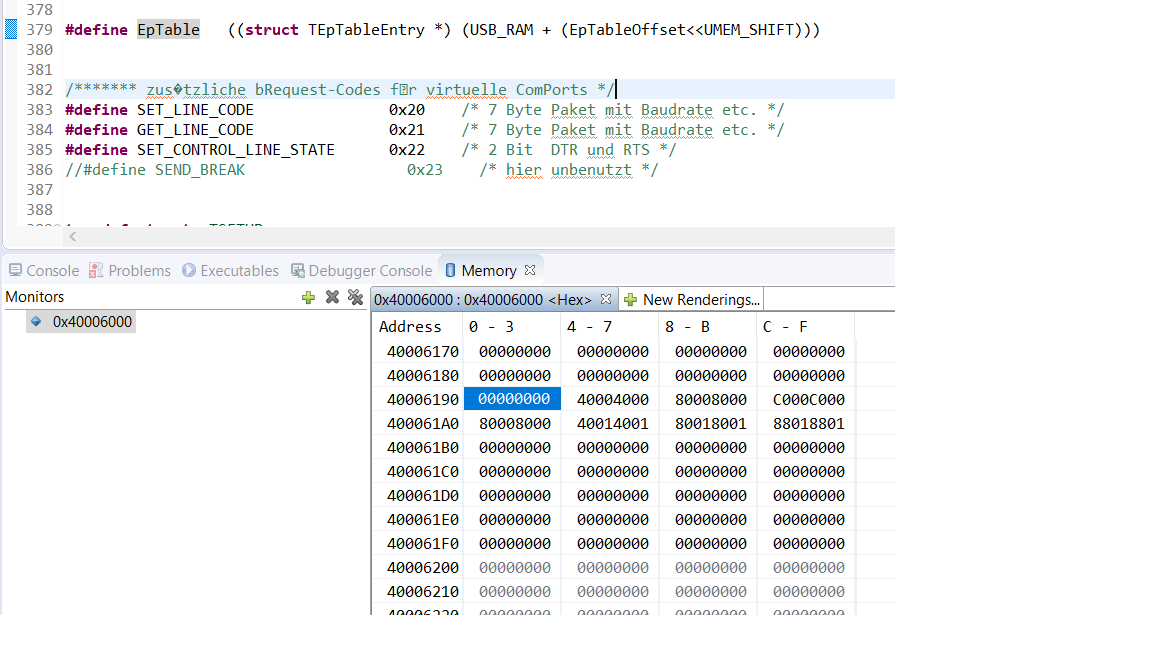


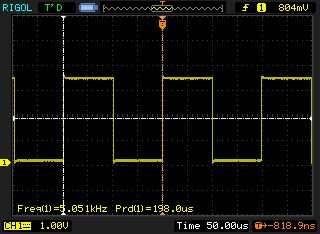
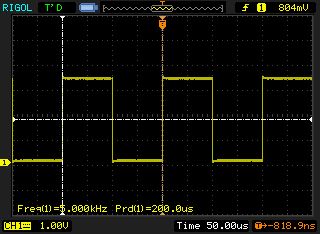








{kind=link}
{kind=link}